
A Study to Identify Long-Term Care Insurance Using Advanced Intelligent RST Hybrid Models with Two-Stage Performance Evaluation


Abstract
:1. Introduction
1.1. Research Background, Research Problems, and Research Motivation
1.2. Continuous Research Motivation and Research Originality
1.3. Research Importance and the Purposes of Research
2. Literature Review
2.1. LTCI and Its Related Application Issues for Developing Potential Customers
2.2. Feature Selection and Its Related Application
2.3. Data Discretization and Its Related Application
2.4. Research on Decision Tree Learning Classifier and Its Related Application
2.5. Research on Rough Set Theory and Its Related Applications
2.6. Rule Filtering Method
2.7. Other Well-Known Classifier Techniques and Related Application Areas
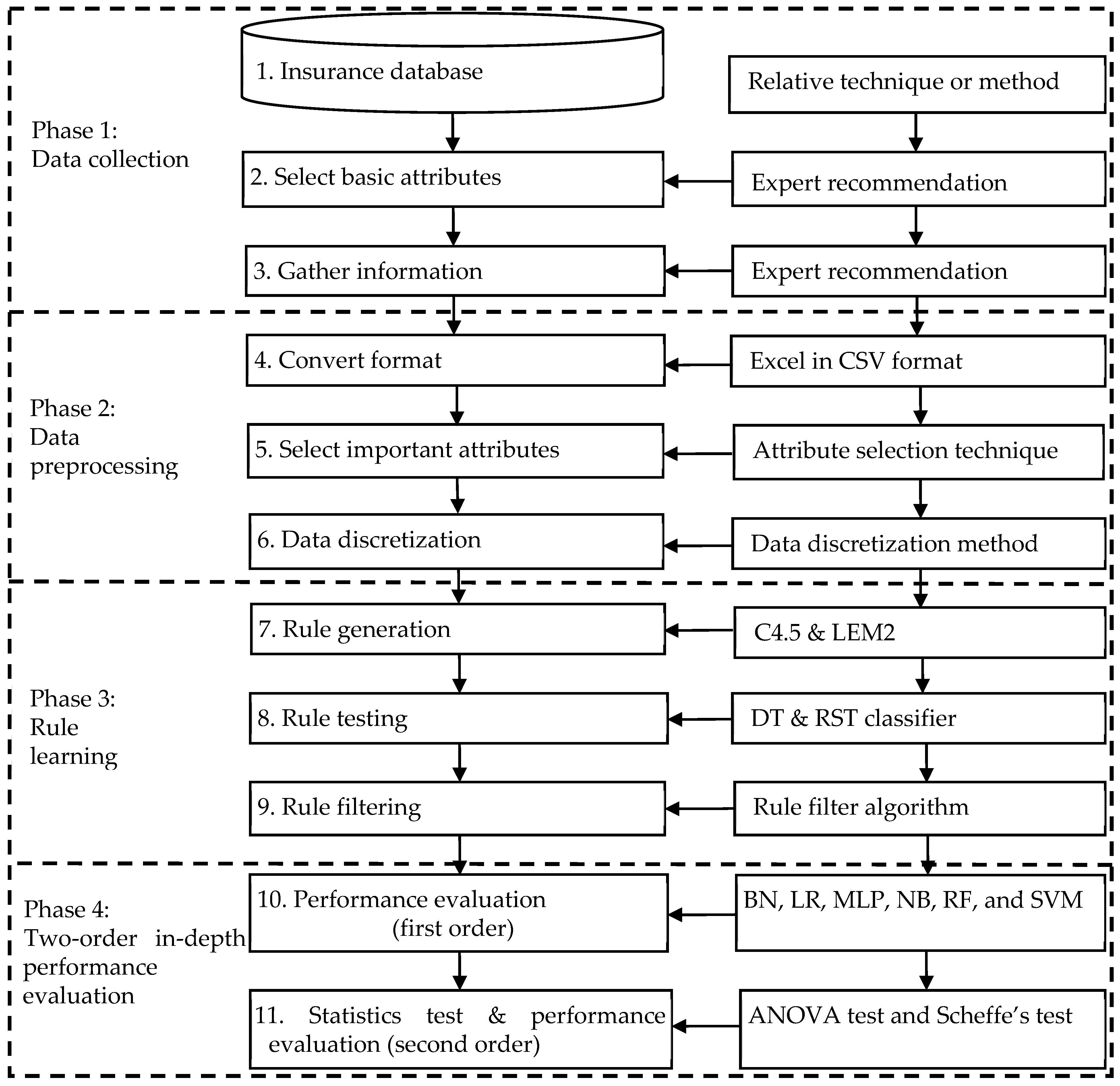
3. The Proposed AIHLCIM
3.1. Reasons for Using the Proposed Models
3.2. The Proposed Models Used
- (1)
- Data collection phase: This consists of three sub-steps: (a) selection of insurance-source databases, (b) selection of basic attributes, and (c) collection of data. The key point is to first select the possible initial basic condition attributes through the relevant insurance and financially experienced knowledge of experts, then select the used condition attributes based on the relevant LTCI literature. Accordingly, supplemented by insurance experts’ knowledge of the unique characteristics of Taiwan’s insurance industry and LTCI experience, some conditional attributes are also selected; the sum of the above attributes is for all conditional attributes. Finally, the relevant attribute data are collected.
- (2)
- The data preprocessing phase: This includes three sub-steps: (a) format conversion, (b) selection of important attributes, and (c) data discretization. The key direction of this phase is to apply the necessary preprocessing procedures to the collected data, including (a) first removing multiple incorrect or noisy observations that may have arisen, (b) removing possible outlier examples, (c) converting the collected data set into the necessary format for the experiment, such as an EXCEL .csv file, to facilitate subsequent experimental operations, and (d) making a simple data normalization technique used for modeling all the ML-based methods for the benefits of a uniform format, good for follow-up experiments; then, attribute selection technology are used to remove irrelevant or redundant condition attributes. In order to further obtain the effective combination of important attributes, it is beneficial to reduce the complexity of the model (that is, reduce the data dimensions) and improve the predictive ability. Finally, the data discretization technique is applied to the numerical (digital) data of the key influencing condition attributes on the LTCI after the attributes are selected; the automatic discretization method is used to cut the individual attribute data into different interval values to leverage human natural language expressions (e.g., small, medium, and large) and enhance classifier performance.
- (3)
- The rule learning phase: This also consists of three sub-steps: (a) rule generation, (b) rule testing, and (c) rule filtering. Key tasks at this stage include first executing the extraction decision rule algorithm (such as C4.5 or LEM2), executing rule testing, and then performing the filtering decision rule work (only LEM2 requires it, because C4.5 has the rule prune function). The main detailed tasks are to discretize the numerical data of the selected important condition attributes, add whether the decision attribute is LTCI (coded Y: yes and N: no), and then put all the attribute data into DT and RST classifiers according to three types of data partitioning: 66% for training and 34% for testing (i.e., about 2:1), 75%/25% (3:1), and 80%/20% (4:1) sub-sets. The combined data are randomly disassembled, and the C4.5 and LEM2 algorithms are accordingly executed to generate rules. A meaningful decision rule set is thus extracted; concurrently, the number of rules of a set generated by the testing is obtained with the initial classification accuracy. Finally, the support threshold for LEM2 is separately set, the decision rules with too-low support are filtered out, and the disadvantage of too many rules in the rough set is overcome, thereby reducing the complexity of the decision rules and improving the classification quality.
- (4)
- The performance evaluation phase: This majorly includes two sub-steps: (a) the first stage involves a performance evaluation and (b) the second stage involves post-event statistical verification. The focus of the first stage is to randomly divide the experimental data set into the same proportion again, 66% as the training data sub-set and the remaining 34% as the testing data sub-set, so as to test the performance of the AIHLCIM and compare it with other different ML techniques. The comparison benchmarks are as follows: (a) internal comparison (for Models A-P, 16 models), (b) single model and intelligent hybrid model comparison (comparison of Models A-L vs. M-P), and (c) external comparison (comparison of optimal Models A-L vs. M-P accuracy rate). Following this, model performance is analyzed according to internal comparison, single model and intelligent hybrid model comparison, and external comparison according to self-defined evaluation criteria: (d) performance comparisons of the rough set and decision tree for properties such as accuracy rate, and (e) performance comparison of C4.5 and LEM2 for rule induction. The second stage involves (a) a one-way ANOVA analysis of variance and (b) a post hoc test of Schaeffer’s method to understand the empirical results of significant differences in the accuracy of the methods and the degree of difference between their groups. Afterwards, the results of differences are analyzed and the reasons are discussed, conclusions are made from the results, and the possible implications and possible major findings of the experimental results in terms practical management for the insurance industry are explained.
