
Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing


Abstract
:1. Introduction
- We demand the generated binary feature vectors should reconstruct both the original intra- and inter-modal neighbor structure, which guarantees the nearest neighbor retrieval results in the Hamming space are consistent with those in the original space.
- The proposed intra- and inter-modal pair-wise similarity preserving functions, which guarantee the similar samples have the same Hamming distance value to the anchor, can assign the same binary code to similar samples.
- For the triplet samples with different modalities, the cross-modal triple relative similarity preserving function demands that similar data pairs should have minimal distance values than those between dissimilar data pairs, which can avoid the imbalance code problem. Furthermore, it helps make the ranking orders of the retrieval results in the Hamming space identical to those in the original space.
2. The Proposed Method
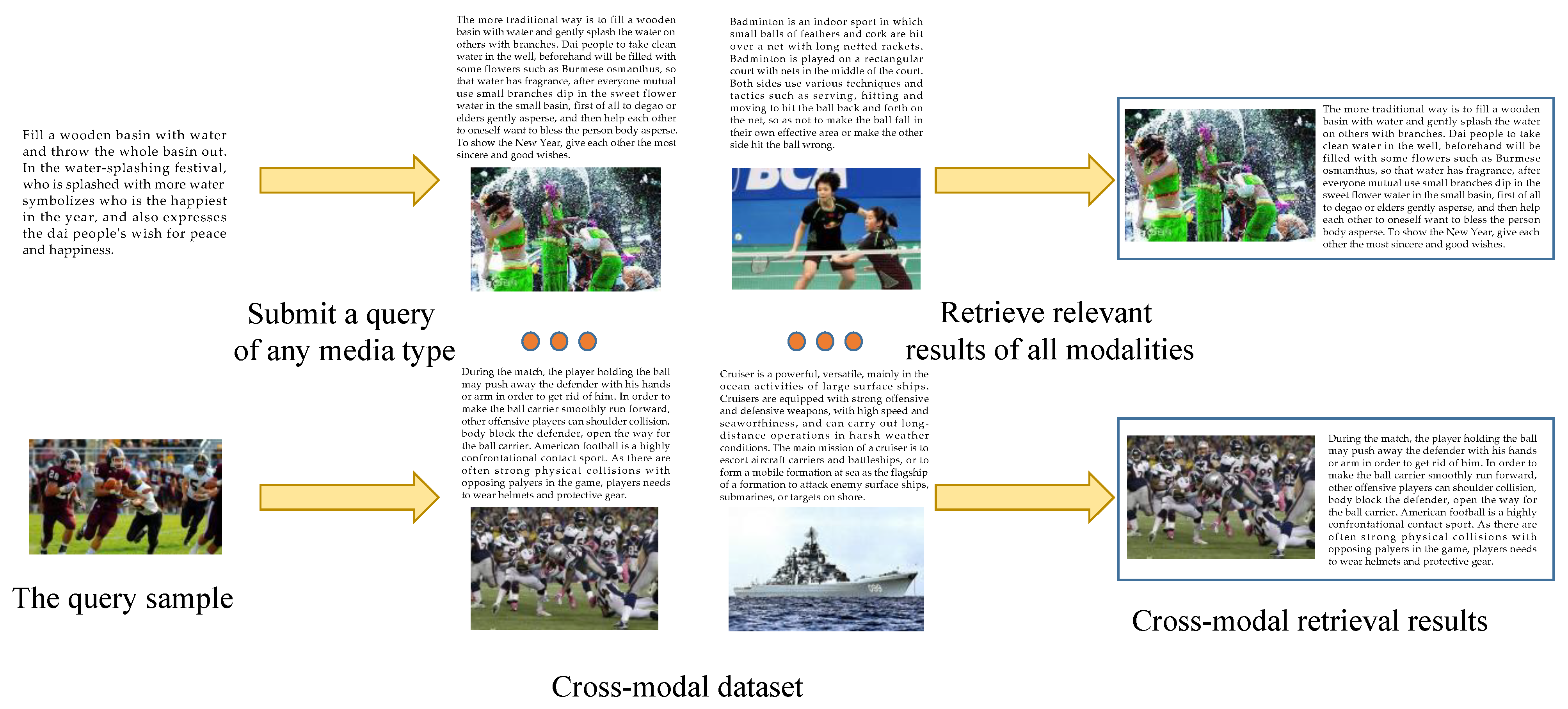
2.1. Cross-Modal Retrieval Algorithm
2.2. Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing
2.2.1. Deep Learning Binary Feature Vectors
2.2.2. Neighbor Structure Preserving
2.2.3. Cross-Modal Pair-Wise Similarity Preserving
2.2.4. Cross-Modal Triple Relative Similarity Preserving
2.2.5. Optimization
| Algorithm 1 Learning of our DRNPH |
| Input: Training set O = {Ii,Ti}ni=1; Batch size m; Max training epoch E; Hash code length k; ImgNet and TxtNet with the parameters , ; The parameters:. Output: Hashing functions ImgNet(Ii,) and TxtNet(Ti, ); 1. Initialize epoch h = 0; 2. Repeat 3. h = h + 1; 4. For i = 1: do 5. Randomly select a small training batch from OE = {Ii, Ti}Ei=1. 6. Generate the image feature FiI using the image network. 7. Generate the text feature FiT using the text network. 8. Calculate SI, ST, SIT by Equations (5), (7) and (8), respectively. 9. Compute the binary feature vectors B = tanh(H). 10. Compute the loss value L by Equation (17). 11. Optimize the network parameters by stochastic gradient descent mechanism. 12. end for 13. until convergence |
