


Deep Learning-Based Software Defect Prediction via Semantic Key Features of Source Code—Systematic Survey
 , ,
, ,  , ,
, ,  and
and 
Abstract
:1. Introduction
- A comprehensive study is conducted to show the state-of-the-art software defect prediction approaches using the contextual information that is generated from the source codes. The strategies for analyzing and representing the source code is the main topic of this study.
- The current challenges and threats related to the semantic features-based SDP are evaluated through examining and addressing the current potential solutions. In addition, we provide guidelines for building an efficient deep learning model for the SDP over various conditions.
- We also group deep learning (DL) models that have recently been used for the SDP based on the semantic features collected from the source codes and compare the performance of the various DL models, and the best DL models that outperform the existing conventional ones are outlined.
2. Background and Related Studies
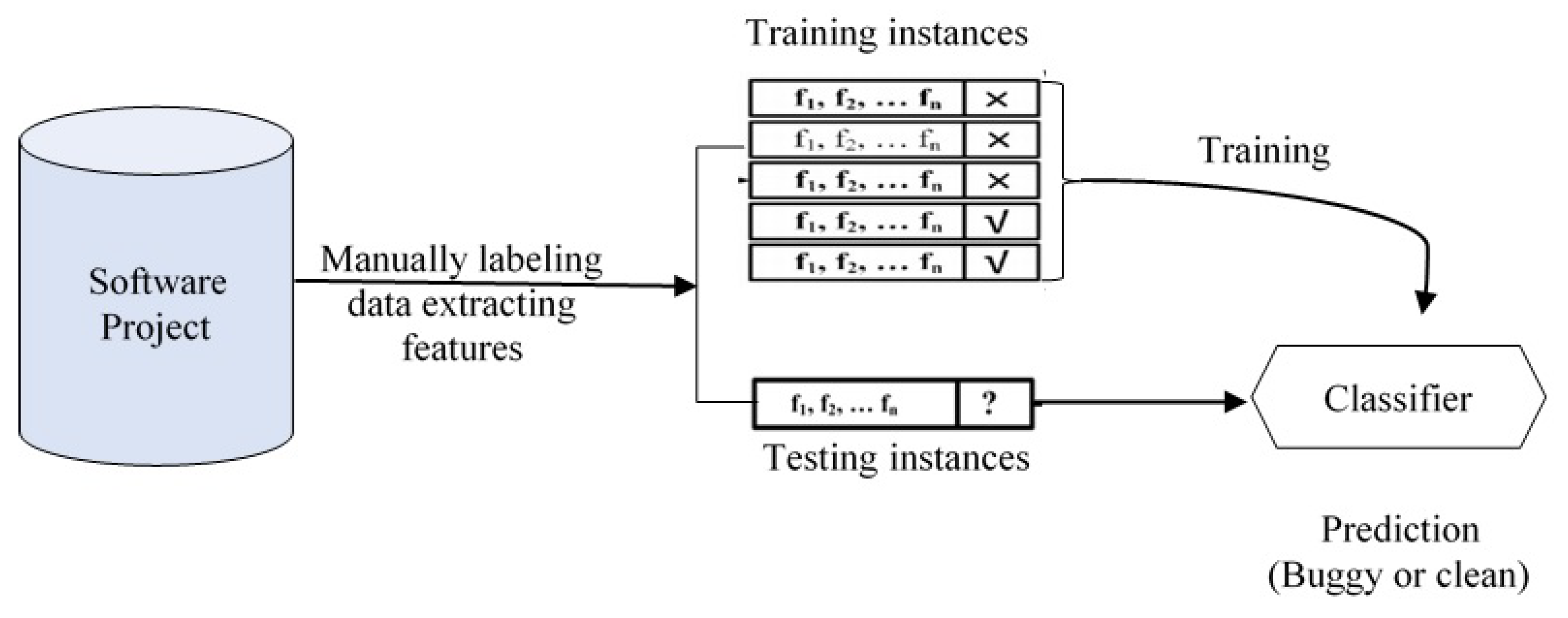
2.1. Traditional Software Defect Prediction
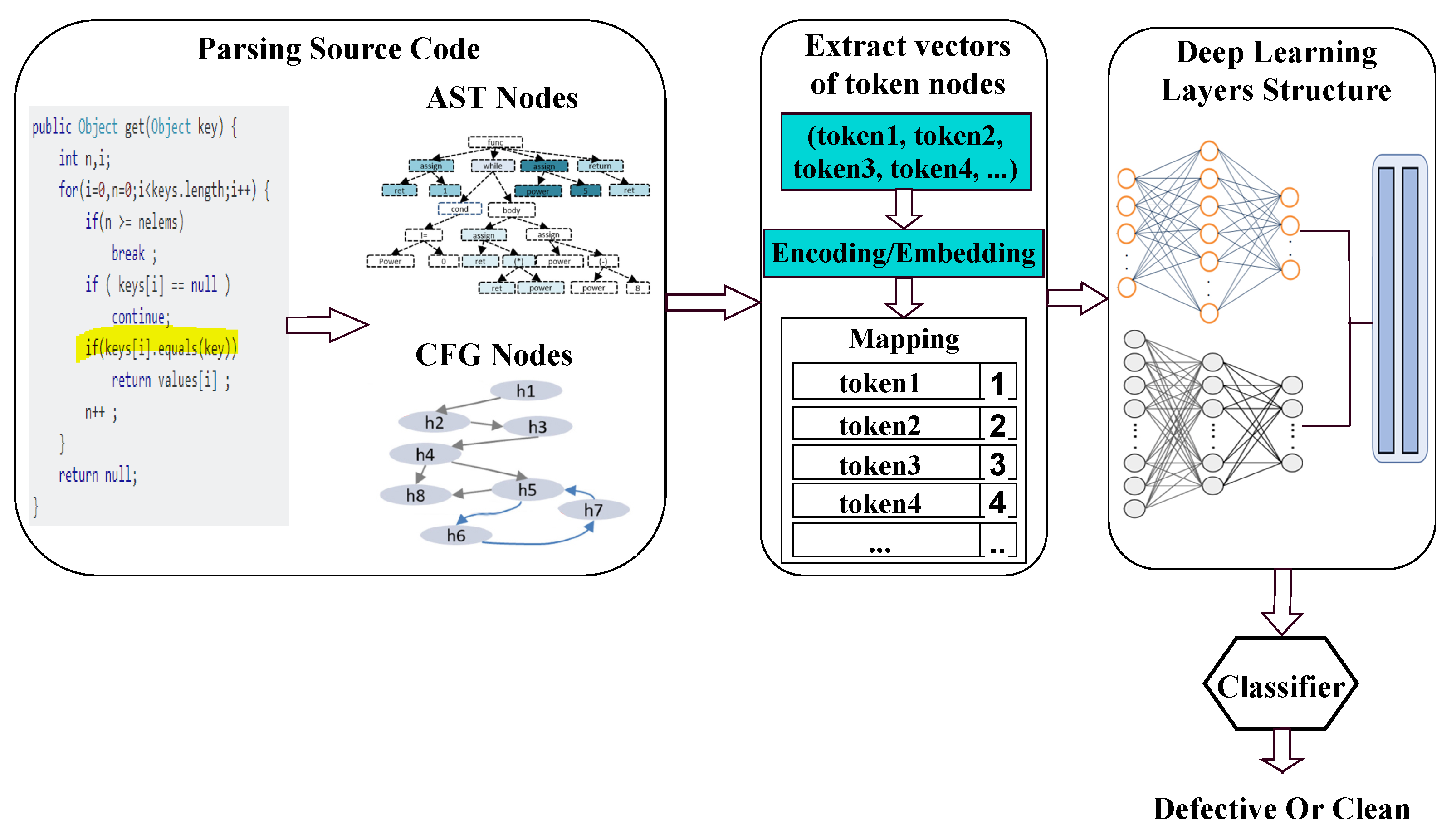
2.2. Software Defect Prediction Based on Analysis the Source Code Semantic Features
