1. Introduction
Dynamic stochastic problems of asset accumulation and allocation subject to random shocks and occasionally binding constraints (for example, non-negativity constraints or limits on asset decumulation or aggregate borrowing) are important in numerical studies of commodity price volatility, macroeconomic fluctuations, and economic growth. Empirical analysis of such problems encounters significant challenges. We illustrate these in a simple model of price volatility in a market for a storable commodity such as grain that is our main focus here. The market includes an exponential positive trend in productivity, a random harvest shock, a non-negativity constraint on stocks, and Euler equations for deriving profit-maximizing storage decisions. These features are shared by many dynamic stochastic models of speculation, economic growth, or macroeconomic fluctuations with occasionally binding constraints and endogenous state-dependent volatility (see for example [
1,
2,
3,
4,
5], and references therein).
A natural way to estimate models with such features could be to implement the estimation of nonlinear Euler equations using the nonstationary observed data and letting the data reveal estimates of trends and other parameters relevant to the volatility of prices or other measures of value.
Even in our simple commodity market model, the exponential trend in the dependent variable (for example, price of a storable commodity) poses a challenge to identification first discussed in the context of a simple first-order decay model [
6].
Standard representation of the Euler equation normalized by the current (unknown) estimated value of the exponential trend solves this identification problem. However, if the aim is to estimate the value of at least one other parameter besides the trend, use of this normalization introduces a serious obstacle: a dichotomy in the empirical model implied by the Euler equation when the estimated trend parameter is in the neighborhood of its true value. This implies a discontinuity in the regression in the limit, rendering the approaches employed in available proofs of consistency inapplicable.
Studies that estimate parameters of models involving similar challenges generally take one of four currently prevalent approaches. The first is to ignore any trend as negligible (see for example [
7,
8,
9,
10,
11,
12,
13]), another is the common practice of resorting to linearization or log-linearization of Euler equations implied by inter-temporal arbitrage (which might well mis-specify the incentives implied by the model) (see [
14,
15,
16] for discussions of the serious implications of such mis-specifications), a third is de-trending of the data prior to estimation using the mean value of an exponential trend estimated on the data in a preliminary step (see [
2,
17,
18]), and a fourth is de-trending the data simultaneously with the estimation of all other unknown parameters but ignoring the endogenous interaction of the trend and economic incentives in the Euler equation (see for example [
1,
3,
19]).
Each of these approaches restricts the information that can be revealed in empirical analysis. How important are these restrictions? It has been difficult to address this question in the absence of a less restrictive approach that can be used for comparison.
We offer such a less restrictive approach—a one-step procedure to estimate all parameters simultaneously—to minimize the sum of squared residuals of the estimated nonlinear Euler equations, recognizing the interaction of an exponential trend in price with the endogenous economic incentives implied by the model.
We use nonlinear least squares which, as Wu [
20] notes in his classic paper, has a central role in inference of parameters in nonlinear regression models. Wu [
20] further notes that such inference is necessarily asymptotic but that much of the work prior to his paper focuses on problems such as asymptotic normality, avoiding the “harder problem” of consistency by assuming that it holds.
We address the key problem of consistency of our estimator in line with the suggestion of [
21] (p. 1050) to focus on extending asymptotic analysis to cases where the forcing variables are not necessarily stationary but have a time invariant representation.
Although exponential trends are commonly used in nonstationary dynamic models, the regressions implied by the Euler equations of the models we consider do not satisfy the sufficient conditions for consistency of estimators available in the literature. In particular, the uniform convergence condition in [
22], the Lipschitz condition of [
20], the Lipschitz conditions of [
23], the continuity-type smoothness conditions of [
24,
25], the differentiability conditions of [
26], and the stochastic Lipschitz conditions in [
27] do not hold.
Article [
28] established consistency and central limit theorems for models where the unobserved errors are independent, as assumed in [
20,
29]. In contrast, and in line with most of the empirical literature on nonlinear dynamic economic models, we consider cases where the residuals are Markovian and not independent.
To the best of our knowledge, in the four decades since [
21] there has been no study that provides asymptotic theory for the estimation of nonstationary nonlinear dynamic stochastic models of intertemporal arbitrage of the type we consider here. These models include an unknown exponential trend in the structure of the predictor that interacts with at least one other parameter and do not have independent errors.