3. Experiments
3.1. Datasets
3.2. Experimental Setting
3.3. Evaluation Metrics
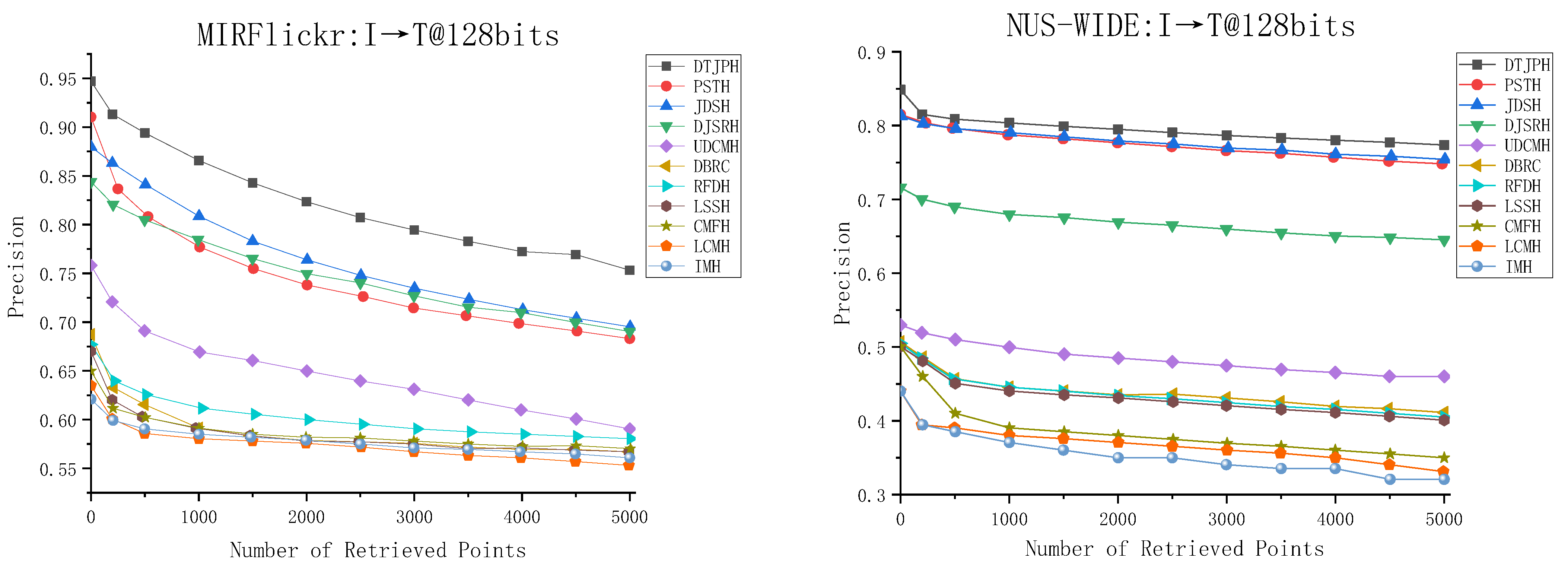
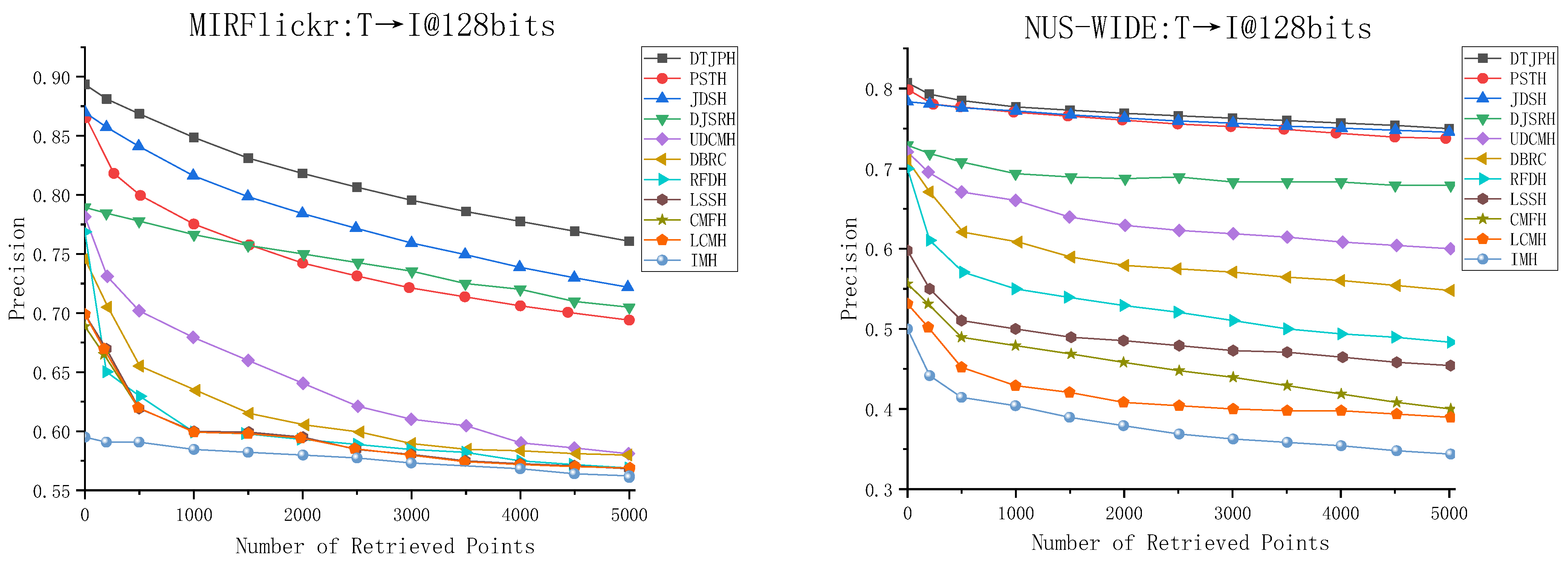
3.4. Experimental Results and Analysis
3.5. Ablation Experiments
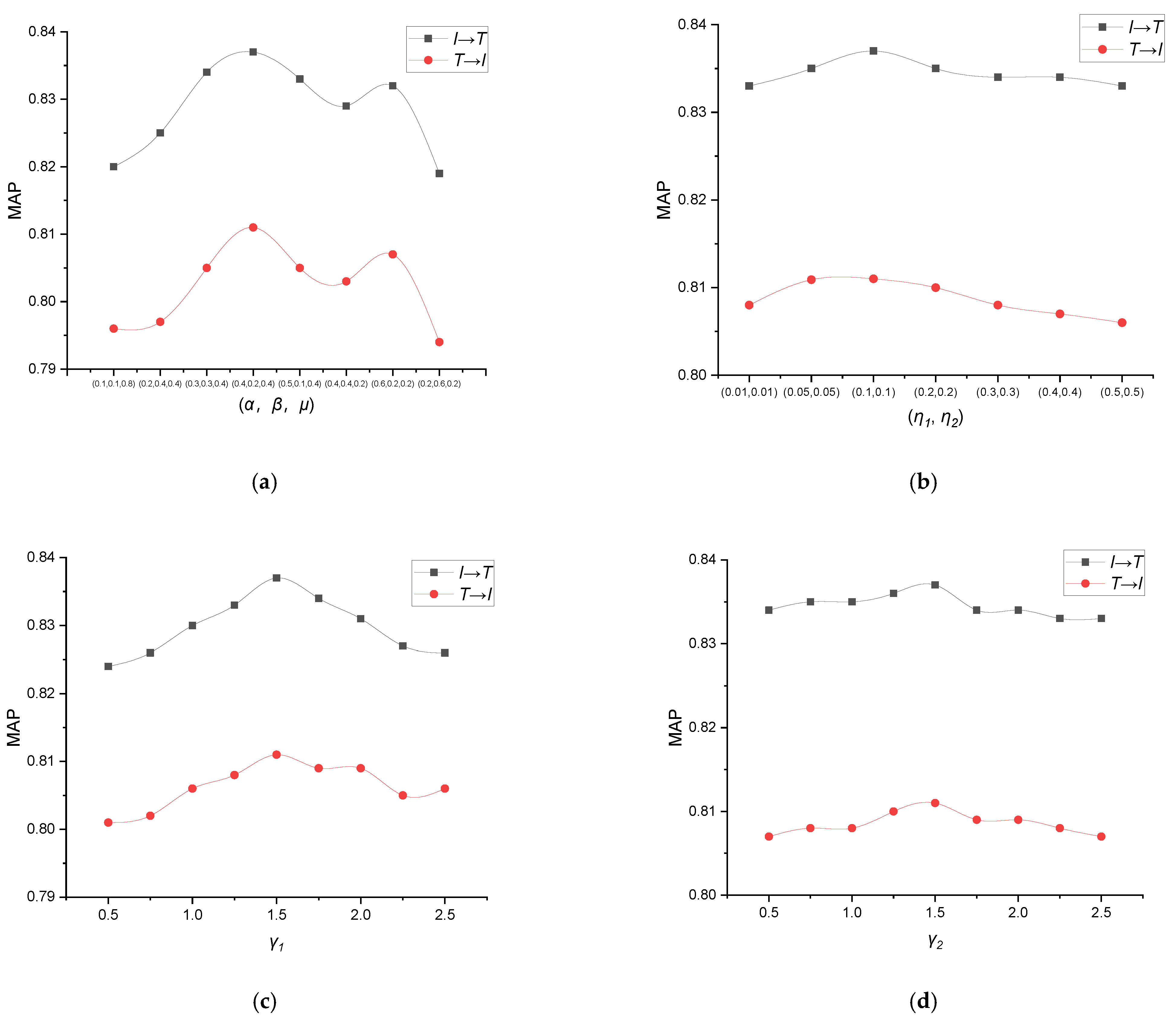
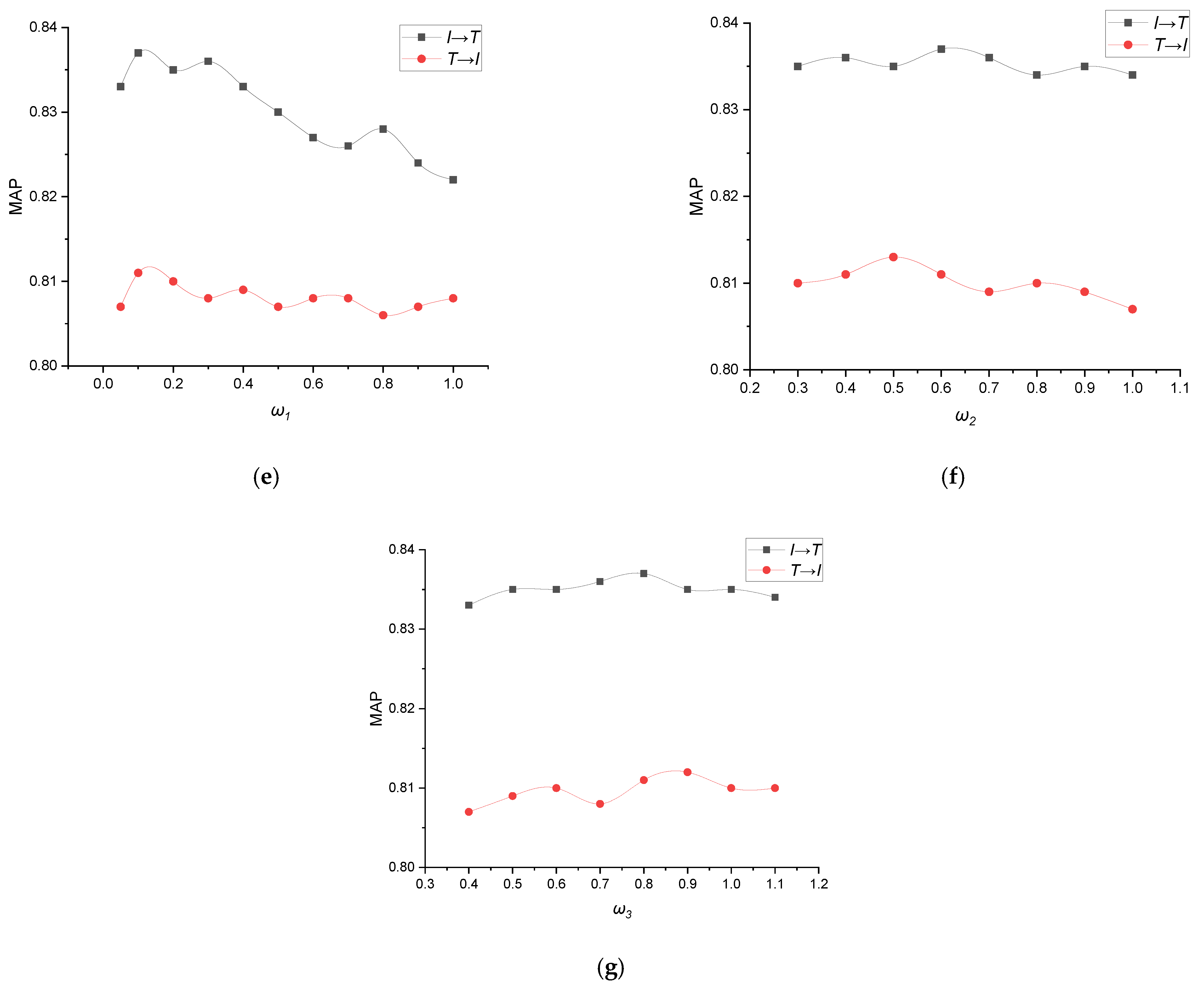
3.6. The Parameter Setting Experiments
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep Supervised Cross-Modal Retrieval. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yu, J.; Wu, X.-J.; Kittler, J. Discriminative Supervised Hashing for Cross-Modal Similarity Search. Image Vis. Comput. 2019, 89, 50–56. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Dimitrova, N.; Li, M.; Sethi, I.K. Multimedia content processing through cross-modal association. In Proceedings of the International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003. [Google Scholar]
- Rasiwasia, N.; Pereira, J.C.; Coviello, E.; Doyle, G.; Lanckriet, G.R.G.; Levy, R.; Vasconcelos, N. A new approach to cross-modal multimedia retrieval. In Proceedings of the International Conference on Multimedia, ACM, Florence, Italy, 25–29 October 2010. [Google Scholar]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-view discriminant analysis. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Wang, K.; He, R.; Wang, W.; Wang, L.; Tan, T. Learning coupled feature spaces for Cross-modal matching. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Kang, P.; Lin, Z.; Yang, Z. Pairwise similarity transferring hash for unsupervised cross-modal retrieval. Comput. Appl. Res. 2021, 38, 3025–3029. [Google Scholar]
