Abstract
The mixture of experts (ME) model is effective for multimodal data in statistics and machine learning. To treat non-stationary probabilistic regression, the mixture of Gaussian processes (MGP) model has been proposed, but it may not perform well in some cases due to the limited ability of each Gaussian process (GP) expert. Although the mixture of Gaussian processes (MGP) and warped Gaussian process (WGP) models are dominant and effective for non-stationary probabilistic regression, they may not be able to handle general non-stationary probabilistic regression in practice. In this paper, we first propose the mixture of warped Gaussian processes (MWGP) model as well as its classification expectation–maximization (CEM) algorithm to address this problem. To overcome the local optimum of the CEM algorithm, we then propose the split and merge CEM (SMC EM) algorithm for MWGP. Experiments were done on synthetic and real-world datasets, which show that our proposed MWGP is more effective than the models used for comparison, and the SMCEM algorithm can solve the local optimum for MWGP.
Keywords:
mixture of experts; warped Gaussian process; classification expectation–maximization algorithm; local optimum; non-stationary probabilistic regression MSC:
68T05
1. Introduction
The mixture of experts (ME) model is effective for multimodal data in statistics and machine learning [1]. In ME, the input space is softly divided into multiple regions by an input-dependent gating function, and each region is specified by an expert. Due to the diversity of experts, such as Gaussian distribution [2] and the support vector machine (SVM) [3], there are a variety of models based on the ME framework.
In the 2000s, Tresp constructed the mixture of Gaussian processes (MGP) model, a special ME where each expert is a stationary Gaussian process (GP) probabilistic regression model, by mixing GPs along the input space to treat non-stationary probabilistic regression [4,5,6,7,8]. Popular gating functions of the MGP include logistic distribution and Gaussian distribution. For learning MGP, the main algorithms are Markov Chain Monte Carlo (MCMC), variational Bayesian (VB), and expectation–maximization (EM). The MGP cannot work correctly on non-stationary probabilistic regression in some situations since the ability of each GP expert is limited.
In this paper, we propose the mixture of warped Gaussian processes (MWGP) model, which has more flexible and attractive properties than MGP to handle non-stationary probabilistic regression, by modeling each component of an MGP with a warped Gaussian process (WGP); these WGPs are combined in the input space by the Gaussian distribution. The WGP is capable of modeling non-stationary probabilistic regression by learning a nonlinear distortion (also called warping) of the GP outputs. The MWGP can be viewed as a generalization of the MGP and WGP frameworks, and it allows for dealing with non-stationary data in each multimodal mode. In MWGP, the mixture parameter, warping function parameter, covariance function parameter, and indicator variable (regarded as the latent variable) are considered simultaneously. To handle this, we designed the classification expectation–maximization (CEM) algorithm for the training of MWGP. However, the CEM algorithm may easily converge to a local optimum for MWGP in some cases. We propose the split and merge CEM (SMCEM) algorithm of MWGP based on the SMCEM algorithm of the MGP and the CEM algorithm of MWGP to solve this problem. Experiments were conducted on synthetic and real-world datasets, and the results demonstrate the feasibility and superior accuracy of our proposed MWGP model trained using the CEM algorithm compared to other comparative models for probabilistic regression. Moreover, the SMCEM algorithm of MWGP can overcome local optima in some datasets at a negligible time cost.
The remainder of this paper is organized as follows. In Section 2, we present related works of GP, MGP, and WGP models. We describe GP, WGP, and our proposed MWGP in Section 3. In Section 4, we present our proposed SMCEM algorithm of MWGP, the CEM algorithm of MWGP, and the partial CEM algorithm of MWGP. The experimental results are presented in Section 5, and the conclusions are drawn in Section 6.
2. Related Works
Related works of the GP. The GP is a versatile tool for probabilistic regression and it has been successfully applied to practical fields such as time series prediction [9] and signal processing [10]. The non-stationary probabilistic regression problem exists widely, but it cannot be modeled effectively by the conventional GP model [11,12]. To solve this, the non-stationary GP model was proposed by introducing a robust and flexible covariance structure [13,14,15,16]. However, a single GP cannot handle the non-stationary probabilistic regression well due to its inherent simplicity.
Related works of the MGP model. The structure of the MGP is shown in Figure 1. As seen in this figure, the MGP is a more effective non-stationary model than the GP. However, the parameter estimation of the MGP is a challenge due to the unknown indicator variable (regarded as the latent variable) and the highly correlated sample [17,18,19,20]. The Markov Chain Monte Carlo (MCMC) method employing Gibbs sampling and hybrid Monte Carlo approximates the intractable integration and summation by the simulated sample of the indicator variable and parameter [6,7,21,22,23], and it is commonly used in a system of partial differential equations [24,25]. The MCMC generally obtains precise results, but it takes a long time to generate the simulated sample. To improve the efficiency, the variational Bayesian (VB) inference and the expectation–maximization (EM) algorithm were proposed. Ross and Dy constructed the VB inference on the basis of the mean-field approximation, where the indicator variable and the stochastic parameter are forced to be independent of the probability distribution [26]. Yuan and Neubauer established a variational EM algorithm by a similar mean-field method as the VB inference [8]. Then, the leave-one-out cross-validation (LOOCV) EM algorithm was proposed based on the LOOCV approximation method, where the probability density of the GP is approximated by the production of LOOCV probability densities [27]. To improve the accuracy, Chen et al. constructed the CEM algorithm by replacing the expectation step (E step) of the conventional EM algorithm with a classification–expectation step (CE step) [28,29]. For the CEM algorithm, samples are classified into components by the maximum a posteriori (MAP) principle of indicator variables in the CE step and the parameters of components are learned independently in the maximization step (M step). Then, the MCMC EM algorithm was designed by approximating the Q-function of the EM algorithm with the Gibbs sampling; this algorithm is generally accurate but slow [30,31,32]. The SMCEM algorithm was constructed by combining the split and merge EM algorithm and the CEM algorithm to address the local optimum of the CEM algorithm for MGP [33,34,35,36]. Regarding the model selection problem, i.e., selecting the number of components, the Dirichlet process as the gating function was developed [6,17,21,22]; moreover, Zhao and Ma proposed a synchronous balancing criterion [37]. Regarding the robustness problem, the robust MGP with the Laplace noise and the robust MGP with the student-t noise were proposed to overcome this difficulty [38].
