1. Introduction
Large sparse linear algebraic systems are ubiquitous in scientific and engineering computation, such as discretization of partial differential equations (PDE) and linearization of non-linear problems. Designing efficient, robust, and adaptive numerical methods for solving them is a long-term challenge. Iterative methods are an effective way to resolve this issue. They can be classified into single-level and multi-level methods. There are two types of single-level methods: stationary and non-stationary [
1]. Due to sluggish convergence, stationary methods, such as weighted Jacobi, Gauss–Seidel and successive over-relaxation methods [
2] are frequently utilized as smoothers in multi-level approaches or as preconditioners. Non-stationary methods typically refer to Krylov subspace methods, such as conjugate gradient (CG) and generalized minimal residual (GMRES) methods [
3,
4], whose convergence rate is heavily influenced by certain factors, such as the initial value. Multi-level methods mainly comprise the geometric multigrid (GMG) method [
5,
6,
7] and the algebraic multigrid (AMG) method [
8,
9]. They are both affected by many factors, such as smoother and coarse grid correction, which heavily affect convergence. Identifying these factors for a concrete problem is an art that requires extensive analysis, innovation, and trial.
In recent years, the technique of automatically picking parameters for Krylov and multi-level methods and constructing a learnable iterative scheme based on deep learning has attracted much interest. Many neural solvers have achieved satisfactory results for second-order elliptic equations with smooth coefficients. Hsieh et al. [
10] utilized a convolutional neural network (CNN) to accelerate convergence of the Jacobi method. Luna et al. [
11] accelerated the convergence of GMRES with a learned initial value. Zhang et al. [
12] combined standard relaxation methods and the DeepONet [
13] to target distinct regions in the spectrum of eigenmodes. Significant efforts have also been made in the development of multigrid solvers, such as the learning smoother, the transfer operator [
14,
15] and coarse-fine splitting [
16].
Huang et al. [
17] exploited a CNN to design a more sensible smoother for anisotropy elliptic equations. The results showed that the magnitude of the learned smoother was dispersed along the anisotropic direction. Wang et al. [
18] introduced a learning-based local weighted least square method for the AMG interpolation operator and applied it to random diffusion equations and one-dimensional small wavenumber Helmholtz equations. Fanaskov [
19] produced the learned smoother and transfer operator of GMG in a neural network form.
When the anisotropic strength is mild (within two orders of magnitude), the studies referred to evidence considerable acceleration. Chen et al. [
20] proposed the Meta-MgNet to learn a basis vector of Krylov subspace as the smoother of GMG for strong anisotropic cases. However, the convergence rate was still sensitive to the anisotropic strength. For convection–diffusion equations, Katrutsa et al. [
21] trained the weighted Jacobi smoother and transfer operator of GMG, which had a positive effect on the upwind discretization system and was also applied to solve a one-dimensional Helmholtz equation. For second-order elliptic equations with random diffusion coefficients, Greenfeld et al. [
22] employed a residual network to construct the prolongation operator of AMG for uniform grids. Luz et al. [
23] extended it to non-uniform grids using graph neural networks, which outperformed classical AMG methods. For jumping coefficient problems, Antonietti et al. [
24] presented a neural network to forecast the strong connection parameter to speed up AMG and used it as a preconditioner for CG. For the Helmholtz equation, Stanziola et al. [
25] constructed a fully learnable neural solver, the helmnet, which was built on U-net and a recurrent neural network [
26]. Azulay et al. [
27] developed a preconditioner based on U-net and shift-Laplacian MG [
28] and applied the flexible GMRES [
29] to solve the discrete system. For solid and fluid mechanics equations, several neural solver methods for associated discrete systems have been proposed, such as, but not limited to, learning initial values [
30,
31], constructing preconditioners [
32], learning the search directions of CG [
33], and learning the parameters of GMG [
34,
35].
In this paper, we propose a Fourier neural solver (FNS), a deep learning and fast Fourier transform (FFT)-based [
36] neural solver. The FNS is made up of two modules: a stationary method and a frequency space correction. Since stationary methods, such as the weighted Jacobi method, have difficulty eliminating low-frequency error, the FNS uses FFT and CNN to learn these modes in the frequency space. Local Fourier analysis (LFA) [
5] has shown that the FNS can pick up on the error components in frequency space that are challenging to eradicate using stationary methods. The FNS builds a complementary relationship with the stationary method and CNN to eliminate error. With the help of FFT, the single-step iteration of the FNS has a
computational complexity. All matrix-vector products are implemented using convolution, which is both storage-efficient and straightforward to parallelize. We investigated the effectiveness and robustness of the FNS on three types of convection–diffusion–reaction equations. For anisotropic diffusion equations, numerical experiments showed that the FNS was able to reduce the number of iterations by nearly 10-times compared to the state-of-the-art Meta-MgNet when the anisotropic strength was relatively strong. For non-symmetric systems arising from the convection–diffusion equation discretized by the central difference method, the FNS can converge, while MG and CG methods diverge. In addition, FNS is faster than other algorithms, such as GMRES and BiCGSTAB(
ℓ) [
37]. For indefinite systems arising from the Helmholtz equation, the FNS outperforms GMRES and BiCGSTAB for medium wavenumbers. In this paper, we apply the FNS to the above three PDE systems. However, the principles employed by the FNS indicate that the FNS has the potential to be useful for a broad range of sparse linear algebraic systems.