In what follows, we address estimation of key parameters of economic models with endogenous volatility. The ability to test the assumption that any secular trend in the endogenous variable of interest is exactly zero is potentially important for tests of other parameters affecting dynamic stochastic behavior. Our main focus is on a dynamic stochastic model of commodity price behavior of a storable commodity such as wheat described in detail in [
2]. This model is a nonstationary extension of the classic stationary model of speculative arbitrage with occasionally binding non-negativity constraints on inventories in the tradition of [
30,
31,
32]. This model is highly relevant to current concerns with price prediction in markets with high and volatile commodity prices.
We develop a novel method of proof of consistency and asymptotic normality for such models. Thus, we establish a foundation for estimation and hypothesis testing, without
- (i)
Ignoring the possibility of a secular trend,
- (ii)
Using prior detrending,
- (iii)
Assuming linear or log-linear Euler equations,
- (iv)
Ignoring the possible interaction of a trend and other parameters in the Euler equation,
- (v)
Assuming independent errors.
In
Section 2, we present a background for the problem we solve. Then, in
Section 3, we present our main example, the commodity storage model. In
Section 4 and
Section 5, we present our proofs of identification, consistency, and asymptotic normality for this nonstationary model of speculative arbitrage of consumable commodity inventories with occasionally binding non-negativity constraints in the tradition of [
30,
31,
32].
We then, in
Section 6, show how our proofs can be applied to two empirical models of economic growth. The presentation of our results for such models is brief, since we discuss the same methodological challenge and use the same techniques as for the commodity storage model. The model in
Section 6.1 is a non-stationary version of the growth model of [
33], which, like many DSGE models, presents the additional challenge that the predictor in the regression is unbounded. In
Section 6.2, we address estimation of a two-sector empirical growth model with occasionally binding constraints in capital.
In
Section 7, we present numerical simulations of our results for the storage model in
Section 3; in
Section 8, we offer concluding remarks.
2. Preliminaries
In this section, we discuss the estimation problem and a general presentation of our approach to solving it.
The types of models we address include intertemporal Euler equations that imply regressions of the form:
where
is time,
is the vector of the unknown true values of at least two parameters, one of which is the exponential trend parameter,
is a compact set in
is a regressor, and
is a martingale difference sequence.
We present our results in the familiar setting of nonlinear least squares estimation although our approach can be more broadly applied. In the standard case [
22], the average of squared residuals
is uniformly convergent in
In the models we consider, this average is pointwise convergent for However, the presence of a quite standard exponential trend in the driving process implies that such convergence is not uniform.
Our proof of strong consistency of the least squares estimator of
is based on the proof of the following uniform strong law of large numbers:
where
,
is a ball centered at
with
, and
(For papers that prove similar uniform laws of large numbers for other regression models, see for example [
20] Lemma 1, p. 504, [
26] p. 1927, and [
27] pp. 878–879).
The regression models considered in this paper imply a new challenge for the proof of (
2). Specifically, for the commodity storage model we present in
Section 3, the predictor
f in (
1) is a function of
where
t is time,
is a value of the trend parameter in the ball
, and
is the true (unknown) value of the trend parameter.
