
The Choice of Time–Frequency Representations of Non-Stationary Signals Affects Machine Learning Model Accuracy: A Case Study on Earthquake Detection from LEN-DB Data

 ,
,  , , , , and
, , , , and 
Abstract
:
1. Introduction
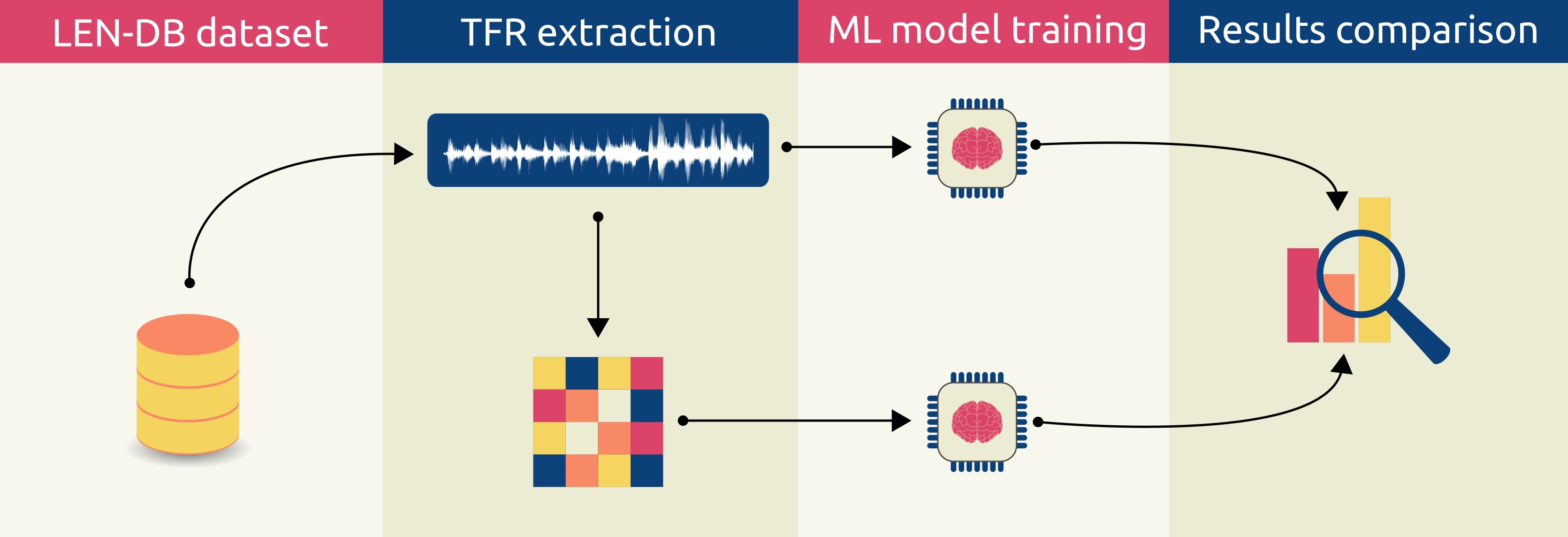
2. Materials and Methods
2.1. Experimental Setup
2.2. LEN-DB Dataset
2.3. Extracting Time–Frequency Representations from Seismograms
- Margenau–Hill (MH) [16]
2.4. Convnet Models and the Base Model
- Batch normalization (BN) layers were added after each convolutional layer and after each fully connected layer, except for the output layer. BN layers were not added to ResNet50 because the mentioned network originally has BN layers incorporated in its architecture.
- Inputs into the networks were adapted so that each model accepted a TFR image and three maximum channel values before data scaling. Data scaling/normalization is thoroughly described in Section 2.5.
- Outputs from the networks were adapted so that each model predicted the probability of the input data being an earthquake.
- VGG16—224 × 224 × 3.
- AlexNet—227 × 227 × 3.
- ResNet50—224 × 224 × 3.
