
Low-Complexity One-Dimensional Parallel Semi-Systolic Structure for Field Montgomery Multiplication Algorithm Perfect for Small IoT Edge Nodes


Abstract
:1. Introduction
1.1. Literature Review
1.2. Paper Contribution
1.3. Paper Organization
2. Montgomery Multiplication in GF()
| Algorithm 1 Montgomery Multiplication Algorithm in GF() |
|
Input: C, D, R−1 = α−(m − 1)/2, and F Output: P Initialization: A0 ← 0, B0 ← 0 Algorithm:
|
| Algorithm 2 Montgomery Multiplication Algorithm in the bit-level formate |
|
Input: C = (cm − 1cm − 2 ⋯ c0), D = (dm − 1dm − 2 ⋯ d00), F = (fm − 1fm − 2 ⋯ f0), Output: P = (pm − 1pm − 2 ⋯ p0) Initialization: A0 = ( ⋯) ← (00 ⋯ 0) B0 = ( ⋯) ← (00 ⋯ 00) Algorithm:
|
3. Dependency Graph
4. Exploration of the Semi-Systolic Multiplier Layout
4.1. Scheduling Function
4.2. Projection Function
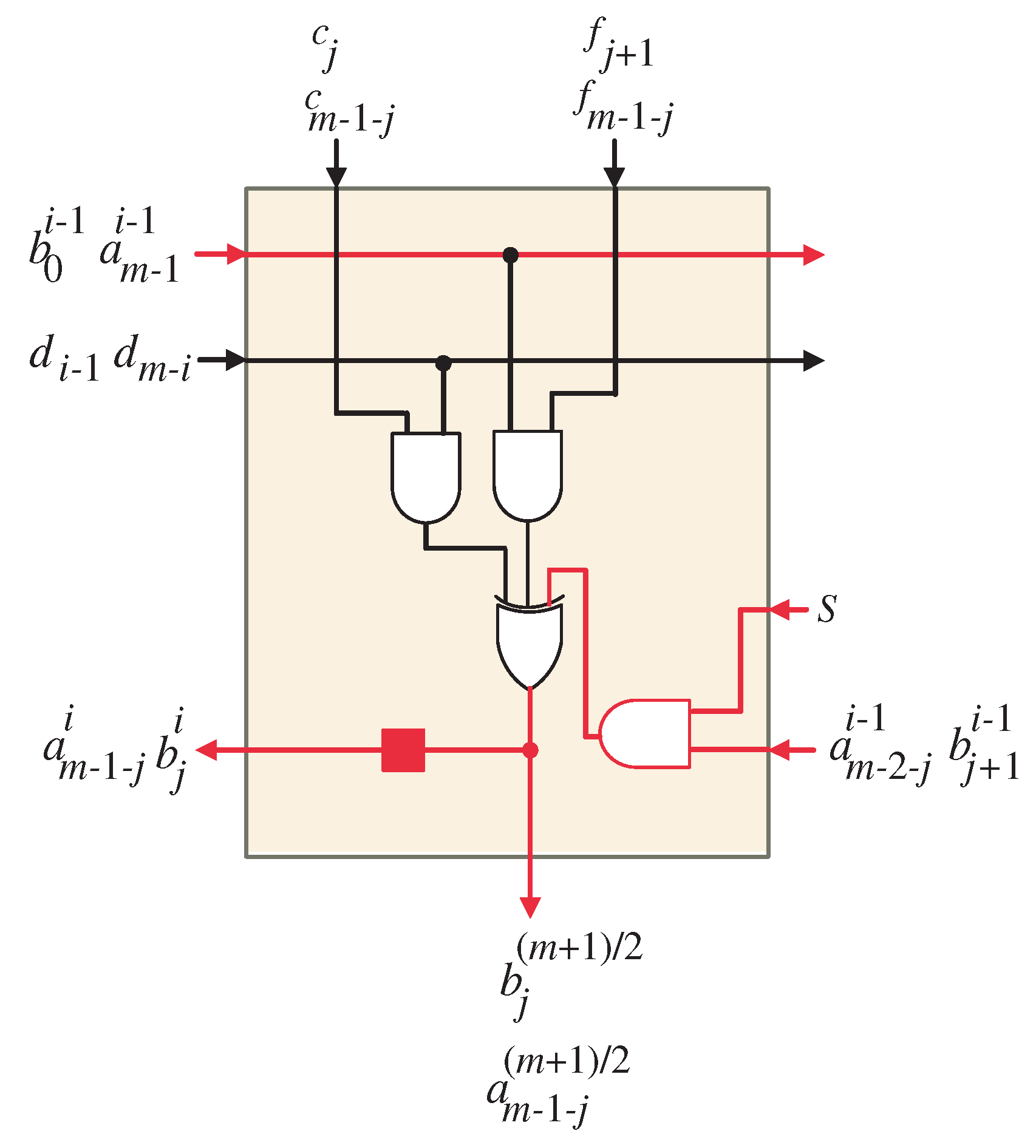
4.3. Semi-Systolic Multiplier Architecture
- Through the first two clock periods, select signal S is deactivated () to enforce the zero input bits of and , , to be localized in each PE. When S is equal to zero, the AND gate output will equal zero, which represents the initial values of and , . When S activates to one, the AND gate output will represent the intermediate values of the partial results of and , . At the same clock periods, the input bits of and are fed in sequence to go through all the PEs.
