
Classification Comparison of Machine Learning Algorithms Using Two Independent CAD Datasets


Abstract
:1. Introduction
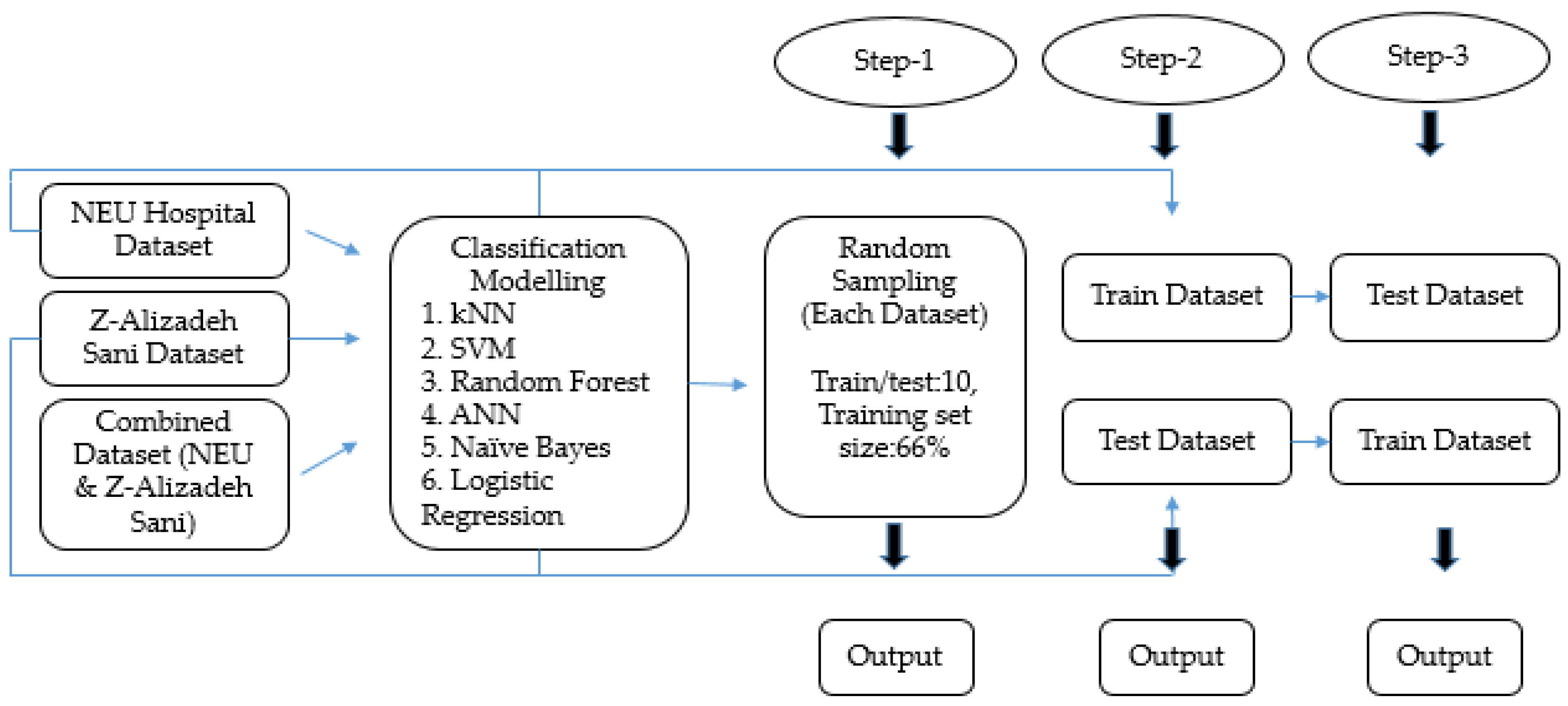
2. Materials and Methods
2.1. Database
2.2. Classification Methods
2.2.1. k-Nearest Neighbors (kNN)
2.2.2. Support Vector Machine (SVM)
2.2.3. Random Forest (RF)
2.2.4. Artificial Neural Network (ANN)
2.2.5. Naïve Bayes (NB)
2.2.6. Logistic Regression (LR)
2.3. Statistical Analysis
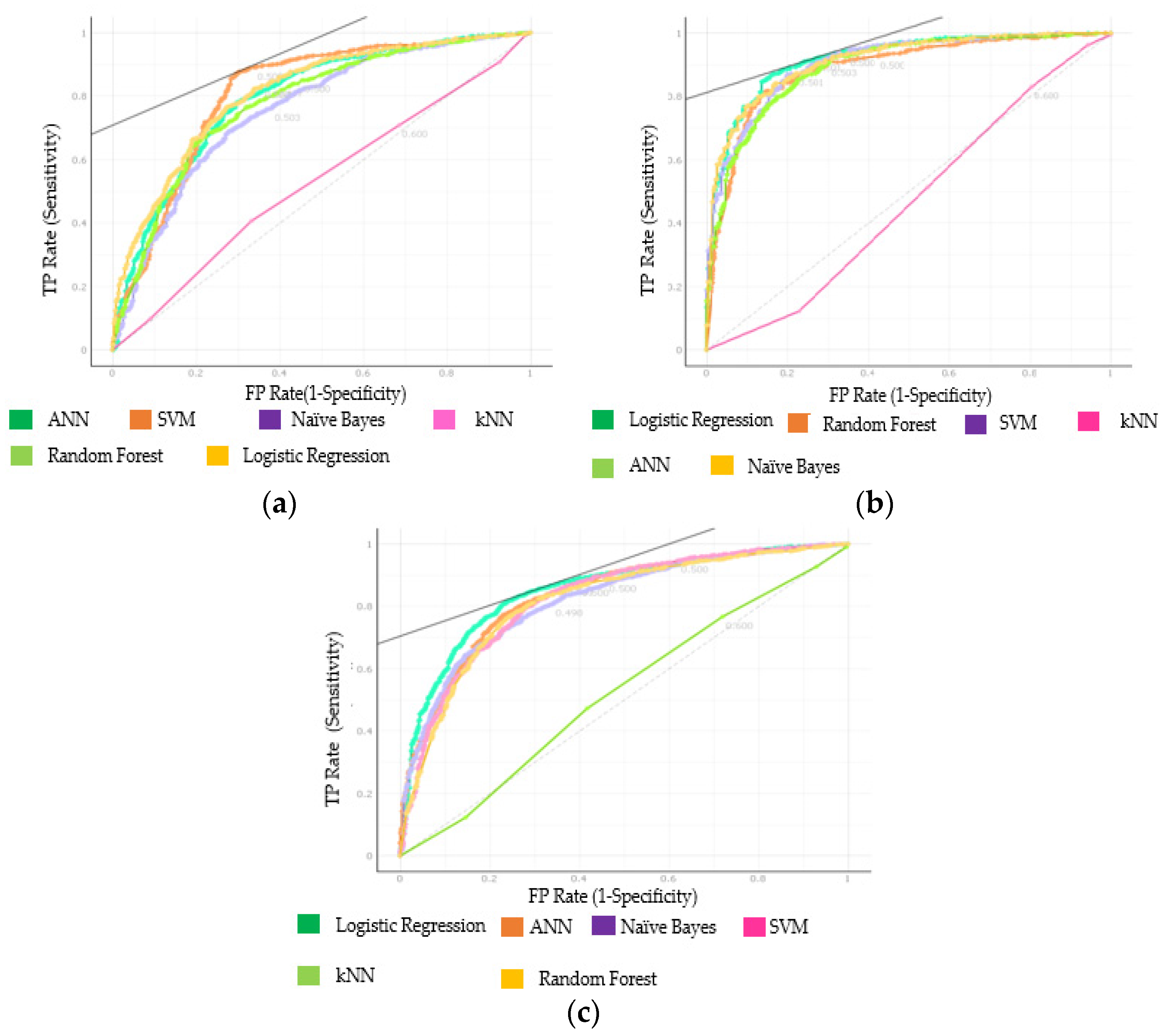
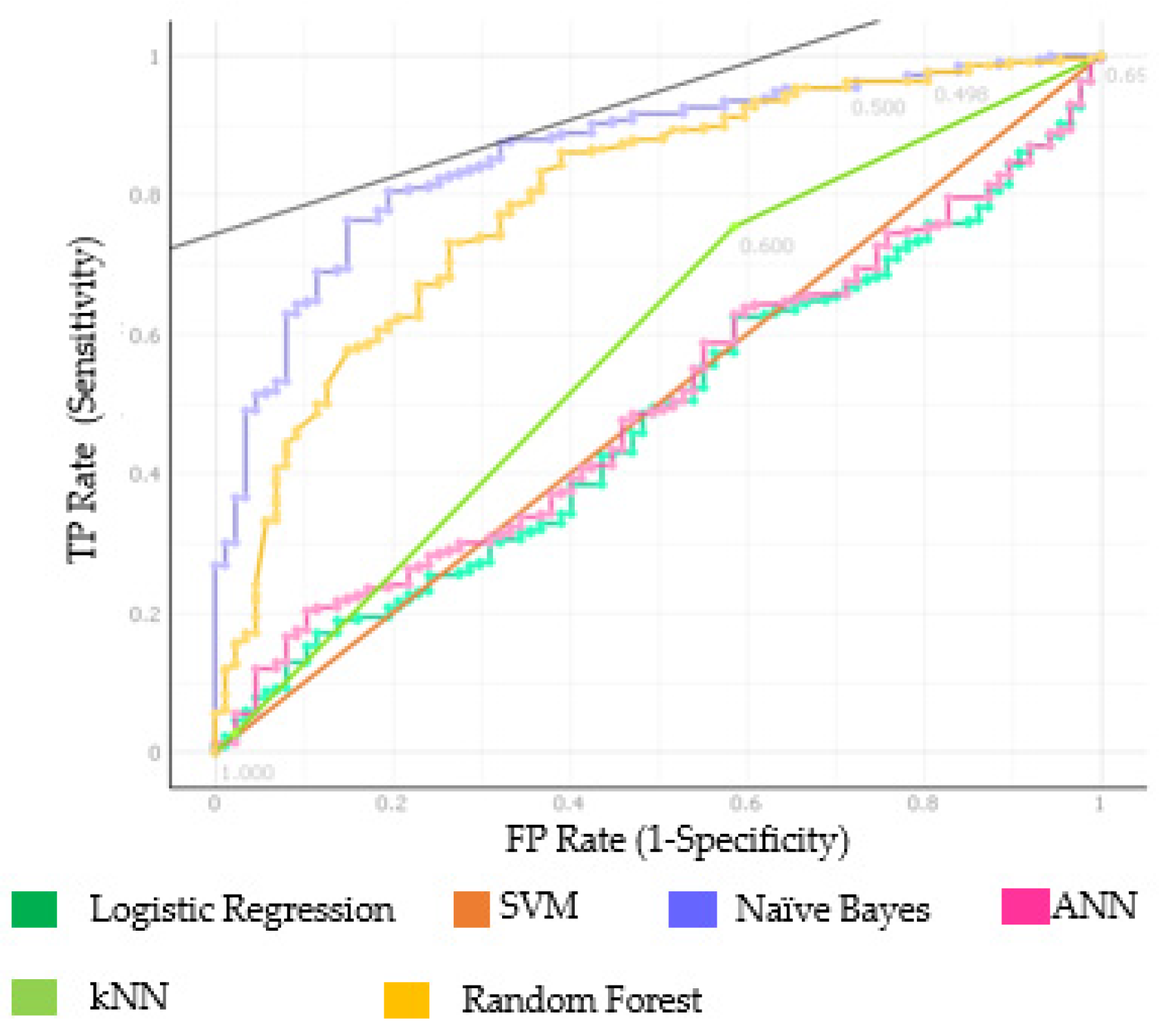
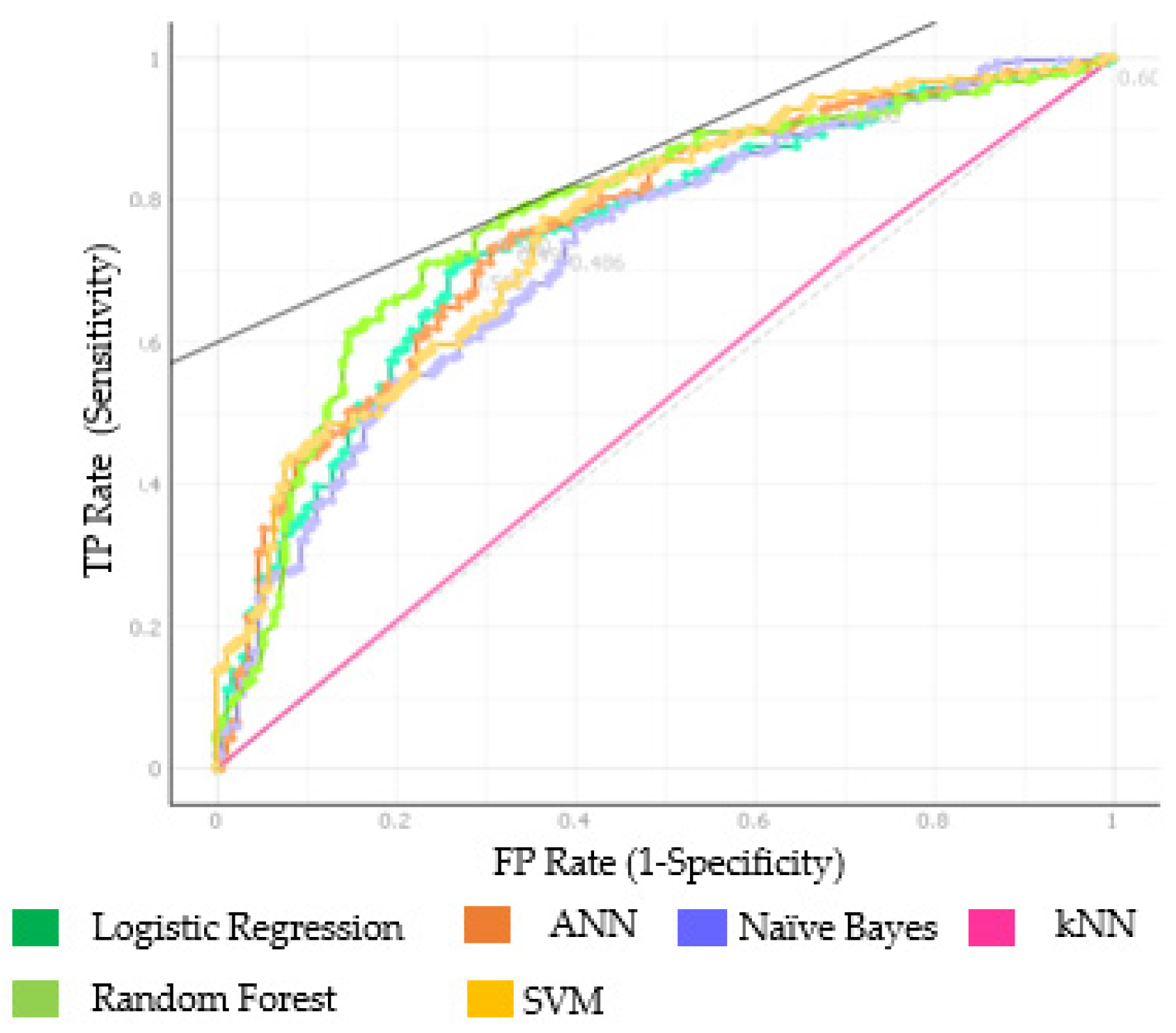
