
The Development of PSO-ANN and BOA-ANN Models for Predicting Matric Suction in Expansive Clay Soil



Abstract
:1. Introduction
2. Background
2.1. ANN
2.2. Levenberg-Marquardt Training Algorithm
2.3. BR-BP Training Algorithm
2.4. Hybrid Intelligent Models
3. Methodology
3.1. Data Analysis
3.1.1. Field Instrumentation Program
3.1.2. Data Extraction
3.1.3. Data Validation and Normalization
3.2. Predictive Modeling
3.2.1. Transfer Function
3.2.2. ANN-BR Algorithm
3.2.3. PSO-ANN Algorithm
- Use the dataset to train BR-BPNN;
- Determine the number of weights and biases in the ANN;
- Optimize the training phase by using the PSO technique;
- 4.
- Regulatory parameters such as c1 and c2, the algorithm’s maximum iteration, and the starting population of the PSO are produced, i.e., , ;
- 5.
- Each particle’s position and velocity are calculated using the position and velocity step. During initialization, the velocity of each solution is assumed to be equal to its starting position;
- 6.
- For , the starting velocities and initial locations of the particles are chosen at random;
- 7.
- The iteration number is set to t = 1;
- 8.
- The particle fitness function is determined by reducing the prediction error caused by the neural network;
- 9.
- The new velocity and position are determined by changing the parameters c1 and c2 in accordance with Equations (3) and (4), and local and global optimum comparisons are performed;
- 10.
- The particles are organized, and the optimal solution x* is discovered;
- 11.
- If the number of repeated measurements t reaches a maximum, the process is terminated; otherwise, t = t + 1 is carried on to Step 8;
- 12.
- When the optimum solution is extracted using the PSO method, the ideal solution has the same weights and optimal biases as PSO;
- 13.
- Optimal weights and biases are applied to the neural network constructed in step 1, and the outcome is predicted;
3.2.4. BOA-ANN Algorithm
- Create a neural network with BR-BPNN training on the dataset;
- Extract the number of weights and network biases;
- Optimize weights and biases using the BOA method;
- 4.
- Hyper parameters and search space are determined;
- 5.
- The initial population of butterflies (solutions), i.e., is created;
- 6.
- The fragrance for each butterfly is calculated using Equation (5);
- 7.
- The position of each butterfly in the search space is determined;
- 8.
- Set the iteration to t = 1;
- 9.
- The performance of each butterfly is calculated using the error caused by the application of the ANN to the butterfly’s position;
- 10.
- The butterfly with the best fitness would be selected;
- 11.
- A random number is generated for each butterfly and then compared to the probability P;
- 12.
- If the random number r generated is less than the probability value P, then the butterfly position is updated via global search, Equation (6);
- 13.
- If the produced random number is greater than the probability value P, the butterfly’s location is updated using local search, Equation (7);
- 14.
- The position of the butterflies is arranged according to their merit, and the best solution is found for ;
- 15.
- If the iteration number t reaches its maximum value, it stops the algorithm; otherwise, it sets t = t + 1 and goes to step 10;
