
Latin Matchings and Ordered Designs OD(n−1, n, 2n−1) †

Abstract
:1. Introduction
2. Preliminaries
3. Related Work
- Teirlinck,1988 [10] If , where, are distinct primes, satisfying for all i, there is an . As a corollary, there are infinitely many for all n, and there is an for all prime n.
- Teirlinck and Lindner, 1988 [12] For , there is an . There is an , but no exists (this is the 36-generals problem).
- Teirlinck, 1990 [13] For odd , there is an .
- Teirlinck, 1992 [7] (this is a survey)
- (a)
- There is no (page 569). We verified this result.
- (b)
- An exists if and only if an affine plane of order n exists (page 575).
- (c)
- An implies an (page 570).
- (d)
- An implies an (page 571).
- (e)
- An exists for every prime power ; an exists for every prime power ; an exists for ; and an exists for (page 578).
- Ray-Chaudhuri and Zhu, 1997 [14] If an and an exists, such that , then an exists. In particular, if an exists, then an exists for all positive s. Moreover, for any , there is an for some finite .
4. Major Findings
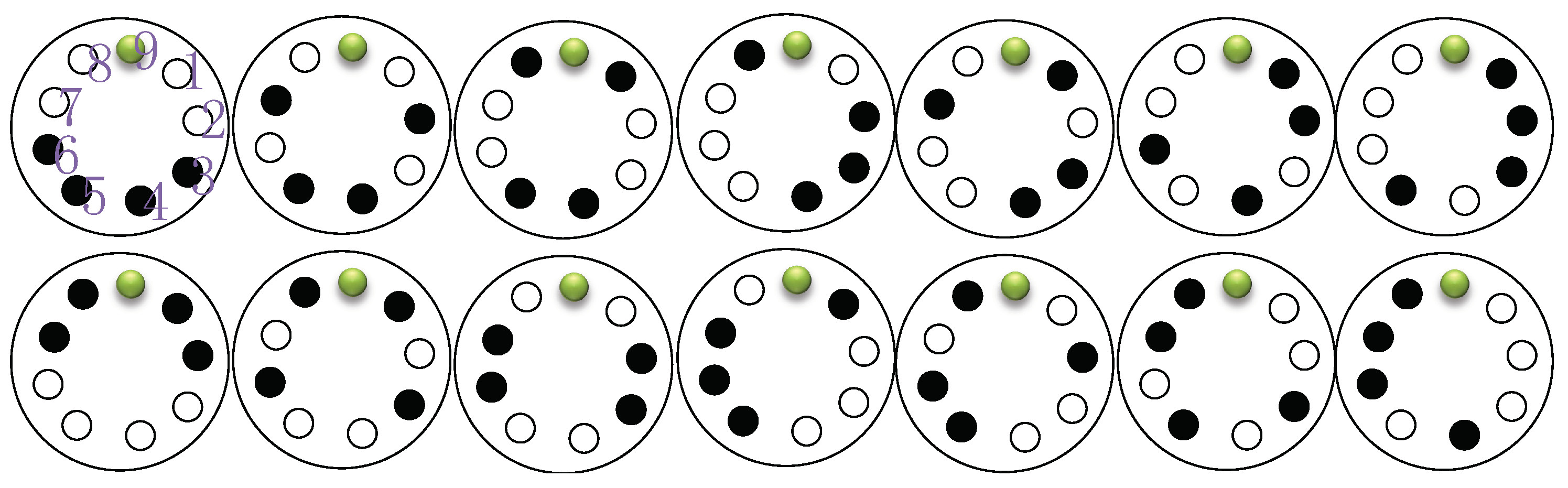
4.1. Construction of LOD from LM
- are independent sets of .
- are disjoint and they contain all the vertices of .
5. An Orthogonal Property of the ’s Obtained from
6. Connections between SLF and SS with Implications
Further Investigation on the Existence or Nonexistence of for Prime n
7. Applications
7.1. Cooperation via Ordered Designs in Hat Guessing Games
- Assume there are nplayers and vhats with different colors . (the supply for hats of any specific color is unique; in other words, each hat is unique). A dealer randomly places one hat to each of the n players (according to uniform distribution).
- Each player can observe the colors of the hats of other players, but cannot see and has to guess the color they receive. All players must guess simultaneously.
- The n players act as a team, and the team wins if all players are right. The question is how to design the best cooperative strategy to obtain the maximal winning probability.
- Parameters are known to the players. No communication is allowed between players after the game starts; communication via wait used in some hat puzzles is also forbidden. However, it is permissible for them to discuss a strategy beforehand.
7.2. Apply Known to Construct Other Ordered Designs
- (1)
- for , matrix Z is an ;
- (2)
- for , matrix Z is an (note: Z is not an ).
7.3. Applications of Ordered Designs or Large Set of Ordered Designs in Experimental Designs, Error-Correcting Codes, Secret-Sharing Scheme, Tournament Scheduling, etc.
8. Concluding Remarks
- Does an exist?