2.3. Related Studies
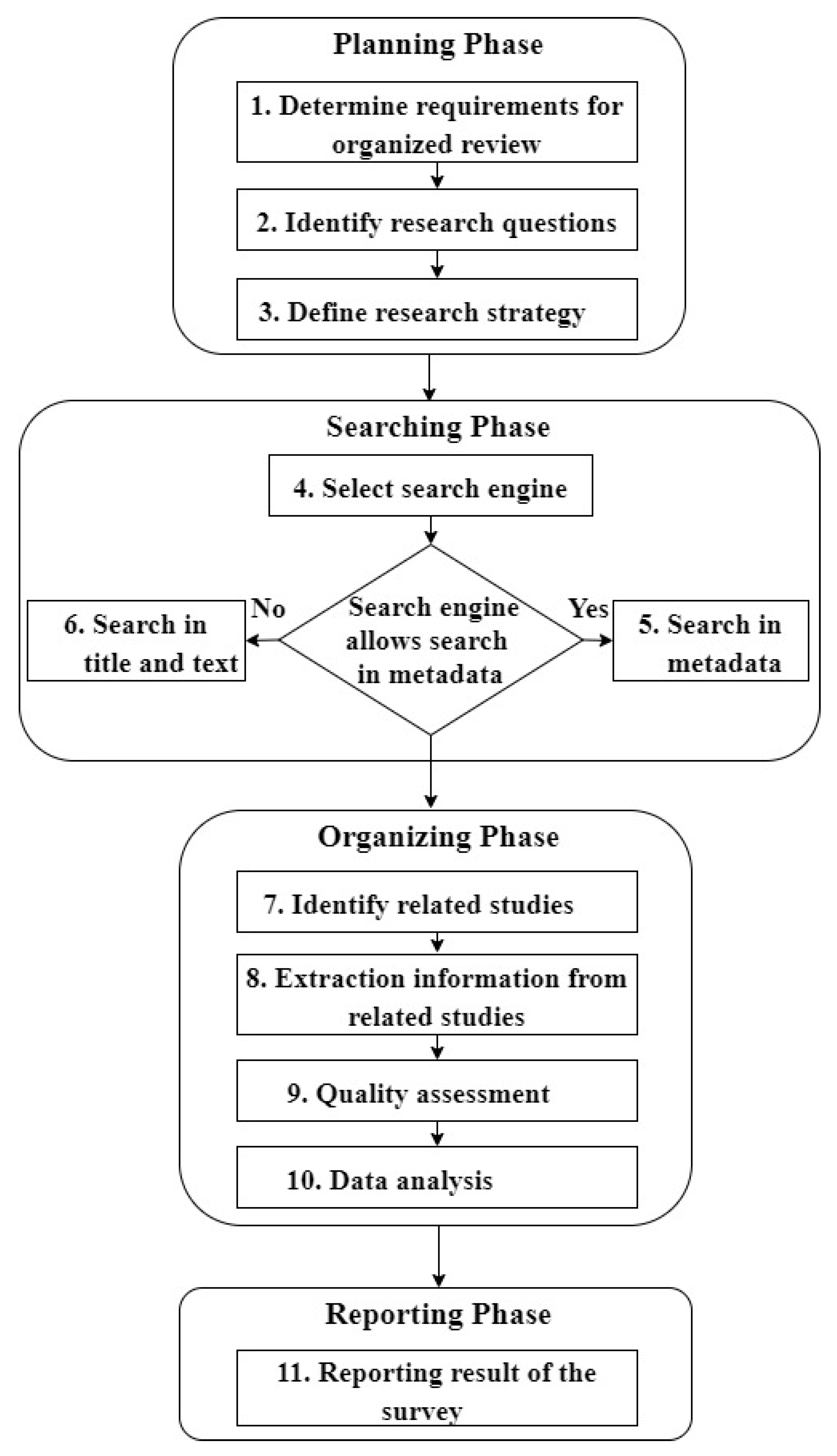
3. Methodology
3.1. Research Strategy
3.2. Research Questions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RQ-No | Research Questions |
|---|---|
| RQ-1 | What is the motivation for using semantic features in SDP? |
| RQ-2 | Which techniques are used for source code representation? |
| RQ-3 | What datasets are used in semantic features-based SDP, and where can they be obtained? |
| RQ-4 | Which deep learning techniques are used in semantic features-based SDP? |
| RQ-5 | Performance analysis of different deep learning techniques applied to semantic feature-based SDP models. |
| RQ-5.1 | Which deep learning techniques outperform existing SDP models? |
| RQ-6 | What evaluation metrics are generally used in semantic features-based SDP models? |
| RQ-7 | What are the challenges in semantic features-based SDP? |
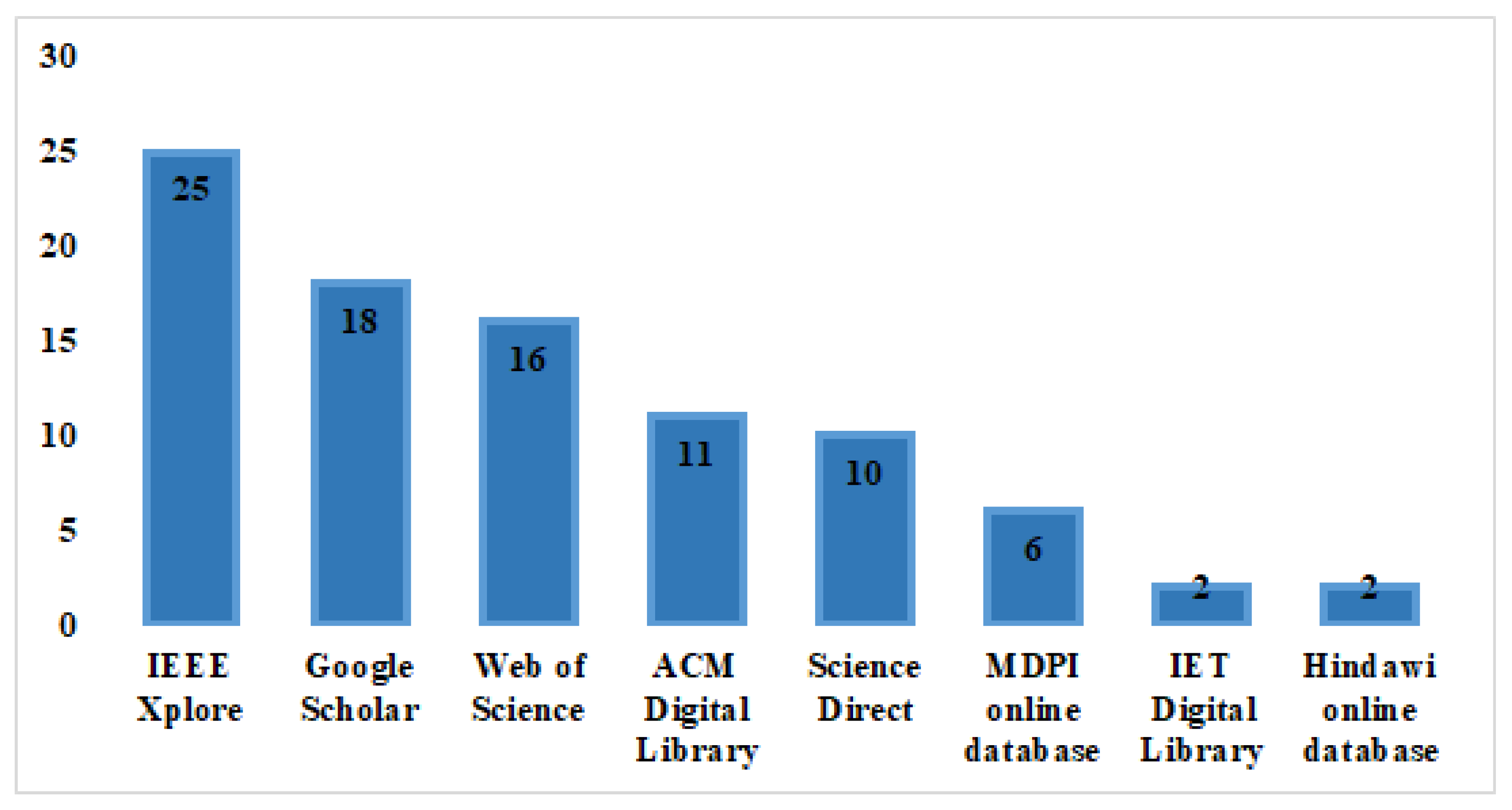
3.3. Search for Related Studies
- IEEE Xplore
- Web of Science
- Google Scholar
- Science Direct
- ACM Digital Library
- Hindawi online database
- IET Digital Library
- MDPI online database
- The study must include a technique for extracting semantic features from the source code.
