
A Novel Decomposed Optical Architecture for Satellite Terrestrial Network Edge Computing



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review and Contribution
2.1. Related Works
2.2. Motivation and Contribution
- (1)
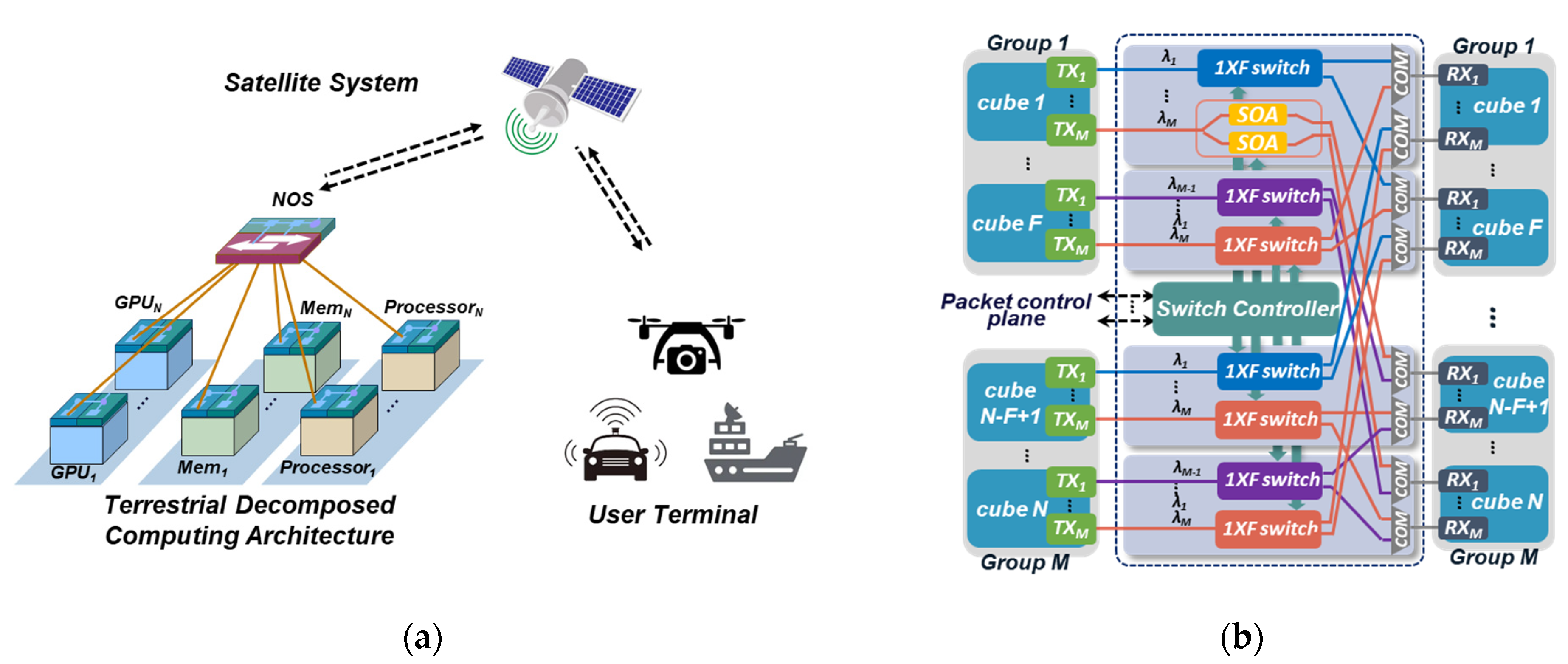
- A four-node decomposed computing prototype is experimentally implemented in this work, consisting of two processor nodes, two memory nodes, and one four-port NOS. The hardware cubes are implemented utilizing FPGA chip, and two independent interconnect channels are designed between hardware cubes and NOS for sending optical payload and signal tags respectively.
- (2)
- The physical and network performance of the decomposed computing prototype are investigated in experimental assessments. In the physical assessment, the SOA-based optical gates achieve ON/OFF switch ratios larger than 60 dB and ensure low inter-channel optical signal interference. The implemented prototype provides a none-error transmission among decomposed hardware cubes with 0.5 dB power compensation at a BER of 1 × 10−9. Meanwhile, in the network performance evaluation, the prototype performs an end-to-end latency of 122.3 ns and zero packet loss after link establishing.
