1. Introduction
The utility of mixture distributions during the last decade or so have provided a mathematical-based strategy to model a wide range of random phenomena effectively. Statistically speaking, the mixture distributions are a useful tool and have greater flexibility to analyze and interpret the probabilistic alias random events in a possibly heterogenous population. In modeling real-life data, it is quite normal to observe that the data have come from a mixture population involving of two or more distributions. One may find ample evidence(s) in terms of applications of finite mixture models not limited to but including in medicine, economics, psychology, survival data analysis, censored data analysis and reliability, among others. In this article, we are going to explore such a finite mixture model based on bounded (on (0,1)) univariate continuous distribution mixing with another baseline (
G) continuous distribution and will study its structural properties with some applications. Next, we provide some useful references related to finite mixture models that are pertinent in this context. Ref. [
1] introduced the classical and Bayesian inference on the finite mixture of exponentiated Kumaraswamy Gompertz and exponentiated Kumaraswamy Fréchet (MEKGEKF) distributions under progressively type II censoring with applications and it appears that this MEKGEKF distribution might be useful in analyzing certain dataset(s), for which either or both of its component distributions will be inadequate to completely explain the data. Consequently, this also serves as one of the main purposes for the current work.
In recent years, there has been a lot of interest in the art of parameter(s) induction to a baseline distribution. The addition of one or more extra shape parameter(s) to the baseline distribution makes it more versatile, particularly for examining the tail features. This parameter(s) induction also improved the goodness-of-fit of the proposed generalized family of distributions, despite the computational difficulty in some cases. Over two decades, there have been numerous generalized G families of continuous univariate distributions that have been derived and explored to model various types of data adequately. The exponentiated family, Marshall–Olkin extended family, beta-generated family, McDonald-generalized family, Kumaraswamy-generalized family, and exponentiated generalized family are among the well-known and widely recognized G families of distributions that are addressed in [
2]. Some Marshall–Olkin extended variants and the Kumaraswamy-generalized family of distributions are proposed. For the exponentiated Kumaraswamy distribution and its log-transform, one can refer to [
3]. Refs. [
4,
5] defined the probability density function (pdf) of exponentiated Kumaraswamy G (henceforth, in short, EKG) distributions, which is as follows:
where
are all positive parameters and
.
The associated cumulative distribution function (cdf) is given by
If
the associated quantile function is given by
In this paper, we consider a finite mixture of two independent EKW distributions with mixing weights and consider an absolute continuous probability model, namely the two-parameter Weibull, as a baseline model.
The rest of this article is organized as follows. In
Section 2, we provide the mathematical description of the proposed model. In
Section 3, some useful structural properties of the proposed model are discussed. The maximum likelihood function of the mixture exponentiated Kumaraswamy-G distribution based on progressively type II censoring is given in
Section 4.
Section 5 deals with the specific distribution of the mixture of exponentiated Kumaraswamy-G distribution when the baseline (
G) is a two parameter Weibull, henceforth known as EKW distribution. In
Section 6, we provide a general framework for the Bayes estimation of the vector of the parameters and the posterior risk under different loss functions of the exponentiated Kumaraswamy-G distribution. In
Section 7, we consider the estimation of the EKW distribution under both the classical and Bayesian paradigms via a simulation study and under various censoring schemes. For illustrative purposes, an application of the EKW distribution is shown by applying the model to bladder cancer data in
Section 8. Finally, some concluding remarks are presented in
Section 9.
3. Structural Properties
We begin this section by discussing the asymptotes and shapes of the proposed mixture model in Equation (3).
There may be more than one root to the Equation (5). If x = x* is the root of the equation, it corresponds to a local maximum, or a local minimum or a point of inflexion depending on where .
A random variable is said to have the exponentiated-G distribution with parameter
if
and if its pdf and cdf is given by
and
, as shown in [
6,
7].
If one considers the following, we have the following equations:
Therefore,
where
and
Note that if , , are integers, then the repective sums will stop at , , and .
The above expression shows the fact that the pdf of the finite mixture of EKG can be represented as the finite mixture of infinite exponentiated-G distribution with parameters and , respectively.