- The PEs produce the internal bit values and , and , sequentially, over the forthcoming clock periods. Additionally, all PEs receive input bits in a bit sequence from and , .
- The resultant output bits of the product P, , are produced in parallel at the outputs of XOR gates shown in Figure 3. They are generated at the last clock period .
5. Results and Discussion
5.1. Complexity Analysis
5.2. Implementation Results
- The suggested semi-systolic multiplier structure uses slightly less space and power than competing designs [34,39]. The average savings of area for are ranging from 2% to 6.6% and ranging from 2.1% to 7.4% for . The achievable average reduction in power consumptions for of the developed multiplier structure over the competitive multiplier structures are ranging from 4.9% to 13.4% and ranging from 6.8% to 11.8% for . The reduction in area and power is mainly due to the slightly lower gate counts and wire area of the proposed design over the competitive ones.
- The suggested semi-systolic multiplier structure has significant savings in delay over the competitive designs of [34,39]. This is attributed to the significant reduction in latency of the proposed designs over the competitive ones. The average savings of delay for are ranging from 49.2% to 50.0% and ranging from 45.9% to 46.4% for ;
- The ADP and PDP of the developed semi-systolic structure are significantly lower than those of the rival designs of [34,39]; The average reductions of ADP at are ranging from 50.2% to 53.3% and ranging from 47.0% to 50.4% for ; The achievable average reduction of PDP of the offered multiplier structure over the competitive ones for is ranging from 51.7% to 56.7% and ranging from 49.5% to 52.8% for .
6. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| ADP | Area–Delay Product |
| PDP | Power–Delay Product |
| ASIC | Application Specific Integrated Circuit |
| ECC | Elliptic Curve Cryptography |
| DG | Dependency Graph |
| CPD | Critical Path Delay |
References
- Chen, C.C.; Lee, C.Y.; Lu, E.H. Scalable and Systolic Montgomery Multipliers Over GF(2m). IEICE Trans. Fundam. 2008, E91-A, 1763–1771. [Google Scholar] [CrossRef]
- Chiou, C.W.; Lee, C.Y.; Deng, A.W.; Lin, J.M. Concurrent error detection in Montgomery multiplication over GF(2m). IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2006, E89-A, 566–574. [Google Scholar] [CrossRef]
- Huang, W.T.; Chang, C.; Chiou, C.; Chou, F. Concurrent error detection and correction in a polynomial basis multiplier over GF(2m). IET Inf. Secur. 2010, 4, 111–124. [Google Scholar] [CrossRef]
- Kim, K.W.; Jeon, J.C. Polynomial Basis Multiplier Using Cellular Systolic Architecture. IETE J. Res. 2014, 60, 194–199. [Google Scholar] [CrossRef]
- Choi, S.; Lee, K. Efficient systolic modular multiplier/squarer for fast exponentiation over GF(2m). IEICE Electron. Express 2015, 12, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Reyhani-Masoleh, A. A new bit-serial architecture for field multiplication using polynomial bases. In Cryptographic Hardware and Embedded Systems, Proceedings of the 7th International Workshop Cryptographic Hardware Embedded Systems (CHES 2008), Washington, DC, USA, 10–13 August 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 314–330. [Google Scholar]
- Abdulrahman, E.A.; Reyhani-Masoleh, A. High-Speed Hybrid-Double Multiplication Architectures Using New Serial-Out Bit-Level Mastrovito Multipliers. IEEE Trans. Comput. 2016, 65, 1734–1747. [Google Scholar] [CrossRef]