2.5. Input Normalization
2.6. Evaluation Metrics
2.7. Statistical Significance
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Withers, M.; Aster, R.; Young, C.; Beiriger, J.; Harris, M.; Moore, S.; Trujillo, J. A comparison of select trigger algorithms for automated global seismic phase and event detection. Bull. Seismol. Soc. Am. 1998, 88, 95–106. [Google Scholar] [CrossRef]
- Yoon, C.E.; O’Reilly, O.; Bergen, K.J.; Beroza, G.C. Earthquake detection through computationally efficient similarity search. Sci. Adv. 2015, 1, e1501057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rojas, O.; Otero, B.; Alvarado, L.; Mus, S.; Tous, R. Artificial neural networks as emerging tools for earthquake detection. Comput. Sist. 2019, 23, 350. [Google Scholar] [CrossRef]
- Perol, T.; Gharbi, M.; Denolle, M. Convolutional neural network for earthquake detection and location. Sci. Adv. 2018, 4, e1700578. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lomax, A.; Michelini, A.; Jozinović, D. An Investigation of Rapid Earthquake Characterization Using Single-Station Waveforms and a Convolutional Neural Network. Seismol. Res. Lett. 2019, 90, 517–529. [Google Scholar] [CrossRef]
- Zhou, Y.; Yue, H.; Kong, Q.; Zhou, S. Hybrid Event Detection and Phase-Picking Algorithm Using Convolutional and Recurrent Neural Networks. Seismol. Res. Lett. 2019, 90, 1079–1087. [Google Scholar] [CrossRef]
- Tous, R.; Alvarado, L.; Otero, B.; Cruz, L.; Rojas, O. Deep Neural Networks for Earthquake Detection and Source Region Estimation in North-Central Venezuela. Bull. Seismol. Soc. Am. 2020, 110, 2519–2529. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Zhu, W.; Sheng, Y.; Beroza, G.C. CRED: A Deep Residual Network of Convolutional and Recurrent Units for Earthquake Signal Detection. Sci. Rep. 2019, 9, 10267. [Google Scholar] [CrossRef]
- Dokht, R.M.; Kao, H.; Visser, R.; Smith, B. Seismic event and phase detection using time-frequency representation and convolutional neural networks. Seismol. Res. Lett. 2019, 90, 481–490. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Langston, C.A. Fast and novel microseismic detection using time-frequency analysis. In SEG Technical Program Expanded Abstracts; Society of Exploration Geophysicists: Tulsa, OK, USA, 2016; Volume 35. [Google Scholar] [CrossRef]
- Magrini, F.; Jozinović, D.; Cammarano, F.; Michelini, A.; Boschi, L. Local earthquakes detection: A benchmark dataset of 3-component seismograms built on a global scale. Artif. Intell. Geosci. 2020, 1, 1–10. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ackroyd, M.H. Short-time spectra and time-frequency energy distributions. J. Acoust. Soc. Am. 1971, 50, 1229–1231. [Google Scholar] [CrossRef]
- Flandrin, P. Time-Frequency/Time-Scale Analysis; Academic Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Hlawatsch, F.; Auger, F. Time-Frequency Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Margenau, H.; Hill, R.N. Correlation between Measurements in Quantum Theory. Prog. Theor. Phys. 1961, 26, 722–738. [Google Scholar] [CrossRef] [Green Version]
- Volpato, A.; Collini, E. Time-frequency methods for coherent spectroscopy. Opt. Express 2015, 23, 20040. [Google Scholar] [CrossRef]
- Ville, J. Theorie et application dela notion de signal analytique. Câbles Transm. 1948, 2, 61–74. [Google Scholar]
- Boashash, B. Time-Frequency Signal Analysis and Processing: A Comprehensive Reference; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Claasen, T.; Mecklenbräuker, W. The Wigner distribution—A tool for time-frequency signal analysis, Parts I–III. Philips J. Res. 1980, 35, 217–250, 276–300, 372–389. [Google Scholar]
- Flandrin, P.; Escudié, B. An interpretation of the pseudo-Wigner-Ville distribution. Signal Process. 1984, 6, 27–36. [Google Scholar] [CrossRef]
- Flandrin, P. Some features of time-frequency representations of multicomponent signals. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’84), Institute of Electrical and Electronics Engineers, San Diego, CA, USA, 19–21 March 1984; Volume 9, pp. 266–269. [Google Scholar] [CrossRef]
