
Communication-Efficient Distributed Learning for High-Dimensional Support Vector Machines

Abstract
:1. Introduction
2. Problem Formulation
3. Distributed Learning for an SVM
| Algorithm 1: CSL distributed support vector machine (CSLSVM). |
 |
3.1. A Communication-Efficient Distributed SVM with Lasso Penalty
3.2. A Communication-Efficient SVM with SCAD Penalty
- (a)
- ;
- (b)
- ;
- (c)
- for all subgradients for some or for some ;
- (d)
- .
- (e)
- .
4. Numerical Experiments
4.1. Simulation Experiments
- L1SVM algorithm: the proposed communication-efficient estimator ;
- SCADSVM algorithm: the proposed communication-efficient estimator ;
- Cen algorithm: the central estimator , which computes the -regularized estimator using all of the dataset;
- Sub algorithm: the sub-data estimator , which computes the -regularized estimator using data only on the first machine.
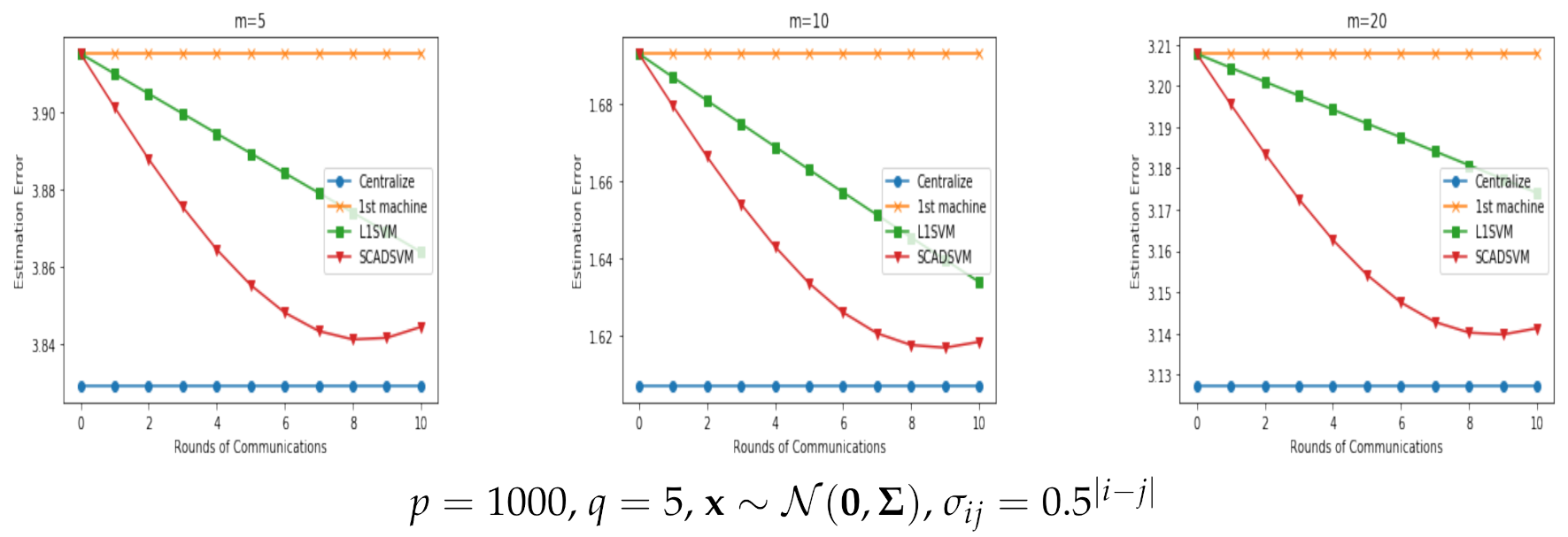
- (i)
- The centralized algorithm was the best among these algorithms because it used the information of the whole dataset.
- (ii)
- The sub algorithm was bad because it only used the information of the data on the first machine.
- (iii)
- Our proposed L1SVM and SCADSVM could both select relevant variables, and the SCADSVM had a better performance than L1SVEM. This implied the non-convex SCADSVM algorithm was more robust than convex L1SVEM, especially for the complex models and massive datasets.
- (iv)
- When was large, our two proposed distributed SVM algorithms were as good as the centralized algorithm.
- (i)
- The central algorithm was still the best classifier, but had the highest communication cost and risk of privacy leakage.There was a big gap between the sub estimator and the centralized estimator.