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PR | Pulse Rate | WBC | White Blood Cell |
| FBS | Fasting Blood Sugar | PLT | Platelet |
| CR | Creatinine | EF-TTE | Ejection Fraction |
| TG | Triglyceride | DM | Diabetes Mellitus |
| LDL | Low Density Lipoprotein | HT | Hypertension |
| HDL | High Density Lipoprotein | FH | Family History |
| Bun | Blood Urea Nitrogen | LVH | Left Ventricular Hypertrophy |
| Hb | Hemoglobin | Region RWMA | Regional Wall Motion Abnormality |
| K | Potassium | VHD | Valvular Heart Disease |
| Na | Sodium |
References
- Lo, Y.; Fujita, H.; Pai, T. Prediction of Coronary Artery Disease Based on Ensemble Learning Approaches and Co-Expressed Observations. J. Mech. Med. Biol. 2016, 16, 1640010. [Google Scholar] [CrossRef]
- Amin, M.; Chiam, Y.; Varathan, K. Identification of significant features and data mining techniques in predicting heart disease. Telemat. Inform. 2019, 36, 82–93. [Google Scholar] [CrossRef]
- Cardiovascular Diseases. 2021. Available online: https://www.who.int/health-topics/cardiovascular-diseases#tab=tab_1 (accessed on 10 September 2021).
