
Local Linear Approximation Algorithm for Neural Network

Abstract
:1. Introduction
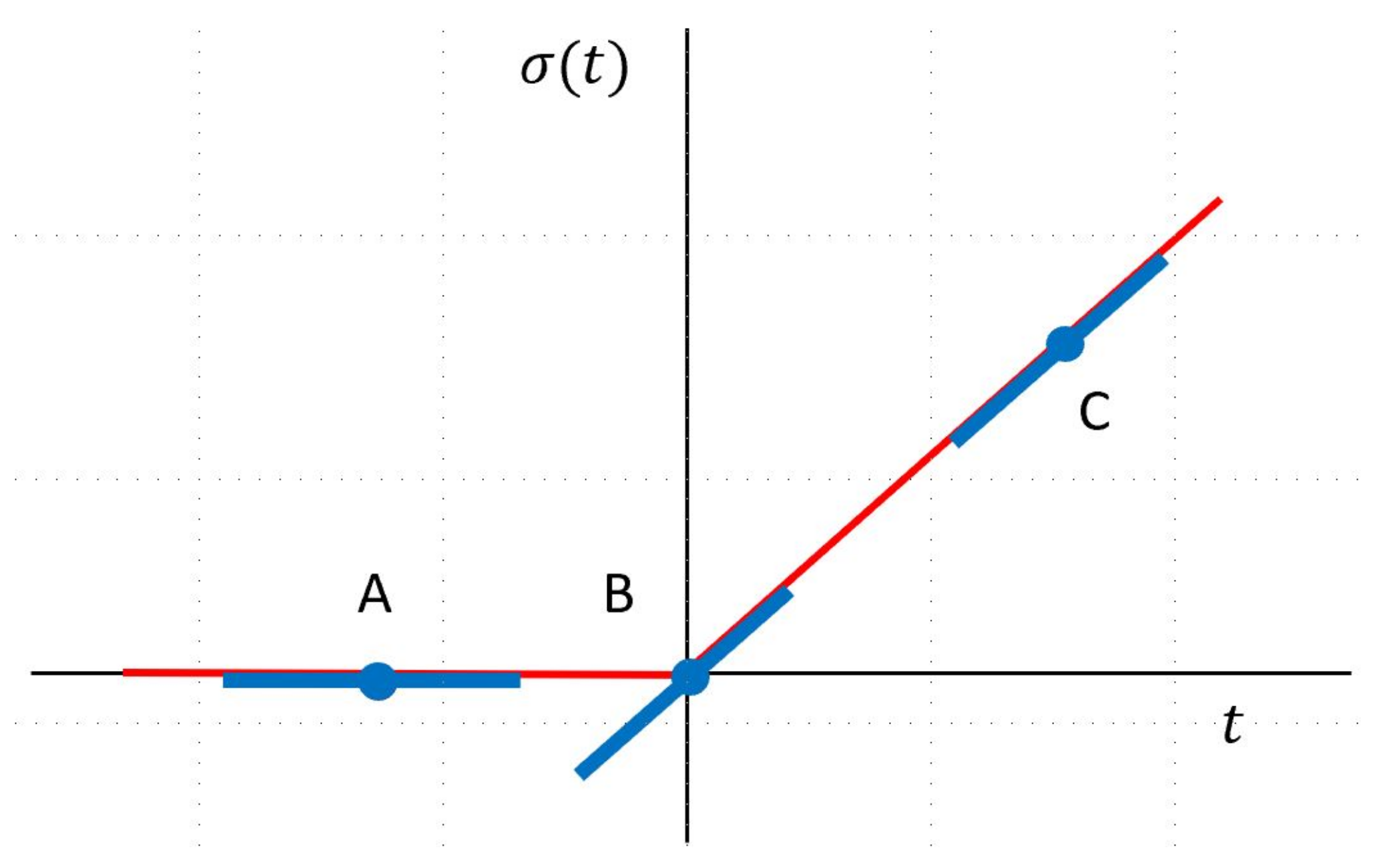
2. New Method for Constructing Neural Network
2.1. Regression Settings
| Algorithm 1 Local Linear Approximation (LLA) Algorithm for Regression |
Input: Given data and the number of nodes Initialization: Get initial values for and in Equation (14) Output: W and
|
2.2. Classification
2.2.1. Binary Classification
| Algorithm 2 Local Linear Approximation (LLA) Algorithm for Classification |
Input: Given data and number of nodes . Initialization: Get initial values for and defined in Equation (19). Output: W and
|
2.2.2. Extension to Multi-Class Classification
2.3. Layer-Wise Optimized Adaptive Neural Network
| Algorithm 3 Layerwise Optimized Adaptive Network (LOAN) |
Input: LOAN structure with being the number of nodes for the l-th layer. Initialization: Obtain the estimates of and in the first hidden layer by fitting the data with one-hidden-layer LLA in Algorithm 1. Set .
|
3. Numerical Comparison
- 1.
- 2.
- XGBoost [36] (python version 1.2.0)
- 3.
- 4.
- 5.