3.2.1. Phase 1: Data Collection
- Step 1. Select the insurance database
- Step 2. Select basic attributes
- Step 3. Collect data
3.2.2. Phase 2: Data Preprocessing
- Step 4. Format conversion
- Step 5. Select important attributes
- Step 6. Perform data discretization
- Step 6-1. Execute expert discretization
- Step 6-2. Execute automatic discretization
3.2.3. Phase 3: Rule Learning
- Step 7. Rule generation
- Step 8. Rule testing
- Step 9. Rule filtering
3.2.4. Phase 4: Two-Order in-Depth Performance Evaluation
- Step 10. The first-order performance evaluation
- Step 11. The second-order statistical test
4. Empirical Results of a Case Study
4.1. Empirical Results
- (1)
- For descriptive statistics: First, a descriptive statistic is a means of quantitatively describing the basic feature information of a given data set by generating summaries about the sample of data; thus, they can provide enough summaries about statistical information from the sample and the measures. Based on the collected data from the LTCI data set, the descriptive statistics were divided into two tabulated forms of information, including nominal data in Table 3 and numerical data in Table 4. From Table 3 and Table 4, it is clear that C1–C11 and D1 are nominal data of attributes, and C12–C19 belong to the numerical data of conditional attributes. D1 has 167 records coded “Y” (Yes, referring to having LTCI) and 340 records coded “N”. As for Table 4, it is observed that the minimum value, maximum value, mean value, and standard deviation were determined for the numerical attributes C12–C19.
- (2)
- For implementing results of feature selection: In this study, some feature selections were used for finding out important attributes in order to benefit experiment operation. There are two ways to be addressed in this step. (1) First, the CFS (correlation-based feature selection) subset evaluator method can be used to measure the worth of subsets of features that have high correlation with the class and consider the individual predictive ability of each feature for working well together, along with the degree of redundancy between attributes; thus, CFS and DT were used and implemented for selecting important attributes in this study. Table 5 lists the results of feature selection methods for implementing CFS and DT. From Table 5, it is clear that attributes C12, C17, and C19 are really key important features of decision attributes (with/without LTCI) based on the two feature selection techniques. (2) Second, three attribute evaluator methods were also used for another measurement, including the gain ratio feature evaluator, information gain ranking filter, and OneR feature evaluator, for evaluating attributes in ranking. Table 6 lists the comparison information for the results of these three similar feature selection methods, gain ratio, information gain, and OneR, in ranking the importance of attributes. Importantly, for the gain ratio and information gain methods, the threshold was o.1; thus, the attributes C19 (0.193918), C17 (0.193723), C12 (0.121827), and C15 (0.114906) were identified using gain ratio, and for information gain, the attributes C19 (0.347007), C17 (0.151519), C13 (0.127195), and C12 (0.124875) were identified. However, for the OneR method, the threshold was 70, and thus the attributes C19 (79.4872), C17 (75.5424), C12 (72.5838), C13 (71.7949), C14 (71.2032), and C18 (70.6114) were also determined. It is very clear that the important attributes are C19, C17, and C12 because they have common intersection.
- (3)
- For running results of automatic data discretization: The data discretization technique is used to discretize the numerical data of attributes for creating comprehensible semantic values in natural language. The semantic value has the meaning of an expression, which refers to expressing the result of a division into linguistically similar word types and deals directly with values for the subsequent attribution of possible objects. Thus, this step of data discretization involves the performance of an automation data discretization technique, and the implementing results are described in Table 7. For example, there are three semantic alternatives of levels for low, medium, and high values of natural language for C12 and two semantic alternatives for low and high values of natural language for C14. This effective function can yield an outcome of better classification accuracy and benefit its classification advantage.
- (4)
- Comparative study: There were seven parts to the comparison studies.
- (a)
- Model comparison: Regarding model comparison, a total of 16 models were compared each other, and Table 8 lists their comparison results in classification accuracy under three different ratios of data partitioning. From Table 8, it is clear that based on the average accuracy, Model H > G > I > E > L > M > J > A > B > K > F > C, D > P > O > N, and the top three accuracies are H➔G➔I. The Models H and G belong to the RST classifier; thus, it is very clear that the RST classifier has the best average accuracy of the combinations of the three ratios (66%/34%, 75%/25%, and 80%/20%) of data partitioning in the proposed AIHLCIM for the LTCI data set.
- (b)
- Classifier comparison: For a fair basis of comparison, all the eight classifiers used in this study were compared without the feature selection and data discretization methods. The experiments for the eight classifiers were run with the three different ratios again. Table 9 shows the comparison results. As a result, the top three average accuracies are DT, RST, and RF for sequential expression. From Table 9, the best classifier was selected from the eight pure classifiers, that being that which has the better accuracy in the same ratio of data partitioning for the LTCI data set. It is clear that DT has the best value (91.09%) in terms of classification accuracy in the ratio of 80%/20%.
- (c)
- Component comparison with feature selection and data discretization: Similarly, the above eight classifiers were compared under the condition of having both feature selection and data discretization methods for the purpose of component comparison. Thus, the experiments were run with three different ratios once more. Table 10 shows the comparison results, and the top three average accuracies are MLP, RF, and DT for sequential expression. From Table 10, the best classifier was selected from the eight classifiers under the condition of both components, that being that which has the better accuracy in the same ratio of data partitioning for the LTCI data set. It is clear that RST (no filter) has the best value (88.10%) for all the classification accuracies in the ratio of 80%/20%.
- (d)
- Component comparison only with feature selection: The above eight classifiers were compared again within the condition of only having the feature selection method for the same purpose of component comparison. The experiments were also run with the same ratios mentioned above once again. Table 11 lists the comparison results. As predicted, the top three average accuracies are RST (no filter), RF, and DT in sequential expression. From Table 11, the best classifier was selected from the eight classifiers under the condition of implementing feature selection, that being that which has the better accuracy in the same ratio of data partitioning for the LTCI data set. It is clear that RST has the best value (96.60%) of all the classification accuracies in the ratio of 66%/34%.
- (e)
- Component comparison only with data discretization: Similarly, the above eight classifiers were compared again in the condition of only having the data discretization technique for the purpose of component comparison. These experiments were also run with the same three ratios mentioned above. Table 12 shows their comparison results. Consequently, the top three average accuracies are LR, RF, and SVM in ranking order. From Table 12, the best classifier was also selected from the eight classifiers under the condition of implementing data discretization, that being that which has the best accuracy in the same ratio of data partitioning for the LTCI data set. It is clear that RF has the best value (94.06%) across all the classification accuracies in the ratio of 80%/20%.
- (f)
- Model comparison in 10 times: For a fair base of comparison, all the eight pure classifiers used were compared without both the feature selection and data discretization methods in 66%/34% for 10 times. The experiments were repeatedly run with a same ratio for 10 times. Table 13 lists their comparison results. As a result, the top three average accuracies in 10 runs were DT, RF, and LR for sequential expression. From Table 13, the best classifier was selected from the eight pure classifiers, that being that which has the best accuracy in the partitioning ratio 66%/34% of data for the LTCI data set. In general, it is clear that DT wins the best role in terms of average classification accuracy, but for standard deviation, the top three standard deviations (stability) in 10 runs are NB, MLP, and RF.
- (g)
- Filter comparison of RST for accuracy, total coverage, and rule numbers with standard deviation: For further exploring the RST classifier, the experiments were defined with/without filter in terms of average classification accuracy, total coverage, and rule numbers with their standard deviation in 66%/34% across 10 times repeatedly for the LTCI data set. Table 14 shows these comparison results for RST. From Table 14, for the comparison of with/without filter, it is clear that the average accuracy rate (72.67 vs. 73.87), total coverage (0.43 vs. 0.40), and rule numbers (105.0 vs. 71.3) have a better outcome after performing the rule filtering technique; concurrently, most of the standard deviations also have more stable outcomes. These facts imply that the rule filtering technique is an effective method for the RST classifier. This case makes a verification and validation of the result from the literature review.
