
Multiscale Balanced-Attention Interactive Network for Salient Object Detection


Abstract
:1. Introduction and Background
- An interactive residual model (IRM) was designed to capture the semantic information of multiscale features. The IRM can extract multiscale information adaptively from the samples and can deal with the scale changes better.
- We proposed a balanced-attention model (BAM), which not only captures the dependence between different features of a single sample, but considers the potential correlation between different samples, which improves the generalization ability of attention mechanism.
- To effectively fuse the output of IRMs and BAM cascade structure, an improved bi-directional propagation strategy was adopted, which can fully capture contextual in-formation of different scales, thereby improving detection performance.
2. Proposed Method
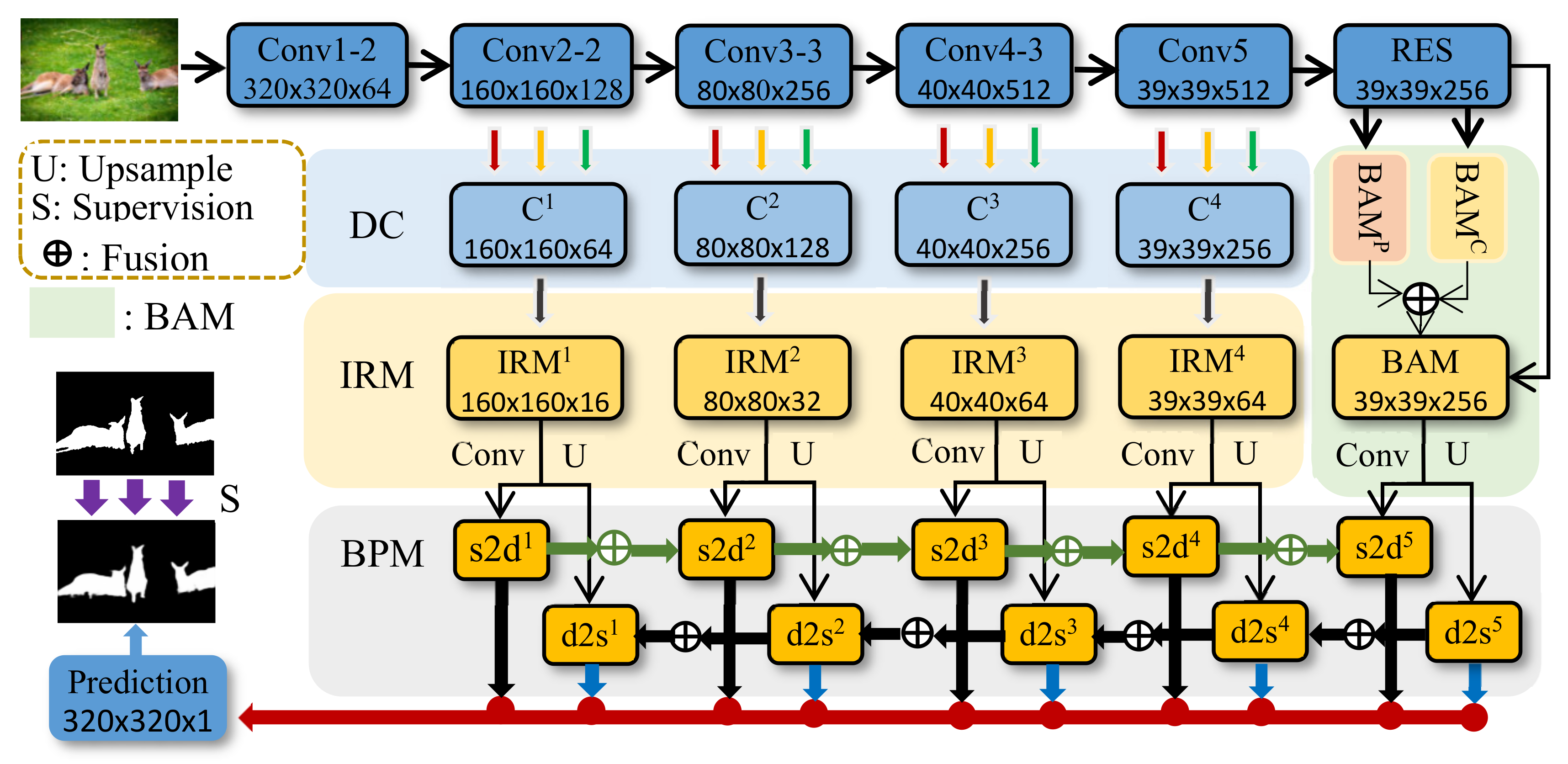
2.1. Network Architecture
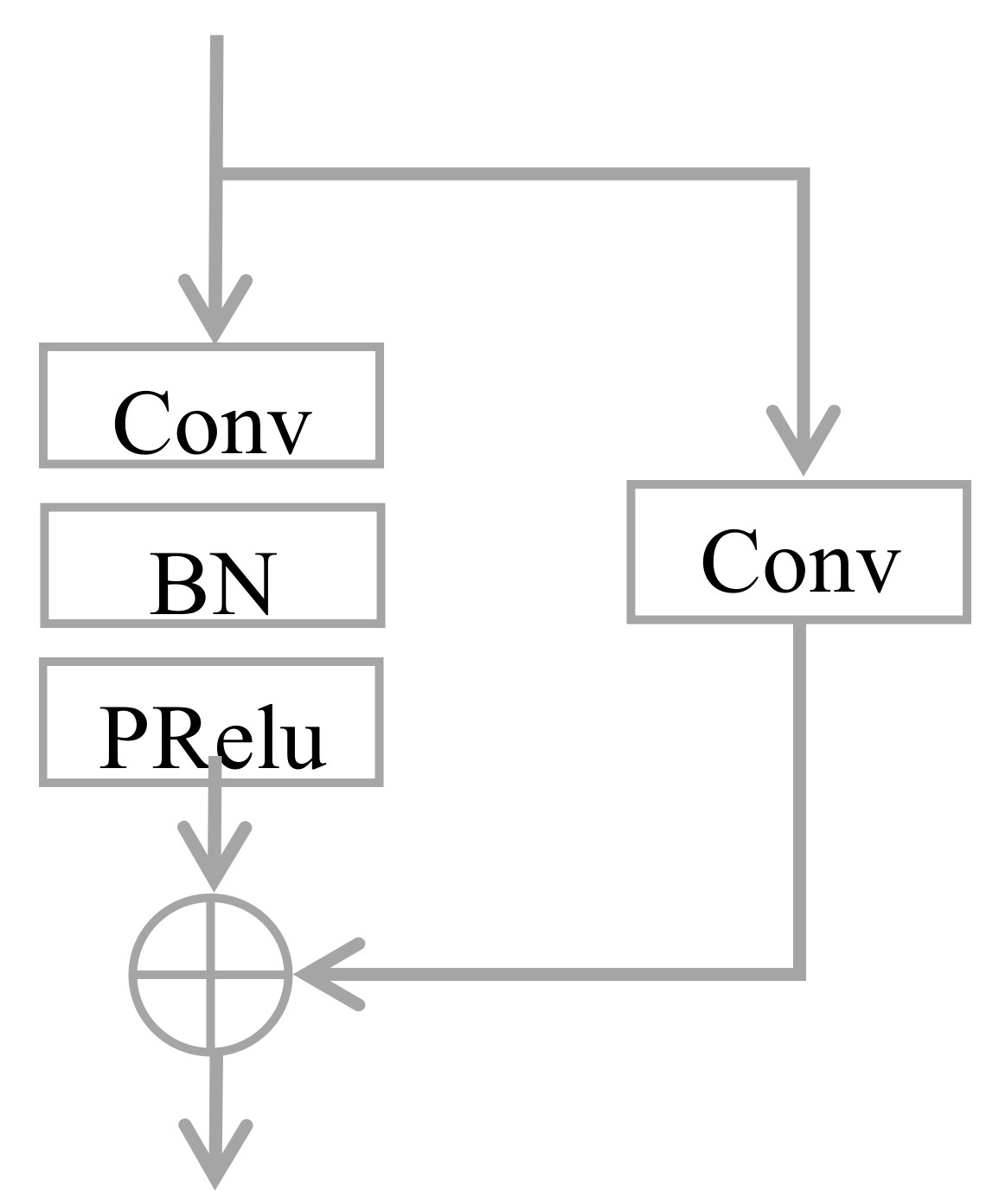
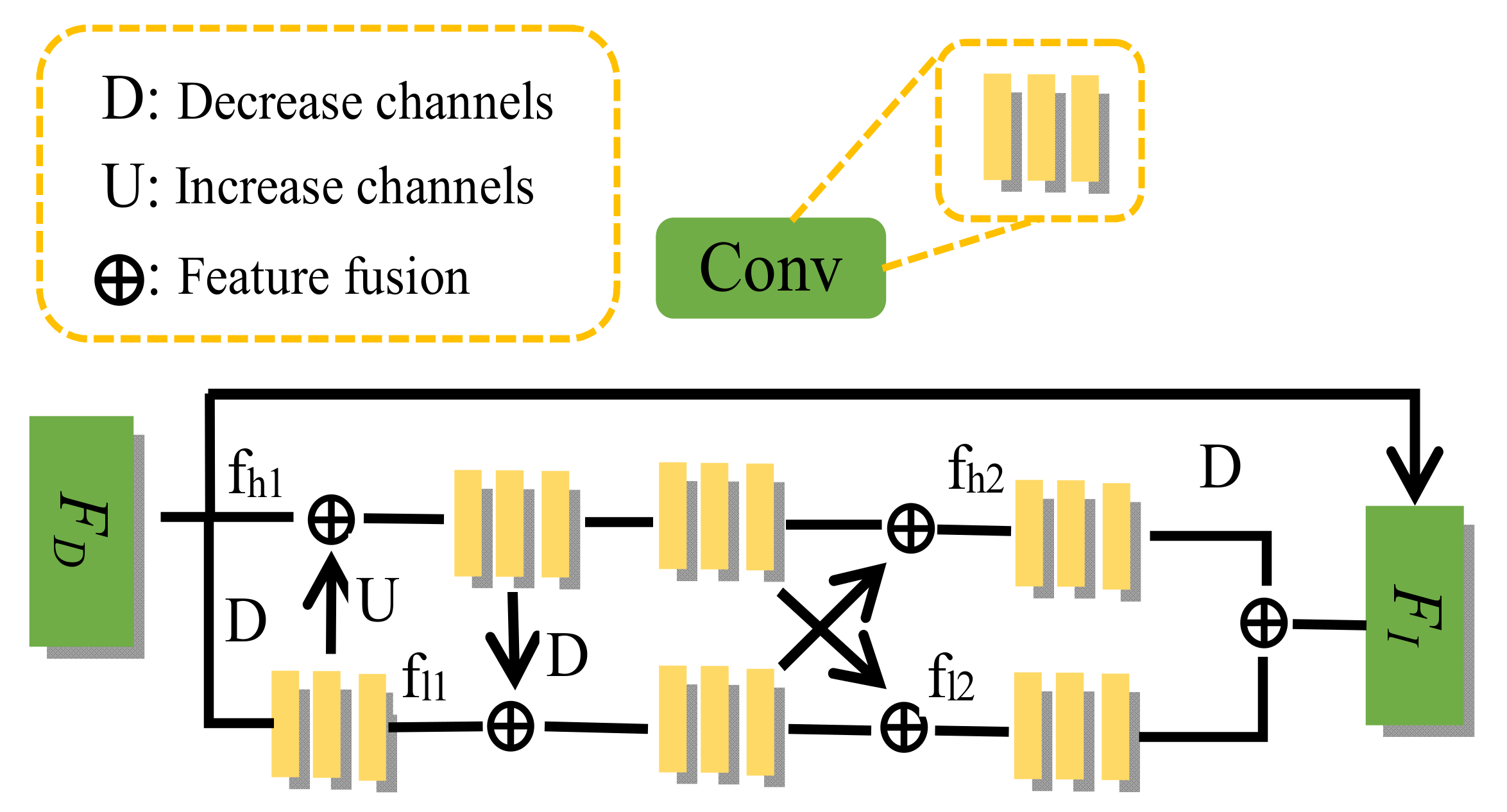
2.2. Interactive Residual Model
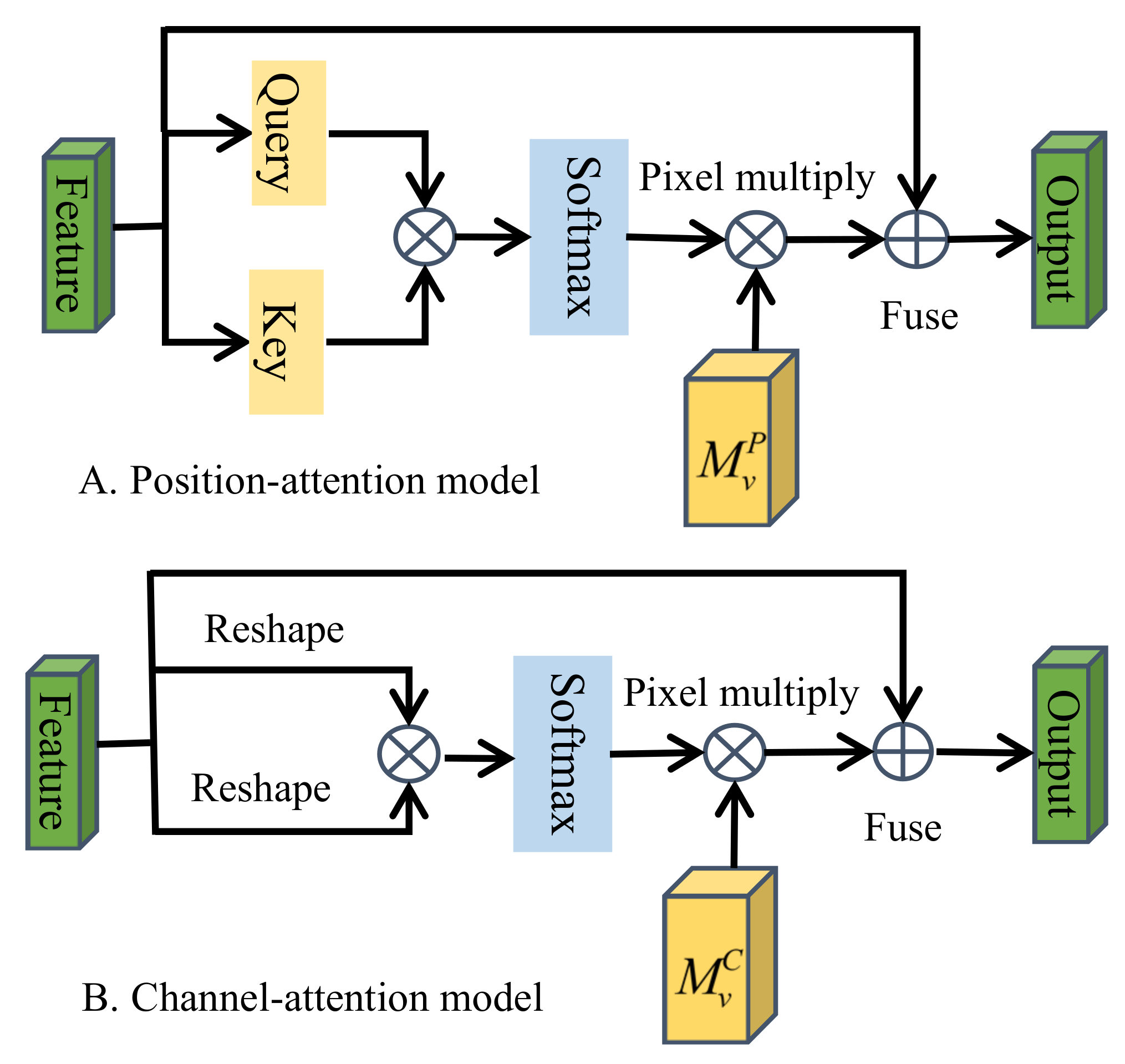
2.3. Balanced-Attention Model
2.4. Model Interaction and Integration
3. Experiment
3.1. Experimental Setup
3.2. Ablation Studies
3.3. Comparison with State-of-the-Art
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gkelios, S.; Sophokleous, A.; Plakias, S.; Boutalis, Y.; Chatzichristofis, S. Deep convolutional features for image retrieval. Expert Syst. Appl. 2021, 177, 114940. [Google Scholar] [CrossRef]