- Su, S.; Zhong, Z.; Zhang, C. Deep Joint-Semantics Reconstructing Hashing for Large-Scale Unsupervised Cross-Modal Retrieval. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Hu, H.; Xie, L.; Hong, R.; Tian, Q. Creating Something from Nothing: Unsupervised Knowledge Distillation for Cross-Modal Hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, J.; Zhou, H.; Zhan, Y.; Tao, D. Deep Graph-neighbor Coherence Preserving Network for Unsupervised Cross-modal Hashing. In Proceedings of the Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021. [Google Scholar]
- Liu, S.; Qian, S.; Guan, Y.; Zhan, J.; Ying, L. Joint-modal Distribution-based Similarity Hashing for Large-scale Unsupervised Deep Cross-modal Retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020. [Google Scholar]
- Wang, K.; He, R.; Wang, L.; Wang, W.; Tan, T. Joint Feature Selection and Subspace Learning for Cross-Modal Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2010–2023. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Deng, C.; Wang, L.; Xie, D.; Liu, X. Coupled CycleGAN: Unsupervised Hashing Network for Cross-Modal Retrieval. In Proceedings of the Thirty-First Innovative Applications of Artificial Intelligence Conference, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Ding, G.; Guo, Y.; Zhou, J. Collective matrix factorization hashing for multimodal data. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Chen, D.; Cheng, M.; Min, C.; Jing, L. Unsupervised Deep Imputed Hashing for Partial Cross-modal Retrieval. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Zhang, J.; Peng, Y. Multi-Pathway Generative Adversarial Hashing for Unsupervised Cross-Modal Retrieval. IEEE Trans. Multimed. 2020, 22, 174–187. [Google Scholar] [CrossRef]
- Tuan, H.; Do, T.-T.; Nguyen, T.V.; Cheung, N.-M. Unsupervised Deep Cross-modality Spectral Hashing. IEEE Trans. Image Process. 2020, 29, 8391–8406. [Google Scholar]
- Shen, X.; Zhang, H.; Li, L.; Liu, L. Attention-Guided Semantic Hashing for Unsupervised Cross-Modal Retrieval. In Proceedings of the International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Wang, C.; Yang, H.; Meinel, C. Deep semantic mapping for cross modal retrieval. In Proceedings of the 2015 IEEE 27th International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015. [Google Scholar]