- An experimental investigation of SDP is presented using deep learning models.
- The article must be a minimum of six pages.
- The study reported without an experimental investigation of the semantic feature-based technique.
- The article has only an abstract (the accessibility of the article is not included in this criterion; both papers (open access and subscription) were included.
- The paper is not a major relevant study article.
- The study does not provide a detailed description of how deep learning is applied.
4. Results
4.1. RQ-1: Motivation
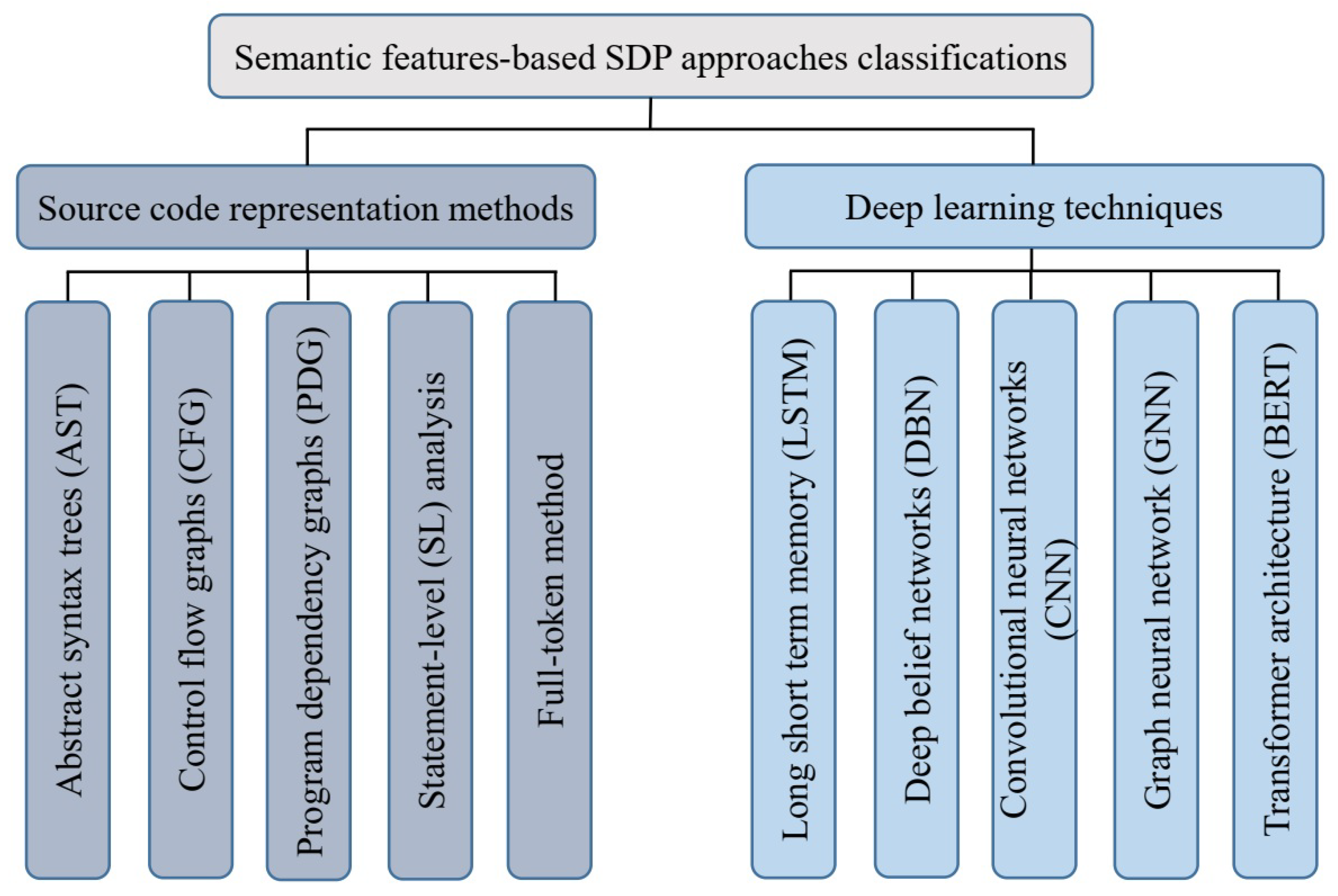
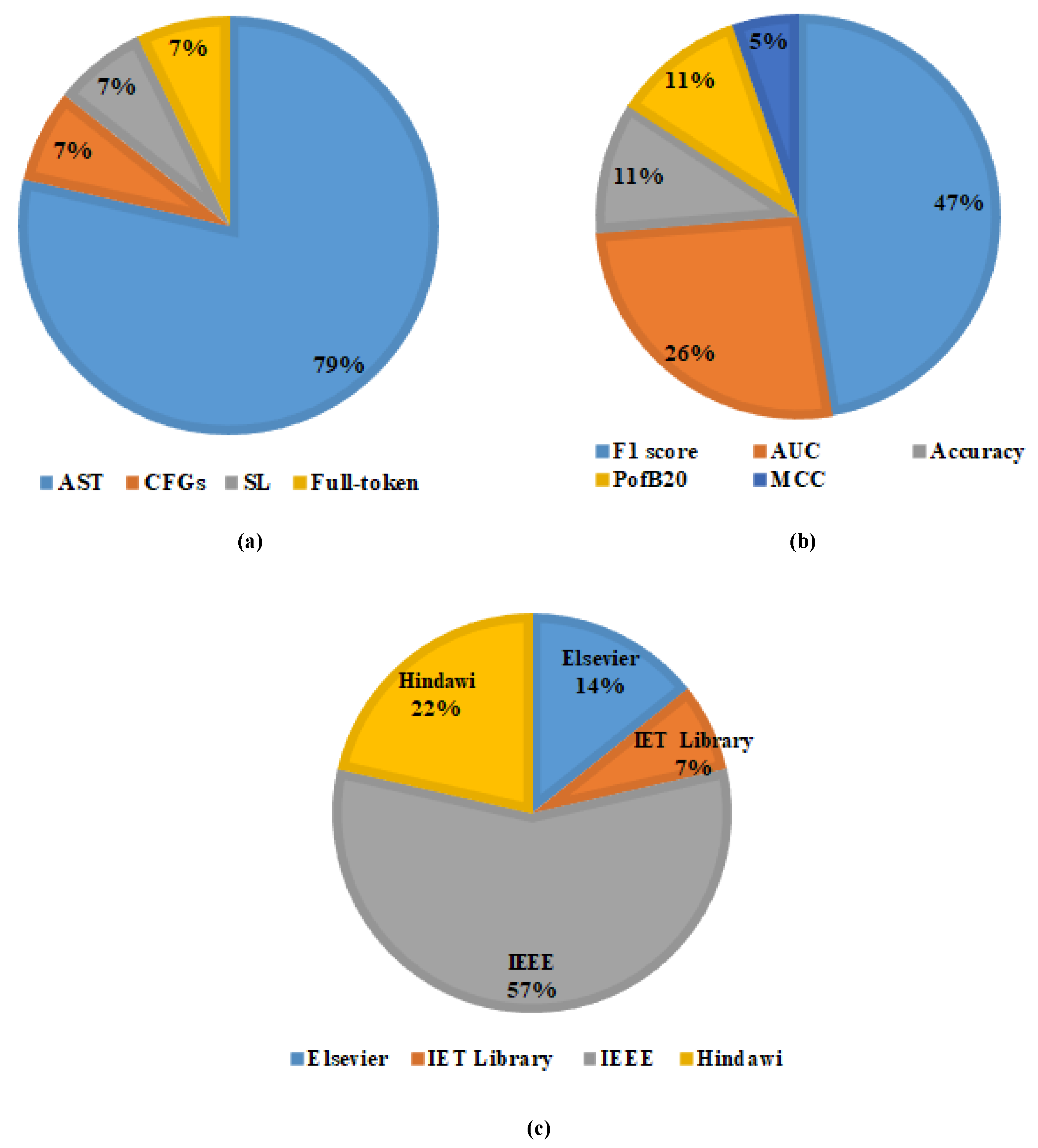
4.2. Rq-2: Source Code Representation Techniques
4.3. Rq-3: Available Dataset
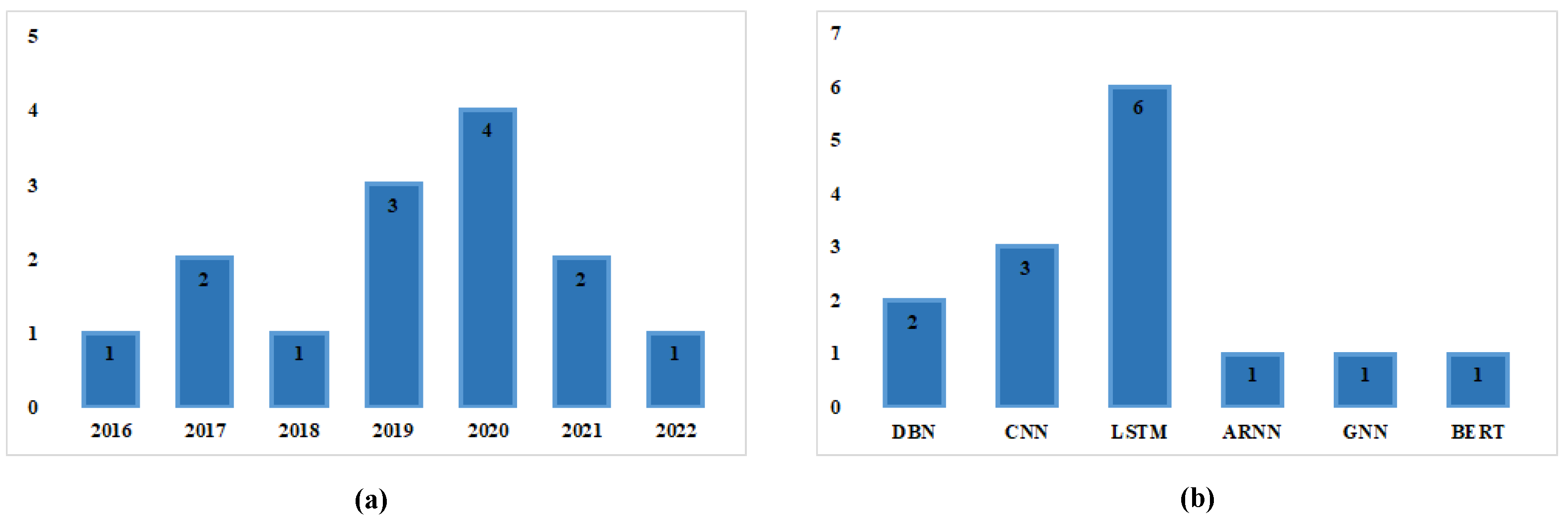
4.4. Rq-4: Deep Learning Techniques for Semantic Feature-Based SDP
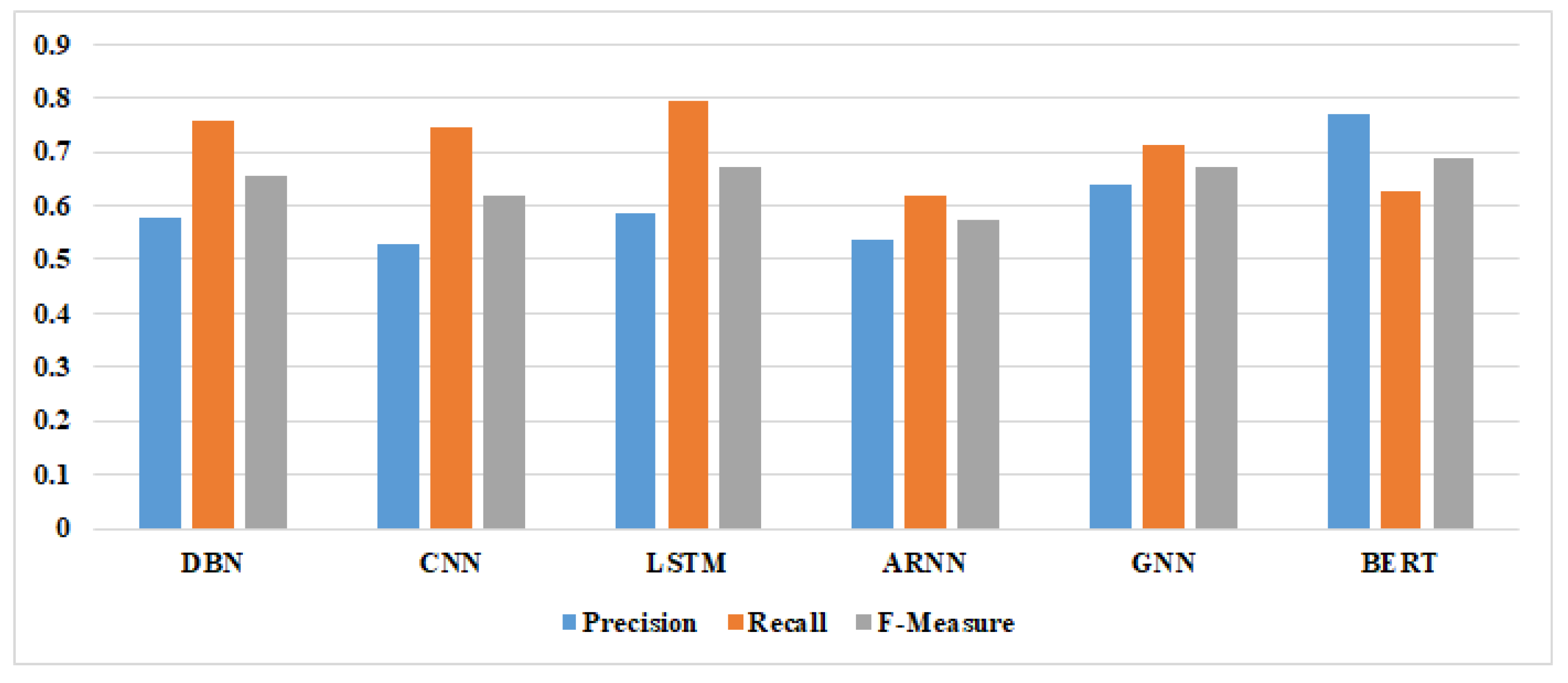
4.5. Rq-5: Performance Analysis of Different Deep Learning Techniques Applied to Semantic Feature-Based SDP Models
4.6. Rq-5.1: Which Deep Learning Techniques Outperform Existing SDP Models?
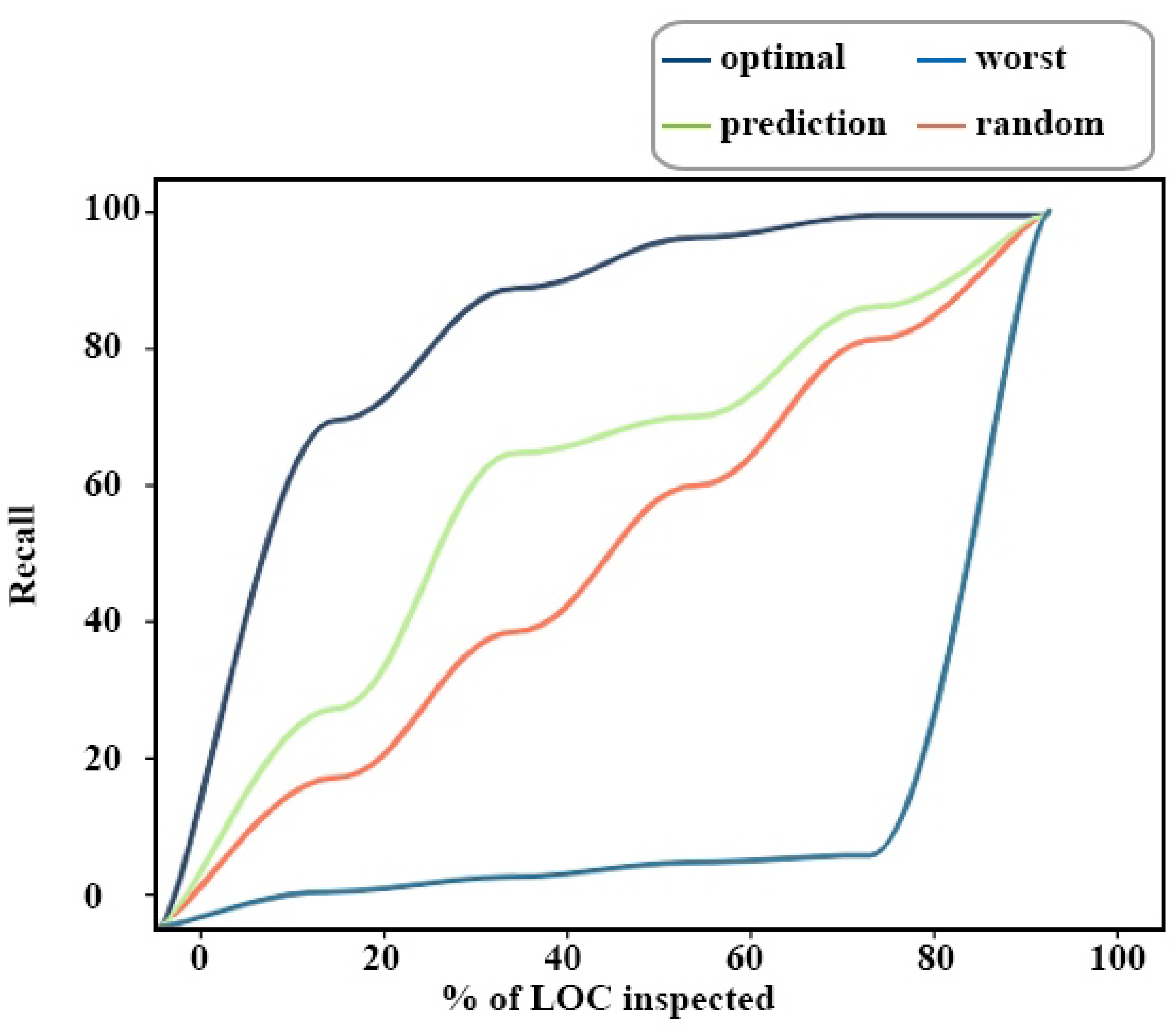
4.7. Rq-6: Evaluation Metrics
- A.
- Non-effort-aware evaluation metrics
- B.
- Effort-aware evaluation metrics
4.8. Rq-7: Semantic Features-Based SDP Challenges
- 1.
- Lack of context
- 2.
- Lack of data
5. Discussion
5.1. General Discussion
5.2. Threats to Validity
5.2.1. Conclusion Validity
5.2.2. Internal Validity
5.2.3. External Validity
6. Conclusions and Future Work
- There should be a more general outcome of various semantic features-based SDP approaches; only a few studies have been studied in generalized methods. When the researcher adopts this perspective, it will be possible to compare SDP’s efficiency and performance.
- Industries should have free access to the dataset to conduct more research experiments for SDP. Researchers and developers should reduce the demand for labeled datasets of large size; they should apply self-supervised learning to large amounts of unlabeled data. They should add more features and test cases so DL can be easily used without overfitting.
- It is essential to compare the performance of DL techniques to other DL /Statistical approaches to assess their potential comparison to SDP.
- Mobile applications have received widespread attention because of their simplicity, portability, timeliness, and efficiency. The business community is constantly developing office and mobile applications suitable for various scenarios. Therefore, SDP techniques can also be applied to mobile application-based architecture. Practitioners should precisely be taking further care to explore the applicability of existing approaches in mobile applications.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SDP | Software Defect Prediction |
| CPDP | Cross Project Defect Prediction |
| WPD | PWithin Project Defect Prediction |
| ML | Machine Learning |
| DL | Deep Learning |
| AST | Abstract Syntax Trees |
| CFG | Control Flow Graph |
| OO | Object-Oriented |
| CNN | Convolutional Neural Networks |
| DBN | Deep Belief Networks |
| LSTM | Long Short Term Memory |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
| NB | Naive Bayes |
| NN | Neural Network |
| KTSVM | Kernel Twin Support Vector Machines |
References
- Zhu, K.; Zhang, N.; Ying, S.; Wang, X. Within-project and cross-project software defect prediction based on improved transfer naive bayes algorithm. Comput. Mater. Contin. 2020, 63, 891–910. [Google Scholar]
- Zhu, K.; Ying, S.; Zhang, N.; Zhu, D. Software defect prediction based on enhanced metaheuristic feature selection optimization and a hybrid deep neural network. J. Syst. Softw. 2021, 180, 111026. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance comparison and current challenges of using machine learning techniques in cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Algabri, R.; Choi, M.T. Deep-learning-based indoor human following of mobile robot using color feature. Sensors 2020, 20, 2699. [Google Scholar] [CrossRef]
- Algburi, R.N.A.; Gao, H.; Al-Huda, Z. A new synergy of singular spectrum analysis with a conscious algorithm to detect faults in industrial robotics. Neural Comput. Appl. 2022, 34, 7565–7580. [Google Scholar] [CrossRef]
- Alghodhaifi, H.; Lakshmanan, S. Autonomous vehicle evaluation: A comprehensive survey on modeling and simulation approaches. IEEE Access 2021, 9, 151531–151566. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Yang, Y.; Algburi, R.N.A. Object scale selection of hierarchical image segmentation with deep seeds. IET Image Process. 2021, 15, 191–205. [Google Scholar] [CrossRef]
- Peng, B.; Al-Huda, Z.; Xie, Z.; Wu, X. Multi-scale region composition of hierarchical image segmentation. Multimed. Tools Appl. 2020, 79, 32833–32855. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Khan, W.A.; Sarwar, M.U.; Iqbal, F.; Luo, S. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed. Signal Process. Control 2021, 68, 102726. [Google Scholar] [CrossRef]
