
Exploring Online Activities to Predict the Final Grade of Student
 , , , ,
, , , ,
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
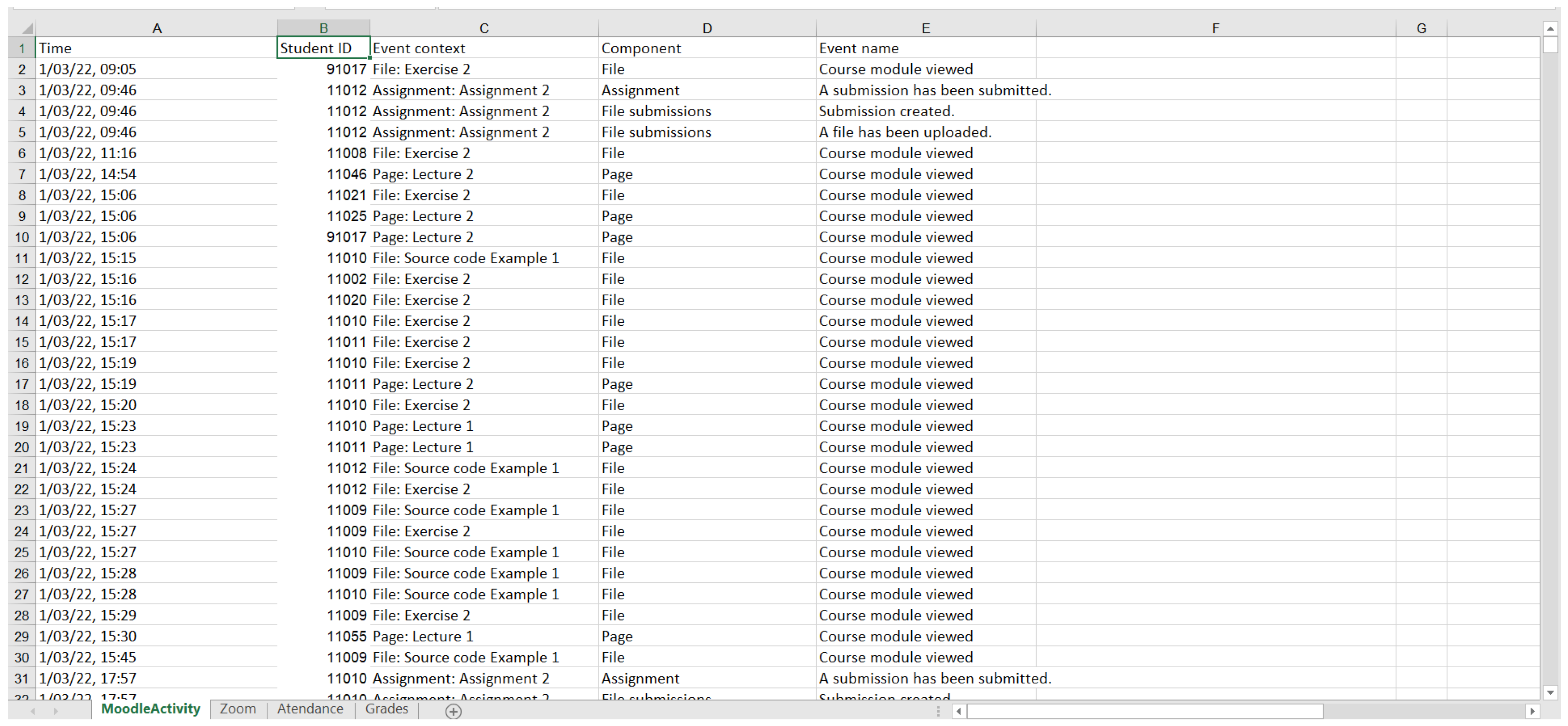
3.1. Dataset
3.2. Methodology
4. Results
4.1. Univariate Analysis
4.2. Bivariate Analysis
4.3. Regression Analysis
4.4. Machine Learning Algorithms
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yamao, E.; Saavedra, L.; Pérez, R.; Hurtado, V. Prediction of academic performance using data mining in first year students of peruvian university. Campus 2018, 23, 151–160. [Google Scholar] [CrossRef]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learn. Environ. 2022, 9, 11. [Google Scholar] [CrossRef]
- Daza, A.; Guerra, C.; Cervera, N.; Burgos, E. Predicting Academic Performance through Data Mining: A Systematic Literature. TEM J. 2022, 11, 939–949. [Google Scholar] [CrossRef]
- Calisir, F.; Basak, E.; Comertoglu, S. Predicting academic performance of master’s students in engineering management. Coll. Stud. J. 2016, 50, 501–513. [Google Scholar]
- Rodríguez, Á.P.A.; Arenas, D.A.M. Programas de intervención para Estudiantes Universitarios con bajo rendimiento académico. Inf. Psicológicos 2016, 16, 13–34. [Google Scholar] [CrossRef]
- York, T.T.; Gibson, C.; Rankin, S. Defining and measuring academic success. Pract. Assess. Res. Eval. 2015, 20, 2. [Google Scholar]
- Shahiri, A.M.; Husain, W. A review on predicting student’s performance using data mining techniques. Procedia Comput. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef] [Green Version]
- Gunawan, H. Catherine: Information Systems Students’ Study Performance Prediction Using Data Mining Approach. In Proceedings of the 2019 Fourth International Conference on Informatics and Computing (ICIC), Semarang, Indonesia, 16–17 October 2019. [Google Scholar] [CrossRef]
- Bin Roslan, M.H.; Chen, C.J. Educational Data Mining for Student Performance Prediction: A Systematic Literature Review (2015–2021). Int. J. Emerg. Technol. Learn. 2022, 17, 147–179. [Google Scholar] [CrossRef]
- Ibrahim, Z.; Rusli, D. Predicting students academic performance: Comparing artificial neural network, decision tree and linear regression. In Proceedings of the 21st Annual SAS Malaysia Forum, Kuala Lumpur, Malaysia, 5 September 2007. [Google Scholar]
- Bayer, J.; Bydzovská, H.; Géryk, J.; Obšívač, T.; Popelínský, L. Predicting dropout from social behaviour of students. In Proceedings of the International Conference on Educational Data Mining, Chania, Greece, 19–21 June 2012; pp. 103–109. [Google Scholar]
- Xiao, W.; Ji, P.; Hu, J. A survey on educational data mining methods used for predicting students’ performance. Eng. Rep. 2022, 4, e12482. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Romero, C.; Ventura, S. Data mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Chalaris, M.; Gritzalis, S.; Maragoudakis, M.; Sgouropoulou, C.; Tsolakidis, A. Improving quality of educational processes providing new knowledge using data mining techniques. Procedia-Soc. Behav. Sci. 2014, 147, 390–397. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Zhang, M.; Fan, J.; Sharma, A.; Kukkar, A. Data mining applications in university information management system development. J. Intell. Syst. 2022, 31, 207–220. [Google Scholar] [CrossRef]
- Amala Jayanthi, M.; Shanthi, I.E. Role of Educational Data Mining in Student Learning Processes with Sentiment Analysis: A Survey. In Research Anthology on Interventions in Student Behavior and Misconduct; Management Association, Ed.; IGI Global: Hershey, PA, USA, 2022; pp. 412–427. [Google Scholar] [CrossRef]