- (5)
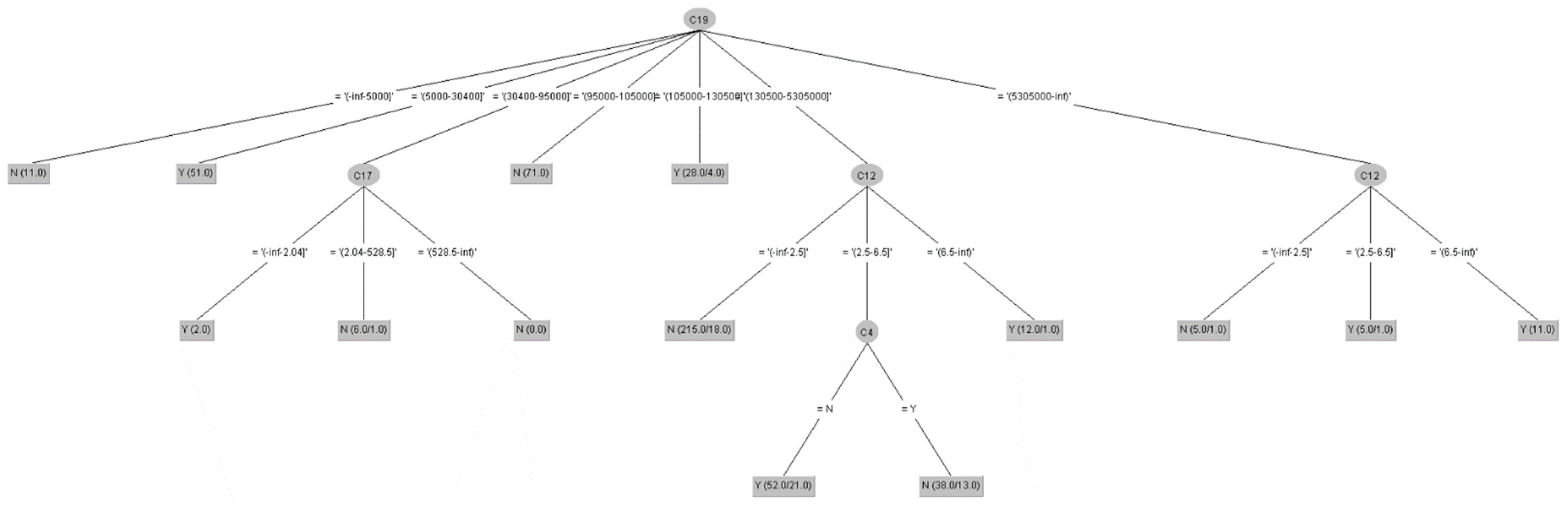
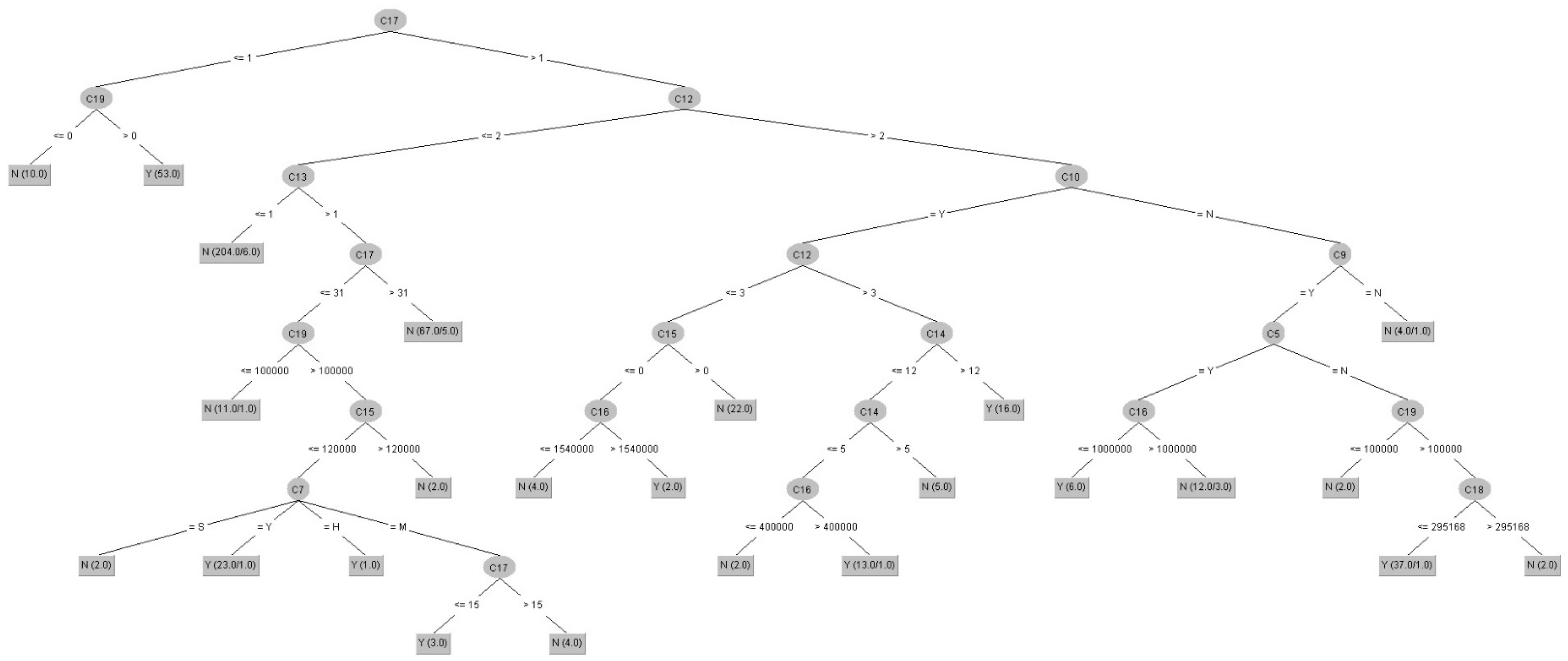
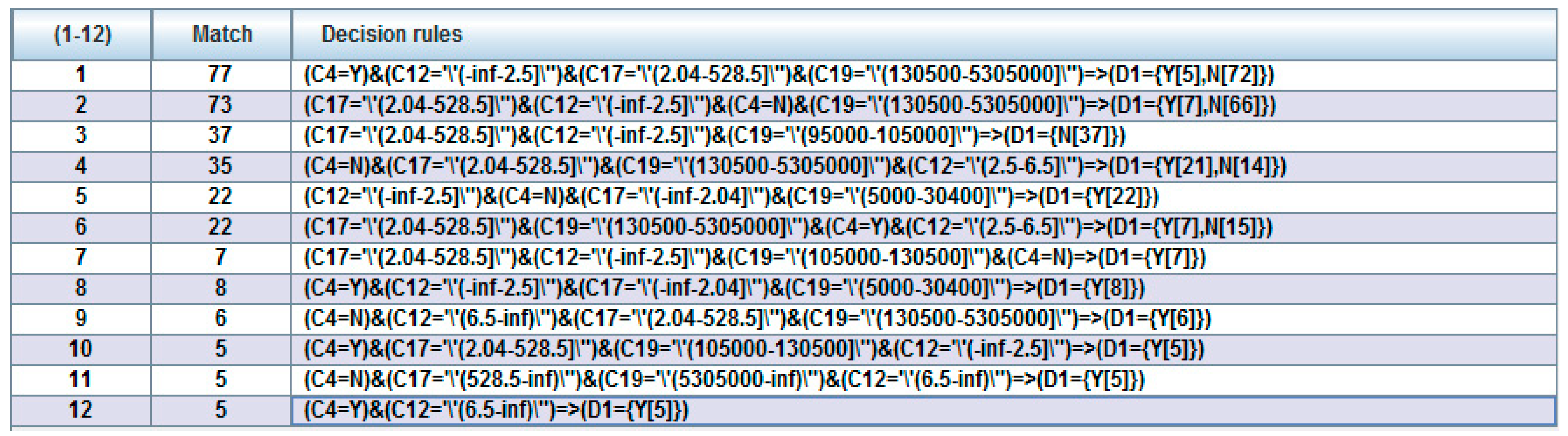
- For induced results of decision rules on a set: In this component, there were two rule induction algorithms used, DT-C4.5 and LEM2. The rule induction method is a function of machine learning fields in which a formal decision rule set is extracted to represent a full scientific model of the given data from a set of observations. Thus, the DT-C4.5 and LEM2 induction algorithms were used to extract the decision rules set for identifying the decision features of LTCI. (1) First, two types of DT algorithms were induced and figured, including a DT-C4.5 rules set in a ratio of 66%/34% after implementing feature selection and data discretization techniques and a same ratio and one without feature selection and data discretization techniques. Table 7 displays the former rule results and Table 8 lists the latter results. For an example of rule expression, if C19 = (30400~95000] and C17 = (-inf~2.04], then Class = Y (i.e., with a LTCI). (2) Second, the RS-LEM2 algorithm was used to generate a rule set upon which was performed feature selection and data discretization techniques. In total, there were only 12 rules in the set created for extracting a decision-making knowledge base for future references and uses. Take Rule 12 as a case: If C4 = Y and C12 = (6.5~inf), then D1 (i.e., Class) = Y (i.e., with a LTCI).
