1. Introduction
Urban areas around the world continue to experience a series of sudden sinkhole collapses that cause severe traffic disruptions and significant economic losses. Underground cavities are the main reason for the formation of sinkholes. Complex conditions such as changes in drainage patterns, excessive pavement loads, and disturbances in infrastructure construction often lead to various cavities [
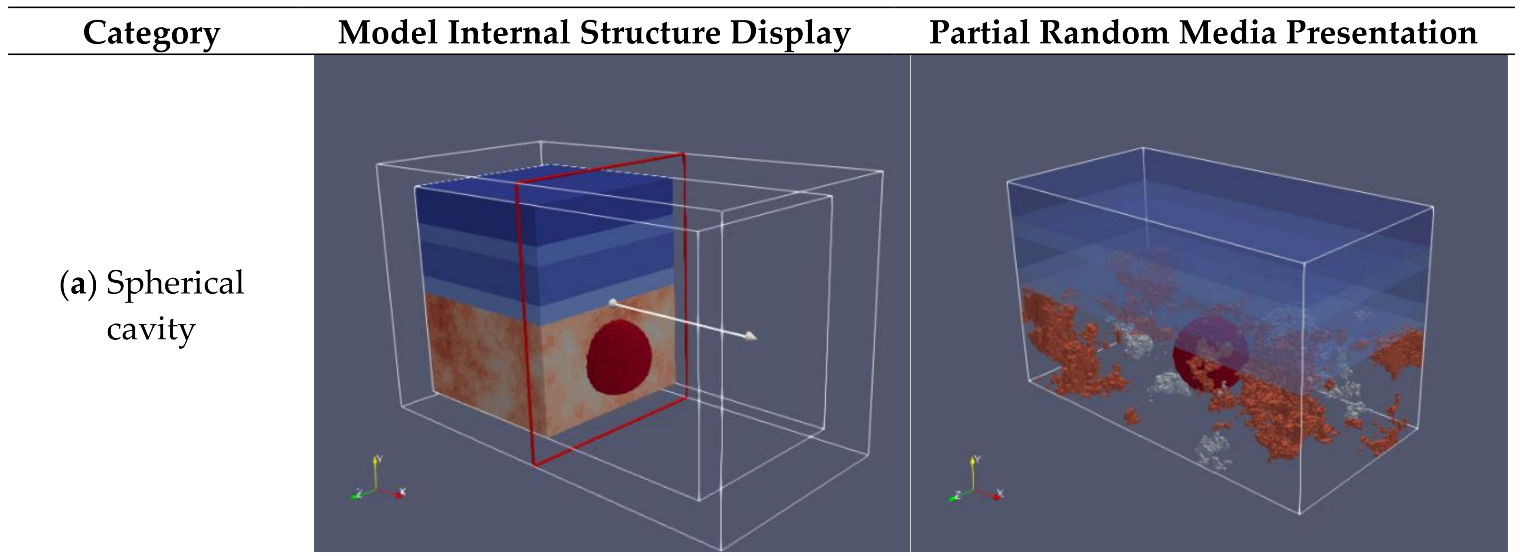
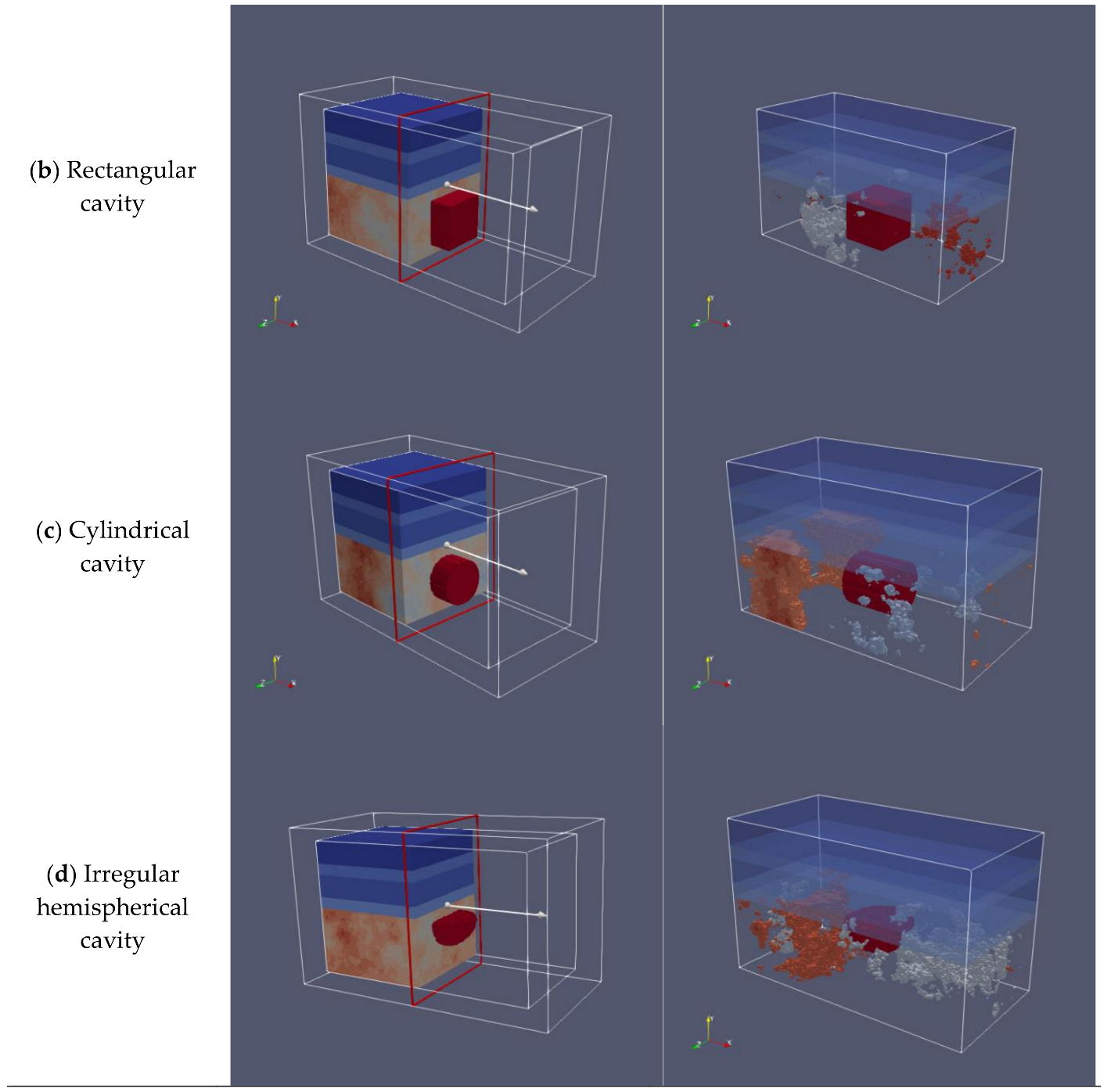
1]. Therefore, the cavities may vary in morphology, for example, cavities with different shapes or combinations of several basic shapes, or they may be filled with different media or have different positions and sizes. Due to the unpredictability and morphological complexity of cavities, there is a growing need for their early recognition.
Ground-penetrating radar (GPR) has gradually been applied to the detection and perception of underground cavities [
2], owing to its nondestructive inspection, strong penetrating ability, and high-precision characteristics. GPR transmitters emit electromagnetic (EM) waves into the surface at multiple spatial positions, and then the reflected signal can be measured by the GPR receiver to establish a two-dimensional (2D) GPR image. Three-dimensional (3D) GPR images can be obtained immediately when multichannel GPR transmitters and receivers exist parallel to the scanning direction at the same time [
3,