Therefore, structural properties, such as moments, entropy, etc., of this model can be obtained from the knowledge of the exponentiated-G distribution and one can refer to [
8] for some pertinent details.
Method 1. Direct cdf inversion method
Step 1: Generate
Step 2: Then, set .
Method 2. Via acceptance-rejection sampling plan
This will work if .
One must define
and
Then, the following scheme will work:
- (i)
Simulate from the pdf in Equation (3).
- (ii)
Simulate , where .
- (iii)
Accept as a sample from the target density if If one must go to step (ii).
One may obtain an expression of the reliability function of mixture EKG, which takes the following form:
where the component-wise reliability function of the mixture model is given by
The density in Equation (1) is flexible in the sense that one can obtain different shapes of hazard rate function (hrf) of the mixture model, which is given by
The quantile function of the mixture model is given by
For example, the median,
, of
for
will be
The various shapes of the pdf and the hrf when the baseline distribution (
G) is Weibull is provided in
Figure 1. In the next section, we discuss the maximum likelihood estimation strategy for the finite mixture of exponentiated Kumaraswamy-G (EKG) distribution under the progressive type-II censoring scheme. For more details, one can refer to [
9]. The necessary and sufficient conditions for identifiability and identifiability properties are discussed in the
Appendix A.
5. Finite Mixture of Exponentiated Kumaraswamy Weibull Distribution
Exponentiated Kumaraswamy Weibull (EKW) distribution is a special case that can be generated from exponentiated Kumaraswamy -G distributions. The EKW distribution is found by taking
G(
x) of the Weibull distribution in Equation (1). One of the most important advantages of the EKW distribution is its capacity to fit data sets with a variety of shapes, as well as for censored data, compared to the component distributions. One must let
G be the Weibull distribution with the pdf and the cdf are given by
and
The inverse of the cdf is given by
The pdf of a mixture of two component densities with mixing proportions, (
for
q = 1 −
p of the exponentiated Kumaraswamy Weibull distribution (henceforth, in short is MKEW) is given by
For the pdf in Equation (6), the following is noted:
- (i)
are the scale parameters and are the shape parameters for the Weibull component.
- (ii)
, are the shape parameters arising from the finite mixture pdf in Equation (4);
- (iii)
are the mixing proportions ,where .
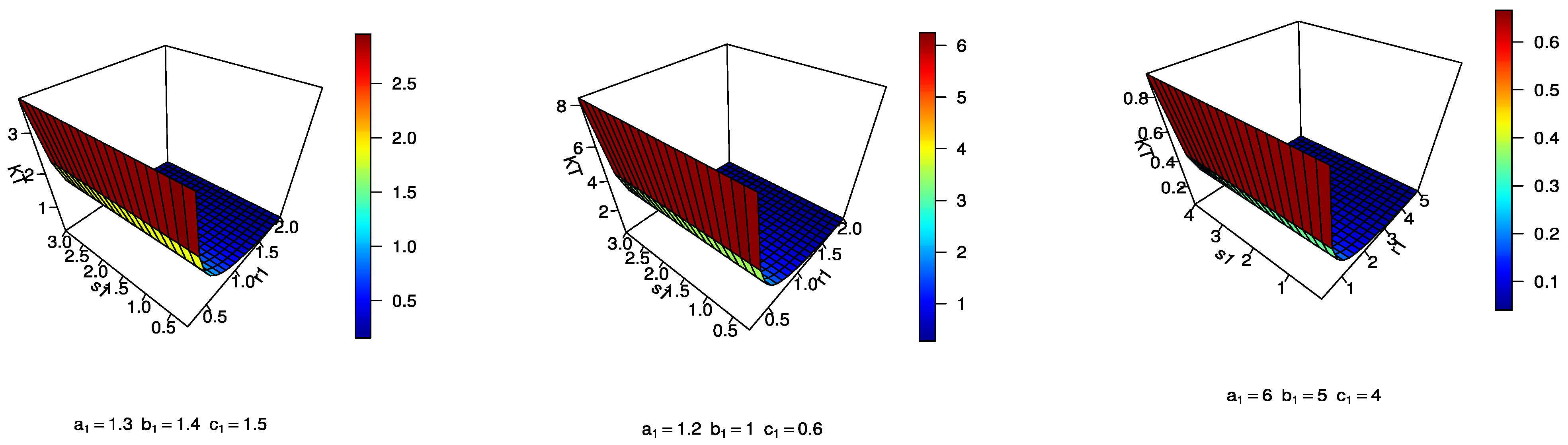
Depending on the different values of the parameters, different shapes of the pdf and the hrf of the MEKW distribution are shown in
Figure 1. From
Figure 1 (left panel), it appears that the MEKW pdf can include symmetric, asymmetric, right-skewed, and decreasing shapes, depending on the values of parameters. From
Figure 1 (right panel), one can observe that the hrf may assume shapes with constants and that are down-upward and increasing.