- (6)
- For in-depth performance evaluation of statistical tests: Accordingly, second-order in-depth performance evaluation methods for difference tests, one-way ANOVA and Scheffe’s post hoc tests, were used in this step for further validating the classifier performance in different partition ratios. First, the one-way ANOVA test was used to measure and investigate whether there is a statistically significant difference at the 95% confidence level between the means of more than two groups to one independent factor and one dependent factor. Second, a Scheffé test is a post hoc statistical analysis of a class used for multiple comparisons between group means to determine where a significant result exists if the F value reaches a significant level. Thus, in order to further measure the eight classifiers (for ease of presentation, BN, LR, MLP, NB, RF, SVM, DT, and RST (no filter) are coded using the numbers 1–8, respectively), each classifier was repeatedly run 10 times in the 70%/30% data ratio again, and 10 samples were obtained. The results of the one-way ANOVA for the accuracy are at a confidence level of 0.95. As a result, they significantly differ, which refers to having a significant difference in their classification accuracy rate. It is presented that three groups were identified: 7, 5, 2 > 1, 6 > 8, 4, 3; that is, DT, RF, and LR > BN and SVM > RST, NB, and MLP, for the result of Scheffe’s test. No significant difference was defined in the three groups: (a) DT, RF, and LR, (b) BN and SVM, and (c) RST, NB, and MLP.
- (7)
- Further verifying a trade-off relationship: For further reviewing the RST classifier, this step re-verifies the trade-off relationship under coverages 0.9 and 0.8 among the accuracy rate, total coverage, and number of rules for executing a sensitivity analysis of RST models in three different ratios (66%/34%, 75%/25%, and 80%/20%). Table 15 shows the results comparison. From Table 15, it is clear that in coverage 0.9, the accuracy rate, total coverage, and number of rules are higher values than those of coverage 0.8. Thus, there exists a trade-off relationship between coverages 0.9 and 0.8 in this study issue data for the RST classifier.
4.2. Discussion
5. Findings and Limitations of Research Results
5.1. Research Findings
- (1)
- (2)
- For the key important attributes, C19, C17, and C12, they are discretized in three, three, and seven semantic values from Table 7, which can be represented as (low, medium, and high), (low, medium, and high), and (very low, low, low medium, medium, high-medium, high, very high) in natural language, respectively, which can improve the model performance.
- (3)
- The DT and RST classifiers are focused on the proposed AIHLCIM, and it was found that the DT classifier has better classification accuracy than RST for the LTCI issue.
- (4)
- Comprehensible knowledge-based decision rules of a set were generated, which can be used as an effective reference for identifying and tracing future LTCI issues.
- (5)
- The accuracy of the proposed AIHLCIMs are all above 85% in average accuracy from Table 8, and this is an acceptable prediction accuracy rate for a variety of industry data analyses.
- (6)
- It was also found that attribute selection and data discretization methods have better classification results than that of single methods when they are used together.
5.2. Research limitations
6. Conclusions
6.1. Conclusions of the Study Results
- (1)
- The hybrid model creates better performance than that of the single model in LTCI data for improving classification accuracy.
- (2)
- (3)
- The feature selection and data discretization techniques have better performance for most of the models used in the study towards the studied issue.
- (4)
- Data discretization techniques can create understandable knowledge for human natural semantic representation of values, which is very helpful to the interested parties. See Table 7.
- (5)
- The generation of knowledge-based decision rules of a set, such as Figure 2, Figure 3 and Figure 4, using DT and RST is easy to understand and can be applied to LTCI practices to help insurers identify new potential customers and create a good situation for insurance companies to promote business operation.
- (6)
- (7)
- The better classifiers and the less accurate classifiers were identified by the conducted experiments across 1 run and 10 runs, respectively.
- (8)
- From Table 14, it is implied that the rule filtering technique is an effective method for the RST classifier to improve classification accuracy and model stability and lower the total rule numbers generated.
- (9)
- The significant difference of eight classifiers was determined, and the group difference was also identified.
- (10)
- From Table 15, the trade-off relationship exactly exists between the accuracy rate, total coverage, and number of rules for the RST model in the three ratios (66%/34%, 75%/25%, and 80%/20%) when comparing coverage 0.9 with coverage 0.8.
6.2. Contributions of the Study
6.3. Subsequent Studies
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Lemke, H.U. Moving from data, information, knowledge and models to wisdom-based decision making in the domain of Computer Assisted Radiology and Surgery (CARS). Int. J. Comput. Assist. Radiol. Surg. 2022, 17, 1513–1517. [Google Scholar] [CrossRef] [PubMed]
- van Wees, M.; Duijs, S.E.; Mazurel, C.; Abma, T.A.; Verdonk, P. Negotiating masculinities at the expense of health: A qualitative study on men working in long-term care in the Netherlands, from an intersectional perspective. Gend. Work. Organ. 2023, 1–19. [Google Scholar] [CrossRef]
- Ngally, P. The Role of CHF-IMIS in health insurance scheme: A digital solution for enhancing penetration of health insurance coverage in Tanzania. Tanzan. J. Health Res. 2022, 23, 134–135. [Google Scholar]
- McKenzie, K.; Smith-Merry, J. Responding to complexity in the context of the national disability insurance scheme. Soc. Policy Soc. 2023, 22, 139–154. [Google Scholar] [CrossRef]
- Asadi, M.J.; Shabanlou, S.; Najarchi, M.; Najafizadeh, M.M. A hybrid intelligent model and computational fluid dynamics to simulate discharge coefficient of circular side orifices. Iran. J. Sci. Technol. Trans. Civ. Eng. 2021, 45, 985–1010. [Google Scholar] [CrossRef]
- Kojima, T.; Hamaya, H.; Ishii, S.; Hattori, Y.; Akishita, M. Association of disability level with polypharmacy and potentially inappropriate medication in community dwelling older people. Arch. Gerontol. Geriatr. 2023, 106, 104873. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, L.; Xu, X. Review of evolution of the public long-term care insurance (LTCI) system in different countries: Influence and challenge. BMC Health Serv. Res. 2020, 20, 1057. [Google Scholar] [CrossRef]