4]. The morphological scale of a cavity can reflect the evolution speed of the cavity and the severity of future road collapse, and it can also accurately reflect the 3D space state of the cavity. Therefore, the accurate detection of morphology has scientific value for studying the mechanism of cavity formation and summarizing the corresponding prevention and repair methods. However, as the quantity of the 3D GPR data increases, the manual analysis of the GPR data becomes time-consuming and difficult to meet the requirements of the efficient and fine detection of cavity morphology.
Three challenges in automating this task cannot be ignored. The first challenge is the selection and extraction of morphological features. Environmental complexities, such as the interference of surrounding pipelines and groundwater leakage, may impose difficulties in describing cavity morphological features. It is impossible to comprehensively describe the reflection properties with one or a few features. Additionally, the acquired morphological attributes still need to be inferred and identified by experienced professionals, making it difficult to obtain a general description feature. The second challenge is the fine classification of cavity morphology in the GPR data. Due to the variety of types, varying sizes, distinct directions and extensions, and irregular shapes, cavity morphology analysis faces difficulties in identification and fine classification. The third challenge is to address the issue of insufficiently labeled GPR data. Compared with objects such as buried rebars and pipes, the scale and diameter distribution of a cavity with collapse threat is relatively large. It is very laborious to make such a large target in the lab, and the targets are generally in regular forms, not universal and representative. To obtain reliable results, the lack of sample data must be considered and addressed.