- Kim, K.W.; Jeon, J.C. A semi-systolic Montgomery multiplier over GF(2m). IEICE Electron. Express 2015, 12, 20150769. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, A. Novel Bit-Serial Semi-Systolic Array Structure for Simultaneously Computing Field Multiplication and Squaring. IEICE Electron. Express 2019, 16, 20190600. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.W.; Lee, J.D. Efficient unified semi-systolic arrays for multiplication and squaring over GF(2m). Electron. Express 2017, 14, 20170458. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.W.; Kim, S.H. Efficient bit-parallel systolic architecture for multiplication and squaring over GF(2m). IEICE Electron. Express 2018, 15, 20171195. [Google Scholar] [CrossRef]
- Ibrahim, A. Efficient Parallel and Serial Systolic Structures for Multiplication and Squaring Over GF(2m). Can. J. Electr. Comput. Eng. 2019, 42, 114–120. [Google Scholar] [CrossRef]
- Roman, S. Field Theory, 2nd ed.; Springer: New York, NY, USA, 1983. [Google Scholar]
- Pillutla, S.R.; Boppana, L. Area-efficient low-latency polynomial basis finite field GF(2m) systolic multiplier for a class of trinomials. Microelectron. J. 2020, 97, 104709. [Google Scholar] [CrossRef]
- Imana, J.L. LFSR-Based Bit-Serial GF(2m) Multipliers Using Irreducible Trinomials. IEEE Trans. Comput. 2020, 70, 156–162. [Google Scholar]
- Pillutla, S.R.; Boppana, L. Low-latency area-efficient systolic bit-parallel GF(2m) multiplier for a narrow class of trinomials. Microelectron. J. 2021, 117, 105275. [Google Scholar] [CrossRef]
- Li, Y.; Cui, X.; Zhang, Y. An Efficient CRT-based Bit-parallel Multiplier for Special Pentanomials. IEEE Trans. Comput. 2021, 71, 736–742. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; He, W. Fast hybrid Karatsuba multiplier for type II pentanomials. IEEE Trans. Very Large Scale Integr. (Vlsi) Syst. 2020, 28, 2459–2463. [Google Scholar] [CrossRef]
- Meher, P.K.; Lou, X. Low-Latency, Low-Area, and Scalable Systolic-Like Modular Multipliers for GF(2m) Based on Irreducible All-One Polynomials. IEEE Trans. Circuits Syst. Regul. Pap. 2016, 64, 399–408. [Google Scholar] [CrossRef]
- Mohaghegh, S.; Yemiscoglu, G.; Muhtaroglu, A. Low-Power and Area-Efficient Finite Field Multiplier Architecture Based on Irreducible All-One Polynomials. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Zhang, Y.; Li, Y. Efficient Hybrid GF(2m) Multiplier for All-One Polynomial Using Varied Karatsuba Algorithm. IEICE Trans. Fundam. Electron. Comput. Sci. 2021, 104, 636–639. [Google Scholar] [CrossRef]
- Zhou, B.B. A New Bit Serial Systolic Multiplier over GF(2m). IEEE Trans. Comput. 1988, 37, 749–751. [Google Scholar] [CrossRef]
- Fenn, S.T.J.; Taylor, D.; Benaissa, M. A Dual Basis Bit Serial Systolic Multiplier for GF(2m). Integration 1995, 18, 139–149. [Google Scholar] [CrossRef]
- Lee, C.Y.; Lu, E.H.; Lee, J.Y. Bit-Parallel Systolic Multipliers for GF(2m) Fields Defined by All-One and Equally-Spaced Polynomials. IEEE Trans. Comput. 2001, 50, 358–393. [Google Scholar]
- Lee, C.Y.; Lu, E.H.; Sun, L.F. Low-Complexity Bit-Parallel Systolic Architecture for Computing AB2+C in a Class of Finite Field GF(2m). IEEE Trans. Circuits Syst. II 2001, 50, 519–523. [Google Scholar]
- Lee, C.Y.; Chiou, C.W. Efficient Design of Low-Complexity Bit-Parallel Systolic Hankel Multipliers to Implement Multiplication in Normal and Dual Bases of GF(2m). IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2005, E88-A, 3169–3179. [Google Scholar] [CrossRef]
- Lee, C.Y. Low-latency bit-pararallel systolic multiplier for irreducible xm+xn+1 with GCD(m,n)=1. IEICE Trans. Fund. Elect. Commun. Comput. Sci. 2008, 55, 828–837. [Google Scholar]
- Bayat-Sarmadi, S.; Farmani, M. High-Throughput Low-Complexity Systolic Montgomery Multiplication Over GF(2m) Based on Trinomials. IEEE Trans. Circuits Syst. II 2015, 62, 377–381. [Google Scholar] [CrossRef]
- Mathe, S.E.; Boppana, L. Bit-parallel systolic multiplier over GF(2m) for irreducible trinomials with ASIC and FPGA implementations. IET Circuits Desvices Syst. 2018, 12, 315–325. [Google Scholar] [CrossRef]
