
A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews

 ,
,  , , and
, , and
Abstract
:1. Introduction
- This research work is one of the first studies to build a framework combining sentiment analysis and a hybrid recommendation system for recommending movies that are not yet released, but where only the trailer has been released.
- We also proposed a model that predicts the movie’s rating before the movie’s official release by analyzing the sentiment of comments from trailer videos on YouTube.
- We have proposed a new way of calculating the comprehensive sentiment of a unreleased movie.
- We also proposed a new framework of a hybrid recommendation system, which can recommend an upcoming new movie to a user based on their preferences.
- We have proposed an idea to calculate the weighting of each movie feature in order to calculate the similarity between two movies.
2. Related Works
2.1. Recommendation System
2.2. Sentiment Analysis
3. Material and Methods
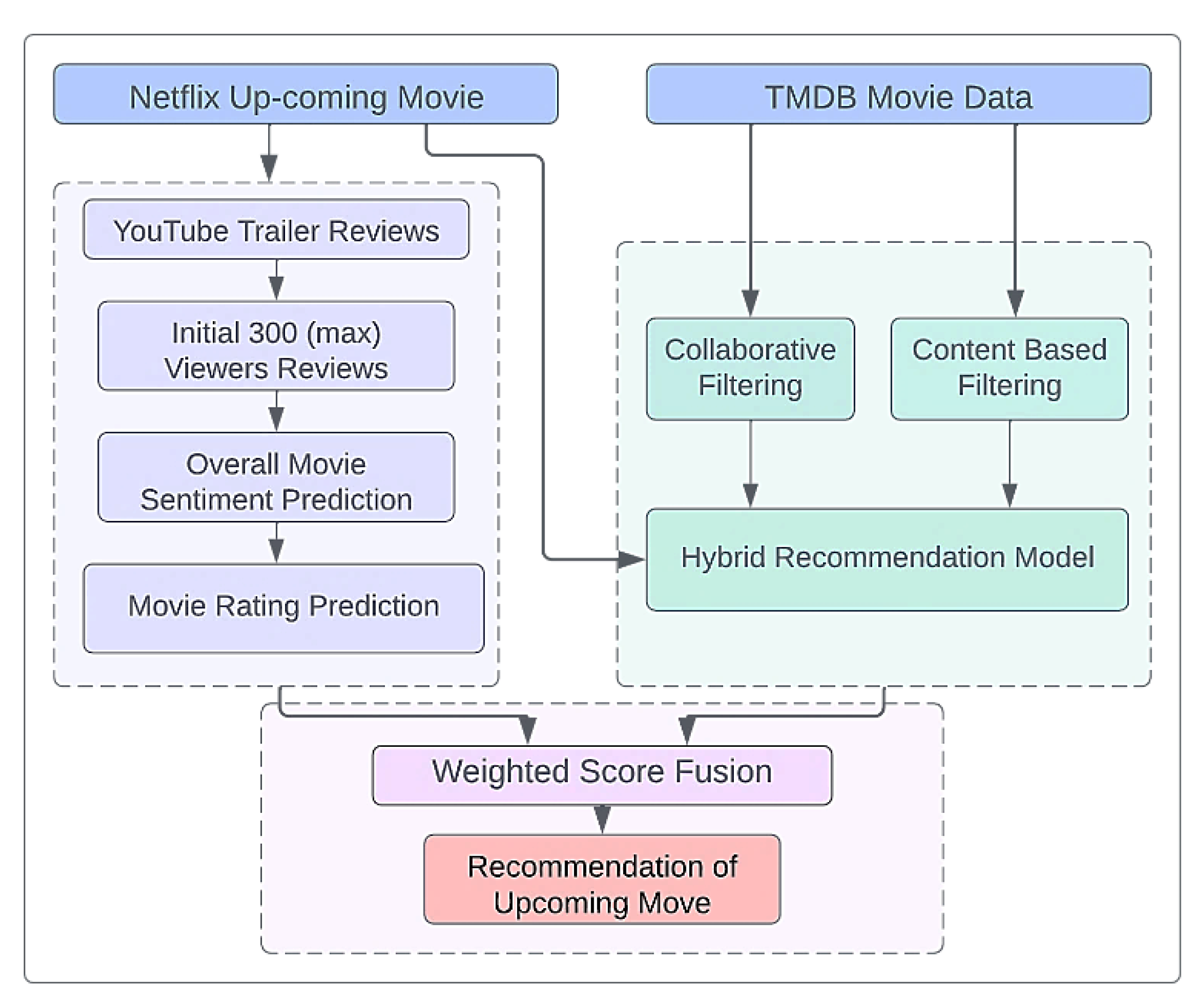
3.1. Proposed Framework
- Movie trailers are usually released well before the release of the actual movie. Forthcoming movie trailers are generally available on YouTube. Viewers share their views about the trailer and express their thoughts regarding the unreleased movie by posting comments on the YouTube trailer video. In our proposed work, module one extracts the movie trailer comments from the official YouTube channel of Netflix. We then compute the overall sentiment and also predict the rating of the forthcoming movie.