- Castrejon, L.; Aytar, Y.; Vondrick, C.; Pirsiavash, H.; Torralba, A. Learning aligned cross modal representations from weakly aligned data. In Proceedings of the Computer Vision and Pattern Recognition, LasVegas, NV, USA, 27–30 June 2016; pp. 2940–2949. [Google Scholar]
- Lin, Z.; Ding, G.; Han, J.; Wang, J. Cross view retrieval via probability-based semantics preserving hashing. IEEE Trans. Cybern. 2017, 47, 4342–4355. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, H.T.; Liu, L.; Yang, Y.; Xu, X.; Huang, Z.; Shen, F.; Hong, R. Exploiting Subspace Relation in Semantic Labels for Cross-Modal Hashing. IEEE Trans. Knowl. Data Eng. 2021, 33, 3351–3365. [Google Scholar] [CrossRef]
- Wang, L.; Zareapoor, M.; Yang, J.; Zheng, Z. Asymmetric Correlation Quantization Hashing for Cross-Modal Retrieval. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, X.; Wang, Y.; Xu, X.-S. Supervised Hierarchical Deep Hashing for Cross-Modal Retrieval. In Proceedings of the MM ’20: The 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Wang, J.; Li, G.; Pan, P.; Zhao, X. Semi-supervised semantic factorization hashing for fast cross-modal Retrieval. Multimed. Tools Appl. 2017, 76, 20197–20215. [Google Scholar] [CrossRef]
- Lin, Z.; Ding, G.; Hu, M.; Wang, J. Semantics-preserving hashing for cross-view retrieval. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kang, P.; Lin, Z.; Yang, Z.; Fang, X.; Bronstein, A.M.; Li, Q.; Liu, W. Intra-class low-rank regularization for supervised and semi-supervised cross-modal retrieval. Appl. Intell. 2022, 52, 33–54. [Google Scholar] [CrossRef]
