1. Introduction
Propensity Score Matching (PSM) is a useful method to reduce the impact of treatment selection bias in the estimation of causal effects in observational studies. Since firstly described by Rosenbaum and Rubin in 1983 [
1], its utility in Medicine, Psychology, Economics and other fields has increased exponentially in the last years, reaching a 17-fold increase in recent years [
2,
3]. Although it does not bypass the necessity for randomized studies, it may be an alternative to reduce the impact of treatment selection bias in observational studies.
The Propensity Score (PS) is defined as the subject’s probability of receiving a specific treatment conditional on the observed covariates [
1]. After stratification by its PS, treated and untreated patients are matched by their PS with the most similar individuals of the opposite group. It leads to a more similar distribution of baseline characteristics between treated and untreated subjects, and it has been demonstrated that because of this more homogeneous distribution of basal characteristics, this method reduces the treatment selection bias [
4,
5].
Once two comparable groups have been obtained, researchers treat PSM studies more similarly to randomized studies (although it does not substitute this randomized studies) and use them as a reasonable alternative for observational studies [
6]. In this sense, it is thought that because PSM controls the possible treatment selection bias, it would be possible to directly measure the effects in both matched groups, and thus it may be better for observational studies than other multivariate adjustment methods.
One important concern is the influence of the significant loss of non-matched individuals that may be seen in some works using this PSM method [
7] and who are not used for posterior analysis. Because we need to eliminate enough unmatched individuals to guarantee in some way the Treatment Selection Bias correction, it is not possible to know if the elimination of this unmatched individuals can cause some loss of information that in other ways would be analyzed and therefore lead us to a non controlled bias. In this sense other authors have reported the over-employment of this technique and its potential implications in potential biases [
8,
9].
Moreover, although we are controlling the Treatment Selection Bias, after matching, we are directly measuring the effect in both matched groups. In this way, compared with a multivariate adjustment method, which is widely used to control groups for other possible confounders, may lead to possible errors in effect estimation (due to overfitting, excess of covariation or reduced number of observations) [
10,
11,
12]. Despite this possible errors, as we previously mentioned, its utility has increased exponentially over the last years, so we need to address special awareness when using this methods. Because of that, we wanted to test the behavior of PSM in different situations, compared with a multivariate analysis based on General Linear Models (GLM) in the estimation of treatment effects to highlight the possible errors of this technique compared with a multivariate adjustment method. For this purpose, we developed a theoretical Monte Carlo Method of treatment effects in which we applied the PSM and a multivariate analysis based on a GLM to compare their ability to estimate the Real Treatment Effect (RTE) in each situation.
2. Materials and Methods
2.1. Theoretical Multivariate Model
Suppose is the patient z probability for a certain event. Its probability may be influenced by a series of independent variables and , each one of them with a concrete weight in this patient probability prediction and , respectively. variables may be related to the received treatment, and variables are supposed to be independent of the received treatment. It may be also influenced by the treatment status of the patient, which may confer some protection t against the event under study.
For each patient, there may be also some unmeasured influence of
in its event probability, which may vary from patient to patient and may be because some unknown or non-measured variables. We consider it as a random variable, which may be based in a normal distribution:
The unmeasured influence in the probability and the t and weights will have positive values if predispose to the adverse event, and thus, negative values are protectors in some way to the adverse event.
Each patient may present some different characteristics. A part from these and characteristics that may predispose in some way the probability for the event under study, it may present other variables unrelated with the event under study. Some of them may predispose to receive the treatment under study , and others, , may be unrelated to either patient outcomes or treatment predisposition.
For a concrete patient, the logit of the probability for a certain event may be predicted by the formula:
Thus, the theoretical event probability for a
z given patient will be:
For posterior metrics, the RTE will be the estimated coefficient [
13]. This RTE will be defined as the Odds Ratio of this probability:
2.2. Monte Carlo Simulations
Once the theoretical model was built, Monte Carlo Simulations were made to construct groups for a posterior analysis. Simulated experiments under this conditions were made, and an event status
was assigned to each patient
z in each simulated experiment, based on a binomial distribution with
and probability
:
The theoretical (real) treatment effect was modified after each group of simulations, ranging from a 0 (null) effect to a 5-fold event reduction (−5) in intervals.