- Radenović, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, X.; Li, E.; Fu, Z. Residual Attention Siamese RPN for Visual Tracking. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Nanjing, China, 16–18 October 2020. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Liu, Y.; Han, J.; Zhang, Q.; Shan, C. Deep Salient Object Detection with Contextual Information Guidance. IEEE Trans. Image Process. 2019, 29, 360–374. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W.; Chen, C.W. Automatic contrast enhancement technology with saliency preservation. IEEE Trans. Circ. Syst. Video Technol. 2015, 25, 1480–1494. [Google Scholar] [CrossRef]
- Wu, J.; Chang, L.; Yu, G. Effective Data Decision-Making and Transmission System Based on Mobile Health for Chronic Disease Management in the Elderly. IEEE Syst. J. 2021, 15, 5537–5548. [Google Scholar] [CrossRef]
- Chang, L.; Wu, J.; Moustafa, N.; Bashir, A.; Yu, K. AI-Driven Synthetic Biology for Non-Small Cell Lung Cancer Drug Effectiveness-Cost Analysis in Intelligent Assisted Medical Systems. IEEE J. Biomed. Health Inform. 2021, 34874878. [Google Scholar] [CrossRef] [PubMed]
- Yu, G.; Wu, J. Efficacy prediction based on attribute and multi-source data collaborative for auxiliary medical system in developing countries. Neural Comput. Appl. 2022, 1–16. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Salient Object Detection with Recurrent Fully Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1734–1746. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse Attention for Salient Object Detection. Computer Vision—ECCV 2018. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11213. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Borji, A.; Itti, L. Exploiting local and global patch rarities for saliency detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Perazzi, F.; Krahenbuhl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, Z.; Davis, L.S. Sub