3.1. Regression Problems
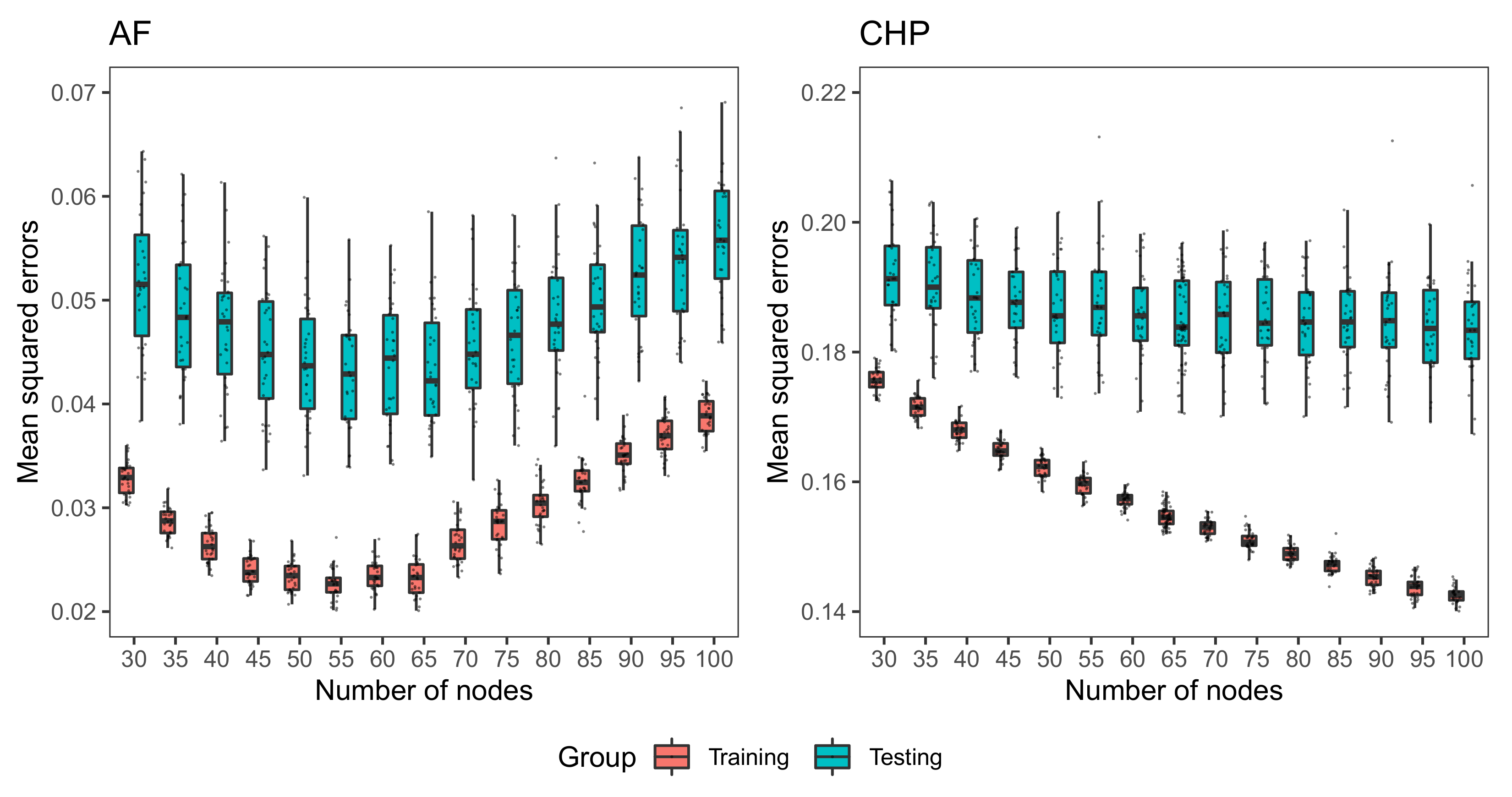
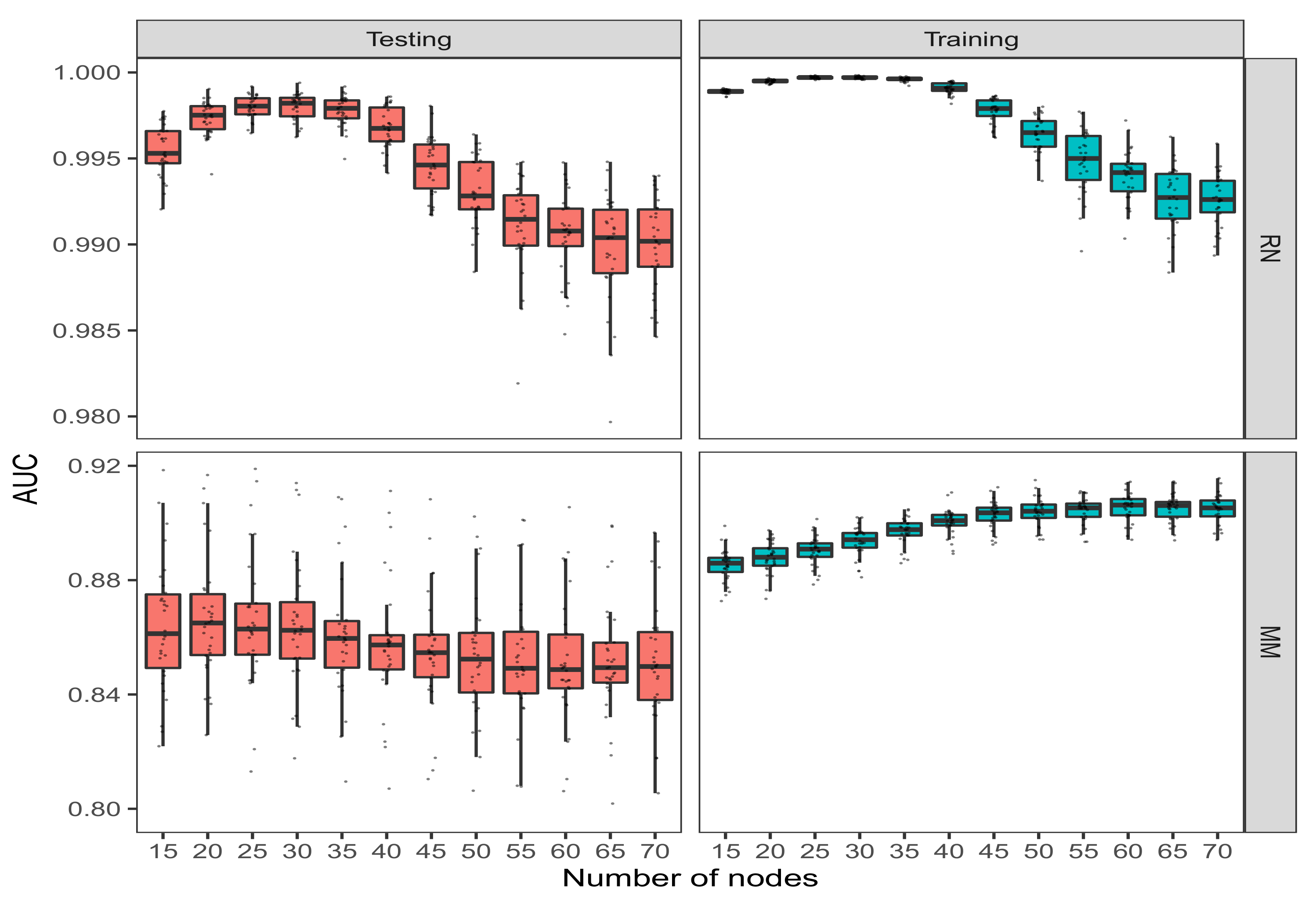
3.1.1. Impact of the Number of Nodes for Regression Problems
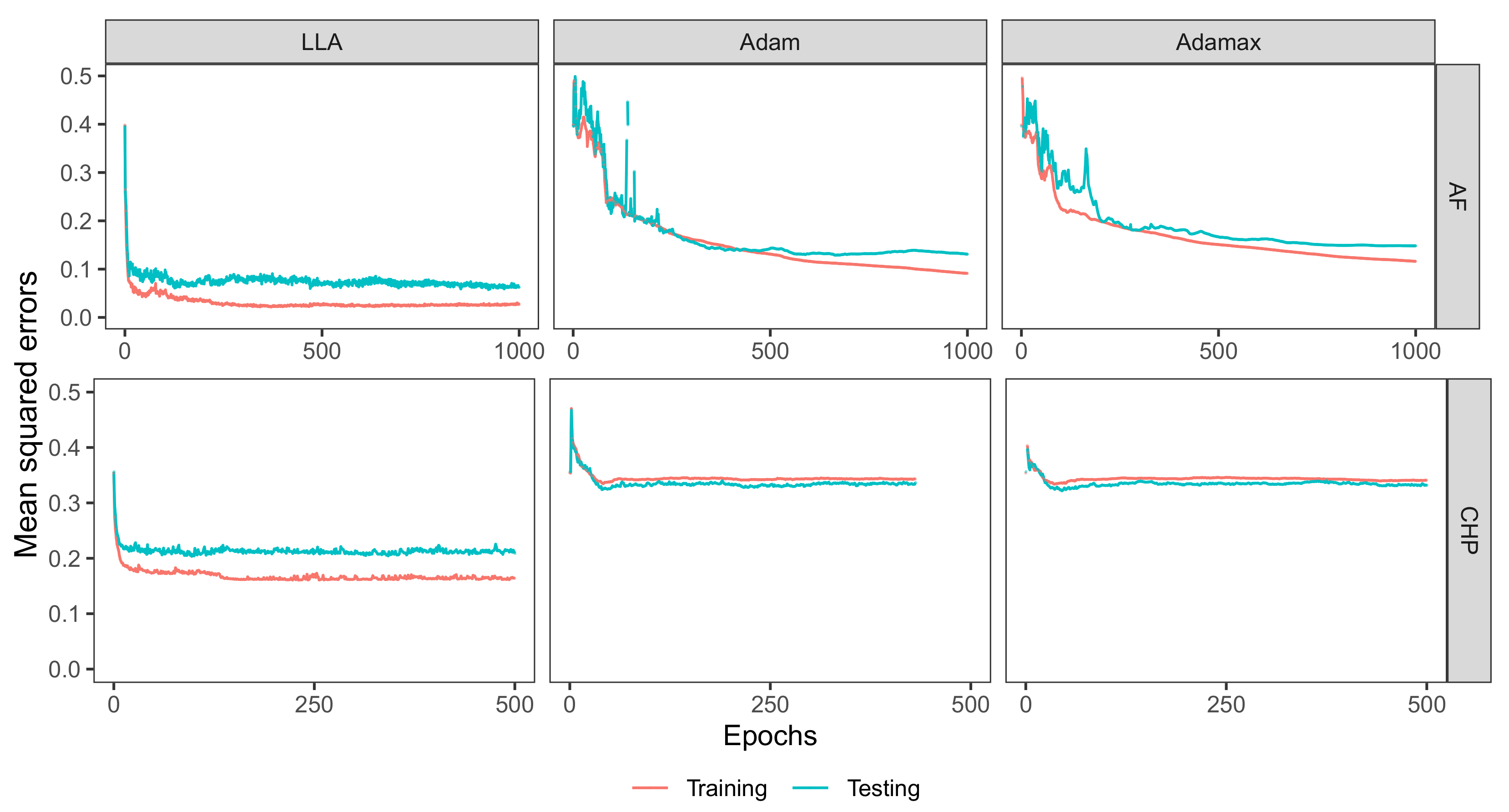
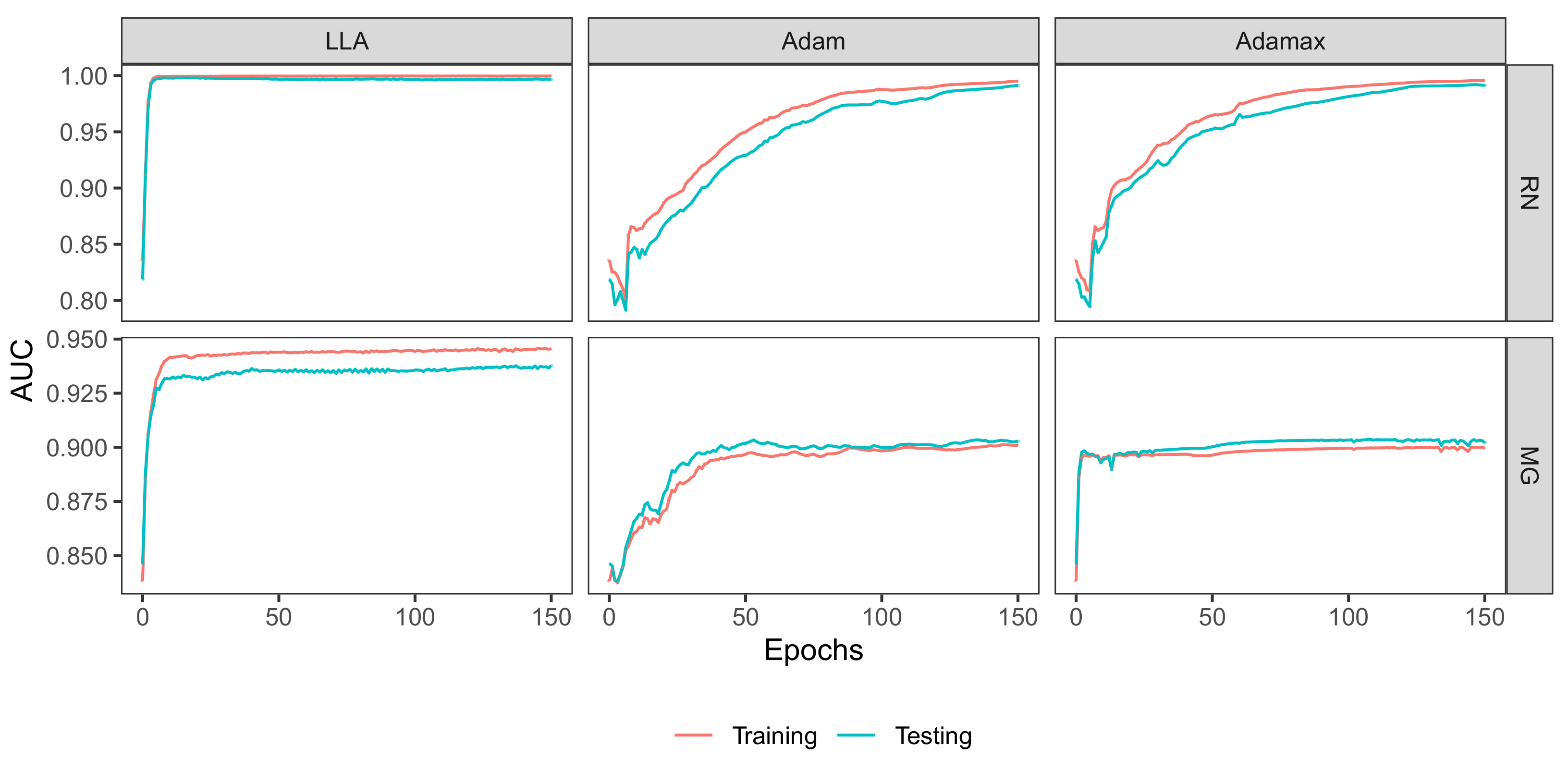
3.1.2. Comparison with Stochastic Gradient Algorithms
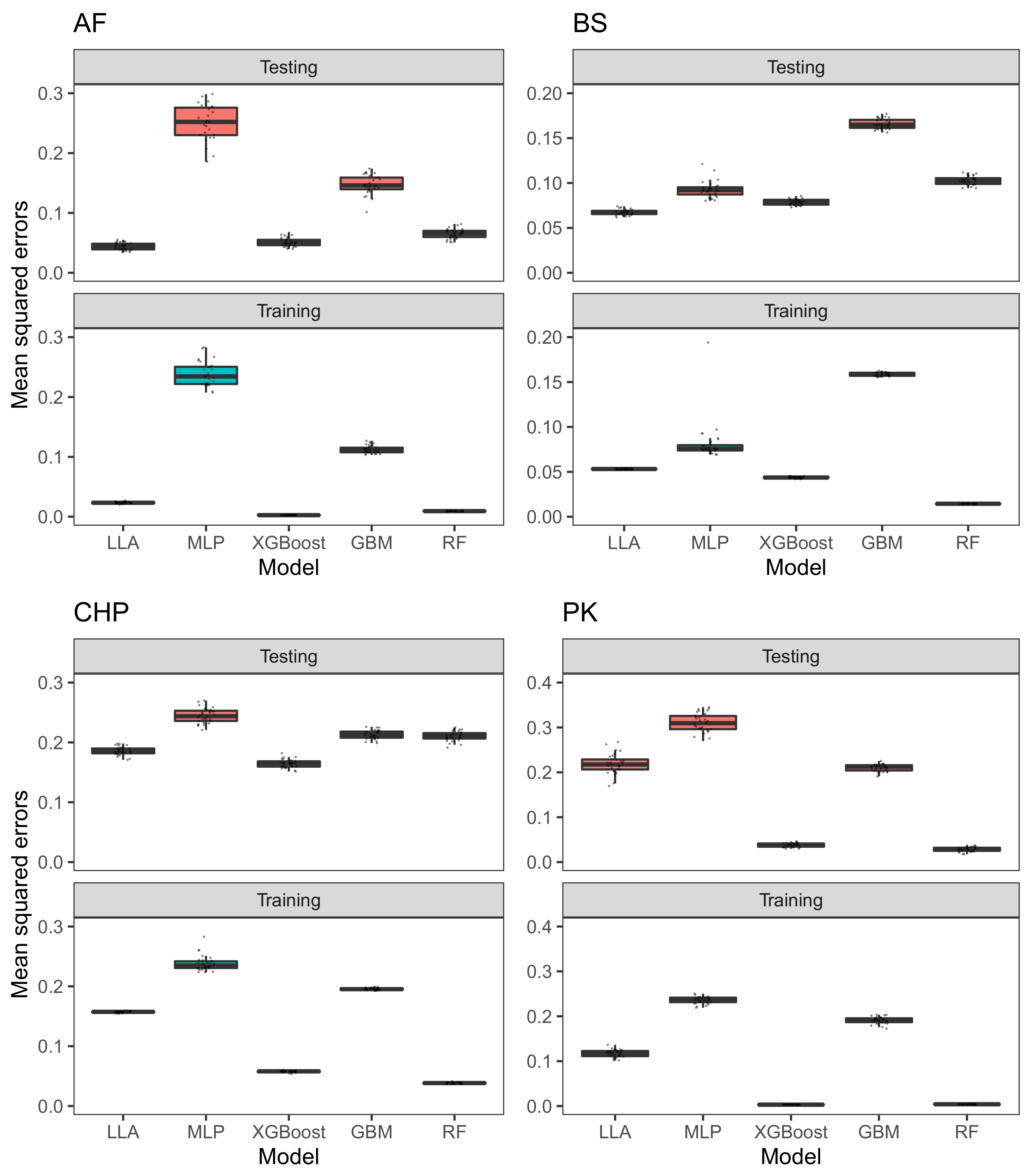
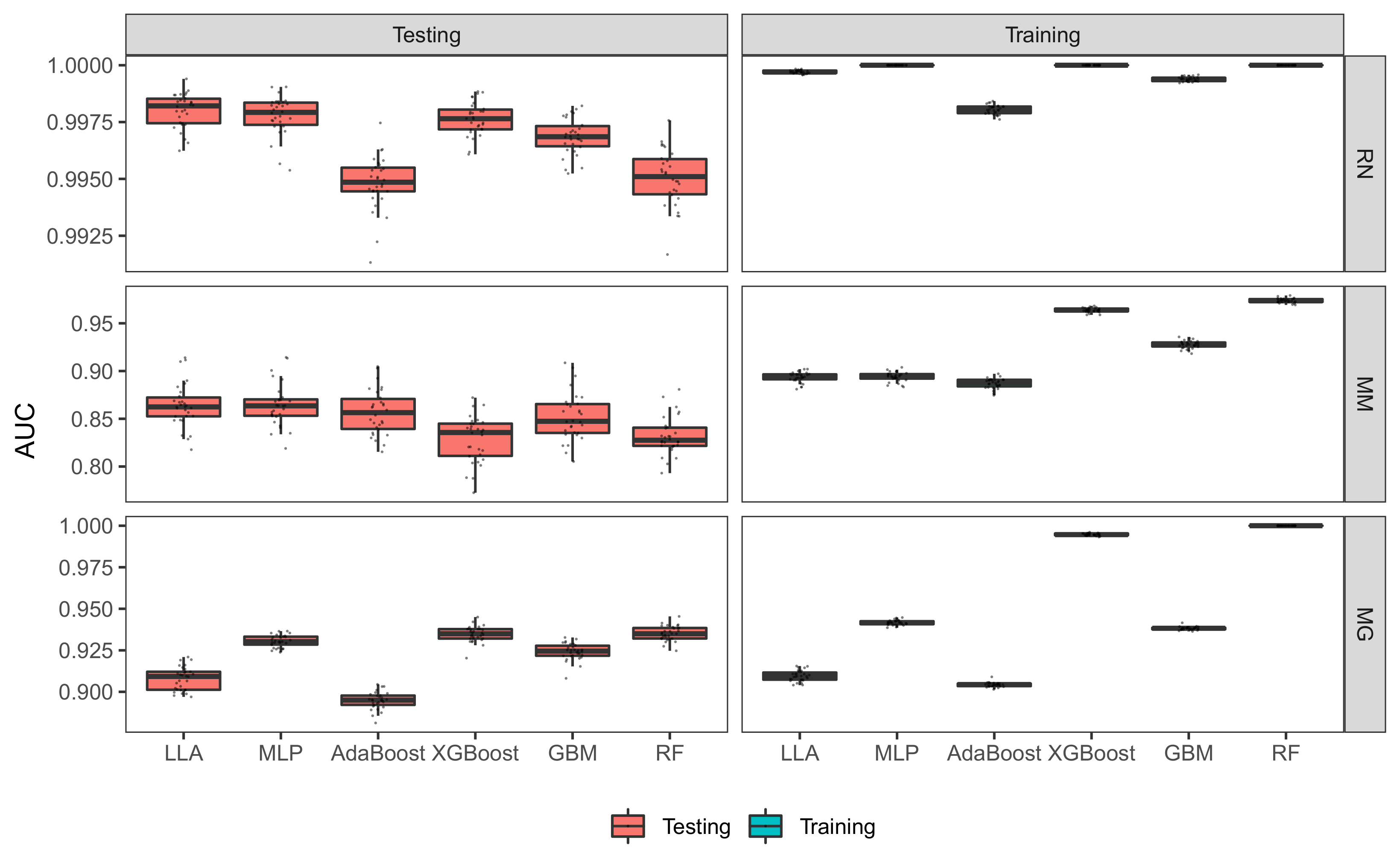
3.1.3. Performance of LLA in Regression Settings
3.2. Classification
3.2.1. Impact of the Number of Nodes for Classification Problems
3.2.2. Comparison with Stochastic Gradient Algorithms
3.2.3. Performance of LLA in Classification Problems
3.3. Analysis of Computational Time
3.4. Performance of Deep LOAN
4. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Theorem 1
Appendix A.2. Proof of Theorem 2
References
- Gardner, W.A. Learning characteristics of stochastic-gradient-descent algorithms: A general study, analysis, and critique. Signal Process. 1984, 6, 113–133. [Google Scholar] [CrossRef]
- Oymak, S.; Soltanolkotabi, M. Overparameterized nonlinear learning: Gradient descent takes the shortest path? In Proceedings of the 36th International Conference on Machine Learning (ICML), PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 4951–4960. [Google Scholar]
- Ali, A.; Dobriban, E.; Tibshirani, R. The implicit regularization of stochastic gradient flow for least squares. In Proceedings of the 37th International Conference on Machine Learning (ICML), PMLR, Virtual, 13–18 July 2020; pp. 233–244. [Google Scholar]
- Douglas, S.; Meng, T.Y. Linearized least-squares training of multilayer feedforward neural networks. In Proceedings of the IJCNN-91-Seattle International Joint Conference on Neural Networks, Seattle, WA, USA, 8–12 July 1991; Volume 1, pp. 307–312. [Google Scholar] [CrossRef]
