1. Introduction
With the rapid development of big data and the Internet of Things (IoT), the dimensionality of optimization problems is becoming increasingly higher and higher [
1,
2], leading to the emergence of high-dimensional optimization problems [
3,
4,
5]. Such a kind of optimization problem brings many undesirable challenges to existing optimizers. Specifically, with the dimensionality increasing, the solution space of optimization problems grows exponentially, resulting in the search effectiveness and the efficiency of existing optimizers degrading dramatically [
6]. On the other hand, wide and flat local regions are also likely to increase rapidly as the dimensionality grows, especially for multimodal problems. This results in it being hard for existing optimizers to effectively escape from local areas, such that global optima cannot be located efficiently [
7,
8].
To address the above challenges, a lot of metaheuristic algorithms have been proposed by taking inspiration from nature and other disciplines. For example, imitating the laws of physics, physics-based optimization algorithms such as Henry gas solubility optimization (HGSO) [
9], and artificial electric field algorithm (AEFA) [
10], have been developed. Inspired by the social behaviors of animals, swarm intelligence optimization algorithms, such as particle swarm optimization (PSO) [
11,
12], ant colony optimization (ACO) [
13,
14,
15], salp swarm algorithm (SSA) [
16] and grey wolf optimization (GWO) [
17], have been devised. Derived from competitive behaviors in sport playing, sport inspiration algorithms, such as the most valuable player algorithm (MVPA) [
18] have been designed. Arisen from theories in mathematics, mathematics inspiration optimization, such as arithmetic optimization algorithm (AOA) [
19] and sine cosine algorithm (SCA) [
20], have been proposed. Inspired by the thoughts of species evolution, evolutionary algorithms, such as genetic algorithms (GA) [
21] and differential evolution algorithms (DE) [
22,
23], have been developed. In addition, some other metaheuristic algorithms, such as adaptive hybrid approach (AHA) [
24], Harris hawks optimization (HHO) [
25], hunger games search (HGS) [
26] and golden jackal optimization (GJO) [
27], have also been designed to solve optimization problems.
Among the above different kinds of metaheuristic algorithms, PSO has been researched the most in dealing with large-scale optimization [
28,
29,
30,
31,
32]. In a broad sense, existing PSO research for high-dimensional optimization problems can be categorized into two main directions [
33]: cooperative co-evolutionary PSOs (CCPSOs) [
34,
35,
36] and holistic large-scale PSOs [
37,
38,
39,
40,
41].
CCPSOs [
42,
43] first adopt the divide-and-conquer technique to divide a high-dimensional problem into a number of low-dimensional sub-problems, and then utilize traditional PSOs for low-dimensional problems to separately solve the decomposed sub-problems. Since Potter [
44] proposed the cooperative co-evolutionary (CC) framework, researchers have employed this framework into different evolutionary algorithms and developed many cooperative co-evolutionary algorithms (CCEAs) [
43,
45], among which CCPSOs [
35,
46] have been developed by introducing PSOs into the CC framework.
However, the optimization performance of CCEAs including CCPSOs heavily relies on the decomposition accuracy in dividing the high-dimensional problem into sub-problems, since the optimization of interacting variables usually interferes with each other [
43]. Ideally, a good decomposition strategy should place interacting variables into the same sub-problem, so that they can be optimized together. Nevertheless, without prior knowledge on the correlations between variables, it is hard to accurately decompose a high-dimensional problem into sub-problems. To solve this issue, researchers have been devoted to designing effective decomposition strategies to divide a high-dimensional problem into sub-problems as accurately as possible by detecting the correlations between variables [
47]. As a consequence, a lot of remarkable decomposition strategies [
48,
49,
50,
51,
52] have been devised and assisted CCEAs, including CCPSOs, to achieve very promising performance in tackling large-scale optimization.
Different from CCPSOs, holistic large-scale PSOs [
33,
53] still consider optimizing all variables together such as traditional PSOs. The key role in designing effective holistic large-scale PSOs lies in devising effective learning strategies for PSO to improve the search diversity, largely so that particles in the swarm could search the solution space in different directions and locate the promising areas fast. To achieve this goal, researchers have abandoned historical information, such as the personal best positions
pbests, the global best position
gbest, or the neighbor best position
nbest, and attempted to employ predominate particles in the current swarm to guide the learning of poor particles. Along this line, many novel effective learning strategies [
29,
31,
32,
54,
55] have been proposed, such as the competitive learning strategy [
29], the level-based learning strategy [
54], the social learning strategy [
56] and the granularity learning strategy [
39], etc.
Though the above large-scale PSO variants have shown promising performance in certain kinds of high-dimensional problems, they are still confronted with many limitations in solving complicated large-scale optimization problems, like those with overlapping interacting variables and those with many wide and flat local basins. For CCPSOs, though, the advanced decomposition strategies could assist them to achieve promising performance. Confronted with problems with overlapping interacting variables, they would place many variables into the same sub-problem, leading to several large-scale sub-problems with a lot of interacting variables, or even place all variables into one same group. In this situation, traditional PSOs designed for low-dimensional problems, lose their effectiveness in solving these large-scale sub-problems. As for holistic PSOs, they are still confronted with premature convergence when solving complex problems with many wide and flat local regions. As a consequence, how to improve the optimization ability of PSO in solving large-scale optimization problems still deserves careful research.