- Does an exist? Does an exist for a composite n?
- Does an exist? Moreover, does an exist?
- Does an exist? Does an exist?
- Is it true that every is a Latin matching? (we verified that this holds for , and we conjecture that this holds for all n.)
- Is it true that every Latin matching is isomorphic to a cyclic Latin matching?
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| OD | Ordered design |
| LOD | Large set of ordered design |
| MIS | Maximal independent (vertex) set |
| SS | Steiner system |
| SLF | Symmetric Latin function |
| LM | Latin matching |
| OA | Orthogonal array |
Appendix A. C++ Program for the Proof of Theorem 3
Appendix B. C++ Program for the Proof Claim (2) in Section 7.2
References
- Colbourn, C.; van Oorschot, P. Applications of Combinatorial Designs in Computer Science. ACM Comput. Surv. 1989, 21, 223–250. [Google Scholar] [CrossRef] [Green Version]
- Gopalakrishnan, K.; Stinson, D.; Cheriton, D. Applications of Orthogonal Arrays to Computer Science. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 149–164. [Google Scholar]
- Raghavarao, D. Constructions and Combinatorial Problems in Design of Experiments; Dover books on advanced mathematics; Dover Publications: New York, NY, USA, 1988. [Google Scholar]
- Hedayat, A.; Sloane, N.; Stufken, J. Orthogonal Arrays Theory and Applications; Springer: New York, NY, USA, 1999. [Google Scholar] [CrossRef]
- Beth, T.; Jungnickel, D.; Lenz, H. Design Theory; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Keevash, P. The Existence of Designs. arXiv 2014, arXiv:1401.3665. [Google Scholar]
- Teirlinck, L. Large Sets of Disjoint Designs and Related Structures. In Contemporary Design Theory: A Collection of Surveys, 1st ed.; Dinitz, J., Stinson, D., Eds.; Wiley-Interscience: Hoboken, NJ, USA, 1992; Chapter 12; pp. 561–592. [Google Scholar]
- Bierbrauer, J. Ordered Designs, Perpendicular Arrays, and Permutation Sets. In Handbook of Combinatorial Designs, 2nd ed.; Colbourn, C., Dinitz, J., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2006; Chapter 38; pp. 543–547. [Google Scholar]
- Rao, C. Combinatorial Arrangements Analogous to Orthogonal Arrays. Sankhya Indian J. Stat. Ser. A 1961, 23, 283–286. [Google Scholar]
- Teirlinck, L. On Large Set of Disjoint Ordered Design. Ars Comb. 1988, 17, 31–37. [Google Scholar]
- Jin, K. On 1-factorizations of Bipartite Kneser Graphs. Theor. Comput. Sci. 2020, 838, 81–93. [Google Scholar] [CrossRef]
- Teirlinck, L.; Lindner, C. The Construction of Large Sets of Idempotent Quasigroups. Eur. J. Comb. 1988, 9, 83–89. [Google Scholar] [CrossRef] [Green Version]
- Teirlinck, L. Generalized Idempotent Orthogonal Arrays. In Coding Theory and Design Theory: Part II, Design Theory, 1st ed.; Ray-Chaudhuri, D., Ed.; Springer: New York, NY, USA, 1990; pp. 368–378. [Google Scholar]
- Ray-Chaudhuri, D.; Zhu, T. Orthogonal arrays and ordered designs. J. Stat. Plan. Inference 1997, 58, 177–183. [Google Scholar] [CrossRef]
- Bierbrauer, J.; Van Trung, T. Some highly symmetric authentication perpendicular arrays. Des. Codes Cryptogr. 1991, 1, 307–319. [Google Scholar] [CrossRef]
- Stinson, D.; Teirlinck, L. A Construction for Authentication/secrecy Codes from 3-homogeneous Permutation Groups. Eur. J. Comb. 1990, 11, 73–79. [Google Scholar] [CrossRef] [Green Version]
- Kramer, E.; kreher, D.; Rees, R.; Stinson, D. On perpendicular arrays with t≥3. Ars Comb. 1989, 28, 215–223. [Google Scholar]
- Rosa, A. Topics on Steiner Systems; North-Holland Publishing Company: Amsterdam, The Netherland, 1980. [Google Scholar]
- McKay, B.; Wanless, I. A Census of Small Latin Hypercubes. SIAM J. Discret. Math. 2008, 22, 719–736. [Google Scholar] [CrossRef] [Green Version]
- Mendelsohn, N.; Hung, S. On the Steiner systems S(3, 4, 14) and S(4, 5, 15). Util. Math. 1972, 1, 5–95. [Google Scholar]
- Östergård, P.; Pottonen, O. There Exists No Steiner System S(4,5,17). J. Comb. Theory Ser. A 2008, 115, 1570–1573. [Google Scholar] [CrossRef] [Green Version]
- Kramer, E.; Mesner, D. Intersections Among Steiner Systems. J. Comb. Theory Ser. A 1974, 16, 273–285. [Google Scholar] [CrossRef]
- Wikipedia. Steiner System. 2022. Available online: https://en.wikipedia.org/wiki/Steiner_system (accessed on 1 December 2022).