The remainder of this paper is organized as follows:
Section 2 proposes a general form of linear convection–diffusion–reaction equation and describes the motivation for designing the FNS.
Section 3 presents the FNS algorithm.
Section 4 examines the performance of the FNS with respect to anisotropy, convection–diffusion, and the Helmholtz equations. Finally,
Section 5 describes the conclusions and potential future work.
2. Motivation
We consider the general linear convection–diffusion–reaction equation with a Dirichlet boundary condition
where
is an open and bounded domain.
is the
order diffusion coefficient matrix.
is the
velocity field that the quantity is moving with.
is the reaction coefficient.
f is the source term.
We can obtain a linear algebraic system once we discretize Equation (
13) by the finite element method (FEM) or finite difference method (FDM)
where
,
and
N is the spatial discrete degrees of freedom.
Classical stationary iterative methods, such as Gauss–Seidel and weighted Jacobi methods, have the generic form
where
is an easily computed operator, such as the inverse of the diagonal matrix (Jacobi method) or the inverse of the lower triangle matrix (Gauss–Seidel method). However, the convergence rate of such methods is relatively low. As an example, we utilize the weighted Jacobi method to solve a special case of Equation (
1) and use LFA to analyze the rationale.
Taking
,
and
, Equation (
1) becomes the Poisson equation. With a linear FEM discretization, in stencil notation, the resulting discrete operator reads
In the weighted Jacobi method,
, where
and
is the identity matrix. Equation (
3) can be written in the pointwise form
Let
be the true solution and define error
. Then, we have
Expanding error in a Fourier series
, substituting the general term
,
into Equation (
6), we have
The convergence factor of the weighted Jacobi method (also known as the smoother factor in the MG framework [
7]) is
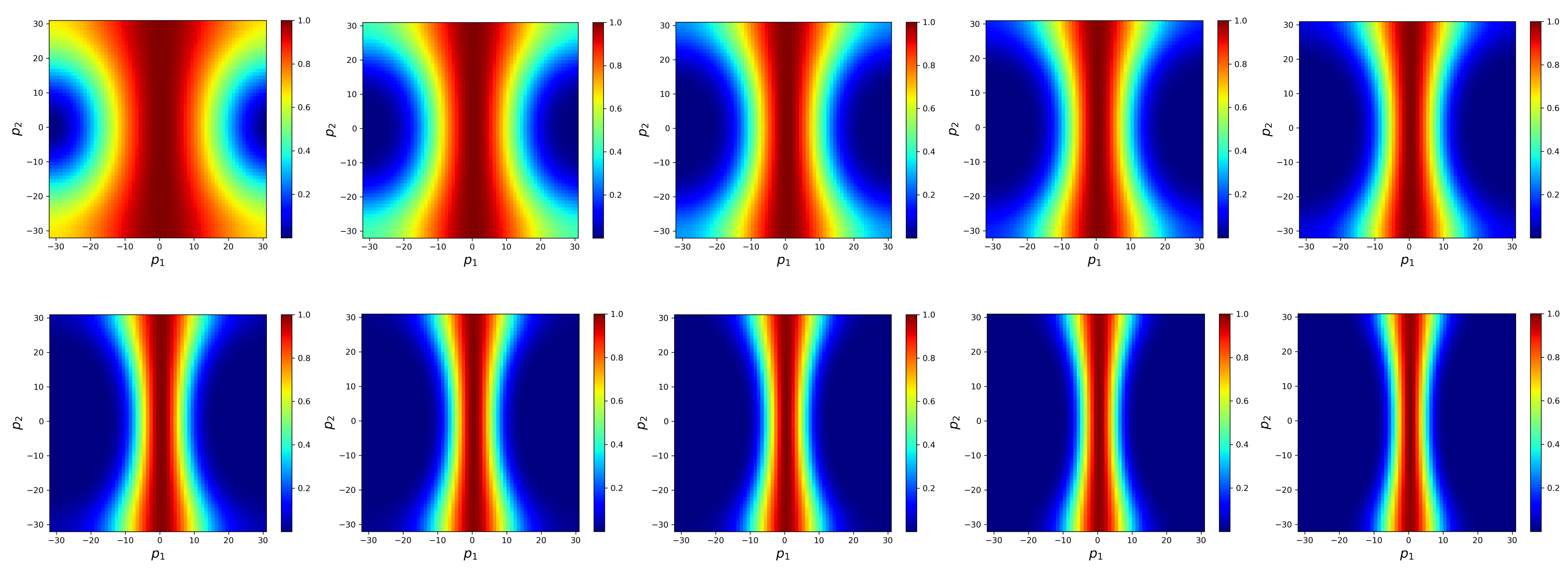
Figure 1a shows the distribution of the convergence factor
of weighted Jacobi (
) in solving a linear system for the Poisson equation. For a better understanding, let
,
,
. Define the high and low-frequency regions
as shown in
Figure 1b. It can be seen that, in the high-frequency region,
is approximately zero, whereas, in the low-frequency region,
is close to one. As a result, the weighted Jacobi method attenuates high-frequency errors quickly but is mostly ineffective for low-frequency errors.
