
Cooperative Guidance Strategy for Active Spacecraft Protection from a Homing Interceptor via Deep Reinforcement Learning



Abstract
:1. Introduction
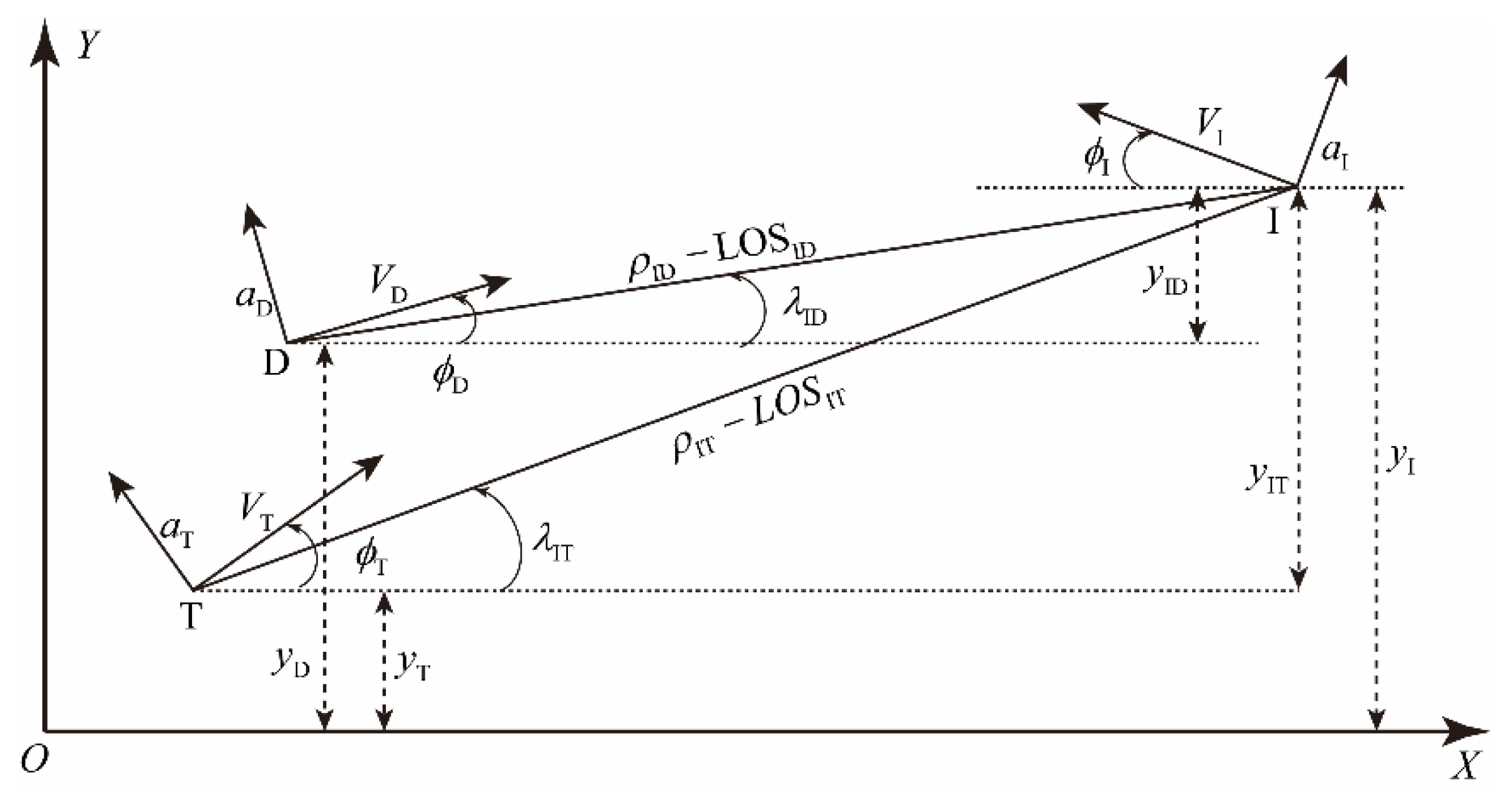
2. Problem Formulation
2.1. Equations of Motion
2.2. Linearized Equations of Motion
2.3. Zero-Effort Miss