Apart from the treatment status and the treatment effect in each simulation, the previously described groups of variables with each concrete weight were introduced in the model for each simulation. This variables were distributed by a binomial distribution with a probability that varied depending on its correlation with other variables. In each group of variables, each variable weight ranged from −2 (protects) to 2 (predisposes).
A total of Monte Carlo Simulations were conducted. There were 50 blocks of experiments, each one with a different real treatment effect. In each block of experiments, each experiment was simulated with 500 individuals and later repeated 200 times for each real treatment effect.
2.3. Unadjusted Model
The Odds Ratio for the event prevention under Treatment status was calculated with a univariable General Linear Model (GLM). For each experiment, with the complete matrix of events
Y and treatment
X status, a GLM was built to estimate the unadjusted estimated risk prevention effect for the treatment
(
stands for Unadjusted Model):
where
U is the error derived from the effects not measured by the model.
From this built model, the estimated Odds Ratio for the RTE
was calculated:
Since this measured Odds Ratio did not take in account other variables, it will be named the unadjusted Odds Ratio, and it will be considered the reference for the improvement in the RTE estimation.
2.4. Multivariate Regression Model
For control purposes, a Multivariate Regression Model (MRM) was built for each experiment with all the variables under analysis. In each experiment, the complete matrix of events
Y, treatment status
X and analyzed variables
A (outcome predictors related to the received treatment),
B (outcome predictors independent of the received treatment),
C (variables that predispose to the received treatment) and
D (variables unrelated to both outcomes and received treatment) were used to build the MRM and estimate the multivariate adjusted event reduction of the treatment
(
stands for Multivariate Regression Model):
where
q,
s,
u and
v are the estimated weights of each kind of variable by the Multivariate Regression Model.
From this built model, the estimated Odds Ratio for the RTE (Multivariate Odds Ratio,
) is calculated:
It will be used as the gold standard for the estimation of the RTE.
2.5. Propensity Score Matching Model
PSM was used to estimate the Treatment Effect. As described early, the PS was built based on a MRM designed to estimate each patient’s predisposition to receive the treatment under investigation. In each patient, the PS was calculated for posterior matching between treated and untreated individuals. For matching, the nearest method was used (with a caliper of 0.2) with the R algorithm included in the MatchIt library [
14].
Once matching was completed, the treatment effect was estimated based on a GLM. For each experiment, the matrix of matched individuals with the events
and treatment
status were used to build a GLM to estimate the estimated risk prevention effect for the treatment
(
stands for Propensity Score Matching Model):
From this built model, the estimated Odds Ratio for the RTE
was calculated:
2.6. Statistical Analysis
For each treatment effect situation, RTE Estimation was measured with each one of the three described methods. This RTE estimation was later compared with the RTE to calculate the inaccuracy of the RTE Estimation (Relative RTE Estimation Error). All variables were expressed as mean +/− 95% Confidence Intervals. The comparison of the RTE Estimation Error between the three described methods was performed with a multivariate analysis of variance (MANOVA test).
For the MRM and the PSM Model, the RTE Estimation Error was compared with the Unadjusted Model to calculate the Relative RTE Estimation Error Reduction for each one. The comparison of this Relative RTE Estimation Error Reduction between MRM and PSM Model was performed with a paired T Test.
For the Unadjusted Model and the PSM Model, the Treatment Selection Bias was calculated with a Pearson’s chi-squared test to evaluate the homogeneity between groups. The comparison of the Treatment Selection bias between both models was performed with a paired T Test comparing the the chi-squared test statistic of both models, and the reduction in the Treatment Selection bias with the PSM Model was expressed as mean +/− 95% Confidence Intervals.