- Singhal, S.; Wu, L. Training multilayer perceptrons with the extende kalman algorithm. Adv. Neural Inf. Process. Syst. 1988, 1, 133–140. [Google Scholar]
- Stan, O.; Kamen, E. A local linearized least squares algorithm for training feedforward neural networks. IEEE Trans. Neural Netw. 2000, 11, 487–495. [Google Scholar] [CrossRef] [PubMed]
- Kollias, S.; Anastassiou, D. An adaptive least squares algorithm for the efficient training of artificial neural networks. IEEE Trans. Circuits Syst. 1989, 36, 1092–1101. [Google Scholar] [CrossRef]
- Ngia, L.S.; Sjoberg, J. Efficient training of neural nets for nonlinear adaptive filtering using a recursive Levenberg-Marquardt algorithm. IEEE Trans. Signal Process. 2000, 48, 1915–1927. [Google Scholar] [CrossRef]
- Kim, C.T.; Lee, J.J. Training two-layered feedforward networks with variable projection method. IEEE Trans. Neural Netw. 2008, 19, 371–375. [Google Scholar]
- Zhou, G.; Si, J. Advanced neural-network training algorithm with reduced complexity based on Jacobian deficiency. IEEE Trans. Neural Netw. 1998, 9, 448–453. [Google Scholar] [CrossRef] [PubMed]
- Maddox, W.; Tang, S.; Moreno, P.; Wilson, A.G.; Damianou, A. Fast adaptation with linearized neural networks. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 13–15 April 2021; Volume 130, pp. 2737–2745. [Google Scholar]
- Khan, M.E.; Immer, A.; Abedi, E.; Korzepa, M. Approximate inference turns deep networks into Gaussian processes. arXiv 2019, arXiv:1906.01930. [Google Scholar]
- Mu, F.; Liang, Y.; Li, Y. Gradients as features for deep representation learning. In Proceedings of the 8th International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Jacot, A.; Gabriel, F.; Hongler, C. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 8571–8580. [Google Scholar]