2.4. Problem Statement
3. Guidance Law Development
3.1. Markov Decision Process
3.1.1. Perfect Information Model
3.1.2. Imperfect Information Model
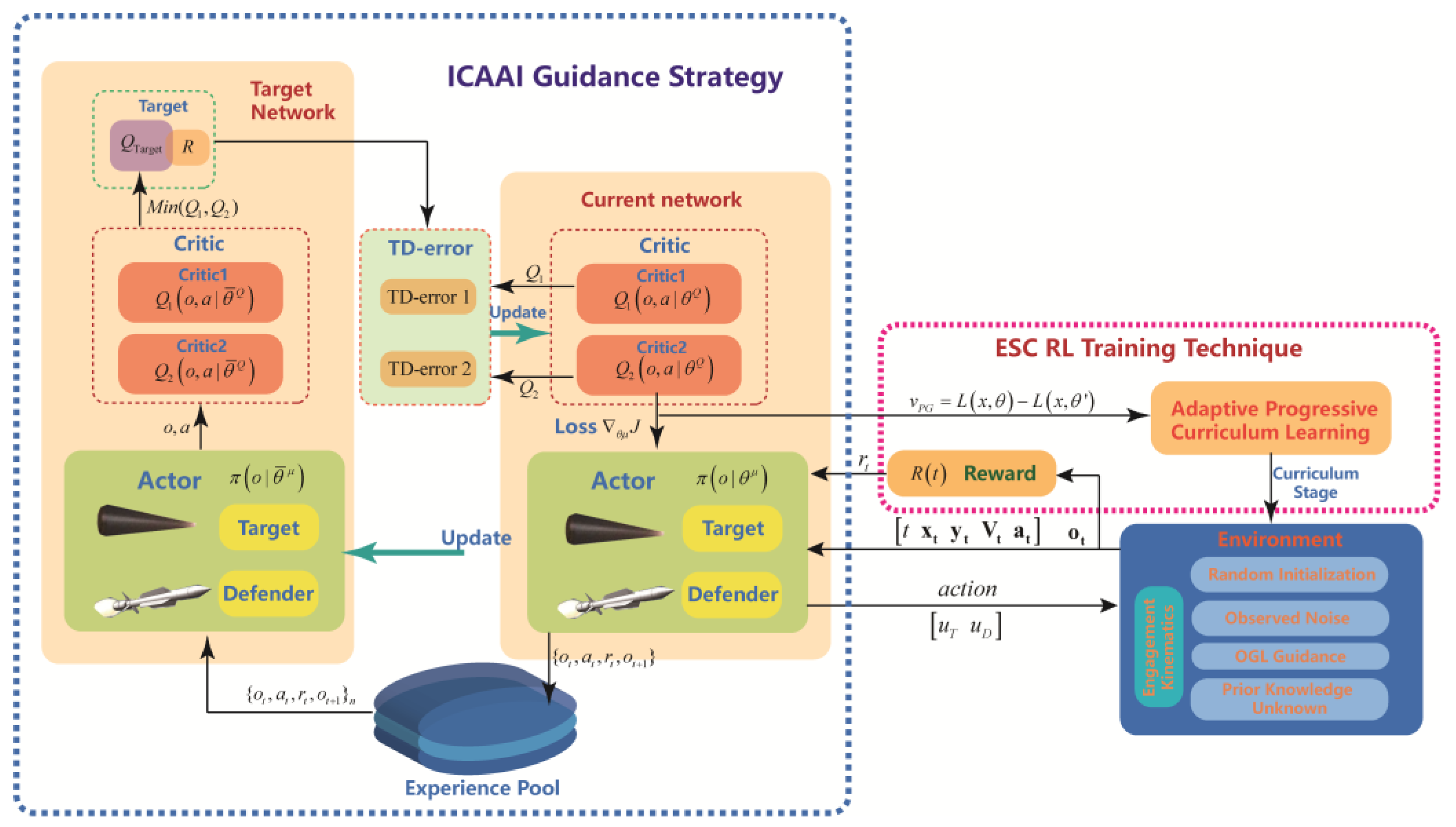
3.2. ICAAI Guidance Law Design
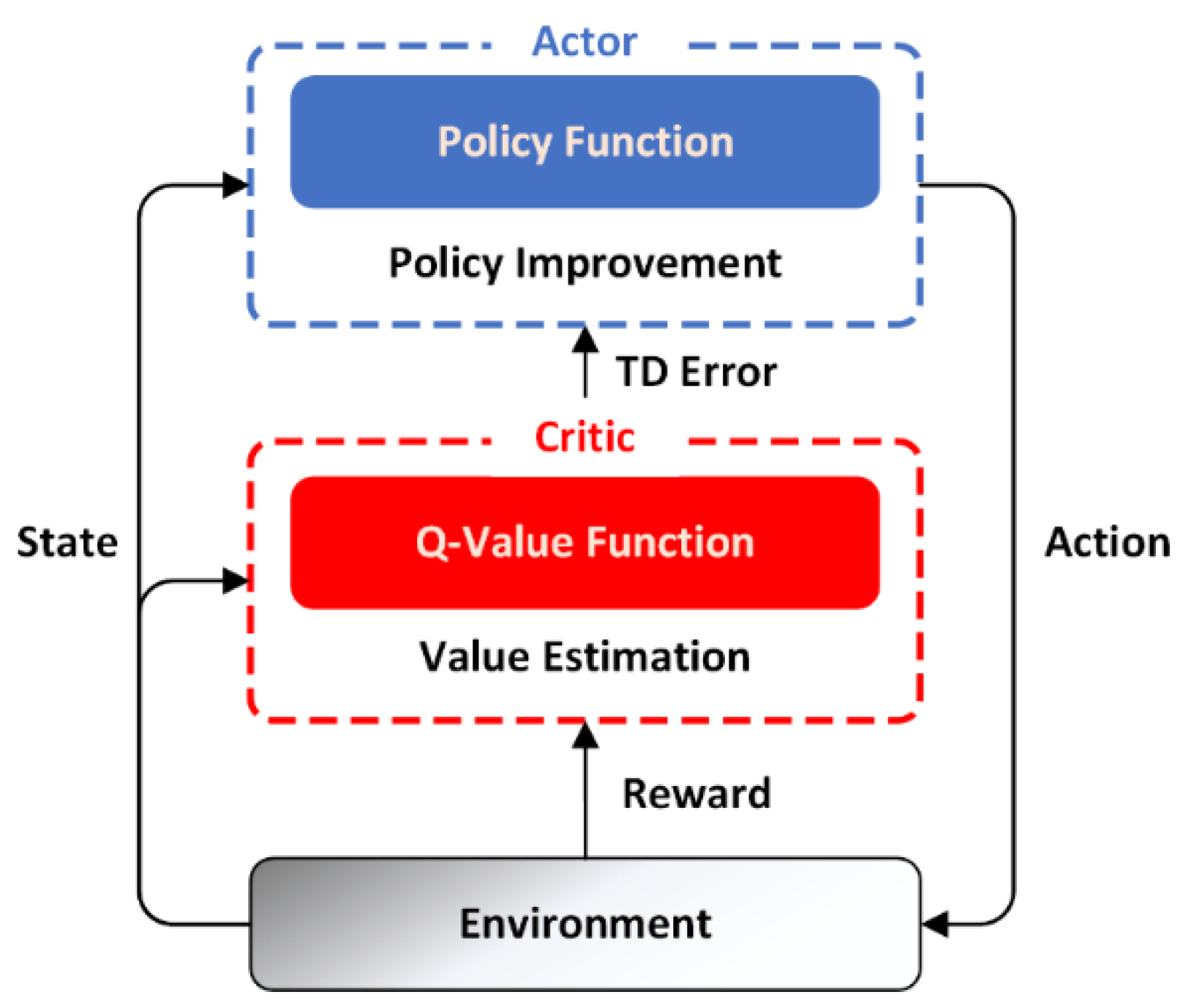
3.2.1. Actor–Critic Algorithms
3.2.2. Twin-Delayed Deep Deterministic Policy Gradient Algorithm
3.2.3. Implementation Details
3.3. ESC Traning Technique
3.3.1. Reward Shaping
3.3.2. Curriculum Learning
- The agent is required to combat the interceptors employing non-maneuvering;
- Square wave signal;
- OGL.