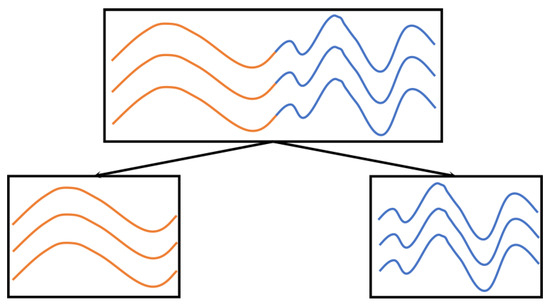
Figure 1.
The diagram structure of the MGP model: the low-layer consists of two GPs and the high-layer structure consists of an MGP. The curves are divided into two curve segments along the input space marked in different colors, and curve segments of one color corresponding to a GP.
Related works of the WGP model. The WGP trained by the maximum likelihood estimation (MLE) method can handle non-stationary probabilistic regression effectively by transforming the GP output in a latent space to the real output in the observation space with a learnable nonlinear monotonic function [39], as seen in Figure 2. From this figure, it is clear that the WGP is much better than the GP, and the performance of the GP degenerates dramatically. In WGP, such a preprocessing transformation can be considered as an integral part of non-stationary probabilistic modeling. The improved WGP models involve a large number of parameters and hyperparameters, which limits the applicability of the WGP. The Hamiltonian MCMC method [40] and the VB inference [41] were proposed to improve the training of the WGP in some situations. To make the WGP structure flexible, Rios et al. constructed the WGP with a deep compositional architecture warping function [42], and the multi-task WGP was proposed [43]. For the optimization of the WGP, a spatial branching strategy was designed [44]. The WGP (being a useful generalization of the GP) has also been widely used in practical applications [45,46,47,48].
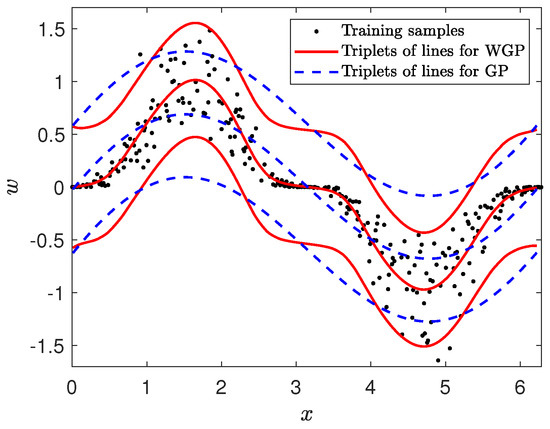
Figure 2.
An example of a non-stationary data regression task. The one-dimensional data are generated by adding Gaussian noise to a sine function. The dataset contains 300 training samples and 600 test samples. These samples are then warped by the function The mean and two standard deviation (SD) bounds are represented by triplets of lines.
3. Model Construction
In this section, we first introduce the GP and WGP models and then describe our proposed MWGP model.
3.1. The GP
The GP is a non-parametric statistical model, which is described briefly as follows. For a dataset the standard Gaussian process (GP) model for probabilistic regression is defined by
where , , , , and are the random latent function described, the n-th output, the n-th input, the n-th Gaussian noise, and the SD of the Gaussian noise, respectively. The random latent function on is subject to a Gaussian distribution
where is the input matrix, is the latent vector, , is the mean vector, is the mean function, is the covariance matrix, and is the covariance function (In this paper, we use the squared exponential covariance function
where is the diagonal matrix) parameterized by
The likelihood function of the GP is obtained by integrating with respect to , given by
where is the independent identically distributed Gaussian distribution obtained by Equation (1), is the output vector, and is the unit matrix.
3.2. The WGP Model
In the non-stationary probabilistic regression problem, the WGP model describes the real output in the observation space as a parametric nonlinear transformation of the GP. For the dataset the WGP is constructed by introducing a latent variable set , where and are the n-th output in the observation space and the n-th input, respectively. The latent vector is subject to a GP with a zero-mean function (i.e., ), defined by Equation (2)
The latent variable is transformed to by a monotonic warping function (In this paper, we assume the warping function to be a feedforward neural network where and are non-negative for any j to ensure monotonicity, J is the number of neurons, and ).
where maps to the entire real line, and is the parameter vector composed of J neurons. As stated above, the established WGP is fully incorporated into the probabilistic framework of the GP.
For convenience, the WGP is denoted as
where is the output vector and . For WGP, the information flow direction is , and the relationships between the main variables are shown in Figure 3. From this figure, outputs are conditionally independent when the strongly correlated are given. The parameters and are learned jointly using a conjugate gradient method for WGP.
