
User2Vec: A Novel Representation for the Information of the Social Networks for Stock Market Prediction Using Convolutional and Recurrent Neural Networks

Abstract
:1. Introduction
- We presented a hybrid model that leverages diverse sources of information for stock market prediction.
- We proposed a new representation called User2Vec, which captures each user’s tweet about a specific share.
- We employed two user scoring mechanisms based on the accuracy of their predictions and their credibility within the social network.
- We used 1D-CNN stacked recursive neural networks to forecast the market direction for the next day.
2. Literature Review
2.1. Prediction Methods
2.2. Feature-Based Methods
3. Materials and Methods
3.1. Data Collection
3.1.1. Yahoo Finance App
3.1.2. Twitter API
3.1.3. Statistical Analysis of the Collected Messages
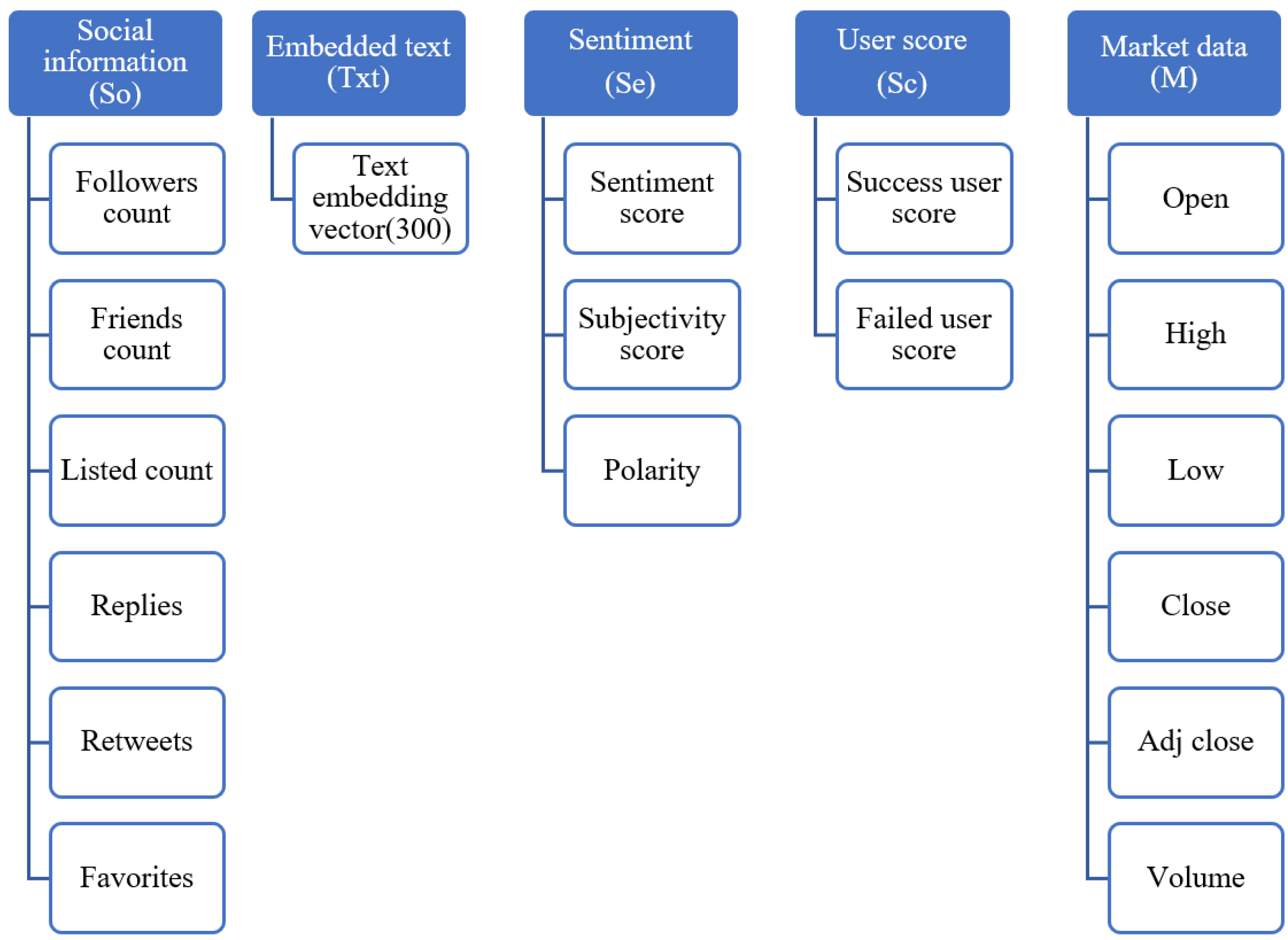
3.2. Feature Extraction
3.2.1. Social Information
3.2.2. Embedded Text
3.2.3. Sentiment
3.2.4. User Score
3.2.5. Market Data
3.3. Prediction
- CNNs have shown their versatility and effectiveness in handling a wide range of data types, including sequences of embedded word vectors. Our proposed model uses a CNN network to process the feature matrix obtained from both numerical and textual data. The structure of the feature matrix is such that each row represents the feature vector of a specific tweet combined with the corresponding numerical market data, while each column captures a distinct feature containing relevant information. To extract meaningful patterns from the feature matrix, our model incorporates two convolutional layers within the CNN component. Each layer comprises fifty 1D filters, thereby enabling the model to capture and analyze local dependencies within the data effectively. Following the convolutional layers, we introduce a batch normalization layer to enhance the performance of the model and stability. This layer normalizes the intermediate outputs of the network, thereby mitigating the impact of internal covariate shifts, as well as improving overall training efficiency and the ability of the model to generalize. By harnessing the power of CNNs in our model architecture, we can efficiently process the combined numerical and textual data. This enables us to extract relevant features and facilitate subsequent analysis for market prediction purposes.