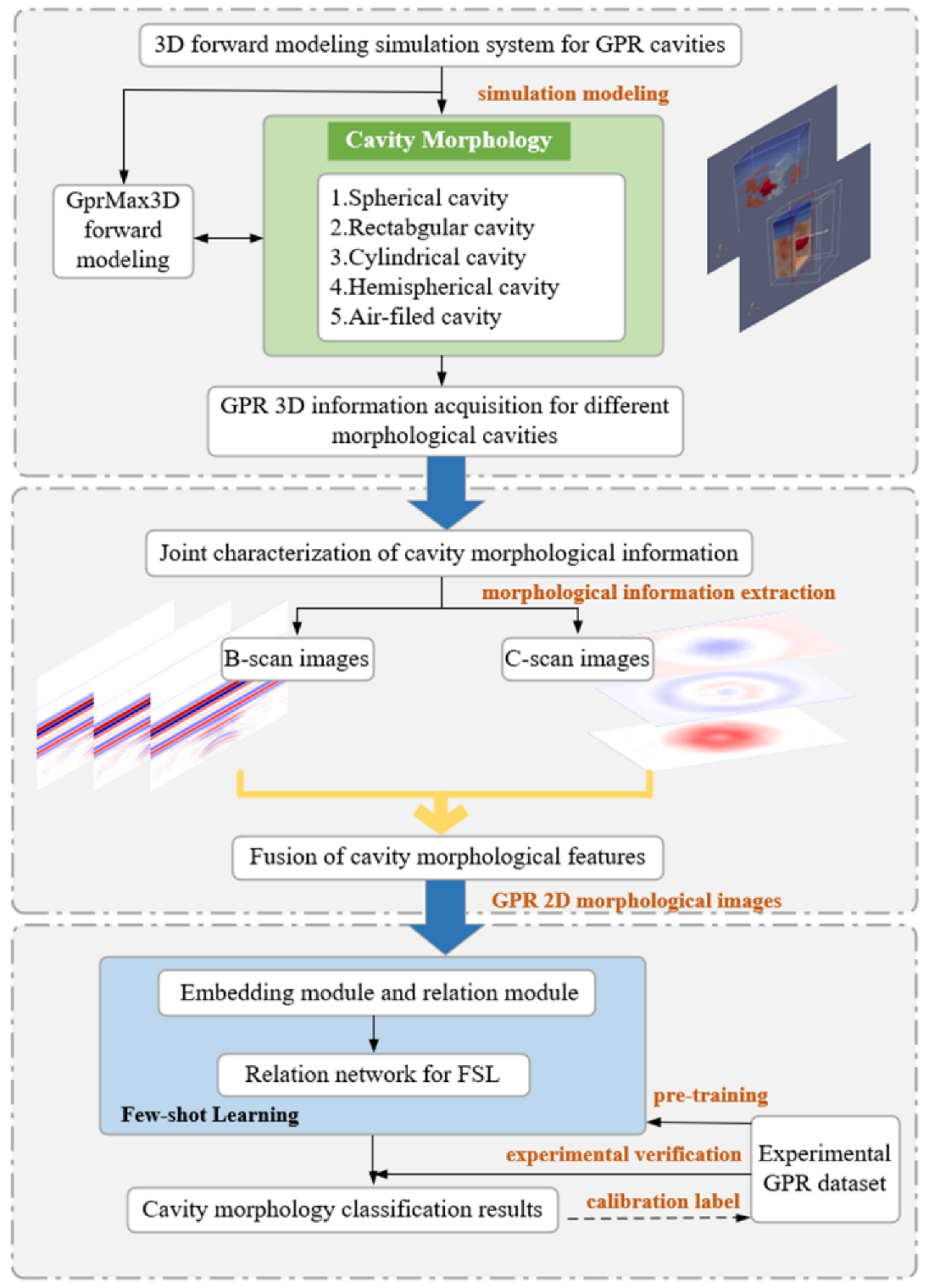
Therefore, in this study, a novel deep learning (DL)-aided framework was proposed to extract the morphological features of cavities and classify them in facing a small number of 3D GPR data.
Figure 1 shows the details of the proposed framework. The contribution of this work is twofold:
- (i)
First, a joint characterization algorithm was developed for cavity morphology that generates 2D morphological images and fully exploits 3D GPR spatial information;
- (ii)
Second, we implemented a novel few-shot learning (FSL) network for cavity morphology classification and embedded a relation network (RelationNet) into the FSL model to adapt to different few-sample cavity scenarios.
The rest of this paper is organized as follows:
Section 2 introduces the literature review of the GPR cavity detection. In
Section 3, the imaging scheme of the 3D GPR data is proposed.
Section 4 introduces the details of the FSL network and RelationNet structure for morphological classification. In
Section 5, the experimental results are compared and analyzed, and finally, in
Section 6, conclusions are drawn.
2. Literature Review
Previous studies have focused on the automated GPR cavity detection process. Qin et al. [
5] proposed a pattern recognition method based on the support vector machine (SVM) classifier to identify cavities in GPR images. Park et al. [
6] combined instantaneous phase analysis with the GPR technique to identify hidden cavities. Hong et al. [
7] developed a new time-domain-reflectometry-based penetrometer system to accurately estimate the relative permittivity at different depths and estimate the state of a cavity. Yang et al. [
8] constructed a horizontal filter to identify cavity disease and eliminate the interference of rebar echo. Based on the data collected by multisensors such as unmanned aerial vehicles (UAVs) and GPR, the authors of [
9,
10] detected and analyzed cavity diseases in disaster-stricken areas to rescue potential victims trapped in cavities. In 2022, Rasol et al. [
11] reviewed state-of-the-art processing techniques such as machine learning and intelligent data analysis methods, as well as their applications and challenges in GPR road pavement diagnosis. To better localize pavement cracks and solve the interference of various factors in the on-site scene, Liu et al. [
12] integrated a ResNet50vd-deformable convolution backbone into YOLOv3, along with a hyperparameter optimization method. To detect subsurface road voids, Yamaguchi et al. [
13] constructed a 3D CNN to extract hyperbolic reflection characteristics from GPR images.