- Padhy, N.; Mishra, D.; Panigrahi, R. The survey of data mining applications and feature scope. arXiv 2022, arXiv:1211.5723. [Google Scholar] [CrossRef]
- Goyal, M.; Vohra, R. Applications of data mining in higher education. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 113. [Google Scholar]
- Zhang, Y.; Lu, W.-X.; Guo, J.-Y.; Zhao, H.-Q.; Yang, Q.-C.; Chen, M. Geo-environmental impact assessment and management information system for the mining area, northeast China. Environ Earth Sci. 2015, 74, 7173–7185. [Google Scholar] [CrossRef]
- Vora, D.R.; Iyer, K. EDM–survey of performance factors and algorithms applied. Int. J. Eng. Technol. 2018, 7, 93–97. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 821. [Google Scholar]
- Sakurai, Y.; Tsuruta, S.; Knauf, R. Success chances estimation of university curricula based on educational history, self-estimated intellectual traits and vocational ambitions. In Proceedings of the 2011 IEEE 11th International Conference on Advanced Learning Technologies, Athens, GA, USA, 6–8 July 2011; pp. 476–478. [Google Scholar]
- Carmona, C.; Castillo, G.; Millán, E. Discovering student preferences in e-learning. In Proceedings of the International Workshop on Applying Data Mining in E-Learning, Crete, Greece, 18 September 2007; pp. 33–42. [Google Scholar]
- El Mourabit, I.; Jai-Andaloussi, S.; Abghour, N. Educational Data Mining Techniques for Detecting Undesirable Students’ Behaviors and Predicting Students’ Performance: A Comparative Study. In Advances on Smart and Soft Computing. Advances in Intelligent Systems and Computing; Saeed, F., Al-Hadhrami, T., Mohammed, E., Al-Sarem, M., Eds.; Springer: Singapore, 2022; Volume 1399. [Google Scholar] [CrossRef]
- Juhaňák, L.; Zounek, J.; Rohlíková, L. Using process mining to analyze students’ quiz-taking behavior patterns in a learning management system. Comput. Hum. Behav. 2019, 92, 496–506. [Google Scholar] [CrossRef]
- Ben-Zadok, G.; Hershkovitz, A.; Mintz, E.; Nachmias, R. Examining online learning processes based on log files analysis: A case study. In Proceedings of the 5th International Conference on Multimedia and ICT in Education (m-ICTE’09), Lisbon, Portugal, 20 April 2009. [Google Scholar]
- Yadav, S.K.; Bharadwaj, B.; Pal, S. Mining Education data to predict student’s retention: A comparative study. arXiv 2012, arXiv:1203.2987. [Google Scholar]
- Juan, A.A.; Daradoumis, T.; Faulin, J.; Xhafa, F. A data analysis model based on control charts to monitor online learning processes. Int. J. Bus. Intell. Data Min. 2009, 4, 159–174. [Google Scholar] [CrossRef]
- Bernacki, M.L.; Chavez, M.M.; Uesbeck, P.M. Predicting achievement and providing support before STEM majors begin to fail. Comput. Educ. 2020, 158, 103999. [Google Scholar] [CrossRef]
- Araka, E.; Oboko, R.; Maina, E.; Gitonga, R. Using Educational Data Mining Techniques to Identify Profiles in Self-Regulated Learning: An Empirical Evaluation. Int. Rev. Res. Open Distrib. Learn. 2022, 23, 131–162. [Google Scholar] [CrossRef]
- Araka, E.; Oboko, R.; Maina, E.; Gitonga, R.K. A Conceptual Educational Data Mining Model for Supporting Self-Regulated Learning in Online Learning Environments. In Handbook of Research on Equity in Computer Science in P-16 Education; Keengwe, J., Tran, Y., Eds.; IGI Global: Hershey, PA, USA, 2021; pp. 278–292. [Google Scholar] [CrossRef]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, S.M.R. Student Engagement Predictions in an e-Learning System and Their Impact on Student Course Assessment Scores. Comput. Intell. Neurosci. 2018, 2018, 6347186. [Google Scholar] [CrossRef] [Green Version]
- Baradwaj, B.K.; Pal, S. Mining educational data to analyze students’ performance. arXiv 2012, arXiv:1201.3417. [Google Scholar]