- Wu, G.; Lin, Z.; Han, J.; Liu, L.; Ding, G.; Zhang, B.; Shen, J. Unsupervised Deep Hashing via Binary Latent Factor Models for Large-scale Cross-modal Retrieval. In Proceedings of the Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Song, J.; Yang, Y.; Yang, Y.; Huang, Z.; Shen, H.T. Inter-media hashing for large-scale retrieval from heterogeneous data sources. In Proceedings of the ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013. [Google Scholar]
- Zhu, X.; Huang, Z.; Shen, H.; Zhao, X. Linear cross-modal hashing for efficient multimedia search. In Proceedings of the ACM Multimedia Conference, Barcelona, Spain, 21–25 October 2013. [Google Scholar]
- Zhou, J. Latent semantic sparse hashing for cross-modal similarity search. In Proceedings of the 37th international ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, QLD, Australia, 6–11 July 2014. [Google Scholar]
- Wang, D.; Wang, Q.; Gao, X. Robust and Flexible Discrete Hashing for Cross-Modal Similarity Search. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2703–2715. [Google Scholar] [CrossRef]
- David, G.L. Object Recognition from Local Scale-Invariant Features. In Proceedings of the International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999. [Google Scholar]
- Zhang, C.; Zhong, Z.; Zhu, L.; Zhang, S.; Cao, D.; Zhang, J. M2GUDA: Multi-Metrics Graph-Based Unsupervised Domain Adaptation for Cross-Modal Hashing. In Proceedings of the International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021. [Google Scholar]
- Qiang, H.; Wan, Y.; Xiang, L.; Meng, X. Deep semantic similarity adversarial hashing for cross-modal retrieval. Neurocomputing 2020, 400, 24–33. [Google Scholar] [CrossRef]
- Jin, L.; Li, Z.; Tang, J. Deep Semantic Multimodal Hashing Network for Scalable Image-Text and Video-Text Retrievals. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Q.; Li, W. Deep Cross-Modal Hashing. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, Z.; Wu, N.; Yang, X.; Yan, B.; Liu, P. Deep Learning Triplet Ordinal Relation Preserving Binary Code for Remote Sensing Image Retrieval Task. Remote Sens. 2021, 13, 4786. [Google Scholar] [CrossRef]