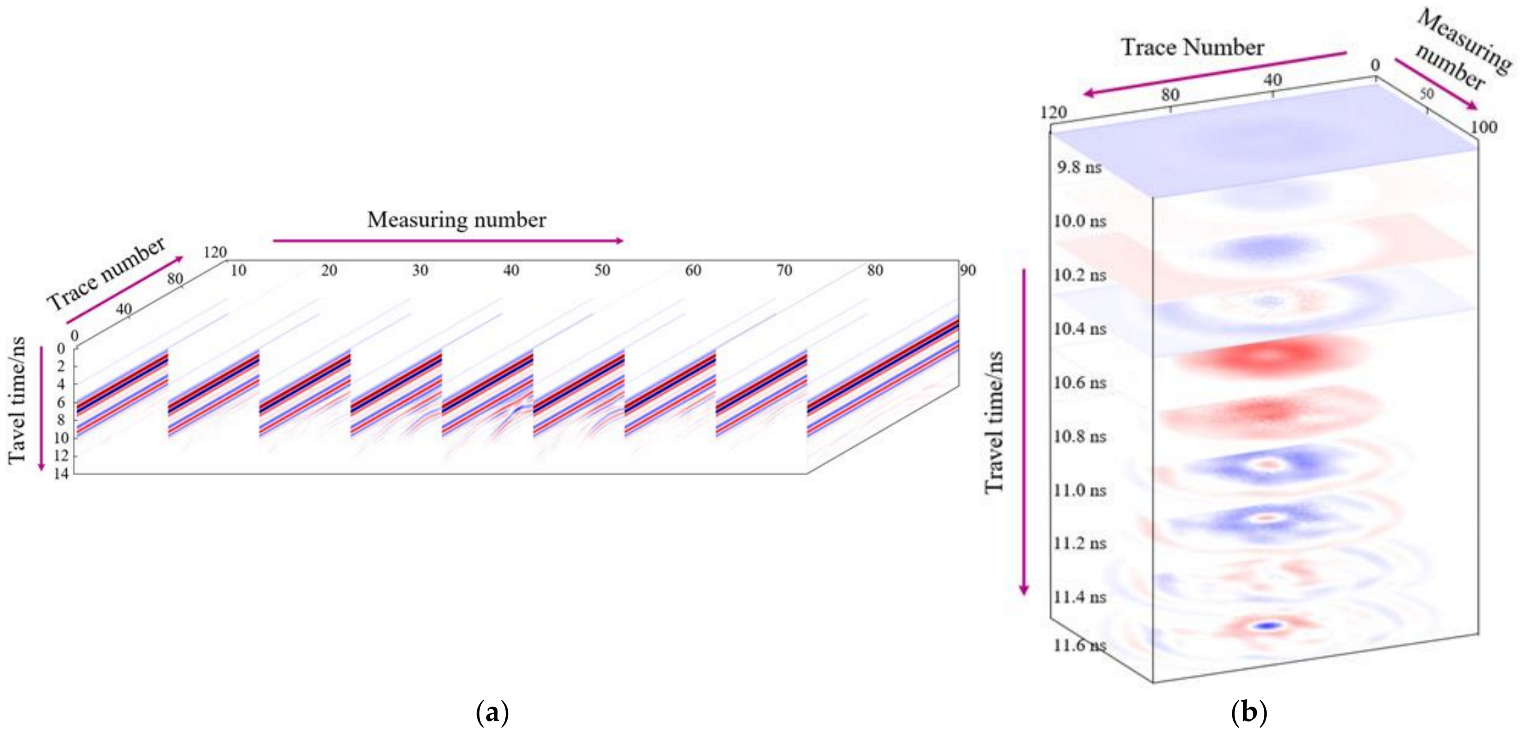
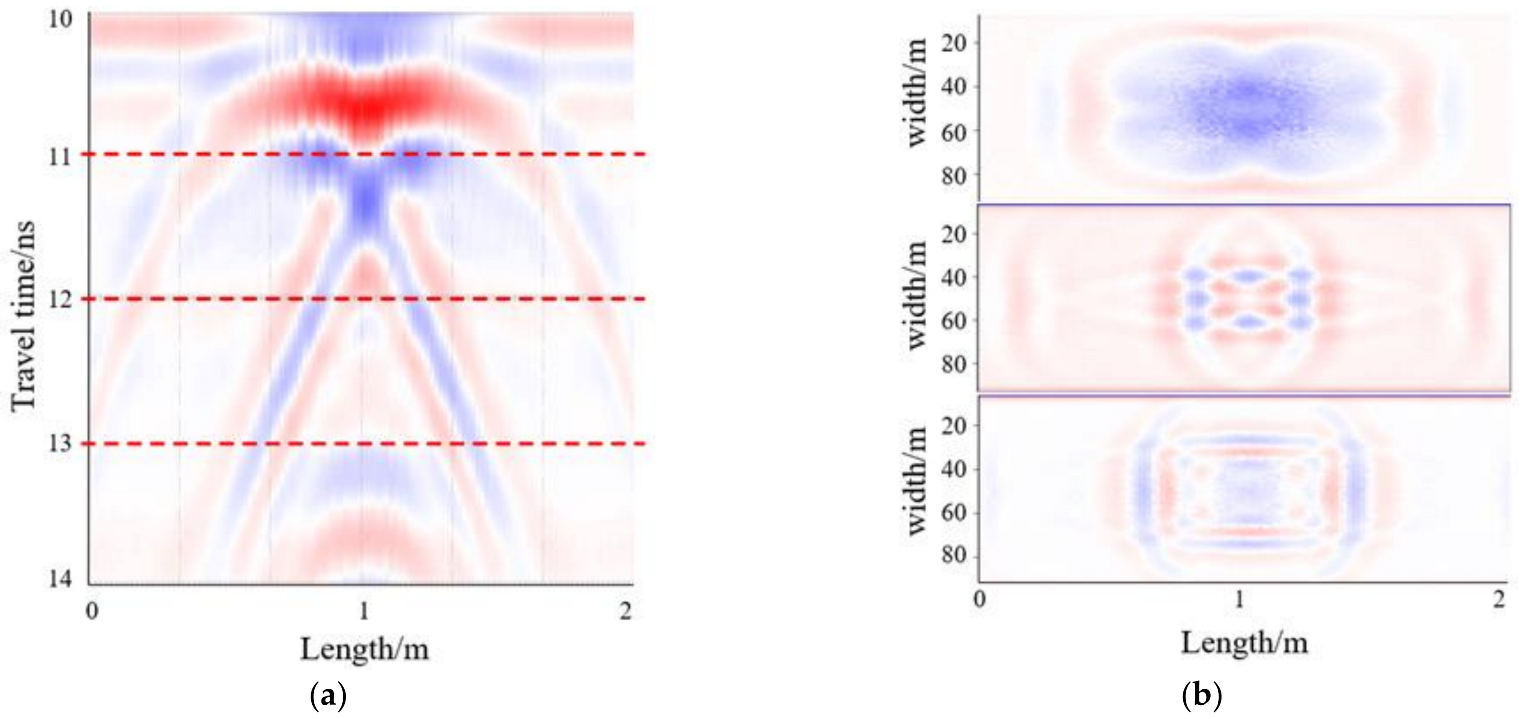
Previous results were based on the processing of only B-scans; however, once faced with specific subsurface objects, it was difficult to classify them using B-scans alone. In particular, the characteristics of various cavities in GPR B-scan images tended to be similar. Therefore, to improve the classification performance, both the GPR B-scan and C-scan images were considered in the classification process using the DL network [
14,
15,
16,
17]. Compared with the 2D GPR data, 3D data can provide rich spatial information and greatly improve the process in terms of data volume, imaging methods, and disease detection accuracy. Luo et al. [
18] established a cavity pattern database including C-scans and B-scans, where the C-scan provides location information of objects, and B-scan information assists in verifying object types. Kim et al. [
19] proposed a triplanar convolutional neural network (CNN) for processing the 3D GPR data, enabling automated underground object classification. Kang et al. [
20] designed the UcNet framework to reduce the misclassification of cavities, and the next year, Kang et al. [
21] developed a transfer-enhanced CNN to improve the classification accuracy. Khudoyarov et al. [
22] proposed a 3D CNN architecture to process the 3D GPR data. The authors of another study [
23] visualized and distinguished underground hidden cavities from other objects (such as buried pipes, and manholes). In 2021, Kim et al. [
24] used the AlexNet network with the transfer learning technology to achieve underground object classification, further improving detection accuracy and speed. Abhinaya et al. [
25] detected cavities around sewers using in-pipe GPR equipment and confirmed that YOLOv3 [
26] was suitable for cavity recognition tasks. Liu et al. [
27] combined the YOLO model and the information embedded in 3D GPR images to address the recognition issue of road defects. The above research demonstrated that, compared with using only B-scan images, the developed CNNs using both the B-scans and C-scans improved the classification performance. However, it was found that the cavity morphology is still indistinguishable due to the difficulty of cavity data acquisition and the lack of a GPR database.