- Martens, J. Deep learning via hessian-free optimization. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 735–742. [Google Scholar]
- Kunstner, F.; Balles, L.; Hennig, P. Limitations of the empirical fisher approximation for natural gradient descent. arXiv 2020, arXiv:1905.12558v3. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Efficient and effective algorithms for training single-hidden-layer neural networks. Pattern Recognit. Lett. 2012, 33, 554–558. [Google Scholar] [CrossRef]
- Kurita, T. Iterative weighted least squares algorithms for neural networks classifiers. New Gener. Comput. 1994, 12, 375–394. [Google Scholar] [CrossRef]
- Martens, J. New Insights and Perspectives on the Natural Gradient Method. J. Mach. Learn. Res. 2020, 21, 1–76. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. Adv. Neural Inf. Process. Syst. 2007, 19, 153. [Google Scholar]
- Bengio, Y.; Delalleau, O. Justifying and generalizing contrastive divergence. Neural Comput. 2009, 21, 1601–1621. [Google Scholar] [CrossRef]
- Hinton, G.E. Learning multiple layers of representation. Trends Cogn. Sci. 2007, 11, 428–434. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G. Deep boltzmann machines. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, PMLR, Clearwater Beach, FL, USA, 16–18 April 2009; Volume 5, pp. 448–455. [Google Scholar]
- Jaderberg, M.; Czarnecki, W.M.; Osindero, S.; Vinyals, O.; Graves, A.; Silver, D.; Kavukcuoglu, K. Decoupled neural interfaces using synthetic gradients. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1627–1635. [Google Scholar]
- Chen, S.; Wang, W.; Pan, S.J. Deep neural network quantization via layer-wise optimization using limited training data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3329–3336. [Google Scholar]