The associated cdf is given by
The hazard rate function of MEKW,
model is flexible, as it allows for different shapes, which is given by
The quantile function is given by
In the next section, by using a quantile function-based formula for skewness and kurtosis, we plot the coefficients of skewness and kurtosis for the MEKW distribution for different values of the parameters, as shown in
Figure 2. From
Figure 2, one can observe that the distribution can be positively skewed, negatively skewed, and could also assume platykurtic and mesokurtic shapes.
In the next section, we discuss a strategy of estimating parameters for the EKG model under the Bayesian paradigm using independent gamma priors.
5.1. Bayesian Estimation Using Gamma Priors for the Finite Mixture of Exponentiated Kumaraswamy-G Family
In this section, we consider the Bayes estimates of the model parameters that are obtained under the assumption that the component random variables for the random vector
have independent gamma priors with hyper parameters
, which is given by
By multiplying Equation (6) with the joint posterior density of the vector
, given the data, we can obtain the following:
Marginal posterior distributions of can be obtained by integrating out the nuisance parameters. Next, we consider the loss function that will be used to derive the estimators from the marginal posterior distributions.
5.2. Bayes Estimation of the Vector of Parameters and Evaluation of Posterior Risk under Different Loss Functions
This section spotlights the derivation of the Bayes estimator (BE) under different loss functions and their respective posterior risks (PR). For a detailed study on different loss error functions, one can refer to [
10]. The Bayes estimators are evaluated using the squared error loss function (SELF), weighted squared error loss function (WSELF), precautionary loss function (PLF), modified (quadratic) squared error loss function (M/Q SELF), logarithmic loss function (LLF), entropy loss function (ELF), and K-Loss function. The K-loss function proposed by [
11] is well fitted for a measure of inaccuracy for an estimator of a scale parameter of a distribution defined by
this loss function is called the K-loss function (KLF).
Table 1 shows the Bayes estimators and the associated posterior risks under each specific loss functions considered in this paper.
Next, we derive the Bayes estimators of the model parameters under different loss functions. They were originally used in estimation problems when the unbiased estimator of
was being considered. Another reason for its popularity is due to its relationship to the least squares theory. The
SEL function makes the computations simpler. Under the
SEL,
WSEL,
,
PL,
LL,
EL and
KL functions in
Table 1, the Bayesian estimation for the random vector
for
, and under various loss functions, it can be obtained as follows.
It is evident that each of the integrals in the above section have no closed form for the resulting joint posterior distribution as given in Equation (9). Therefore, they need to be solved analytically. Consequently, the MCMC technique is proposed to generate samples from the posterior distributions and then the Bayes estimates of the parameter vector are computed under progressively type II censored samples. Next, we provide the general form of the Bayesian credible intervals.
5.3. Credible Intervals
In this subsection, asymmetric
two-sided Bayes probability interval estimates of the parameter vector
, denoted by
, are obtained by solving the following expression:
Since it is difficult to find the interval and analytically, we apply suitable numerical techniques to solve Equation (11).