- Shaima, C.; Moorthi, P.; Shaheen, N. Cardiovascular diseases: Traditional and non-traditional risk factors. J. Med. Allied Sci. 2016, 6, 46. [Google Scholar] [CrossRef]
- Dwivedi, A. Performance evaluation of different machine learning techniques for prediction of heart disease. Neural Comput. Appl. 2016, 29, 685–693. [Google Scholar] [CrossRef]
- Ayatollahi, H.; Gholamhosseini, L.; Salehi, M. Predicting coronary artery disease: A comparison between two data mining algorithms. BMC Public Health 2019, 19, 448. [Google Scholar] [CrossRef]
- Abdar, M.; Książek, W.; Acharya, U.; Tan, R.; Makarenkov, V.; Pławiak, P. A new machine learning technique for an accurate diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 2019, 179, 104992. [Google Scholar] [CrossRef]
- Akella, A.; Akella, S. Machine learning algorithms for predicting coronary artery disease: Efforts toward an open-source solution. Future Sci. OA 2021, 7, FSO698. [Google Scholar] [CrossRef]
- Cuvitoglu, A.; Isik, Z. Classification of CAD dataset by using principal component analysis and machine learning approaches. In Proceedings of the 2018 5th International Conference on Electrical and Electronic Engineering (ICEEE), Istanbul, Turkey, 3–5 May 2018. [Google Scholar] [CrossRef]
- Kutrani, H.; Eltalhi, S. Cardiac Catheterization Procedure Predicyion Using Machine Learning and Data Mining Techniques. 2019. Available online: https://www.semanticscholar.org/paper/Cardiac-Catheterization-Procedure-Prediction-Using-Kutrani-Eltalhi/763ac488da8a97c19170ecff36a2e8dbdffe64c6 (accessed on 22 August 2021).
- Tougui, I.; Jilbab, A.; El Mhamdi, J. Heart disease classification using data mining tools and machine learning techniques. Health Technol. 2020, 10, 1137–1144. [Google Scholar] [CrossRef]
- Naushad, S.; Hussain, T.; Indumathi, B.; Samreen, K.; Alrokayan, S.; Kutala, V. Machine learning algorithm-based risk prediction model of coronary artery disease. Mol. Biol. Rep. 2018, 45, 901–910. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository: Z-Alizadeh Sani Data Set. 2020. Available online: https://archive.ics.uci.edu/ml/datasets/Z-Alizadeh+Sani (accessed on 28 November 2020).
- Sharma, T.; Sharma, A.; Mansotra, V. Performance Analysis of Data Mining Classification Techniques on Public Health Care Data. 2016. Available online: https://www.researchgate.net/publication/313571291_Performance_Analysis_of_Data_Mining_Classification_Techniques_on_Public_Health_Care_Data (accessed on 22 August 2021).
- Abdulqader, D.M.; Abdulazeez, A.M.; Zeebaree, D.Q. Machine Learning Supervised Algorithms of Gene Selection: A Review. Technol. Rep. Kansai Univ. 2020, 62. [Google Scholar]
- Ahmed, F.S.; Ali, L.; Mustafa, R.U.; Khattak, H.A.; Hameed, T.; Wajahat, I.; Kadry, S.; Bukhari, S.A. Correction to: A hybrid machine learning framework to predict mortality in paralytic ileus patients using electronic health records (EHRs). J. Ambient. Intell. Humaniz. Comput. 2021, 12, 3283–3293. [Google Scholar] [CrossRef]
- Yahyaoui, A.; Jamil, A.; Rasheed, J.; Yesiltepe, M. A Decision Support System for Diabetes Prediction Using Machine Learning and Deep Learning Techniques. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 6–7 November 2019. [Google Scholar] [CrossRef]
- Lodha, P.; Talele, A.; Degaonkar, K. Diagnosis of Alzheimer’s Disease Using Machine Learning. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Iwendi, C.; Bashir, A.K.; Peshkar, A.; Sujatha, R.; Chatterjee, J.M.; Pasupuleti, S.; Mishra, R.; Pillai, S.; Jo, O. COVID-19 Patient Health Prediction Using Boosted Random Forest Algorithm. Front. Public Health 2020, 8, 357. [Google Scholar] [CrossRef]
- Naghibi, S.; Pourghasemi, H.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2015, 188, 44. [Google Scholar] [CrossRef] [PubMed]