For the PSM Model, the percentage of excluded patients in each analysis was also analyzed. This was be expressed as the mean of the percentage exclusions in each analysis and the 95% Confidence Interval of the percentage exclusions in each analysis.
2.7. Analysis Software
For the data generation with the Monte Carlo Simulations and the posterior analysis, the open software R [
15] was used. The R library MatchIt [
14] was used for the PSM. All written code for this purpose is available through the PropensityScoreReview repository [
16].
3. Results
3.1. Treatment Selection Bias Reduction with Propensity Score Matching
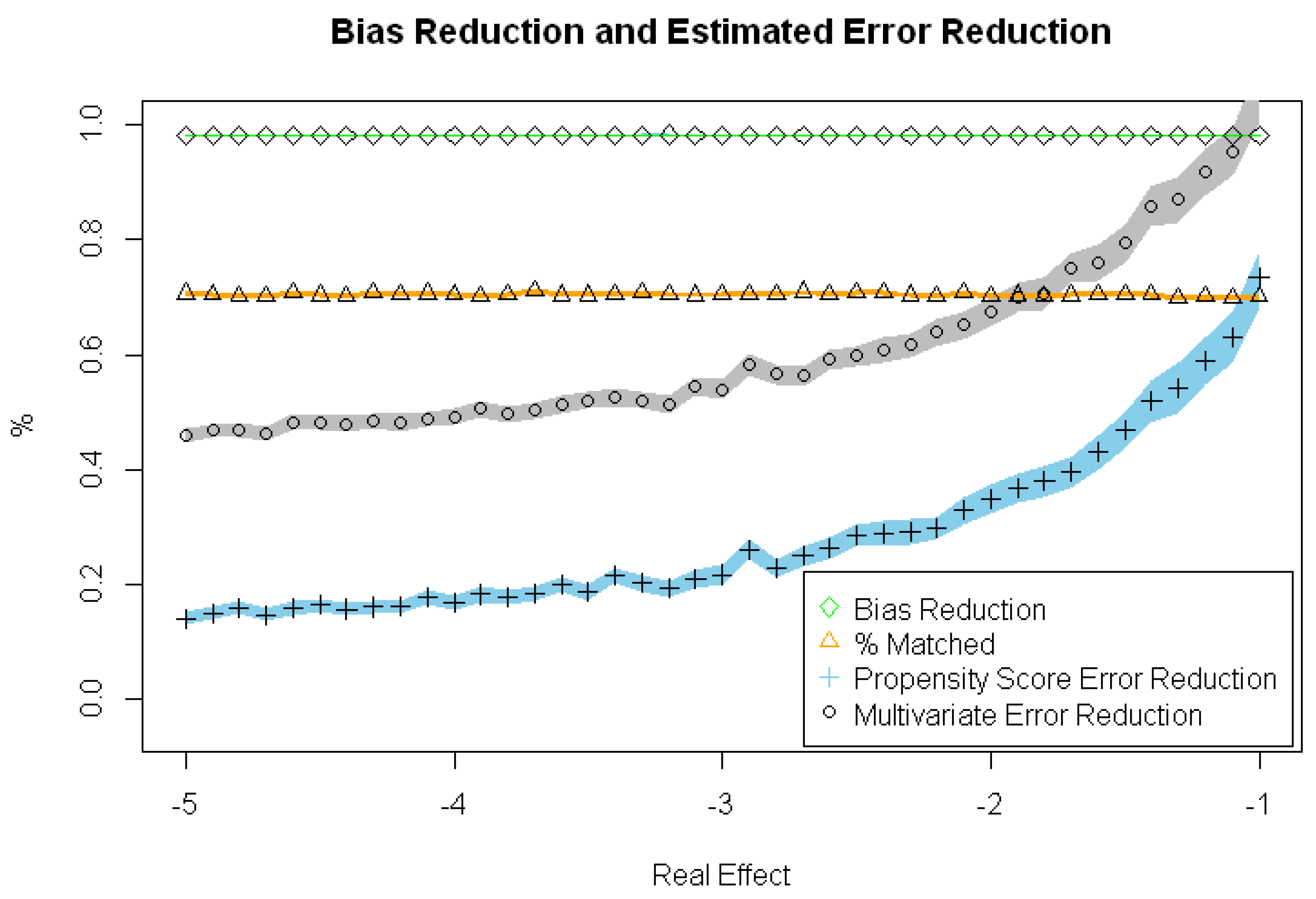
The PSM Model significantly reduces the Treatment Selection Bias in all scenarios. As seen in
Table 1 and
Figure 1, there is a Relative Treatment Selection Bias reduction of about 0.98 in all scenarios. The main problem of this model is the important number of excluded patients (there is only a 70% of patients that are included for the analysis).