- In our model, we used stacked bidirectional LSTM layers to generate a concise representation of the input data for predicting stock market direction, thus building upon the output of the CNN networks. Stacked structures, comprising two or more LSTM layers, are employed to capture increasingly complex data patterns. In a stacked RNN, the output of the lower layers serves as input for higher layers, thereby enabling the model to achieve varying levels of abstraction across multiple network layers. According to theoretical evidence, a deep hierarchical model can represent some functions more efficiently than a shallow one [78]. Traditional RNNs have a limitation in that they only consider previous context and disregard future context. However, bidirectional LSTM models overcome this limitation by processing data in both forward and backward directions, thereby effectively incorporating both past and future context. Our model incorporates stacked bidirectional LSTM layers to leverage this advantage. The feature vectors obtained from the outputs of the CNNs are fed into the cells of the first bidirectional LSTM network. One LSTM layer processes the data in its original order, while the other LSTM layer performs the same task in reverse. Each input vector generates two independent output vectors from these two networks: one considering the previous inputs and the other considering the future inputs. These two outputs are concatenated to form an intermediate representation for each input vector, which is then passed as input to the second bidirectional LSTM network. The second network operates similarly, thus producing the final representation of the input data for the last layer. The LSTM transition equations are as follows:where represents the input at time step t, displays the input gate activation, represents the forget gate activation, serves as the memory cell state, represents the output gate activation, and is the hidden state at time step t. W and U are weight matrices, and b denotes bias vectors. The activation functions used are the sigmoid function () and the hyperbolic tangent function ( and ).The output of the LSTM layers provides a bullish or bearish label, thereby representing the prediction of the network for the market direction of the following day.
4. Experimental Analysis
4.1. Evaluation Metrics
4.2. Experiment Setup
4.3. Pre-Processing
- Weekend data exclusion: To preserve the integrity and accuracy of our dataset, we performed a meticulous data pre-processing procedure to eliminate information pertaining to weekends or holidays. This aspect holds significant importance in financial data analysis, since markets are commonly closed during these time periods, thus introducing potential irregularities into the data. By excluding weekends and holidays from our dataset, we concentrated our analysis only on trading days when the market was active. This approach ensures consistency within our data and prevents any distortions or biases that may arise from incorporating non-trading days.
- Time zone alignment: Achieving the proper alignment of time zones between financial data and text data is of paramount importance to ensure accurate analysis and the seamless integration of information. By establishing consistent time zones, we effectively eliminate discrepancies and allow for a seamless merging of these two essential data sources. In this study, we adopted the United States Eastern Time Zone as our reference time zone for data processing.
- Normalization: In order to mitigate multivariate value divergence, the numerical characteristics were standardized using min–max normalization, thereby ensuring that their values fell within the range of . This was achieved by linearly transforming the data values. The equation below describes the min–max normalization for feature vector x.The min–max normalization formula for normalizing a value to a target interval with original boundaries is represented as:where is the i-th element in x. and denote the minimum and maximum values of x.
- Tweet embedding layer: Word-embedding networks assign each word in a text to a D-dimensional vector space, which can subsequently serve as input for a neural network. Here, we utilized the word2vec word-embedding network, which was trained on a corpus of 100 billion words sourced from Google News. This network assigns a 300-dimensional vector to each of the 3 million words within its vocabulary. Each word in a tweet’s text is converted to a 300-dimensional vector. Then, by averaging these vectors, a 300-dimensional representation is produced for each tweet.
4.4. Model Performance
4.4.1. Ablation Study
- Rand: A naive Bayes predictor that disregards all tweets and generates random predictions for market directions, with a 50% probability of success for both upward and downward trends.
- Arima(M) [17]: A traditional prediction method that solely relies on market information.
- SBiLSTM-Day2Vec(M,Se) [6]: A state-of-the-art deep neural network baseline that predicts stock trends by incorporating a sequence of market data (M) and sentiments of the messages (Se) for each day. Many previous works in the field use this model with variations, such as using daily aggregated sentiment or incorporating additional layers such as attention [26], ref. [55], to predict the stock’s direction. Unlike our proposed model, which uses the sentiment of each tweet separately, this model aggregates the sentiment for an entire day.