To the above end, this paper proposes an elite-directed particle swarm optimization with historical information (EDPSO) to tackle large-scale optimization by taking inspiration from the “Pareto Principle” [
57], which is also known as the 80-20 rule that 80% of the consequences come from 20% of the causes, asserting an unequal relationship between inputs and outputs. Specifically, the main components of the proposed EDPSO are summarized as follows.
- (1)
An elite-directed learning strategy is devised to let elite particles in the current swarm direct the update of non-elite particles. Specifically, particles in the current swarm are first divided into two separate sets: the elite set consisting of the top 20% best particles and the non-elite set containing the remaining 80% of particles. Then, the non-elite set is further equally separated into two layers. In this way, actually, the swarm is divided into three layers: the elite layer, the better half of the non-elite set, and the worse half of the non-elite set. Subsequently, particles in the last layer are updated by learning from those in the first two layers, and the ones in the second layers are guided by those in the first layers with particles in the first layer (namely the elite layer) unchanged and directly entering the next generation. In this manner, particles in different layers are updated in different ways. Therefore, the learning diversity and the learning effectiveness of particles are expectedly largely improved.
- (2)
An additional archive is maintained to store the obsolete elites in the elite set and then is used to cooperate with particles in the first two layers to direct the update of non-elite particles, so that the diversity of guiding exemplars could be promoted and thus the learning diversity of particles is further enhanced.
With the above two techniques, the proposed EDPSO is expected to compromise the search diversity and fast convergence well to explore and exploit the high-dimensional space appropriately to find high-quality solutions. To verify the effectiveness of the proposed EDPSO, extensive experiments are conducted to compare it with several state-of-the-art large-scale optimizers on the widely used CEC’2010 [
58] and CEC’2013 [
59] large-scale benchmark optimization problem sets. Meanwhile, deep investigations on EDPSO are also conducted to find what contributes to its promising performance.
The rest of this paper is organized as follows.
Section 2 reviews closely related work on the classical PSO and large-scale PSO variants. In
Section 3, the proposed EDPSO is presented in detail. Subsequently, extensive experiments are performed to compare the proposed algorithm with state-of-the-art peer large-scale optimizers in
Section 4. Lastly, we end this paper with the conclusion shown in
Section 5.
3. Proposed Method
Elite individuals in one species usually preserve more valuable evolutionary information to guide the evolution of the species than others [
86]. Taking inspiration from this, we devise an elite-directed PSO (EDPSO) with historical information to improve the learning effectiveness and the learning diversity of particles to search the large-scale solution space efficiently. Specifically, the main components of the proposed EDPSO are elucidated in detail as follows.
3.1. Elite-Directed Learning
Taking inspiration from the “Pareto Principle” [
57] which is also known as the 80-20 rule that 80% of the consequences come from 20% of the causes, asserting an unequal relationship between inputs and outputs, we first divide the swarm with
NP particles into two exclusive sets. One set is the elite set containing the top best 20% of particles, while another set is the non-elite set containing the remaining 80% of particles. To further treat different particles differently, we further divide the non-elite set equally into two layers. One layer consists of the best half of the non-elite set, while another layer contains the remaining half of the non-elite set. In this way, we actually separate particles in the swarm into three exclusive layers. The first layer, denoted as
L1, is the elite set, composed of the top best 20% of particles. The second layer, denoted as
L2, is the best half of the non-elite set, made up of 40% particles that are only inferior to those in
L1. The third layer, denoted as
L3, contains the remaining 40% of particles. On the whole, it is found that particles in the first layer (
L1) are the best, while those in the third layer (
L3) are the worst among the three layers.
Since particles in different layers preserve different strengths in exploring and exploiting the solution space, we treat them differently. Specifically, for particles in the third layer (L3), since they are all dominated by those in the first two layers (L1 and L2), they are updated by learning from those predominant particles in L1 and L2. Likewise, for particles in the second layer (L2), since they are all dominated by those in the first layer (L1), they are updated by learning from those in L1. As for particles in the first layer, since they are the best in the swarm, we do not update them and let them directly enter the next generation to preserve valuable evolutionary information and keep them from being destroyed, so that the evolution of the swarm can be guaranteed to converge to promising areas.
In particular, particles in the third layer (
L3) are updated as follows:
where
and
are the position and the velocity of the
ith particle in the third layer (
L3), respectively.
and
are two different exemplars randomly selected from
L1∪
L2.
,
, and
are three real random numbers uniformly generated within [0, 1].
ϕ is a control parameter within [0, 1], which is in charge of the influence of the second exemplar on the updated particle.
Likewise, particles in the second layer (
L2) are updated as follows:
where
and
are the position and the velocity of the
ith particle in the second layer (
L2), respectively.
and
represent the two different exemplars randomly selected from the first layer (
L1).
In addition to the above updated formula, the following details deserve special attention:
- (1)
For particles in L2 and L3, we randomly select two different predominant particles from higher layers to direct their update. In this way, for different particles, the two guiding exemplars are different. In addition, for the same particle, the two guiding exemplars are also different in different generations. Therefore, the learning diversity of particles is largely improved.
- (2)
As for the two selected exemplars, we utilize the better one as the first guiding exemplar and the worse one as the second guiding exemplar. That is to say, in Equation (4), is better than and in Equation (6), is better than Such employment of the two exemplars results in the first guiding exemplar being mainly responsible for leading the update particle to approach promising areas, and thus is in charge of the convergence. At the same time, the second guiding exemplar is mainly responsible for diversity, so that the updated particle is prevented from approaching the first exemplar too greedily. In this way, a promising balance between fast convergence and high diversity is expectedly maintained at the particle level during the update of each particle.
