1. Introduction
Smartphones have become an essential tool in our daily lives, but they do not last forever. The best phone goes through many problems before it dies, which makes you look for a new one. Therefore, when buying a new phone, it is necessary to know how long the phone will last before it dies. In this article, we will cover the lifespan of smartphones, considering that they follow a specific distribution, and we will estimate the parameters of this distribution and some important functions, such as the entropy function of this distribution, in order to provide some information that will benefit the companies designed for these devices, as well as to support decision makers in the field of technology to improve efficiency and to extend the life of these phones. In this study, we will consider that the lifetimes of phones follow the gamma distribution.
A continuous probability distribution called gamma is used to model continuous random variables (lifetimes of phones) with skewed distributions and fixed positive values. This group of continuous probability distributions has two parameters. The gamma distribution is exemplified in particular by the exponential, Erlang, and chi-squared distributions. It is extensively applied in a variety of application areas, such as engineering, the environment, meteorology, climatology, and other physical circumstances, as well as queuing theory and reliability theory (see Lawless [
1]). The probability density function (PDF) of a gamma random variable (RV) is defined as follows:
where
is the well-known gamma function defined by
and the corresponding cumulative distribution function (CDF) is given by
where
=
is the upper incomplete gamma function. The PDF of a gamma RV takes on a wide variety of shapes depending on the values of
, also known as the shape parameter, and
referred to as the inverse scale parameter, called a rate parameter. The hazard function shape of gamma distribution can be increased, decreased, or constant depending on
,
, or
, respectively. When
, the gamma RV becomes an exponential RV with parameter
, and when
,
and
, one can show that gamma RV decreases to the chi-square distribution with
n degrees of freedom. Moreover, when
(integer), the gamma distribution is sometimes known as the Erlang distribution. In addition, the log-normal distribution is a limiting special case when
.
However, estimating the gamma parameters is still a complex issue. Recently, there have been many studies on the estimation procedure for the gamma distribution based on both complete and censored data. For instance, Son and Oh [
2] proposed a Bayesian estimator using Gibbs sampling for the two-parameter gamma distribution based on a complete sample. Under the same sample, Pradhan and Kundu [
3] studied the Bayes estimation and prediction of the two-parameter gamma distribution. Basak and Balakrishnan [
4] considered some classical procedures to estimate the three-parameter gamma distribution using progressive Type-II samples. Bayesian inference for the capability index of the gamma distribution was developed by Almeida et al. [
5]. Recently, Dey et al. [
6] derived maximum likelihood and Bayes estimates of the unknown parameters of the gamma lifetime model based on progressive Type-II censoring, and also studied the problem of interval estimation.
Uncertainty about the time of death is part of the life of any product, and plays an important role in demographic and actuarial sciences. This paper analyzes death uncertainty through the concept of entropy. For more details on the concept of uncertainty and its applications, one can see Singh [
7]. One way to define entropy in statistics is the expected value of the information content of a random variable. Information content, also known as subjective information or surprise, is a measure of the amount of information gained by observing the outcome of a random variable. The information content is inversely proportional to the probability of the outcome: the higher the probability of the outcome, the less information you provide; the outcome is less likely. There are several types of informational entropies. The concept of entropy was defined by Rényi [
8]. For more details, see, Amigó et al. [
9]. Here, we focus our attention on two of the most famous measures of entropy, namely the Shannon [
10], and Rényi [
8] entropies. If
X is a continuous RV with PDF, say,
, then the Shannon entropy “ShEn”, say,
, is defined by
and the Rényi entropy “REn”, say,
, is given by
Note that as
tends to one,
tends to
. When
gamma
, the
and
can be obtained as
and
where
is the digamma function, given by
and
is known as Euler’s constant. As given by Acharya et al. [
11], the Renyi entropy has many applications. Estimations of the Shannon and Renyi entropies have many applications in various fields; for example, in medicine, it is used in measuring genetic diversity, measuring neural activity, detecting cardiac autonomic neuropathy (CAN) in patients with diabetes (Cornforth et al. [
12]), etc. Several authors have presented the problem of estimating entropy functions for different distributions under various samples. Among them, Kang et al. [
13] introduced estimators of entropy for a double exponential distribution when the samples are multiplying Type-II censored samples. Cho et al. [
14] estimated the ShEn function of the Rayleigh distribution based on doubly generalized Type II hybrid censored samples. Based on generalized Type II hybrid censored samples, Cho et al. [
15] derived estimators for the entropy function of a Weibull distribution. The estimated entropy for a generalized exponential distribution under record values is obtained by Chacko [
16]. Liu and Gui [
17] investigated the ShEn for Lomax distribution based on a generalized progressive hybrid censoring scheme. Furthermore, statistical inference on the ShEn of the inverse Weibull distribution under PFF censoring was considered by Yu et al. [
18]. One of the main objectives of this research is to estimate the ShEn and REn of gamma distribution based on progressive first-failure censoring data.