- Cordero, E.; de Gosson, M.; Dörfler, M.; Nicola, F. Generalized Born-Jordan distributions and applications. Adv. Comput. Math. 2020, 46, 51. [Google Scholar] [CrossRef]
- Jeong, J.; Williams, W.J. Kernel design for reduced interference distributions. IEEE Trans. Signal Process. 1992, 40, 402–412. [Google Scholar] [CrossRef]
- Choi, H.I.; Williams, W.J. Improved Time-Frequency Representation of Multicomponent Signals Using Exponential Kernels. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 862–871. [Google Scholar] [CrossRef]
- Hlawatsch, F.; Manickam, T.G.; Urbanke, R.L.; Jones, W. Smoothed pseudo-Wigner distribution, Choi-Williams distribution, and cone-kernel representation: Ambiguity-domain analysis and experimental comparison. Signal Process. 1995, 43, 149–168. [Google Scholar] [CrossRef]
- Papandreou, A.; Boudreaux-Bartels, G.F. Distributions for time-frequency analysis: A generalization of Choi-Williams and the Butterworth distribution. In Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP-92), San Francisco, CA, USA, 23–26 March 1992; Volume 5, pp. 181–184. [Google Scholar] [CrossRef]
- Wu, D.; Morris, J.M. Time-frequency representations using a radial Butterworth kernel. In Proceedings of the IEEE-SP International Symposium on Time- Frequency and Time-Scale Analysis, Philadelphia, PA, USA, 25–28 October 1994; pp. 60–63. [Google Scholar] [CrossRef]
- Papandreou, A.; Boudreaux-Bertels, G. Generalization of the Choi-Williams Distribution and the Butterworth Distribution for Time-Frequency Analysis. IEEE Trans. Signal Process. 1993, 41, 463. [Google Scholar] [CrossRef]
- Auger, F. Représentations Temps-Fréquence des Signaux Non-Stationnaires: Synthèse et Contribution. Ph.D. Thesis, Ecole Centrale de Nantes, Nantes, France, 1991. [Google Scholar]
- Guo, Z.; Durand, L.G.; Lee, H. The time-frequency distributions of nonstationary signals based on a Bessel kernel. IEEE Trans. Signal Process. 1994, 42, 1700–1707. [Google Scholar] [CrossRef]
- Auger, F.; Flandrin, P.; Goncalves, P.; Lemoine, O. Time-Frequency Toolbox Reference Guide. Hewston Rice Univ. 2005, 180, 1–179. [Google Scholar]
- Man’ko, V.I.; Mendes, R.V. Non-commutative time-frequency tomography. Phys. Lett. Sect. A Gen. At. Solid State Phys. 1999, 263. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Jozinović, D.; Lomax, A.; Štajduhar, I.; Michelini, A. Rapid prediction of earthquake ground shaking intensity using raw waveform data and a convolutional neural network. Geophys. J. Int. 2020, 222, 1379–1389. [Google Scholar] [CrossRef]
- Baldi, P.; Vershynin, R. The capacity of feedforward neural networks. Neural Netw. 2019, 116, 288–311. [Google Scholar] [CrossRef] [Green Version]
- Nawi, N.M.; Atomi, W.H.; Rehman, M. The Effect of Data Pre-processing on Optimized Training of Artificial Neural Networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef] [Green Version]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Dietterich, T.G. Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [Green Version]
- Bonferroni, C.E. Teoria statistica delle classi e calcolo delle probabilità. Pubbl. R Ist. Sup. Sci. Econ. Commer. Fir. 1936, 8, 3–62. [Google Scholar]
- Mousavi, S.M.; Sheng, Y.; Zhu, W.; Beroza, G.C. STanford EArthquake Dataset (STEAD): A Global Data Set of Seismic Signals for AI. IEEE Access 2019, 7, 179464–179476. [Google Scholar] [CrossRef]
- Amato, F.; Guignard, F.; Robert, S.; Kanevski, M. A novel framework for spatio-temporal prediction of environmental data using deep learning. Sci. Rep. 2020, 10, 22243. [Google Scholar] [CrossRef]
- Wang, S.; Cao, J.; Yu, P. Deep Learning for Spatio-Temporal Data Mining: A Survey. IEEE Trans. Knowl. Data Eng. 2020, 1. [Google Scholar] [CrossRef]
- Wang, L.; Xu, T.; Stoecker, T.; Stoecker, H.; Jiang, Y.; Zhou, K. Machine learning spatio-temporal epidemiological model to evaluate Germany-county-level COVID-19 risk. Mach. Learn. Sci. Technol. 2021, 2, 035031. [Google Scholar] [CrossRef]