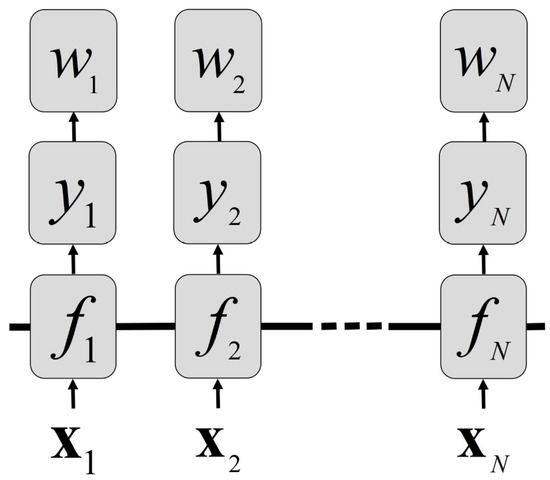
Figure 3.
A diagram showing the relations among the main variables in the WGP model.
3.3. The MWGP Model
To process multimodal data while modeling the non-stationary nature of each mode, we describe our proposed MWGP model mathematically next, where C-different WGP components are mixed in the input region. The structure of MWGP is similar to that of the MGP, as illustrated in Figure 1. Compared to the MGP, the two-layer structure of MWGP can address non-stationary probabilistic regression in different ways.
A subscript c is inserted in the preceding notation for the number of components. The n-th sample is allocated to the c-th WGP component by an indicator variable (regarded as a latent variable), where . If is in the c-th component, then = 1; otherwise, = 0. The distribution of the indicator variable vector is given by
where is the c-th column of the unit matrix and
The distribution of the input vector is given by
where and are the mean vector and the covariance matrix of the Gaussian distribution, respectively. Equation (5) is commonly used in most generative mixture models.
After the distributions of Equations (4) and (5) are given, the distribution of the output vector is given based on Equation (3) by
where is the input matrix composed of in which is the sample number, is the output vector composed of , parameterizes the warping function of the c-th component, and . For MWGP, C WGP components are independent, and each component is defined by Equation (6). MWGP is generally more flexible than the MGP and WGP; its information flow direction is , as shown in Figure 4. If then the MWGP degenerates to WGP; if , then the MWGP degenerates to MGP.
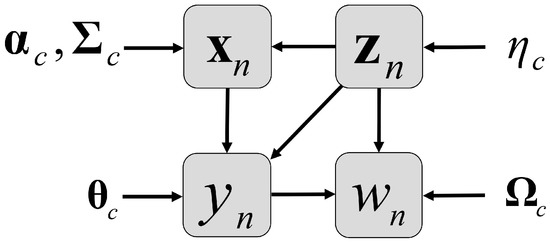
Figure 4.
The probabilistic graphical model of the MWGP model: the elements inside the boxes are main variables and the others are parameters.
With the above analysis, the mixture structure, the covariance function, and the warping function are incorporated simultaneously in the same probabilistic model framework. The computational cost of MWGP is similar to MGP since the time complexity of the inverse covariance matrix operation in MWGP is the same as that in MGP, i.e., . For MWGP, there is an overfitting problem when too many extra parameters are added.
4. Algorithm Design
To handle the large time complexity of calculating the Q-function in the conventional EM algorithm of MWGP, we designed the CEM and partial CEM algorithms. In the CEM algorithm of MWGP, a local optimum is generally generated when there is a large separation between two parts of the MWGP component in practice. This separation is created by having many components of MWGP in one region and few in another. To escape from this separation, simultaneous split and merge operations were performed repeatedly by merging two similar components in a region with many components and splitting one component in another region with few components. As the CEM algorithm of MWGP can sometimes get trapped in a local optimum, we developed the SMCEM algorithm of MWGP to address this issue. The CEM algorithm of MWGP and the partial CEM algorithm of MWGP are sub-algorithms of the SMCEM algorithm for MWGP.
4.1. Procedures of the Proposed Algorithms
Denote the indicator variable matrix and the whole parameter set , where . For MWGP, procedures of the SMCEM algorithm, the CEM algorithm, and the partial CEM algorithm are presented in Algorithms 1–3.
| Algorithm 1 The SMCEM algorithm for MWGP |
| Input: Output:
|
| Algorithm 2 The CEM algorithm for MWGP |
| Input: Output:
|
| Algorithm 3 The partial CEM algorithm for MWGP. |
| Input: Output:
|
The k-means clustering method is adopted in the first step of Algorithm 1 since it is possible for some samples to belong to the same component if they are close in distance. In the second and third steps of Algorithm 1, the split candidate set and the merge candidate set are sorted by split and merge criteria, respectively. By renumbering the merge and split candidate sets, we obtain the candidate set . In the fifth step of Algorithm 1, we perform the partial CEM algorithm to retrain the parameters of new components and ensure that all other components are not affected by this retraining. The CEM algorithm is performed as a full training procedure for all components in the sixth step of Algorithm 1. In the seventh step of Algorithm 1, it is obvious that the accepted split or merge operation attempts to increase the value of the approximated Q-function in each iteration. We set hyperparameters , J, and D according to the best RMSE (the root mean square error (RMSE) is used to characterize the accuracy of the model, which is defined mathematically by , where is the estimation of ). In Algorithm 1, components of MWGP with poor aggregation are divided in the split operation, and those with high similarity are combined in the merge operation. Simultaneous split and merge operations can perform a global search by crossing over low-likelihood positions.