- In module 2, our objective is to produce a list of unreleased movies according to the preferences or likes of the individual user. Here, we have used the TMDb dataset, which contains movie metadata and user rating data. Firstly, we compute user preferences using the TMDb user rating dataset. Next, with the help of intrinsic movie data, we have discovered similar movies from the upcoming movie dataset that align with the user’s taste. This module combines the previous and upcoming movies data and builds a hybrid recommendation system in order to produce a list of preferred upcoming movies.
- The first module assesses the popularity of the forthcoming movies by predicting the rating of each new movie. The second module presents a list of new movies closely similar to the user’s existing preferred movies. In the third module, we fuse the predicted ranking and preferred list of forthcoming movies from modules one and two. Finally, we are able to offer potentially popular unreleased movies to the user, according to their preference.
3.2. Dataset Description
3.2.1. YouTube Trailer Review Dataset
3.2.2. TMDb Data Set
4. Experimental Methods
4.1. Analysis of Review Data
4.1.1. Preprocessing of Review Data
4.1.2. Sentiment Analysis
4.2. Hybrid Recommendation System
| Algorithm 1: Hybrid Recommendation System for up-coming Movie Recommendations. |
| Input: Set of Users Set of Movies Set of New Movies User Rating Matrix Movie Feature vector Feature Weight vector IMDb Rating of all movies Predicted Rating of all new movies Output: Recommendmost promising upcoming movies according to the preference .
|
4.3. Weighted Score Fusion
5. Result and Discussion
5.1. New Movie Rating Prediction
5.2. Movie Similarity
5.3. Hybrid Recommender System
5.4. Combined Score (CS)
5.5. Qualitative Analysis
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carrer-Neto, W.; Hernández-Alcaraz, M.L.; Valencia-García, R.; García-Sánchez, F. Social knowledge-based recommender system. Application to the movies domain. Expert Syst. Appl. 2012, 39, 10990–11000. [Google Scholar] [CrossRef] [Green Version]
- Winoto, P.; Tang, T.Y. The role of user mood in movie recommendations. Expert Syst. Appl. 2010, 37, 6086–6092. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September2016; pp. 233–240. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30October2008; pp. 931–940. [Google Scholar]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15August 2002; pp. 253–260. [Google Scholar]
- Ma, H.; Zhou, T.C.; Lyu, M.R.; King, I. Improving recommender systems by incorporating social contextual information. ACM Trans. Inf. Syst. (TOIS) 2011, 29, 1–23. [Google Scholar] [CrossRef]
- Sarwar, B.M. Sparsity, Scalability, and Distribution in Recommender Systems; University of Minnesota: Minneapolis, MN, USA, 2001. [Google Scholar]
- Huang, Z.; Chen, H.; Zeng, D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 116–142. [Google Scholar] [CrossRef] [Green Version]
- Natarajan, S.; Vairavasundaram, S.; Natarajan, S.; Gandomi, A.H. Resolving data sparsity and cold start problem in collaborative filtering recommender system using linked open data. Expert Syst. Appl. 2020, 149, 113248. [Google Scholar] [CrossRef]
- Lu, Z.; Dou, Z.; Lian, J.; Xie, X.; Yang, Q. Content-based collaborative filtering for news topic recommendation. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Sharma, L.; Anju, G. A survey of recommendation system: Research challenges. Int. J. Eng. Trends Technol. (IJETT) 2013, 4, 1989–1992. [Google Scholar]
- Das, N.; Borra, S.; Dey, N.; Borah, S. Social networking in web based movie recommendation system. In Social Networks Science: Design, Implementation, Security, and Challenges; Springer: Cham, Switzerland, 2018; pp. 25–45. [Google Scholar]
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation systems: Principles, methods and evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Shani, G.; Gunawardana, A. Evaluating recommendation systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 257–297. [Google Scholar]
- Melville, P.; Sindhwani, V. Recommender systems. Encycl. Mach. Learn. 2010, 1, 829–838. [Google Scholar]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 77–118. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Lops, P.; Gemmis, M.D.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 73–105. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. In The Adaptive Web; Springer: Heidelberg/Berlin, Germany, 2007; pp. 325–341. [Google Scholar]