- Wang, Z.; Sun, F.; Zhang, L.; Liu, P. Minimal Residual Ordinal Loss Hashing with an Adaptive Optimization Mechanism. EURASIP J. Image Video Process. 2020, 2020, 10. [Google Scholar] [CrossRef]
- Liu, H.; Ji, R.; Wu, Y.; Huang, F. Ordinal Constrained Binary Code Learning for Nearest Neighbor Search. In Proceedings of the Thirty-First Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhang, J.; Peng, Y.; Yuan, M. Unsupervised Generative Adversarial Cross-modal Hashing. In Proceedings of the Thirty-Second {AAAI} Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, C.; Deng, C.; Li, N.; Liu, W.; Gao, X.; Tao, D. Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhan, Y.; Yu, J.; Yu, Z.; Zhang, R.; Tao, D.; Tian, Q. Comprehensive Distance-Preserving Autoencoders for Cross-Modal Retrieval. In Proceedings of the MM ’18: ACM Multimedia Conference, Seoul, Korea, 22–26 October 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Siddan, G.; Palraj, P. Foetal neurodegenerative disease classification using improved deep ResNet classification based VGG-19 feature extraction network. Multimed. Tools Appl. 2022, 81, 2393–2408. [Google Scholar] [CrossRef]
- Mu, Y.; Ni, R.; Zhang, C.; Gong, H.; Hu, T.; Li, S.; Sun, Y.; Zhang, T.; Guo, Y. A Lightweight Model of VGG-16 for Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6916–6922. [Google Scholar]
- Zhang, C.; Meng, D.; He, J. VGG-16 Convolutional Neural Network-Oriented Detection of Filling Flow Status of Viscous Food. J. Adv. Comput. Intell. Intell. Inform. 2020, 24, 568–575. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Lew, M.S. The MIR Flickr retrieval evaluation. In Proceedings of the International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008. [Google Scholar]
- Chua, T.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. NUS-WIDE: A real-world web image database from National University of Singapore. In Proceedings of the International Conference on Image and Video Retrieval, Santorini Island, Greece, 8–10 July 2009. [Google Scholar]