4. Experiments
4.1. Optimal Pursuit and Evasion Guidance Laws
4.2. Engagement Setup
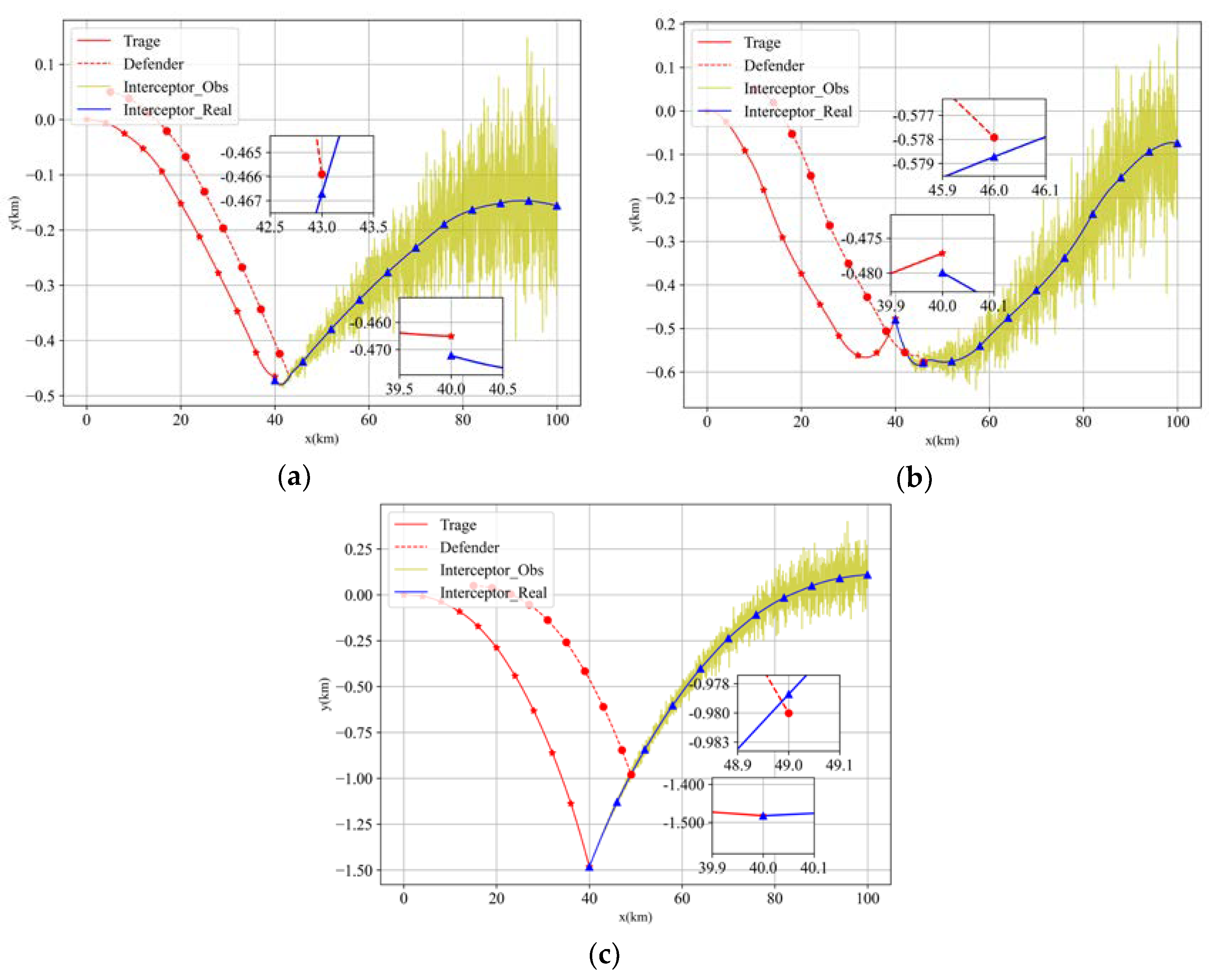
