1. Introduction
In task-oriented dialogue systems, the primary objective is to enable user–system communication to accomplish specific tasks, such as a restaurant search, hotel reservation, or schedule management. These systems generally focus on understanding the user input, tracking dialogue states, and generating appropriate responses.
The conventional task-oriented dialogue system follows a pipelined structure, consisting of several interconnected modules: the Natural Language Understanding (NLU) module, the Dialogue State Tracking (DST) module, the Dialogue Policy Learning (POL) module, and the Natural-Language-Generation (NLG) module, as shown in
Figure 1 [
1]. First, the NLU module is responsible for extracting semantic information from user inputs. The DST module utilizes the previous conversation history to update the belief state at the time of the current utterance. The belief state is a structured expression method that represents the user’s conversational goals and information gathered thus far. The system then searches the database for relevant information based on the belief state. The POL module determines the system action based on the knowledge retrieved from the database and the current belief state. Finally, the NLG module generates a system response based on the decision made by the POL module. In general, this pipelined architecture facilitates the flow of information in a task-oriented dialogue system, enabling efficient understanding of the user input, tracking dialogue states, determining system actions, and generating appropriate responses.
The conventional pipelined structure of task-oriented dialogue systems, however, suffers from error propagation between independent modules and limited adaptability to new domains. To address these problems, recent studies have proposed structures that integrate independent modules using pre-trained language models [
2,
3,
4].
Recent language models have widely adopted the Transformer-based model [
5] and have shown a dramatic increase in performance, in tasks such as object name recognition, natural language inference, and machine translation. Theses language models generally employ transfer learning [
6], where knowledge is first learned from a source domain and then transferred to the target domain. The Transformer-based language model consists of a pre-training step, which first learns the syntax and semantics of the language from large text data, and a fine-tuning step, which adjusts the model’s parameters for downstream tasks. Therefore, pre-trained language models that capture the syntax and semantics of a language render better performance compared to learning data from scratch. During fine-tuning, the entire parameter set of the pre-trained language model is adjusted to fit the downstream task.
A recent study [
7] showed that larger pre-trained language models, with more parameters, tend to achieve better performance in downstream tasks. This trend also applies to task-oriented dialogue systems, where the parameter count of the pre-trained language models has reached tens of billions. However, fine-tuning such large-scale models poses challenges. First, the training time increases as the number of parameters grows since the entire parameter set is updated during fine-tuning. Second, fine-tuning a large-scale pre-trained language model requires significant storage space due to the increased model size.
In this paper, we propose PEFTTOD (the name PEFTTOD comes from integrating the PEFT method into TOD systems), a novel structure for solving task-oriented dialogue (TOD) systems using a large-scale pre-trained language model. PEFTTOD efficiently utilizes the parameters by employing the Adapter Layer [
8] and prefix tuning [
9] techniques from the Parameter-Efficient Fine-Tuning (PEFT) method [
10]. The PEFT method incorporates a trainable layer into the pre-trained language model while freezing the parameters of the existing model and learning only the newly added layer. The PEFT method offers several advantages. First, although the PEFT method is trained with a much smaller parameter count than the pre-trained language model, it achieves performance comparable to fine-tuning. Second, by freezing the weight of the pre-trained language model and training only the added trainable layers, the original state of the pre-trained model is preserved. Third, whereas fine-tuning requires saving the entire model, the PEFT method only necessitates saving the parameters of the trainable layer, resulting in significantly reduced storage space. Lastly, since the parameters of the pre-trained language model remain frozen, the weight update process of the frozen layers is skipped, leading to faster training speeds.
PEFTTOD utilizes PPTOD [
2] as its pre-trained language model, which integrates an extensive knowledge conversational domain based on T5 [
11] and combines it with the PEFT method [
10]. The performance of PEFTTOD was evaluated using the Multi-WOZ 2.0 benchmark dataset [
12]. Compared to the conventional fine-tuning method, PEFTTOD uses only 4% of the parameters of the existing model during the training process. This leads to improvement in training time by 20% and storage space savings by up to 95%. Moreover, PEFTTOD demonstrated 4% improvement in the combined score compared to the baseline, despite using only 4% from the parameters of the previous model.