- Olga, R.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar]
- Hu, D.; Nie, F.; Li, X. Deep Binary Reconstruction for Cross-modal Hashing. IEEE Trans. Multimed. 2019, 21, 973–985. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neighbor Structure Preserving | Cross-Modal Pair-Wise Similarity Preserving | Cross-Modal Relative Similarity Preserving | |
|---|---|---|---|
| UGACH [41] | × | × | √ |
| DCMH [37] | × | × | × |
| SSAH [42] | × | × | × |
| DSCMR [1] | × | √ | × |
| DSSAH [35] | √ | × | × |
| CDPAE [43] | × | √ | × |
| UKD [9] | × | √ | × |
| Our | √ | √ | √ |
| Task | Method | MIRFlickr | NUS-WIDE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 16 Bits | 32 Bits | 64 Bits | 128 Bits | 16 Bits | 32 Bits | 64 Bits | 128 Bits | ||
| IMH | 0.612 | 0.601 | 0.592 | 0.579 | 0.470 | 0.473 | 0.476 | 0.459 | |
| LCMH | 0.559 | 0.569 | 0.585 | 0.593 | 0.354 | 0.361 | 0.389 | 0.383 | |
| CMFH | 0.621 | 0.624 | 0.625 | 0.627 | 0.455 | 0.459 | 0.465 | 0.467 | |
| LSSH | 0.584 | 0.599 | 0.602 | 0.614 | 0.481 | 0.489 | 0.507 | 0.507 | |
| RFDH | 0.632 | 0.636 | 0.641 | 0.652 | 0.488 | 0.492 | 0.494 | 0.508 | |
| DBRC | 0.617 | 0.619 | 0.620 | 0.621 | 0.424 | 0.459 | 0.447 | 0.447 | |
| UDCMH | 0.689 | 0.698 | 0.714 | 0.717 | 0.511 | 0.519 | 0.524 | 0.558 | |
| DJSRH | 0.810 | 0.843 | 0.862 | 0.876 | 0.724 | 0.773 | 0.798 | 0.817 | |
| JDSH | 0.832 | 0.853 | 0.882 | 0.892 | 0.736 | 0.793 | 0.832 | 0.835 | |
| PSTH | 0.863 | 0.872 | 0.880 | 0.895 | 0.774 | 0.796 | 0.842 | 0.821 | |
| DRNPH | 0.876 | 0.902 | 0.914 | 0.933 | 0.790 | 0.811 | 0.826 | 0.837 | |
| Task | Method | MIRFlickr | NUS-WIDE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 16 Bits | 32 Bits | 64 Bits | 128 Bits | 16 Bits | 32 Bits | 64 Bits | 128 Bits | ||
| IMH | 0.603 | 0.595 | 0.589 | 0.580 | 0.478 | 0.483 | 0.472 | 0.462 | |