- 16.
- The best solution from the BOA algorithm is the best solution for the same optimal weights and biases;
- 17.
- Apply optimal weights and biases to the neural network created in step 1 and predicting the output of the problem;
4. Results
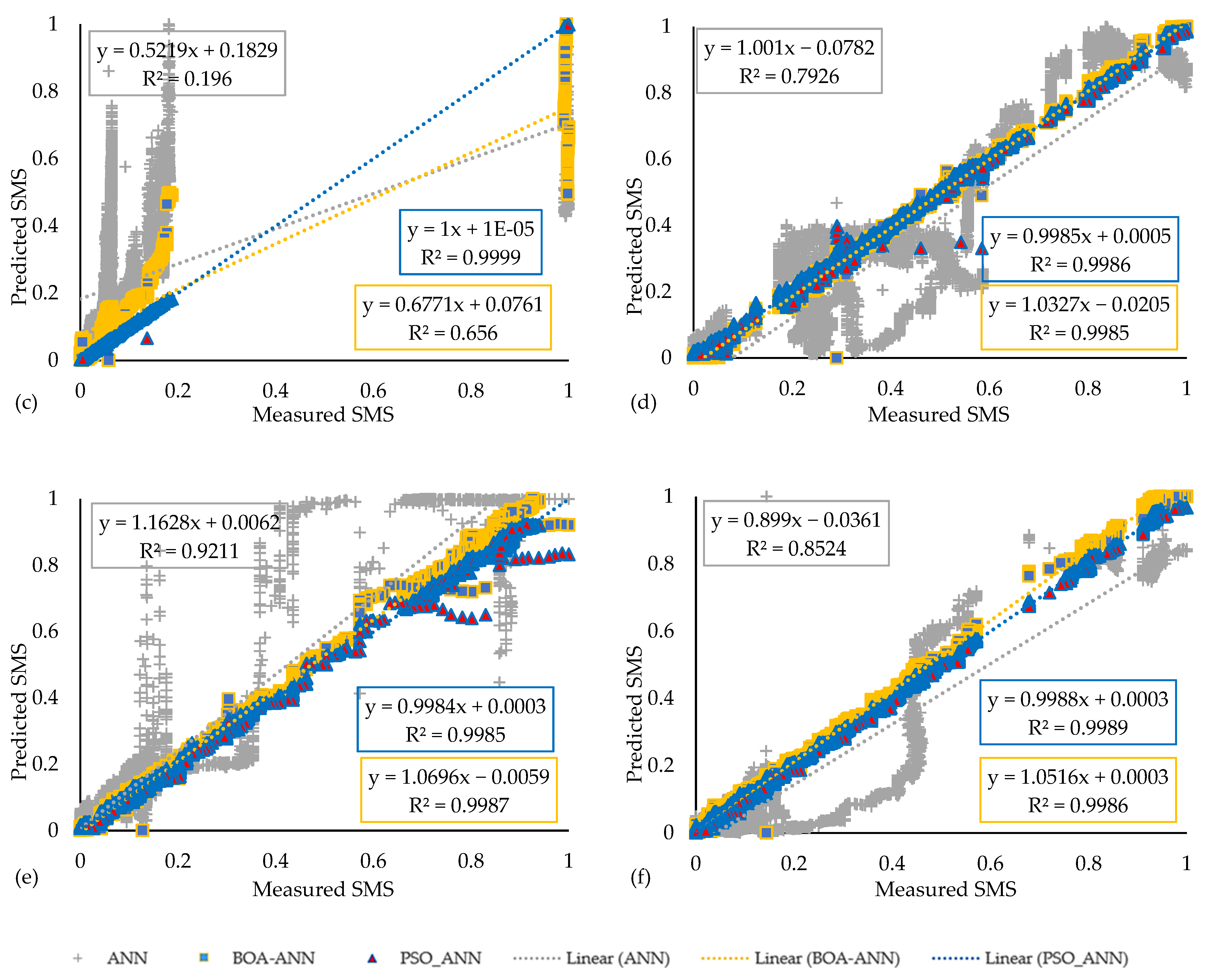
4.1. ANN-BR and Hybrid Models
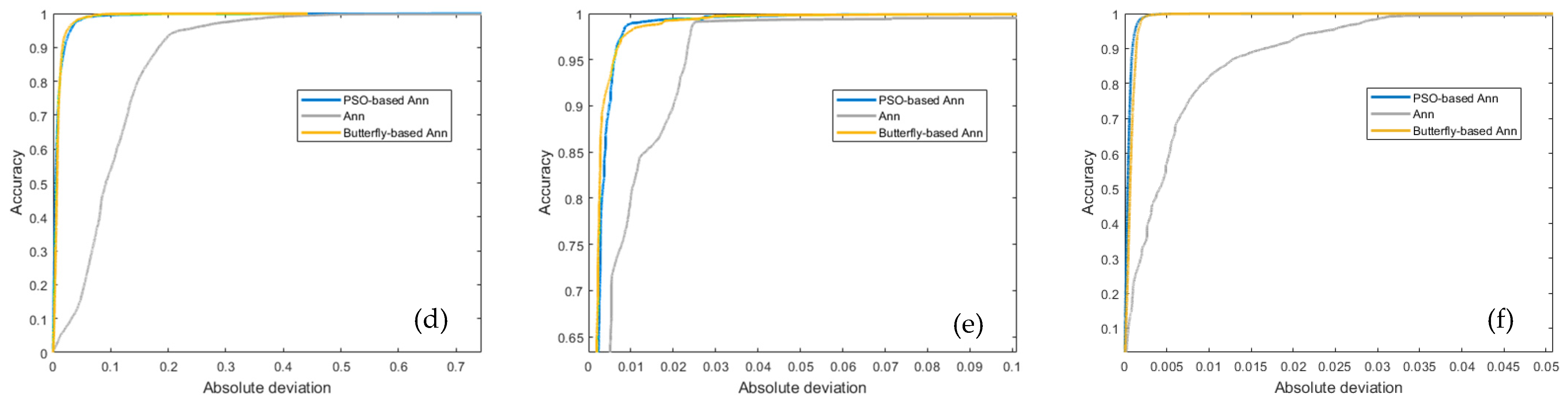
4.2. Regression Error Characteristic Curves
4.3. Sensitivity Analysis
- The performance of ANN-BR in all initially calculated models was better than ANN-LM. A similar result was achieved when comparing the ANN-BR and ANN-LM in hybrid algorithms;
- The PSO-ANN was capable of accurately predicting the SMS. The PSO algorithm had the best total performance in fine-tuning ANN-BR for predicting the SMS regarding R2, MSE, δ, and REC curve values. Specifically, the PSO-ANN had superiority in 11 out of 18 HWS in terms of R2 value; most of them were in the deeper level of the soil slopes (3 m and 4.5 m). Regarding the R2 value, the BOA-ANN dominates the four most accurate SMS predictions in the upper spots of studied soil slopes (1.5 m depth). R2 values of both hybrid algorithms were too close to each other in all 18 considered spots, and both are recommended for predicting SMS;
- In terms of MSE, PSO-ANN had the better performance in HWS 1, and HWS 6 and BOA-ANN had the better performance in the remaining HWS in 1.5 depth. For the 3 m depth, the PSO-ANN had prevalence in HWS 3, 5, and HWS6, the BOA-ANN dominated the prediction of HWS 2 and HWS 4’s SMS values, and the ANN-BR had a better performance in HWS 1. For 4.5 m depth, the PSO-ANN had a better convergence in HWS 2, 3, 5, and 6, and the ANN-BR performed better in HWS 1 and BOA-ANN in HWS 4;
- From the REC values point of view, the PSO-ANN had the best performance in all 18 HWS’ SMS predictions. Both hybrid methods could escalate the effectiveness of the normal ANN-BR, and their performance had a significant privilege over the ANN-BR approach;
- Considering the combination index, δ, by which all R2, RMSE, and VAF values were considered in tandem for each algorithm, the performance of the PSO-ANN was better in HWS 1; for the BOA-ANN in HWS 2, 3, 4, 5, and 6 at 1.5 m depth. At 3 m depth, the PSO-ANN model had the best performance in all HWS, and the BOA-ANN had a similar performance in HWS 2 and 4. Similarly, for 4 m depth, the PSO-ANN had the best performance in HWS 1, 2, 3, and 5, and the BOA-ANN had a better performance in HWS 4, 5, and 6. Both hybrid algorithms had similar performance for HWS 5;
- Regarding input variables, inserting the soil and air temperature data sets had a crucial impact on the accuracy of SMS prediction. After adding these two variables’ data sets, the accuracy of the predicted ANN-BR model improved by 30%;
- All input variables, such as soil temperature, VSMC, rainfall, and the air temperature influence predicting SMS. In sensitivity analysis, the rainfall variable with the highest impact on SMS and its effectiveness was 3 to 4 times more than other input variables;
- As a result, the hybrid models proposed in this work have the potential to be implemented as a precise technique for SMS prediction and fine-tuning the ANN-BR algorithm.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| (ANN) | Artificial Neural Network |