- User2Vec (M,Se): This model incorporates market data and sentiment analysis as its feature set, which is a commonly employed approach to stock market prediction. Many prior studies have utilized these features in their models. Comparing the results with the outcomes of the baseline models is limited to the market data and sentiment tag (SBiLSTM-Day2Vec(M,Se)), which allows us to observe the impact of the primary contribution of this paper: converting each tweet of a user into a vector instead of converting all messages of a day into a vector.
- User2Vec(Txt): In this model, solely the text section of the tweet is utilized to construct the input vector. This approach aims to investigate whether utilizing the text of the tweets directly can be effective or if it is preferable to employ the extracted sentiment from them.
- User2Vec(Txt,M,Se): By comparing the results with a model that only uses the market and sentiment data, we can examine the effect of using the embedded text representations of tweets to enhance the accuracy of the model’s predictions.
- User2Vec(Txt,M,Se,So): By comparing the results with the previous model, we can determine whether incorporating a social analysis of users can enhance the prediction accuracy or not.
- User2Vec(Txt,M,Se,Sc): Similarly to the previous model, this model explores the impact of utilizing users’ scores on the model’s success rate.
- User2Vec(M,Se,So): The only missing feature in this model is the text of the tweets. As the length of the embedded text is significantly larger than the numerical features, excluding this feature reduces the input size and the model’s parameters. Compared to the full model, the objective of this model is to examine the contribution of the textual component of the input data.
- User2Vec(Txt,M,Se,So,Sc): This represents the complete version of our proposed model, wherein it incorporates the entire set of features.
4.4.2. Analysis and Comparison with the State of the Art
4.4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bernal, A.; Fok, S.; Pidaparthi, R. Financial Market Time Series Prediction with Recurrent Neural Networks; Citeseer: State College, PA, USA, 2012. [Google Scholar]
- Chakraborty, P.; Pria, U.S.; Rony, M.R.A.H.; Majumdar, M.A. Predicting stock movement using sentiment analysis of Twitter feed. In Proceedings of the 2017 6th International Conference on Informatics, Electronics and Vision & 2017 7th International Symposium in Computational Medical and Health Technology (ICIEV-ISCMHT), Himeji, Japan, 1–3 September 2017; pp. 1–6. [Google Scholar]
- Dingli, A.; Fournier, K.S. Financial time series forecasting—A deep learning approach. Int. J. Mach. Learn. Comput. 2017, 7, 118–122. [Google Scholar] [CrossRef]
- Guo, K.; Sun, Y.; Qian, X. Can investor sentiment be used to predict the stock price? Dynamic analysis based on the China stock market. Phys. A Stat. Mech. Appl. 2017, 469, 390–396. [Google Scholar] [CrossRef]
- Di Persio, L.; Honchar, O. Recurrent neural networks approach to the financial forecast of Google assets. Int. J. Math. Comput. Simul. 2017, 11, 7–13. [Google Scholar]
- Althelaya, K.A.; El-Alfy, E.S.M.; Mohammed, S. Evaluation of bidirectional LSTM for short-and long-term stock market prediction. In Proceedings of the 2018 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 151–156. [Google Scholar]
- Zhang, J.; Cui, S.; Xu, Y.; Li, Q.; Li, T. A novel data-driven stock price trend prediction system. Expert Syst. Appl. 2018, 97, 60–69. [Google Scholar] [CrossRef]
- Chong, E.; Han, C.; Park, F. Deep learning networks for stock market analysis and prediction: Methodology, data representations, and case studies. Expert Syst. Appl. 2017, 83, 187–205. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; He, Y.; Yuan, C.; Huang, Y. Stock market prediction exploiting microblog sentiment analysis. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4482–4488. [Google Scholar]
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Yang, C.; Zhang, J.; Puthal, D.; Luo, Y.; Li, J. Stock market analysis using social networks. In Proceedings of the Australasian Computer Science Week Multiconference, Brisbane, QLD, Australia, 29 January–2 February 2018; pp. 1–10. [Google Scholar]
- Kamkarhaghighi, M.; Chepurna, I.; Aghababaei, S.; Makrehchi, M. Discovering credible Twitter users in the stock market domain. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016; pp. 66–72. [Google Scholar]
- Daly, K.; Fayyad, A. Can oil prices predict stock market returns? Mod. Appl. Sci. 2011, 5, 44. [Google Scholar] [CrossRef] [Green Version]
- Taboada, M. Sentiment analysis: An overview from linguistics. Annu. Rev. Linguist. 2016, 2, 325–347. [Google Scholar] [CrossRef] [Green Version]
- Velay, M.; Daniel, F. Stock chart pattern recognition with deep learning. arXiv 2018, arXiv:1808.00418. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G.; Bergmeir, C.; Caceres, G.; Chhay, L.; O’Hara-Wild, M.; Yasmeen, F. Forecast: Forecasting Functions for Time Series and Linear Models. 2019. Available online: https://cran.r-project.org/package=forecast (accessed on 16 May 2023).