8. Application on Bladder Cancer Data
In this section, we provide a real data analysis to illustrate some practical applications of the proposed distributions. The data are from [
13], which correspond to the remission times (in months) of a random sample of n = 128 bladder cancer patients. These data are given as follows:
0.08, 2.09, 3.48, 4.87, 6.94, 8.66, 13.11, 23.63, 0.20, 2.23, 3.52, 4.98, 6.97, 9.02, 13.29, 0.40, 2.26, 3.57, 5.06, 7.09, 9.22, 13.80, 25.74, 0.50, 2.46, 3.64, 5.09, 7.26, 9.47, 14.24, 25.82, 0.51, 2.54, 3.70, 5.17, 7.28, 9.74, 14.76, 26.31, 0.81, 2.62, 3.82, 5.32, 7.32, 10.06, 14.77, 32.15, 2.64, 3.88, 5.32, 7.39, 10.34, 14.83, 34.26, 0.90, 2.69, 4.18, 5.34, 7.59, 10.66, 15.96, 36.66, 1.05, 2.69, 4.23, 5.41, 7.62, 10.75, 16.62, 43.01, 1.19, 2.75, 4.26, 5.41, 7.63, 17.12, 46.12, 1.26, 2.83, 4.33, 5.49, 7.66, 11.25, 17.14, 79.05, 1.35, 2.87, 5.62, 7.87, 11.64, 17.36, 1.40, 3.02, 4.34, 5.71, 7.93, 11.79, 18.10, 1.46, 4.40, 5.85, 8.26, 11.98, 19.13, 1.76, 3.25, 4.50, 6.25, 8.37, 12.02, 2.02, 3.31, 4.51, 6.54, 8.53, 12.03, 20.28, 2.02, 3.36, 6.76, 12.07, 21.73, 2.07, 3.36, 6.93, 8.65, 12.63, 22.69.