More precisely, for the storage model,
where
is a regressor, and
is a vector of strictly positive estimated parameter values. The term
has a dichotomy when
passes through
Indeed, if
then
decreases exponentially with
In contrast, if
then
increases exponentially with
This dichotomy induces a discontinuity in
If
and at least one other parameter are unknown, the proof of (
2) is not necessarily immediate. In the nontrivial case, the ball
in (
2) includes
and values of
that are strictly less than
and other values for
that are strictly greater than
This implies that the discontinuity in
can occur in the interior of the ball
in (
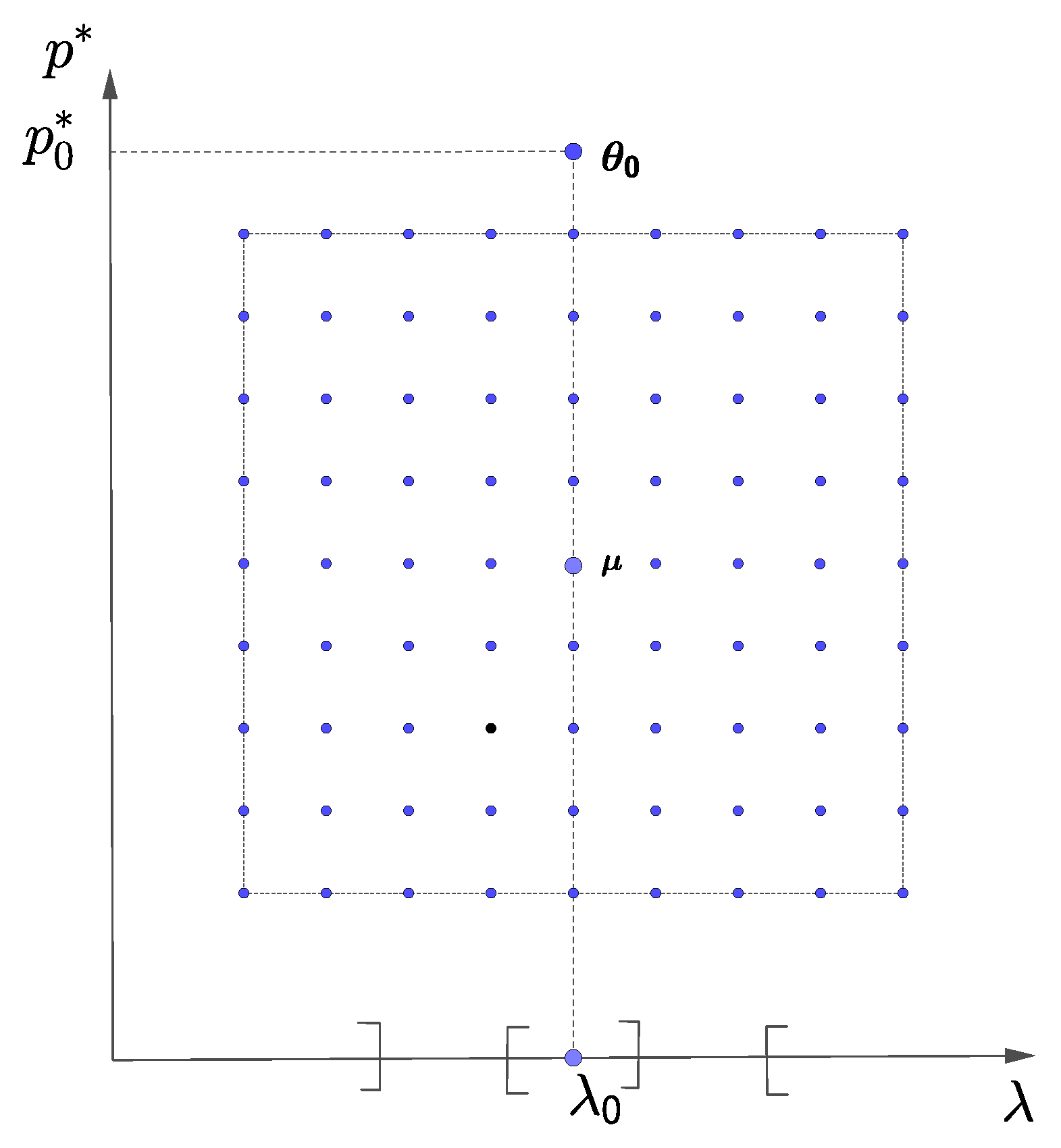
2). For simplicity, such a ball is illustrated in two dimensions by the square ball in
Figure 1, where we denote the other parameter as
and
is its unknown true value.
Were
the only unknown, the ball
would not include
, simplifying the proof of (
2). Indeed, the ball
would be an open interval strictly to the left or to the right of
, as illustrated by the alternate open intervals on the horizontal axis of
Figure 1. We shall refer to the dots in
Figure 1 when discussing the proof of Theorem 2 below, which makes use of sequences of arrays of discrete points such as the array for the square ball illustrated in
Figure 1.
The function f is such that small deviations in from can induce large deviations in the estimates of the other parameters. The presence of in the predictor f implies that the trend parameter estimator must be superconsistent if the estimators of the other unknown parameters are to be consistent.
In our proof of (
2), we use Azuma’s Lemma for martingale difference sequences [
34], to show that the predictor
f and its slope have a bound of polynomial order which we prove is killed by a negative exponential bound, uniformly on
In what follows, we address estimation of key parameters of three types of economic models with endogenous volatility in which the ability to test the assumption that any secular trend in the endogenous variable of interest is exactly zero is potentially important for tests of other parameters affecting dynamic stochastic behavior. Our main focus is on estimation of a dynamic stochastic model of commodity price behavior, addressed in
Section 3. This model is most relevant to the current concern with high and volatile prices of storable commodities.