- Li, L.; Leng, S.; Yang, J.; Yu, M. Stock market autoregressive dynamics: A multinational comparative study with quantile regression. Math. Probl. Eng. 2016, 2016, 1285768. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z. Modelling and forecasting the stock market volatility of SSE Composite Index using GARCH models. Future Gener. Comput. Syst. 2018, 79, 960–972. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Cen, L.; Ruta, D.; Ruta, A. Using Recommendations for Trade Returns Prediction with Machine Learning. In Proceedings of the International Symposium on Methodologies for Intelligent Systems, Warsaw, Poland, 26–29 June 2017; Springer: Cham, Switzerland, 2017; pp. 718–727. [Google Scholar]
- Huang, C.F.; Li, H.C. An Evolutionary Method for Financial Forecasting in Microscopic High-Speed Trading Environment. Comput. Intell. Neurosci. 2017, 2017, 9580815. [Google Scholar] [CrossRef] [Green Version]
- Tang, L.; Zhang, S.; He, L.; Fan, H. Research on Stock Prediction in China based on Social Network and SVM Algorithms. In Proceedings of the 2018 2nd International Conference on Economic Development and Education Management (ICEDEM 2018), Dalian, China, 29–30 December 2018; Atlantis Press: Amsterdam, The Netherlands, 2018; pp. 435–438. [Google Scholar]
- Bustos, O.; Pomares, A.; Gonzalez, E. A comparison between SVM and multilayer perceptron in predicting an emerging financial market: Colombian stock market. In Proceedings of the 2017 Congreso Internacional de Innovacion y Tendencias en Ingenieria (CONIITI), Bogotá, Colombia, 4–6 October 2017; IEEE: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Weng, B.; Ahmed, M.A.; Megahed, F.M. Stock market one-day ahead movement prediction using disparate data sources. Expert Syst. Appl. 2017, 79, 153–163. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Awad, M. Stock market movement prediction using disparate text features with machine learning. In Proceedings of the 2019 Third International Conference on Intelligent Computing in Data Sciences (ICDS), Marrakech, Morocco, 28–30 October 2019; pp. 1–6. [Google Scholar]
- Hu, H.; Tang, L.; Zhang, S.; Wang, H. Predicting the direction of stock markets using optimized neural networks with Google Trends. Neurocomputing 2018, 285, 188–195. [Google Scholar] [CrossRef]
- Qiu, M.; Song, Y. Predicting the direction of stock market index movement using an optimized artificial neural network model. PLoS ONE 2016, 11, e0155133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mingyue, Q.; Cheng, L.; Yu, S. Application of the Artificial Neural Network in predicting the direction of stock market index. In Proceedings of the 2016 10th International Conference on Complex, Intelligent, and Software Intensive Systems (CISIS), Fukuoka, Japan, 6–8 July 2016; pp. 219–223. [Google Scholar]
- Zhong, X.; Enke, D. Forecasting daily stock market return using dimensionality reduction. Expert Syst. Appl. 2017, 67, 126–139. [Google Scholar] [CrossRef]
- Hong, L.; Modirrousta, M.; Hossein Nasirpour, M.; Mirshekari Chargari, M.; Mohammadi, F.; Moravvej, S.; Rezvanishad, L.; Rezvanishad, M.; Bakhshayeshi, I.; Alizadehsani, R.; et al. GAN-LSTM-3D: An efficient method for lung tumour 3D reconstruction enhanced by attention-based LSTM. CAAI Trans. Intell. Technol. 2023. [Google Scholar] [CrossRef]
- Sartakhti, M.; Kahaki, M.; Moravvej, S.; Joortani, M.; Bagheri, A. Persian language model based on BiLSTM model on COVID-19 corpus. In Proceedings of the 2021 5th International Conference On Pattern Recognition And Image Analysis (IPRIA), Kashan, Iran, 28–29 April 2021; pp. 1–5. [Google Scholar]
- Moravvej, S.; Mousavirad, S.; Moghadam, M.; Saadatm, M. An lstm-based plagiarism detection via attention mechanism and a population-based approach for pre-training parameters with imbalanced classes. In Proceedings of the Neural Information, Processing of the 28th International Conference (ICONIP 2021), Sanur, Indonesia, 8–12 December 2021; pp. 690–701. [Google Scholar]