- Yadav, S.K.; Bharadwaj, B.; Pal, S. Data mining applications: A comparative study for predicting student’s performance. arXiv 2012, arXiv:1202.4815. [Google Scholar]
- Arora, R.K.; Badal, D. Mining association rules to improve academic performance. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 428–433. [Google Scholar]
- Kovacic, Z. Early prediction of student success: Mining students’ enrolment data. In Proceedings of the Informing Science & IT Education Conference (InSITE) 2010, Washington, DC, USA, 14–17 February 2010. [Google Scholar]
- Tjandra, E.; Kusumawardani, S.S.; Ferdiana, R. Student performance prediction in higher education: A comprehensive review. AIP Conf. Proc. 2022, 2470, 050005. [Google Scholar] [CrossRef]
- Priya, K.S.; Kumar, A.S. Improving the student’s performance using educational data mining. Int. J. Adv. Netw. Appl. 2013, 4, 1806. [Google Scholar]
- Abu Tair, M.M.; El-Halees, A.M. Mining educational data to improve students’ performance: A case study. Int. J. Inf. Commun. Technol. Res. 2012, 2, 2. [Google Scholar]
- Algarni, A. Data mining in education. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 456–461. [Google Scholar] [CrossRef] [Green Version]
- Pandey, U.K.; Pal, S. Data Mining: A prediction of performer or underperformer using classification. arXiv 2011, arXiv:1104.4163. [Google Scholar]
- Ahmed, A.B.E.D.; Elaraby, I.S. Data mining: A prediction for student’s performance using classification method. World J. Comput. Appl. Technol. 2014, 2, 43–47. [Google Scholar] [CrossRef]
- Bhise, R.B.; Thorat, S.S.; Supekar, A.K. Importance of data mining in higher education system. IOSR J. Humanit. Soc. Sci. (IOSR-JHSS) 2013, 6, 18–21. [Google Scholar]
- Ramesh, V.; Parkavi, P.; Ramar, K. Predicting student performance: A statistical and data mining approach. Int. J. Comput. Appl. 2013, 63, 8. [Google Scholar] [CrossRef]
- Adekitan, A.I.; Salau, O. The impact of engineering students’ performance in the first three years on their graduation result using educational data mining. Heliyon 2019, 5, e01250. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaur, H.; Bathla, E.G. Student performance prediction using educational data mining techniques. Int. J. Future Revolut. Comput. Sci. Commun. Eng. 2018, 4, 93–97. [Google Scholar]
- Nichat, A.A.; Raut, D.A.B. Predicting and Analysis of Student Performance Using Decision Tree Technique. Int. J. 2017, 5, 7319–7328. [Google Scholar]
- Saranya, S.; Ayyappan, R.; Kumar, N. Student progress analysis and educational institutional growth prognosis using data mining. Int. J. Eng. Sci. Res. Technol. 2014, 3, 1982–1987. [Google Scholar]
- Archer, E.; Chetty, Y.B.; Prinsloo, P. Benchmarking the habits and behaviours of successful students: A case study of academic-business collaboration. Int. Rev. Res. Open Distrib. Learn. 2014, 15, 62–83. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zhang, X. Prediction and analysis for students’ marks based on decision tree algorithm. In Proceedings of the 2010 Third International Conference on Intelligent Networks and Intelligent Systems, Shenyang, China, 1–3 November 2010; pp. 338–341. [Google Scholar]
- Trakunphutthirak, R.; Lee, V.C.S. Application of Educational Data Mining Approach for Student Academic Performance Prediction Using Progressive Temporal Data. J. Educ. Comput. Res. 2022, 60, 742–776. [Google Scholar] [CrossRef]
- Hamoud, A.; Hashim, A.S.; Awadh, W.A. Predicting student performance in higher education institutions using decision tree analysis. Int. J. Interact. Multimed. Artif. Intell. 2018, 5, 26–31. [Google Scholar] [CrossRef] [Green Version]