- Burke, R. Hybrid recommender systems: Survey and experiments. User Modeling User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web; Springer: Heidelberg/Berlin, Germany, 2007; pp. 377–408. [Google Scholar]
- Paradarami, T.K.; Bastian, N.D.; Wightman, J.L. A hybrid recommender system using artificial neural networks. Expert Syst. Appl. 2017, 83, 300–313. [Google Scholar] [CrossRef]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis; Springer: Cham, Switzerland, 2017; pp. 1–10. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Yang, C.; Wei, B.; Wu, J.; Zhang, Y.; Zhang, L. CARES: A ranking-oriented CADAL recommender system. In Proceedings of the 9th ACM/IEEE-CS Joint Conference on Digital Libraries, New York, NY, USA, 15–19 June2009; pp. 203–212. [Google Scholar]
- Katarya, R.; Verma, O.P. Recommender system with grey wolf optimizer and FCM. Neural Comput. Appl. 2018, 30, 1679–1687. [Google Scholar] [CrossRef]
- Hsu, C.C.; Chen, H.C.; Huang, K.K.; Huang, Y.M. A personalized auxiliary material recommendation system based on learning style on Facebook applying an artificial bee colony algorithm. Comput. Math. Appl. 2012, 64, 1506–1513. [Google Scholar] [CrossRef] [Green Version]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Alcalá, J. Improving collaborative filtering recommender system results and performance using genetic algorithms. Knowl.-Based Syst. 2011, 24, 1310–1316. [Google Scholar] [CrossRef]
- Ujjin, S.; Bentley, P.J. Particle swarm optimization recommender system. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium, SIS’03 (Cat. No. 03EX706), Indianapolis, IN, USA, 26 April 2003; pp. 124–131. [Google Scholar]
- Katarya, R. Movie recommender system with metaheuristic artificial bee. Neural Comput. Appl. 2018, 30, 1983–1990. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Yuan, Z.; Jin, Q. Personalized real-time movie recommendation system: Practical prototype and evaluation. Tsinghua Sci. Technol. 2019, 25, 180–191. [Google Scholar] [CrossRef]
- Lavanya, R.; Bharathi, B. Movie Recommendation System to Solve Data Sparsity Using Collaborative Filtering Approach. Trans. Asian Low-Resour. Lang. Inf. Processing 2021, 20, 1–14. [Google Scholar] [CrossRef]
- Chen, Y.L.; Yeh, Y.H.; Ma, M.R. A movie recommendation method based on users’ positive and negative profiles. Inf. Processing Manag. 2021, 58, 102531. [Google Scholar] [CrossRef]
- Philip, S.; Shola, P.; Ovye, A. Application of content-based approach in research paper recommendation system for a digital library. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 37–40. [Google Scholar] [CrossRef] [Green Version]
- Viard, T.; Fournier-S’niehotta, R. Movie rating prediction using content-based and link stream features. arXiv 2018, arXiv:1805.02893. [Google Scholar]
- Belkin, N.J.; Croft, W.B. Information filtering and information retrieval: Two sides of the same coin? Commun. ACM 1992, 35, 29–38. [Google Scholar] [CrossRef]
- Di Noia, T.; Mirizzi, R.; Ostuni, V.C.; Romito, D.; Zanker, M. Linked open data to support content-based recommender systems. In Proceedings of the 8th International Conference on Semantic Systems, Graz, Austria, 5–7 September 2012; pp. 1–8. [Google Scholar]
- Musto, C.; Lops, P.; de Gemmis, M.; Semeraro, G. Semantics-aware recommender systems exploiting linked open data and graph-based features. Knowl.-Based Syst. 2017, 136, 1–14. [Google Scholar] [CrossRef]
- Uluyagmur, M.; Cataltepe, Z.; Tayfur, E. Content-based movie recommendation using different feature sets. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 24–26 October 2012; Volume 1, pp. 17–24. [Google Scholar]
- Reddy, S.R.S.; Nalluri, S.; Kunisetti, S.; Ashok, S.; Venkatesh, B. Content-based movie recommendation system using genre correlation. In Smart Intelligent Computing and Applications; Springer: Singapore, 2019; pp. 391–397. [Google Scholar]
- Son, J.; Kim, S.B. Content-based filtering for recommendation systems using multiattribute networks. Expert Syst. Appl. 2017, 89, 404–412. [Google Scholar] [CrossRef]
- Ali, S.M.; Nayak, G.K.; Lenka, R.K.; Barik, R.K. Movie recommendation system using genome tags and content-based filtering. In Advances in Data and Information Sciences; Springer: Singapore, 2018; pp. 85–94. [Google Scholar]