Before proceeding further, we fitted the mixture EKW distribution to the complete data set.
Table 8 reports the ML and Bayesian estimates for the parameters for the complete bladder cancer data.
Figure 3 represents the overall fit of EKW for these data.
The validity of the fitted model is assessed by computing the Kolmogorov–Smirnov distance (KSD) statistics with
p-Value KS (PVKS) in
Table 8. In addition, we plotted the fitted cdf and the empirical cdf, as shown in
Figure 3. This was conducted by replacing the parameters with their ML (in red) estimates, as shown in
Figure 3. The KSD statistics for ML are 0.0443 and the corresponding
p-value is 0.9629. Therefore, the KS test, along with
Figure 3, indicate that the EKW distribution provides the best fit for this data set.
Next, we fitted the MEKW distribution to the complete data set.
Table 9 reports the ML and Bayesian estimates for the parameters for the complete bladder cancer data.
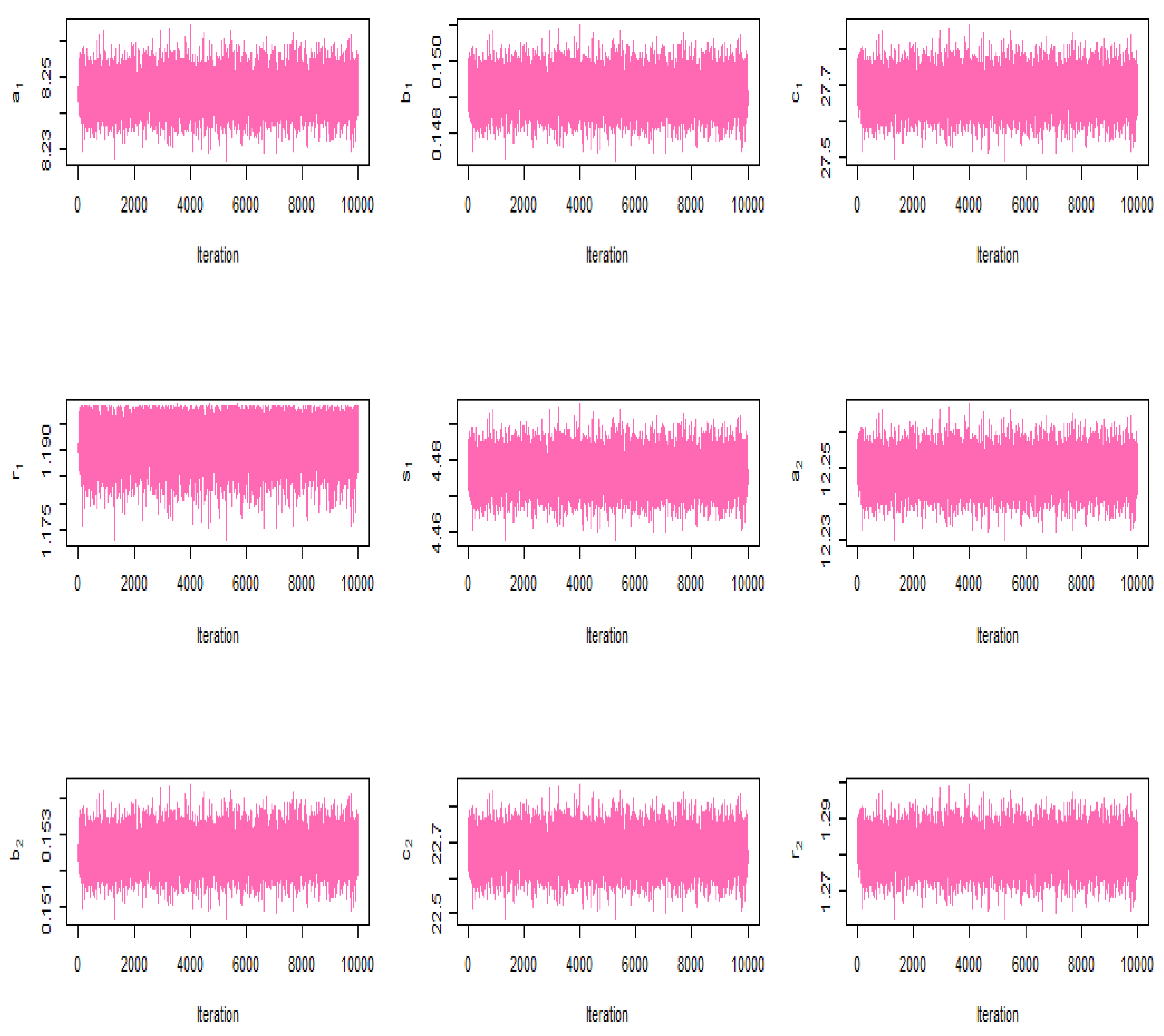
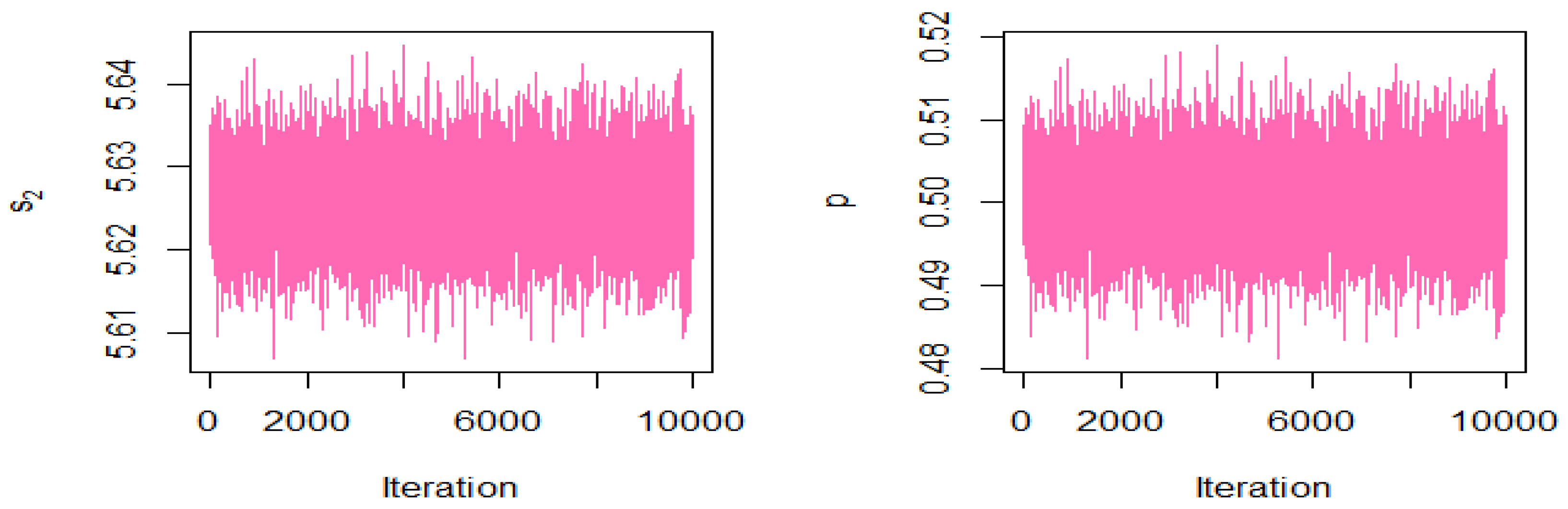
In
Figure 4 and
Figure 5, we provide the trace plots of the MCMC results, showing the MCMC procedure converges.