- Shaukat, K.; Alam, T.M.; Ahmed, M.; Luo, S.; Hameed, I.A.; Iqbal, M.S.; Li, J.; Iqbal, M.A. A model to enhance governance issues through opinion extraction. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 511–516. [Google Scholar]
- McCabe, T.J. A complexity measure. IEEE Trans. Softw. Eng. 1976, 4, 308–320. [Google Scholar] [CrossRef]
- Halstead, M.H. Elements of Software Science (Operating and Programming Systems Series); Elsevier Science Inc.: New York, NY, USA, 1977. [Google Scholar]
- Chidamber, S.R.; Kemerer, C.F. A metrics suite for object oriented design. IEEE Trans. Softw. Eng. 1994, 20, 476–493. [Google Scholar] [CrossRef] [Green Version]
- Harrison, R.; Counsell, S.J.; Nithi, R.V. An evaluation of the MOOD set of object-oriented software metrics. IEEE Trans. Softw. Eng. 1998, 24, 491–496. [Google Scholar] [CrossRef]
- Jiang, T.; Tan, L.; Kim, S. Personalized defect prediction. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 279–289. [Google Scholar]
- e Abreu, F.B.; Carapuça, R. Candidate metrics for object-oriented software within a taxonomy framework. J. Syst. Softw. 1994, 26, 87–96. [Google Scholar] [CrossRef]
- Elish, K.O.; Elish, M.O. Predicting defect-prone software modules using support vector machines. J. Syst. Softw. 2008, 81, 649–660. [Google Scholar] [CrossRef]
- Wang, T.; Li, W.h. Naive bayes software defect prediction model. In Proceedings of the 2010 International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 10–12 December 2010; pp. 1–4. [Google Scholar]
- Erturk, E.; Sezer, E.A. A comparison of some soft computing methods for software fault prediction. Expert Syst. Appl. 2015, 42, 1872–1879. [Google Scholar] [CrossRef]
- Gayatri, N.; Nickolas, S.; Reddy, A.; Reddy, S.; Nickolas, A. Feature selection using decision tree induction in class level metrics dataset for software defect predictions. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 20–22 October 2010; Volume 1, pp. 124–129. [Google Scholar]
- Wan, H.; Wu, G.; Yu, M.; Yuan, M. Software defect prediction based on cost-sensitive dictionary learning. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 1219–1243. [Google Scholar] [CrossRef]
- Jin, C. Cross-project software defect prediction based on domain adaptation learning and optimization. Expert Syst. Appl. 2021, 171, 114637. [Google Scholar] [CrossRef]
- Wang, S.; Liu, T.; Tan, L. Automatically learning semantic features for defect prediction. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 297–308. [Google Scholar]
- Wang, S.; Liu, T.; Nam, J.; Tan, L. Deep semantic feature learning for software defect prediction. IEEE Trans. Softw. Eng. 2018, 46, 1267–1293. [Google Scholar] [CrossRef]
- Pan, C.; Lu, M.; Xu, B. An empirical study on software defect prediction using codebert model. Appl. Sci. 2021, 11, 4793. [Google Scholar] [CrossRef]
- Pandey, S.K.; Mishra, R.B.; Tripathi, A.K. Machine learning based methods for software fault prediction: A survey. Expert Syst. Appl. 2021, 172, 114595. [Google Scholar] [CrossRef]
- Akimova, E.N.; Bersenev, A.Y.; Deikov, A.A.; Kobylkin, K.S.; Konygin, A.V.; Mezentsev, I.P.; Misilov, V.E. A survey on software defect prediction using deep learning. Mathematics 2021, 9, 1180. [Google Scholar] [CrossRef]
- Catal, C.; Diri, B. A systematic review of software fault prediction studies. Expert Syst. Appl. 2009, 36, 7346–7354. [Google Scholar] [CrossRef]
- Hall, T.; Beecham, S.; Bowes, D.; Gray, D.; Counsell, S. A systematic literature review on fault prediction performance in software engineering. IEEE Trans. Softw. Eng. 2011, 38, 1276–1304. [Google Scholar] [CrossRef]
- Hosseini, S.; Turhan, B.; Gunarathna, D. A systematic literature review and meta-analysis on cross project defect prediction. IEEE Trans. Softw. Eng. 2017, 45, 111–147. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Almomani, M.A.; Adeyemo, V.E.; Al-Tashi, Q.; Mojeed, H.A.; Imam, A.A.; Bajeh, A.O. Impact of feature selection methods on the predictive performance of software defect prediction models: An extensive empirical study. Symmetry 2020, 12, 1147. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, Z.; Jing, X.; Liu, Y. Non-negative sparse-based SemiBoost for software defect prediction. Softw. Test. Verif. Reliab. 2016, 26, 498–515. [Google Scholar] [CrossRef]
- Wu, F.; Jing, X.Y.; Sun, Y.; Sun, J.; Huang, L.; Cui, F.; Sun, Y. Cross-project and within-project semisupervised software defect prediction: A unified approach. IEEE Trans. Reliab. 2018, 67, 581–597. [Google Scholar] [CrossRef]
- Zhang, Z.W.; Jing, X.Y.; Wang, T.J. Label propagation based semi-supervised learning for software defect prediction. Autom. Softw. Eng. 2017, 24, 47–69. [Google Scholar] [CrossRef]
- Hua, W.; Sui, Y.; Wan, Y.; Liu, G.; Xu, G. Fcca: Hybrid code representation for functional clone detection using attention networks. IEEE Trans. Reliab. 2020, 70, 304–318. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Kim, S.; Zimmermann, T.; Pan, K.; James, E., Jr. Automatic identification of bug-introducing changes. In Proceedings of the 21st IEEE/ACM International Conference on Automated Software Engineering (ASE’06), Tokyo, Japan, 18–22 September 2006; pp. 81–90. [Google Scholar]