- Ashraf, S.; Saleem, S.; Ahmed, T.; Aslam, Z.; Muhammad, D. Conversion of adverse data corpus to shrewd output using sampling metrics. Vis. Comput. Ind. Biomed. Art 2020, 3, 19. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Guo, C. Enhancing Face Identification Using Local Binary Patterns and K-Nearest Neighbors. J. Imaging 2017, 3, 37. [Google Scholar] [CrossRef] [Green Version]
- Thabtah, F.; Abdelhamid, N.; Peebles, D. A machine learning autism classification based on analysis. Health Inf. Sci. Syst. 2019, 7, 12. [Google Scholar] [CrossRef]
- Hsu, Y.C.; Tsai, I.; Hsu, H.; Hsu, P.W.; Cheng, M.H.; Huang, Y.L.; Chen, J.H.; Lei, M.H.; Ling, C.Y. Using Anti-Malondialdehyde Modified Peptide Autoantibodies to Import Machine Learning for Predicting Coronary Artery Stenosis in Taiwanese Patients with Coronary Artery Disease. Diagnostics 2021, 11, 961. [Google Scholar] [CrossRef]
- Megna, R.; Petretta, M.; Assante, R.; Zampella, E.; Nappi, C.; Gaudieri, V.; Mannarino, T.; D’Antonio, A.; Green, R.; Cantoni, V.; et al. A Comparison among Different Machine Learning Pretest Approaches to Predict Stress-Induced Ischemia at PET/CT Myocardial Perfusion Imaging. Comput. Math. Methods Med. 2021, 2021, 3551756. [Google Scholar] [CrossRef]
- Muhammad, L.; Al-Shourbaji, I.; Haruna, A.; Mohammed, I.; Ahmad, A.; Jibrin, M. Machine Learning Predictive Models for Coronary Artery Disease. SN Comput. Sci. 2021, 2, 350. [Google Scholar] [CrossRef]
- Sharma, D.; Gotlieb, N.; Farkouh, M.; Patel, K.; Xu, W.; Bhat, M. Machine Learning Approach to Classify Cardiovascular Disease in Patients With Nonalcoholic Fatty Liver Disease in the UK Biobank Cohort. J. Am. Heart Assoc. 2022, 11, e022576. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhang, X.; Ma, R.; Wang, X.; Liu, J.; Keerman, M.; Yan, Y.; Ma, J.; Song, Y.; Zhang, J.; et al. Cardiovascular Disease Prediction by Machine Learning Algorithms Based on Cytokines in Kazakhs of China. Clin. Epidemiol. 2021, 13, 417–428. [Google Scholar] [CrossRef] [PubMed]
- Patro, S.; Padhy, N.; Chiranjevi, D. Ambient assisted living predictive model for cardiovascular disease prediction using supervised learning. Evol. Intell. 2020, 14, 941–969. [Google Scholar] [CrossRef]
- Alizadehsani, R.; Zangooei, M.H.; Hosseini, M.J.; Habibi, J.; Khosravi, A.; Roshanzamir, M.; Khozeimeh, F.; Sarrafzadegan, N.; Nahavandi, S. Coronary artery disease detection using computational intelligence methods. Knowl.-Based Syst. 2016, 109, 187–197. [Google Scholar] [CrossRef]
- Couronné, R.; Probst, P.; Boulesteix, A. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 270. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, H.J. Speech and Language Processing. 2021. Available online: https://web.stanford.edu/~jurafsky/slp3/5.pdf (accessed on 28 November 2021).
- Austin, P.; Tu, J.; Ho, J.; Levy, D.; Lee, D. Using methods from the data mining and machine-learning literature for disease classification and prediction: A case study examining classification of heart failure subtypes. J. Clin. Epidemiol. 2013, 66, 398–407. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Fu, Y.; Lin, J.; Ji, Y.; Fang, Y.; Wu, J. Coronary Artery Disease Detection by Machine Learning with Coronary Bifurcation Features. Appl. Sci. 2020, 10, 7656. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | NEU Hospital | Z-Alizadeh Sani | ||
|---|---|---|---|---|
| Mean ± SD | Median (Min–Max) | Mean ± SD | Median (Min–Max) | |
| Age | 60.98 ± 10.95 | 62 (32–89) | 58.89 ± 10.39 | 58 (30–86) |
| BP (mm/Hg) | 124.33 ± 17.03 | 120 (80–220) | 129.55 ± 18.94 | 130 (90–190) |
| PR (ppm) | 74.92 ± 12.50 | 74 (45–171) | 75.14 ± 8.91 | 70 (50–110) |
| FBS (mg/dL) | 120.02 ± 42.68 | 107 (69–362) | 119.18 ± 52.08 | 98 (62–400) |
| CR (mg/dL) | 0.90 ± 0.45 | 0.82 (0.5–7.6) | 1.05 ± 0.26 | 1 (0.5–2.2) |