- Shin, Y. Effects of depth, width, and initialization: A convergence analysis of layer-wise training for deep linear neural networks. arXiv 2019, arXiv:1910.05874. [Google Scholar] [CrossRef]
- Song, Y.; Meng, C.; Liao, R.; Ermon, S. Nonlinear equation solving: A faster alternative to feedforward computation. arXiv 2020, arXiv:2002.03629. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980v9. [Google Scholar]
- Pal, S.K.; Mitra, S. Multilayer perceptron, fuzzy sets, classifiaction. IEEE Trans. Neural Netw. 1992, 3, 683–697. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pace, R.K.; Barry, R. Sparse spatial autoregressions. Stat. Probab. Lett. 1997, 33, 291–297. [Google Scholar] [CrossRef]
- Breiman, L. Bias, Variance, and Arcing Classifiers; Technical Report, 460; Statistics Department, University of California: Berkeley, CA, USA, 1996. [Google Scholar]
- Heck, D.; Knapp, J.; Capdevielle, J.; Schatz, G.; Thouw, T. CORSIKA: A Monte Carlo code to simulate extensive air showers. Rep. Fzka 1998, 6019, 5–8. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | AF | BS | CHP | PK |
|---|---|---|---|---|
| 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | |
| MSE for Testing Data | ||||
| LLA | 4.3317 (0.5895) | 6.7291 (0.2957) | 18.5801 (0.6955) | 22.8113 (5.4049) |
| MLP | 25.4913 (3.4600) | 9.9173 (2.0827) | 24.1495 (1.0754) | 31.4595 (2.3832) |
| XGBoost | 5.1042 (0.7245) | 7.8751 (0.3137) | 16.4491 (0.6905) | 3.7880 (0.4386) |
| AdaBoost | 31.7242 (2.6197) | 27.7419 (0.7384) | 56.3744 (5.3267) | 60.9171 (1.8358) |
| GBM | 14.7338 (1.5846) | 16.5968 (0.5592) | 21.2866 (0.7254) | 21.0340 (0.7685) |
| RF | 6.5254 (0.7346) | 10.2843 (0.4672) | 21.2067 (0.9217) | 2.8041 (0.4835) |
| MSE for Training Data | ||||
| LLA | 2.3213 (0.1634) | 5.3265 (0.0828) | 15.7216 (0.1275) | 11.7173 (0.8164) |