- (3)
- As the NOS port count directly impacts the scalability and feasibility of decomposed architectures, we further investigate the physical performance in terms of output OSNR and required power penalty as a function of the NOS port count. The proposed decomposed architecture provides an output OSNR of up to 30.5 dB under the NOS port count of 64. Scaling the NOS port count to 64, an error-free operation with a power penalty of 1.5 dB is achieved.
- (4)
- The scalability of the NOS-based computing network with decomposed hardware is also evaluated in this work. Based on the experimentally measured parameters, the network performance of the NOS-based decomposed architecture is also numerically assessed under different network scales and link bandwidths. The results show that with a scale of 4096 hardware cubes and a memory cube access rate of 0.9, an end-to-end latency of 148.5 ns inside a rack and an end-to-end latency of 265.6 ns across racks are obtained under a link bandwidth of 40 Gb/s.
3. Decomposed Optical Network for STN Edge Computing
4. Experimental Demonstration of Decomposed Optical Architecture
4.1. Experimental Setup
4.2. Physical Performance of Decomposed Prototype
4.3. Network Performance of Decomposed Computing Prototype
5. Scalability and Discussion
5.1. Physical Performance under Different Port Counts
5.2. Network Performance under Larger Network Scales
5.3. Discussion
6. Conclusions
- (1)
- In the physical assessment, the implemented computing prototype with decomposed hardware cubes achieves none-error packet transmission based on the power compensation of 0.5 dB. Minimal signal interference across the optical channel is ensured with larger than 60 dB ON/OFF ratio of SOA-based gates.
- (2)
- For the network performance of the computing prototype with decomposed hardware cubes, an end-to-end access latency of 122.3 ns can be obtained in the experimental investigation, while there is zero packet loss after initial CDR procedure.
- (3)
- When scaling the NOS port count to 64, the NOS-based interconnect network provides optical signals with 30.5 dB OSNR at the receiver part of decomposed hardware cubes, while requiring power compensation of 1.5 dB for none-error packet transmission. Under a network scale of 4096 decomposed hardware cubes, numerical studies report an end-to-end access latency of 148.5 ns inside the same rack with an MCAR of 0.9 and TRX bandwidth of 40 Gb/s.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, T.; Kwak, J.; Choi, J.P. Satellite Edge Computing Architecture and Network Slice Scheduling for IoT Support. IEEE Internet Things J. 2021, 8, 1. [Google Scholar] [CrossRef]
- Xie, R.; Tang, Q.; Wang, Q.; Liu, X.; Yu, F.R.; Huang, T. Satellite-Terrestrial Integrated Edge Computing Networks: Architecture, Challenges, and Open Issues. IEEE Netw. 2020, 34, 224–231. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Guo, X.; Qu, Z. Satellite edge computing for the internet of things in aerospace. Sensors 2019, 19, 4375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, C.; Zhang, Y.; Xie, R.; Hao, X.; Huang, T. Integrating edge computing into low earth orbit satellite networks: Architecture and prototype. IEEE Access 2021, 9, 39126–39138. [Google Scholar] [CrossRef]
- Tang, Q.; Fei, Z.; Li, B.; Han, Z. Computation offloading in LEO satellite networks with hybrid cloud and edge computing. IEEE Internet Things J. 2021, 8, 9164–9177. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.; Xing, Z.; Peng, W.; Liu, L. A Computation Offloading Strategy in Satellite Terrestrial Networks with Double Edge Computing. In Proceedings of the 2018 IEEE International Conference on Communication Systems (ICCS), Chengdu, China, 19–21 December 2018; pp. 450–455. [Google Scholar] [CrossRef]