Life-testing experiments are powerful tools in modern science and technology for gaining comprehensive knowledge of products. It is challenging to obtain comprehensive information about every failed unit in the life-testing experiment. The sampling process is condensed by the particular censoring method set in advance to save time and cut costs. The final sample we obtain is known as a censored sample. Censoring is a highly prevalent occurrence that has been exploited extensively in the fields of industrial engineering, biology, clinical trials, radio interference, etc. It has been shown through various life experiences that both statistical inference and cost savings can be achieved by designing a reasonably effective censoring system. The most popular censoring techniques among the numerous approaches are Type-I and Type-II with its PFF schemes. For more information see, Balakrishnan and Aggarwala [
19], Wu and Kus [
20], Dube et al. [
21], Maurya et al. [
22], and references cited therein. In the PFF censoring scheme, we randomly divide
N(
) units into
n groups, with each group containing
k independent units. We observe these
n groups simultaneously and independently. Now, let the failure times of
items under the study have a continuous PDF
and CDF
; the joint PDF of
can be formulated as
where
.
In this study, we consider PFF censoring because of its good generalization behavior with other censoring plans. To the best of our knowledge, there are not any papers dealing with the estimation of the gamma distribution parameters based on PFF censoring.
3. Expectation–Maximization Algorithm
The EM algorithm was presented mathematically in detail by Dempster et al. [
26] whereas for its application to PFF see, Ng et al. [
27]. Suppose that
consists of observable
data and censored observations (
) data, with
being a
vector, such that
(
),
. The likelihood function, say,
, of the complete data is given by
The log-likelihood for the complete lifetimes of
items from the two parameters gamma distribution, say,
, can be represented as
The E-step involves the computation of the conditional expectation
, which is equal to the pseudo
, defined as
Then, the E-step needs the computation of
and
, where, the conditional probability function of the censored data, given the observed data, can be obtained [
24] as follows:
Given that
for
, the required expected values of a truncated gamma from the left at
t are, respectively, given by
and
The M-step deals with maximization of
with respect to
and
. Let the
-stage estimate of (
) be (
); then, next updated estimate (
) is obtained by maximizing the following equation:
By taking the derivatives of (30) with respect to
and
, respectively, and equating them to zero, as follows:
and
From (31),
and from (33),
or equivalently,
Substituting from (34) in (33), we have
We observe that the updated estimate
of
can be computed from the fixed-point method, for which we solve the equation
where
and
It is observed that
can be obtained from (36). Then, (
,
) are used as the current estimates of (
) in the next iteration. The MLEs of (
) can be obtained by repeating the E-step and M-step until convergence is achieved. We stop the iterations when
, where ∈ is the tolerance limit.