| MLP | 24.5284 (0.0268) | 7.7488 (0.7496) | 23.7055 (1.1570) | 23.7447 (1.3502) |
| XGBoost | 0.2623 (0.0268) | 4.3713 (0.0946) | 5.7634 (0.1456) | 0.3115 (0.0264) |
| AdaBoost | 29.2881 (1.1124) | 27.2715 (0.6059) | 55.8631 (5.5463) | 60.4119 (1.1948) |
| GBM | 11.2280 (0.6303) | 15.8681 (0.1972) | 19.5493 (0.1864) | 19.0881 (0.7516) |
| RF | 0.9366 (0.0388) | 1.4413 (0.0179) | 3.8432 (0.0766) | 0.3897 (0.0356) |
| Methods | 6 PCs | 9 PCs | 13 PCs | All (19) PCs |
|---|---|---|---|---|
| 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | |
| MSE for Testing Data | ||||
| LLA | 23.1102 (2.1758) | 9.3551 (0.9400) | 10.2220 (1.1961) | 22.2247 (3.0623) |
| MLP | 41.7293 (2.6673) | 34.7943 (2.3511) | 30.6869 (2.1018) | 30.6617 (2.9831) |
| XGBoost | 50.8823 (3.2462) | 47.1367 (2.7843) | 42.9631 (2.6408) | 44.4751 (2.1000) |
| AdaBoost | 81.2930 (2.6109) | 78.9303 (2.7339) | 76.2363 (2.2727) | 76.5351 (2.5682) |
| GBM | 67.0713 (2.3618) | 62.4927 (2.2980) | 59.1466 (1.8239) | 59.7928 (1.9610) |
| RF | 41.2433 (2.8571) | 39.6862 (2.6231) | 37.7282 (2.5413) | 39.9511 (2.5392) |
| MSE for Training Data | ||||
| LLA | 17.0868 (1.2977) | 5.8743 (0.3081) | 5.8837 (0.5092) | 11.7854 (0.8391) |
| MLP | 37.1915 (1.8439) | 27.9013 (0.9417) | 22.0252 (0.9036) | 20.5078 (0.9063) |
| XGBoost | 10.0009 (0.7694) | 6.6056 (0.4240) | 4.0770 (0.3162) | 2.9568 (0.2952) |
| AdaBoost | 79.1353 (2.3975) | 76.3020 (2.1195) | 73.5840 (2.0781) | 73.5073 (2.3712) |
| GBM | 59.1133 (1.5346) | 53.7506 (1.1314) | 49.5714 (0.9834) | 49.4500 (0.9870) |
| RF | 5.9341 (0.2602) | 5.6795 (0.1998) | 5.3804 (0.2432) | 5.6393 (0.2185) |
| Methods | RN | MM | MG |
|---|---|---|---|
| 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | |
| AUC Scores for Testing Data | |||
| LLA | 99.8007 (0.0750) | 86.4075 (2.3068) | 90.7903 (0.6989) |