- Moravvej, S.; Joodaki, M.; Kahaki, M.; Sartakhti, M. A method based on an attention mechanism to measure the similarity of two sentences. In Proceedings of the 2021 7th International Conference on Web Research (ICWR), Tehran, Iran, 19–20 May 2021; pp. 238–242. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lim, B.; Arık, S.; Loeff, N.; Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Moravvej, S.; Maleki Kahaki, M.; Salimi Sartakhti, M.; Joodaki, M. Efficient GAN-based method for extractive summarization. J. Electr. Comput. Eng. Innov. 2022, 10, 287–298. [Google Scholar]
- Moravvej, S.; Kahaki, M.; Sartakhti, M.; Mirzaei, A. A method based on attention mechanism using bidirectional long-short term memory (BLSTM) for question answering. In Proceedings of the 2021 29th Iranian Conference On Electrical Engineering (ICEE), Tehran, Iran, 18–20 May 2021; pp. 460–464. [Google Scholar]
- Moravvej, S.; Alizadehsani, R.; Khanam, S.; Sobhaninia, Z.; Shoeibi, A.; Khozeimeh, F.; Sani, Z.; Tan, R.; Khosravi, A.; Nahavandi, S.; et al. RLMD-PA: A reinforcement learning-based myocarditis diagnosis combined with a population-based algorithm for pretraining weights. Contrast Media Mol. Imaging 2022, 2022, 8733632. [Google Scholar] [CrossRef]
- Danaei, S.; Bostani, A.; Moravvej, S.; Mohammadi, F.; Alizadehsani, R.; Shoeibi, A.; Alinejad-Rokny, H.; Nahavandi, S. Myocarditis Diagnosis: A Method using Mutual Learning-Based ABC and Reinforcement Learning. In Proceedings of the 2022 IEEE 22nd International Symposium on Computational Intelligence and Informatics and 8th IEEE International Conference on Recent Achievements in Mechatronics, Automation, Computer Science and Robotics (CINTI-MACRo), Budapest, Hungary, 21–22 November 2022; pp. 265–270. [Google Scholar]
- Moravvej, S.; Mirzaei, A.; Safayani, M. Biomedical text summarization using conditional generative adversarial network (CGAN). arXiv 2021, arXiv:2110.11870. [Google Scholar]
- Wang, J.; Yu, L.; Lai, K.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2, pp. 225–230. [Google Scholar]
- Ballings, M.; Van den Poel, D.; Hespeels, N.; Gryp, R. Evaluating multiple classifiers for stock price direction prediction. Expert Syst. Appl. 2015, 42, 7046–7056. [Google Scholar] [CrossRef]
- Sharma, N.; Juneja, A. Combining of random forest estimates using LSboost for stock market index prediction. In Proceedings of the 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 1199–1202. [Google Scholar] [CrossRef]
- Picasso, A.; Merello, S.; Ma, Y.; Oneto, L.; Cambria, E. Technical analysis and sentiment embeddings for market trend prediction. Expert Syst. Appl. 2019, 135, 60–70. [Google Scholar] [CrossRef]
- Izzah, A.; Sari, Y.A.; Widyastuti, R.; Cinderatama, T.A. Mobile app for stock prediction using Improved Multiple Linear Regression. In Proceedings of the 2017 International Conference on Sustainable Information Engineering and Technology (SIET), Batu, Indonesia, 24–25 November 2017; pp. 150–154. [Google Scholar]
- Ariyo, A.A.; Adewumi, A.O.; Ayo, C.K. Stock price prediction using the ARIMA model. In Proceedings of the 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, Cambridge, UK, 26–28 March 2014; pp. 106–112. [Google Scholar]
- Ouahilal, M.; El Mohajir, M.; Chahhou, M.; El Mohajir, B.E. Optimizing stock market price prediction using a hybrid approach based on HP filters and support vector regression. In Proceedings of the 2016 4th IEEE International Colloquium on Information Science and Technology (CiSt), Tangier, Morocco, 24–26 October 2016; pp. 290–294. [Google Scholar]
- Krollner, B.; Vanstone, B.J.; Finnie, G.R. Financial time series forecasting with machine learning techniques: A survey. In Proceedings of the 18th European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 28–30 April 2010. [Google Scholar]
- Tollo, G.; Tanev, S.; Liotta, G.; De March, D. Using online textual data, principal component analysis and artificial neural networks to study business and innovation practices in technology-driven firms. Comput. Ind. 2015, 74, 16–28. [Google Scholar] [CrossRef] [Green Version]
- Corazza, M.; De March, D.; Tollo, G. Design of adaptive Elman networks for credit risk assessment. Quant. Financ. 2021, 21, 323–340. [Google Scholar] [CrossRef]