According to the Corollary in McLachlan et al. [
28] (page 84), the proposed EM estimator sequence converges to the unique maximizer of the log-likelihood function. Using the obtained point estimators of
,
and the invariance property of MLEs, we can derive the estimates for the ShEn and REn measures, which are given as follows:
and
5. Radio Transceiver Data
The data used here were first provided by Aitkin [
36] in 2022. They contain phone lifetimes in hours. The considered data were obtained from the study of the operating lifetimes of field telephones (radio transceivers) operating under industry conditions, which examined the lifetimes of a sample of 88 telephones, all of which were the same make and type. The aim of the study was to create a cleaning and maintenance program for phones to reduce the possibility of them breaking down and becoming unusable. According to this study, the phones were used by workers on eight-hour shifts. The number of shifts during which the telephones were operating correctly was recorded for each of the phones in the study. The telephones were switched off at the end of a shift, placed in the battery charger, and switched on again at the beginning of the next shift. Some telephones failed to switch on correctly at the beginning of a shift; others failed during a shift. The lifetimes of the 88 phones were recorded as 8, 16, 16, 16, 16, 32, 32, 40, 40, 40, 40, 56, 56, 56, 60, 64, 72, 72, 72, 72, 72, 80, 80, 80, 80, 96, 96, 104, 108, 112, 112, 114, 120, 128, 136, 152, 152, 152, 156, 160, 168, 168, 168, 168, 168, 176, 184, 184, 184, 194, 208, 208, 216, 224, 224, 224, 224, 232, 240, 246, 256, 264, 264, 272, 280, 288, 304, 308, 328, 328, 340, 352, 358, 360, 384, 392, 400, 424, 438, 448, 464, 480, 536, 552, 576, 608, 656, 716. To check whether the gamma distribution is an appropriate statistical distribution to fit the lifetime data set or not, the MLEs of the gamma parameters
and
were calculated. Moreover, various criteria, such as the negative log-likelihood function “
”, Akaike information criterion “
”, Bayesian information criterion “
”, and Kolmogorov–Smirnov (K-S) statistics, were applied to test the goodness of fit of the model with its corresponding
p-value, where
is a parameter vector,
d is the number of parameters in the fitted model,
is evaluated at the MLEs, and
N is the number of observed values. The numerical values of the MLEs,
, AIC, BIC, K-S, and
p-values for the complete data set were computed as
,
,
, AIC
, BIC
, K-S
, and
p-value
. We can see that the gamma distribution shows a good fit for the data set, and we do not reject the hypothesis that the data come from gamma distribution at significance levels of 0.05 because of the high
p-value. In support of that, the fitting of the gamma model was examined using graphical fitting (
Figure 1) techniques, including (i) a fitted gamma PDF, (ii) a probability–probability plot, (iii) a quantile–quantile plot, and (iv) an empirical and fitted gamma CDF. This figure proves again that the gamma distribution is a suitable lifetime model to fit considered data. Hence, we may use our model to analyze this data.
Before creating PFF censored samples, we would like to provide an initial idea of the different estimators based on the complete data (
,
). First, based on the complete data, the MLEs of the
,
,
, and
are calculated and provided in
Table 1. When dealing with full data, the MLEs were calculated using both the NR and EM algorithms, and we discovered that the values are identical. Thus, the results are only provided once in
Table 1 to avoid repetition. Similar reasoning can be applied to the MLEs’ approximated 95% CIs.
Figure 2 gives a likelihood function surface plot for a two-parameter gamma distribution.
Figure 3 gives the contour plot of the profile log-likelihood parameters
and
. It reveals that the maximum value is attained at (
. Furthermore, we depict the graphs of parameter profile versus log-likelihood function in
Figure 4. From these graphs, we can say that the estimated ML can be calculated uniquely, or equivalently, the log-likelihood for this data is maximized when
and
.