- Guo, J.; Chang, Z.; Wang, S.; Ding, H.; Feng, Y.; Mao, L.; Bao, Y. Who limits the resource efficiency of my datacenter: An analysis of alibaba datacenter traces. In Proceedings of the ACM 27th International Symposium on Quality of Service, Phoenix, AZ, USA, 24–25 June 2019; pp. 1–10. [Google Scholar]
- Lin, R.; Cheng, Y.; Andrade, M.D.; Wosinska, L.; Chen, J. Disaggregated data centers: Challenges and trade-offs. IEEE Commun. Mag. 2020, 58, 20–26. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Egi, N.; Panda, A.; Ratnasamy, S.; Shi, G.; Shenker, S. Network support for resource disaggregation in next generation datacenters. In Proceedings of the 12th ACM Workshop on Hot Topics in Netwworks (HotNets-XII), College Park, MD, USA, 21–22 November 2013. [Google Scholar]
- Li, C.-S.; Franke, H.; Parris, C.; Abali, B.; Kesavan, M.; Chang, V. Composable architecture for rack scale big data computing. Futur. Gener. Comp. Syst. 2017, 67, 180–193. [Google Scholar] [CrossRef] [Green Version]
- Bielski, M.; Syrigos, I.; Katrinis, K.; Syrivelis, D.; Reale, A.; Theodoropoulos, D.; Alachiotis, N.; Pnevmatikatos, D.; Pap, E.; Zervas, G.; et al. dReDBox: Materializing a full-stack rack-scale system prototype of a next-generation disaggregated datacenter. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1093–1098. [Google Scholar] [CrossRef]
- Alexoudi, T.; Terzenidis, N.; Pitris, S.; Moralis-Pegios, M.; Maniotis, P.; Vagionas, C.; Mitsolidou, C.; Mourgias-Alexandris, G.; Kanellos, G.T.; Miliou, A.; et al. Optics in Computing: From Photonic Network-on-Chip to Chip-to-Chip Interconnects and Disintegrated Architectures. J. Light. Technol. 2019, 37, 363–379. [Google Scholar] [CrossRef] [Green Version]
- Pfandzelter, T.; Bermbach, D. QoS-Aware Resource Placement for LEO Satellite Edge Computing. In Proceedings of the 6th International Conference on Fog and Edge Computing (ICFEC), Messina, Italy, 16–19 May 2022; pp. 66–72. [Google Scholar]
- Tong, M.; Wang, X.; Li, S.; Peng, L. Joint Offloading Decision and Resource Allocation in Mobile Edge Computing-Enabled Satellite-Terrestrial Network. Symmetry 2022, 14, 564. [Google Scholar] [CrossRef]
- Gao, P.X. Network requirements for resource disaggregation. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 249–264. [Google Scholar]
- Lim, K.; Turner, Y.; Santos, J.R.; AuYoung, A.; Chang, J.; Ranganathan, P.; Wenisch, T.F. System-level implications of disaggregated memory. In Proceedings of the IEEE International Symposium on High-Performance Comp Architecture, New Orleans, LA, USA, 25–29 February 2012; pp. 1–12. [Google Scholar]
- Shan, Y.; Huang, Y.; Chen, Y.; Zhang, Y. LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18), Carlsbad, CA, USA, 8–10 October 2018; pp. 69–87. [Google Scholar]
- Abrahamse, R.; Hadnagy, A.; Al-Ars, Z. Memory-Disaggregated In-Memory Object Store Framework for Big Data Applications. arXiv 2022, arXiv:2204.12889. [Google Scholar]
- Guo, X.; Xue, X.; Yan, F.; Pan, B.; Exarchakos, G.; Calabretta, N. DACON: A reconfigurable application-centric optical network for disaggregated data center infrastructures [Invited]. J. Opt. Commun. Netw. 2022, 14, A69–A80. [Google Scholar] [CrossRef]
- Ali, H.M.M.; El-Gorashi, T.E.H.; Lawey, A.Q.; Elmirghani, J.M.H. Future energy efficient data centers with disaggregated servers. J. Light. Technol. 2017, 35, 5361–5380. [Google Scholar]