The main contribution of this paper is three-fold. Firstly, existing pre-trained language models typically employ billions of parameters, which leads to longer training times, as well as significant storage space due to the larger model size. In our proposed approach, PEFTTOD, we adopted the Adapter Layer and PEFT-based prefix tuning to decrease the number of parameters. Secondly, PEFTTOD was trained with a substantially smaller parameter count and, thus, requires less storage space. Consequently, as the parameters of the pre-trained language model remain frozen, the training speed is accelerated. Thirdly, we conducted extensive experiments using the Multi-WOZ 2.0 benchmark dataset to prove our advantages.
The remainder of the paper is organized as follows. In
Section 2, we provide an overview of the related work.
Section 3 presents the details and design of our proposed approach, and
Section 4 presents the evaluation results. Finally, we conclude our paper in
Section 5.
3. Design
This paper proposes PEFTTOD, a Transformer-based task-oriented dialogue system that leverages a parameter-efficient language-model-tuning method. This system combines a Transformer-based language model with an efficient learning structure for conversational knowledge. PEFTTOD’s pre-trained language model uses PPTOD [
2], which is trained on a large amount of conversational domain knowledge, based on T5 [
11]. In PPTOD, a prompt corresponding to the downstream task of the task-oriented dialogue system is combined with the input data. For example, prompts such as “translate dialogue to belief state:”, “translate dialogue to dialogue action:”, and “translate dialogue to system response:” are used. However, a prompt attached to the data may not be optimized for the model’s performance [
9]. To address this issue, the proposed PEFTTOD system incorporates a structure that enables the model to learn the prompt directly through prefix tuning.
3.1. End-to-End Dialogue Modeling
PEFTTOD incorporates a structured framework that effectively learns conversational knowledge by leveraging PPTOD [
2], a T5-based language model trained on a substantial amount of information specific to the conversational domain.
The system architecture of PEFTTOD is based on a sequence-to-sequence architecture model, as shown in
Figure 2. At each dialog turn, the encoder takes input consisting of the dialogue history and the user’s utterance. On the basis of the encoded conversation information, the decoder generates a belief state, which represents the system’s understanding of the user’s intentions and requirements.