In the second and third steps of Algorithm 2, and are updated alternately. Samples are classified into C components to overcome the time complexity of the conventional EM algorithm in the third step of Algorithm 2. In the fourth step of Algorithm 2, we apply a relatively long-term convergence criterion.
since may fluctuate during iterations, we present the largest number of iterations, i.e., = 30 and = 0.002. Regarding the annealing mechanism, Algorithm 2 can be viewed as a deterministic annealing EM algorithm with the annealing parameter tending to positive infinity, while the conventional EM algorithm can be viewed as a deterministic annealing EM algorithm with the annealing parameter being one. Theoretically, Algorithm 2 is more likely to fall into a local optimum than the conventional EM algorithm. The details of the CEM algorithm are described in Appendix A.
Algorithm 3 was performed on new components generated by the simultaneous split and merge operations. In the second and third steps of Algorithm 3, and are updated alternately, where . In the third step of Algorithm 3, for is obtained by using the initialized , while is set for the other components. The details of the partial CEM algorithm are described in Appendix B.
4.2. Prediction Strategy
For MWGP, the time complexity of the conventional prediction method is generally high. We adopted the classification approximation method for MWGP to improve the predictive efficiency. In this prediction, the mean predictive output is used since the RMSE is measurable. In this paper, we used a predictive strategy similar to the MGP (or ME), i.e., the weighted prediction. A test sample was put into each WGP expert to calculate the predictive distribution individually, and then these predictive distributions were weighted and averaged according to the posterior probability to obtain the overall predictive distribution.
For the test sample in the c-th component, the predictive distribution in the latent space of the WGP is a standard GP
By a nonlinear transformation in Equation (7), the predictive distribution in the observation space is calculated by
Compared to the shape of the predictive distribution in Equation (7), the shape of the predictive distribution in Equation (8) is generally asymmetric and multimodal. By integrating in Equation (8), the mean predictive output in the latent space of the WGP is obtained by
where is the inverse of . The closed-form solution of is generally difficult to obtain, so we used the Newton–Raphson method to calculate it. Since Equation (9) is the one-dimensional integral of in the Gaussian density function, it can be solved accurately by the Gauss–Hermite quadrature method.
Finally, the overall mean predictive output for MWGP is given based on Equation (9):
where
5. Experimental Results
In this section, we show the experimental results of MWGP on synthetic datasets and three types of real-world datasets. The experiments were conducted on a personal computer equipped with a 2.9 GHz Intel Core i7 CPU and 16.00 GB of RAM, using Matlab R2019b.
5.1. Comparative Models
Models and related algorithms are described in Table 1, where GP, support vector machine (SVM), and feedforward neural network (FNN) are comparative models. The GPML toolbox in Matlab R2019b, the SVM toolbox in Matlab R2019b, and the FNN toolbox in Matlab R2019b were adopted in our experiments. For MWGP II, MWGP I, and WGP, we chose an optimal value of J to avoid overfitting while balancing accuracy and efficiency. RMSE and MAE (note that the mean absolute error (MAE) is used to describe the sensitivity of the model to outliers, which is defined mathematically by , where is the estimation of ) are used to assess the performance of real-world datasets.

Table 1.
The symbols represent the models and related algorithms; the bold font is used for our proposed models.
5.2. Synthetic Datasets of MWGP I
To test the consistency of MWGP I, we generated 10 typical synthetic datasets by the MGP model with the component number C = 2 and the input dimension number , denoted by , respectively. is the original dataset, where there are 300 training samples and 600 test samples. In each dataset, samples are warped by a monotonic function . The number of neurons J is set as 2, and is randomly generated from a Gaussian distribution. The main parameters of MWGP I on are shown in Table 2. The other datasets that differ from are listed as follows.
Table 2.
RPs and AEPs with SDEPs were obtained through 150 trials using MWGP I on .
- (a low noise dataset): .
- (a high noise dataset): .
- , .
- , .
- (a short length-scale dataset): , .
- (a long length-scale dataset): , .
- (a medium overlapping dataset): , .
- (a large overlapping dataset): , .
- (an unbalanced dataset): , .
The real parameters (RPs), average estimated parameters (AEPs), and standard deviations of estimated parameters (SDEPs) obtained by MWGP I on are listed in Table 2, where the AEPs obtained by MWGP I are similar to the related RPs and the related SDEPs are generally small. As a result, the parameter estimate of MWGP I is practically unbiased and effective.
The predictive results of MWGP I and MGP on are presented in Figure 5a. The figure suggests that MWGP I outperforms MGP in the flat zone, specifically in the intervals (10.8, 11.7). In Figure 5b, the predictive probability density of MWGP I is asymmetrical across the whole distribution, but the predictive probability density of the MGP is symmetrical even when it is calculated by using the warped samples. Warping functions learned by MWGP I on are shown in Figure 6. The warping function learned for the first component in Figure 6a is linear-like, while the warping function learned for the second component in Figure 6b is power-like, with an order between 0 and 1. It can be seen that MWGP I is flexible enough to handle non-stationary among different regions on a multimodal dataset.
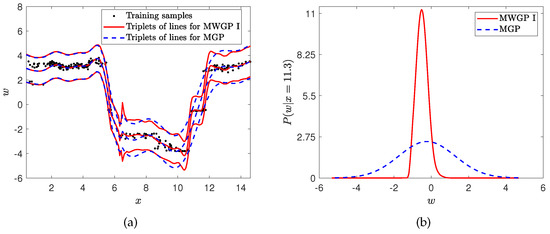
Figure 5.