modular Salient Region Detection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M. Saliency Detection via Dense and Sparse Reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, L.; Chen, Z.; Wu, Q.M.J.; Zhao, H.; He, W.; Yan, X. AMPNet: Average-and Max-Pool Networks for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4321–4333. [Google Scholar] [CrossRef]
- Rui, Z.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, L.; Lu, H.; Xiang, R.; Ming, Y. Deep networks for saliency detection via local estimation and global search. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, H. Progressive Attention Guided Recurrent Network for Salient Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-Aware Salient Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wu, R.; Feng, M.; Guan, W.; Wang, D.; Lu, H.; Ding, E. A Mutual Learning Method for Salient Object Detection with Intertwined Multi-Supervision. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.; Borji, A. Salient Object Detection with Pyramid Attention and Salient Edges. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection. IEEE Comput. Soc. 2017, 202–211. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Ju, D.; Lu, H.; You, H.; Gang, W. A Bi-Directional Message Passing Model for Salient Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. BDCN: Bi-Directional Cascade Network for Perceptual Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 100–113. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Xiangqian, W. Pyramid feature attention network for saliency detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Geng, Z.; Guo, M.H.; Chen, H.; Li, X.; Wei, K.; Lin, Z. Is attention better than matrix decomposition? In Proceedings of the 2015 International Conference on Learning Representation, A Virtual Event. 28 December 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4 December 2017. [Google Scholar]