- Khan, I.; Al Sadiri, A.; Ahmad, A.R.; Jabeur, N. Tracking student performance in introductory programming by means of machine learning. In Proceedings of the 2019 4th Mec International Conference on Big Data and Smart City (Icbdsc), Muscat, Oman, 15–16 January 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Cruz, M.E.L.T.; Encarnacıon, R.E. Analysis and Prediction of Students’ Academic Performance and Employability Using Data Mining Techniques: A Research Travelogue. Eurasia Proc. Sci. Technol. Eng. Math. 2021, 16, 117–131. [Google Scholar] [CrossRef]
- Hardman, J.; Paucar-Caceres, A.; Fielding, A. Predicting students’ progression in higher education by using the random forest algorithm. Syst. Res. Behav. Sci. 2013, 30, 194–203. [Google Scholar] [CrossRef]
- Kaur, P.; Singh, M.; Josan, G.S. Classifcation and prediction based data mining algorithms to predict slow learners in education sector. Procedia Comput. Sci. 2015, 57, 500–508. [Google Scholar] [CrossRef] [Green Version]
- Waheed, H.; Hassan, S.U.; Aljohani, N.R.; Hardman, J.; Alelyani, S.; Nawaz, R. Predicting academic performance of students from VLE big data using deep learning models. In Computers in Human Behavior; Elsevier: Amsterdam, The Netherlands, 2020; Volume 104, p. 106189. [Google Scholar] [CrossRef] [Green Version]
- Admass, W.S. Review on Predicting Student Academic Performance using Data Mining Classification Algorithm. J. Comput. Eng. Inf. Technol. 2021, 10, 11. [Google Scholar]
- Zhang, Y.; Yun, Y.; An, R.; Cui, J.; Dai, H.; Shang, X. Educational Data Mining Techniques for Student Performance Prediction: Method Review and Comparison Analysis. Front. Psychol. 2021, 12, 698490. [Google Scholar] [CrossRef]
- Sweeney, M.; Lester, J.; Rangwala, H. Next-term student grade prediction. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 970–975. [Google Scholar]
- Polyzou, A.; Karypis, G. Grade prediction with models specific to students and courses. Int. J. Data Sci. Anal. 2016, 2, 159–171. [Google Scholar] [CrossRef] [Green Version]
- Cakmak, A. Predicting student success in courses via collaborative filtering. Int. J. Intell. Syst. Appl. Eng. 2017, 5, 10–17. [Google Scholar] [CrossRef] [Green Version]
- Hu, Q.; Polyzou, A.; Karypis, G.; Rangwala, H. Enriching course-specific regression models with content features for grade prediction. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 504–513. [Google Scholar]
- Morsy, S.; Karypis, G. Cumulative knowledge-based regression models for next-term grade prediction. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 552–560. [Google Scholar]
- Mishra, T.; Kumar, D.; Gupta, S. Mining Students’ Data for Prediction Performance. In Proceedings of the Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 8–9 February 2014; pp. 255–262. [Google Scholar]
- Gray, G.; McGuinness, C.; Owende, P. An application of classification models to predict learner progression in tertiary education. In Proceedings of the Advance Computing Conference (IACC), 2014 IEEE International, Gurgaon, India, 21–22 February 2014; pp. 549–554. [Google Scholar]
- Ljubobratović, D.; Matetić, M. Using LMS Activity Logs to Predict Student Failure with Random Forest Algorithm. Future Inf. Sci. 2019, 113, 113–119. [Google Scholar] [CrossRef]
- Bhusal, A. Predicting Student’s Performance Through Data Mining. arXiv 2021, arXiv:2112.01247. [Google Scholar]
- Moreno-Ger, P.; Burgos, D. Machine Learning and Student Activity to Predict Academic Grades in Online Settings in Latam. In Radical Solutions for Digital Transformation in Latin American Universities; Springer: Singapore, 2021; pp. 243–257. [Google Scholar]