The generated belief state is used for database search, enabling the system to obtain the corresponding DB state from the database. Additionally, based on the encoded dialog information and DB state, the decoder generates a system action and a system response. The system action determines the decision or action the dialogue system should take, while the system response represents the system’s generated reply to the user.
PEFTTOD was trained on the Multi-WOZ 2.0 dataset, specifically on the task of the end-to-end dialogue modeling [
45]. The proposed system was trained using the maximum likelihood method, a common approach in machine learning, which aims to optimize the model’s parameters by maximizing the likelihood of generating the correct outputs given the inputs.
Say that
(here,
D is the data and
,
), then the loss (
L) becomes:
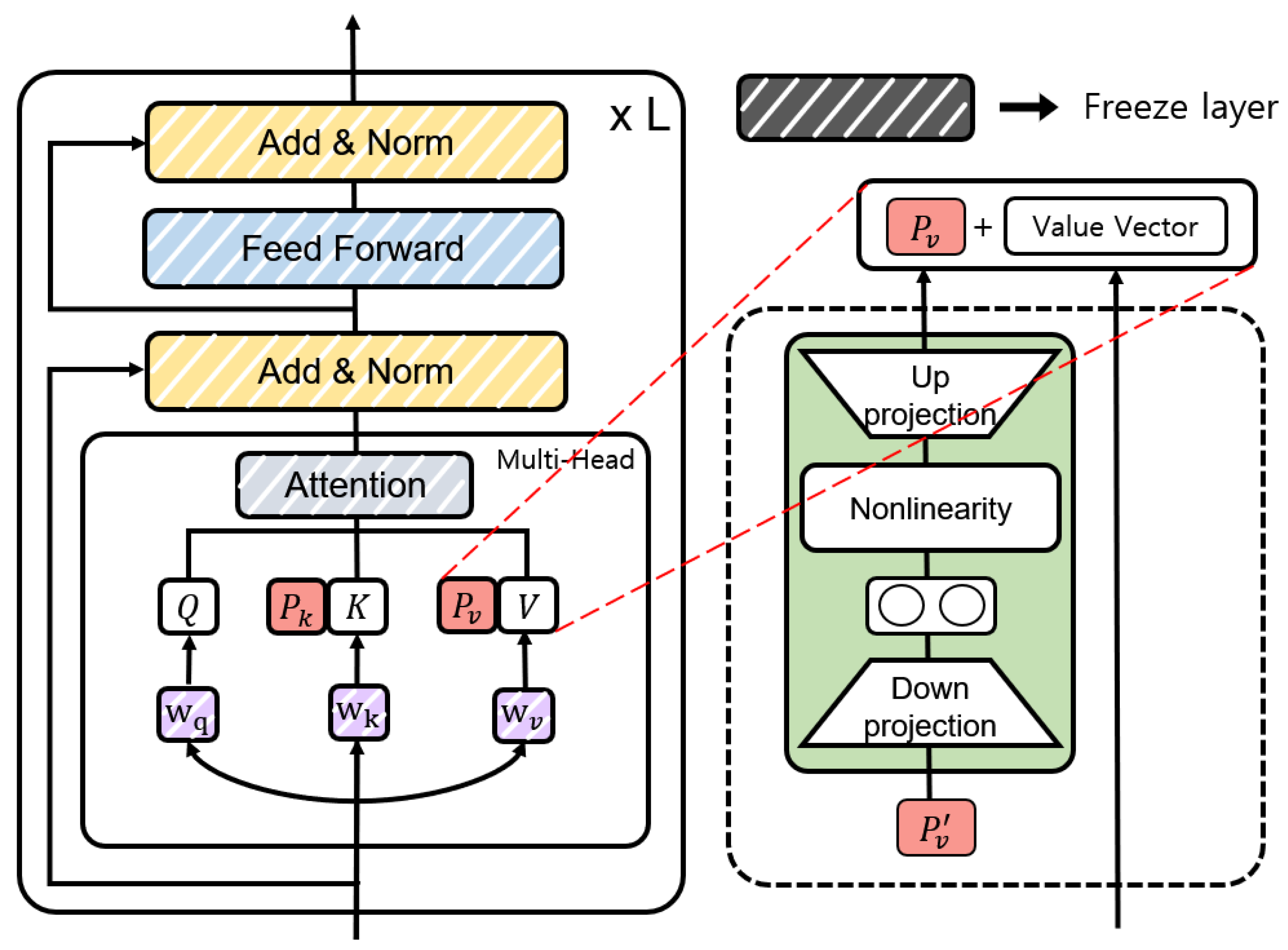
3.2. The Proposed Model
Figure 3 shows the encoder and decoder parts of
Figure 2 in detail. PEFTTOD incorporates a PEFT method within a pre-trained language model. The left part of
Figure 3 shows the structure of the existing system, while the right part represents the structure of PEFTTOD. PEFTTOD effectively compresses the hidden state information as it passes through the Attention Layer and Feed-Forward Layer and then transfers it to the subsequent layers. It then adds an Adapter, i.e., a trainable bottleneck layer, to each layer. In addition, within the attention mechanism, prefix tuning is performed to learn
and
. This allows the model to directly learn the prompt information within the language model itself, making the structure task-independent. Unlike the existing system, which combines prompts with input data on a task-specific basis, PEFTTOD learns and utilizes prompt information within the language model itself. In the following subsection, we describe the parallel Adapter and prefix tuning in more detail.
Figure 4 shows the structure with the parallel Adapter [
39] applied in PEFTTOD. PEFTTOD is a Transformer-based architecture that incorporates two Adapter Layers within a single layer and input value
x, replacing the input of the hidden state. The value
x represents the value before passing through the Attention Layer.
In Equation (
2),
down-projects the incoming hidden state
h,
f is a non-linear activation function,
up-projects the hidden state, and
r is the residual network. Here,
and
, where
is the hidden size and
is the bottleneck size. During training, the pre-trained language model combined with these Adapters freezes the parameters corresponding to the pre-trained language model, and only the Adapter is fine-tuned. Thus, the conversational knowledge can be efficiently forwarded within the pre-trained language model.