- Moghaddam, A.H.; Moghaddam, M.H.; Esfandyari, M. Stock market index prediction using artificial neural network. J. Econ. Financ. Adm. Sci. 2016, 21, 89–93. [Google Scholar] [CrossRef] [Green Version]
- Arévalo, A.; Niño, J.; Hernández, G.; Sandoval, J. High-frequency trading strategy based on deep neural networks. In Proceedings of the International Conference on Intelligent Computing, Lanzhou, China, 2–5 August 2016; Springer: Cham, Switzerland, 2016; pp. 424–436. [Google Scholar]
- Hoseinzade, E.; Haratizadeh, S. CNNpred: CNN-based stock market prediction using a diverse set of variables. Expert Syst. Appl. 2019, 129, 273–285. [Google Scholar] [CrossRef]
- Gao, P.; Zhang, R.; Yang, X. The application of stock index price prediction with neural networks. Math. Comput. Appl. 2020, 25, 53. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Q.; Huang, Z.; Li, J. EAN: Event attention network for stock price trend prediction based on sentimental embedding. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 311–320. [Google Scholar]
- Moravvej, S.; Mousavirad, S.; Oliva, D.; Mohammadi, F. A Novel Plagiarism Detection Approach Combining BERT-based Word Embedding, Attention-based LSTMs and an Improved Differential Evolution Algorithm. arXiv 2023, arXiv:2305.02374. [Google Scholar]
- Yu, S.; Xia, F.; Li, S.; Hou, M.; Sheng, Q. Spatio-Temporal Graph Learning for Epidemic Prediction. Acm Trans. Intell. Syst. Technol. 2023, 14, 36. [Google Scholar] [CrossRef]
- Nelson, D.M.; Pereira, A.C.; de Oliveira, R.A. Stock market’s price movement prediction with LSTM neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1419–1426. [Google Scholar]
- Ding, G.; Qin, L. Study on the prediction of stock price based on the associated network model of LSTM. Int. J. Mach. Learn. Cybern. 2020, 11, 1307–1317. [Google Scholar] [CrossRef] [Green Version]
- Jin, Z.; Yang, Y.; Liu, Y. Stock closing price prediction based on sentiment analysis and LSTM. Neural Comput. Appl. 2019, 32, 9713–9729. [Google Scholar] [CrossRef]
- Liu, J.; Lin, H.; Yang, L.; Xu, B.; Wen, D. Multi-Element Hierarchical Attention Capsule Network for Stock Prediction. IEEE Access 2020, 8, 143114–143123. [Google Scholar] [CrossRef]
- Baughman, M.; Haas, C.; Wolski, R.; Foster, I.; Chard, K. Predicting Amazon spot prices with LSTM networks. In Proceedings of the 9th Workshop on Scientific Cloud Computing, Tempe, AZ, USA, 11 June 2018; pp. 1–7. [Google Scholar]
- Lin, Y.F.; Huang, T.M.; Chung, W.H.; Ueng, Y.L. Forecasting fluctuations in the financial index using a recurrent neural network based on price features. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 5, 780–791. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhao, J.; Xu, K. Can online emotions predict the stock market in China? In Proceedings of the International Conference on Web Information Systems Engineering, Shanghai, China, 8–10 November 2016; Springer: Cham, Switzerland, 2016; pp. 328–342. [Google Scholar]
- Zhang, X.; Fuehres, H.; Gloor, P.A. Predicting stock market indicators through twitter “I hope it is not as bad as I fear”. Procedia-Soc. Behav. Sci. 2011, 26, 55–62. [Google Scholar] [CrossRef] [Green Version]
- Baker, M.; Wurgler, J. Investor sentiment and the cross-section of stock returns. J. Financ. 2006, 61, 1645–1680. [Google Scholar] [CrossRef] [Green Version]
- Baker, M.; Wurgler, J. Investor sentiment in the stock market. J. Econ. Perspect. 2007, 21, 129–152. [Google Scholar] [CrossRef] [Green Version]
- Gilbert, E.; Karahalios, K. Widespread worry and the stock market. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4. [Google Scholar]
- Guo, Z.; Ye, W.; Yang, J.; Zeng, Y. Financial index time series prediction based on bidirectional two dimensional locality preserving projection. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 934–938. [Google Scholar]
- Zhou, S.; Zhou, L.; Mao, M.; Tai, H.M.; Wan, Y. An optimized heterogeneous structure LSTM network for electricity price forecasting. IEEE Access 2019, 7, 108161–108173. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Awad, M.A. Augmented Textual Features-Based Stock Market Prediction. IEEE Access 2020, 8, 40269–40282. [Google Scholar] [CrossRef]