- Feng, Z.L.; Glinskaya, E.; Chen, H.T.; Gong, S.; Qiu, Y.; Xu, J.M.; Yip, W.N. Long-term care system for older adults in China: Policy landscape, challenges, and future prospects. Lancet 2020, 396, 1362–1372. [Google Scholar] [CrossRef]
- Dominguez, R.; Cannella, S.; Ponte, B.; Framinan, J.M. On the dynamics of closed-loop supply chains under remanufacturing lead time variability. OMEGA-Int. J. Manag. Sci. 2020, 97, 102106. [Google Scholar] [CrossRef]
- Pätäri, E.; Karell, V.; Luukka, P.; Yeomans, J.S. Comparison of the multicriteria decision-making methods for equity portfolio selection: The U.S. evidence. Eur. J. Oper. Res. 2018, 265, 655–672. [Google Scholar] [CrossRef]
- Fung, D.W.; Wei, P.; Yang, C.C. State subsidized reinsurance programs: Impacts on efficiency, premiums, and expenses of the US health insurance markets. Eur. J. Oper. Res. 2023, 306, 941–954. [Google Scholar] [CrossRef]
- del Val, E.B.; Claramunt Bielsa, M.M.; Varea Soler, X. Role of private long-term care insurance in financial sustainability for an aging society. Sustainability 2020, 12, 8894. [Google Scholar] [CrossRef]
- Jiang, D.; Tu, G.; Jin, D.; Wu, K.; Liu, C.; Zheng, L.; Zhou, T. A hybrid intelligent model for acute hypotensive episode prediction with large-scale data. Inf. Sci. 2021, 546, 787–802. [Google Scholar] [CrossRef]
- Klinkel, S.; Chen, L.; Dornisch, W. A NURBS based hybrid collocation-Galerkin method for the analysis of boundary represented solids. Comput. Methods Appl. Mech. Eng. 2015, 284, 689–711. [Google Scholar] [CrossRef]
- Ravi Kumar, P.; Ravi, V. Bankruptcy prediction in banks and firms via statistical and intelligent techniques—A review. Eur. J. Oper. Res. 2007, 180, 1–28. [Google Scholar] [CrossRef]
- Baracchini, T.; Hummel, S.; Verlaan, M.; Cimatoribus, A.; Wuest, A.; Bouffard, D. An automated calibration framework and open source tools for 3D lake hydrodynamic models. Environ. Model. Softw. 2020, 134, 104787. [Google Scholar] [CrossRef]
- Ouyang, R.L.; Chou, C.A. Integrated optimization model and algorithm for pattern generation and selection in logical analysis of data. Environ. Model. Softw. 2020, 134, 104787. [Google Scholar] [CrossRef]
- Zhao, X.; Wu, L. Classification and pruning strategy of knowledge data decision tree based on rough set. In Data Processing Techniques and Applications for Cyber-Physical Systems (DPTA 2019); Advances in Intelligent Systems and Computing; Huang, C., Chan, Y.W., Yen, N., Eds.; Springer: Singapore, 2020; Volume 1088. [Google Scholar] [CrossRef]
- Gao, L.Y.; Wu, W.G. Relevance assignation feature selection method based on mutual information for machine learning. Knowl.-Based Syst. 2020, 209, 106439. [Google Scholar] [CrossRef]
- Solorio-Fernández, S.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A. A supervised filter feature selection method for mixed data based on spectral feature selection and information-theory redundancy analysis. Pattern Recognit. Lett. 2020, 138, 321–328. [Google Scholar] [CrossRef]
- Cohen, J.P.; Ding, W.; Kuhlman, C.; Chen, A.; Di, L. Rapid building detection using machine learning. Appl. Intell. 2016, 45, 443–457. [Google Scholar] [CrossRef] [Green Version]
- Nascimento, D.C.; Pires, C.E.; Mestre, D.G. Applying machine learning techniques for scaling out data quality algorithms in cloud computing environments. Appl. Intell. 2016, 45, 530–548. [Google Scholar] [CrossRef]
- Nesarani, A.; Ramar, R.; Pandian, S. An efficient approach for rice prediction from authenticated Block chain node using machine learning technique. Environ. Technol. Innov. 2020, 20, 101064. [Google Scholar] [CrossRef]
- Stracca, L. Our currency, your problem? The global effects of the Euro debt crisis. Eur. Econ. Rev. 2015, 74, 1–13. [Google Scholar] [CrossRef]
- Yan, C.; Li, Z.; Boota, M.W.; Zohaib, M.; Liu, X.; Shi, C.; Xu, J. River pattern discriminant method based on Rough Set theory. J. Hydrol. Reg. Stud. 2023, 45, 101285. [Google Scholar] [CrossRef]
- Abreu, L.R.; Maciel, I.S.; Alves, J.S.; Braga, L.C.; Pontes, H.L. A decision tree model for the prediction of the stay time of ships in Brazilian ports. Eng. Appl. Artif. Intell. 2023, 117, 105634. [Google Scholar] [CrossRef]
- Kishino, M.; Matsumoto, K.; Kobayashi, Y.; Taguchi, R.; Akamatsu, N.; Shishido, A. Fatigue life prediction of bending polymer films using random forest. Int. J. Fatigue 2023, 166, 107230. [Google Scholar] [CrossRef]
- Yan, J.; Zeng, S.; Tian, B.; Cao, Y.; Yang, W.; Zhu, F. Relationship between highway geometric characteristics and accident risk: A multilayer perceptron model (MLP) approach. Sustainability 2023, 15, 1893. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Sun, J.; Ji, J. Estimates on compressed neural networks regression. Neural Netw. 2015, 63, 10–17. [Google Scholar] [CrossRef] [Green Version]
- Kitson, N.K.; Constantinou, A.C.; Guo, Z.; Liu, Y.; Chobtham, K. A survey of Bayesian Network structure learning. Artif. Intell. Rev. 2023, 56, 8721–8814. [Google Scholar] [CrossRef]
- Song, Y.X.; Yang, X.D.; Luo, Y.G.; Ouyang, C.L.; Yu, Y.; Ma, Y.L.; Mi, W.D. Comparison of logistic regression and machine learning methods for predicting postoperative delirium in elderly patients: A retrospective study. CNS Neurosci. Ther. 2023, 29, 158–167. [Google Scholar] [CrossRef]
- Kim, T.; Lee, J.S. Maximizing AUC to learn weighted naive Bayes for imbalanced data classification. Expert Syst. Appl. 2023, 217, 119564. [Google Scholar] [CrossRef]
- Qin, Z.; Li, Q. An uncertain support vector machine with imprecise observations. Fuzzy Optim. Decis. Mak. 2023, 1–19. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, P.; Xu, Y.; Xie, H. Construction of decision tree based on C4.5 algorithm for online voltage stability assessment. Int. J. Electr. Power Energy Syst. 2020, 118, 105793. [Google Scholar] [CrossRef]
- Fujioka, A.; Nagano, M.; Ikegami, K.; Masumoto, K.H.; Yoshikawa, T.; Koinuma, S.; Shigeyoshi, Y. Circadian expression and specific localization of synaptotagmin17 in the suprachiasmatic nucleus, the master circadian oscillator in mammals. Brain Res. 2023, 1798, 148129. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.M.; Lee, Y.M. Are life insurance futures a safe haven during COVID-19? Financ. Innov. 2023, 9, 13. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Soroka, A.; Han, L.; Jian, J.; Tang, M. Cloud-based big data analytics for customer insight-driven design innovation in SMEs. Int. J. Inf. Manag. 2020, 51, 102034. [Google Scholar] [CrossRef]
- Alseadoon, I.; Ahmad, A.; Alkhalil, A.; Sultan, K. Migration of existing software systems to mobile computing platforms: A systematic mapping study. Front. Comput. Sci. 2021, 15, 152204. [Google Scholar] [CrossRef]
- Woratschek, H.; Horbel, C.; Popp, B. Determining customer satisfaction and loyalty from a value co-creation perspective. Serv. Ind. J. 2020, 40, 777–799. [Google Scholar] [CrossRef]