Figure 5 illustrates the structure of prefix tuning [
9] in PEFTTOD. We combined the key (
K) and value (
V) of the Transformer’s multi-head attention block with the prefix vectors
and
each of length
l.
and
are defined as
. However, if we use the combined prefix vector as a direct parameter, then the performance will degrade. To solve this problem, we stabilized
P by reparameterizing
through a neural network identical to the structure of the Adapter, as shown in Equation (
3) [
46].
where
,
,
f denotes the non-linear activation function,
is the hidden size, and
is the bottleneck size. This neural network only maintains the matrix corresponding to the reparameterized
P and can be removed after training. In the training step, the query of the Transformer’s attention block is defined as
, the key is
, and the value is
. Here,
M is the max sequence length. During training, as shown in Equation (
4), we concatenate the prefix vectors
and
in
K and
V, respectively, where
and
.
In PEFTTOD, the prefix tuning is trained by inserting a prefix vector into the attention mechanism of the pre-trained language model. This differs from the existing model where the prompt is combined with the input data in an arbitrary manner [
2]. In contrast, the prefix vectors
and
inserted inside the model allow for the learning of the prompt that is optimized specifically for the entire conversation system.
3.3. Domain Adaptation
The proposed system uses two methods for domain adaptation. The first way is to use a special token. Special tokens are specifically designed to identify different components of the inputs corresponding to different subtasks. As demonstrated by SimpleTOD [
31], the absence of special tokens can lead to the generation of much longer belief states, system actions, and system responses. Therefore, it is important to clearly distinguish between the user and the text of the system within the dialogue history of the system. To identify the user’s utterance, the system’s utterance, the dialogue state (belief state), the DB state, and the system action, the proposed system uses <sos_u>, <eos_u>, <sos_r>, <eos_r>, <sos_b>, <eos_b>, <sos_db>, <eos_db>, and <sos_a>, <eos_a>, respectively.
The second method employs delexicalization. The delexicalization method is a preprocessing method that groups specific slot values into categories [
21]. For example, if there is a slot called “Food” with various food options, the corresponding slots related to food are pre-processed and categorized as “Food”. During the generation process, the actual values are retrieved from the database and filled accordingly.
4. Evaluation
We evaluated the performance of PEFTTOD in the context of task-oriented dialogue systems for end-to-end dialogue modeling [
45]. The evaluation was conducted using the benchmark dataset Multi-WOZ 2.0 [
12]. The baseline model, PPTOD, which is described as a language model based on T5 [
11], was trained to acquire a significant amount of knowledge about the conversation domain. We conducted a comparative experiment according to the structure of the system combined with the PEFT method.
PPTOD uses a smaller model, and it was trained directly to replicate the same experimental setup as the proposed system. In
Table 1,
Table 2 and
Table 3, the baseline performance is indicated as “Fine-tuning”, while the performance of direct training is indicated as “Fine-tuning (our run)”. Additionally, “params” represents the trainable parameters of the language model with the PEFT method applied.
4.1. Dataset and Evaluation Metrics
The experiments used the Multi-Woz 2.0 dataset, which is widely used as a benchmark dataset for the task-oriented dialogue system. The dataset is a multi-domain dataset, which consists of 8438 conversations for seven domains: tourism, attractions, hospitals, police stations, hotels, restaurants, taxis, and trains. The experiment focused on five of these domains, excluding hospitals and police stations, due to the absence of dev and test data for these domains. Note that a single conversation can involve conversations from multiple domains and databases associated with the belief state are organized based on their respective domains. Therefore, the database state uses the dialogue state (belief state) generated through dialogue state tracking as a query to search from a predefined database and obtain the search result. The proposed system first predicts the dialogue state (belief state) through DST and searches the DB at the time of inference. Next, based on the DB state and dialogue history obtained as a search result, the system action and system response results are generated sequentially. To evaluate the performance of the model, an end-to-end dialogue modeling evaluation was conducted, which measured the quality of the generated belief state, system action, and system response when a user utterance is input. The model’s evaluation metrics followed the automatic evaluation metrics [
12]. The automatic evaluation metrics are widely used in dialogue system research utilizing the MultiWOZ 2.0 dataset. Inform measures whether the system has provided the correct entity, and success measures whether it has responded to all the requested information. Additionally, BLEU [
47] was used to assess the quality of the generated response. The combined score was the performance evaluation index proposed in [
48] and is shown as Equation (
5).