| (ANN-BR) | Artificial Neural Network Bayesian Regularization |
| (BPNN) | Back-Propagation Neural Network |
| (BR-BPNN) | Bayesian Regularized Back-propagation Neural Network |
| (BR) | Bayesian Regularization |
| (BR-BP) | Bayesian Regularization Back-propagation |
| (BOA) | Butterfly Optimization Algorithm |
| (R2) | Coefficient of Determination |
| (GNM) | Gauss-Newton Method |
| (HVCCS) | High-Volume Change Clay Soil |
| (HWS) | Highway Slopes |
| (HSSR) | Highway Slopes Sustainability and Resiliency |
| (LM) | Levenberg-Marquardt |
| (LOGSIG) | Log Sigmoid |
| (LSTM) | Long Short-Term Memory |
| (MAE) | Mean Absolute Error |
| (MSE) | Mean Square Error |
| (PSO) | Particle Swarm Optimization |
| (PURELIN) | Purelin |
| (RNN) | Recurrent Neural Networks |
| (REC) | Regression Error Characteristic |
| (SMS) | Soil Matric Suction |
| (SWRC) | Soil Water Retention Curve |
| (TANSIG) | Tansigmoid |
| (TIS) | Transportation Infrastructure System |
| (VAF) | Variance Account For |
| (VSMC) | Volumetric Soil Moisture Content |
Appendix A












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Depths | VSMC | Air Temperature (°C) | Rainfall (mm) | Soil Temperature (°C) | Suction (kPa) |
|---|---|---|---|---|---|
| 1.5 m Depth | |||||
| Max | 0.47 | 51.929 | 48.00 | 27.666 | 267.874 |
| Min | 0.343 | −4.366 | 0.00 | 8.367 | 8.767 |
| Average | 0.409 | 19.116 | 0.211 | 19.744 | 22.687 |
| Median | 0.407 | 18.835 | 0.00 | 18.166 | 9.599 |
| Standard deviation | 0.027 | 10.532 | 1.484 | 5.124 | 46.336 |
| 3 m Depth | |||||
| Max | 0.62 | 51.929 | 48.00 | 25.562 | 24.067 |
| Min | 0.445 | −4.366 | 0.00 | 11.565 | 9.600 |
| Average | 0.521 | 19.116 | 0.211 | 20.725 | 10.716 |
| Median | 0.534 | 18.835 | 0.00 | 20.4 | 10.433 |
| Standard deviation | 0.036 | 10.532 | 1.484 | 3.30 | 1.776 |
| 4.5 m Depth | |||||
| Max | 0.48 | 51.929 | 48.00 | 31.109 | 12.869 |
| Min | 0.445 | −4.366 | 0.00 | 19.633 | 9.599 |
| Average | 0.456 | 19.116 | 0.211 | 22.101 | 10.065 |
| Median | 0.450 | 18.835 | 0.00 | 22.45 | 10.010 |
| Standard deviation | 0.010 | 10.532 | 1.484 | 1.476 | 0.329 |
| Depths | VSMC | Air Temperature (°C) | Rainfall (mm) | Soil Temperature (°C) | Suction (kPa) |
|---|---|---|---|---|---|
| 1.5 m Depth | |||||
| Max | 0.84 | 51.111 | 48.00 | 26.200 | 15.699 |
| Min | 0.428 | −2.413 | 0.00 | 16.130 | 9.235 |
| Average | 0.520 | 19.327 | 0.210 | 20.380 | 10.357 |
| Median | 0.519 | 18.419 | 0.00 | 19.944 | 10.133 |
| Standard deviation | 0.015 | 8.699 | 1.589 | 2.741 | 1.146 |
| 3 m Depth | |||||
| Max | 0.84 | 51.111 | 48.00 | 23.167 | 14.446 |
| Min | 0.507 | −2.413 | 0.00 | 18.600 | 9.533 |
| Average | 0.519 | 19.327 | 0.210 | 21.006 | 10.155 |
| Median | 0.520 | 18.419 | 0.00 | 21.067 | 10.067 |
| Standard deviation | 0.005 | 8.699 | 1.589 | 1.453 | 0.479 |
| 4.5 m Depth | |||||
| Max | 0.58 | 51.111 | 48.000 | 22.600 | 69.355 |
| Min | 0.417 | −2.413 | 0.000 | 20.478 | 10.201 |
| Average | 0.525 | 19.327 | 0.210 | 21.413 | 10.974 |
| Median | 0.500 | 18.419 | 0.00 | 21.467 | 10.434 |
| Standard deviation | 0.036 | 8.699 | 1.589 | 0.427 | 4.194 |
| Depths | VSMC | Air Temperature (°C) | Rainfall (mm) | Soil Temperature (°C) | Suction (kPa) |
|---|---|---|---|---|---|