- Sheth, J.; Kellstadt, C.H. Next frontiers of research in data driven marketing: Will techniques keep up with data tsunami? J. Bus. Res. 2021, 125, 780–784. [Google Scholar] [CrossRef]
- Shah, D.; Murthi, B.P.S. Marketing in a data-driven digital world: Implications for the role and scope of marketing. J. Bus. Res. 2021, 125, 772–779. [Google Scholar] [CrossRef]
- Hughes, H.D. The settlement of disputes in the public service. Public Adm. 1968, 46, 45–62. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Approaches to multi-objective feature selection: A systematic literature review. IEEE Access 2020, 8, 125076–125096. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Fusion of statistical importance for feature selection in deep neural network-based intrusion detection system. Inf. Fusion 2023, 90, 353–363. [Google Scholar] [CrossRef]
- Lin, R.H.; Pei, Z.X.; Ye, Z.Z.; Guo, C.C.; Wu, B.D. Hydrogen fuel cell diagnostics using random forest and enhanced feature selection. Int. J. Hydrogen Energy 2020, 45, 10523–10535. [Google Scholar] [CrossRef]
- Kazemi, F.; Asgarkhani, N.; Jankowski, R. Predicting seismic response of SMRFs founded on different soil types using machine learning techniques. Eng. Struct. 2023, 274, 114953. [Google Scholar] [CrossRef]
- Nguyen, B.H.; Xue, B.; Zhang, M. A survey on swarm intelligence approaches to feature selection in data mining. Swarm Evol. Comput. 2020, 54, 100663. [Google Scholar] [CrossRef]
- Zhang, B.; Tseng, M.L.; Qi, L.; Guo, Y.; Wang, C.H. A comparative online sales forecasting analysis: Data mining techniques. Comput. Ind. Eng. 2023, 176, 108935. [Google Scholar] [CrossRef]
- Seeja, K.R. Feature selection based on closed frequent itemset mining: A case study on SAGE data classification. Neurocomputing 2015, 151, 1027–1032. [Google Scholar] [CrossRef]
- Zhang, Z.; He, J.; Gao, G.; Tian, Y. Sparse multi-criteria optimization classifier for credit risk evaluation. Soft Comput. 2017, 23, 3053–3066. [Google Scholar] [CrossRef]
- Kaba, A.; Ramaiah, C.K. Demographic differences in using knowledge creation tools among faculty members. J. Knowl. Manag. 2017, 21, 857–871. [Google Scholar] [CrossRef]
- Qian, W.; Li, Y.; Ye, Q.; Ding, W.; Shu, W. Disambiguation-based partial label feature selection via feature dependency and label consistency. Inf. Fusion 2023, 94, 152–168. [Google Scholar] [CrossRef]
- Chen, Y.S.; Lin, C.K.; Chou, J.C.L.; Hung, Y.H.; Wang, S.W. Research on industry data analytics on processing procedure of named 3-4-8-2 components combination for the application identification in new chain convenience store. Processes 2023, 11, 180. [Google Scholar] [CrossRef]
- Alaka, H.A.; Oyedele, L.O.; Owolabi, H.A.; Akinade, O.O.; Bilal, M. Systematic review of bankruptcy prediction models: Towards a framework for tool selection. Expert Syst. Appl. 2018, 94, 164–184. [Google Scholar] [CrossRef]
- Sarker, I.H.; Colman, A.; Han, J. BehavDT: A behavioral decision tree learning to build user-centric context-aware predictive model. Mob. Netw. Appl. 2020, 25, 1151–1161. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993. [Google Scholar]
- Sarailidis, G.; Wagener, T.; Pianosi, F. Integrating scientific knowledge into machine learning using interactive decision trees. Comput. Geosci. 2023, 170, 105248. [Google Scholar] [CrossRef]
- Luo, J.; Fujita, H.; Yao, Y.; Qin, K. On modeling similarity and three-way decision under incomplete information in rough set theory. Knowl.-Based Syst. 2020, 191, 105251. [Google Scholar] [CrossRef]
- Zhang, C.; Li, D.; Kang, X.; Song, D.; Sangaiah, A.K.; Broumi, S. Neutrosophic fusion of rough set theory: An overview. Comput. Ind. 2020, 115, 103117. [Google Scholar] [CrossRef]
- Yolcu, A.; Benek, A.; Öztürk, T.Y. A new approach to neutrosophic soft rough sets. Knowl. Inf. Syst. 2023, 65, 2043–2060. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, L. Efficient approaches for maintaining dominance-based multigranulation approximations with incremental granular structures. Int. J. Approx. Reason. 2020, 126, 202–227. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, B.Q. On two new types of fuzzy rough sets via overlap functions and corresponding applications to three-way approximations. Inf. Sci. 2023, 620, 158–186. [Google Scholar] [CrossRef]
- Sun, B.; Ma, W.; Li, B.; Li, X. Three-way decisions approach to multiple attribute group decision making with linguistic information-based decision-theoretic rough fuzzy set. Int. J. Approx. Reason. 2018, 93, 424–442. [Google Scholar] [CrossRef]
- Yin, T.; Chen, H.; Yuan, Z.; Li, T.; Liu, K. Noise-resistant multilabel fuzzy neighborhood rough sets for feature subset selection. Inf. Sci. 2023, 621, 200–226. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W. A comparison of three strategies to rule induction from data with numerical attributes. In Proceedings of the International Workshop on Rough Sets in Knowledge Discovery (RSKD 2003), Warsaw, Poland, 5–13 April 2003; pp. 132–140. [Google Scholar]
- Grzymala-Busse, J.W. A new version of the rule induction system LERS. Fundam. Informaticae 1997, 31, 27–39. [Google Scholar] [CrossRef]
- Cui, L.; Ren, T.; Zhang, X.; Feng, Z. Optimization of large-scale knowledge forward reasoning based on OWL 2 DL ontology. In Collaborative Computing: Networking, Applications and Worksharing: 18th EAI International Conference, CollaborateCom 2022, Hangzhou, China, 15–16 October 2022, Proceedings, Part II; Springer Nature: Cham, Switzerland, 2023; pp. 380–399. [Google Scholar]
- Nguyen, H.S.; Nguyen, S.H. Analysis of stulong data by rough set exploration system (RSES). In Proceedings of the ECML/PKDD 2003 Discovery Challenge, Dubrovnik, Croatia, 22–26 September 2003; pp. 71–82. [Google Scholar]
- Obregon, J.; Jung, J.Y. RuleCOSI+: Rule extraction for interpreting classification tree ensembles. Inf. Fusion 2023, 89, 355–381. [Google Scholar] [CrossRef]
- Wu, X.; Feng, Z.; Liu, Y.; Qin, Y.; Yang, T.; Duan, J. Enhanced safety prediction of vault settlement in urban tunnels using the pair-copula and Bayesian network. Appl. Soft Comput. 2023, 132, 109711. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, G.; Reniers, G. Vulnerability assessment of atmospheric storage tanks to floods based on logistic regression. Reliab. Eng. Syst. Saf. 2020, 196, 106721. [Google Scholar] [CrossRef]
- Huang, L.; Leng, H.; Li, X.; Ren, K.; Song, J.; Wang, D. A data-driven method for hybrid data assimilation with multilayer perceptron. Big Data Res. 2020, 23, 100179. [Google Scholar] [CrossRef]
- Ghaddar, B.; Naoum-Sawaya, J. High dimensional data classification and feature selection using support vector machines. Eur. J. Oper. Res. 2018, 265, 993–1004. [Google Scholar] [CrossRef]
- Singh, V.; Poonia, R.C.; Kumar, S.; Dass, P. Prediction of COVID-19 corona virus pandemic based on time series data using Support Vector Machine. J. Discret. Math. Sci. Cryptogr. 2020, 23, 1583–1597. [Google Scholar] [CrossRef]