4.2. Adapter Types
This experiment evaluated the performance of the Adapters with different structures, namely the Houlsby Adapter and Parallel Adapter. These Adapters were compared with PPTOD, a model that was pre-trained on the conversation knowledge. The results are presented in
Table 1, indicating that the Parallel Adapter structure demonstrated the best performance among the evaluated options. Therefore, the paper leveraged this parallel Adapter structure for further experiments and analysis. Furthermore, we also explored the usage of prefix tuning on the dialogue system. When only prefix tuning was used, it resulted in a lack of communication knowledge within the language model. To address this limitation, the experiments in
Section 4.5 combined the use of prefix tuning with the Adapter structure.
Table 1.
Experimental results for Adapter types. In this and the following tables, the bold numbers indicate the highest performance for each criteria.
Table 1.
Experimental results for Adapter types. In this and the following tables, the bold numbers indicate the highest performance for each criteria.
| Method | Inform | Success | BLEU | Comb. | Params |
|---|
| Fine-tuning | 87.8 | 75.3 | 19.89 | 101.44 | 100% |
| Fine-tuning (our run) | 83.7 | 75.4 | 19.07 | 98.62 | 100% |
| Prefix tuning | 58.5 | 42.7 | 12.28 | 62.88 | 0.30% |
| Houlsby Adapter | 82.0 | 71.8 | 17.50 | 94.40 | 1.32% |
| Parallel Adapter | 83.4 | 74.0 | 19.14 | 97.84 | 1.32% |
4.3. Performance Comparison for the Number of Adapters
Generally, in a pre-trained language model, as more parameters are trained, the performance tends to improve [
7]. Therefore, this experiment investigated the impact of increasing the number of Adapter Layers.
Table 2 presents the results of this comparison for both the Houlsby Adapter and the Parallel Adapter. The numbers in the parentheses denote the number of Adapters connected in series. It was observed that, as the number of Adapter Layers increased, the performance of both Adapter structures improved. This suggested that incorporating more Adapter Layers enhanced the overall performance of the model. Notably, even when the parameters corresponding to the pre-trained language model were not trained, but the parameters related to the PEFT method increased, there was still a performance improvement. This indicated that the Adapter Layer played a crucial role. However, note that, when the Adapter number reached seven, we observed a performance degradation; thus, it is important to find the optimal number of Adapters to achieve the best performance.
Table 2.
Experimental results for the number of Adapters.
Table 2.
Experimental results for the number of Adapters.
| Method | Inform | Success | BLEU | Comb. | Params |
|---|
| Fine-tuning | 87.8 | 75.3 | 19.89 | 101.44 | 100% |
| Fine-tuning (our run) | 83.7 | 75.4 | 19.07 | 98.62 | 100% |
| Houlsby Adapter | 82.0 | 71.8 | 17.50 | 94.40 | 1.32% |
| Houlsby Adapter (3) | 87.8 | 77.3 | 17.73 | 100.28 | 3.96% |
| Houlsby Adapter (5) | 89.4 | 76.9 | 17.58 | 100.73 | 6.60% |
| Houlsby Adapter (7) | 85.6 | 77.7 | 17.62 | 99.27 | 9.24% |
| Parallel Adapter | 83.4 | 74.0 | 19.14 | 97.84 | 1.32% |
| Parallel Adapter (3) | 87.4 | 76.1 | 17.58 | 99.33 | 3.96% |
| Parallel Adapter (5) | 86.7 | 76.9 | 19.15 | 100.95 | 6.60% |
| Parallel Adapter (7) | 87.0 | 75.4 | 19.61 | 100.81 | 9.24% |
4.4. Prefix-Tuning Performance Comparison
In this experiment, we used the T5-based PPTOD-Small, which was trained to acquire conversation knowledge, in order to evaluate the performance of prefix tuning. PPTOD [
2] is a trained model that incorporates a prompt with the input data. Therefore, for the models that use prefix tuning, we excluded the combination of prompts with the input data during training.
Table 2 shows that the model with a combination of the Houlsby Adapters and Parallel Adapters in series for three and five times, respectively, achieved the highest performance. Hence, we incorporated prefix tuning into these Adapters in the experiments. In
Table 3, we observe that the model combining prefix tuning after connecting the Parallel Adapter three times in series yielded the best performance. Consequently, we named this proposed model PEFTTOD. The inclusion of prefix tuning in the model’s structure enhanced the performance by allowing the model to learn information related to specialized prompts within the conversation system, without explicitly combining prompts in the input data.