4. Strong Consistency of Estimators
For the storage model discussed in the previous section, the estimation procedure in [
2] involves two steps. In a preliminary step, the exponential trend on the observed prices and time is estimated and the point estimate of the trend is used to "de-trend" the prices. In the second step, conditional on the point estimate of the trend parameter, estimate behavioral parameters related to short run arbitrage. In contrast, here we propose estimation of all key parameters of the model in a single step.
Given data on prices and time only, in this section we prove strong consistency of nonlinear least squares estimation of three key parameters of the model: the trend parameter, the detrended price threshold, and the interest rate, For clarity of exposition, in the remainder of this section and in the following section we write a subscript “0” to denote the true parameter values.
Our empirical model is based in the threshold nonlinear price autoregression (
10). The presence of an exponential trend in the threshold affects the regression predictor; in fact our empirical model violates key assumptions of continuous threshold models (see [
39] for a survey), including continuity of the regression in the limit.
Price changes have two distinct volatility regimes that are recurrent, a feature which is useful for the implementation of our estimation approach. In one regime, intertemporal arbitrage is not active, stocks are zero, and the predictor in regression (
1) is a function of calendar time and of the trend parameter. In the other regime, intertemporal arbitrage is active, the expected relative price change equals the interest rate, and the predictor in (
1) is independent of the trend parameter. This second regime allows us to bound the predictor in the regression and its slope with a bound of polynomial order which, using Azuma’s Lemma [
34], we prove is killed by a negative exponential bound.
For our asymptotic theory, we assume that the invariant distribution for the detrended price process has support
with
(For linear consumption demand, [
40] derives a finite upper bound
to guarantee
for all
t).
We assume that the parameter space is compact.
Our objective is to estimate
using least squares. Note that if
then we cannot identify
in (
11). Indeed, for
then there exists a ball
centered at
such that:
where
Therefore, the model in (
11) does not satisfy Wu’s ([
20] Theorem 1) necessary identification condition.
To avoid this problem, we divide the regression model (
11) by
where
To simplify the notation, we redefine the predictor as that is,
The normalized regression model is:
Remark 1. The predictors do not satisfy the Lipschitz condition for consistency in [20] (condition (3.6), p. 506), the Lipschitz condition of [23] (Assumption A 4, p. 1467), the continuity-type smoothness conditions of [24,25], or the Lipschitz conditions (3.10)–(3.11) of [27] (p. 874). Furthermore, the errors are not assumed to be independent, unlike the cases of [20] (lemma 2, p. 504), [28] (p. 551), and [29] (Lemma 3.1, p. 912). Remark 2. The predictor is non-differentiable at the 2-dimensional set therefore, it does not satisfy the conditions for consistency in [26]. Even if we change the predictor using a smooth perturbation, the predictor does not satisfy condition (2.3) in [26] (p. 1921). Our next remark explains why estimation of a log-linearized regression implied by the Euler equation (which is a natural alternative to our approach in this paper) has a problem of lack of identification.
Remark 3. Instead of Equation (12), we could write:whereand Taking natural logarithms,Let where denotes the expectation with respect to the invariant distribution of the ergodic process Note that Indeed, since ln is strictly concave and the invariant distribution is not deterministic, then implying that by the ergodicity of the detrended price process. Define and Then, we can write (15) as:where We could now use Equation (16) to estimate and This is an arguably simpler regression than (13), since t enters linearly inside the min operator. However, the parameter is clearly not identified from the estimate of in Equation (16), implying that we cannot use (16) for one-step estimation of and We now turn to the proof of identification of
in regression (
13). Given
and a ball
centered at
which does not contain
let
Using the fact that the price process has a unique invariant distribution which is a global attractor, our next result establishes that
diverges to infinity at rate at least
T, thus identifying
Theorem 1. Given there exists an open ball centered at and a constant , such that with probability one there is such that: Proof of Theorem 1. Let
Consider the nontrivial case where
Then,
Without loss of generality, we assume
For
close enough to
for appropriately chosen values of
on its ergodic support such that
and for
close enough to
we have:
If
then:
If
then we have two possible cases. Either
or
A straightforward calculation shows for arbitrary constant
we have that for all
except for a finite number of
Choosing small enough
and small enough radius of the ball
by the ergodicity of the price process
we conclude that there exists a constant
, and a
with:
□
Define
to be the least squares estimator of
that is,
Note that the term
in the predictor implies that the objective function in the least squares minimization does not converge uniformly in the parameter space. Hence, our objective function does not satisfy the uniform convergence condition of [
22].