- Śliwerski, J.; Zimmermann, T.; Zeller, A. When do changes induce fixes? ACM Sigsoft Softw. Eng. Notes 2005, 30, 1–5. [Google Scholar] [CrossRef]
- Malhotra, R. A systematic review of machine learning techniques for software fault prediction. Appl. Soft Comput. 2015, 27, 504–518. [Google Scholar] [CrossRef]
- Li, Z.; Jing, X.Y.; Zhu, X. Progress on approaches to software defect prediction. IET Softw. 2018, 12, 161–175. [Google Scholar] [CrossRef]
- Rathore, S.S.; Kumar, S. A study on software fault prediction techniques. Artif. Intell. Rev. 2019, 51, 255–327. [Google Scholar] [CrossRef]
- Li, N.; Shepperd, M.; Guo, Y. A systematic review of unsupervised learning techniques for software defect prediction. Inf. Softw. Technol. 2020, 122, 106287. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering—A systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A survey of machine learning for big code and naturalness. ACM Comput. Surv. (CSUR) 2018, 51, 1–37. [Google Scholar] [CrossRef]
- Sajnani, H.; Saini, V.; Svajlenko, J.; Roy, C.K.; Lopes, C.V. Sourcerercc: Scaling code clone detection to big-code. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; pp. 1157–1168. [Google Scholar]
- Kamiya, T.; Kusumoto, S.; Inoue, K. CCFinder: A multilinguistic token-based code clone detection system for large scale source code. IEEE Trans. Softw. Eng. 2002, 28, 654–670. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Xu, M. A survey on machine learning techniques for cyber security in the last decade. IEEE Access 2020, 8, 222310–222354. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Chen, S.; Liu, D. Cyber threat detection using machine learning techniques: A performance evaluation perspective. In Proceedings of the 2020 International Conference on Cyber Warfare and Security (ICCWS), Virtual Event, 20–21 October 2020; pp. 1–6. [Google Scholar]
- Algabri, R.; Choi, M.T. Target recovery for robust deep learning-based person following in mobile robots: Online trajectory prediction. Appl. Sci. 2021, 11, 4165. [Google Scholar] [CrossRef]
- Algabri, R.; Choi, M.T. Robust person following under severe indoor illumination changes for mobile robots: Online color-based identification update. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 12–15 October 2021; pp. 1000–1005. [Google Scholar]
- Baxter, I.D.; Yahin, A.; Moura, L.; Sant’Anna, M.; Bier, L. Clone detection using abstract syntax trees. In Proceedings of the Proceedings. International Conference on Software Maintenance (Cat. No. 98CB36272), Bethesda, MD, USA, 20–20 November 1998; pp. 368–377. [Google Scholar]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Wang, K.; Liu, X. A novel neural source code representation based on abstract syntax tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 783–794. [Google Scholar]
- Allen, F.E. Control flow analysis. ACM Sigplan Not. 1970, 5, 1–19. [Google Scholar] [CrossRef]
- Gabel, M.; Jiang, L.; Su, Z. Scalable detection of semantic clones. In Proceedings of the 30th International Conference on Software Engineering, Leipzig, Germany, 10–18 May 2008; pp. 321–330. [Google Scholar]
- Yousefi, J.; Sedaghat, Y.; Rezaee, M. Masking wrong-successor Control Flow Errors employing data redundancy. In Proceedings of the 2015 5th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 29–29 October 2015; pp. 201–205. [Google Scholar]
- Wang, H.; Zhuang, W.; Zhang, X. Software defect prediction based on gated hierarchical LSTMs. IEEE Trans. Reliab. 2021, 70, 711–727. [Google Scholar] [CrossRef]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating sequences from structured representations of code. arXiv 2018, arXiv:1808.01400. [Google Scholar]
- Allamanis, M.; Sutton, C. Mining source code repositories at massive scale using language modeling. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 207–216. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 5110–5121. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2073–2083. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to represent programs with graphs. arXiv 2017, arXiv:1711.00740. [Google Scholar]
- Bryksin, T.; Petukhov, V.; Alexin, I.; Prikhodko, S.; Shpilman, A.; Kovalenko, V.; Povarov, N. Using large-scale anomaly detection on code to improve kotlin compiler. In Proceedings of the 17th International Conference on Mining Software Repositories, Seoul, Korea, 29–30 June 2020; pp. 455–465. [Google Scholar]
- D’Ambros, M.; Lanza, M.; Robbes, R. Evaluating defect prediction approaches: A benchmark and an extensive comparison. Empir. Softw. Eng. 2012, 17, 531–577. [Google Scholar] [CrossRef]
- Kamei, Y.; Shihab, E.; Adams, B.; Hassan, A.E.; Mockus, A.; Sinha, A.; Ubayashi, N. A large-scale empirical study of just-in-time quality assurance. IEEE Trans. Softw. Eng. 2012, 39, 757–773. [Google Scholar] [CrossRef]