- Quinn, R.J.; Gray, G. Prediction of student academic performance using Moodle data from a Further Education setting. Ir. J. Technol. Enhanc. Learn. 2020, 5, 1. [Google Scholar] [CrossRef] [Green Version]
- Mueen, A.; Zafar, B.; Manzoor, U. Modeling and Predicting Students’ Academic Performance Using Data Mining Techniques. Int. J. Mod. Educ. Comput. Sci. 2016, 8, 36–42. [Google Scholar] [CrossRef] [Green Version]
- Gadhavi, M.; Patel, C. Student final grade prediction based on linear regression. Indian J. Comput. Sci. Eng. 2017, 8, 274–279. [Google Scholar]
- Alhassan, A.; Zafar, B.; Mueen, A. Predict students’ academic performance based on their assessment grades and online activity data. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 4. [Google Scholar] [CrossRef]
- Qiu, F.; Zhang, G.; Sheng, X.; Jiang, L.; Zhu, L.; Xiang, Q.; Chen, P.K. Predicting students’ performance in e-learning using learning process and behaviour data. Sci. Rep. 2020, 12, 453. [Google Scholar] [CrossRef]
- Mozahem, N.A. Using learning management system activity data to predict student performance in face-to-face courses. Int. J. Mob. Blended Learn. 2020, 12, 20–31. [Google Scholar] [CrossRef]
- Hussain, M.; Hussain, S.; Zhang, W.; Zhu, W.; Theodorou, P.; Abidi, S.M.R. Mining moodle data to detect the inactive and low-performance students during the moodle course. In Proceedings of the 2nd International Conference on Big Data Research, New York, NJ, USA, 27–29 October 2018; pp. 133–140. [Google Scholar]
- Meier, Y.; Xu, J.; Atan, O.; Van der Schaar, M. Predicting grades. IEEE Trans. Signal Process. 2015, 64, 959–972. [Google Scholar] [CrossRef] [Green Version]
- Okubo, F.; Yamashita, T.; Shimada, A.; Ogata, H. A neural network approach for students’ performance prediction. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, New York, NJ, USA, 13–17 March 2017; pp. 598–599. [Google Scholar]
- Xu, B.; Yang, D. Motivation classification and grade prediction for MOOCs learners. Comput. Intell. Neurosci. 2016, 2016, 4. [Google Scholar] [CrossRef] [Green Version]
- Mouri, K.; Okubo, F.; Shimada, A.; Ogata, H. Bayesian network for predicting students’ final grade using e-book logs in university education. In Proceedings of the 2016 IEEE 16th International Conference on Advanced Learning Technologies (ICALT), Austin, TX, USA, 25–28 July 2016; pp. 85–89. [Google Scholar]
- Luo, Y.; Chen, N.; Han, X. Students’ Online Behavior Patterns Impact on Final Grades Prediction in Blended Courses. In Proceedings of the 2020 Ninth International Conference of Educational Innovation through Technology (EITT), Porto, Portugal, 13–17 December 2020; pp. 154–158. [Google Scholar]
- Kumar, M.; Singh, A.J.; Handa, D. Literature survey on student’s performance prediction in education using data mining techniques. Int. J. Educ. Manag. Eng. 2017, 7, 40–49. [Google Scholar] [CrossRef]
- Alhothali, A.; Albsisi, M.; Assalahi, H.; Aldosemani, T. Predicting Student Outcomes in Online Courses Using Machine Learning Techniques: A Review. Sustainability 2022, 14, 6199. [Google Scholar] [CrossRef]
- Nabil, A.; Seyam, M.; Abou-Elfetouh, A. Prediction of students’ academic performance based on courses’ grades using deep neural networks. IEEE Access 2021, 9, 140731–140746. [Google Scholar] [CrossRef]
- Desuky, A.S.; Hussain, S. An improved hybrid approach for handling class imbalance problem. Arab. J. Sci. Eng. 2021, 46, 3853–3864. [Google Scholar] [CrossRef] [PubMed]
- Gaber, T.; Hassanien, A.E.; El-Bendary, N.; Dey, N. (Eds.) The 1st International Conference on Advanced Intelligent System and Informatics (AISI2015), November 28–30, 2015, Beni Suef, Egypt; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Akay, M.F. Support vector machines combined with feature selection for breast cancer diagnosis. Expert Syst. Appl. 2019, 36, 3240–3247. [Google Scholar] [CrossRef]