- Kriegerowski, M.; Petersen, G.M.; Vasyura-Bathke, H.; Ohrnberger, M. A deep convolutional neural network for localization of clustered earthquakes based on multistation full waveforms. Seismol. Res. Lett. 2019, 90, 510–516. [Google Scholar] [CrossRef]
- Jozinović, D.; Lomax, A.; Štajduhar, I.; Michelini, A. Transfer learning: Improving neural network based prediction of earthquake ground shaking for an area with insufficient training data. Geophys. J. Int. 2022, 229, 704–718. [Google Scholar] [CrossRef]
- Otović, E.; Njirjak, M.; Jozinović, D.; Mauša, G.; Michelini, A.; Štajduhar, I. Intra-domain and cross-domain transfer learning for time series data—How transferable are the features? Knowl.-Based Syst. 2022, 239, 107976. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L2 | Dropout | Batch Normalization | ||||
|---|---|---|---|---|---|---|
| Original | Modified | Original | Modified | Original | Modified | |
| VGG16 | 5 | 50%, the first two fully connected layers | ✗ | ✗ | ✓ | |
| AlexNet | ✗ | ✗ | 50%, the first two fully connected layers | ✗ | ✗ | ✓ |
| ResNet50 | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Optimizer | Learning Rate | Decay | Momentum | Batch Size | Epochs | |
|---|---|---|---|---|---|---|
| CNN (all TFRs except spectrogram) | SGD | 0.1 | 0.0001 | 0.9 | 16 | 30 |
| CNN (spectrogram) | SGD | 0.0001 | 0.0001 | 0.9 | 16 | 30 |
| Base model | Adam | 0.0001 | ✗ | ✗ | 128 | 500 |
| Time–Frequency Representation | CNN Architecture | ||
|---|---|---|---|
| VGG16 | ResNet50 | AlexNet | |
| BJ | 94.69% | 94.52% | 94.28% |
| BUD | 93.86% | 93.39% | 92.41% |
| CW | 92.68% | 93.03% | 93.75% |
| MH | 86.45% | 88.70% | 88.79% |
| PWV | 95.11% | 95.57% | 95.71% |
| RIDB | 94.94% | 95.00% | 94.47% |
| SP | 92.46% | 93.74% | 92.55% |
| SPWV | 93.21% | 93.79% | 90.34% |
| WV | 94.90% | 95.24% | 94.72% |
| Base | 94.15% | ||
| Time–Frequency Representation | CNN Architecture | ||
|---|---|---|---|
| VGG16 | ResNet50 | AlexNet | |
| BJ | 0.9807 | 0.9791 | 0.9762 |
| BUD | 0.9725 | 0.9697 | 0.9608 |
| CW | 0.967 | 0.9697 | 0.9706 |
| MH | 0.9253 | 0.9484 | 0.9509 |
| PWV | 0.9826 | 0.9857 | 0.9859 |
| RIDB | 0.9811 | 0.9815 | 0.9783 |
| SP | 0.962 | 0.9715 | 0.9618 |
| SPWV | 0.9679 | 0.9677 | 0.9415 |
| WV | 0.9824 | 0.9841 | 0.9805 |
| Base | 0.9785 | ||
| Time–Frequency Representation | CNN Architecture | ||
|---|---|---|---|
| VGG16 | ResNet50 | AlexNet | |
| BJ | 0 | 0.01 | 0.323 |
| BUD | 0.042 | 0 | 0 |
| CW | 0 | 0 | 0.007 |
| MH | 0 | 0 | 0 |
| PWV | 0 | 0 | 0 |
| RIDB | 0 | 0 | 0.016 |
| SP | 0 | 0.002 | 0 |
| SPWV | 0 | 0.014 | 0 |
| WV | 0 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Njirjak, M.; Otović, E.; Jozinović, D.; Lerga, J.; Mauša, G.; Michelini, A.; Štajduhar, I. The Choice of Time–Frequency Representations of Non-Stationary Signals Affects Machine Learning Model Accuracy: A Case Study on Earthquake Detection from LEN-DB Data. Mathematics 2022, 10, 965. https://doi.org/10.3390/math10060965
Njirjak M, Otović E, Jozinović D, Lerga J, Mauša G, Michelini A, Štajduhar I. The Choice of Time–Frequency Representations of Non-Stationary Signals Affects Machine Learning Model Accuracy: A Case Study on Earthquake Detection from LEN-DB Data. Mathematics. 2022; 10(6):965. https://doi.org/10.3390/math10060965
Chicago/Turabian StyleNjirjak, Marko, Erik Otović, Dario Jozinović, Jonatan Lerga, Goran Mauša, Alberto Michelini, and Ivan Štajduhar. 2022. "The Choice of Time–Frequency Representations of Non-Stationary Signals Affects Machine Learning Model Accuracy: A Case Study on Earthquake Detection from LEN-DB Data" Mathematics 10, no. 6: 965. https://doi.org/10.3390/math10060965
APA StyleNjirjak, M., Otović, E., Jozinović, D., Lerga, J., Mauša, G., Michelini, A., & Štajduhar, I. (2022). The Choice of Time–Frequency Representations of Non-Stationary Signals Affects Machine Learning Model Accuracy: A Case Study on Earthquake Detection from LEN-DB Data. Mathematics, 10(6), 965. https://doi.org/10.3390/math10060965