- Wu, R.; Zhang, H.; Kim, S.; Cheung, S.C. Relink: Recovering links between bugs and changes. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 15–25. [Google Scholar]
- Yatish, S.; Jiarpakdee, J.; Thongtanunam, P.; Tantithamthavorn, C. Mining software defects: Should we consider affected releases? In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 654–665. [Google Scholar]
- Jureczko, M.; Madeyski, L. Towards identifying software project clusters with regard to defect prediction. In Proceedings of the 6th International Conference on Predictive Models in Software Engineering, Timişoara, Romania, 12–13 September 2010; pp. 1–10. [Google Scholar]
- Peters, F.; Menzies, T. Privacy and utility for defect prediction: Experiments with morph. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 189–199. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. Graphcodebert: Pre-training code representations with data flow. arXiv 2020, arXiv:2009.08366. [Google Scholar]
- Phan, A.V.; Le Nguyen, M.; Bui, L.T. Convolutional neural networks over control flow graphs for software defect prediction. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 45–52. [Google Scholar]
- Li, J.; He, P.; Zhu, J.; Lyu, M.R. Software defect prediction via convolutional neural network. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security (QRS), Prague, Czech Republic, 25–29 July 2017; pp. 318–328. [Google Scholar]
- Meilong, S.; He, P.; Xiao, H.; Li, H.; Zeng, C. An approach to semantic and structural features learning for software defect prediction. Math. Probl. Eng. 2020, 2020, 6038619. [Google Scholar] [CrossRef]
- Dam, H.K.; Pham, T.; Ng, S.W.; Tran, T.; Grundy, J.; Ghose, A.; Kim, T.; Kim, C.J. Lessons learned from using a deep tree-based model for software defect prediction in practice. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 46–57. [Google Scholar]
- Majd, A.; Vahidi-Asl, M.; Khalilian, A.; Poorsarvi-Tehrani, P.; Haghighi, H. SLDeep: Statement-level software defect prediction using deep-learning model on static code features. Expert Syst. Appl. 2020, 147, 113156. [Google Scholar] [CrossRef]
- Deng, J.; Lu, L.; Qiu, S. Software defect prediction via LSTM. IET Softw. 2020, 14, 443–450. [Google Scholar] [CrossRef]
- Liang, H.; Yu, Y.; Jiang, L.; Xie, Z. Seml: A semantic LSTM model for software defect prediction. IEEE Access 2019, 7, 83812–83824. [Google Scholar] [CrossRef]
- Lin, J.; Lu, L. Semantic feature learning via dual sequences for defect prediction. IEEE Access 2021, 9, 13112–13124. [Google Scholar] [CrossRef]
- Fan, G.; Diao, X.; Yu, H.; Yang, K.; Chen, L. Software defect prediction via attention-based recurrent neural network. Sci. Program. 2019, 2019, 6230953. [Google Scholar] [CrossRef]
- Xu, J.; Wang, F.; Ai, J. Defect prediction with semantics and context features of codes based on graph representation learning. IEEE Trans. Reliab. 2020, 70, 613–625. [Google Scholar] [CrossRef]
- Uddin, M.N.; Li, B.; Ali, Z.; Kefalas, P.; Khan, I.; Zada, I. Software defect prediction employing BiLSTM and BERT-based semantic feature. Soft Comput. 2022, 26, 7877–7891. [Google Scholar] [CrossRef]
- Lessmann, S.; Baesens, B.; Mues, C.; Pietsch, S. Benchmarking classification models for software defect prediction: A proposed framework and novel findings. IEEE Trans. Softw. Eng. 2008, 34, 485–496. [Google Scholar] [CrossRef]
- Mende, T.; Koschke, R. Effort-aware defect prediction models. In Proceedings of the 2010 14th European Conference on Software Maintenance and Reengineering, Madrid, Spain, 15–18 March 2010; pp. 107–116. [Google Scholar]
- Tufano, M.; Watson, C.; Bavota, G.; Di Penta, M.; White, M.; Poshyvanyk, D. Deep learning similarities from different representations of source code. In Proceedings of the 2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR), Gothenburg, Sweden, 27 May–3 June 2018; pp. 542–553. [Google Scholar]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Thornton, A.; Lee, P. Publication bias in meta-analysis: Its causes and consequences. J. Clin. Epidemiol. 2000, 53, 207–216. [Google Scholar] [CrossRef]
- Troya, J.; Moreno, N.; Bertoa, M.F.; Vallecillo, A. Uncertainty representation in software models: A survey. Softw. Syst. Model. 2021, 20, 1183–1213. [Google Scholar] [CrossRef]


| Q-No. | Standard Questions |
|---|---|
| Q-1 | Is the goal of the study clearly defined? |
| Q-2 | Is every factor and variable sufficiently stated? |
| Q-3 | Are the context and scope of the study accurately defined? |
| Q-4 | Is the size of the dataset appropriate? |
| Q-5 | Is the proposed approach well-described and supported by sufficient experiments? |
| Q-6 | Are suitable performance measures selected? |
| Q-7 | Are the study processes adequately documented? |
| Q-8 | Are comparative studies of semantic feature-based SDP and other traditional methods available? |
| Q-9 | Does the study contribute to the literature in this field? |
| Q-10 | Are the significant results defined clearly in terms of accuracy, reliability, and validity? |
| Dataset | Language | Size | Remarks |