3.2. Real Treatment Effect Estimation and Relative Real Treatment Effect Estimation Error Reduction with Propensity Score Matching Model and Multivariate Regression Model
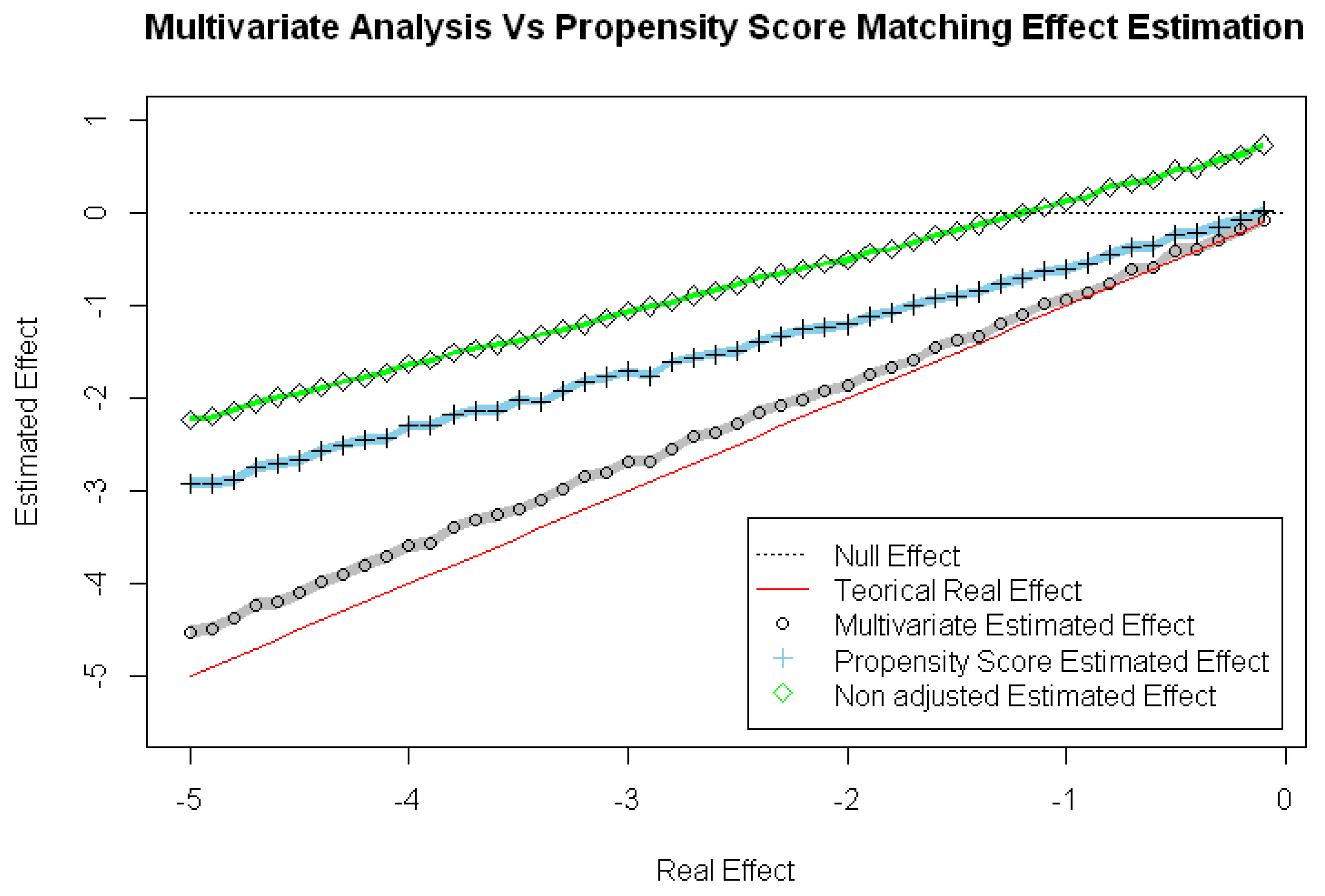
As it can be seen in
Figure 2 and
Figure 3 and
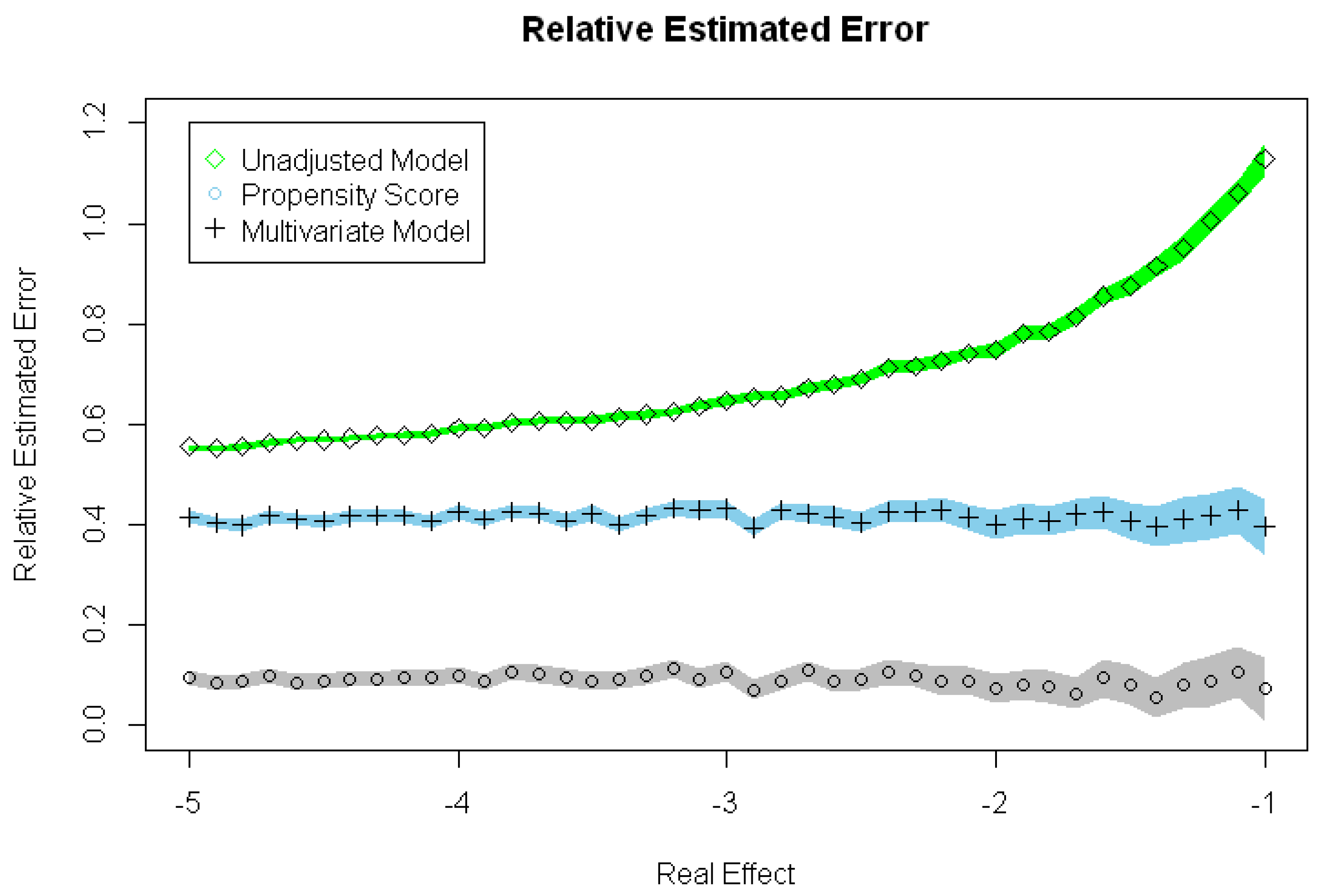
Table 2, the PSM Model and the MRM significantly estimate a more accurate RTE than the Unadjusted Model. This PSM Model and MRM present a significantly reduced Relative RTE Estimated Error, compared with the Unadjusted Model.
The MRM also presents a Relative RTE Estimated Error significantly lower than the PSM Model, which leads to a significantly increased Relative RTE Estimated Error Reduction compared with the PSM Model.
4. Discussion
PSM has been widely used in different subjects for Treatment Selection Bias reduction. As we show in this present work, PSM corrects the Treatment Selection Bias properly, obtaining two comparable groups, so we can thus directly measure the effect under investigation. In this sense, in our work, the Treatment Selection Bias practically disappears with the PSM (Treatment Selection Bias reduction of 0.982–0.983 among all scenarios). However, despite this reduction, PSM still fails in the RTE estimation, compared with MRM. We demonstrate how despite this reduction in Treatment Selection Bias, the Relative RTE Estimation error rounds to 0.4 while the MRM is 4 times smaller (it rounds to 0.1).