For Bayesian estimation, given by
Section 4, we cannot obtain the informative priors, so all Bayesian estimates are obtained here based on the noninformative prior (NIP) (
). Using the MH algorithm described in
Section 4.3, we generate
MCMC samples and discard the first
samples as burn-in. To run the MCMC algorithm, the ML estimates of
, and
are taken to be the initial guesses. Under SE and LINEX loss functions (with
), the Bayesian MCMC estimates and associated 95% credible intervals of
,
,
, and
using both of the noninformative priors are computed and presented in
Table 1. From
Table 1, we can see both the MLE and the Bayes estimates of
,
,
, and
are relatively close. We considered a convergence diagnostic criterion proposed by Geweke [
37] to confirm the convergences of chains generated via MCMC, assuming a 95% confidence level. This graph allows us to confirm the convergence of the chain. Trace plots based on 60,000 chain values of
,
,
, and
are provided in
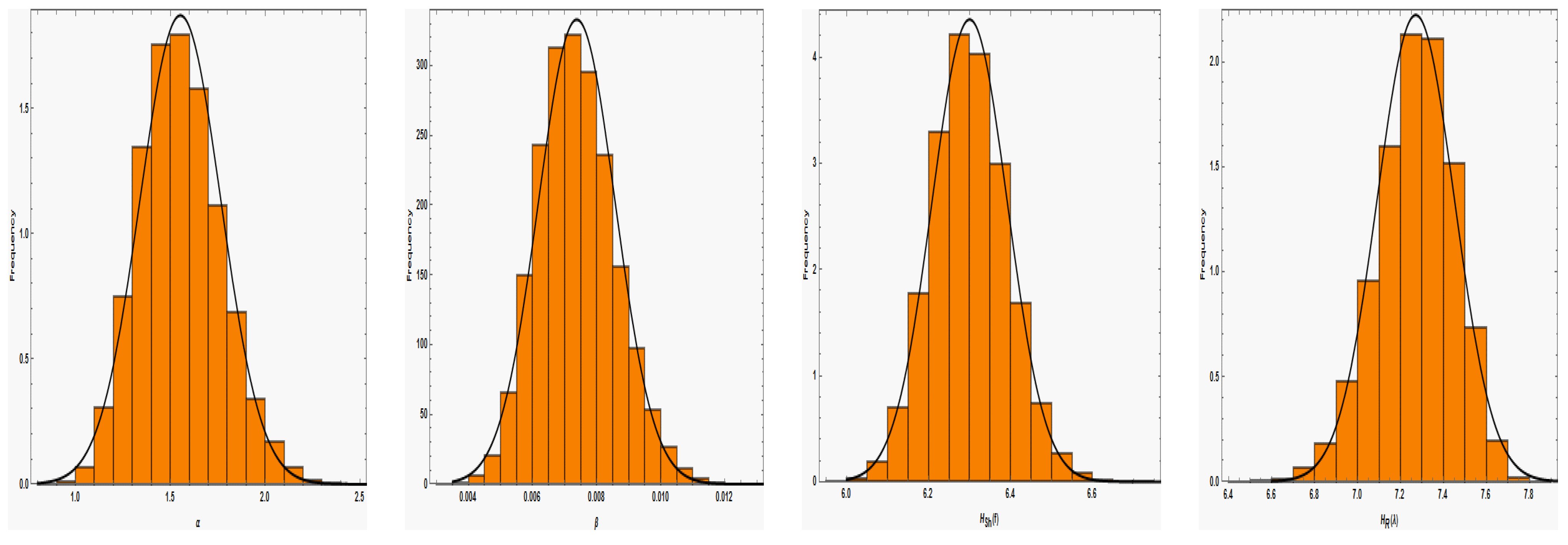
Figure 5 to demonstrate how well the simulated MCMC samples approximate. Each trace plot displays the sample’s arithmetic mean (represented by a dashed horizontal line) and its 95% HPD intervals (represented by a solid horizontal line). It shows that the MCMC method based on the remaining 60,000 variates converges successfully, and that using the first 10,000 samples as burn-in is suitable from a size point of view to eliminate the influence of the initial values. The histograms for the parameter estimates based on 60,000 chain values and the Gaussian kernel are also shown in
Figure 6. The estimates unequivocally demonstrate that each and every one of the generated posteriors is symmetric with respect to the theoretical posterior density functions. The estimates clearly indicate that all of the generated posteriors are symmetric with respect to the theoretical posterior density functions.
In our next step, we randomly partition the given data into
groups with
independent items inside each group in order to analyze this data set using PFF censored samples. Thereafter, the following first-failure censored data are obtained: 8, 16, 16, 32, 40, 40, 56, 60, 72, 72, 72, 80, 80, 96, 108, 112, 120, 136, 152, 156, 168, 168, 168, 184, 184, 208, 216, 224, 224, 240, 256, 264, 280, 304, 328, 340, 358, 384, 400, 438, 464, 536, 576, 656. Next, we generate PFF censored samples using three different censoring schemes from the above first-failure censored sample with
. The different censoring schemes and the corresponding PFF censored samples are presented in
Table 2. As was presented above for the complete sample, the estimates of ML and Bayes were calculated, and the numerical results are presented in
Table 3. Moreover, the estimates of
,
,
, and
based on EM algorithm were calculated and added to the table because they differ from the estimates calculated by NR in the case of censored samples data.