|---|---|---|---|
| Datasets for [58] | Java | 16M examples in 9500 projects. | Their model used the AST technique to represent a code fragment as a sequence of compositional paths |
| GitHub Corpus [59] | Java | 11,000 projects | It is a giga-token probabilistic language based on 352 mega Java source code. |
| Github Bigquery repository [60] | Python | 7.4M files | They developed an open-sourced the benchmark that includes five classifiers and one task for program repair using a sample of 7.4M deduplicated Python scripts taken from GitHub. |
| CodeNN Dataset [61] | C# | 66,015 fragments | They present an entire computation method for building a framework for representing source code. |
| Dataset for [62] | C# | 2.9 M lines of 29 projects | They collected a dataset for the VARMISUSE task from open-source C# projects on GitHub. We picked the top-starred (non-fork) projects on GitHub to select projects. |
| Dataset for [63] | Kotlin | 932,548 files, 47,751 reports, and 4,044,790 functions. | Their approach depends on anomaly detection to source code and bytecode. They describe defective code as a segment that differs from standard code is written in a specific programming language. |
| Dataset | Avg. Instances | Avg. Defect-Prone% | Remarks |
|---|---|---|---|
| AEEEM | 1074 | 19.40 | This dataset was created by D’Ambros et al. [64] to implement class-level defect prediction. |
| NASA MDP | 1585 | 17.67 | NASA MDP came from National Aeronautics and Space Administration (NASA) mission-critical software projects. There are officially 13 data sets in the NASA MDP repository. |
| Kamei | 37,902 | 21.11 | Kamei dataset was published by Kamei et al. [65], Kamei dataset was created from six open-source software projects (i.e., Columba, Bugzilla, Mozilla, JDT, Eclipse, and PostgreSQL), and its goal is to develop a risk model for modification. |
| ReLink | 217 | 37.79 | Wu et al. [66] created ReLink dataset from three projects: Safe, Apache, and ZXing, each with 26 metrics. |
| SOFTLAB | 86 | 15.20 | SOFTLAB came from a Turkish technology company that specialized in domestic appliance applications. SOFTLAB contains five projects (ar1, ar3, ar4, ar5, ar6), including 29 static code features. |
| JIRA | 1483 | 14.01 | Yatish et al. [67] have created a new repository for defect datasets called JIRA. JIRA dataset is a collection of models from nine open-source systems. |
| PROMISE | 499 | 18.52 | The PROMISE dataset was created by Jureczko [68], which contains the characteristics of most different projects. |
| MORPH | 338 | 24 | The MORPH group was presented by Peters et al. [69], which contains defect data sets from various open-source programs utilized in a study on the issue of data privacy in defect prediction. |
| Studies | Year | DL Methods | Code Representation | Evaluation Metrics | Pros | Cons | Performance | Limitations |
|---|---|---|---|---|---|---|---|---|
| Wang et al. [23] | 2016 | DBN | AST | F1 score | The same DBN methodology can be applied to various data types and applications. | DBN models require massive data to execute the better performance. | The study proposed using a powerful representation-learning technique and DL to automatically learn the semantic features from source code to predict software defects. | Their experiments have been performed on java projects needed to test them on other software projects. |
| Wang et al. [24] | 2018 | DBN | AST | F1 score and PofB20 | – | – | It is the extension of Wang et al. [23] to demonstrate the viability and efficiency of predicting defects using semantic representation from source code. | Their outputs were highly efficient; they only needed to apply them to real projects. |
| Phan et al. [74] | 2017 | CNN | CFGs | AUC | Easy to improve the prediction model through adding a Conv layer for pooling (like cbow). | CNNs typically operate much more slowly Because of procedures like max pool. | In the study, the authors suggested using deep neural networks and accurate graphs representing instruction execution patterns to detect defect features automatically. | Comparative analysis is limited; their results need to be compared with the findings of other approaches. |
| Li et al. [75] | 2017 | CNN | AST | F1 score | – | – | They built a prediction model using CNN to learn semantic information from the program’s AST. | Results must be compared to those obtained by other methods of AST node sequence. |
| Meilong et al. [76] | 2020 | CNN | AST | F1 score | – | – | This study explored contextual data based on AST sequences to highlight defect features. | They need to conduct more projects in many languages to verify the generalizability of their study. |
| Dam et al. [77] | 2019 | LSTM | AST | F1 score and AUC | LSTM is an excellent tool for any task requiringa sequence and text generation. | Training LSTM model requires more memory, and they can overfit easily. | They built a prediction system upon LSTM architecture to capture the source code’s syntax and semantics representation. | The results are limited; various datasets must be used to test the results. The findings must also be compared to other approaches. |