- (ii)
- Our two proposed communication-efficient estimators could match the central estimator with a few rounds of communication. The prediction errors of SCADSVM were lower than that of L1SVM, and it was more robust than L1SVM.
4.2. Real Data
- (i)
- Since these datasets had no well-specified model, the curves behaved quite differently on these datasets. However, overall there was a large gap between the sub algorithm and centralized solution.
- (ii)
- In most of the cases, the distributed L1SVM algorithm still converged quite slowly.
- (iii)
- The proposed distributed SCADSVM could obtain a solution that was highly competitive with the centralized model within a few rounds of communications, and was more robust than the distributed L1SVM.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Banerjee, M.; Durot, C.; Sen, B. Divide and conquer in nonstandard problems and the super-efficiency phenomenon. Ann. Stat. 2019, 47, 720–757. [Google Scholar] [CrossRef] [Green Version]
- Jordan, M.I.; Lee, J.D.; Yang, Y. Communication-Efficient Distributed Statistical Inference. J. Am. Stat. Assoc. 2019, 114, 668–681. [Google Scholar] [CrossRef] [Green Version]
- Volgushev, S.; Chao, S.K.; Cheng, G. Distributed inference for quantile regression processes. arXiv 2017, arXiv:1701.06088. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Liu, W.; Mao, X.; Yang, Z. Distributed High-dimensional Regression Under a Quantile Loss Function. arXiv 2019, arXiv:1906.05741. [Google Scholar]
- Wang, L.; Lian, H. Communication-efficient estimation of high-dimensional quantile regression. Anal. Appl. 2020, 18, 1057–1075. [Google Scholar] [CrossRef]
- Zhang, Y.; Duchi, J.; Wainwright, M. Divide and conquer kernel ridge regression: A distributed algorithm with minimax optimal rates. J. Mach. Learn. Res. 2015, 16, 3299–3340. [Google Scholar]
- Han, Y.; Mukherjee, P.; Ozgur, A.; Weissman, T. Distributed statistical estimation of high-dimensional and nonparametric distributions. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 506–510. [Google Scholar]
- Wang, X.; Yang, Z.; Chen, X.; Liu, W. Distributed inference for linear support vector machine. J. Mach. Learn. Res. 2019, 20, 1–41. [Google Scholar]
- Zou, H. An improved 1-norm svm for simultaneous classification and variable selection. In Proceedings of the Eleventh International Conference on Artificial Intelligence and Statistics, PMLR, San Juan, Puerto Rico, 21–24 March 2007; pp. 675–681. [Google Scholar]
- Meinshausen, N.; Bühlmann, P. High-dimensional graphs and variable selection with the lasso. Ann. Stat. 2006, 34, 1436–1462. [Google Scholar] [CrossRef] [Green Version]
- Zhao, P.; Yu, B. On model selection consistency of Lasso. J. Mach. Learn. Res. 2006, 7, 2541–2563. [Google Scholar]
- Meinshausen, N.; Yu, B. Lasso-type recovery of sparse representations for high-dimensional data. Ann. Stat. 2009, 37, 246–270. [Google Scholar] [CrossRef]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Bühlmann, P.; Van De Geer, S. Statistics for High-Dimensional Data: Methods, Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Giraud, C. Estimator Selection. In Introduction to High-Dimensional Statistics; Chapman and Hall: London, UK; CRC: London, UK, 2014; pp. 117–136. [Google Scholar]
- Fan, J.; Fan, Y. High dimensional classification using features annealed independence rules. Ann. Stat. 2008, 36, 2605. [Google Scholar] [CrossRef] [Green Version]
- Bradley, P.S.; Mangasarian, O.L. Feature selection via concave minimization and support vector machines. ICML Citeseer 1998, 98, 82–90. [Google Scholar]
- Peng, B.; Wang, L.; Wu, Y. An error bound for l1-norm support vector machine coefficients in ultra-high dimension. J. Mach. Learn. Res. 2016, 17, 8279–8304. [Google Scholar]
- Zhu, J.; Rosset, S.; Tibshirani, R.; Hastie, T.J. 1-norm support vector machines. Advances in neural information processing systems. Citeseer 2003, 16, 49–56. [Google Scholar]