Tabulated values show that the various estimations are reasonably close to one another. Moreover, for
,
, and
, the Bayes estimation based on NIP has good behavior when compared to the other intervals in terms of interval lengths. In the cases of CS1 and CS2, we discover that the MLE of
based on the EM algorithm is the best estimate, whereas in the case of CS3, we find that the Bayes estimation based on the NIP prior is the best.
Table 4 shows the effect of parameter
v on the Bayes estimates, whereas in the case of negative values, we noticed that there was an increase in the values of the estimates from those calculated by the SE loss function, and vice versa in the case of the positive value. Practically, it is not possible to compare the methods presented in this paper with one sample, so we will present a simulation study in the next section.
6. Simulation Study
The proposed estimates of the entropy functions provided by (3) and (4), as well as the unknown parameters of the gamma distribution, are compared numerically in this section. Based on their average biases and mean squared errors (MSE), the MLEs and Bayes estimates are compared. On the other hand, for the interval estimates, we contrast them in light of their average lengths. For this aim, each simulation uses PFF censored samples. The following steps were used to simulate a PFF-censored sample from the gamma distribution with parameters and for given values of n, m, k, and a progressive censoring scheme :
- (1)
Create a random sample of size m from standard uniform distribution, denoted by .
- (2)
Set for where .
- (3)
Set for . Thus, () is a progressively Type-II censored sample from standard uniform distribution.
- (4)
Set for . The data set () is a progressively first-failure censored sample from standard uniform distribution.
- (5)
Finally, set with , and hence, the required progressively first-failure censored sample is ().
Three different sample sizes,
and 50, as well as four failure sample sizes,
, and 40, were used in this study. Using different censoring schemes, we first derived progressively first-failure type-II censored samples that follow the gamma distribution with
and
. Then, we calculated the MLEs of
,
,
, and
based on the NR method, using (10)–(15). Next, according to (35)–(38), the EM algorithm was applied to compute the MLEs. To compute the Bayes estimates based on the NIP and informative prior of
and
, using the MH algorithm, we ran the iterative process up to
11,000 iterations by discarding the first
iterations as a burn-in period. For the informative prior, the values of the hyperparameters were taken as
,
,
, and
. Moreover, the Bayes estimates with respect to the LINEX loss function were computed for the values of
and
. Recall that the notation (
) used in the tables expresses the censoring scheme (
). The average bias values (in the first row) and the MSEs (in the second row) of the MLEs and Bayes estimates are presented in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9. The bias and mean-squared errors (MSEs) of the estimates were computed using the following formula:
For the problem under study,
, and
.
Besides the point estimates, log-transformed MLEs, EM, and Bayesian methods were used to obtain the 95% confidence/credible intervals for
,
,
, and
.
Table 9 and
Table 10 give the average lengths (ALs) and coverage probabilities (CPs) of the resulting intervals of
,
,
, and
with
, respectively. In general, we notice from
Table 6,
Table 7,
Table 8 and
Table 9 that the Bayes estimates have superior performance compared to the MLEs in terms of the MSEs. For the case of the LINEX loss function, the Bayes estimate of
and
seems to be a reasonable choice when
. However, the best choice of
, and
is when
. Additionally, it was found that the Bayes estimates derived using the informative prior (IP) perform better in terms of MSEs than those acquired using the NIP. Furthermore, the average biases and MSEs both tend to decrease with increasing effective sampling sizes. As a result, increasing the sample size generally yields better-estimating results. Moreover, in most cases considered, the MSEs of all estimates decrease as
k increases, while
n and
m remain fixed. The ALs of the NIP are also longer than IP ALs. Then, the IP outperforms the NIP.
Table 9 and
Table 10 show that for all censoring schemes, the EM technique produces more precise confidence intervals than NR intervals. Comparing all three methods, it is evident that Bayes credible intervals have the best average lengths. Then, the Bayes approach is more suited to obtaining the confidence intervals of
,
,
, and
. Additionally, compared to the IP, the NIP ALs have greater lengths. Then, the IP outperforms the NIP. Finally, it can be noted that all average interval lengths decrease when the effective sample sizes increase. Moreover, it was observed that the CPs of the asymptotic and credible intervals of
,
,
, and
were all close to the desired level of 0.95.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}