Next, we establish that the least squares estimator for
is strongly consistent. Our proof of strong consistency follows the approach of [
41]. We prove the uniform convergence of
to zero. Since
is a bounded martingale difference sequence,
pointwise
Using Azuma’s Lemma [
34], we prove that for a sequence of arrays of points
with cardinality at most a polynomial of
T:
(
Figure 1 illustrates an example of square ball
, with base of length 2, for
).
The following theorem extends the uniform convergence result from the array
to the entire ball
In the proof, we use the structure of the predictor, which implies that:
where
is a finite constant.
Theorem 2. is strongly consistent, that is, Proof of Theorem 2. Let
and
a ball centered at
The strong consistency of
follows from the following uniform strong law of large numbers. See for example [
20] (Lemma 1, p. 504), [
26] (p. 1927), and [
27] (pp. 878–879):
Considering the facts that
is in a bounded set, that
(Theorem 1), and that
is a martingale difference sequence, it suffices to prove:
where
For the proof of (
20), we consider two Lemmata. For any given
consider a grid of
dots in the square ball
defined by:
(for
we denote by
the integer part of
that is, the greatest integer
).
An example of such a grid of dots is presented in
Figure 1, for
and
Lemma 1 presents the proof of (
20) for
. This partition technique is presented in [
42] for a trigonometric regression model with Gaussian innovations. Lemma 2 extends the result to
Proof of Lemma 1. Since
is a martingale difference sequence, we conclude that for any given
is a martingale difference sequence. Observing that this martingale sequence is bounded by a finite constant
using Azuma’s inequality [
34] we conclude that for any
for any
and for all
where the upper bound in (
22) is independent of
Since there are
points in
(
22) implies that for any
and for all
From the last inequality and the Borel–Cantelli Lemma, we conclude that with probability one:
□
Proof of Lemma 2. Let:
First, note that there exist finite positive constants
such that for any
Indeed,
(i) If
and
then applying the mean value theorem to
we conclude:
where
denote the minimum and the maximum values for the corresponding parameters.
(ii) If
and
by continuity of
and the fact that
there exists
between
and
with
We now repeat the argument in
i) to show (
23).
For any given
and any given
choose a point
in the grid
such that:
By (
23) and (
24), the first term goes to zero uniformly in
and by Lemma 1, the second term goes to zero uniformly in
. □
This concludes the proof of Theorem 2. □
5. Asymptotic Normality of Estimators
Our proof of asymptotic normality requires superconsistency of the estimator for the trend parameter. Precisely, we prove:
Proof of Proposition 1. If not, then with positive probability there exists
and a subsequence of natural numbers
satisfying:
which is a contradiction to the fact that with probability one we have:
□
Next, we establish asymptotic normality for the least squares estimator of the vector Since the predictors are non-differentiable, the least squares estimator of this model does not satisfy the smoothness conditions in the literature. Our proof of asymptotic normality uses smooth perturbations of the objective function.
Theorem 3. converges in distribution to a normal random vector with mean zero and covariance matrix given by where and are the following positive definite matrices:with and Proof of Theorem 3. By definition:
where
We apply the mean value theorem to the gradient Note that is not necessarily differentiable everywhere. To address this problem, we work with a smooth perturbation of
We say that a pair is a critical point of when That is, the critical pairs are those where is not differentiable. Define as the set of for which there is a critical pair in the segment joining with
Consider the following perturbation of
where
is a smooth perturbation of
More precisely,
is a function which is twice differentiable,
for any
in a neighborhood of
or of
and satisfies for all
for some positive finite constant
By the mean value theorem applied to
, we have:
for some
in the segment joining
with
Define Since then
To conclude the proof, it suffices to show that
converges weakly to a multivariate normal distribution and that:
converges in probability to a positive definite matrix (as
First note that any linear combination of the components of
is explicitly of the form
which is a martingale difference array satisfying the conditions in Theorem (2.3) in [
43] (p. 621). Therefore, any linear combination of the components of
converges in distribution to a normal distribution. By the Cramér–Wold Theorem [
44],
converges weakly to a normal multivariate distribution with zero mean and a variance–covariance matrix given by:
where
and
Clearly,
is a positive definite matrix.