- (3)
With respect to Equations (5) and (7), once the elements in the position of the update particle are out of the range of the associated variables, they are set as the lower bounds of the associated variables if they are smaller than the associated lower bounds and are set as the upper bounds of the associated variables if they are larger than the associated upper bounds.
- (4)
Taking deep observation, we find that particles in L3 have a wider range to learn than those in L2. This is because particles in L3 learn from those in L2∪L1 consisting of the top best 60% of particles in the swarm, while particles in L2 only learn from those in L1 containing the top best 20% of particles. Therefore, we can see that during the evolution, particles in L3 bias to exploring the solution space, while those in L2 bias to exploiting the found promising areas. Hence, a promising balance between exploration and exploitation is expectedly maintained at the swarm level during the evolution of the whole swarm.
- (5)
Since particles in L1 are preserved to directly enter the next generation, they become better and better during the evolution, though the members in L1 are likely changed. As a result, particles in L1 are expected to converge to optimal areas.
3.2. Historical Information Utilization
During the evolution, some of the particles in L1 in the last generation are replaced by some of the updated particles in L2 and L3, once they are better. Therefore, some particles in L1 are obsolete and enter L2 and L3 to update in the next generation. However, these obsolete solutions may also contain useful evolutionary information. To make full use of the historical information, we maintain an additional archive A of size NP/2 to store the obsolete elite individuals.
Specifically, before the update of particles in each generation, when the three layers are formed, we first compute L1,g∩L1,g−1 to obtain the elite particles that survive to directly enter the next generation. Then, we calculate L1,g–1 − (L1,g∩L1,g–1) to obtain the obsolete elites. These obsolete elites are stored in the archive A.
As for the update of the archive A, in the beginning, A is set to be empty. Then, the obsolete elites (L1,g–1 − (L1,g∩L1,g–1)) are inserted into A from the worst to the best. Once the archive A is full, namely its size exceeds NP/2, we adopt the “first-in-first-out” strategy to remove individuals in A until its size reaches NP/2.
To make use of the obsolete elites in A reasonably, we only introduce them into the learning of particles in L3, so that the convergence of the swarm is not destroyed. Specifically, to guarantee that particles in L3 learn from better ones, we first seek those individuals in A that are better than the best one in L3 to form a candidate set A’. Then, A’ is utilized to update particles in L3 along with the first two layers. That is to say, in Equation (4), the two guiding exemplars are randomly selected from L1∪L2∪A’ instead of only from L1∪L2.
With the above modification, the number of candidate exemplars for particles in L3 is enlarged, and thus the learning diversity of particles in L3 is further promoted to fully explore the high-dimensional solution space. It should be mentioned that on the one hand, particles in L3 are guaranteed to learn from better ones; on the other hand, the learning of particles in L2, which are bias to exploiting promising areas, remains unchanged. Therefore, the convergence of the swarm is not destroyed.
Experiments conducted in
Section 4.3 will demonstrate the usefulness of the additional archive
A in helping the proposed EDPSO to achieve a promising performance.
3.3. Overall Procedure of EDPSO
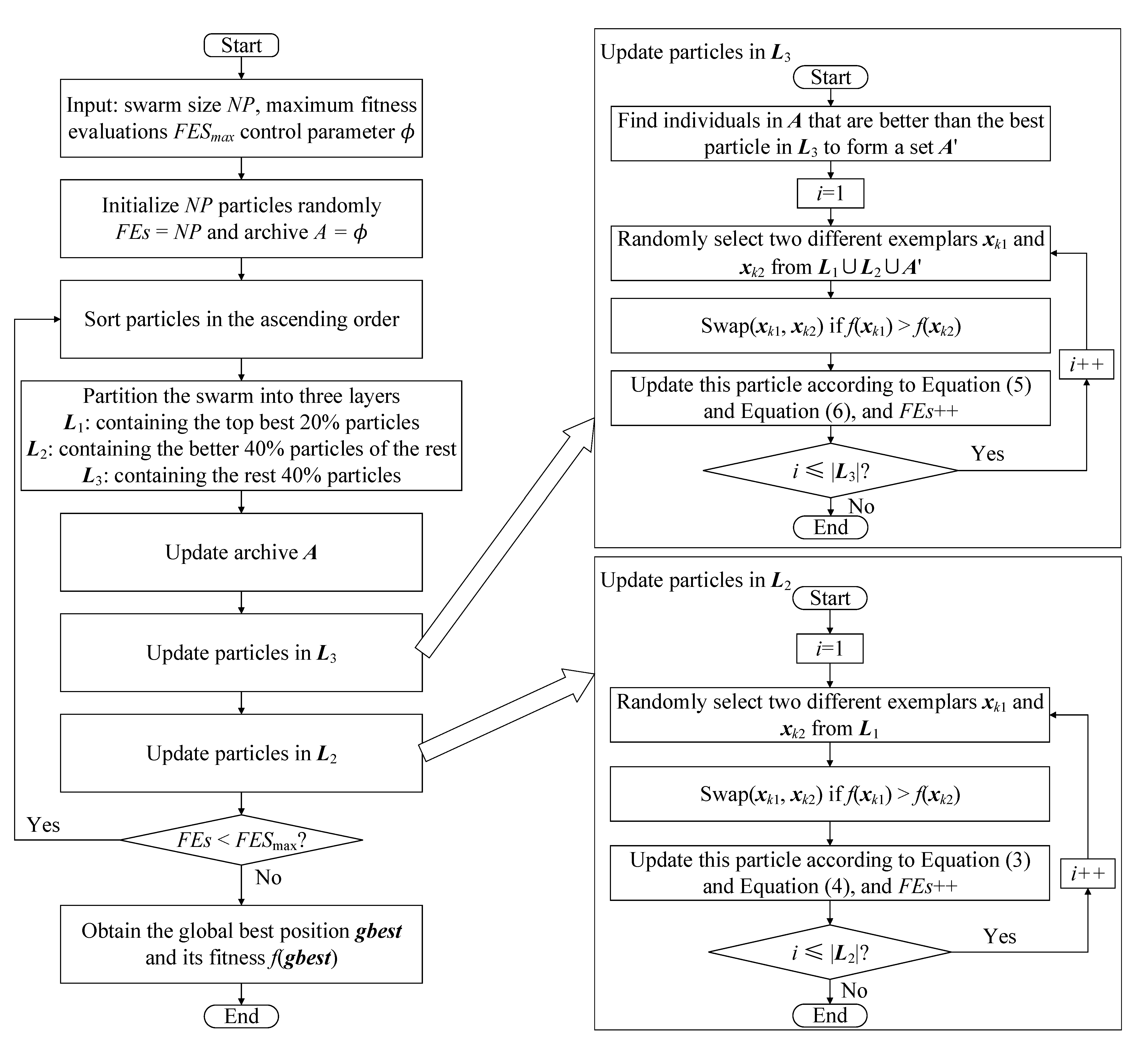
Integrating the above components, the complete EDPSO is obtained with its overall flowchart exhibited in
Figure 1 and the overall procedure presented in Algorithm 1. Specifically, in the beginning,
NP particles are randomly initialized and evaluated as shown in Line 1. After that, the algorithm jumps into the main iteration (Lines 3–25). During the iteration, the whole swarm is sorted in an ascending order of fitness (Line 4), and then the swarm is partitioned into three layers (Line 5) along with the update of the archive