- Wegkamp, M.; Yuan, M. Support vector machines with a reject option. Bernoulli 2011, 17, 1368–1385. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Becker, N.; Toedt, G.; Lichter, P.; Benner, A. Elastic SCAD as a novel penalization method for SVM classification tasks in high-dimensional data. BMC Bioinform. 2011, 12, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Park, C.; Kim, K.R.; Myung, R.; Koo, J.Y. Oracle properties of scad-penalized support vector machine. J. Stat. Plan. Inference 2012, 142, 2257–2270. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Y.; Wang, L.; Li, R. Variable selection for support vector machines in moderately high dimensions. J. R. Stat. Soc. Ser. Stat. Methodol. 2016, 78, 53. [Google Scholar] [CrossRef] [Green Version]
- Lian, H.; Fan, Z. Divide-and-conquer for debiased l1-norm support vector machine in ultra-high dimensions. J. Mach. Learn. Res. 2017, 18, 6691–6716. [Google Scholar]
- Wang, J.; Kolar, M.; Srebro, N.; Zhang, T. Efficient Distributed Learning with Sparsity. arXiv 2016, arXiv:1605.07991. [Google Scholar]
- Koo, J.Y.; Lee, Y.; Kim, Y.; Park, C. A bahadur representation of the linear support vector machine. J. Mach. Learn. Res. 2008, 9, 1343–1368. [Google Scholar]
- Belloni, A.; Chernozhukov, V. l1-penalized quantile regression in high-dimensional sparse models. Ann. Stat. 2011, 39, 82–130. [Google Scholar] [CrossRef]
- Van Der Vaart, A.W.; van der Vaart, A.W.; van der Vaart, A.; Wellner, J. Weak Convergence and Empirical Processes: With Applications to Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Koltchinskii, V. Oracle Inequalities in Empirical Risk Minimization and Sparse Recovery Problems: Ecole d’Eté de Probabilités de Saint-Flour XXXVIII-2008; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011; Volume 2033. [Google Scholar]
- Tao, P.; An, I. Convex analysis approach to D.C. programming theory, algorithms and applications. Acta Math. Vietnam. 1997, 22, 289–355. [Google Scholar]
- Zou, H.; Li, R. One-step sparse estimates in nonconcave penalized likelihood models. Ann. Stat. 2008, 36, 1509. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n = 200, p = 500 | ||||
|---|---|---|---|---|
| m | Sub | L1SVM | SCADSVM | Cen |
| 5 | 21 | 2 | 1 | 0 |
| 10 | 22 | 3 | 4 | 0 |
| 15 | 28 | 0 | 1 | 0 |
| 20 | 24 | 0 | 0 | 0 |
| n = 200, p = 1000 | ||||
| m | Sub | L1SVM | SCADSVM | Cen |
| 5 | 49 | 8 | 7 | 0 |
| 10 | 39 | 2 | 0 | 0 |
| 15 | 42 | 1 | 0 | 0 |
| 20 | 42 | 1 | 1 | 0 |
| n = 400, p = 500 | ||||
| m | Sub | L1SVM | SCADSVM | Cen |
| 5 | 4 | 4 | 0 | 0 |
| 10 | 3 | 0 | 0 | 0 |
| 15 | 5 | 0 | 0 | 0 |
| 20 | 1 | 0 | 0 | 0 |
| n = 400, p = 1000 | ||||
| m | Sub | L1SVM | SCADSVM | Cen |
| 5 | 6 | 0 | 0 | 0 |
| 10 | 7 | 0 | 0 | 0 |
| 15 | 4 | 0 | 0 | 0 |
| 20 | 4 | 0 | 0 | 0 |
| Data Name | Number of Data | Features | Task |
|---|---|---|---|
| a9a | 48,842 | 123 | Classification |
| w8a | 64,700 | 301 | Classification |
| phishing | 11,055 | 68 | Classification |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Shen, H. Communication-Efficient Distributed Learning for High-Dimensional Support Vector Machines. Mathematics 2022, 10, 1029. https://doi.org/10.3390/math10071029
Zhou X, Shen H. Communication-Efficient Distributed Learning for High-Dimensional Support Vector Machines. Mathematics. 2022; 10(7):1029. https://doi.org/10.3390/math10071029
Chicago/Turabian StyleZhou, Xingcai, and Hao Shen. 2022. "Communication-Efficient Distributed Learning for High-Dimensional Support Vector Machines" Mathematics 10, no. 7: 1029. https://doi.org/10.3390/math10071029
APA StyleZhou, X., & Shen, H. (2022). Communication-Efficient Distributed Learning for High-Dimensional Support Vector Machines. Mathematics, 10(7), 1029. https://doi.org/10.3390/math10071029