| 1.5 m Depth | |||||
| Max | 0.54 | 43.583 | 48.00 | 25.433 | 12.573 |
| Min | 0.326 | −6.021 | 0.00 | 13.933 | 8.925 |
| Average | 0.468 | 18.537 | 0.208 | 19.466 | 9.858 |
| Median | 0.469 | 18.813 | 0.00 | 18.267 | 9.703 |
| Standard deviation | 0.022 | 9.526 | 1.582 | 3.822 | 0.485 |
| 3 m Depth | |||||
| Max | 0.53 | 43.583 | 48.00 | 24.00 | 11.367 |
| Min | 0.403 | −6.021 | 0.00 | 15.933 | 9.189 |
| Average | 0.457 | 18.537 | 0.208 | 19.533 | 9.839 |
| Median | 0.455 | 18.813 | 0.00 | 19.276 | 9.733 |
| Standard deviation | 0.013 | 9.526 | 1.582 | 2.289 | 0.488 |
| 4.5 m Depth | |||||
| Max | 0.51 | 43.583 | 48.00 | 25.370 | 22.777 |
| Min | 0.333 | −6.021 | 0.00 | 15.50 | 9.400 |
| Average | 0.418 | 18.537 | 0.208 | 23.50 | 12.572 |
| Median | 0.431 | 18.813 | 0.00 | 23.553 | 12.120 |
| Standard deviation | 0.048 | 9.526 | 1.582 | 1.051 | 2.361 |
| Depths | VSMC | Air Temperature (°C) | Rainfall (mm) | Soil Temperature (°C) | Suction (kPa) |
|---|---|---|---|---|---|
| 1.5 m Depth | |||||
| Max | 0.54 | 44.159 | 51.00 | 26.767 | 120.404 |
| Min | 0.360 | −7.689 | 0.00 | 13.700 | 8.885 |
| Average | 0.445 | 18.323 | 0.222 | 20.206 | 9.638 |
| Median | 0.446 | 18.506 | 0.00 | 19.300 | 9.183 |
| Standard deviation | 0.031 | 10.193 | 1.589 | 4.268 | 2.342 |
| 3 m Depth | |||||
| Max | 0.55 | 44.159 | 51.00 | 24.633 | 11.714 |
| Min | 0.383 | −7.689 | 0.00 | 17.200 | 9.268 |
| Average | 0.452 | 18.323 | 0.222 | 20.725 | 9.734 |
| Median | 0.452 | 18.506 | 0.00 | 20.544 | 9.566 |
| Standard deviation | 0.023 | 10.193 | 1.589 | 2.652 | 0.556 |
| 4.5 m Depth | |||||
| Max | 0.48 | 44.159 | 51.00 | 25.367 | 37.064 |
| Min | 0.412 | −7.689 | 0.00 | 21.724 | 11.834 |
| Average | 0.436 | 18.323 | 0.222 | 23.247 | 14.417 |
| Median | 0.434 | 18.506 | 0.00 | 23.344 | 12.067 |
| Standard deviation | 0.017 | 10.193 | 1.589 | 0.999 | 7.201 |
| Depths | VSMC | Air Temperature (°C) | Rainfall (mm) | Soil Temperature (°C) | Suction (kPa) |
|---|---|---|---|---|---|
| 1.5 m Depth | |||||
| Max | 0.58 | 45.929 | 48.00 | 29.449 | 39.472 |
| Min | 0.484 | −6.268 | 0.00 | 15.167 | 9.386 |
| Average | 0.547 | 17.876 | 0.209 | 22.103 | 9.784 |
| Median | 0.543 | 17.827 | 0.00 | 21.660 | 9.567 |
| Standard deviation | 0.014 | 9.574 | 1.602 | 3.984 | 1.446 |
| 3 m Depth | |||||
| Max | 0.54 | 45.929 | 48.00 | 26.593 | 11.934 |
| Min | 0.498 | −6.268 | 0.00 | 18.030 | 10.067 |
| Average | 0.525 | 17.876 | 0.209 | 21.206 | 10.364 |
| Median | 0.523 | 17.827 | 0.00 | 21.156 | 10.234 |
| Standard deviation | 0.011 | 9.574 | 1.602 | 2.244 | 0.395 |
| 4.5 m Depth | |||||
| Max | 0.56 | 45.929 | 48.00 | 23.10 | 12.333 |
| Min | 0.518 | −6.268 | 0.00 | 19.333 | 10.466 |
| Average | 0.523 | 17.876 | 0.209 | 21.084 | 10.838 |
| Median | 0.523 | 17.827 | 0.00 | 21.148 | 10.634 |
| Standard deviation | 0.003 | 9.574 | 1.602 | 0.993 | 0.462 |
| 3 m Depth | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ANN-BR | Ranking of Each Algorithm between the Same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.538 | 1.80 × 10−3 | 76.610 | 1.055 | 18 | 3 | 1 | 3 | 3 |
| HWS 2 | 0.984 | 3.88 × 10−2 | 96.887 | 1.899 | 16 | 3 | 3 | 3 | 3 |
| HWS 3 | 0.442 | 4.18 × 10−2 | 46.201 | 0.616 | 18 | 3 | 3 | 3 | 3 |