- Belarbi, M.A.; Mahmoudi, S.; Belalem, G. PCA as dimensionality reduction for large-scale image retrieval systems. Int. J. Ambient. Comput. Intell. (IJACI) 2017, 8, 45–58. [Google Scholar] [CrossRef] [Green Version]
- Elahi, M.; Deldjoo, Y.; Bakhshandegan Moghaddam, F.; Cella, L.; Cereda, S.; Cremonesi, P. Exploring the semantic gap for movie recommendations. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 326–330. [Google Scholar]
- Deldjoo, Y.; Dacrema, M.F.; Constantin, M.G.; Eghbal-Zadeh, H.; Cereda, S.; Schedl, M.; Ionescu, B.; Cremonesi, P. Movie genome: Alleviating new item cold start in movie recommendation. User Modeling User-Adapt. Interact. 2019, 29, 291–343. [Google Scholar] [CrossRef] [Green Version]
- Breitfuss, A.; Errou, K.; Kurteva, A.; Fensel, A. Representing emotions with knowledge graphs for movie recommendations. Future Gener. Comput. Syst. 2021, 125, 715–725. [Google Scholar] [CrossRef]
- Aslanian, E.; Radmanesh, M.; Jalili, M. Hybrid recommender systems based on content feature relationship. IEEE Trans. Ind. Inform. 2016. [Google Scholar] [CrossRef]
- Porcel, C.; Tejeda-Lorente, A.; Martínez, M.A.; Herrera-Viedma, E. A hybrid recommender system for the selective dissemination of research resources in a technology transfer office. Inf. Sci. 2012, 184, 1–19. [Google Scholar] [CrossRef]
- Melville, P.; Mooney, R.J.; Nagarajan, R. Content-boosted collaborative filtering for improved recommendations. In Proceedings of the Eighteenth National Conference on Artificial Intelligence (AAAI-2002), Edmonton, Canada, 28 July–1 August 2002; Volume 23, pp. 187–192. [Google Scholar]
- Zhang, H.R.; Min, F.; He, X.; Xu, Y.Y. A hybrid recommender system based on user-recommender interaction. Math. Probl. Eng. 2015, 2015, 145636. [Google Scholar] [CrossRef] [Green Version]
- Walek, B.; Fojtik, V. A hybrid recommender system for recommending relevant movies using an expert system. Expert Syst. Appl. 2020, 158, 113452. [Google Scholar] [CrossRef]
- Bahl, D.; Kain, V.; Sharma, A.; Sharma, M. A novel hybrid approach towards movie recommender systems. J. Stat. Manag. Syst. 2020, 23, 1049–1058. [Google Scholar] [CrossRef]
- Kumar, S.; De, K.; Roy, P.P. Movie recommendation system using sentiment analysis from microblogging data. IEEE Trans. Comput. Soc. Syst. 2020, 7, 915–923. [Google Scholar] [CrossRef]
- Duan, L.; Gao, T.; Ni, W.; Wang, W. A hybrid intelligent service recommendation by latent semantics and explicit ratings. Int. J. Intell. Syst. 2021, 36, 7867–7894. [Google Scholar] [CrossRef]
- Prabowo, R.; Thelwall, M. Sentiment analysis: A combined approach. J. Informetr. 2009, 3, 143–157. [Google Scholar] [CrossRef]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Wang, G.; Cheng, X.; Fu, Y. Mining affective text to improve social media item recommendation. Inf. Processing Manag. 2015, 51, 444–457. [Google Scholar] [CrossRef]
- Li, H.; Cui, J.; Shen, B.; Ma, J. An intelligent movie recommendation system through group-level sentiment analysis in microblogs. Neurocomputing 2016, 210, 164–173. [Google Scholar] [CrossRef]
- Diao, Q.; Qiu, M.; Wu, C.Y.; Smola, A.J.; Jiang, J.; Wang, C. Jointly modeling aspects, ratings and sentiments for movie recommendation (JMARS). In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August2014; pp. 193–202. [Google Scholar]
- Wang, L.; Niu, J.; Yu, S. SentiDiff: Combining textual information and sentiment diffusion patterns for Twitter sentiment analysis. IEEE Trans. Knowl. Data Eng. 2019, 32, 2026–2039. [Google Scholar] [CrossRef]
- Dang, C.N.; Moreno-García, M.N.; Prieta, F.D.L. An Approach to Integrating Sentiment Analysis into Recommender Systems. Sensors 2021, 21, 5666. [Google Scholar] [CrossRef] [PubMed]
- Xiang, R.; Chersoni, E.; Lu, Q.; Huang, C.R.; Li, W.; Long, Y. Lexical data augmentation for sentiment analysis. J. Assoc. Inf. Sci. Technol. 2021, 72, 1432–1447. [Google Scholar] [CrossRef]
- Cambria, E. Affective Computing and Sentiment Analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Liu, Q.; Decherchi, S.; Xing, F.; Kwok, K. SenticNet 7: A Commonsense-based Neurosymbolic AI Framework for Explainable Sentiment Analysis. LREC. 2022. Available online: https://sentic.net/publications/#sentiment-analysis (accessed on 2 May 2022).