- Lee, C.Y.; Chiou, C.W.; Lin, J.M. Concurrent error detection in a polynomial basis multiplier over GF(2m). J. Electron. Test. 2006, 22, 143–150. [Google Scholar] [CrossRef]
- Chiou, C.W.; Lee, C.M.; Sun, Y.S.; Lee, C.Y.; Lin, J.M. High-throughput Dickson basis multiplier with a trinomial for lightweight cryptosystems. IET Comput. Digit. Tech. 2018, 12, 187–191. [Google Scholar] [CrossRef]
- Lee, K. Resource and Delay Efficient Polynomial Multiplier over Finite Fields GF(2m). J. Korea Soc. Digit. Ind. Inf. Manag. 2020, 16, 1–9. [Google Scholar]
- Lee, K. Low Complexity Systolic Montgomery Multiplication over Finite Fields GF(2m). J. Korea Soc. Digit. Ind. Inf. Manag. 2022, 18, 1–9. [Google Scholar]
- Mathe, S.E.; Boppana, L. Design and Implementation of a Sequential Polynomial Basis Multiplier over GF(2m). KSII Trans. Int. Inf. Syst. 2017, 11, 2680–2700. [Google Scholar]
- Gebali, F. Algorithms and Parallel Computers; John Wiley: New York, NY, USA, 2011. [Google Scholar]
- Ibrahim, A.; Gebali, F. Scalable and Unified Digit-Serial Processor Array Architecture for Multiplication and Inversion over GF(2m). IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 22, 2894–2906. [Google Scholar] [CrossRef]
- Ibrahim, A.; Alsomani, T.; Gebali, F. New Systolic Array Architecture for Finite Field Inversion. IEEE Can. J. Electr. Comput. Eng. 2017, 40, 23–30. [Google Scholar] [CrossRef]
- Chiou, C.W.; Lin, J.M.; Lee, C.Y.; Ma, C.T. Novel Mastrovito Multiplier over GF(2m) Using Trinomial. In Proceedings of the 2011 5th International Conference on Genetic and Evolutionary Computing (ICGEC), Kitakyushu, Japan, 29 August–1 September 2011; pp. 237–242. [Google Scholar]
- Ibrahim, A.; Gebali, F.; Bouteraa, Y.; Tariq, U.; Ahanger, T.; Alnowaiser, K. Compact Bit-Parallel Systolic Multiplier Over GF(2m). IEEE Can. J. Electr. Comput. Eng. 2021, 44, 199–205. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design | AND | XOR | MUX | Latch | Latency | CPD | Area Complexity | Time Complexity |
|---|---|---|---|---|---|---|---|---|
| Huang [3] | 0 | |||||||
| Chiou [31] | 0 | |||||||
| Lee [32] | 0 | |||||||
| Lee [33] | 0 | |||||||
| Chiou [38] | m | |||||||
| Kim [4] | 0 | |||||||
| Sarmadi [28] | () | |||||||
| Mathe [29] | m | m | ||||||
| Mathe [34] | m | |||||||
| Ibrahim [39] | m | |||||||
| Proposed | 0 |
| Multiplier | Type | m | Area [Kgates] | Delay [ns] | Power [mW] | ADP | PDP | Area Saving (%) | Delay Saving (%) | Power Saving (%) | ADP Saving (%) | PDP Saving (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mathe [34] | Sequential | 409 | 10.6 | 13.4 | 6.7 | 142.0 | 89.8 | 6.6 | 50.0 | 13.4 | 53.3 | 56.7 |
| 571 | 14.9 | 18.3 | 9.3 | 272.7 | 170.2 | 7.4 | 46.4 | 11.8 | 50.4 | 52.8 | ||
| Ibrahim [39] | Systolic | 409 | 10.1 | 13.2 | 6.1 | 133.3 | 80.5 | 2.0 | 49.2 | 4.9 | 50.2 | 51.7 |
| 571 | 14.1 | 18.1 | 8.8 | 255.2 | 159.3 | 2.1 | 45.9 | 6.8 | 47.0 | 49.5 | ||
| Proposed | Systolic | 409 | 9.9 | 6.7 | 5.8 | 66.3 | 38.9 | - | - | - | - | |
| 571 | 13.8 | 9.8 | 8.2 | 135.2 | 80.4 | - | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahim, A.; Tariq, U.; Ahanger, T.A.; Gebali, F. Low-Complexity One-Dimensional Parallel Semi-Systolic Structure for Field Montgomery Multiplication Algorithm Perfect for Small IoT Edge Nodes. Mathematics 2023, 11, 111. https://doi.org/10.3390/math11010111
Ibrahim A, Tariq U, Ahanger TA, Gebali F. Low-Complexity One-Dimensional Parallel Semi-Systolic Structure for Field Montgomery Multiplication Algorithm Perfect for Small IoT Edge Nodes. Mathematics. 2023; 11(1):111. https://doi.org/10.3390/math11010111
Chicago/Turabian StyleIbrahim, Atef, Usman Tariq, Tariq Ahamed Ahanger, and Fayez Gebali. 2023. "Low-Complexity One-Dimensional Parallel Semi-Systolic Structure for Field Montgomery Multiplication Algorithm Perfect for Small IoT Edge Nodes" Mathematics 11, no. 1: 111. https://doi.org/10.3390/math11010111