A (Line 6). Subsequently, particles in
L3 are updated (Lines 7–16), following which is the update of particles in
L2 (Lines 17–25). The main iteration proceeds until the maximum number of fitness evaluations is exhausted. Then, at the end of the algorithm, the global best position
gbest and its fitness
f(
gbest) are obtained from
L1 as the output.
From Algorithm 1, we can see that EDPSO needs O(NP × D) to store the positions of all particles and O(NP × D) to store the velocity of all particles. In addition, it also needs O(NP × D) to store the archive, and O(NP) to store the sorted index of particles. Comprehensively, EDPSO needs O(NP × D) space during the evolution.
Concerning the time complexity, in each generation, it takes O(
NPlog
NP) time to sort the swarm (Lines 4) and O(
NP) to divide the swarm into three layers (Lines 5–6). Then, it takes O(
NP ×
D) to update the archive (Lines 6), and to update particles in
L2 and
L3 (Lines 7–25) O(
NP ×
D) time complexity is also needed. To sum up, the whole complexity in one generation is O(
NP ×
D), which is the same as the classical PSO.
| Algorithm 1: The pseudocode of EDPSO |
| Input: swarm size NP, maximum fitness evaluations FESmax and control parameter ∅ |
| 1: | Initialize NP particles randomly and caculate their fitness; |
| 2: | FEs = NP and set the archive empty A = ∅ |
| 3: | While (FEs < FESmax) do |
| 4: | Sort particles in ascending order according to their fitness; |
| 5: | Partition the swarm into three layers: the elite layer L1 containing the top best 20% of particles, the second layer L2 containing the half best of the non-elite particles (40% particles), and the third layer L3 consisting of another half of the non-elite particles (40% particles); |
| 6: | Update the archive A; |
| 7: | For each particle in L3 do |
| 8: | Find those individuals in A that are better than the best particle in L3 to form a set A’; |
| 9: | Select two different exemplars xk1 and xk2 from L1∪L2∪A’; |
| 10: | If f(xk1) > f(xk2) then |
| 11: | Swap(xk1, xk2); |
| 12: | End If |
| 13: | Update this particle according to Equations (4) and (5); |
| 14: | If the elements in xi are smaller than the lower bounds of the associated variables, they are set as the asociated lower bounds; if they are larger than the upper bounds of the associated variables, they are set as the associated upper bounds. |
| 15: | Evaluate its fitness and FEs++; |
| 16: | End For |
| 17: | For each particle in L2 do |
| 18: | Select two different exemplars xk1 and xk2 from L1; |
| 19: | If f(xk1) > f(xk2) then |
| 20: | Swap(xk1, xk2); |
| 21: | End If |
| 22: | Update this particle according to Equations (6) and (7); |
| 23: | If the elements in xi are smaller than the lower bounds of the associated variables, they are set as the asociated lower bounds; if they are larger than the upper bounds of the associated variables, they are set as the associated upper bounds. |
| 24: | Evaluate its fitness and FEs++; |
| 25: |
End For |
| 26: | End While |
| 27: | Obtain the global best position gbest and its fitness f(gbest); |
| Output: f(gbest) and gbest |
4. Experiments
In this section, we conduct extensive comparison experiments to validate the effectiveness of the proposed EDPSO on the commonly used CEC’2010 [
58] and CEC’2013 [
59] large-scale benchmark problem sets by comparing EDPSO with several state-of-the-art large-scale optimizers. The CEC’2010 set contains twenty 1000-
D optimization problems, while the CEC’2013 set consists of fifteen 1000-D problems. In particular, the CEC’2013 set is an extension of the CEC’2010 set by introducing more complicated features, such as overlapping interacting variables and unbalanced contribution of variables. Therefore, the CEC’2013 benchmark problems are more difficult to optimize. The main characteristics of the CEC’2010 and the CEC’2013 sets are briefly summarized in
Table 1 and
Table 2, respectively. For more details, please refer to [
58,
59].