- Li, J.; Pan, Z.; Liu, Q.; Cui, Y.; Sun, Y. Complementarity-Aware Attention Network for Salient Object Detection. IEEE Trans. Cybern. 2020, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.H.; Liu, Z.N.; Mu, T.J.; Hu, S.M. Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), A Virtual Event. 19 June 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representation, San Diego, CA, USA, 9 May 2015. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.; Martin, R.; Hu, S. PCT: Point Cloud Transformer. Comput. Vis. Media 2020, 7, 187–199. [Google Scholar] [CrossRef]
- Hu, X.; Fu, C.-W.; Zhu, L.; Wang, T.; Heng, P.-A. SAC-Net: Spatial Attenuation Context for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1079–1090. [Google Scholar] [CrossRef]
- Liu, N.; Han, J. DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 603–612. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to Detect Salient Objects with Image-Level Supervision. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yan, Q.; Li, X.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.; Yuille, A. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Based on Multiscale Deep Features. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Movahedi, V.; Elder, J.H. Design and perceptual validation of performance measures for salient object segmentation. In Proceedings of the Computer Vision & Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A New Way to Evaluate Foreground Maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 2015 International Conference on Learning Representation, San Diego, CA, USA, 9 May 2015. [Google Scholar]
- Islam, M.A.; Kalash, M.; Bruce, N.D.B. Revisiting salient object detection: Simultaneous detection, ranking, and subitizing of multiple salient objects. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji., A.; Tu., Z.; Torr., P.H. Deeply Supervised Salient Object Detection with Short Connections. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P. Non-local Deep Features for Salient Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, G.; Yu, Y. Deep Contrast Learning for Salient Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yao, Q.; Lu, H.; Xu, Y.; Wang, H. Saliency detection via Cellular Automata. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lee, G.; Tai, Y.W.; Kim, J. Deep Saliency with Encoded Low Level Distance Map and High Level Features. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, P.; Dong, W.; Lu, H.; Wang, H.; Yin, B. Learning Uncertain Convolutional Features for Accurate Saliency Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Model | F-Measure↑ | MAE↓ | S-Measure↑ |
|---|---|---|---|---|
| a | VGG | 0.760 | 0.074 | 0.790 |
| b | VGG + IRM | 0.782 | 0.065 | 0.803 |
| c | VGG + BAMp | 0.775 | 0.066 | 0.804 |
| d | VGG + BAMc | 0.763 | 0.069 | 0.801 |
| e | VGG + BAMp + BAMc | 0.781 | 0.066 | 0.806 |
| f | VGG + BPM | 0.777 | 0.068 | 0.801 |
| g | VGG + IRM + BAM | 0.800 | 0.061 | 0.820 |
| h | VGG + IRM + BPM | 0.789 | 0.063 | 0.809 |
| i | VGG + BAM + BPM | 0.785 | 0.060 | 0.822 |
| j | VGG + IRM + BAM + BPM | 0.809 | 0.058 | 0.824 |
| No. | Model | F-Measure↑ | MAE↓ | S-Measure↑ |
|---|---|---|---|---|