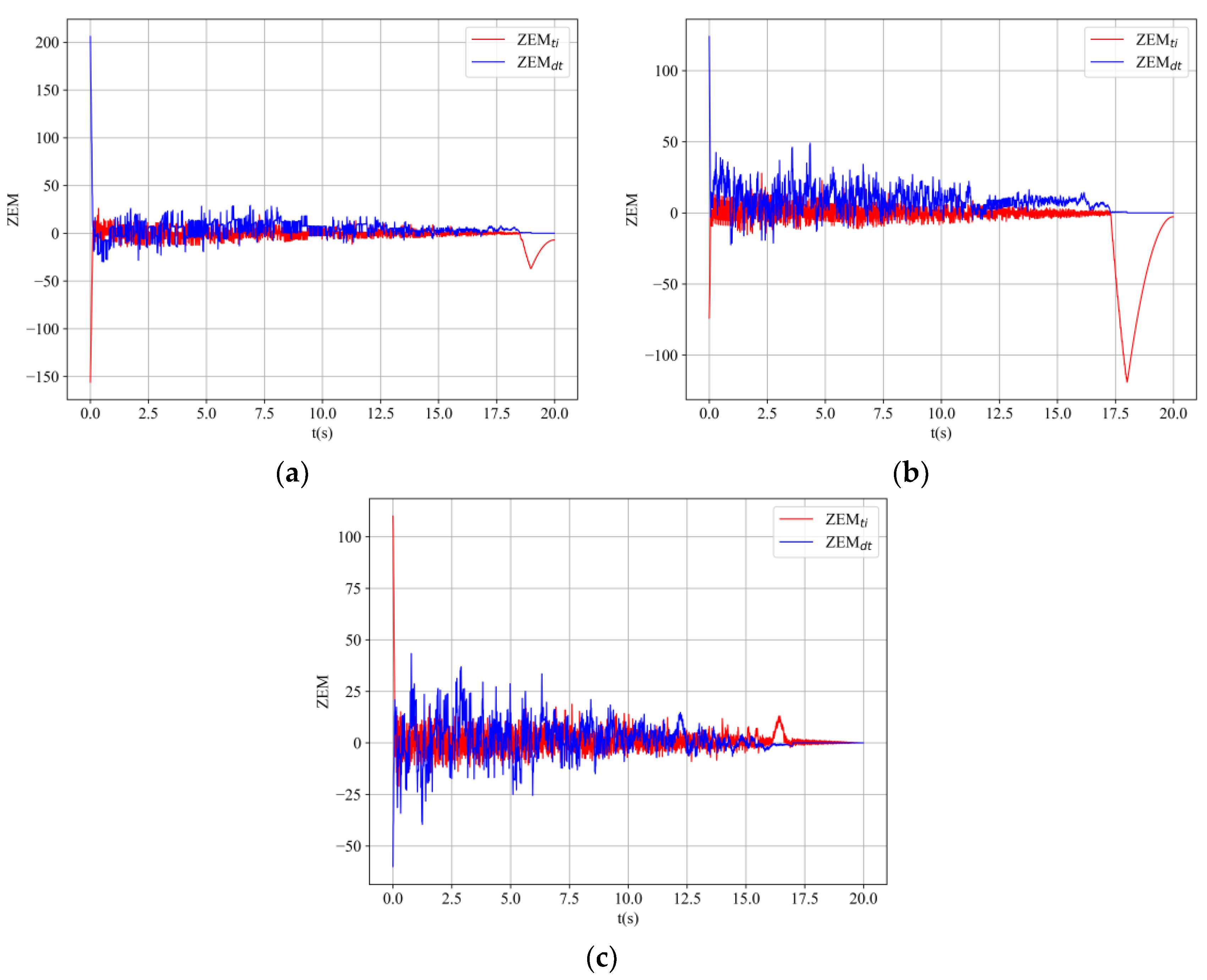
4.3. Experiment 1: Real-Time Performance of the Guidance Policy