| Majd et al. [78] | 2020 | LSTM | Statement-Level (SL) features | F1 score and Accuracy | – | – | They developed effective SDP models based on statement-level. Results were evaluated on more than 100,000 C++/C programs. | Additional metrics for other programming languages, such as Java, Python, or Kotlin, are required. |
| Deng et al. [79] | 2020 | LSTM | AST | F1 score | – | – | They built a prediction model to automatically learn semantic information from the program’s ASTs using LSTM. | Results must be compared to those obtained by other methods of AST node sequence. |
| Liang et al. [80] | 2019 | LSTM | AST | F1 score | – | – | The study proposed to express semantic features using word2vec and used LSTM as the predictor to enhance the performance of the SDP model. | More semantic features about programs, such as data flow details, should be captured as features to validate their work. |
| Lin and Lu [81] | 2021 | BiLSTM | AST | F1 score, AUC and MCC | BiLSTM is better for solving the fixed sequence to sequence prediction problem with varying input and output lengths. | BiLSTM is costly because it uses double LSTM cells. | A BiLSTM-based network was used to extract token sequences from the AST and train the proposed model by learning contextual features. | There is a need for additional metrics for programming languages such as Java, Python, Kotlin, etc. |
| Wang et al. [57] | 2021 | GH-LSTM | AST | F1 score and PofB20 | It is a good choice for source code analysis tasks such as named entity recognition. | It is difficult to train more accurately. | A defect prediction model based on gated hierar-chical LSTM (GH-LSTM) has been proposed, which uses the semantic features extracted from the word embeddings of AST of source code files. | A comparison study is constrained; it is necessary to contrast their results with other approaches’ results. |
| Fan et al. [82] | 2019 | ARNN | AST | F1 score and AUC | While creating a model, it accurately captures the relationships between the text’s words. | The vanishing and gradient problem affects deep RNNs, negatively affecting prediction performance. | An attention-based RNN has been proposed to predict software defects based on semantic features extracted from the source code’s AST. | Experimental work should be conducted on a wide range of projects, including both personal and companyrelated projects. |
| Xu et al. [83] | 2020 | GNN | AST | F1 score, AUC, and Accuracy | GNN is suitable for training models on any dataset that contains pairwise relationships and input data. | GNNs are not noise-resistant in graph-based data | The GNN has been constructed to predict the software defects using the contextual information extracted from the AST. | To validate their study, more semantic program features, like data flow information, should be included as features. |
| Uddin et al. [84] | 2022 | BiLSTM and BERT | Full-token and AST | F1 score | BERT models, which are trained on a big corpus, make it easier for more precise and smaller jobs. | In BERT models, training is slow because it is big and requires updating a lot of weights. | The suggested approach employs a BERT model to capture the semantic features of code to predict software defects. | Their study lacks comparison with other domain adaptation methods for SDP. |
| Model | Precision | Recall | F-Measure |
|---|---|---|---|
| DBN | 0.534 | 0.816 | 0.645 |
| DP-DBN | 0.624 | 0.696 | 0.658 |
| DP-CNN | 0.521 | 0.733 | 0.609 |
| CNN | 0.534 | 0.759 | 0.627 |
| LSTM | 0.569 | 0.896 | 0.696 |
| SLDEEP LSTM | 0.609 | 0.716 | 0.658 |
| Seml LSTM | 0.589 | 0.596 | 0.592 |
| DP-LSTM | 0.489 | 0.558 | 0.521 |
| BiLSTM | 0.581 | 0.733 | 0.648 |
| GH-LSTM | 0.561 | 0.673 | 0.612 |
| ARNN | 0.538 | 0.618 | 0.575 |
| GNN | 0.639 | 0.713 | 0.673 |
| BERT | 0.769 | 0.625 | 0.689 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdu, A.; Zhai, Z.; Algabri, R.; Abdo, H.A.; Hamad, K.; Al-antari, M.A. Deep Learning-Based Software Defect Prediction via Semantic Key Features of Source Code—Systematic Survey. Mathematics 2022, 10, 3120. https://doi.org/10.3390/math10173120
Abdu A, Zhai Z, Algabri R, Abdo HA, Hamad K, Al-antari MA. Deep Learning-Based Software Defect Prediction via Semantic Key Features of Source Code—Systematic Survey. Mathematics. 2022; 10(17):3120. https://doi.org/10.3390/math10173120
Chicago/Turabian StyleAbdu, Ahmed, Zhengjun Zhai, Redhwan Algabri, Hakim A. Abdo, Kotiba Hamad, and Mugahed A. Al-antari. 2022. "Deep Learning-Based Software Defect Prediction via Semantic Key Features of Source Code—Systematic Survey" Mathematics 10, no. 17: 3120. https://doi.org/10.3390/math10173120
APA StyleAbdu, A., Zhai, Z., Algabri, R., Abdo, H. A., Hamad, K., & Al-antari, M. A. (2022). Deep Learning-Based Software Defect Prediction via Semantic Key Features of Source Code—Systematic Survey. Mathematics, 10(17), 3120. https://doi.org/10.3390/math10173120