| HWS 4 | 0.890 | 1.62 × 10−2 | 79.256 | 1.569 | 18 | 3 | 3 | 3 | 3 |
| HWS 5 | 0.959 | 6.20 × 10−3 | 92.113 | 1.836 | 16 | 3 | 3 | 2 | 2 |
| HWS 6 | 0.923 | 1.50 × 10−3 | 85.231 | 1.703 | 17 | 3 | 3 | 3 | 3 |
| PSO-ANN | Ranking of each algorithm between the same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.997 | 1.88 × 10−3 | 97.817 | 1.972 | 18 | 1 | 2 | 1 | 1 |
| HWS 2 | 0.999 | 4.18 × 10−4 | 99.987 | 1.999 | 18 | 1 | 2 | 2 | 1 |
| HWS 3 | 0.999 | 4.82 × 10−4 | 95.997 | 1.959 | 16 | 1 | 1 | 2 | 1 |
| HWS 4 | 0.999 | 3.69 × 10−4 | 96.906 | 1.967 | 16 | 1 | 2 | 1 | 1 |
| HWS 5 | 0.999 | 4.02 × 10−4 | 92.808 | 1.926 | 16 | 2 | 1 | 1 | 1 |
| HWS 6 | 0.999 | 1.77 × 10−4 | 94.879 | 1.948 | 18 | 1 | 1 | 1 | 1 |
| BOA-ANN | Ranking of each algorithm between the same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.995 | 4.84 × 10−3 | 97.466 | 1.962 | 18 | 2 | 3 | 2 | 2 |
| HWS 2 | 0.999 | 3.97 × 10−4 | 99.988 | 1.999 | 18 | 1 | 1 | 1 | 1 |
| HWS 3 | 0.809 | 5.43 × 10−4 | 96.577 | 1.621 | 16 | 2 | 2 | 1 | 2 |
| HWS 4 | 0.999 | 3.30 × 10−4 | 96.904 | 1.967 | 18 | 2 | 1 | 2 | 1 |
| HWS 5 | 0.999 | 4.45 × 10−4 | 35.210 | 1.350 | 18 | 1 | 2 | 3 | 3 |
| HWS 6 | 0.999 | 2.05 × 10−4 | 94.861 | 1.947 | 18 | 2 | 2 | 2 | 2 |
| 4.5 m Depth | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ANN-BR | Ranking of EACH Algorithm between the Same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.857 | 1.00 × 10−4 | 91.254 | 1.648 | 14 | 3 | 1 | 3 | 3 |
| HWS 2 | 0.735 | 4.00 × 10−3 | 54.081 | 1.078 | 16 | 3 | 3 | 3 | 3 |
| HWS 3 | 0.994 | 1.17 × 10−1 | 98.959 | 1.862 | 16 | 3 | 3 | 3 | 3 |
| HWS 4 | 0.982 | 2.79 × 10−2 | 95.985 | 1.896 | 18 | 3 | 2 | 3 | 3 |
| HWS 5 | 0.999 | 2.20 × 10−3 | 99.979 | 1.997 | 17 | 3 | 3 | 3 | 3 |
| HWS 6 | 0.926 | 9.70 × 10−3 | 85.902 | 1.708 | 18 | 3 | 3 | 3 | 3 |
| PSO-ANN | Ranking of each algorithm between the same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.998 | 1.58 × 10−3 | 97.875 | 1.973 | 16 | 1 | 2 | 1 | 1 |
| HWS 2 | 0.998 | 2.21 × 10−4 | 99.779 | 1.995 | 17 | 1 | 1 | 1 | 1 |
| HWS 3 | 0.999 | 1.95 × 10−3 | 99.942 | 1.997 | 18 | 1 | 1 | 1 | 1 |
| HWS 4 | 0.997 | 4.62 × 10−2 | 99.335 | 1.942 | 18 | 1 | 3 | 2 | 2 |
| HWS 5 | 1.00 | 1.20 × 10−4 | 99.999 | 2.000 | 18 | 1 | 1 | 1 | 1 |
| HWS 6 | 0.983 | 1.59 × 10−4 | 95.709 | 1.924 | 18 | 2 | 1 | 1 | 2 |
| BOA-ANN | Ranking of each algorithm between the same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.996 | 2.68 × 10−3 | 97.619 | 1.967 | 18 | 2 | 3 | 2 | 2 |
| HWS 2 | 0.998 | 2.85 × 10−4 | 99.734 | 1.994 | 16 | 2 | 2 | 2 | 2 |
| HWS 3 | 0.999 | 3.83 × 10−3 | 99.920 | 1.995 | 18 | 2 | 2 | 2 | 2 |
| HWS 4 | 0.997 | 2.33 × 10−3 | 99.944 | 1.992 | 17 | 2 | 1 | 1 | 1 |
| HWS 5 | 1.00 | 2.01 × 10−4 | 99.999 | 2.000 | 18 | 1 | 2 | 2 | 1 |
| HWS 6 | 0.998 | 2.20 × 10−4 | 95.678 | 1.954 | 18 | 1 | 2 | 2 | 1 |
References
- Douglas, S.; Dunlap, G. Light commercial construction on Yazoo clay. Forensic Eng. 2000, 2000, 607–616. [Google Scholar]
- Lee, L.T., Jr. State Study 151 and 236: Yazoo Clay Investigation; Transportation Research Record (TRR): Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Khan, M.S.; Amini, F.; Nobahar, M. Performance Evaluation of Highway Slopes on Yazoo Clay; Mississippi. Dept. of Transportation: Washington, DC, USA, 2020.