- Desuky, A.S.; Elbarawy, Y.M.; Kausar, S.; Omar, A.H.; Hussain, S. Single-Point Crossover and Jellyfish Optimization for Handling Imbalanced Data Classification Problem. IEEE Access 2022, 10, 11730–11749. [Google Scholar] [CrossRef]
- Aydoğdu, Ş. Predicting student final performance using artificial neural networks in online learning environments. Educ. Inf. Technol. 2020, 25, 1913–1927. [Google Scholar] [CrossRef]
- Wojciechowski, A.; Palmer, L.B. Individual student characteristics: Can any be predictors of success in online classes. Online J. Distance Learn. Adm. 2005, 8, 13. [Google Scholar]
- Jo, I.H.; Yu, T.; Lee, H.; Kim, Y. Relations between student online learning behavior and academic achievement in higher education: A learning analytics approach. In Emerging Issues in Smart Learning; Springer: Berlin/Heidelberg, Germany, 2015; pp. 275–287. [Google Scholar]
- Alonso, J.M.; Casalino, G. Explainable artificial intelligence for human-centric data analysis in virtual learning environments. In International Workshop on Higher Education Learning Methodologies and Technologies Online; Springer: Berlin/Heidelberg, Germany, 2019; pp. 125–138. [Google Scholar]
- Hao, J.; Gan, J.; Zhu, L. MOOC performance prediction and personal performance improvement via Bayesian network. Educ. Inf. Technol. 2022, 27, 7303–7326. [Google Scholar] [CrossRef]
- Karimi, H.; Huang, J.; Derr, T. A deep model for predicting online course performance. Cse Msu Educ. 2014, 192, 302. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute/s | Description |
|---|---|
| GRADE | Final semester mark obtained in the “Object-oriented programming” course—Fail (2), Satisfactory (3), Good (4), Very Good (5), and Excellent (6) |
| LEC1-LECT8 | Eight attributes indicating whether the student has read each lecture or not (Lecture 1–Lecture 8) |
| ASSIGN1-ASSIGN8 | Eight attributes indicating whether the student has submitted a task for self-assessment (Assignment 1–Assignment 8) |
| CODE1-CODE8 | Eight attributes indicating whether the student has read each programming code or not (Source code 1–Source code 8) |
| EXER1-EXER8 | Eight attributes indicating whether the student has read each exercise or not (Exercise 1–Exercise 8) |
| ATTEND1-ATTEND13 | Eight attributes indicating whether the student has attended the online classes or not (Week 1–Week 13) |
| Event Context | GRADE | p Value | ||||
|---|---|---|---|---|---|---|
| Fail n(%) | Satisfactory n(%) | Good n(%) | Very good n(%) | Excellent n(%) | ||
| Lectures | ||||||
| LEC1 | 7 (8.5) | 18 (22.0) | 30 (36.6) | 18 (22.0) | 9 (11.0) | <0.001 |
| LEC2 | 10 (11.0) | 20 (22.0) | 31 (34.1) | 20 (22.0) | 10 (11.0) | <0.001 |
| LEC3 | 8 (9.6) | 17 (20.5) | 29 (34.9) | 19 (22.9) | 10 (12.0) | <0.001 |
| LEC4 | 5 (6.6) | 13 (17.1) | 28 (36.8) | 20 (26.3) | 10 (13.2) | <0.001 |
| LEC5 | 6 (8.0) | 13 (17.3) | 26 (34.7) | 20 (26.7) | 10 (13.3) | <0.001 |
| LEC6 | 6 (8.2) | 10 (13.7) | 28 (38.4) | 19 (26.0) | 10 (13.7) | <0.001 |
| LEC7 | 3 (4.8) | 8 (12.9) | 22 (35.5) | 19 (30.6) | 10 (16.1) | <0.001 |
| LEC8 | 3 (4.6) | 9 (13.8) | 24 (36.9) | 19 (29.2) | 10 (15.4) | <0.001 |
| Exercises | ||||||
| EXER2 | 4 (5.1) | 17 (21.5) | 29 (36.7) | 19 (24.1) | 10 (12.7) | <0.001 |
| EXER3 | 0 (0.0) | 14 (20.6) | 27 (39.7) | 17 (25.0) | 10 (14.7) | <0.001 |
| EXER4 | 3 (4.3) | 11 (15.9) | 25 (36.2) | 20 (29.0) | 10 (14.5) | <0.001 |
| EXER5 | 2 (3.3) | 9 (14.8) | 21 (34.4) | 19 (31.1) | 10 (16.4) | <0.001 |