Finally, using the superconsistency of
(Proposition 1), we conclude that:
which converges in probability to the matrix:
where
and
Clearly,
is also a positive definite matrix.
Therefore,
converges in distribution to the multivariate normal distribution:
□
6. Models of Optimal Economic Growth
In this section, we present two models of economic growth. They share the same estimation challenge as for the estimation of the storage model of
Section 3; thus our discussion for these models is brief.
6.1. One Sector Stochastic Growth with a Trend in Effective Labor Supply
In this subsection, we use the results presented in
Section 4 and
Section 5 to develop asymptotic theory for estimation of a neoclassical one-sector model of economic growth.
To present our example of a growth model in a familiar setting, we use the model of [
33], with the standard modification to include technological change that increases the supply of effective labor at time
by a constant factor
We normalize initial labor to be equal to one; thus
. The production function is
, where
is capital at time
t, and
is an independently and identically distributed (
) shock with compact support
.
Our results in this section can be extended to incorporate risky labor supply and unbounded productivity shocks, using the convergence results of [
45,
46,
47].
Preferences are of the constant relative risk aversion type, , where is consumption at time and is a known constant. Logarithmic utility is the limiting case as
Conditional on a given level of initial resources , the maximization problem is:
subject to
where denotes expectation conditional on information at time 0 and
Define , . Then the maximization problem has a stationary representation:
subject to
with .
Let
Assume that
Then [
33] (Lemma 3.2), implies that there are strictly positive real numbers
and
such that
and
, for all
in the ergodic set.
The Euler equation for this problem is:
In terms of trending consumption and trending capital, Equation (
25) implies:
where
For clarity of exposition, in the remainder of this subsection we write a subscript “0” to denote the true parameter values. Given data on and , our objective is to estimate . We assume that the parameter space is compact.
Clearly, there exists a finite
M such that
This bound allows us to define the predictor
as:
Equations (19) and (20) imply the following regression model:
The predictor has variations that are of order more specifically,
We define the least squares estimator as:
The proofs of the results in this section are similar to the corresponding proofs for the storage model; thus, we only offer further notes for their proofs.
We now present the identification theorem for For a given and a ball centered at which does not contain let
As in the storage model, diverges to infinity a rate of at least More precisely:
Theorem 4. Given there exists an open ball centered at and a constant , such that with probability one there is such that: Proof of Theorem 4. Let Consider the nontrivial case where Without loss of generality, we assume Using the same proof of Theorem 1, it suffices to note that:
where is near and for some
Our next results are similar to the results in Theorem 2 and Proposition 1 of
Section 4 and
Section 5.
Proof of Theorem 5. There exist finite positive constants such that for all
□
Proof of Proposition 2. We now summarize the proof of superconsistency for the estimator of
The proof proceeds by contradiction. If the result does not hold, with positive probability there exists
and a subsequence of natural numbers
satisfying:
which is a contradiction of the fact that with probability one:
□
Next, we present our asymptotic normality result for this model.
Theorem 6. converges in distribution to a normal random vector with mean zero and covariance matrix where and are the following positive definite matrices:andwith , , ,
,
and 6.2. Two-Sector Growth Model with an Occasionally Binding Constraint on Capital
In this subsection, we present a two-sector model of economic growth. In the model, as in the storage model in
Section 3 above, the consumption process alternates between two endogenous regimes separated by a consumption threshold. In one regime, consumption follows a downward stochastic trend, and in the other regime, consumption in expectation exhibits jumps towards a trending attractor. Realized marginal utility can be highly volatile in this regime in which labor productivity grows at a fixed exogenous rate
, and labor is distributed among two sectors in fixed proportions
a and
with
In one sector, production is exogenous, proportional to labor and to the realization of an shock h. The production function of the second sector is Cobb–Douglas, using capital as well as labor. Total capital in this sector is the sum of human capital proportional to effective labor, , and the discretionary capital stock K, which is endogenous and bounded below by zero. For example, consider a peasant economy with a non-irrigated sector subject to weather uncertainty and a capital-intensive irrigated sector with deterministic output.
The production function is given by:
where
are known constants.