- Cai, J.-S.; Yeh, T.-C.J.; Yan, E.-C.; Tang, R.-X.; Hao, Y.-H.; Huang, S.-Y.; Wen, J.-C. Importance of variability in initial soil moisture and rainfalls on slope stability. J. Hydrol. 2019, 571, 265–278. [Google Scholar] [CrossRef]
- Melinda, F.; Rahardjo, H.; Han, K.K.; Leong, E.C. Shear strength of compacted soil under infiltration condition. J. Geotech. Geoenviron. Eng. 2004, 130, 807–817. [Google Scholar] [CrossRef]
- Lim, T.; Rahardjo, H.; Chang, M.; Fredlund, D.G. Effect of rainfall on matric suctions in a residual soil slope. Can. Geotech. J. 1996, 33, 618–628. [Google Scholar] [CrossRef]
- Kaykhosravi, S.; Khan, U.T.; Jadidi, M.A. The effect of climate change and urbanization on the demand for low impact development for three Canadian cities. Water 2020, 12, 1280. [Google Scholar] [CrossRef]
- Marengo, J.A.; Camarinha, P.I.; Alves, L.M.; Diniz, F.; Betts, R.A. Extreme rainfall and hydro-geo-meteorological disaster risk in 1.5, 2.0, and 4.0 °C global warming scenarios: An analysis for Brazil. Front. Clim. 2021, 3, 610433. [Google Scholar] [CrossRef]
- Mallick, J.; Alqadhi, S.; Talukdar, S.; AlSubih, M.; Ahmed, M.; Khan, R.A.; Kahla, N.B.; Abutayeh, S.M. Risk assessment of resources exposed to rainfall induced landslide with the development of GIS and RS based ensemble metaheuristic machine learning algorithms. Sustainability 2021, 13, 457. [Google Scholar] [CrossRef]
- Touma, D.; Stevenson, S.; Swain, D.L.; Singh, D.; Kalashnikov, D.A.; Huang, X. Climate change increases risk of extreme rainfall following wildfire in the western United States. Science advances 2022, 8, eabm0320. [Google Scholar] [CrossRef]
- Kaykhosravi, S.; Abogadil, K.; Khan, U.T.; Jadidi, M.A. The low-impact development demand index: A new approach to identifying locations for LID. Water 2019, 11, 2341. [Google Scholar] [CrossRef] [Green Version]
- Kaykhosravi, S.; Khan, U.T.; Jadidi, M.A. A simplified geospatial model to rank LID solutions for urban runoff management. Sci. Total Environ. 2022, 831, 154937. [Google Scholar] [CrossRef]
- Duncan, J.M.; Wright, S.G.; Brandon, T.L. Soil Strength and Slope Stability; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Statistics Bureau of Transportation. National Transportation Statistics. Res. Innov. Technol. Adm. 2015, 1–470. [Google Scholar]
- International Traffic Safety Data and Analysis Group. Road Safety Annual Report; International Traffic Safety Data and Analysis Group: Paris, France, 2019. [Google Scholar]
- Fassin, D.; Vasquez, P. Humanitarian exception as the rule: The political theology of the 1999 Tragedia in Venezuela. Am. Ethnol. 2005, 32, 389–405. [Google Scholar] [CrossRef]
- Kothari, U.C.; Momayez, M. Machine learning: A novel approach to predicting slope instabilities. Int. J. Geophys. 2018, 2018, 4861254. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S.; Network, N. A comprehensive foundation. Neural Netw. 2004, 2, 41. [Google Scholar]
- Nie, W.; Feng, D.; Lohpaisankrit, W.; Li, C.; Yuan, J.; Chen, Y. A dynamic Bayesian network-based model for evaluating rainfall-induced landslides. Bull. Eng. Geol. Environ. 2019, 78, 2069–2080. [Google Scholar] [CrossRef]
- Wang, Y.; Aladejare, A.E. Bayesian characterization of correlation between uniaxial compressive strength and Young’s modulus of rock. Int. J. Rock Mech. Min. Sci. 2016, 85, 10–19. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, L.; Jia, J. Diagnosis of embankment dam distresses using Bayesian networks. Part II. Diagnosis of a specific distressed dam. Can. Geotech. J. 2011, 48, 1645–1657. [Google Scholar] [CrossRef]
- Araei, A.A. Artificial neural networks for modeling drained monotonic behavior of rockfill materials. Int. J. Geomech. 2014, 14, 04014005. [Google Scholar] [CrossRef]
- Yagiz, S.; Sezer, E.; Gokceoglu, C. Artificial neural networks and nonlinear regression techniques to assess the influence of slake durability cycles on the prediction of uniaxial compressive strength and modulus of elasticity for carbonate rocks. Int. J. Numer. Anal. Methods Geomech. 2012, 36, 1636–1650. [Google Scholar] [CrossRef]
- Shahin, M.A.; Maier, H.R.; Jaksa, M.B. Data division for developing neural networks applied to geotechnical engineering. J. Comput. Civ. Eng. 2004, 18, 105–114. [Google Scholar] [CrossRef]
- Nobahar, M.; Khan, M. Prediction of Matric Suction of Highway Slopes Using Autoregression Artificial Neural Network (ANN) Model. Geo-Extreme 2021, 2021, 40–50. [Google Scholar]
- Snieder, E.; Khan, U. Large-Scale Evaluation of Temporal Trends in ANN Behaviour for Daily Flow Forecasts in Canadian Catchments. In Proceedings of the EGU General Assembly 2022, Vienna, Austria, 23–27 May 2022. [Google Scholar]
- Khan, U.T.; He, J.; Valeo, C. River flood prediction using fuzzy neural networks: An investigation on automated network architecture. Water Sci. Technol. 2018, 2017, 238–247. [Google Scholar] [CrossRef] [PubMed]
- Liou, Y.-A.; Liu, S.-F.; Wang, W.-J. Retrieving soil moisture from simulated brightness temperatures by a neural network. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1662–1672. [Google Scholar]
- Atluri, V.; Hung, C.-C.; Coleman, T.L. An artificial neural network for classifying and predicting soil moisture and temperature using Levenberg-Marquardt algorithm. In Proceedings of the IEEE Southeastcon’99. Technology on the Brink of 2000 (Cat. No. 99CH36300), Lexington, Kentucky, 25–28 March 1999; pp. 10–13. [Google Scholar]