| EXER6 | 2 (5.9) | 6 (17.6) | 14 (41.2) | 9 (26.5) | 3 (8.8) | <0.001 |
| EXER7 | 4 (6.1) | 10 (15.2) | 23 (34.8) | 19 (28.8) | 10 (15.2) | <0.001 |
| EXER8 | 3 (4.9) | 7 (11.5) | 23 (37.7) | 18 (29.5) | 10 (16.4) | <0.001 |
| Source codes | ||||||
| SC1 | 6 (7.7) | 17 (21.8) | 26 (33.3) | 19 (24.4) | 10 (12.8) | <0.001 |
| SC2 | 3 (5.1) | 13 (22.0) | 19 (32.2) | 15 (25.4) | 9 (15.3) | <0.001 |
| SC3 | 0 (0.0) | 13 (22.8) | 18 (31.6) | 16 (28.1) | 10 (17.5) | <0.001 |
| SC4 | 1 (2.0) | 9 (18.4) | 19 (38.8) | 12 (24.5) | 8 (16.3) | <0.001 |
| SC5 | 2 (4.8) | 6 (14.3) | 17 (40.5) | 9 (21.4) | 8 (19.0) | <0.001 |
| SC6 | 3 (5.5) | 11 (20.0) | 21 (38.2) | 11 (20.0) | 9 (16.4) | <0.001 |
| SC7 | 1 (2.8) | 6 (16.7) | 14 (38.9) | 9 (25.0) | 6 (16.7) | <0.001 |
| SC8 | 2 (5.7) | 5 (14.3) | 12 (34.3) | 9 (25.7) | 7 (20.0) | <0.001 |
| SC9 | 2 (5.1%) | 6 (15.4) | 16 (41.0) | 8 (20.5) | 7 (17.9) | <0.001 |
| Assignments | ||||||
| ASSIG2 | 1 (1.4) | 12 (17.4) | 28 (40.6) | 18 (26.1) | 10 (14.5) | <0.001 |
| ASSIG3 | 0 (0.0) | 7 (13.5) | 21 (40.4) | 14 (26.9) | 10 (19.2) | <0.001 |
| ASSIG4 | 2 (3.5) | 7 (12.3) | 21 (36.8) | 17 (29.8) | 10 (17.5) | <0.001 |
| ASSIG5 | 1 (2.6) | 3 (7.7) | 11 (28.2) | 14 (35.9) | 10 (25.6) | <0.001 |
| ASSIG6 | 2 (5.1) | 2 (7.7) | 11 (28.2) | 15 (38.5) | 8 (20.5) | <0.001 |
| ASSIG7 | 1 (3.0) | 1 (3.0) | 10 (30.3) | 15 (45.5) | 6 (18.2) | <0.001 |
| ASSIG8 | 1 (2.7) | 3 (8.1) | 14 (37.8) | 11 (29.7) | 8 (21.6) | <0.001 |
| Status | GRADE | p Value | ||||
|---|---|---|---|---|---|---|
| Fail n(%) | Satisfactory n(%) | Good n(%) | Very good n(%) | Excellent n(%) | ||
| Attendance | ||||||
| Less than 60% | 16 (30.8) | 19 (36.5) | 14 (26.9) | 3 (5.8) | 0 (0.0) | <0.001 |
| 60% or more | 3 (5.7) | 3 (5.7) | 20 (37.7) | 17 (32.1) | 10 (18.9) | |
| Event Context | Estimates | Odds Ratio (OR) | p Value |
|---|---|---|---|
| Lectures | |||
| LEC1 | −2.539 | 0.079 | <0.001 |
| LEC2 | −3.080 | 0.046 | <0.001 |
| LEC3 | −2.523 | 0.080 | <0.001 |
| LEC4 | −2.746 | 0.064 | <0.001 |
| LEC5 | −2.439 | 0.087 | <0.001 |
| LEC6 | 0.254 | 1.289 | 0.663 |
| LEC7 | −1.044 | 0.352 | 0.218 |
| LEC8 | −1.851 | 0.157 | 0.017 |
| Exercises | |||
| EXER2 | −2.325 | 0.098 | <0.001 |
| EXER3 | 21.545 | 0.000 | 0.995 |
| EXER4 | −0.815 | 0.442 | 0.224 |
| EXER5 | −1.976 | 0.139 | 0.005 |
| EXER6 | 0.528 | 1.696 | 0.408 |
| EXER7 | 1.444 | 4.238 | 0.017 |
| EXER8 | −1.451 | 0.234 | 0.029 |
| Source codes | |||
| SC1 | −1.965 | 0.140 | <0.001 |
| SC2 | −0.944 | 0.389 | 0.106 |
| SC3 | −21.177 | 0.000 | 0.996 |
| SC4 | −2.494 | 0.083 | 0.002 |
| SC5 | −1.224 | 0.294 | 0.064 |
| SC6 | −1.525 | 0.218 | 0.062 |
| SC7 | −1.949 | 0.142 | 0.058 |
| SC8 | 1.601 | 4.956 | 0.188 |
| SC9 | −0.389 | 0.677 | 0.699 |
| Assignments | |||
| ASSIG2 | −3.708 | 0.025 | <0.001 |
| ASSIG3 | −18.260 | 0.000 | 0.996 |
| ASSIG4 | −1.862 | 0.155 | 0.016 |
| ASSIG5 | 0.080 | 1.084 | 0.940 |
| ASSIG6 | −0.553 | 0.575 | 0.429 |
| ASSIG7 | −1.665 | 0.189 | 0.054 |
| ASSIG8 | −2.101 | 0.122 | <0.01 |
| Random Forest Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| K = 0 | 0.91 | 0.90 | 0.90 | 0.90 |
| K = 1 | 0.77 | 0.72 | 0.72 | 0.72 |
| K = 2 | 0.77 | 0.57 | 0.40 | 0.47 |
| K = 3 | 0.69 | 0.98 | 0.90 | 0.94 |
| K = 4 | 0.76 | 0.71 | 0.98 | 0.83 |
| Average | 0.78 | 0.77 | 0.78 | 0.77 |
| Algorithms | Four (4) Weeks Data | Eight (8) Weeks Data | Imbalanced Complete Dataset | Balanced Complete Dataset | Four (4) Weeks Data | Eight (8) Weeks Data | Imbalanced Complete Dataset | Balanced Complete Dataset | Four (4) Weeks Data | Eight (8) Weeks Data | Imbalanced Complete Dataset | Balanced Complete Dataset | Four (4) Weeks Data | Eight (8) Weeks Data | Imbalanced Complete Dataset | Balanced Complete Dataset |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | Precision | Precision | Precision | Precision | Recall | Recall | Recall | Recall | F1-Score | F1-Score | F1-Score | F1-Score | |