In this section, we first investigate the parameter settings of the swarm size
NP and the control parameter
ϕ for EDPSO in
Section 4.1. Then, in
Section 4.2, the proposed EDPSO is extensively compared with several state-of-the-art large-scale algorithms on the two benchmark sets. Lastly, in
Section 4.3, the effectiveness of the additional archive in EDPSO is verified by conducting experiments on the CEC’2010 benchmark set.
In the experiments, for fair comparisons, without being otherwise stated, the maximum number of fitness evaluations is set as 3000 × D (where D is the dimension size) for all algorithms. For each algorithm on each optimization problem, we execute it independently for 30 runs, and then utilize the median, the mean, and the standard deviation (Std) values over the 30 independent runs to evaluate its performance, so that fair and comprehensive comparisons can be made.
In addition, to tell whether there is significant difference between the proposed EDPSO and the compared methods, we run the Wilcoxon rank-sum test at the significance level of “α = 0.05” to compare the performance of EDPSO with that of each compared algorithm on each problem. Furthermore, to compare the overall performance of different algorithms on one whole benchmark set, we also conduct the Friedman test at the significance level of “α = 0.05” on each benchmark set.
4.1. Parameter Settings
In the proposed EDPSO, two parameters, namely the swarm size
NP and the control parameter
ϕ, are needed to fine-tune. Therefore, to find suitable settings for these two parameters for EDPSO, we conduct experiments on the CEC’2010 set by varying
NP from 500 to 1000, and
ϕ from 0.1 to 0.9 for EDPSO. The comparison results among these settings are shown in
Table 1. In particular, in this table, the best results among different settings of
ϕ under the same setting of
NP are highlighted in bold. The average rank of each configuration of
ϕ under the same setting of
NP obtained by the Friedman test is also presented in the last row of each part in
Table 1.
From
Table 3, we can obtain the following findings. (1) For different settings of
NP, we find that when
NP ranges from 500 to 800, the most suitable
ϕ is 0.4; when it ranges from 900 to 1000, the most suitable
ϕ is 0.3. This indicates that the setting of
ϕ is not so closely related to
NP. (2) Furthermore, we find that neither a too small
ϕ nor a too large
ϕ is suitable for EDPSO. This is because a too small
ϕ decreases the influence of the second exemplar on the updated particle, leading to the updated particle greedily approaching the promising area where the first exemplar is located. In this case, once the first exemplar falls into local areas, the updated particle likely falls into local basins as well. Therefore, the algorithm likely encounters premature convergence. On the contrary, a too large
ϕ increases the influence of the second exemplar, leading to the updated particle being dragged too far away from promising areas. In this situation, the convergence of the swarm slows down. (3) It is observed that a relatively large
NP is preferred for EDPSO to achieve good performance. This is because a small
NP cannot afford enough diversity for the algorithm to explore the solution space. However, a too large
NP (such as
NP = 900 or 1000) is not beneficial for EDPSO to achieve good performance because too high diversity is afforded, leading to that the convergence of the swarm slows down.
Based on the above observation, NP = 600 and ϕ = 0.4 are the recommended settings for the two parameters in EDPSO when solving 1000-D optimization problems.
4.2. Comparisons with State-of-the-Art Large-Scale Optimizers
This section conducts extensive comparison experiments to compare the proposed EDPSO with several state-of-art large-scale algorithms including five holistic large-scale PSO optimizers and four state-of-the-art CCEAs. Specifically, the five holistic large-scale optimizers are TPLSO [
31], SPLSO [
55], LLSO [
54], CSO [
29], and SLPSO [
55], respectively, while the four CCEAs are DECC-GDG [
69], DECC-DG [
74], DECC-RDG [
79], and DECC-RDG2 [
74], respectively. In particular, we compare EDPSO with these algorithms on the 1000-
D CEC’2010 and the 1000-D CEC’2013 large-scale benchmark sets.
Table 4 and
Table 5 show the fitness comparison results between EDPSO and the nine compared algorithms on the CEC’2010 and the CEC’2013 benchmark sets, respectively. In these two tables, the symbol “+” above the
p-value indicates that the proposed EDPSO is significantly superior to the associated compared algorithms on the corresponding problems, and the symbol “−” means that EDPSO is significantly inferior to the associated compared algorithms on the related problems, while the symbol “=” denotes that EDPSO achieves equivalent performance with the compared algorithms on the associated problems. Accordingly, “
w/
t/
l” in the second to last rows of the two tables count the numbers of “+”, “=”, and “–”, respectively. In addition, the last rows of the two tables present the averaged ranks of all algorithms, which are obtained from the Friedman test.