- Moayedi, H.; Mehrabi, M.; Mosallanezhad, M.; Rashid, A.S.A.; Pradhan, B. Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng. Comput. 2019, 35, 967–984. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Emadi, M.; Cherati, A.; Heung, B.; Mosavi, A.; Scholten, T. Bio-inspired hybridization of artificial neural networks: An application for mapping the spatial distribution of soil texture fractions. Remote Sens. 2021, 13, 1025. [Google Scholar] [CrossRef]
- Gordan, B.; Jahed Armaghani, D.; Hajihassani, M.; Monjezi, M. Prediction of seismic slope stability through combination of particle swarm optimization and neural network. Eng. Comput. 2016, 32, 85–97. [Google Scholar] [CrossRef]
- Asadnia, M.; Chua, L.H.; Qin, X.; Talei, A. Improved particle swarm optimization–based artificial neural network for rainfall-runoff modeling. J. Hydrol. Eng. 2014, 19, 1320–1329. [Google Scholar] [CrossRef]
- Alqadhi, S.; Mallick, J.; Talukdar, S.; Bindajam, A.A.; Saha, T.K.; Ahmed, M.; Khan, R.A. Combining logistic regression-based hybrid optimized machine learning algorithms with sensitivity analysis to achieve robust landslide susceptibility mapping. Geocarto Int. 2021, 1–26. [Google Scholar] [CrossRef]
- Paryani, S.; Neshat, A.; Javadi, S.; Pradhan, B. Comparative performance of new hybrid ANFIS models in landslide susceptibility mapping. Nat. Hazards 2020, 103, 1961–1988. [Google Scholar] [CrossRef]
- Nguyen, H.; Mehrabi, M.; Kalantar, B.; Moayedi, H.; Abdullahi, M.a.M. Potential of hybrid evolutionary approaches for assessment of geo-hazard landslide susceptibility mapping. Geomat. Nat. Hazards Risk 2019, 10, 1667–1693. [Google Scholar] [CrossRef]
- Bui, D.T.; Moayedi, H.; Kalantar, B.; Osouli, A.; Pradhan, B.; Nguyen, H.; Rashid, A.S.A. A novel swarm intelligence—Harris hawks optimization for spatial assessment of landslide susceptibility. Sensors 2019, 19, 3590. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rukhaiyar, S.; Alam, M.; Samadhiya, N.K. A PSO-ANN hybrid model for predicting factor of safety of slope. Int. J. Geotech. Eng. 2018, 12, 556–566. [Google Scholar] [CrossRef]
- Xi, W.; Li, G.; Moayedi, H.; Nguyen, H. A particle-based optimization of artificial neural network for earthquake-induced landslide assessment in Ludian county, China. Geomat. Nat. Hazards Risk 2019, 10, 1750–1771. [Google Scholar] [CrossRef] [Green Version]
- Xing, Y.; Yue, J.; Chen, C. Interval estimation of landslide displacement prediction based on time series decomposition and long short-term memory network. IEEE Access 2019, 8, 3187–3196. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, J.; He, X.; Yang, L.; Cui, T.; Yu, T.; Kheiry, A.N. Application of swarm intelligence algorithms to the characteristic wavelength selection of soil moisture content. Int. J. Agric. Biol. Eng. 2021, 14, 153–161. [Google Scholar] [CrossRef]
- Lohar, G.; Sharma, S.; Saha, A.K.; Ghosh, S. Optimization of geotechnical parameters used in slope stability analysis by metaheuristic algorithms. In Applications of Internet of Things; Springer: Berlin/Heidelberg, Germany, 2021; pp. 223–231. [Google Scholar]
- Yitian, L.; Gu, R.R. Modeling flow and sediment transport in a river system using an artificial neural network. Environ. Manag. 2003, 31, 0122–0134. [Google Scholar] [CrossRef]
- Wilby, R.L.; Wigley, T.; Conway, D.; Jones, P.; Hewitson, B.; Main, J.; Wilks, D. Statistical downscaling of general circulation model output: A comparison of methods. Water Resour. Res. 1998, 34, 2995–3008. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural networks and their applications. Rev. Sci. Instrum. 1994, 65, 1803–1832. [Google Scholar] [CrossRef] [Green Version]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Nielsen, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015; Volume 25. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; pp. 4104–4108. [Google Scholar]
- Stevens, S.S.; Marks, L.E. Psychophysics: Introduction to Its Perceptual, Neural, and Social Prospects; Routledge: London, UK, 2017. [Google Scholar]
- Arora, S.; Singh, S. Butterfly optimization algorithm: A novel approach for global optimization. Soft Comput. 2019, 23, 715–734. [Google Scholar] [CrossRef]
- Arora, S.; Anand, P. Learning automata-based butterfly optimization algorithm for engineering design problems. Int. J. Comput. Mater. Sci. Eng. 2018, 7, 1850021. [Google Scholar] [CrossRef]
- Bi, J.; Bennett, K.P. Regression error characteristic curves. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 43–50. [Google Scholar]
- Yang, Y.; Zhang, Q. A hierarchical analysis for rock engineering using artificial neural networks. Rock Mech. Rock Eng. 1997, 30, 207–222. [Google Scholar] [CrossRef]
- Le, L.T.; Nguyen, H.; Dou, J.; Zhou, J. A comparative study of PSO-ANN, GA-ANN, ICA-ANN, and ABC-ANN in estimating the heating load of buildings’ energy efficiency for smart city planning. Appl. Sci. 2019, 9, 2630. [Google Scholar] [CrossRef] [Green Version]
- Olive, W.; Chleborad, A.; Frahme, C.; Schlocker, J.; Schneider, R.; Schuster, R. Swelling Clays Map of the Conterminous United States; United States Geological Survey: Reston, VA, USA, 1989.