- Alhamzeh, A.; Mukhopadhaya, S.; Hafid, S.; Bremard, A.; Egyed-Zsigmond, E.; Kosch, H.; Brunie, L. A Hybrid Approach for Stock Market Prediction Using Financial News and Stocktwits. In CLEF 2021: Experimental IR Meets Multilinguality, Multimodality, and Interaction; Lecture Notes in Computer, Science; Candan, K.S., Ionescu, B., Goeuriot, L., Larsen, B., Müller, H., Joly, A., Maistro, M., Piroi, F., Faggioli, G., Ferro, N., Eds.; Springer: Cham, Switzerland, 2021; Volume 12880. [Google Scholar] [CrossRef]
- Bujari, A.; Furini, M.; Laina, N. On using cashtags to predict companies stock trends. In Proceedings of the 2017 14th IEEE Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2017; pp. 25–28. [Google Scholar]
- Pegah, E.; Mehdi, S.; Ahmad, N. U2VDow30: Dow 30 Stocks tweets for proposing User2Vec approach. Mendeley Data 2022. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP), Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Tang, D.; Wei, F.; Yang, Y.; Zhou, M.; Liu, T.; Qin, B. Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification. In Proceedings of the 52th ACL Conference, Baltimore, Maryland, 22–27 June 2014. [Google Scholar]
- Bengio, Y. Learning Deep Architectures for AI; Now Publishers Inc.: Delft, The Netherlands, 2009. [Google Scholar]
- Mehta, P.; Pandya, S.; Kotecha, K. Harvesting social media sentiment analysis to enhance stock market prediction using deep learning. PeerJ Comput. Sci. 2021, 7, e476. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Chen, Y.; Zhang, S.; Zhang, Q. Stock market index prediction using deep Transformer model. Expert Syst. Appl. 2022, 208, 118128. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, Z.; Li, F.; Ho, S.; Cambria, E. Learning-based stock trending prediction by incorporating technical indicators and social media sentiment. Cogn. Comput. 2023, 15, 1092–1102. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, S. A Novel Stock Index Direction Prediction Based on Dual Classifier Coupling and Investor Sentiment Analysis. Cogn. Comput. 2023, 15, 1023–1041. [Google Scholar] [CrossRef]
- Ammirato, S.; Fattoruso, G.; Violi, A. Parsimonious AHP-DEA Integrated Approach for Efficiency Evaluation of Production Processes. J. Risk Financ. Manag. 2022, 15, 293. [Google Scholar] [CrossRef]
- Fattoruso, G.; Barbati, M.; Ishizaka, A.; Squillante, M. A hybrid AHPSort II and multi-objective portfolio selection method to support quality control in the automotive industry. J. Oper. Res. Soc. 2022, 74, 209–224. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Open | High | Low | Close | Adj Close | Volume | Label |
|---|---|---|---|---|---|---|---|
| 1/8/2018 | 174.35 | 175.61 | 173.93 | 174.3 | 171.03 | 20,567,800 | 0 |
| 1/9/2018 | 174.55 | 175.06 | 173.41 | 174.3 | 171.01 | 21,584,000 | 0 |
| 1/10/2018 | 173.16 | 174.3 | 173 | 174.2 | 170.97 | 23,959,900 | 1 |
| 1/11/2018 | 174.59 | 175.49 | 174.49 | 175.2 | 171.95 | 18,667,700 | 1 |
| Hashtag | #Tweets | #Positive Tweets | #Negative Tweets | #Unique User-ID |
|---|---|---|---|---|
| AAPL | 417,334 | 366,080 | 51,254 | 63,355 |
| AXP | 9569 | 2873 | 1674 | 163 |
| BA | 66,637 | 24,481 | 10,484 | 641 |
| CAT | 41,543 | 13,193 | 7403 | 3380 |
| CSCO | 7093 | 2919 | 841 | 187 |
| CVX | 15,214 | 6322 | 1739 | 40 |
| DIS | 153,032 | 54,067 | 18,651 | 877 |
| DOW | 14,697 | 237 | 125 | 285 |
| GS | 59,401 | 26,514 | 9042 | 182 |
| HD | 62,497 | 21,553 | 7139 | 123 |
| IBM | 62,871 | 19,898 | 7394 | 10,440 |
| INTC | 36,816 | 14,394 | 5166 | 551 |
| JNJ | 42,045 | 14,656 | 5975 | 448 |
| JPM | 10,614 | 3817 | 1492 | 99 |
| KO | 16,444 | 5756 | 2273 | 17 |
| MCD | 68,810 | 23,163 | 8199 | 218 |
| MMM | 11,301 | 3500 | 2355 | 47 |
| MRK | 19,687 | 7610 | 2202 | 132 |
| MSFT | 156,643 | 81,402 | 13,081 | 979 |
| NKE | 50,659 | 17,551 | 6653 | 946 |
| PFE | 74,733 | 26,829 | 7601 | 151 |
| PG | 53,866 | 18,803 | 5635 | 193 |
| TRV | 4451 | 1344 | 505 | 318 |
| UNH | 15,576 | 5574 | 2280 | 80 |
| UTX | 9977 | 3085 | 1323 | 267 |
| V | 34,638 | 12,492 | 5144 | 163 |
| VZ | 18,913 | 7028 | 2513 | 116 |
| WBA | 29,835 | 8002 | 339 | 256 |
| WMT | 13,268 | 5275 | 1706 | 313 |