Fitting results of MWGP I and MGP on : (a) Predictions of MWGP I and MGP. Line triplets represent the mean and two standard deviation (SD) bounds; (b) predictive probability densities of MWGP I and MGP at .
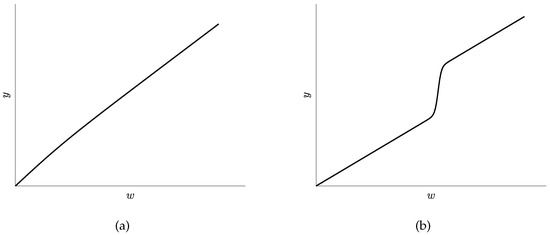
Figure 6.
Warping functions obtained by MWGP I on : (a) The warping function learned in the first component; (b) the warping function learned in the second component.
In Table 3, the average predicted RMSEs, SDs of predicted RMSEs, p-values [52] of predicted RMSEs, and average running times for MWGP I and the other models on are illustrated, where p-values are obtained by MWGP I and the other comparative models, respectively. The prediction accuracies of MWGP I and MGP are better than the other models due to the mixture structure, and the prediction accuracy of MWGP I is the best of all. MWGP I is superior to MGP in accuracy because of the warping function. Although the SDEPs of and are larger than the other parameters, the predicted results of MWGP I are accurate in . Thus, MWGP I is robust for the estimates of and . The SDs of predicted RMSEs for MWGP I and the other models are small. From the p-values, the predicted RMSE of MWGP I is different from the other models, except for MGP on and . Thus, our proposed MWGP I is effective, and it can optimize all parameters jointly.
Table 3.
The average predicted RMSEs, SDs of predicted RMSEs, p-values of predicted RMSEs, and average running times (seconds) for MWGP I and the other models from over one hundred trials on synthetic datasets; the bold font represents the best results.
5.3. Synthetic Datasets of MWGP II
For MWGP I, there is a local optimum in some cases. We propose MWGP II as a solution to this issue. To verify the consistency of MWGP II, we generated 6 typical synthetic datasets by MGP with C = 5 and . In , there are 750 training samples and 1500 test samples. In each dataset, samples are warped by . We set J = 3 and generated at random using a Gaussian distribution for these synthetic datasets. The main parameters of MWGP II on are shown in Table 4. The other datasets that differ from are listed as follows.
Table 4.
The main parameters of MWGP II on .
- (a noise dataset): , and .
- , , , , and .
- (a length-scale dataset): , , , , and .
- (an overlapping dataset):
- (an unbalanced dataset): , , , and , .
The average ALLFs (approximated log-likelihood functions, i.e., values of the approximated Q-function after convergence of the SMCEM algorithm) and average running times of MWGP II and MWGP I on are shown in Table 5. In these synthetic datasets, the average ALLF of MWGP II is larger than MWGP I, so MWGP II overcomes the local optimum of MWGP I. The average running time of MWGP II is longer than MWGP I since the partial CEM algorithm and the CEM algorithm are performed several times for the training of MWGP II. It can be concluded from the above discussion that our proposed MWGP II is effective.
Table 5.
The average ALLFs and running times (seconds) of MWGP II and MWGP I from over one hundred trials on the synthetic datasets; the bold font represents the best results.
5.4. Toy and Motorcycle Datasets
Toy data [7,27] and motorcycle data [6,8,27] were used to test the performance of the MGP. We tested the consistency of our proposed MWGP II and MWGP I on the toy dataset and the motorcycle dataset . consisted of four components generated by four continuous functions, i.e.,
where and , as shown in Figure 7a. In each component, there are 50 training samples and 50 test samples. We set J = 2 and C = 4 for .
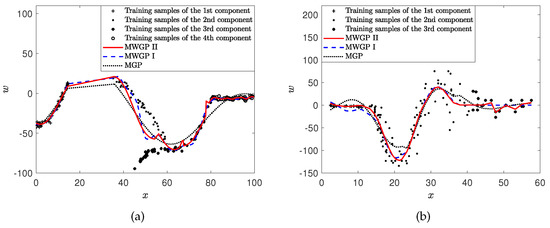
Figure 7.
(a) Predictions of MWGP II, MWGP I, and MGP on (b) predictions of MWGP II, MWGP I, and MGP on .
presents the accelerometer readings recorded at 133 moments during an experiment evaluating the effectiveness of crash helmets. In , samples belong to three components along the time axis (millisecond), i.e., , and , as shown in Figure 7b. We performed 7-fold cross-validation on this dataset, with the k-th fold consisting of the dataset . We used 19 samples as the test set and the remaining samples as the training set. For this dataset, we set J = 2 and C = 3 for .
We compare the MWGP II, MWGP I, MGP, WGP, GP, FNN, and SVM models on and , respectively. The average predicted RMSEs, average predicted MAEs, and average running times of these models are listed in Table 6. With these datasets, MWGP II and MWGP I are more accurate than the other models, and MWGP II is more accurate than MWGP I. The average predicted RMSE and average predicted MAE of the MGP are larger than those of a single GP and the WGP since the data in and are highly multimodal and non-stationary. The FNN and SVM can hardly fit and accurately. In Figure 7a, MWGP II and MWGP I are better than the MGP, for example on the interval ; in Figure 7b, MWGP II and MWGP I are better than the MGP, for example on the interval . Consequently, both MWGP II and MWGP I are effective for these tasks, and MWGP II can overcome the local optimum of MWGP I at the expense of only a little time on these datasets. In summary, the preprocessing transformation is critical for MGP in the toy and motorcycle datasets.
Table 6.