From
Table 4, the comparison results between EDPSO and the nine compared algorithms on the 20 1000-
D CEC’2010 benchmark problems are summarized as follows:
- (1)
From the perspective of the averaged ranks (shown in the last row) obtained by the Friedman test, EDPSO and LLSO achieve much smaller rank values than the other eight compared algorithms. This demonstrates that the proposed EDPSO and LLSO achieve significantly better performance on the CEC’2010 benchmark set than the other eight compared algorithms.
- (2)
In view of the results (shown in the second to last row) obtained from the Wilcoxon rank-sum test, it is intuitively found that the proposed EDPSO is significantly better than the nine compared algorithms on at least 11 problems, and shows inferiority to them on at most eight problems. In particular, compared with the five holistic large-scale PSOs (namely TPLSO, SPLSO, LLSO, CSO, and SL-PSO), EDPSO shows significant dominance to them on 11, 12, 11, 15, and 12 problems, respectively, and only displays inferiority to them on eight, seven, eight, five, and eight problems, respectively. In comparison with the four CCEAs (namely, DECC-GDG, DECC-DG2, DECC-RDG, and DECC-RDG2), EDPSO significantly outperforms DECC-GDG on 17 problems, and significantly beats DECC-DG2, DECC-RDG, and DECC-RDG2 on all 15 problems.
From
Table 5, we can draw the following conclusions with respect to the comparison results between the proposed EDPSO and the nine state-of-the-art compared methods on the 15 1000-
D CEC’2013 benchmark problems:
- (1)
In terms of the average rank values obtained from the Friedman test, the proposed EDPSO achieves a much smaller rank value than seven compared algorithms. This indicates that the proposed EDPSO achieves much better overall performance than them on such a difficult benchmark set. In particular, EDPSO achieves considerably similar performance with LLSO, but obtains slightly inferior performance to TPLSO.
- (2)