Faced with such a problem, FSL [
28,
29], as a novel DL technique, was developed to generalize the network with very few or fewer training samples for each class. This changes the situation where traditional DL models must require large quantities of labeled data. FSL can be divided into three categories: model-based, optimization-based, and metric-based learning methods [
30]. The model-based learning method first designs the model structure and then uses the designed model to quickly update parameters on a small number of samples, and finally directly establishes the mapping function of the input and prediction values. Santoro et al. [
31] proposed the use of memory augmentation to solve this task and a memory-based neural network approach to adjust bias through weight updates. Munkhdalai et al. [
32] proposed a meta-learning network, and its fast generalization ability is derived from the “fast weight” mechanism, where the gradients generated during training are used for fast weight generation. The optimization-based learning method completes the task of small sample classification by adjusting the optimization method instead of the conventional gradient descent method. Based on the fact that gradient-based optimization algorithm does not work well with a small quantity of data, Ravi et al. [
33] studied an updated function or rule for model parameters. The method proposed by Finn et al. [
34] can deal with situations with a small number of samples and can obtain better model generalization performance with only a small number of training times. The main advantages of this method are that it does not depend on the model form, nor does it need to add new parameters to the meta-learning network. The metric-based learning method is developed to measure the distance/similarity between the training set and the support set and completes the classification with the help of the nearest neighbor method. Vinyals et al. [
35] proposed a new matching network, which aims to build different encoders for the support set and the batch set, respectively. Sung et al. [
36] proposed a RelationNet network to model the measurement method, which learns the distance measurement method by training a CNN network.
4. Few-Shot Learning Designed for Morphology Classification
4.1. FSL Definition
FSL is able to quickly identify new classes on very few samples. It is generally divided into three kinds of datasets: training set, support set, and testing set. The training set can be further divided into a sample set and a query set. If the support set contains
labeled examples for each of
unique classes, the target few-shot problem is called
-way -shot.
Figure 7 shows the FSL architecture for a
four-way one-shot problem.
The parameters are optimized by the training set, hyperparameters are tuned using the support set, and finally, the performance of function is evaluated on the test set. Each sample is assigned a class label . The data structure in the training phase is constructed to be similar to that in the testing phase; that is, the sample set and query set during the training simulate the support set and testing set at the testing time. The sample set is built by randomly picking classes from the training set with labeled samples, and the rest of these samples are used in the query set .