The average predicted RMSEs, average predicted MAEs, and average running times (seconds) of different models from over thirty trials on the toy dataset, the motorcycle dataset, and the river-flow datasets; the bold font represents the best results.
5.5. River-flow Datasets
We conducted experiments on ten river-flow datasets to verify the consistency of our proposed MWGP II and MWGP I [53]. In each dataset, about 40 years (i.e., from 1920 to 1960) of monthly river flow for rivers in the USA (such as the Current River, the Mad River, the Madison River, and the Mackenzie River) were recorded. There are approximately 155 training samples and 313 test samples in each dataset. For river-flow datasets, there is minimal correlation between prediction accuracy and the value of C. We set J = 2 and C = 4 for these datasets.
For comparison, MWGP II, MWGP I, MGP, WGP, GP, FNN, and SVM are considered in , respectively. The average predicted RMSEs (cubic meters/second), average predicted MAEs, and average running times of these models are recorded in Table 6. From this table, MWGP II and MWGP I are smaller than the other models in terms of the average predicted RMSE and average predicted MAE, and the average predicted RMSE and average predicted MAE of MWGP II are smaller than those of MWGP I. Although MWGP I has the same accuracy as MWGP II in , it is more efficient than MWGP II. Based on the analysis above, our proposed MWGP II and MWGP I are effective for processing the river-flow datasets, and demonstrate that the nonlinear transformation is useful for this type of data. Additionally, MWGP II can overcome the local optimum of MWGP I at a minimal computational cost on some datasets.
6. Conclusions and Discussion
In this paper, we demonstrate that the MWGP model is a valuable generalization of the MGP and WGP models, and it is well suited for solving non-stationary probabilistic regression. From another point of view, the standard preprocessing transformation in MWGP can be learned adaptively and improved upon. We show that simultaneous split and merge operations are able to eliminate the component differences between the two regions to avoid the local optimum of the CEM algorithm for MWGP. Experimental results on synthetic and real-world datasets show that our proposed MWGP trained by the CEM algorithm as well as MWGP trained by the SMCEM algorithm are effective.
For MWGP, the actual number of WGP components is generally difficult to learn due to the correlation among outputs. In future work, we will focus on learning C for MWGP. Moreover, for probabilistic regression models, there are likely outliers in the observations that deviate significantly from the other samples. We will consider the robustness for MWGP based on the robustness of the MGP.
Author Contributions
Conceptualization, Y.X. and D.W.; methodology, Y.X., D.W. and Z.Q.; data simulation and experiment, Y.X. and D.W.; writing—original draft, Y.X.; writing—review and editing, D.W.; supervision, D.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (62006149), the Natural Science Foundation of Shaanxi Province (2020JQ-403), and the Foundation of Shaanxi Educational Committee (18JK0792).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The motorcycle data and the river-flow data that support the findings of this study are available at https://doi.org/10.1111/j.2517-6161.1985.tb01327.x; https://doi.org/10.2307/1403750 (accessed on 9 June 2022). All other datasets are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare that they have no known competing financial interest or personal relationships that could have appeared to influence the work reported in this paper.
Nomenclature
| AEP | Average estimated parameter |
| ALLF | Approximated log-likelihood function |
| CEM | Classification expectation–maximization (also called hard-cut expectation–maximization or hard expectation–maximization) |
| EM | Expectation–maximization |
| FNN | Feedforward neural network |
| GP | Gaussian process |
| LOOCV | Leave-one-out cross-validation |
| MAE | Mean absolute error |
| MAP | Maximum a posteriori |
| MCMC | Markov chain Monte Carlo |
| ME | Mixture of experts |
| MGP | Mixture of Gaussian processes |
| MLE | Maximum likelihood estimation |
| MWGP | Mixture of warped Gaussian processes |
| RMSE | Root mean square error |
| RP | Real parameter |
| SDEP | Standard deviation of the estimated parameter |
| SD | Standard deviation |
| SMCEM | Split and merge classification expectation–maximization |
| SVM | Support vector machine |
| VB | Variational Bayesian |
| WGP | Warped Gaussian process |
Appendix A. Details of the CEM Algorithm
Appendix A.1. The Derivation of the Q-Function and Details of the Approximated MAP Principle
Denote as the function vector of the c-th component, as the covariance matrix of the c-th component, and as a Jacobian term. The total log-likelihood function of MWGP is given by
where is the log-likelihood function of the c-th WGP given by
The Q-function of the conventional EM algorithm of MWGP is obtained by the expectation of Equation (A1) with respect to
The posterior probability is calculated by
where is the Jacobian term. Since the number of is , the time complexity of calculating Equation (A2) is . Thus, the classification approximation is adopted for calculating Equation (A2), and then we obtain the approximated Q-function for the CEM algorithm:
where is calculated by an approximation of the MAP method, i.e., :
Appendix A.2. Details for Maximizing the Approximated Q-Function
Parameters and are updated jointly by the conjugated gradient method inherited by training the WGP.
Parameters , and are solved analytically as follows. By adopting the Lagrange multiplier method when , we have
Let = 0 and = 0. Then, we have
Appendix B. Details of the Partial CEM Algorithm
Appendix B.1. Details of Maximizing the Approximated Q-Function of the Partial CEM Algorithm
The approximated Q-function Equation (A4) is equal to
where the first three terms, i.e., are only maximized for the partial CEM algorithm. The details for maximizing are described in Appendix A.2.
Appendix B.2. Details of the Approximated MAP Principle of the Partial CEM Algorithm
When , is obtained by the approximated MAP method:
where is derived by Equation (A3).