With respect to the results obtained from the Wilcoxon rank-sum test, in comparison with the five holistic large-scale PSO variants, EDPSO significantly dominates SPLSO, CSO, and SL-PSO six, eight, and eight problems, respectively, and only exhibits inferiority to them in three, three, and four problems, respectively. Compared with LLSO, EDPSO achieves very competitive performance with it. However, in comparison with TPLSO, EDPSO shows slightly inferiority on this benchmark set. Competed with the four CCEAs, EDPSO presents significant superiority to them all on 12 problems and displays inferiority to them all on three problems.
The above experiments have demonstrated the effectiveness of the proposed EDPSO in solving high-dimensional problems. To further demonstrate its efficiency, we conduct experiments on the CEC’2010 and the CEC’2013 benchmark sets to investigate the convergence behavior comparisons between EDPSO and the compared algorithms. In these experiments, we set the maximum number of fitness evaluations as 5 × 10
6 for all algorithms. Then, we record the global best fitness every 5 × 10
5 fitness evaluations.
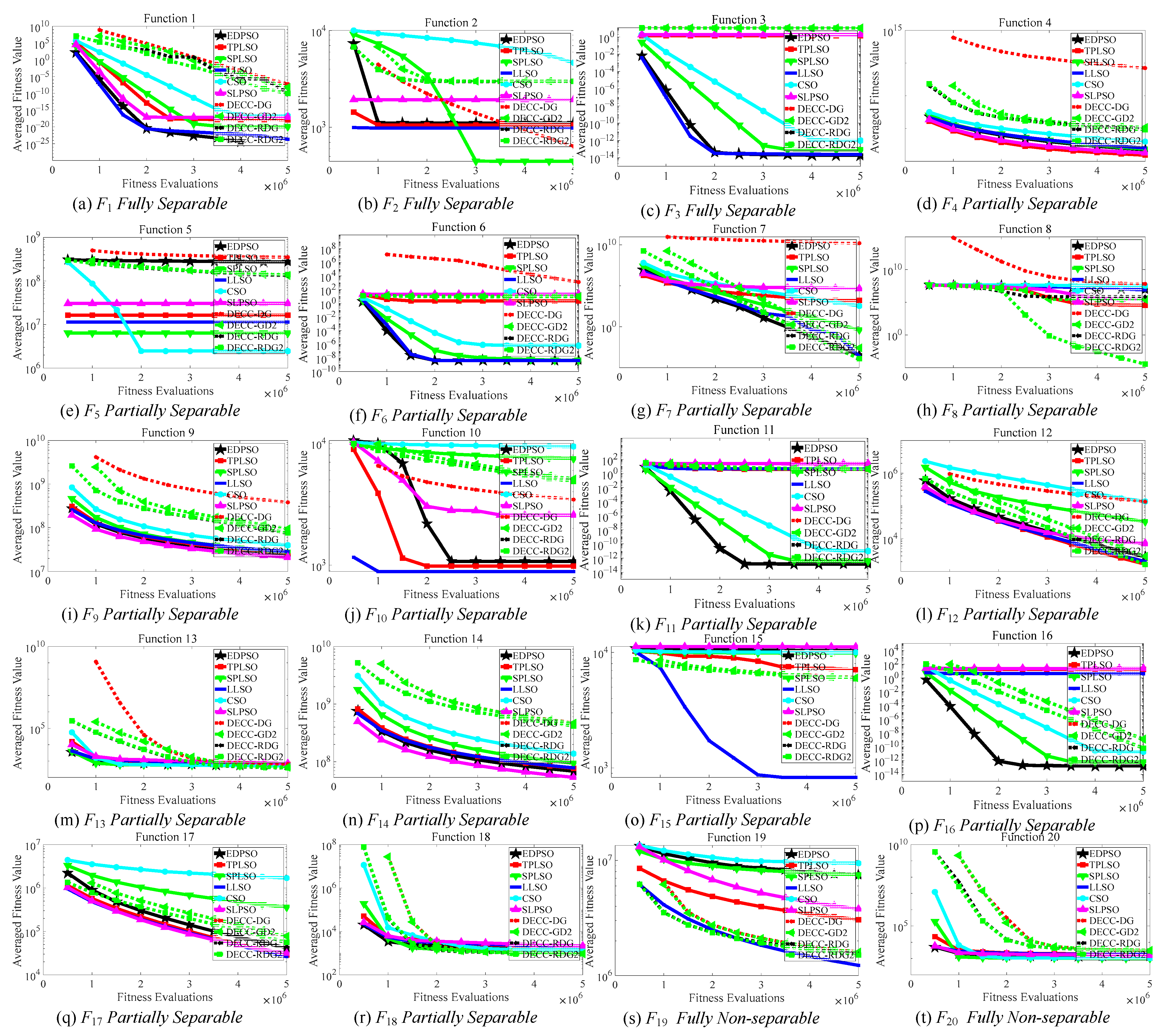
Figure 2 and
Figure 3 display the convergence behavior comparisons between EDPSO and the nine compared algorithms on the CEC’2010 and the CEC’2013 benchmark sets, respectively.
From
Figure 2, at first glance, we find that EDPSO achieves clearly better performance than the nine compared algorithms in terms of both convergence speed and solution quality on three problems (
F1,
F11, and
F16). In particular, EDPSO could finally find the true global optimum of
F1. Taking deep observation, it is found that on the whole CEC’2010 benchmark set, the proposed EDPSO achieves highly competitive or even much better performance than most of the compared algorithms on most problems with respect to both the convergence speed and the solution quality. This implicitly demonstrates that the proposed EDPSO is efficient when solving high-dimensional problems.
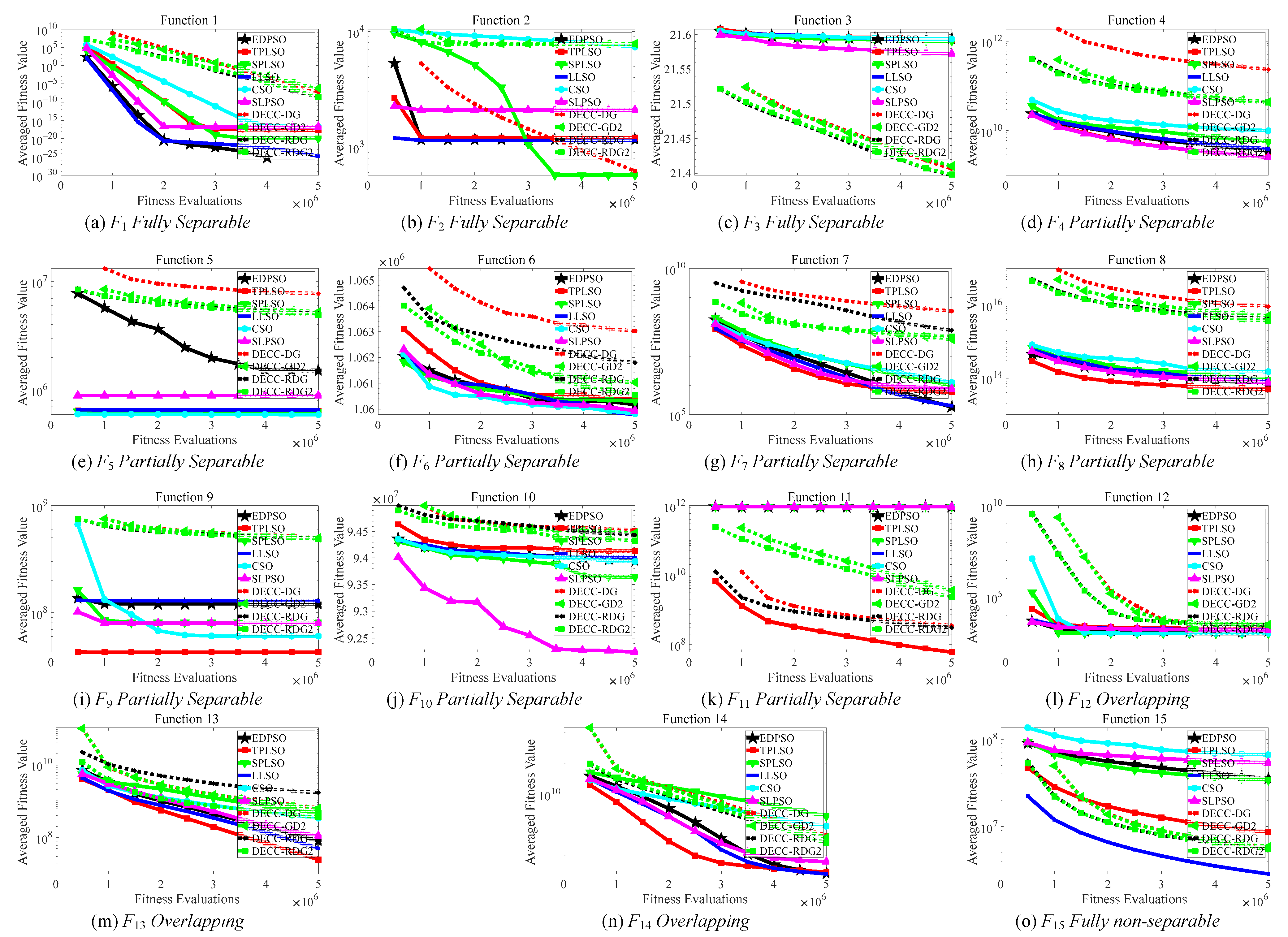
From
Figure 3, the convergence comparison results between the proposed EDPSO and the compared algorithms on the CEC’2013 show that the proposed EDPSO still presents considerably competitive or even great superiority to most of the compared algorithms on most problems in terms of both the convergence speed and the solution quality. This further demonstrates that the proposed EDPSO is efficient when solving complicated high-dimensional problems.