- Wang, Z.; Ho, S.B.; Cambria, E. Multi-level fine-scaled sentiment sensing with ambivalence handling. Int. J. UncertainFuzziness Knowl.-Based Syst. 2020, 28, 683–697. [Google Scholar] [CrossRef]
- Valdivia, A.; Luzón, M.V.; Cambria, E.; Herrera, F. Consensus vote models for detecting and filtering neutrality in sentiment analysis. Inf. Fusion 2018, 44, 126–135. [Google Scholar] [CrossRef]
- Li, W.; Shao, W.; Ji, S.; Cambria, E. BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis. Neurocomputing 2022, 467, 73–82. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, J.; Zhang, J.; Wang, S. Aggregated graph convolutional networks for aspect-based sentiment classification. Inf. Sci. 2022, 600, 73–93. [Google Scholar] [CrossRef]
- Dai, A.; Hu, X.; Nie, J.; Chen, J. Learning from word semantics to sentence syntax by graph convolutional networks for aspect-based sentiment analysis. Int. J. Data Sci. Anal. 2022, 1–10. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/tmdb/tmdb-movie-metadata (accessed on 2 May 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reviewer Name | Comments | Time |
|---|---|---|
| Helen and Lolly | This film is going to break my heart. I can never have children. I have a long term illness. 😞 | 2021-09-06T16:00:12Z |
| Christina Watkins | Finally, a good Netflix movie trailer!!! Cannot wait to see Melissa play a more serious role ✨💕 | 2021-09-06T18:01:37Z |
| Samantha Richele | I'm already crying and it was just the trailer. 🥺😭 | 2021-09-07T00:57:40Z |
| Features | Value |
|---|---|
| Original title | The Starling |
| IMDb Rating | 6.3 |
| Director | Theodore Melfi |
| Cast | Melissa McCarthy, Chris O’Dowd, Kevin Kline |
| Release Year | 2021 |
| Genres | Comedy, Drama |
| Keywords | woman adjusting life loss contends feisty bird garden husband who’s struggling find forward |
| Type of Noise | Example |
|---|---|
| Stop words | The, an, a, in, are, as, at, be |
| Words more than three same consecutive latter | 2pacccccccccccc is better perioddddddddddddd baby baby stole pacs style babyyyyyyyyyyyyyyyyyyy |
| Weblink | May I know the background music name from <ahref=“https://www.youtube.com/watch?v=n4Uv5VHRDZg&t=0m33s”>0:33</a>❤......I just love it! |
| Special characters | #, @, !, $, %, …** |
| Emojis | 😂🤣❤□👍❤□ |
| Cleaned Comments | Positive | Neutral | Negative | Compound Score |
|---|---|---|---|---|
| looks really good hope movie trailerjitniacchi | 0.515 | 0.485 | 0 | 0.7485 |
| waste your time this boring chaotic with a stupid ending | 0 | 0.294 | 0.706 | −0.9006 |
| basically, Netflix does not want people to sleep alwaysbinge-watching | 0.14 | 0.86 | 0 | 0.0772 |
| Movie Name | Overall Sentiment | Predicted Rating | IMDb Rating |
|---|---|---|---|
| The Starling | 0.2359 | 6.2 | 6.3 |
| AjeebDaastaans | 0.3774 | 6.9 | 6.7 |
| Sentinelle | 0.0838 | 5.4 | 4.7 |