| TG (mg/dL) | 148.96 ± 82.30 | 131 (7–686) | 150.34 ± 97.96 | 122 (37–1050) |
| LDL (mg/dL) | 117.75± 39.32 | 114 (40–337) | 104.64 ± 35.40 | 100 (18–232) |
| HDL (mg/dL) | 45.77 ± 13.76 | 44 (13–169) | 40.23 ± 10.56 | 39 (15.9–111) |
| Bun (mg/dL) | 36.76 ± 15.22 | 34 (13–182) | 17.50 ± 6.96 | 16 (6–52) |
| Hb (g/dL) | 13.70 ± 1.68 | 13.90 (8.2–17.5) | 13.53 ± 1.61 | 13.2 (8.9–17.60) |
| K (mEq/lit) | 4.39 ± 0.44 | 4.4 (3–5.7) | 4.23 ± 0.46 | 4.2 (3–6.60) |
| Na (mEq/lit) | 139.87 ± 2.70 | 140 (129–147) | 140.1 ± 3.81 | 141 (128–156) |
| WBC (cells/mL) | 7.85 ± 5.36 | 7280 (2300–11240) | 7562.06 ± 2413.74 | 7100 (3700–18000) |
| Lymph (%) | 30.73 ± 9.30 | 30.3 (1.58–86.4) | 32.4 ± 9.97 | 32 (7–60) |
| Neut (%) | 59.74 ± 9.67 | 60.16 (3.27–90.1) | 60.15 ± 10.18 | 60 (32–89) |
| PLT (1000/mL) | 241.95 ± 77.12 | 232 (66–778) | 221.49 ± 60.79 | 210 (25–742) |
| EFTTE (%) | 57.75 ± 7.35 | 60 (30–72) | 47.23 ± 8.93 | 50 (15–60) |
| Variables | n (%) | ||
|---|---|---|---|
| NEU Hospital | Z-Alizadeh Sani | ||
| Gender | Female | 148 (31.2%) | 127 (41.9%) |
| DM | Present | 114 (24.0%) | 90 (29.7%) |
| HT | Present | 216 (45.5%) | 179 (59.1%) |
| Smoking | Present | 139 (29.3%) | 63 (20.8%) |
| FH | Present | 65 (13.7%) | 48 (15.8%) |
| Edema | Present | 15 (3.2%) | 12 (4.0%) |
| Murmur | Present | 19 (4.0%) | 41 (13.5%) |
| Chest Pain | Present | 216 (45.5%) | 164 (54.1%) |
| Dyspnea | Present | 75 (15.8%) | 134 (44.2%) |
| LVH | Present | 73 (15.4%) | 20 (6.6%) |
| Region RWMA | Present | 70 (14.7%) | 86 (28.4%) |
| VHD | Present | 180 (37.9%) | 187 (61.7%) |
| Variable | Groups | NEU Hospital | Z-Alizadeh Sani | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean ± SD | Median (Min–Max) | Z | p | Mean ± SD | Median (Min–Max) | Z | p | ||
| Age | Absent | 60.41 ± 10.57 | 61.00 (34.00–89.00) | −1.086 | 0.277 | 53.06 ± 9.32 | 52.00 (30.00–79.00) | −6.102 | <0.001 |
| Present | 61.30 ± 11.15 | 62.00 (32.00–89.00) | 61.25 ± 9.88 | 61.50 (36.00–86.00) | |||||
| Systolic BP | Absent | 123.76 ± 16.07 | 120.00 (95.00–200.00) | −0.694 | 0.488 | 122.47 ± 18.30 | 120.00 (90.00–180.00) | −4.455 | <0.001 |
| Present | 124.65 ± 17.56 | 120.00 (80.00–220.00) | 132.41 ± 18.48 | 130.00 (90.00–190.00) | |||||
| PR | Absent | 73.15 ± 13.23 | 72.00 (52.00–168.00) | −3.073 | 0.002 | 72.78 ± 8.08 | 70.00 (50.00–100.00) | −2.944 | 0.003 |
| Present | 75.90 ± 11.98 | 75.00 (45.00–171.00) | 76.09 ± 9.07 | 74.00 (50.00–110.00) | |||||
| FBS | Absent | 117.16 ± 40.75 | 105 (78.00–362.00) | −1.367 | 0.172 | 102.34 ± 34.79 | 92.00 (65.00–300.00) | −4.121 | <0.001 |
| Present | 121.61 ± 43.70 | 107.00 (69.00–338.00) | 125.97 ± 56.26 | 103.00 (62.00–400.00) | |||||
| CR | Absent | 0.92 ± 0.57 | 0.830 (0.560–7.590) | −0.552 | 0.581 | 1.02 ± 0.19 | 1.00 (0.60–1.60) | −0.985 | 0.325 |
| Present | 0.89 ± 0.37 | 0.810 (0.53–5.60) | 1.07± 0.29 | 1.00 (0.50–2.20) | |||||
| TG | Absent | 140.31 ± 70.06 | 130.00 (7.00–388.00) | −1.265 | 0.206 | 128.68 ± 75.54 | 110.00 (37.00–450.00) | −3.214 | 0.001 |
| Present | 153.78 ± 88.13 | 131.00 (24.00–686.00) | 159.07 ± 104.55 | 130.00 (50.00–1050.00) | |||||
| LDL | Absent | 113.19 ± 32.34 | 109.50 (42.00–200.00) | −1.425 | 0.154 | 105.95 ± 35.41 | 101 (18.00–232.00) | −0.512 | 0.608 |
| Present | 120.29 ± 42.55 | 118.00 (40.00–337.00) | 104.12 ± 35.46 | 100.00 (30.00–213.00) | |||||
| HDL | Absent | 45.65 ± 11.76 | 44.50 (13.00–82.00) | −1.031 | 0.303 | 40.94 ± 11.59 | 42.00 (15.90–83.00) | −0.669 | 0.503 |
| Present | 45.84 ± 14.77 | 43.00 (23.00–169.00) | 39.95 ± 10.13 | 39.00 (18.00–111.00) | |||||
| BUN | Absent | 37.02 ± 15.63 | 34.00 (17.00–182.00) | −0.551 | 0.582 | 16.53 ± 6.15 | 15.00 (6.00–41.00) | −1.518 | 0.129 |
| Present | 36.61 ± 15.02 | 34.00 (13.00–141.00) | 17.89 ± 7.23 | 16.00 (8.00–52.00) | |||||