- Brouwer, A.; Etzion, T. Some New Distance-4 Constant Weight Codes. Adv. Math. Commun. 2011, 5, 417–424. [Google Scholar]
- Nurmela, K.; Kaikkonen, M.; Östergård, P. New Constant Weight Codes from Linear Permutation Groups. IEEE Trans. Inf. Theory 2006, 43, 1623–1630. [Google Scholar] [CrossRef]
- Van Pul, C.; Etzion, T. New Lower Bounds for Constant Weight Codes. IEEE Trans. Inf. Theory 1989, 35, 1324–1329. [Google Scholar] [CrossRef] [Green Version]
- The-New-York-Time. Why Mathematicians Now Care about Their Hat Color. 2001. Available online: http://www.nytimes.com/2001/04/10/science/why-mathematicians-now-care-about-their-hat-color.html (accessed on 1 December 2022).
- Lenstra, H.; Seroussi, G. On Hats and Other Covers. In Proceedings of the IEEE International Symposium on Information Theory, Lausanne, Switzerland, 30 June–5 July 2002; p. 342. [Google Scholar]
- Butler, S.; Hajiaghayi, M.; Kleinberg, R.; Leighton, T. Hat Guessing Games. SIAM Rev. 2009, 51, 399–413. [Google Scholar] [CrossRef]
- Ma, T.; Sun, X.; Yu, H. A New Variation of Hat Guessing Games. In Proceedings of the International Computing and Combinatorics Conference, Dallas, TX, USA, 14–16 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 616–626. [Google Scholar]
- Feige, U. You Can Leave Your Hat On (If You Guess Its Color); Technical Report; The Weizmann Institute of Science: Rehovot, Israel, 2004. [Google Scholar]
- Jin, K.; Jin, C.; Gu, Z. Cooperation via Codes in Restricted Hat Guessing Games. In Proceedings of the AAMAS’19: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 547–555. [Google Scholar]
- Ebert, T.; Merkle, W.; Vollmer, H. On the Autoreducibility of Random Sequences. SIAM J. Comput. 2003, 32, 1542–1569. [Google Scholar] [CrossRef] [Green Version]
- Aspnes, J.; Beigel, R.; Furst, M.; Rudich, S. The Expressive Power of Voting Polynomials. In Proceedings of the 23rd ACM Symposium on Theory of Computing, New Orleans, LA, USA, 5–8 May 1991; pp. 402–409. [Google Scholar]
- Ben-Zwi, O.; Newman, I.; Wolfovitz, G. Hats, Auctions and Derandomization. Random Struct. Algorithms 2015, 46, 478–493. [Google Scholar] [CrossRef] [Green Version]
- Majumdar, D.; Martin, R. Efficient designs based on orthogonal arrays of type I and type II for experiments using units ordered over time or space. Stat. Methodol. 2004, 1, 19–35. [Google Scholar] [CrossRef]
- Ramya, L.; Nehru Viji, S.; Arun Prasad, P.; Kanagasabai, V.; Gautham, N. MOLS sampling and its applications in structural biophysics. Biophys. Rev. 2010, 2, 169–179. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wikipedia. Latin Hypercube Sampling. 2022. Available online: https://en.wikipedia.org/wiki/Latin_hypercube_sampling (accessed on 1 December 2022).
- Schmidt, N. Latin Squares and Their Applications to Cryptography. Master’s Thesis, Boise State University, Boise, ID, USA, 2016. [Google Scholar]
- Schellenberg, P.; van Rees, G.; Vanstone, S. The existence of balanced tournament designs. Ars Comb. 1977, 3, 303–318. [Google Scholar]
- Robinson, D. Constructing an annual round-robin tournament played on neutral grounds. Math. Chron. 1981, 10, 73–82. [Google Scholar]
- Mendelsohn, E.; Rodney, P. The existence of court balanced tournament designs. Discret. Math. 1994, 133, 207–216. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| ordern | prime ≥ 17 | 4 | composite ≥ 6 | ||
| Latin matching | Yes | No | Unknown | No | No |
| Yes | Unknown | Unknown | No [7] (p. 569) | Unknown |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, K.; Zhu, T.; Gu, Z.; Sun, X. Latin Matchings and Ordered Designs OD(n−1, n, 2n−1). Mathematics 2022, 10, 4703. https://doi.org/10.3390/math10244703
Jin K, Zhu T, Gu Z, Sun X. Latin Matchings and Ordered Designs OD(n−1, n, 2n−1). Mathematics. 2022; 10(24):4703. https://doi.org/10.3390/math10244703
Chicago/Turabian StyleJin, Kai, Taikun Zhu, Zhaoquan Gu, and Xiaoming Sun. 2022. "Latin Matchings and Ordered Designs OD(n−1, n, 2n−1)" Mathematics 10, no. 24: 4703. https://doi.org/10.3390/math10244703