| Dance Dreams: Hot Chocolate Nutcracker | 0.5858 | 7.9 | 7.1 |
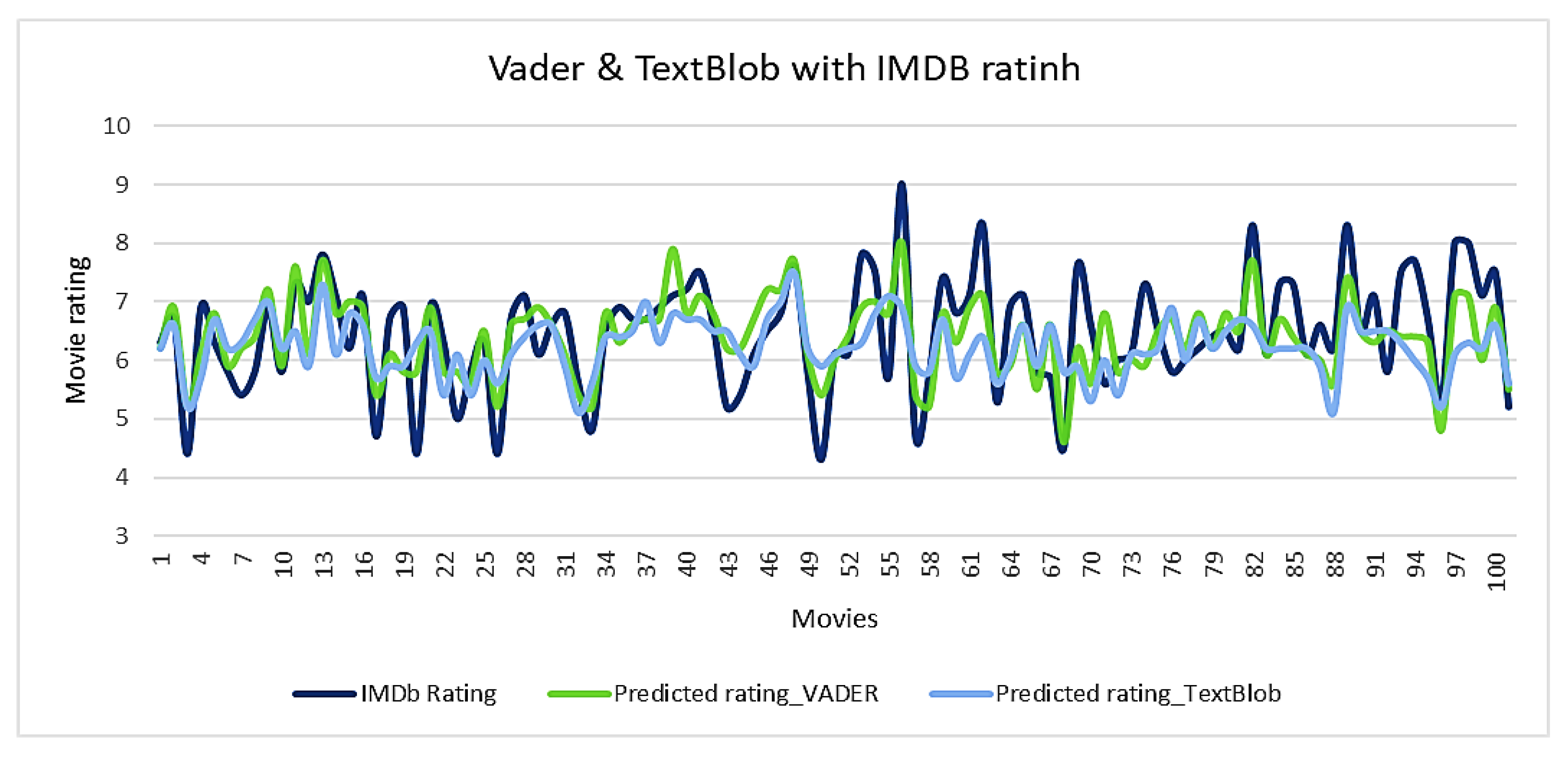
| S. No. | Movie Name | IMDb Rating | Vader Rating | TextBlob Rating |
|---|---|---|---|---|
| 1 | Caught by a Wave | 5.8 | 5.9 | 6.2 |
| 2 | The Starling | 6.4 | 6.2 | 6.2 |
| 3 | Squid Game | 8 | 7.1 | 6.3 |
| 4 | Dealer | 7.1 | 6.8 | 6.1 |
| 5 | Irul | 5.8 | 5.9 | 6.2 |
| 6 | The Midnight Sky | 5.6 | 5.4 | 5.1 |
| 7 | I Care a Lot | 6.3 | 5.8 | 5.4 |
| 8 | Ludo | 7.6 | 7.7 | 7.5 |
| 9 | Mank | 6.9 | 6.7 | 6.3 |
| 10 | The Devil All The Time | 7.1 | 6.6 | 6.6 |
| Sl. No | Original Title | Genres | Director | Similarity |
|---|---|---|---|---|
| 1 | Terminator2: Judgment Day | Action, Thriller, Science Fiction | James Cameron | 0.7319 |
| 2 | The Abyss | Adventure, Action, Thriller, Science Fiction | James Cameron | 0.5498 |
| 3 | Aliens | Horror, Action, Thriller, Science Fiction | James Cameron | 0.5498 |
| 4 | True Lies | Action, Thriller | James Cameron | 0.5375 |
| 5 | Terminator 3: Rise of the Machines | Action, Thriller, Science Fiction | Jonathan Mostow | 0.4534 |
| 6 | Terminator Genisys | Science Fiction, Action, Thriller, Adventure | Alan Taylor | 0.4139 |
| 7 | Avatar | Action, Adventure, Fantasy, Science Fiction | James Cameron | 0.3943 |
| 8 | Terminator Salvation | Action, Science Fiction, Thriller | Mcg | 0.3501 |
| 9 | The Running Man | Action, Science Fiction | Paul Michael Glaser | 0.3169 |
| 10 | Fortress | Action, Thriller, Science Fiction | Stuart Gordon | 0.3046 |
| Sl. No | Original Title | Genres | Director | Similarity |
|---|---|---|---|---|
| 1 | Revolutionary Road | Drama, Romance | Sam Mendes | 0.4512 |
| 2 | Jarhead | Drama, War | Sam Mendes | 0.4268 |
| 3 | Road to Perdition | Thriller, Crime, Drama | Sam Mendes | 0.3943 |
| 4 | Away We Go | Drama, Comedy, Romance | Sam Mendes | 0.3943 |
| 5 | Regarding Henry | Drama | Mike Nichols | 0.3333 |
| 6 | The Wackness | Drama | Jonathan Levine | 0.313 |
| 7 | Albatross | Drama | Niall MacCormick | 0.2945 |
| 8 | The Cement Garden | Drama | Andrew Birkin | 0.2937 |
| 9 | Faces | Drama | John Cassavetes | 0.2886 |
| 10 | Liberty Heights | Drama | Barry Levinson | 0.2886 |
| Rating | 5 | 4.5 | 4 | 3.5 | 3 | 2.5 | 2 | 1.5 | 1 | 0.5 |
| No. of movies | 4 | 6 | 11 | 3 | 7 | 0 | 7 | 3 | 2 | 1 |
| Sl. No | Original Title | Genres | IMDB Rating |
|---|---|---|---|
| 1 | The Lord of the Rings: The Return of the King | Adventure, Fantasy, Action | 9 |
| 2 | Taxi Driver | Crime, Drama | 8.3 |
| 3 | Lawrence of Arabia | Adventure, Drama, History, War | 8.3 |
| 4 | The Lord of the Rings: The Two Towers | Adventure, Fantasy, Action | 8.8 |
| Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score | |
|---|---|---|---|---|---|
| 1 | Jaguar | Action, Adventure | 0.2041 | 6.5 | 3.1639 |
| 2 | Project Power | Action, Adventure | 0.2041 | 6.2 | 3.1026 |