| Hb | Absent | 13.84 ± 1.55 | 13.90 (10.30–17.30) | −0.920 | 0.358 | 13.26 ± 1.51 | 13.40 (9.00–17.50) | −0.802 | 0.423 |
| Present | 13.63 ± 1.74 | 13.80 (8.20–17.50) | 13.11 ± 1.65 | 13.10 (8.90–17.60) | |||||
| K | Absent | 4.38 ± 0.42 | 4.35 (3.30–5.50) | −0.572 | 0.567 | 4.10 ± 0.38 | 4.10 (3.00–5.20) | −3.133 | 0.002 |
| Present | 4.39 ± 0.44 | 4.40 (3.00–5.70) | 4.28 ± 0.48 | 4.30 (3.10–6.60) | |||||
| Na | Absent | 139.86 ± 2.72 | 140.00 (129.00–146.00) | −0.086 | 0.931 | 141.51 ± 3.35 | 141.00 (131.00–153.00) | −1.686 | 0.092 |
| Present | 139.88 ± 2.70 | 140.00 (130.00–147.00) | 140.79 ± 3.97 | 141.00 (128.00–156.00) | |||||
| WBC | Absent | 8.01 ± 8.35 | 7.05 (3.87–112.40) | −1.689 | 0.091 | 7.30 ± 2.11 | 7.10 (3.80–178.00) | −0.902 | 0.367 |
| Present | 7.77 ± 2.47 | 7.43 (2.30–27.71) | 7.67± 2.52 | 7.15 (3.70–18.00) | |||||
| Lymph | Absent | 31.03 ± 10.104 | 30.71 (3.37–86.38) | −0.474 | 0.636 | 34.39 ± 9.533 | 34.00 (9.00–60.00) | −2.171 | 0.030 |
| Present | 30.56 ± 8.84 | 30.29 (1.58–73.87) | 31.60 ± 10.06 | 31.50 (7.00–60.00) | |||||
| Neut | Absent | 59.58 ± 10.15 | 59.28 (9.06–90.08) | −0.623 | 0.533 | 58.16 ± 9.817 | 58 (32.00–89.00) | −2.156 | 0.031 |
| Present | 59.83 ± 9.41 | 60.28 (3.27–87.78) | 60.95 ± 10.24 | 60 (33.00–86.00) | |||||
| PLT | Absent | 234.33 ± 65.65 | 227.50 (60.00–492.00) | −1.401 | 0.161 | 230.56 ± 76.02 | 217.00 (129.00–742.00) | −1.203 | 0.229 |
| Present | 246.19 ± 82.62 | 235.00 (79.00–778.00) | 217.83 ± 53.23 | 208.00 (25.00–410.00) | |||||
| EF-TTE | Absent | 59.42 ± 5.51 | 60.00 (30.00–68.00) | −3.450 | 0.001 | 50.52 ± 8.04 | 55.00 (15.00–60.00) | −5.238 | <0.001 |
| Present | 56.81 ± 8.05 | 60.00 (30.00–72.00) | 45.91 ± 8.94 | 45.50 (15.00–60.00) | |||||
| Variables | NEU Hospital | Z-Alizadeh Sani | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Absent | Present | Χ2 | p | Absent | Present | Χ2 | p | ||||||
| n | % | n | % | n | % | n | % | ||||||
| Sex | Female | 47 | 31.8 | 101 | 68.2 | 1.521 | 0.217 | 41 | 32.30% | 86 | 67.7 | 1.362 | 0.243 |
| Male | 123 | 37.6 | 204 | 62.4 | 46 | 26.10% | 130 | 73.9 | |||||
| DM | No | 137 | 38.0 | 224 | 62.0 | 3.056 | 0.080 | 77 | 36.20% | 136 | 63.8 | 19.379 | <0.001 |
| Yes | 33 | 28.9 | 81 | 71.1 | 10 | 11.10% | 80 | 88.9 | |||||
| HT | No | 97 | 37.5 | 162 | 62.5 | 0.685 | 0.408 | 55 | 44.40% | 69 | 55.6 | 25.090 | <0.001 |
| Yes | 73 | 33.8 | 143 | 66.2 | 32 | 17.90% | 147 | 82.1 | |||||
| Current Smoker | No | 134 | 39.9 | 202 | 60.1 | 8.364 | 0.004 | 73 | 30.40% | 167 | 69.6 | 1.637 | 0.201 |
| Yes | 36 | 25.9 | 103 | 74.1 | 14 | 22.20% | 49 | 77.8 | |||||
| FH | No | 151 | 36.8 | 259 | 63.2 | 1.410 | 0.235 | 75 | 29.40% | 180 | 70.6 | 0.384 | 0.535 |
| Yes | 19 | 29.2 | 46 | 70.8 | 12 | 25.00% | 36 | 75.0 | |||||
| Edema | No | 168 | 36.5 | 292 | 63.5 | 3.399 | 0.065 | 85 | 29.20% | 206 | 70.8 | 0.886 | 0.519 |
| Yes | 2 | 13.3 | 13 | 86.7 | 2 | 16.70% | 10 | 83.3 | |||||
| Systolic Murmur | No | 168 | 36.8 | 288 | 63.2 | 5.497 | 0.019 | 75 | 28.60% | 187 | 71.4 | 0.007 | 0.933 |
| Yes | 2 | 10.5 | 17 | 89.5 | 12 | 29.30% | 29 | 70.7 | |||||
| Chest Pain | No | 141 | 54.4 | 118 | 45.6 | 86.212 | <0.001 | 77 | 55.40% | 62 | 44.6 | 89.328 | <0.001 |
| Yes | 29 | 13.4 | 187 | 86.6 | 10 | 6.10% | 154 | 93.9 | |||||
| Dyspnea | No | 158 | 39.5 | 242 | 60.5 | 15.178 | <0.001 | 40 | 23.70% | 129 | 76.3 | 4.750 | 0.029 |
| Yes | 12 | 16.0 | 63 | 84.0 | 47 | 35.10% | 87 | 64.9 | |||||
| LVH | No | 150 | 37.3 | 252 | 62.7 | 2.644 | 0.104 | 83 | 29.30% | 200 | 70.7 | 0.794 | 0.373 |
| Yes | 20 | 27.4 | 53 | 72.6 | 4 | 20.00% | 16 | 80.0 | |||||
| Region RWMA | No | 161 | 39.8 | 244 | 60.2 | 18.788 | <0.001 | 83 | 38.20% | 134 | 61.8 | 33.966 | <0.001 |
| Yes | 9 | 12.9 | 61 | 87.1 | 4 | 4.70% | 82 | 95.3 | |||||
| VHD | No | 107 | 36.3 | 188 | 63.7 | 0.079 | 0.779 | 40 | 34.5% | 76 | 65.5 | 3.057 | 0.080 |