Table 3.
Experimental results for prefix tuning.
Table 3.
Experimental results for prefix tuning.
| Method | Inform | Success | BLEU | Comb. | Params |
|---|
| Fine-tuning | 87.8 | 75.3 | 19.89 | 101.44 | 100% |
| Fine-tuning (our run) | 83.7 | 75.4 | 19.07 | 98.62 | 100% |
| Houlsby Adapter (3) | 87.8 | 77.3 | 17.73 | 100.28 | 3.96% |
| Houlsby Adapter (3) + prefix tuning | 84.5 | 74.1 | 18.38 | 97.68 | 4.27% |
| Houlsby Adapter (5) | 89.4 | 76.9 | 17.58 | 100.73 | 6.60% |
| Houlsby Adapter (5) + prefix tuning | 88.3 | 77.4 | 18.01 | 100.86 | 6.90% |
| Parallel Adapter (3) | 87.4 | 76.1 | 17.58 | 99.33 | 3.96% |
| Parallel Adapter (3) + prefix tuning | 88.3 | 78.4 | 19.38 | 102.73 | 4.27% |
| Parallel Adapter (5) | 86.7 | 76.9 | 19.15 | 100.95 | 6.60% |
| Parallel Adapter (5) + prefix tuning | 86.5 | 75.2 | 18.92 | 99.77 | 6.90% |
4.5. Low-Resource Conditions
This experiment examined how effectively PEFTTOD can transfer conversational knowledge under low-resource conditions. The MultiWOZ 2.0 dataset was used, with training conducted using 1%, 5%, 10%, and 20% of the available training data. As presented in the results in
Table 4, when utilizing PEFTTOD with only 4.27% of the parameters compared to the baseline, the performance decreased at low-resource levels of 1% and 5%, but improved at higher-resource levels of 10% and 20%. This indicated that, even when PEFTTOD learns from a small number of parameters, if it exceeds the threshold of 10% on MultiWOZ 2.0, the performance begins to show improvement.
4.6. Prefix Length
In this experiment, we investigated the optimal length of the learnable vectors
and
, in the prefix tuning, as illustrated in
Figure 5. We explored the range of lengths for
and
from 3 to 15 to determine the optimal value. The results revealed that the optimal prefix length for PEFTTOD was 10. The results indicated that the optimal prefix length for PEFTTOD was 10. Therefore, finding the optimal prefix length was crucial to achieving the best performance (
Figure 6).
4.7. Efficiency
In order to evaluate the efficiency of PEFTTOD, we conducted experiments focusing on the training time and storage space. PEFTTOD takes advantage of the PEFT method by training only the Adapter Layers, without updating the baseline parameters. As a result, the training process is faster compared to traditional methods. Additionally, since only the parameters corresponding to the trained Adapter Layers are stored, significant storage space is saved.
The evaluation results in
Table 5 show that PEFTTOD improved the training time by over 20%, while utilizing only 4% of the parameters compared to the baseline model. Additionally, it achieved a remarkable 96% savings in the storage space requirement. These findings highlight the efficiency gains achieved by adopting PEFTTOD in task-oriented dialogue systems.
5. Conclusions and Future Work
This paper proposed a novel task-oriented dialogue system, called PEFTTOD, which incorporates the parameter-efficient language-model-tuning method. PEFTTOD leverages parallel Adapters and prefix tuning to efficiently train the conversation knowledge within a task-oriented dialogue system. Through experiments, we obtained the optimal Adapter structure and the number of stacks, and the effectiveness of combining the prefix tuning was demonstrated. The evaluation results revealed an improvement in the combined score, an evaluation metric of the Multi-Woz dataset, by 4% compared to the existing T5-based baseline model. Furthermore, despite utilizing only around 4% of the parameters compared to the baseline model, notable efficiency gains were achieved, including a 20% improvement in training speed and an approximately 96% reduction in storage space requirements.
As future work, we intend to extend our proposal to the open-domain dialogue systems rather than being limited to the task-oriented dialogue systems. Additionally, we plan to explore Adapters suitable for the ever-increasing large-scale pre-trained languages, in order to validate their effectiveness.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}