- Saljoghei, A.; Yuan, H.; Mishra, V.; Enrico, M.; Parsons, N.; Kochis, C.; De Dobbelaere, P.; Theodoropoulos, D.; Pnevmatikatos, D.; Syrivelis, D.; et al. MCF-SMF Hybrid Low-Latency Circuit-Switched Optical Network for Disaggregated Data Centers. J. Light. Technol 2019, 37, 4017–4029. [Google Scholar] [CrossRef]
- Zhu, Z.; Di Guglielmo, G.; Cheng, Q.; Glick, M.; Kwon, J.; Guan, H.; Carloni, L.P.; Bergman, K. Photonic Switched Optically Connected Memory: An Approach to Address Memory Challenges in Deep Learning. J. Light. Technol 2020, 38, 2815–2825. [Google Scholar] [CrossRef]
- Gonzalez, J.; Palma, M.G.; Hattink, M.; Rubio-Noriega, R.; Orosa, L.; Mutlu, O.; Bergman, K.; Azevedo, R. Optically connected memory for disaggregated data centers. J. Parallel Distrib. Comput. 2022, 163, 300–312. [Google Scholar] [CrossRef]
- Ballani, H.; Costa, P.; Behrendt, R.; Cletheroe, D.; Haller, I.; Jozwik, K.; Karinou, F.; Lange, S.; Shi, K.; Thomsen, B.; et al. Sirius: A flat datacenter network with nanosecond optical switching. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM’20), Association for Computing Machinery, New York, NY, USA, 10–14 August 2020; pp. 782–797. [Google Scholar]
- Guo, X.; Yan, F.; Wang, J.; Exarchakos, G.; Peng, Y.; Xue, X.; Pan, B.; Calabretta, N. RDON: A rack-scale disaggregated data center network based on a distributed fast optical switch. J. Opt. Commun. Netw. 2020, 12, 251–263. [Google Scholar] [CrossRef]
- Yan, F.; Miao, W.; Raz, O.; Calabretta, N. OPSquare: A flat DCN architecture based on flow-controlled optical packet switches. J. Opt. Commun. Netw. 2017, 9, 291–303. [Google Scholar] [CrossRef]
- Miao, W.; Luo, J.; Lucente, S.D.; Dorren, H.; Calabretta, N. Novel flat datacenter network architecture based on scalable and flow controlled optical switch system. Opt. Express 2014, 22, 2465–2472. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drepper, U. What Every Programmer Should Know about Memory. Available online: http://people.redhat.com/drepper/cpumemory.pdf (accessed on 9 February 2015).
- Xilinx. UltraScale Architecture and Product Data Sheet: Overview. Available online: https://www.xilinx.com/products/silicon-devices/fpga/virtex-ultrascale.html (accessed on 20 May 2022).
- Xilinx. VC709 Evaluation Board for the Virtex-7 FPGA. Available online: https://www.xilinx.com/products/boards-and-kits/dk-v7-vc709-g.html (accessed on 11 March 2019).
- Xilinx. IBERT for UltraScale/UltraScale+ GTH Transceivers. Available online: https://www.xilinx.com/products/intellectual-property/ibert_ultrascale_gth.html (accessed on 4 February 2021).
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach, 6th ed.; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Matani, D.; Shah, K.; Mitra, A. An O(1) Algorithm for Implementing the lfu CACHE eviction Scheme. arXiv 2021, arXiv:2110.11602. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Zhang, Y.; Jiang, Y.; Wu, S.; Li, H. A Novel Decomposed Optical Architecture for Satellite Terrestrial Network Edge Computing. Mathematics 2022, 10, 2515. https://doi.org/10.3390/math10142515
Guo X, Zhang Y, Jiang Y, Wu S, Li H. A Novel Decomposed Optical Architecture for Satellite Terrestrial Network Edge Computing. Mathematics. 2022; 10(14):2515. https://doi.org/10.3390/math10142515
Chicago/Turabian StyleGuo, Xiaotao, Ying Zhang, Yu Jiang, Shenggang Wu, and Hengnian Li. 2022. "A Novel Decomposed Optical Architecture for Satellite Terrestrial Network Edge Computing" Mathematics 10, no. 14: 2515. https://doi.org/10.3390/math10142515
APA StyleGuo, X., Zhang, Y., Jiang, Y., Wu, S., & Li, H. (2022). A Novel Decomposed Optical Architecture for Satellite Terrestrial Network Edge Computing. Mathematics, 10(14), 2515. https://doi.org/10.3390/math10142515