Appendix C. Split and Merge Criteria
Since there are too many candidate sets, it is necessary to propose specific reasonable criteria to speed up the SMCEM algorithm.
The merge criterion is defined by
where is the Euclidean norm, and represents the following vectors , in which are derived by Equation (A3). Components with the largest are used for merging, where .
The split criterion is defined by
The component with the smallest is used for splitting.
References
- Yuksel, S.E.; Wilson, J.N.; Gader, P.D. Twenty years of mixture of experts. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1177–1193. [Google Scholar] [CrossRef]
- Jordan, M.I.; Jacobs, R.A. Hierarchies mixtures of experts and the EM algorithm. Neural Comput. 1994, 6, 181–214. [Google Scholar] [CrossRef]
- Lima, C.A.M.; Coelho, A.L.V.; Zuben, F.J.V. Hybridizing mixtures of experts with support vector machines: Investigation into nonlinear dynamic systems identification. Inf. Sci. 2007, 177, 2049–2074. [Google Scholar] [CrossRef]
- Tresp, V. Mixtures of Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 1 January 2000; Volume 13, pp. 654–660. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–38. [Google Scholar]
- Rasmussen, C.E.; Ghahramani, Z. Infinite mixture of Gaussian process experts. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 9–14 December 2002; Volume 2, pp. 881–888. [Google Scholar]
- Meeds, E.; Osindero, S. An alternative infinite mixture of Gaussian process experts. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 4–7 December 2005; Volume 18, pp. 883–896. [Google Scholar]
- Yuan, C.; Neubauer, C. Variational mixture of Gaussian process experts. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–11 December 2008; Volume 21, pp. 1897–1904. [Google Scholar]
- Brahim-Belhouari, S.; Bermak, A. Gaussian process for nonstationary time series prediction. Comput. Stat. Data Anal. 2004, 47, 705–712. [Google Scholar] [CrossRef]
- Pérez-Cruz, F.; Vaerenbergh, S.V.; Murillo-Fuentes, J.J.; Lázaro-Gredilla, M.; Santamaría, I. Gaussian processes for nonlinear signal processing: An overview of recent advances. IEEE Signal Process. Mag. 2013, 30, 40–50. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Process for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Chapter 2. [Google Scholar]
- MacKay, D.J.C. Introduction to Gaussian processes. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 133–166. [Google Scholar]
- Xu, Z.; Guo, Y.; Saleh, J.H. VisPro: A prognostic SqueezeNet and non-stationary Gaussian process approach for remaining useful life prediction with uncertainty quantification. Neural Comput. Appl. 2022, 34, 14683–14698. [Google Scholar] [CrossRef]
- Heinonen, M.; Mannerström, H.; Rousu, J.; Kaski, S.; Lähdesmäki, H. Non-stationary Gaussian process regression with hamiltonian monte carlo. In Proceedings of the Machine Learning Research, Cadiz, Spain, 9–11 May 2016; Volume 51, pp. 732–740. [Google Scholar]
- Wang, Y.; Chaib-draa, B. Bayesian inference for time-varying applications: Particle-based Gaussian process approaches. Neurocomputing 2017, 238, 351–364. [Google Scholar] [CrossRef]
- Rhode, S. Non-stationary Gaussian process regression applied in validation of vehicle dynamics models. Eng. Appl. Artif. Intell. 2020, 93, 103716. [Google Scholar] [CrossRef]
- Sun, S.; Xu, X. Variational inference for infinite mixtures of Gaussian processes with applications to traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2010, 12, 466–475. [Google Scholar] [CrossRef]
- Jeon, Y.; Hwang, G. Bayesian mixture of gaussian processes for data association problem. Pattern Recognit. 2022, 127, 108592. [Google Scholar] [CrossRef]
- Li, T.; Ma, J. Attention mechanism based mixture of Gaussian processes. Pattern Recognit. Lett. 2022, 161, 130–136. [Google Scholar] [CrossRef]
- Kim, S.; Kim, J. Efficient clustering for continuous occupancy mapping using a mixture of Gaussian processes. Sensors 2022, 22, 6832. [Google Scholar] [CrossRef]
- Tayal, A.; Poupart, P.; Li, Y. Hierarchical double Dirichlet process mixture of Gaussian processes. In Proceedings of the 26th AAAI Conference on Artificial Intelligence (AAAI), Toronto, ON, Canada, 22–26 July 2012; pp. 1126–1133. [Google Scholar]
- Sun, S. Infinite mixtures of multivariate Gaussian processes. In Proceedings of the International Conference on Machine Learning and Cybernetics (ICMLC), Tianjin, China, 14–17 July 2013; pp. 1011–1016. [Google Scholar]
- Kastner, M. Monte Carlo methods in statistical physics: Mathematical foundations and strategies. Commun. Nonlinear Sci. Numer. Simul. 2010, 15, 1589–1602. [Google Scholar] [CrossRef]
- Khodadadian, A.; Parvizi, M.; Teshnehlab, M.; Heitzinger, C. Rational design of field-effect sensors using partial differential equations, Bayesian inversion, and artificial neural networks. Sensors 2022, 22, 4785. [Google Scholar] [CrossRef] [PubMed]
- Noii, N.; Khodadadian, A.; Ulloa, J.; Aldakheel, F.; Wick, T.; François, S.; Wriggers, P. Bayesian inversion with open-source codes for various one-dimensional model problems in computational mechanics. Arch. Comput. Methods Eng. 2022, 29, 4285–4318. [Google Scholar] [CrossRef]