| Yes | 63 | 35.0 | 117 | 65.0 | 47 | 25.1% | 140 | 74.9 | |||||
| Classifier | AUC | CA | F1 | Precision | Recall | |
|---|---|---|---|---|---|---|
| NEU Hospital Dataset (475) | kNN | 0.527 | 0.567 | 0.678 | 0.649 | 0.709 |
| SVM | 0.811 | 0.811 | 0.857 | 0.834 | 0.882 | |
| RF | 0.780 | 0.738 | 0.805 | 0.773 | 0.839 | |
| ANN | 0.798 | 0.754 | 0.813 | 0.794 | 0.834 | |
| Naïve Bayes | 0.758 | 0.710 | 0.772 | 0.782 | 0.762 | |
| LR | 0.813 | 0.765 | 0.820 | 0.807 | 0.834 | |
| Z-Alizadeh Sani Dataset (303) | kNN | 0.468 | 0.647 | 0.770 | 0.718 | 0.830 |
| SVM | 0.908 | 0.856 | 0.903 | 0.869 | 0.939 | |
| RF | 0.890 | 0.832 | 0.886 | 0.854 | 0.922 | |
| ANN | 0.896 | 0.844 | 0.892 | 0.880 | 0.904 | |
| Naïve Bayes | 0.914 | 0.845 | 0.889 | 0.906 | 0.873 | |
| LR | 0.924 | 0.865 | 0.907 | 0.895 | 0.919 | |
| Combined Dataset (778) | kNN | 0.522 | 0.605 | 0.722 | 0.682 | 0.767 |
| SVM | 0.826 | 0.786 | 0.847 | 0.813 | 0.833 | |
| RF | 0.815 | 0.776 | 0.839 | 0.807 | 0.875 | |
| ANN | 0.834 | 0.782 | 0.842 | 0.814 | 0.872 | |
| Naïve Bayes | 0.821 | 0.758 | 0.816 | 0.827 | 0.806 | |
| LR | 0.851 | 0.795 | 0.851 | 0.828 | 0.876 |
| Classifier | AUC | CA | F1 | Precision | Recall |
|---|---|---|---|---|---|
| kNN | 0.584 | 0.657 | 0.758 | 0.762 | 0.755 |
| SVM | 0.500 | 0.713 | 0.832 | 0.713 | 1.000 |
| RF | 0.795 | 0.776 | 0.858 | 0.780 | 0.954 |
| ANN | 0.498 | 0.287 | - | - | - |
| Naïve Bayes | 0.861 | 0.756 | 0.850 | 0.755 | 0.972 |
| LR | 0.479 | 0.287 | - | - | - |
| Classifier | AUC | CA | F1 | Precision | Recall |
|---|---|---|---|---|---|
| kNN | 0.512 | 0.642 | 0.782 | 0.642 | 1.000 |
| SVM | 0.763 | 0.716 | 0.810 | 0.709 | 0.944 |
| RF | 0.777 | 0.737 | 0.786 | 0.824 | 0.751 |
| ANN | 0.761 | 0.718 | 0.772 | 0.802 | 0.744 |
| Naïve Bayes | 0.729 | 0.686 | 0.749 | 0.771 | 0.728 |
| LR | 0.752 | 0.716 | 0.763 | 0.822 | 0.711 |
| Year | Disease | Dataset | Algorithms | Best Classifier (AUC) |
|---|---|---|---|---|
| 2021 [26] | CAD | NTPC, Taiwan and ILH, Taiwan | Decision tree, RF, SVM | RF (94%) |
| 2021 [27] | Cardiovascular Disease | University Federico II | ADA, AdaBoost, LR, Naïve Bayes, RF, Rpart, SVM, XGBoost | LR (75%) |
| 2021 [28] | CAD | General Hospitals in Kano | LR, SVM, kNN, RF, Naïve Bayes, Gradient Booting | RF (92.04%) |
| 2021 [29] | Cardiovascular Disease | UK Biobank | Naïve Bayes, RF, Lasso, Ridge, SVM, LR, Neural Network | RF (79.9%) |
| 2021 [30] | Cardiovascular Disease | Kazakh population in Xinjiang | DT, kNN, LR, Naïve Bayes, RF, SVM, XGB | LR (87.2%) |
| 2020 [31] | Cardiovascular Disease | Cleveland database of UCI repository, Statlog heart disease dataset. | Linear Regression, Multiple Linear Regression, Ridge Regression, Decision Tree, SVM, kNN, Naive Bayes | Naïve Bayes (83%) |
| AUC | Step 1 | Step 2 | Step 3 |
|---|---|---|---|
| Lower than 60% | kNN | kNN, SVM, ANN, LR | kNN |
| Higher than 75% | SVM, RF, ANN, Naïve Bayes, LR | RF, Naïve Bayes | SVM, RF, ANN, LR |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuvalı, M.; Yaman, B.; Tosun, Ö. Classification Comparison of Machine Learning Algorithms Using Two Independent CAD Datasets. Mathematics 2022, 10, 311. https://doi.org/10.3390/math10030311
Yuvalı M, Yaman B, Tosun Ö. Classification Comparison of Machine Learning Algorithms Using Two Independent CAD Datasets. Mathematics. 2022; 10(3):311. https://doi.org/10.3390/math10030311
Chicago/Turabian StyleYuvalı, Meliz, Belma Yaman, and Özgür Tosun. 2022. "Classification Comparison of Machine Learning Algorithms Using Two Independent CAD Datasets" Mathematics 10, no. 3: 311. https://doi.org/10.3390/math10030311
APA StyleYuvalı, M., Yaman, B., & Tosun, Ö. (2022). Classification Comparison of Machine Learning Algorithms Using Two Independent CAD Datasets. Mathematics, 10(3), 311. https://doi.org/10.3390/math10030311