4.2. Relation Network Architecture and Relation Score Computation
The relation network (RelationNet) is a typical metric-learning-based FSL method. In essence, metric-learning-based methods [
36,
37,
38,
39,
40,
41] compare the similarities between query images and support classes through a feed-forward pass through an episodic training mechanism [
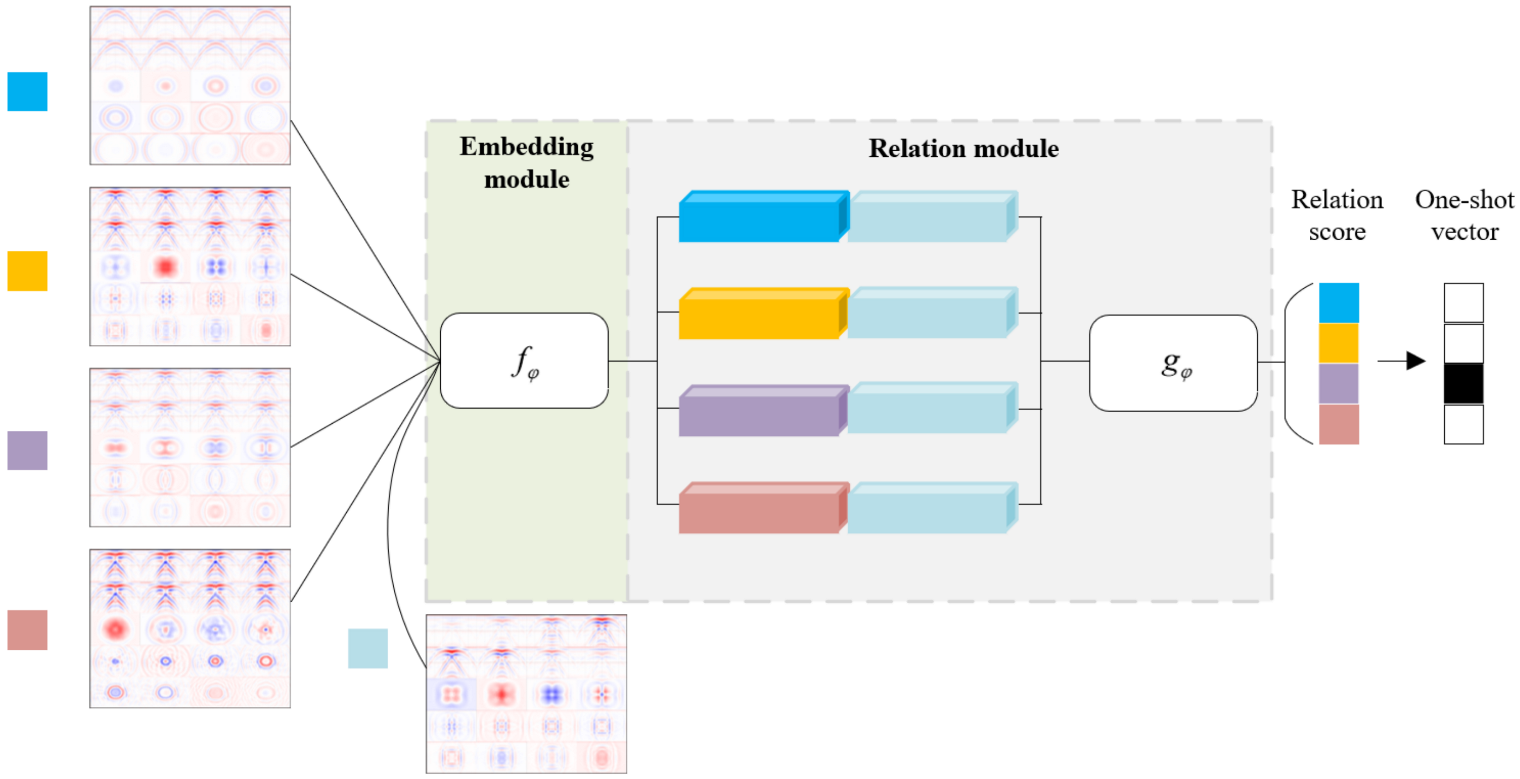
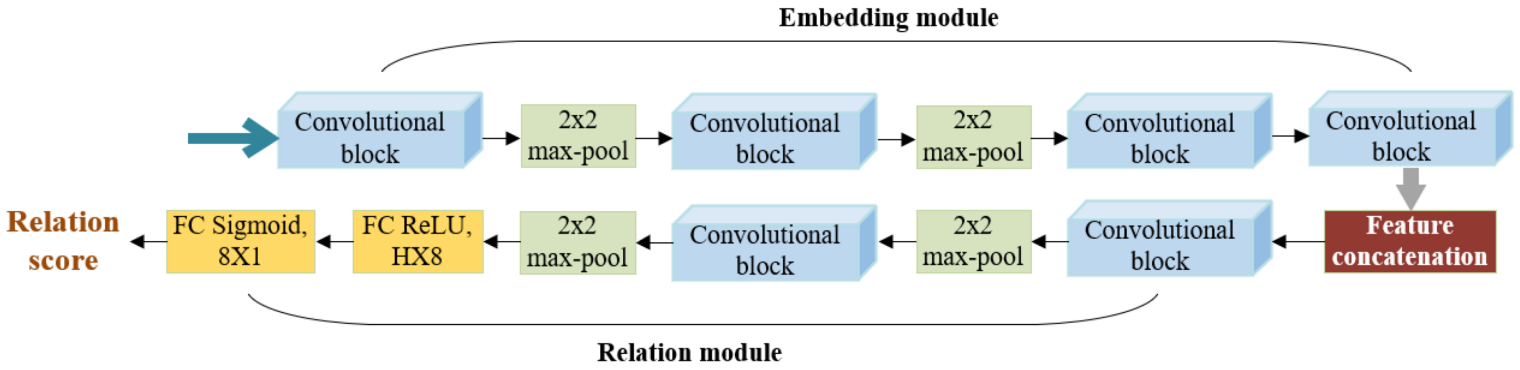
35]. The core of RelationNet is to learn a nonlinear metric through deep CNN, rather than selecting a fixed metric function. RelationNet is a two-branch architecture that includes an embedding module and a relation module. The embedding module is used to extract image features. The relation module obtains the correlation score between query images and sample images; that is, it measures their similarity, so as to realize the recognition task of a small number of samples.
Figure 8 represents the RelationNet architecture settings for FSL. The embedding module utilizes four convolutional blocks, and each convolutional block consists of a 64-filter
convolution, a batch normalization, and a ReLU nonlinearity layer. In addition to the above, the first two convolutional blocks also include a
max-pooling layer, and the latter two convolutional blocks do not contain the pooling layer. The output feature maps are then obtained for the following convolutional layers in the relation module. The relation module consists of two convolutional blocks and two fully connected layers. Each convolutional block is a
convolution containing 64 filters, followed by batch normalization, ReLU nonlinearity, and
max-pooling. For the network architectures, in order to generate relation scores within a reasonable range, in all fully connected layers, ReLU functions are employed, except for the output layer, in which Sigmoid is used.
The prior few-shot works use fixed pre-specified distance metrics, such as the Euclidean or cosine distances, to perform classification [
35,
42]. Compared with the previously used fixed metrics, RelationNet can be viewed as a metric capable of learning deep embeddings and deep nonlinearities. By learning the similarity using a flexible function approximator, RelationNet can better identify matching/mismatching pairs. Sample
in the query set
and sample
in the sample set
are fed through the embedding module
to produce feature maps
and
, respectively. Then, these two feature maps
and
are combined using the operator
. After that, the combined feature map is fed into the relation module
, which finally produces a scalar in the range of 0–1 to represent the similarity between
and
, also called the relation score. Thus, the relation score
is generated as shown in Equation (2):
Here, the mean square error loss is computed to train the model, as shown in Equation (3), regressing the relation score
to the ground truth: the similarity of matched pairs is 1, and the similarity of unmatched pairs is 0.