The above experiments on the two benchmark sets have demonstrated the effectiveness and efficiency of the proposed EDPSO. The superiority of EDPSO in solving high-dimensional problems mainly benefits from the proposed elite-directed learning strategy, which treats particles in different layers differently and lets particles in different layers learn from different numbers of predominant particles in higher layers. With this strategy, the learning effectiveness and the learning diversity of particles are largely improved, and the algorithm could compromise the search diversification and intensification well at the swarm level and the particle level to explore and exploit the solution space properly to obtain satisfactory performance.
4.3. Effectiveness of the Additional Archive
In this section, we conduct experiments to verify the usefulness of the additional archive. To this end, we first develop two versions of EDPSO. First, we remove the archive in EDPSO, leading to a variant of EDPSO, which we name as “EDPSO-WA”. Second, to demonstrate the effectiveness of using predominant individuals in the archive that are better than the best in the third layer, we replace this strategy by randomly choosing individuals in the archive along with the first two layers to direct the update of particles in the third layer. As a result, a new variant of EDPSO, which we name “EDPSO-ARand”, is developed. Then, we conduct experiments on the CEC’2010 benchmark set to compare the three different versions of EDPSO.
Table 6 presents the comparison results with the best results in bold.
From
Table 6, we can obtain the following findings. (1) With respect to the results of the Friedman test, the proposed EDPSO achieves the smallest rank among the three versions of EDPSO. In addition, from the perspective of the number of problems where the associated algorithm obtains the best results, we find the proposed EDPSO obtains the best results on 10 problems. These observations demonstrate the effectiveness of the additional archive and the way of using this archive. (2) Further, compared with EDPSO-WA, both the proposed EDPSO and EDPSO-ARand achieve much better performance. This demonstrates the usefulness of the additional archive. In comparison with EDPSO-ARand, the proposed EDPSO performs much better. This demonstrates the usefulness of the way of using predominant individuals in the archive to direct the update of particles in the third layer.
To summarize, the additional archive is helpful for EDPSO to achieve promising performance. This is because it introduces more candidate exemplars for particles in the third layer without destroying the convergence of the swarm. In this way, the learning diversity of particles is further promoted, which is beneficial for the swarm to explore the solution space and escape from local regions.
5. Conclusions
This paper has proposed an elite-directed particle swarm optimization with historical information (EDPSO) to tackle large-scale optimization problems. By taking inspiration from the “Pareto Principle”, which is also known as the 80-20 rule, we first partition the swarm into three layers with the first layer containing the top best 20% of particles and the other two layers of the same size consisting of the remaining 80% of particles. Then, particles in the third layer are updated by learning from two different exemplars randomly selected from those in the first two layers, and particles in the second layer are updated by learning from two different exemplars randomly selected from the first layer. To preserve the valuable evolutionary information, particles in the first layer are not updated and directly enter the next generation. To make full use of potentially valuable historical information, we additionally maintain an archive to store the obsolete elites in the first layer and then introduce them to the learning of particles in the third layer. With the above two techniques, particles in the last two layers could learn from different numbers of predominant candidates, and therefore the learning effectiveness and the learning diversity of particles are expectedly largely improved. By means of the proposed elite-directed learning strategy, EDPSO could compromise exploration and exploitation well at both the particle level and the swarm level to search high-dimensional space, which contributes to its promising performance solving complex large-scale optimization problems.
Extensive experiments have been conducted on the widely used CEC’2010 and CEC’2013 large-scale benchmark sets to validate the effectiveness of the proposed EDPSO. Experimental results have demonstrated that the proposed EDPSO could consistently achieve much better performance than the compared peer large-scale optimizers on the two benchmark sets. This verifies that EDPSO is promising for solving large-scale optimization problems in real-world applications.
However, in EDPSO, the control parameter ϕ is currently fixed and needs fine-tuning, which requires a lot of effort. To alleviate this issue, in the future, we will concentrate on devising an adaptive adjustment scheme for ϕ to eliminate its sensitivity based on the evolution state of the swarm and the evolutionary information of particles. In addition, to promote the application of the proposed EDPSO, in the future, we will also focus on utilizing EDPSO to solve real-world optimization problems.







{kind=link}
{kind=link}
{kind=link}