As we mentioned earlier, our main concern about the PSM method is the percentage of unmatched individuals and its possible influence on the posterior estimation of RTE. Other authors have also suggested how the PSM can misestimate the effect compared with MRM [
10,
11,
12]. In our work, there is significant sample reduction, with a percentage of analyzed individuals of 70.12 to 70.66% from the total individuals under investigation. In addition, it may be the reason for the inaccuracy of the RTE Estimation compared with the MRM.
MRMs do not deal with two comparable populations, but instead, they weigh the different variables under study. Despite dealing with non-comparable groups, thanks to this weighting of the analyzed variables, the MRM can find a solution in a different way than the problem of the Treatment Selection Bias. In addition, since no individual is eliminated from the analysis, there is no loss of information, reducing other potential biases that may appear in the PSM method.
In our present work, although both (PSM and MRM) reduce the Relative RTE Estimation Error, this reduction is better with the MRM than the PSM. This best performance of the MRM may confirm our previous preoccupation about the possible influence of the sample reduction in the posterior estimation of the RTE.
Since there may be a significant reduction in the sample under analysis when we are using a PSM method, we have to take it in account before accepting the obtained results, especially when this reduction is important. Other multivariate methods should always be performed in addition to the PSM analysis and both results compared in order to seek a possible uncontrolled bias. If a significant difference is obtained between both analyses, we have to suspect a possible bias derived from the sample reduction once the matching has been performed.
5. Conclusions
With the PSM, a reduction in the Treatment Selection Bias is achieved with a reduction in the Relative Real Treatment Effect Estimation Error, but the MRM reduces this estimation error significantly more compared with the PSM. In addition, the PSM leads to a significant reduction in the sample, with some loss of information derived from the matching process that may lead to another not known bias and thus to the inaccuracy of the effect estimation compared with the MRM.




{kind=link}
{kind=link}
{kind=link}