| 3 | Ganglands | Crime, Action, Adventure | 0.1666 | 6.3 | 2.55 |
| 4 | Thunder Force | Action, Adventure, Comedy | 0.1666 | 5.2 | 2.3666 |
| 5 | Dealer | Crime, Action, Adventure | 0.1443 | 6.8 | 2.2805 |
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | The Trial of the Chicago 7 | Drama | 0.1767 | 6.9 | 2.6870 |
| 2 | The White Tiger | Drama | 0.1767 | 6.7 | 2.6516 |
| 3 | All Together Now | Drama | 0.1767 | 6.5 | 2.6162 |
| 4 | Two Distant Strangers | Drama | 0.1767 | 6.1 | 2.5455 |
| 5 | Rogue City | Action, Crime, Drama | 0.1767 | 6.1 | 2.5455 |
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | Mosul | Action, Adventure, Drama | 0.1625 | 6.8 | 2.4537 |
| 2 | The Trial of the Chicago 7 | Drama | 0.125 | 6.9 | 1.9 |
| 3 | The White Tiger | Drama | 0.125 | 6.7 | 1.875 |
| 4 | All Together Now | Drama | 0.125 | 6.5 | 1.85 |
| 5 | Two Distant Strangers | Drama | 0.125 | 6.1 | 1.8 |
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | Jaguar | Action, Adventure | 0.2041 | 6.5 | 3.1230 |
| 2 | Project Power | Action, Adventure | 0.2041 | 6.2 | 3.0618 |
| 3 | Ganglands | Crime, Action, Adventure | 0.1666 | 6.3 | 2.5166 |
| 4 | Thunder Force | Action, Adventure, Comedy | 0.1666 | 5.2 | 2.3333 |
| 5 | Dealer | Crime, Action, Adventure | 0.1443 | 6.8 | 2.2516 |
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | Jaguar | Action, Adventure | 0.2041 | 6.5 | 3.1639 |
| 2 | Project Power | Action, Adventure | 0.2041 | 6.2 | 3.1026 |
| 3 | The Trial of the Chicago 7 | Drama | 0.1767 | 6.9 | 2.6870 |
| 4 | The White Tiger | Drama | 0.1767 | 6.7 | 2.6516 |
| 5 | All Together Now | Drama | 0.1767 | 6.5 | 2.6162 |
| 6 | Ganglands | Crime, Action, Adventure | 0.1666 | 6.3 | 2.55 |
| 7 | Two Distant Strangers | Drama | 0.1767 | 6.1 | 2.5455 |
| 8 | Rogue City | Action, Crime, Drama | 0.1767 | 6.1 | 2.5455 |
| 9 | Mosul | Action, Adventure, Drama | 0.1625 | 6.8 | 2.4537 |
| 10 | Dealer | Crime, Action, Adventure | 0.1443 | 6.8 | 2.2516 |
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Justice League: Crisis on Two Earths | Action, Adventure, Animation | 7.1 |
| Batman: Year One | Action, Adventure, Animation, Crime, Science Fiction | 7.1 |
| Batman: Mask of the Phantasm | Action, Adventure, Animation, Family | 7.4 |
| Justice League: The Flashpoint Paradox | Fantasy, Science Fiction, Animation, Action, Adventure | 7.3 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Captain America: Civil War | Adventure, Action, Science Fiction | 7.8 |
| Batman: Under the Red Hood | Action, Animation | 7.6 |
| Batman: The Dark Knight Returns, Part 1 | Action, Animation | 7.7 |
| Captain America: The Winter Soldier | Action, Adventure, Science Fiction | 7.6 |
| Batman v Superman: Dawn of Justice | Action, Adventure, Fantasy | 6.5 |
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Justice League | Action, Adventure, Animation | 7.1 |