- Ross, J.C.; Dy, J.G. Nonparametric mixture of Gaussian processes with constraints. In Proceedings of the 30th International Conference on Machine Learning (ICML), Atlanta, GA, USA, 17–19 June 2013; pp. 1346–1354. [Google Scholar]
- Yang, Y.; Ma, J. An efficient EM approach to parameter learning of the mixture of Gaussian processes. In Proceedings of the Advances in International Symposium on Neural Networks (ISNN), Guilin, China, 29 May–1 June 2011; Volume 6676, pp. 165–174. [Google Scholar]
- Chen, Z.; Ma, J.; Zhou, Y. A precise hard-cut EM algorithm for mixtures of Gaussian processes. In Proceedings of the 10th International Conference on Intelligent Computing (ICIC), Taiyuan, China, 3–6 August 2014; Volume 8589, pp. 68–75. [Google Scholar]
- Celeux, G.; Govaert, G. A classification EM algorithm for clustering and two stochastic versions. Comput. Stat. Data Anal. 1992, 14, 315–332. [Google Scholar] [CrossRef]
- Wu, D.; Chen, Z.; Ma, J. An MCMC based EM algorithm for mixtures of Gaussian processes. In Proceedings of the Advances in International Symposium on Neural Networks (ISNN), Jeju, Republic of Korea, 15–18 October 2015; Volume 9377, pp. 327–334. [Google Scholar]
- Wu, D.; Ma, J. An effective EM algorithm for mixtures of Gaussian processes via the MCMC sampling and approximation. Neurocomputing 2019, 331, 366–374. [Google Scholar] [CrossRef]
- Ma, J.; Xu, L.; Jordan, M.I. Asymptotic convergence rate of the EM algorithm for Gaussian mixtures. Neural Comput. 2000, 12, 2881–2907. [Google Scholar] [CrossRef]
- Zhao, L.; Chen, Z.; Ma, J. An effective model selection criterion for mixtures of Gaussian processes. In Proceedings of the Advances in Neural Networks-ISNN, Jeju, Republic of Korea, 15–18 October 2015; Volume 9377, pp. 345–354. [Google Scholar]
- Ueda, N.; Nakano, R.; Ghahramani, Z.; Hinton, G.E. SMEM algorithm for mixture models. Adv. Neural Inf. Process. Syst. 1998, 11, 599–605. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Li, L. A novel split and merge EM algorithm for Gaussian mixture model. In Proceedings of the International Conference on Natural Computation (ICNC), Tianjin, China, 14–16 August 2009; pp. 479–483. [Google Scholar]
- Zhang, Z.; Chen, C.; Sun, J.; Chan, K.L. EM algorithms for Gaussian mixtures with split-and-merge operation. Pattern Recognit. 2003, 36, 1973–1983. [Google Scholar] [CrossRef]
- Zhao, L.; Ma, J. A dynamic model selection algorithm for mixtures of Gaussian processes. In Proceedings of the IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 1095–1099. [Google Scholar]
- Li, T.; Wu, D.; Ma, J. Mixture of robust Gaussian processes and its hard-cut EM algorithm with variational bounding approximation. Neurocomputing 2021, 452, 224–238. [Google Scholar] [CrossRef]
- Snelson, E.; Rasmussen, C.E.; Ghahramani, Z. Warped Gaussian processes. Adv. Neural Inf. Process. Syst. 2003, 16, 337–344. [Google Scholar]
- Schmidt, M.N. Function factorization using warped Gaussian processes. In Proceedings of the 26th International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; pp. 921–928. [Google Scholar]
- Lázaro-Gredilla, M. Bayesian warped Gaussian processes. Adv. Neural Inf. Process. Syst. 2012, 25, 6995–7004. [Google Scholar]
- Rios, G.; Tobar, F. Compositionally-warped Gaussian processes. Neural Netw. 2019, 118, 235–246. [Google Scholar] [CrossRef]
- Zhang, Y.; Yeung, D.Y. Multi-task warped Gaussian process for personalized age estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2622–2629. [Google Scholar]
- Wiebe, J.; Cecílio, I.; Dunlop, J.; Misener, R. A robust approach to warped Gaussian process-constrained optimization. Math. Program. 2022, 196, 805–839. [Google Scholar] [CrossRef]
- Mateo-Sanchis, A.; Muñoz-Marí, J.; Pérez-Suay, A.; Camps-Valls, G. Warped Gaussian processes in remote sensing parameter estimation and causal inference. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1647–1651. [Google Scholar] [CrossRef]
- Jadidi, M.G.; Miró, J.V.; Dissanayake, G. Warped Gaussian processes occupancy mapping with uncertain inputs. IEEE Robot. Autom. Lett. 2017, 2, 680–687. [Google Scholar] [CrossRef]
- Kou, P.; Liang, D.; Gao, F.; Gao, L. Probabilistic wind power forecasting with online model selection and warped Gaussian process. Energy Convers. Manag. 2014, 84, 649–663. [Google Scholar] [CrossRef]
- Gonçalves, I.G.; Echer, E.; Frigo, E. Sunspot cycle prediction using warped Gaussian process regression. Adv. Space Res. 2020, 65, 677–683. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Nickisch, H. Gaussian processes for machine learning (GPML) toolbox. J. Mach. Learn. Res. 2010, 11, 3011–3015. [Google Scholar]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feedforward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Mcleod, A.I. Parsimony, model adequacy and periodic correlation in forecasting time series. Int. Stat. Rev. 1993, 61, 387–393. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).