| a | +Self-attention | 0.804 | 0.060 | 0.824 |
| b | +Beyond-attention | 0.801 | 0.059 | 0.818 |
| c | +BAM | 0.809 | 0.058 | 0.824 |
| F-Measure↑ | MAE↓ | S-Measure↑ | |
|---|---|---|---|
| 1 | 0.7534 | 0.0742 | 0.7860 |
| 2 | 0.7517 | 0.0756 | 0.7859 |
| 3 | 0.7634 | 0.0711 | 0.7927 |
| 4 | 0.7578 | 0.0741 | 0.7899 |
| 5 | 0.7588 | 0.0715 | 0.7881 |
| No. | F-Measure↑ | MAE↓ | S-Measure↑ |
|---|---|---|---|
| {1,1,1} | 0.7634 | 0.0711 | 0.7927 |
| {1,2,3} | 0.7658 | 0.0710 | 0.7988 |
| {1,3,5} | 0.7683 | 0.0694 | 0.7971 |
| {1,2,4} | 0.7768 | 0.0678 | 0.8014 |
| {1,4,7} | 0.7513 | 0.0760 | 0.7848 |
| Model | DUTS-TE | ECSSD | PASCAL-S | HKU-IS | DUT-OMROM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F↑ | M↓ | S↑ | F↑ | M↓ | S↑ | F↑ | M↓ | S↑ | F↑ | M↓ | S↑ | F↑ | M↓ | S↑ | |
| Ours | 0.809 | 0.058 | 0.824 | 0.909 | 0.058 | 0.886 | 0.821 | 0.092 | 0.806 | 0.901 | 0.042 | 0.880 | 0.763 | 0.069 | 0.781 |
| CANet [34] | 0.796 | 0.056 | 0.840 | 0.907 | 0.049 | 0.898 | 0.832 | 0.120 | 0.790 | 0.897 | 0.040 | 0.895 | 0.719 | 0.071 | 0.795 |
| NLDF [51] | 0.813 | 0.065 | 0.816 | 0.905 | 0.063 | 0.875 | 0.822 | 0.098 | 0.805 | 0.902 | 0.048 | 0.878 | 0.753 | 0.080 | 0.771 |
| Amulet [28] | 0.773 | 0.075 | 0.796 | 0.911 | 0.062 | 0.849 | 0.862 | 0.092 | 0.820 | 0.889 | 0.052 | 0.886 | 0.737 | 0.083 | 0.771 |
| DCL [52] | 0.782 | 0.088 | 0.795 | 0.891 | 0.088 | 0.863 | 0.804 | 0.124 | 0.791 | 0.885 | 0.072 | 0.861 | 0.739 | 0.097 | 0.764 |
| UCF [55] | 0.771 | 0.116 | 0.777 | 0.908 | 0.080 | 0.884 | 0.820 | 0.127 | 0.806 | 0.888 | 0.073 | 0.874 | 0.735 | 0.131 | 0.748 |
| DSS [50] | 0.813 | 0.065 | 0.812 | 0.906 | 0.064 | 0.882 | 0.821 | 0.101 | 0.796 | 0.900 | 0.050 | 0.878 | 0.760 | 0.074 | 0.765 |