| Batman v Superman: Dawn of Justice | Action, Adventure, Fantasy | 6.5 |
| Suicide Squad | Action, Adventure, Crime, Fantasy, Science Fiction | 5.9 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Spiderman: Homecoming | Action, Adventure, Science Fiction | 7.4 |
| Deadpool | Action, Adventure, Comedy | 7.4 |
| Logan | Action, Drama, Science Fiction | 7.6 |
| Captain America: Civil War | Adventure, Action, Science Fiction | 7.8 |
| Doctor Strange | Action, Animation, Family, Fantasy, Science Fiction | 6.6 |
| Guardians of the Galaxy Vol. 2 | Action, Adventure, Comedy, Science Fiction | 7.6 |
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Guardians of the Galaxy Vol. 2 | Action, Adventure, Comedy, Science Fiction | 7.6 |
| Spiderman: Homecoming | Action, Adventure, Science Fiction | 7.4 |
| Logan | Action, Drama, Science Fiction | 7.6 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Justice League | Action, Adventure, Animation | 7.1 |
| Pirates of the Caribbean: Dead Men Tell No Tales | Action, Adventure, Fantasy | 6.6 |
| Doctor Strange | Action, Animation, Family, Fantasy, Science Fiction | 6.6 |
| Baby Driver | Action, Crime | 7.2 |
| Kong: Skull Island | Action, Adventure, Fantasy | 6.2 |
| Life | Comedy, Crime | 6.4 |
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Batman v Superman: Dawn of Justice | Action, Adventure, Fantasy | 6.5 |
| Suicide Squad | Action, Adventure, Crime, Fantasy, Science Fiction | 5.9 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Justice League | Action, Adventure, Animation | 7.1 |
| Warcraft | Action, Adventure, Fantasy | 6.3 |
| Doctor Strange | Action, Animation, Family, Fantasy, Science Fiction | 6.6 |
| Guardians of the Galaxy Vol. 2 | Action, Adventure, Comedy, Science Fiction | 7.6 |
| Kong: Skull Island | Action, Adventure, Fantasy | 6.2 |
| The LEGO Batman Movie | Action, Animation, Comedy, Family, Fantasy | 7.2 |
| Batman and Harley Quinn | Animation, Action, Adventure | 5.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sahu, S.; Kumar, R.; MohdShafi, P.; Shafi, J.; Kim, S.; Ijaz, M.F. A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews. Mathematics 2022, 10, 1568. https://doi.org/10.3390/math10091568
Sahu S, Kumar R, MohdShafi P, Shafi J, Kim S, Ijaz MF. A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews. Mathematics. 2022; 10(9):1568. https://doi.org/10.3390/math10091568
Chicago/Turabian StyleSahu, Sandipan, Raghvendra Kumar, Pathan MohdShafi, Jana Shafi, SeongKi Kim, and Muhammad Fazal Ijaz. 2022. "A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews" Mathematics 10, no. 9: 1568. https://doi.org/10.3390/math10091568
APA StyleSahu, S., Kumar, R., MohdShafi, P., Shafi, J., Kim, S., & Ijaz, M. F. (2022). A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews. Mathematics, 10(9), 1568. https://doi.org/10.3390/math10091568