- Wiharto, W.; Kusnanto, H.; Herianto, H. System diagnosis of coronary heart disease using a combination of dimensional reduction and data mining techniques: A review. Indones. J. Electr. Eng. Comput. Sci. 2017, 7, 514–523. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets, Theoretical Aspects of Reasoning about Data; Kluwer: Dordrecht, The Netherlands, 1991. [Google Scholar]
- Chen, Q.; Guo, Z.; Zhao, J.; Ouyang, Q. Comparisons of different regressions tools in measurement of antioxidant activity in green tea using near infrared spectroscopy. J. Pharm. Biomed. Anal. 2012, 60, 92–97. [Google Scholar] [CrossRef] [PubMed]
- Vij, R.; Arora, S. A novel deep transfer learning based computerized diagnostic Systems for Multi-class imbalanced diabetic retinopathy severity classification. Multimed. Tools Appl. 2023, 1–38. [Google Scholar] [CrossRef]
- Yap, A.U.; Ong, J.E.; Yahya, N.A. Effect of resin coating on highly viscous glass ionomer cements: A dynamic analysis. J. Mech. Behav. Biomed. Mater. 2020, 113, 104120. [Google Scholar] [CrossRef]
- Tsumoto, S. Incremental rule induction based on rough set theory. In International Symposium on Methodologies for Intelligent Systems; Lecture Notes in Computer Science; LNAI 6804; Springer: Berlin/Heidelberg, Germany, 2011; pp. 70–79. [Google Scholar]
- Wang, J.; Xu, C.; Zhang, J.; Zhong, R. Big data analytics for intelligent manufacturing systems: A review. J. Manuf. Syst. 2022, 62, 738–752. [Google Scholar] [CrossRef]
- Shi, H.Y.; Yeh, S.C.J.; Chou, H.C.; Wang, W.C. Long-term care insurance purchase decisions of registered nurses: Deep learning versus logistic regression models. Health Policy 2023, 129, 104709. [Google Scholar] [CrossRef]
- Chen, Y.-S.; Lin, C.-K.; Chou, J.C.-L.; Chen, S.-F.; Ting, M.-H. Application of advanced hybrid models to identify the sustainable financial management clients of long-term care insurance policy. Sustainability 2022, 14, 12485. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Element | |||||||||||||||||
| Feature selection method | √ | √ | √ | √ | √ | √ | √ | √ | |||||||||
| Data discretization technique | √ | √ | √ | √ | √ | √ | √ | √ | |||||||||
| Decision tree_DT-C4.5 | √ | √ | √ | √ | |||||||||||||
| Rough sets_RS-LEM2 | √ | √ | √ | √ | √ | √ | √ | √ | |||||||||
| Rule filter | √ | √ | √ | √ | |||||||||||||
| Comparative studies (BN, LR, MLP, NB, RF, and SVM) | √ | √ | √ | √ | |||||||||||||
| ANOVA test and Scheffe’s test | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | |
| Item | Attribute Encoding | Category | Attribute Length | Property Description |
|---|---|---|---|---|
| 1 | C1 | Symbolic | 1 | Gender (M: male, F: female, and T: third gender) |
| 2 | C2 | Symbolic | 1 | Educational background (G: below junior high school, H: high school, C: junior college, U: university, and M: master or above) |
| 3 | C3 | Symbolic | 1 | Nature of work (A: internal work, B: field work, C: mixed, O: other) |
| 4 | C4 | Symbolic | 1 | Marriage (Y: married and N: unmarried) |
| 5 | C5 | Symbolic | 1 | Whether the spouse is working (Y: yes and N: no) |
| 6 | C6 | Symbolic | 1 | Family salary structure (S: single salary, D: double salary or above, and O: other) |
| 7 | C7 | Symbolic | 1 | Payment method (Y: annual payment, H: semi-annual payment, S: quarterly payment, M: monthly payment, and O: other) |
| 8 | C8 | Symbolic | 1 | Payer (I: self, P: parents, S: spouse, C: children, and O: others) |
| 9 | C9 | Symbolic | 1 | Whether to pay the renewal premium (Y: yes and N: no) |
| 10 | C10 | Symbolic | 1 | Have you ever renewed an investment policy (Y: yes and N: no) |
| 11 | C11 | Symbolic | 1 | Whether to pay the insurance fee sustainably (Y: yes and N: no) |
| 12 | C12 | Numeric | 4 | Total number of policies purchased in the past |
| 13 | C13 | Numeric | 4 | Number of effective policies |
| 14 | C14 | Numeric | 4 | Time since first purchase in months |
| 15 | C15 | Numeric | 12 | Critical illness insurance |
| 16 | C16 | Numeric | 12 | Total life insurance amount |
| 17 | C17 | Numeric | 12 | Total sum insured of life insurance (including critical illness) |
| 18 | C18 | Numeric | 12 | Total premiums for policies in force for the current year |
| 19 | C19 | Numeric | 12 | Total sum of insured insurance |
| 20 | D1 (Class) | Symbolic | 1 | LTCI (decision attribute, Y: yes and N: no) |
| Data | Type | Missing | Distinct | Unique | Label | Count | |
|---|---|---|---|---|---|---|---|
| Feature | |||||||
| C1 | Nominal | 0 (0%) | 2 | 0 (0%) | F | 253 | |
| M | 254 | ||||||
| C2 | Nominal | 0 (0%) | 6 | 0 (0%) | C | 51 | |
| M | 35 | ||||||
| U | 150 | ||||||
| H | 165 | ||||||
| D | 4 | ||||||
| G | 102 | ||||||
| C3 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 427 | |
| N | 80 | ||||||
| C4 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 244 | |
| N | 263 | ||||||
| C5 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 218 | |
| N | 289 | ||||||
| C6 | Nominal | 0 (0%) | 2 | 0 (0%) | S | 239 | |
| D | 268 | ||||||
| C7 | Nominal | 0 (0%) | 4 | 0 (0%) | S | 43 | |
| Y | 331 | ||||||
| H | 18 | ||||||
| M | 115 | ||||||
| C8 | Nominal | 0 (0%) | 4 | 0 (0%) | I | 307 | |
| P | 180 | ||||||
| C | 5 | ||||||
| S | 15 | ||||||
| C9 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 305 | |
| N | 202 | ||||||
| C10 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 144 | |
| N | 363 | ||||||
| C11 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 459 | |
| N | 48 | ||||||
| D1 | Nominal | 0 (0%) | 2 | 0 (0%) | Y | 167 | |
| N | 340 | ||||||
| Data | Type | Missing | Distinct | Unique | Minimum | Maximum | Mean | Std. Deviation | |
|---|---|---|---|---|---|---|---|---|---|
| Feature | |||||||||
| C12 | Numeric | 0 (0%) | 17 | 3 (1%) | 0 | 20 | 2.400 | 2.542 | |
| C13 | Numeric | 0 (0%) | 13 | 2 (0%) | 0 | 15 | 2.014 | 1.852 | |
| C14 | Numeric | 1 (0%) | 30 | 5 (1%) | 0 | 33 | 4.280 | 6.736 | |
| C15 | Numeric | 0 (0%) | 33 | 14 (3%) | 0 | 6,500,000 | 248,165.680 | 563,763.809 | |
| C16 | Numeric | 0 (0%) | 129 | 85 (17%) | 0 | 77,700,000 | 1,625,192.787 | 6,422,077.476 | |
| C17 | Numeric | 0 (0%) | 150 | 107 (21%) | 0 | 7970 | 178.529 | 669.726 | |
| C18 | Numeric | 0 (0%) | 438 | 404 (80%) | 0 | 817,431 | 44,286.686 | 73,373.819 | |
| C19 | Numeric | 0 (0%) | 185 | 135 (27%) | 0 | 79,740,000 | 1,790,703.635 | 6,700,770.620 | |
| Method | By CFS Subset Evaluator | By DT (Presentation Frequency) | |
|---|---|---|---|
| Result | |||
| Key attributes | C4, C12, C17, C19 vs. D1 | C16 (3), C17 (3), C19 (3), C12 (2), C14 (2), C15 (2), C5 (1), C7 (1), C13 (1), C9 (1), C10 (1), C18 (1) vs. D1 | |
| Method | Gain Ratio Feature Evaluator | Information Gain Ranking Filter | Oner Feature Evaluator | |
|---|---|---|---|---|
| Result | ||||