The explanation has two aspects. Firstly, the high-frequency reflects the local oscillation, while the low-frequency reflects the global pattern. Since is sparse and the basic operation of the weighted Jacobi method is a local operation, it is challenging to remove low-frequency global error components. Secondly, is sparse and is commonly dense, which means that the mapping is non-local, making local operations difficult to approximate.
Therefore, we should seek the solution in another space to obtain an effective approximation of the non-local mapping. For example, the Krylov method approximates the solution in a subspace spanned by a basis set. The MG generates a coarse space to broaden the receptive field of the local operation. However, as mentioned in
Section 1, these methods require the careful design of various parameters. In this paper, we propose the FNS, a generic solver that uses FFT to learn solutions in frequency space, with the parameters obtained automatically in a data-driven manner.
3. Fourier Neural Solver
Denote stationary iterative methods of (
3) in an operator form
and the
th step residual
then the
th step error
satisfies residual equation
As shown in the preceding section, the slow convergence rate of stationary methods is due to the difficulty of reducing low-frequency errors. Even high-frequency errors might not be effectively eliminated by in many cases. We employ stationary methods to rapidly erase some components of the error and use FFT to convert the remaining error components to frequency space. The resulting solver is the Fourier neural solver.
Figure 2 shows a flowchart of the
th step for the FNS. The module for solving the residual equation in frequency space is denoted as
. It consists of three steps: FFT→Hadamard product→IFFT. The parameter
of
is the output of the hyper-neural network (HyperNN). The input
of the HyperNN are the PDE parameters corresponding to the discrete systems. During training, the only parameter
of the HyperNN serves as the optimization parameter.
The three-step operation of
was inspired by the fast Poisson solver [
38]. Let eigenvalues and eigenvectors of
be
and
, respectively. Solving Equation (
2) entails three steps:
In particular, when
is the system generated by a five-point stencil (
4), its eigenvector
is the sine function. The first and third steps above can now be performed with a computational complexity of
using fast sine transform (based on the FFT). The computational complexity of each iteration of the FNS is
.
It is worth noting that, although can smooth some components of the error, the components that are removed are indeterminate. As a result, instead of filtering high-frequency modes in frequency space, learns the error components that cannot easily eliminate. For with a fixed stencil, we can use LFA to demonstrate that the learned is complementary to .
The loss function used here for training is the relative residual
where
are the training data.
is the batch size.
K indicates that the
th step solution
is used to calculate the loss. These specific values will be given in the next section. The training and testing algorithms of the FNS are summarized in Algorithms 1 and 2, respectively.
| Algorithm 1: FNS offline traning. |
| | Data: PDE parameters and corresponding discrete systems |
| | Input: , HyperNN(), K and Epochs |
| 1 | forepochEpochsdo serial |
| 2 | | | fordo parallel |
| 3 | | | | | HyperNN |
| 4 | | | | | zeros like |
| 5 | | | | | fordo serial |
| 6 | | | | | | | |
| 7 | | | | | | | |
| 8 | | | | | | | |
| 9 | | | | | | | |
| 10 | | | | | | | |
| 11 | | | | | | | |
| 12 | | | | | end |
| 13 | | | end |
| 14 | | | Compute loss function (12) |
| 15 | | | Apply Adam algorithm [39] to update parameters |
| 16 | end |
| 17 | returnlearned FNS |
| Algorithm 2: FNS online testing. |
 |
5. Conclusions and Future Work
This paper proposes an interpretable FNS to solve large sparse linear systems. It is composed of a stationary method and a frequency correction, which are used to eliminate errors in different Fourier modes. Numerical experiments undertaken showed that the FNS was more effective and robust than other solvers in solving the anisotropic diffusion equation, the convection–diffusion equation and the Helmholtz equation. The core concepts discussed here are relevant to a broad range of systems.
There is still a great deal of work to do. First, we only considered uniform mesh in this paper. We intend to generalize the FNS to non-uniform grids by exploiting geometric deep learning tools, such as graph neural networks and graph Fourier transform. Secondly, as previously discussed, the stationary method converges slowly or diverges in some situations, which has prompted researchers to approximate solutions in other transform space. This is true for almost all advanced iterative methods, including MG, Krylov subspace methods and the FNS. This specified space, however, may not always be the best choice. In the future, we will investigate additional potential transforms, such as Chebyshev, Legendre transforms, and potentially learnable transforms based on data.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