Figure 6 and
Figure 7 show the MCMC density and HDI intervals for the results of the Bayesian estimation of the MEKW model for the complete sample. Therefore, we will use the estimate for the mixing parameter
in computing the ML and Bayesian estimates for other parameters when using complete samples.
Two different sampling schemes are used to generate the progressively censored samples from the bladder cancer data with m = 100, which are as follows:
Strategy 1: (99*0,28); (type II censoring scheme).
Strategy 2: (28,99*0); .
In both cases, we have considered the optimization algorithm to compute the ML estimates.
Table 10 shows the ML estimates for these two schemes.
For Case 1, where m = 100 and under the Scheme 1, the following can be noted: 0.08 0.20 0.40 0.50 0.51 0.81 0.90 1.05 1.19 1.26 1.35 1.40 1.46 1.76 2.02 2.02 2.07 2.09 2.23 2.26 2.46 2.54 2.62 2.64 2.69 2.69 2.75 2.83 2.87 3.02 3.25 3.31 3.36 3.36 3.48 3.52 3.57 3.64 3.70 3.82 3.88 4.18 4.23 4.26 4.33 4.34 4.40 4.50 4.51 4.87 4.98 5.06 5.09 5.17 5.32 5.32 5.34 5.41 5.41 5.49 5.62 5.71 5.85 6.25 6.54 6.76 6.93 6.94 6.97 7.09 7.26 7.28 7.32 7.39 7.59 7.62 7.63 7.66 7.87 7.93 8.26 8.37 8.53 8.65 8.66 9.02 9.22 9.47 9.74 10.06 10.34 10.66 10.75 11.25 11.64 11.79 11.98 12.02 12.03 12.07.
For Case 2, where m = 100 and under the Scheme 2, the following can be noted: 0.08 0.20 0.40 0.50 0.90 1.05 1.19 1.35 1.40 1.46 1.76 2.02 2.09 2.23 2.26 2.46 2.64 2.69 2.69 2.75 2.83 3.02 3.25 3.31 3.36 3.36 3.48 3.52 3.57 3.64 3.82 4.18 4.23 4.26 4.33 4.34 4.40 4.50 4.51 4.87 4.98 5.06 5.09 5.17 5.32 5.32 5.41 5.41 5.49 5.62 5.71 6.25 6.54 6.76 6.93 6.94 6.97 7.09 7.28 7.32 7.39 7.59 7.62 7.63 7.66 8.37 8.53 8.65 9.02 9.47 9.74 10.06 10.66 10.75 11.25 11.64 11.79 11.98 12.02 12.07 12.63 13.29 14.24 14.77 16.62 17.12 17.36 18.10 19.13 20.28 22.69 23.63 25.74 25.82 26.31 34.26 36.66 43.01 46.12 79.05.
In addition, Bayesian credible interval estimates of the parameters are obtained numerically using Markov chain Monte Carlo (MCMC) techniques. That is, samples are simulated from the joint posterior distribution in Equation (12) using the Metropolis–Hasting algorithm to obtain the posterior mean values of the estimates of the parameters by MCMC.
Table 10 reports the estimates of the MEKW parameters with the corresponding SE and credible confidence intervals using the HDI algorithm of the Bayesian estimators.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}