| Important attributes | C19➔C17➔C12➔C15➔C16➔C13➔C14➔C18➔C9➔C2➔C4➔C10➔C8➔C5➔C7➔C11➔C1➔C6➔C3 vs. D1 | C19➔C17➔C13➔C12➔C14➔C16➔C18➔C2➔C15➔C9➔C4➔C8➔C7➔C5➔C10➔C1➔C11➔C6➔C3 vs. D1 | C19➔C17➔C12➔C13➔C14➔C18➔C2➔C15➔C16➔C4➔C3➔C6➔C5➔C10➔C7➔C11➔C9➔C1➔C8 vs. D1 | |
| Feature | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 |
|---|---|---|---|---|---|---|---|---|
| Value | (−inf~2.5] (2.5~6.5] (6.5~inf) | (−inf~2.5] (2.5~5.5] (5.5~inf) | (−inf~0.05] (0.05~inf) | (−inf~1,225,000] (1,225,000~inf) | (−inf~20,400] (20,400~5905,000] (5,905,000~inf) | (−inf~2.04] (2.04~528.5] (528.5~inf) | (−inf~36,517] (36,517~inf) | (−inf~5000] (5000~30,400] (30,400~95,000] (95,000~105,000] (105,000~130,500] (130,500~5305,000] (5,305,000~inf) |
| Model | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ratio | |||||||||||||||||
| 66%/34% | 87.21 | 86.63 | 85.50 | 85.50 | 87.79 | 86.05 | 96.60 | 98.60 | 87.79 | 86.63 | 91.60 | 93.50 | 83.72 | 79.80 | 82.10 | 84.30 | |
| 75%/25% | 86.61 | 86.61 | 82.80 | 82.80 | 88.98 | 85.04 | 96.10 | 100.0 | 90.55 | 89.76 | 89.60 | 89.50 | 90.55 | 86.40 | 87.80 | 85.83 | |
| 80%/20% | 86.14 | 86.14 | 88.10 | 88.10 | 91.09 | 88.12 | 88.30 | 90.00 | 94.06 | 87.13 | 78.60 | 83.30 | 91.09 | 74.50 | 72.10 | 86.14 | |
| Average | 86.65 | 86.46 | 85.47 | 85.47 | 89.29 | 86.40 | 93.67 2 | 96.20 1 | 90.80 3 | 87.84 | 86.60 | 88.77 | 88.45 | 80.23 | 80.67 | 85.42 | |
| Model | BN | LR | MLP | NB | RF | SVM | DT | RST | The Best Classifier | |
|---|---|---|---|---|---|---|---|---|---|---|
| Ratio | ||||||||||
| 66%/34% | 83.14 | 75.58 | 76.16 | 70.93 | 84.30 | 71.51 | 83.72 | 82.10 | 84.30 for RF | |
| 75%/25% | 78.74 | 82.68 | 77.17 | 73.23 | 85.83 | 70.08 | 90.55 | 88.30 | 90.55 for DT | |
| 80%/20% | 84.16 | 85.15 | 70.30 | 71.29 | 86.14 | 69.31 | 91.09 | 86.30 | 91.09 for DT | |
| Average | 82.01 | 81.14 | 74.54 | 71.82 | 85.42 3 | 70.30 | 88.45 1 | 85.57 2 | 88.65 | |
| Model | BN | LR | MLP | NB | RF | SVM | DT | RST | The Best Classifier | |
|---|---|---|---|---|---|---|---|---|---|---|
| Ratio | ||||||||||
| 66%/34% | 86.05 | 81.98 | 87.21 | 86.05 | 87.21 | 81.98 | 86.63 | 85.50 | 87.21 for MLP and RF | |
| 75%/25% | 85.83 | 86.61 | 86.61 | 85.83 | 86.61 | 82.68 | 86.61 | 82.80 | 86.61 for LR, MLP, RF, and DT | |
| 80%/20% | 85.15 | 86.14 | 86.14 | 85.15 | 86.14 | 84.16 | 86.14 | 88.10 | 88.10 for RST | |
| Average | 85.68 | 84.91 | 86.65 1 | 85.68 | 86.65 1 | 82.94 | 86.46 3 | 85.47 | ||
| Model | BN | LR | MLP | NB | RF | SVM | DT | RST | The Best Classifier | |
|---|---|---|---|---|---|---|---|---|---|---|
| Ratio | ||||||||||
| 66%/34% | 84.30 | 76.74 | 69.19 | 70.93 | 87.79 | 70.35 | 86.05 | 96.60 | 96.60 for RST | |
| 75%/25% | 78.74 | 81.10 | 70.08 | 71.65 | 88.98 | 70.08 | 85.04 | 96.10 | 96.10 for RST | |
| 80%/20% | 83.17 | 81.19 | 69.31 | 70.30 | 91.09 | 68.32 | 88.12 | 88.30 | 91.09 for RF | |
| Average | 82.07 | 79.68 | 69.53 | 70.96 | 89.29 2 | 69.58 | 86.40 3 | 93.67 1 | ||
| Model | BN | LR | MLP | NB | RF | SVM | DT | RST | The Best Classifier | |
|---|---|---|---|---|---|---|---|---|---|---|
| Ratio | ||||||||||
| 66%/34% | 83.14 | 87.21 | 84.30 | 83.14 | 87.21 | 87.79 | 86.63 | 91.60 | 91.60 for RST | |
| 75%/25% | 85.83 | 90.55 | 88.19 | 85.04 | 88.19 | 88.19 | 89.76 | 89.60 | 90.55 for LR | |
| 80%/20% | 84.16 | 92.08 | 89.11 | 84.16 | 94.06 | 89.11 | 87.13 | 78.60 | 94.06 for RF | |
| Average | 84.38 | 89.95 1 | 87.20 | 84.11 | 89.82 2 | 88.36 3 | 87.84 | 86.60 | ||
| Model | BN | LR | MLP | NB | RF | SVM | DT | RST | The Best Classifier | |
|---|---|---|---|---|---|---|---|---|---|---|
| Run | ||||||||||
| 1 | 83.14 | 75.58 | 76.16 | 70.93 | 84.30 | 71.51 | 83.72 | 82.40 | 84.30 for RF | |
| 2 | 84.88 | 77.33 | 73.26 | 73.26 | 87.21 | 75.00 | 82.56 | 72.60 | 87.21 for RF | |
| 3 | 84.88 | 78.49 | 73.84 | 73.84 | 86.63 | 75.58 | 87.21 | 79.70 | 86.63 for RF | |
| 4 | 82.56 | 98.26 | 76.74 | 72.09 | 88.95 | 76.74 | 87.79 | 90.80 | 98.26 for LR | |
| 5 | 87.79 | 73.84 | 73.84 | 72.09 | 90.70 | 73.84 | 91.28 | 76.30 | 91.28 for DT | |
| 6 | 80.81 | 73.84 | 70.93 | 72.09 | 84.88 | 71.51 | 87.21 | 75.00 | 87.21 for DT | |
| 7 | 80.23 | 77.33 | 72.67 | 70.35 | 81.98 | 70.35 | 84.88 | 79.80 | 84.88 for DT | |
| 8 | 84.30 | 79.07 | 66.86 | 72.09 | 90.12 | 75.00 | 88.37 | 77.60 | 90.12 for RF | |
| 9 | 83.72 | 98.84 | 70.93 | 72.67 | 86.05 | 80.23 | 89.53 | 72.10 | 98.84 for LR | |
| 10 | 77.33 | 79.07 | 72.67 | 72.09 | 83.72 | 76.74 | 83.14 | 68.30 | 83.72 for RF | |
| Average | 81.78 | 85.66 3 | 70.15 | 72.28 | 86.63 2 | 77.32 | 87.01 1 | 72.67 | 87.01 for DT | |
| Std. Dev. | 2.9257 | 9.3601 | 2.8186 2 | 1.0058 1 | 2.8494 3 | 2.9786 | 2.8928 | 6.2939 | ||
| Model | RST (No Filter) | Total Coverage | Rule Number | RST (With Filter) | Total Coverage | Rule Number | |
|---|---|---|---|---|---|---|---|
| Run | |||||||
| 1 | 82.40 | 0.491 | 131 | 83.10 | 0.445 | 90 | |
| 2 | 72.60 | 0.486 | 128 | 71.40 | 0.445 | 87 | |
| 3 | 79.70 | 0.399 | 130 | 82.00 | 0.353 | 90 | |
| 4 | 90.80 | 0.439 | 130 | 90.10 | 0.410 | 89 | |
| 5 | 76.30 | 0.538 | 113 | 74.70 | 0.503 | 83 | |
| 6 | 75.00 | 0.509 | 125 | 76.50 | 0.491 | 84 | |
| 7 | 79.80 | 0.543 | 113 | 78.40 | 0.509 | 88 | |
| 8 | 77.60 | 0.387 | 128 | 78.30 | 0.347 | 83 | |
| 9 | 72.10 | 0.497 | 119 | 73.80 | 0.462 | 84 | |
| 10 | 68.30 | 0.416 | 68 | 69.50 | 0.383 | 47 | |
| Average | 72.67 | 0.43 | 105.0 | 73.87 | 0.40 | 71.3 | |
| Std. Dev. | 6.29 | 0.06 | 19.02 | 6.10 | 0.06 | 12.78 | |
| RST Model | Accuracy | Coverage 0.9 | Number of Rules | Accuracy | Coverage 0.8 | Number of Rules | |
|---|---|---|---|---|---|---|---|
| Ratio | |||||||
| 66%/34% | 82.10 | 0.486 | 137 | 76.60 | 0.445 | 110 | |
| 75%/25% | 88.30 | 0.472 | 162 | 85.50 | 0.433 | 132 | |
| 80%/20% | 86.30 | 0.500 | 165 | 82.10 | 0.382 | 142 | |
| Average | 85.57 | 0.486 | 154.7 | 81.40 | 0.420 | 128.0 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Hung, Y.-H.; Lin, Y.-S. A Study to Identify Long-Term Care Insurance Using Advanced Intelligent RST Hybrid Models with Two-Stage Performance Evaluation. Mathematics 2023, 11, 3010. https://doi.org/10.3390/math11133010
Chen Y-S, Hung Y-H, Lin Y-S. A Study to Identify Long-Term Care Insurance Using Advanced Intelligent RST Hybrid Models with Two-Stage Performance Evaluation. Mathematics. 2023; 11(13):3010. https://doi.org/10.3390/math11133010
Chicago/Turabian StyleChen, You-Shyang, Ying-Hsun Hung, and Yu-Sheng Lin. 2023. "A Study to Identify Long-Term Care Insurance Using Advanced Intelligent RST Hybrid Models with Two-Stage Performance Evaluation" Mathematics 11, no. 13: 3010. https://doi.org/10.3390/math11133010
APA StyleChen, Y.-S., Hung, Y.-H., & Lin, Y.-S. (2023). A Study to Identify Long-Term Care Insurance Using Advanced Intelligent RST Hybrid Models with Two-Stage Performance Evaluation. Mathematics, 11(13), 3010. https://doi.org/10.3390/math11133010