| MLP | 99.7777 (0.0856) | 86.3424 (2.1636) | 93.0479 (0.3572) |
| XGBoost | 99.7641 (0.0723) | 82.8425 (2.4301) | 93.4792 (0.4691) |
| AdaBoost | 99.4795 (0.1202) | 85.6732 (2.3398) | 89.4802 (0.5192) |
| GBM | 99.6859 (0.0793) | 85.2137 (2.5059) | 92.4214 (0.5086) |
| RF | 99.5045 (0.1249) | 83.2001 (1.9674) | 93.5235 (0.4453) |
| AUC Scores for Training Data | |||
| LLA | 99.9705 (0.0072) | 89.3458 (0.5252) | 90.9545 (0.3217) |
| MLP | 100.0000 (0.0000) | 89.4176 (0.4736) | 94.1618 (0.1429) |
| XGBoost | 100.0000 (0.0000) | 96.3674 (0.2275) | 99.4716 (0.0675) |
| AdaBoost | 99.8049 (0.0199) | 88.7022 (0.5184) | 90.4314 (0.1327) |
| GBM | 99.9389 (0.0097) | 92.7635 (0.4055) | 93.8208 (0.0975) |
| RF | 100.0000 (0.0000) | 97.3740 (0.2280) | 100.0000 (0.0000) |
| Data | LLA | Adam | Adamax | |
|---|---|---|---|---|
| AF | MSE (std) | 4.6 (0.6) | 25.2 (4.0) | 24.3 (3.2) |
| Time (std) | 207.3 (12.6) | 58.8 (5.1) | 49.3 (5.2) | |
| CHP | MSE (std) | 18.8 (0.7) | 24.9 (1.2) | 23.8 (0.1) |
| Time (std) | 998.9 (190.1) | 407.3 (80.6) | 397.2 (77.4) | |
| RN | AUC (std) | 99.8 (0.1) | 99.6 (0.2) | 99.6 (0.0) |
| Time (std) | 101.2 (1.7) | 26.8 (1.4) | 24.1 (0.9) | |
| MG | AUC (std) | 91.8 (0.7) | 91.9 (0.0) | 91.7 (0.1) |
| Time (std) | 122.8 (2.3) | 68.0 (2.9) | 59.1 (3.9) |
| Methods | |||
|---|---|---|---|
| 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | |
| MSE for Testing Data | |||
| LOAN | 18.580 (0.696) | 18.016 (0.674) | 17.524 (0.653) |
| MLP | 22.538 (0.967) | 20.627 (0.896) | 20.232 (0.876) |
| XGBoost | 28.537 (0.777) | 20.796 (0.661) | 18.340 (0.652) |
| GBM | 35.532 (0.869) | 24.591 (0.745) | 21.287 (0.726) |
| RF | 66.745 (1.496) | 53.697 (1.151) | 43.940 (1.096) |
| MSE for Training Data | |||
| LOAN | 15.722 (0.128) | 14.365 (0.243) | 12.555 (0.157) |