4.3. RelationNet-Based Cavity Morphology Classification Scheme
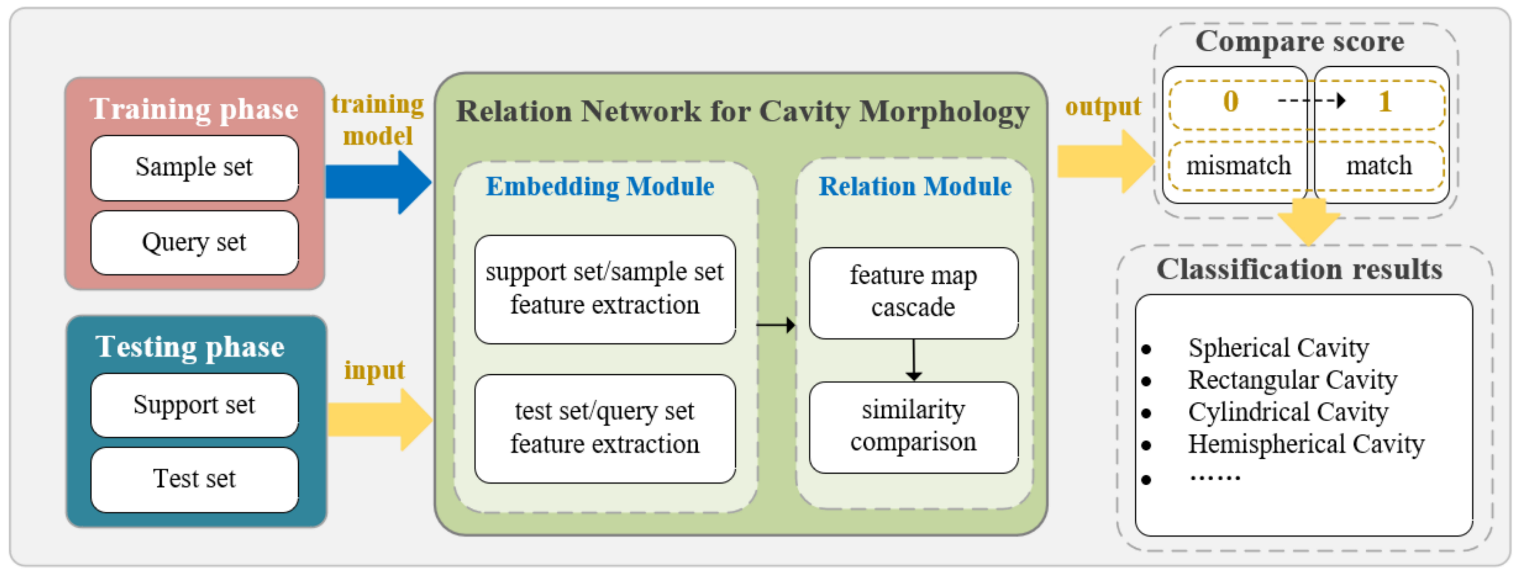
Based on the data and structural characteristics of the GPR cavity morphological recognition system, we divide the complex processing process into two main parts: a training phase and a testing phase, as shown in
Figure 9. The cavity morphologies are discussed here, e.g., cylindrical, rectangular, spherical, and irregular hemispherical. First, a training set is inputted to learn classification rules inside the network in the training phase. Then, in the testing phase, a small number of support samples (labeled) and test samples (unlabeled) are inputted into the trained network model, and the unlabeled test samples are predicted and classified, thereby outputting the final morphological classification results.
Based on the above principle, the RelationNet-based GPR cavity morphology classification system first obtains the trained model on the training set and then recognizes the new category of cavity images. The embedding model is used to extract the feature information of each inputted GPR image and then concatenates the image features between the test sample and support sample. Then, the integrated features are inputted into the relation model for comparison. According to the comparison results, it is judged to which category the test sample belongs, so as to achieve the classification of cavity morphologies.
6. Conclusions
In this paper, we first applied the FSL technique to classify and identify cavity morphology characteristics based on the 3D GPR data. RelationNet was adopted as the FSL framework and trained end-to-end from scratch. Based on the advantages of learning a deep distance metric, RelationNet addressed the issue of insufficient cavity data and obtained the classification results using only a few samples. The experiment results demonstrated the effectiveness of using RelationNet in morphology classification performance. The RelationNet model achieved an average classification accuracy value of 97.328% in the four-way five-shot and 78.097% in the four-way one-shot problem.
There is a limitation that could be addressed in future research. In the experiments, all the models were trained on the source domain (e.g., miniImageNet and tieredImageNet) and directly tested on the target domain (e.g., cavity radar dataset). However, the performance hardly improved or significantly dropped when there was a large domain shift. In this paper, based on the fact that there was no intersection between the source set and our cavity radar dataset, there was a large domain offset between the source and target domains. Future efforts need to be made to integrate prior knowledge into FSL or explore one-shot or zero-shot classification methods.
For on-site applications, there are two limitations that could be addressed in future research. First, the real cavity data are difficult to collect for training the proposed method. Additionally, the publicly available GPR cavity datasets are limited. Efforts need to be made in the future to collect and prepare GPR datasets to facilitate the implementation of this method. Second, the proposed method was only tested for cavity morphology classification using the GprMax3D data. The scalability of the method in other challenging environments and applications needs further investigation. Future studies could test this method for collecting cavity data and classifying their morphologies in on-site city roads.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}