Suppose that preferences over consumption are Each period, after observation of total production, the consumer chooses the amount of consumption and of the discretionary capital stock. Conditional on a given level of initial resources the maximization problem is:
subject to
Effective labor at time t is given by . Let . The problem can then be stated in units of effective labor:
subject to
given.
where
The value function satisfies the Bellman equation:
The value function
V is strictly concave (the strict concavity of
V is a nontrivial implication of the strict concavity of
see [
48]), implying that the consumption function
is strictly increasing in
In particular,
and then
Furthermore,
with first order necessary conditions implying:
where
From (
32), we conclude:
where
and
Equivalently:
where
Write a subscript “0” to denote the true parameter values. Assuming that
are known,
is the parameter vector to estimate. The vector
belongs to a compact set
There exists a finite
M such that
This bound allows us to define the predictor
as:
Equations (33) and (34) imply the following regression model:
Define the least squares estimator as:
We assume that the distribution of the shocks is absolutely continuous with a strictly positive derivative on the interior of its support, assumed compact. Similar to the commodity storage model of
Section 4, the ergodicity properties of the model can then be used to show that the detrended consumption process
is aperiodic and positive Harris recurrent, implying that it has a unique invariant distribution which is a global attractor. We assume that the threshold
lies in the interior of the invariant distribution for the detrended marginal value process.
We merely state our results here and do not offer proofs of consistency and asymptotic normality for this model because they use the same tools as those used in the proofs presented for the models in the previous two sections.
Results:
where
and
are the following positive definite matrices:
and
where:
7. Finite Sample Properties of Our Estimator
In this section, we provide results of Monte Carlo experiments to illustrate the performance of our estimator for finite samples. We simulate the nonstationary storage model discussed in
Section 3.
For our first specification of parameter values and functions, we take a widely used parametrization of the storage model (see for example [
2,
7,
11,
49,
50]). We include a trend in supply shocks that implies a trend in price of
per period, the same price trend used in the heuristic storage model simulated in [
2]. Inverse consumption demand is
The interest rate is
The shocks have a Gaussian distribution with expectation equal to 100 and standard deviation equal to
Following [
2,
8,
9], we approximate the normal distribution of the shocks with 10 nodes each of probability
using the procedure of [
51]. The nodes are 82.45, 89.55, 93.23, 96.14, 98.74, 101.26, 103.86, 106.77, 110.45, and 117.55.
To solve the model, we iterate on the SREE price function p on a grid of 3000 equally spaced nodes on detrended available supply For values of z not on those grid points, we interpolate p using cubic splines. We then generate independent draws from the normal discretized distribution of the supply shocks, and simulate 300,000 consecutive prices. This large sample allows us to generate 300,000 − successive samples of size T, the first starting from period thesecond from period etc.
We summarize our Monte Carlo experiments for this case in
Table 1. For all parameter estimates at sample sizes of 500, the medians (50th percentile) of the distribution of estimates are already quite close to the true parameter values. As predicted by our theory, the convergence is particularly fast for trend parameter
The column ASE in
Table 1 corresponds to the average of the evaluation of the expression for the asymptotic standard error using the corresponding element in the main diagonal of the asymptotic covariance matrix reported in Theorem 3. Particularly for samples of sizes 500 or higher, this lower bound for the standard error of the parameter estimates is quite close to the standard error and to the root mean squared error (RMSE) of the estimates.
As checks on the robustness of our results,
Table 2 and
Table 3 show two other cases. These are taken from the stationary commodity storage models simulated in [
7] (see Table 2 in [
7]) but assuming no depreciation of inventories. (For simplicity, the set of commodity storage models considered in this paper assume zero depreciation, although it is straightforward to generalize our results for cases with positive depreciation.) The case in
Table 2 corresponds to an inverse consumption demand
the interest rate is
and the distribution of the shocks is the same as in the model in
Table 1. The case in
Table 3 has
and shocks have a lognormal distribution such that the log of the shocks are normally distributed with mean zero and standard deviation
We discretize the lognormal distribution using the same procedure as for the other two cases, with 10 nodes of probability
each.
Table 2 and
Table 3 confirm the convergence of our estimators and the relevance of the expressions for asymptotic standard errors for the small sample sizes considered.
All these experiments have been executed on Microsoft Windows 11 Home x64 PC system with an Intel Core i7-1165G7 @2.80Ghz processor and 12 GB of RAM, using MATLAB R2022a.


 ,
, 

{kind=link}