| MLP | 21.272 (0.656) | 18.353 (0.472) | 16.737 (0.543) |
| XGBoost | 27.909 (0.183) | 19.150 (0.242) | 15.127 (0.167) |
| GBM | 35.161 (0.196) | 23.762 (0.210) | 19.549 (0.186) |
| RF | 66.707 (0.609) | 53.538 (0.333) | 43.483 (0.329) |
| Methods | |||
|---|---|---|---|
| 100 × Mean (Std) | 100 × Mean (Std) | 100 × Mean (Std) | |
| AUC for Testing Data | |||
| LLA | 90.7903 (0.6989) | 93.8978 (0.3857) | 94.3385 (0.3556) |
| MLP | 92.6980 (0.3915) | 93.0171 (0.4185) | 92.8342 (0.5058) |
| XGBoost | 89.5843 (0.6247) | 92.4452 (0.4989) | 93.2186 (0.4459) |
| GBM | 87.8336 (0.6711) | 91.4000 (0.5723) | 92.4214 (0.5087) |
| RF | 82.2163 (1.1715) | 86.5378 (0.6972) | 87.6666 (0.6656) |
| AUC for Training Data | |||
| LLA | 90.9545 (0.3217) | 95.2309 (0.1458) | 96.9006 (0.1088) |
| MLP | 93.3201 (0.1632) | 94.7166 (0.1804) | 95.6310 (0.2325) |
| XGBoost | 90.2653 (0.1400) | 93.8429 (0.1111) | 95.6249 (0.0967) |
| GBM | 88.2751 (0.1475) | 92.2619 (0.1215) | 93.8208 (0.0975) |
| RF | 82.4167 (0.6175) | 86.8213 (0.2831) | 88.0429 (0.1949) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, M.; Liao, Y.; Li, R.; Sudjianto, A. Local Linear Approximation Algorithm for Neural Network. Mathematics 2022, 10, 494. https://doi.org/10.3390/math10030494
Zeng M, Liao Y, Li R, Sudjianto A. Local Linear Approximation Algorithm for Neural Network. Mathematics. 2022; 10(3):494. https://doi.org/10.3390/math10030494
Chicago/Turabian StyleZeng, Mudong, Yujie Liao, Runze Li, and Agus Sudjianto. 2022. "Local Linear Approximation Algorithm for Neural Network" Mathematics 10, no. 3: 494. https://doi.org/10.3390/math10030494
APA StyleZeng, M., Liao, Y., Li, R., & Sudjianto, A. (2022). Local Linear Approximation Algorithm for Neural Network. Mathematics, 10(3), 494. https://doi.org/10.3390/math10030494