| LCMH | 0.561 | 0.569 | 0.582 | 0.582 | 0.376 | 0.387 | 0.408 | 0.419 | |
| CMFH | 0.642 | 0.662 | 0.676 | 0.685 | 0.529 | 0.577 | 0.614 | 0.645 | |
| LSSH | 0.618 | 0.626 | 0.626 | 0.628 | 0.455 | 0.459 | 0.468 | 0.473 | |
| RFDH | 0.681 | 0.693 | 0.698 | 0.702 | 0.612 | 0.641 | 0.658 | 0.680 | |
| DBRC | 0.618 | 0.626 | 0.626 | 0.628 | 0.455 | 0.459 | 0.468 | 0.473 | |
| UDCMH | 0.692 | 0.704 | 0.718 | 0.733 | 0.637 | 0.653 | 0.695 | 0.716 | |
| DJSRH | 0.786 | 0.822 | 0.835 | 0.847 | 0.712 | 0.744 | 0.771 | 0.789 | |
| JDSH | 0.825 | 0.864 | 0.878 | 0.880 | 0.721 | 0.795 | 0.794 | 0.804 | |
| PSTH | 0.845 | 0.844 | 0.845 | 0.861 | 0.749 | 0.769 | 0.803 | 0.791 | |
| DRNPH | 0.860 | 0.872 | 0.885 | 0.897 | 0.780 | 0.795 | 0.804 | 0.811 | |
| Task | Method | MIRFlickr | NUS-WIDE |
|---|---|---|---|
| DRNPH-1 | 0.899 | 0.807 | |
| DRNPH-2 | 0.904 | 0.811 | |
| DRNPH-3 | 0.910 | 0.815 | |
| DRNPH-4 | 0.925 | 0.831 | |
| DRNPH | 0.933 | 0.837 |
| Task | Method | MIRFlickr | NUS-WIDE |
|---|---|---|---|
| DRNPH-1 | 0.868 | 0.792 | |
| DRNPH-2 | 0.871 | 0.793 | |
| DRNPH-3 | 0.875 | 0.796 | |
| DRNPH-4 | 0.891 | 0.807 | |
| DRNPH | 0.897 | 0.811 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Wang, Z.; Wu, N.; Li, G.; Feng, C.; Liu, P. Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing. Mathematics 2022, 10, 2644. https://doi.org/10.3390/math10152644
Yang X, Wang Z, Wu N, Li G, Feng C, Liu P. Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing. Mathematics. 2022; 10(15):2644. https://doi.org/10.3390/math10152644
Chicago/Turabian StyleYang, Xiaohan, Zhen Wang, Nannan Wu, Guokun Li, Chuang Feng, and Pingping Liu. 2022. "Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing" Mathematics 10, no. 15: 2644. https://doi.org/10.3390/math10152644
APA StyleYang, X., Wang, Z., Wu, N., Li, G., Feng, C., & Liu, P. (2022). Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing. Mathematics, 10(15), 2644. https://doi.org/10.3390/math10152644