| XOM | 23,439 | 8153 | 3558 | 250 |
| Model | Parameter | Value |
|---|---|---|
| CNN | filter size | 50 |
| kernel size | 1 | |
| activation function | relu | |
| LSTM | unit size | 20 |
| Proposed | batch size | 128 |
| learning rate | 0.01 | |
| optimizer | Adam | |
| loss function | mean absolute error | |
| epoch | 700 |
| Model | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Rand | 0.4623 ± 0.0055 | 0.5645 ± 0.0047 | 0.6412 ± 0.0061 | 0.5012 ± 0.0070 |
| Arima(M) | 0.5105 ± 0.0035 | 0.5955 ± 0.0033 | 0.7022 ± 0.0050 | 0.5345 ± 0.0063 |
| SBiLSTM-Day2Vec(M,Se) | 0.6255 ± 0.0042 | 0.6245 ± 0.0039 | 0.9602 ± 0.0022 | 0.7523 ± 0.0028 |
| User2Vec(M,Se) | 0.7140 ± 0.0030 | 0.6902 ± 0.0031 | 0.9015 ± 0.0023 | 0.7812 ± 0.0025 |
| User2Vec(Txt) | 0.6815 ± 0.0037 | 0.7241 ± 0.0033 | 0.7255 ± 0.0034 | 0.7210 ± 0.0035 |
| User2Vec(Txt,M,Se) | 0.7444 ± 0.0027 | 0.7212 ± 0.0032 | 0.9045 ± 0.0021 | 0.8019 ± 0.0024 |
| User2Vec(Txt,M,Se,So) | 0.7810 ± 0.0025 | 0.7845 ± 0.0024 | 0.8615 ± 0.0026 | 0.8245 ± 0.0023 |
| User2Vec(M,Se,So) | 0.7242 ± 0.0031 | 0.7200 ± 0.0032 | 0.8242 ± 0.0028 | 0.7712 ± 0.0027 |
| User2Vec(Txt,M,Se,Sc) | 0.7344 ± 0.0030 | 0.7314 ± 0.0032 | 0.8300 ± 0.0027 | 0.7842 ± 0.0026 |
| User2Vec(Txt,M,Se,So,Sc) | 0.7514 ± 0.0029 | 0.8100 ± 0.0023 | 0.7311 ± 0.0031 | 0.7710 ± 0.0027 |
| Stock | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Apple | 0.7410 ± 0.0015 | 0.7443 ± 0.0023 | 0.7546 ± 0.0021 | 0.7494 ± 0.0018 |
| CAT | 0.6358 ± 0.0034 | 0.6614 ± 0.0036 | 0.6728 ± 0.0031 | 0.6670 ± 0.0033 |
| CSCO | 0.7143 ± 0.0027 | 0.7059 ± 0.0025 | 0.7301 ± 0.0028 | 0.7177 ± 0.0026 |
| CVX | 0.6351 ± 0.0033 | 0.6406 ± 0.0037 | 0.6601 ± 0.0035 | 0.6502 ± 0.0036 |
| GS | 0.5682 ± 0.0042 | 0.5816 ± 0.0043 | 0.6012 ± 0.0041 | 0.5911 ± 0.0042 |
| IBM | 0.5987 ± 0.0038 | 0.6027 ± 0.0039 | 0.6128 ± 0.0037 | 0.6077 ± 0.0038 |
| JNJ | 0.6214 ± 0.0035 | 0.6137 ± 0.0037 | 0.6208 ± 0.0036 | 0.6170 ± 0.0037 |
| JPM | 0.7273 ± 0.0022 | 0.7143 ± 0.0024 | 0.8333 ± 0.0023 | 0.7692 ± 0.0025 |
| MCD | 0.6182 ± 0.0036 | 0.6363 ± 0.0037 | 0.6423 ± 0.0038 | 0.6392 ± 0.0037 |
| MSFT | 0.6605 ± 0.0033 | 0.7046 ± 0.0034 | 0.7911 ± 0.0032 | 0.7452 ± 0.0035 |
| KO | 0.6061 ± 0.0039 | 0.6230 ± 0.0041 | 0.6545 ± 0.0040 | 0.6381 ± 0.0042 |
| Work | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Sharma et al. [43] | 0.5201 ± 0.0035 | 0.5404 ± 0.0037 | 0.5302 ± 0.0039 | 0.5335 ± 0.0038 |
| Jin et al. [60] | 0.5523 ± 0.0031 | 0.5644 ± 0.0030 | 0.5801 ± 0.0032 | 0.5721 ± 0.0031 |
| Liu et al. [61] | 0.5804 ± 0.0029 | 0.5909 ± 0.0028 | 0.6050 ± 0.0030 | 0.5979 ± 0.0029 |
| Bouktif et al. [71] | 0.6003 ± 0.0027 | 0.6110 ± 0.0026 | 0.6251 ± 0.0028 | 0.6180 ± 0.0027 |
| Mehta et al. [79] | 0.6250 ± 0.0024 | 0.6355 ± 0.0023 | 0.6485 ± 0.0025 | 0.6359 ± 0.0024 |
| Wang C et al. [80] | 0.6455 ± 0.0022 | 0.6563 ± 0.0021 | 0.6688 ± 0.0023 | 0.6525 ± 0.0022 |
| Wang Z et al. [81] | 0.6650 ± 0.0020 | 0.6661 ± 0.0019 | 0.6880 ± 0.0021 | 0.6720 ± 0.0020 |
| Wang J et al. [82] | 0.6800 ± 0.0019 | 0.6913 ± 0.0018 | 0.7132 ± 0.0020 | 0.7072 ± 0.0019 |
| Proposed with Transformer | 0.7051 ± 0.0017 | 0.7269 ± 0.0012 | 0.7483 ± 0.0018 | 0.7324 ± 0.0017 |
| Proposed | 0.7661 ± 0.0016 | 0.7667 ± 0.0014 | 0.7878 ± 0.0018 | 0.7722 ± 0.0018 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eslamieh, P.; Shajari, M.; Nickabadi, A. User2Vec: A Novel Representation for the Information of the Social Networks for Stock Market Prediction Using Convolutional and Recurrent Neural Networks. Mathematics 2023, 11, 2950. https://doi.org/10.3390/math11132950
Eslamieh P, Shajari M, Nickabadi A. User2Vec: A Novel Representation for the Information of the Social Networks for Stock Market Prediction Using Convolutional and Recurrent Neural Networks. Mathematics. 2023; 11(13):2950. https://doi.org/10.3390/math11132950
Chicago/Turabian StyleEslamieh, Pegah, Mehdi Shajari, and Ahmad Nickabadi. 2023. "User2Vec: A Novel Representation for the Information of the Social Networks for Stock Market Prediction Using Convolutional and Recurrent Neural Networks" Mathematics 11, no. 13: 2950. https://doi.org/10.3390/math11132950