| Depths | VSMC | Air Temperature (°C) | Rainfall (mm) | Soil Temperature (°C) | Suction (kPa) |
|---|---|---|---|---|---|
| 1.5 m Depth | |||||
| Max | 0.55 | 45.361 | 48.00 | 25 | 12.698 |
| Min | 0.426 | −7.082 | 0.00 | 15.829 | 9.227 |
| Average | 0.520 | 18.218 | 0.208 | 20.483 | 10.372 |
| Median | 0.523 | 18.528 | 0.00 | 20 | 10.101 |
| Standard deviation | 0.019 | 10.106 | 1.574 | 2.914 | 0.654 |
| 3 m Depth | |||||
| Max | 0.54 | 45.361 | 48.00 | 24.766 | 17.90 |
| Min | 0.490 | −7.082 | 0.00 | 17.433 | 9.206 |
| Average | 0.518 | 18.218 | 0.208 | 20.830 | 10.277 |
| Median | 0.516 | 18.528 | 0.00 | 20.566 | 9.718 |
| Standard deviation | 0.005 | 10.106 | 1.574 | 2.480 | 1.509 |
| 4.5 m Depth | |||||
| Max | 0.50 | 45.361 | 48.00 | 22.566 | 11.178 |
| Min | 0.377 | −7.082 | 0.00 | 19.366 | 9.983 |
| Average | 0.453 | 18.218 | 0.208 | 21.101 | 10.236 |
| Median | 0.457 | 18.528 | 0.00 | 21.233 | 10.167 |
| Standard deviation | 0.017 | 10.106 | 1.574 | 1.043 | 0.243 |
| 1.5 m Depth | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ANN-BR | Ranking of Each Algorithm between the Same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.737496 | 5.50 E−03 | 54.389 | 1.082 | 16 | 3 | 3 | 3 | 3 |
| HWS 2 | 0.997647 | 3.12E+00 | 99.530 | 0.100 | 16 | 3 | 3 | 3 | 3 |
| HWS 3 | 0.948841 | 3.28E−02 | 90.024 | 1.768 | 15 | 3 | 3 | 3 | 3 |
| HWS 4 | 0.684909 | 4.86E−02 | 46.870 | 0.889 | 18 | 3 | 3 | 3 | 3 |
| HWS 5 | 0.691881 | 7.03E−01 | 47.866 | 0.254 | 14 | 3 | 3 | 3 | 3 |
| HWS 6 | 0.963224 | 1.67E−02 | 92.742 | 1.839 | 16 | 3 | 3 | 3 | 3 |
| PSO-ANN | Ranking of each algorithm between the same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.997447 | 2.17E−03 | 99.489 | 1.988 | 16 | 1 | 1 | 1 | 1 |
| HWS 2 | 0.999650 | 1.25E+00 | 99.926 | 0.750 | 17 | 2 | 2 | 2 | 2 |
| HWS 3 | 0.998699 | 3.41E−03 | 99.182 | 1.986 | 18 | 2 | 2 | 2 | 2 |
| HWS 4 | 0.984022 | 6.55E−03 | 88.116 | 1.843 | 16 | 2 | 2 | 2 | 2 |
| HWS 5 | 0.886905 | 4.35E−01 | 78.657 | 1.138 | 16 | 1 | 2 | 1 | 2 |
| HWS 6 | 0.998098 | 8.02E−04 | 99.382 | 1.989 | 18 | 2 | 1 | 2 | 2 |
| BOA-ANN | Ranking of each algorithm between the same HWS | ||||||||
| Site Location | R | MSE | VAF | δ | #Neurons | R | MSE | VAF | δ |
| HWS 1 | 0.996795 | 2.61E−03 | 97.626 | 1.967 | 16 | 2 | 2 | 2 | 2 |
| HWS 2 | 0.999750 | 1.03E+00 | 99.945 | 0.969 | 18 | 1 | 1 | 1 | 1 |
| HWS 3 | 0.999050 | 2.34E−03 | 99.260 | 1.988 | 18 | 1 | 1 | 1 | 1 |
| HWS 4 | 0.993680 | 2.26E−03 | 90.077 | 1.886 | 16 | 1 | 1 | 1 | 1 |
| HWS 5 | 0.840119 | 1.79E−01 | 66.443 | 1.191 | 18 | 2 | 1 | 2 | 1 |
| HWS 6 | 0.999600 | 1.83E−03 | 99.601 | 1.993 | 18 | 1 | 2 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davar, S.; Nobahar, M.; Khan, M.S.; Amini, F. The Development of PSO-ANN and BOA-ANN Models for Predicting Matric Suction in Expansive Clay Soil. Mathematics 2022, 10, 2825. https://doi.org/10.3390/math10162825
Davar S, Nobahar M, Khan MS, Amini F. The Development of PSO-ANN and BOA-ANN Models for Predicting Matric Suction in Expansive Clay Soil. Mathematics. 2022; 10(16):2825. https://doi.org/10.3390/math10162825
Chicago/Turabian StyleDavar, Saeed, Masoud Nobahar, Mohammad Sadik Khan, and Farshad Amini. 2022. "The Development of PSO-ANN and BOA-ANN Models for Predicting Matric Suction in Expansive Clay Soil" Mathematics 10, no. 16: 2825. https://doi.org/10.3390/math10162825
APA StyleDavar, S., Nobahar, M., Khan, M. S., & Amini, F. (2022). The Development of PSO-ANN and BOA-ANN Models for Predicting Matric Suction in Expansive Clay Soil. Mathematics, 10(16), 2825. https://doi.org/10.3390/math10162825