| RF | 0.47 | 0.71 | 0.70 | 0.78 | 0.51 | 0.75 | 0.77 | 0.77 | 0.53 | 0.70 | 0.72 | 0.78 | 0.46 | 0.71 | 0.71 | 0.77 |
| XGB | 0.43 | 0.68 | 0.59 | 0.76 | 0.56 | 0.68 | 0.56 | 0.76 | 0.59 | 0.68 | 0.59 | 0.76 | 0.55 | 0.67 | 0.57 | 0.75 |
| KNN | 0.44 | 0.65 | 0.63 | 0.72 | 0.48 | 0.66 | 0.63 | 0.73 | 0.45 | 0.69 | 0.66 | 0.73 | 0.54 | 0.62 | 0.60 | 0.73 |
| SVM | 0.39 | 0.66 | 0.59 | 0.70 | 0.40 | 0.68 | 0.89 | 0.72 | 0.49 | 0.67 | 0.59 | 0.70 | 0.45 | 0.67 | 0.55 | 0.70 |
| Reference | Dataset | Courses | Records | Features | Algorithms Used | Performance Matrices |
|---|---|---|---|---|---|---|
| [94] | Open University Learning Analytics Dataset (OULAD) | 22 | 32,593 | Demographic, Registration, Assessment, Interaction | J48, RepTree, RandomTree, FURIA | Accuracy 92.56%(for best classifier FURIA) |
| [95] | OULAD | 22 | 32,593 | Demographic, Registration, Assessment, Interaction | LightGBM, XGBoost, AdaBoost, RF, MLP and Naïve Bayes | Precision, Recall, F1-score 84.1% (for best classifier LightGBM) |
| [96] | OULAD | 22 | 32,593 | Demographic, Registration, Assessment, Interaction | Long-Short Term Memory (LSTM), SVM, Logistic Regression, DOPPFCN | Precision, Recall, F1-score 0.8757 F1-score for intra-class binary classification |
| [69] | University of Rijeka Dataset | One | 408 | ID, lectures, quizzes, labs, videos and grade | Random Forest | Accuracy 96.3% |
| [72] | Further education setting Dataset | One | 690 | Moodle log data variables | Random Forest, LDA, k-NN, GBM | Accuracy, Kappa, Accuracy 60.5% (for best classifier Random Forest) |
| [73] | King Abdulaziz University Dataset | Two | 60 | assignments, quizzes, forums and tests | Naïve Bayes, Neural Network, and Decision Tree | Specificity, Precision, Recall, Accuracy 86% (for best classifier Naïve Bayes) |
| [75] | Deanship of E-Learning and Distance Education dataset | 6 | 241 | Mobile Course Access Data, Course Access Data and Assessment Data | decision tree, random forest, sequential minimal optimization, multilayer perceptron, and logistic regression. | TPR, Kappa, Precision, Recall, F1-score, RMSE, Accuracy 99.17 (for best classifier Random Forest) |
| [78] | Learn Moodle Dataset | One | 6119 | Quiz, Forum, Workshop, Assignment, Activeness | Random Forest (RF) and Artificial Immune Recognition System (AIRS), fuzzy unordered rule induction algorithm (FURIA) | Accuracy 99.85% (for best classifier FURIA) |
| Our Study | University of Plovdiv Dataset | One | 7057 records | Attendance, Lectures, Assignments, Code, Exercises, Grade | Random Forest, XGBoost, KNN, and SVM | Precision, Recall, F1-score, Accuracy 78%(for best classifier Random Forest) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gaftandzhieva, S.; Talukder, A.; Gohain, N.; Hussain, S.; Theodorou, P.; Salal, Y.K.; Doneva, R. Exploring Online Activities to Predict the Final Grade of Student. Mathematics 2022, 10, 3758. https://doi.org/10.3390/math10203758
Gaftandzhieva S, Talukder A, Gohain N, Hussain S, Theodorou P, Salal YK, Doneva R. Exploring Online Activities to Predict the Final Grade of Student. Mathematics. 2022; 10(20):3758. https://doi.org/10.3390/math10203758
Chicago/Turabian StyleGaftandzhieva, Silvia, Ashis Talukder, Nisha Gohain, Sadiq Hussain, Paraskevi Theodorou, Yass Khudheir Salal, and Rositsa Doneva. 2022. "Exploring Online Activities to Predict the Final Grade of Student" Mathematics 10, no. 20: 3758. https://doi.org/10.3390/math10203758