| ELD [54] | 0.747 | 0.092 | 0.749 | 0.865 | 0.082 | 0.839 | 0.772 | 0.122 | 0.757 | 0.843 | 0.072 | 0.823 | 0.738 | 0.093 | 0.743 |
| RFCN [10] | 0.784 | 0.091 | 0.791 | 0.898 | 0.097 | 0.860 | 0.827 | 0.118 | 0.793 | 0.895 | 0.079 | 0.859 | 0.747 | 0.095 | 0.774 |
| BSCA [53] | 0.597 | 0.197 | 0.630 | 0.758 | 0.183 | 0.725 | 0.666 | 0.224 | 0.633 | 0.723 | 0.174 | 0.700 | 0.616 | 0.191 | 0.652 |
| MDF [44] | 0.729 | 0.093 | 0.732 | 0.832 | 0.105 | 0.776 | 0.763 | 0.143 | 0.694 | 0.860 | .0129 | 0.810 | 0.694 | 0.092 | 0.720 |
| RSD [49] | 0.757 | 0.161 | 0.724 | 0.845 | 0.173 | 0.788 | 0.864 | 0.155 | 0.805 | 0.843 | 0.156 | 0.787 | 0.633 | 0.178 | 0.644 |
| LEGS [23] | 0.655 | 0.138 | - | 0.827 | 0.118 | 0.787 | 0.756 | 0.157 | 0.682 | 0.770 | 0.118 | - | 0.669 | 0.133 | - |
| MCDL [22] | 0.461 | 0.276 | 0.545 | 0.837 | 0.101 | 0.803 | 0.741 | 0.143 | 0.721 | 0.808 | 0.092 | 0.786 | 0.701 | 0.089 | 0.752 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Chen, R.; Deng, D. Multiscale Balanced-Attention Interactive Network for Salient Object Detection. Mathematics 2022, 10, 512. https://doi.org/10.3390/math10030512
Yang H, Chen R, Deng D. Multiscale Balanced-Attention Interactive Network for Salient Object Detection. Mathematics. 2022; 10(3):512. https://doi.org/10.3390/math10030512
Chicago/Turabian StyleYang, Haiyan, Rui Chen, and Dexiang Deng. 2022. "Multiscale Balanced-Attention Interactive Network for Salient Object Detection" Mathematics 10, no. 3: 512. https://doi.org/10.3390/math10030512
APA StyleYang, H., Chen, R., & Deng, D. (2022). Multiscale Balanced-Attention Interactive Network for Salient Object Detection. Mathematics, 10(3), 512. https://doi.org/10.3390/math10030512