4.4. Experiment 2: Convergence and Performance of the Guidance Policy
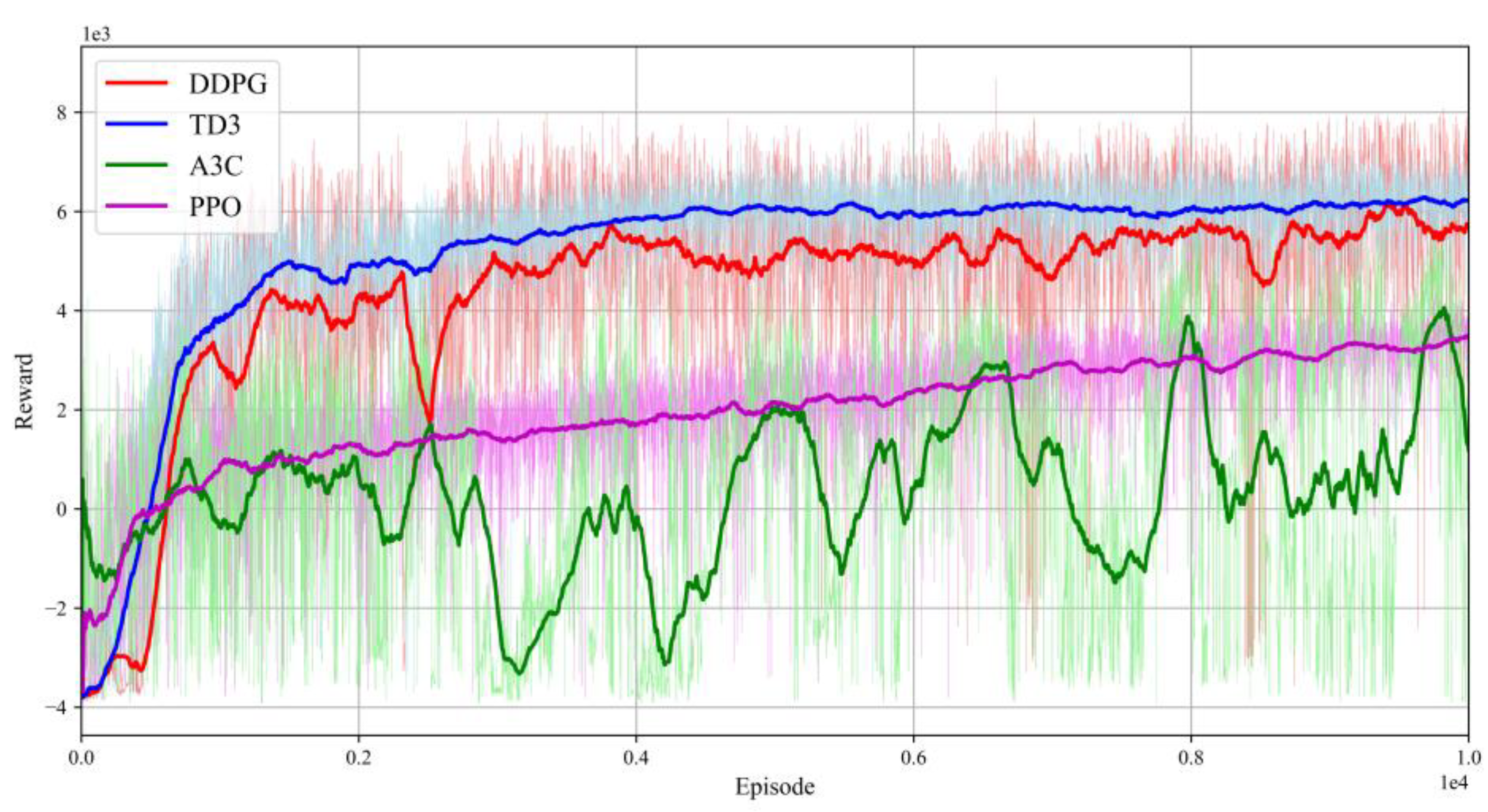
4.4.1. Baselines
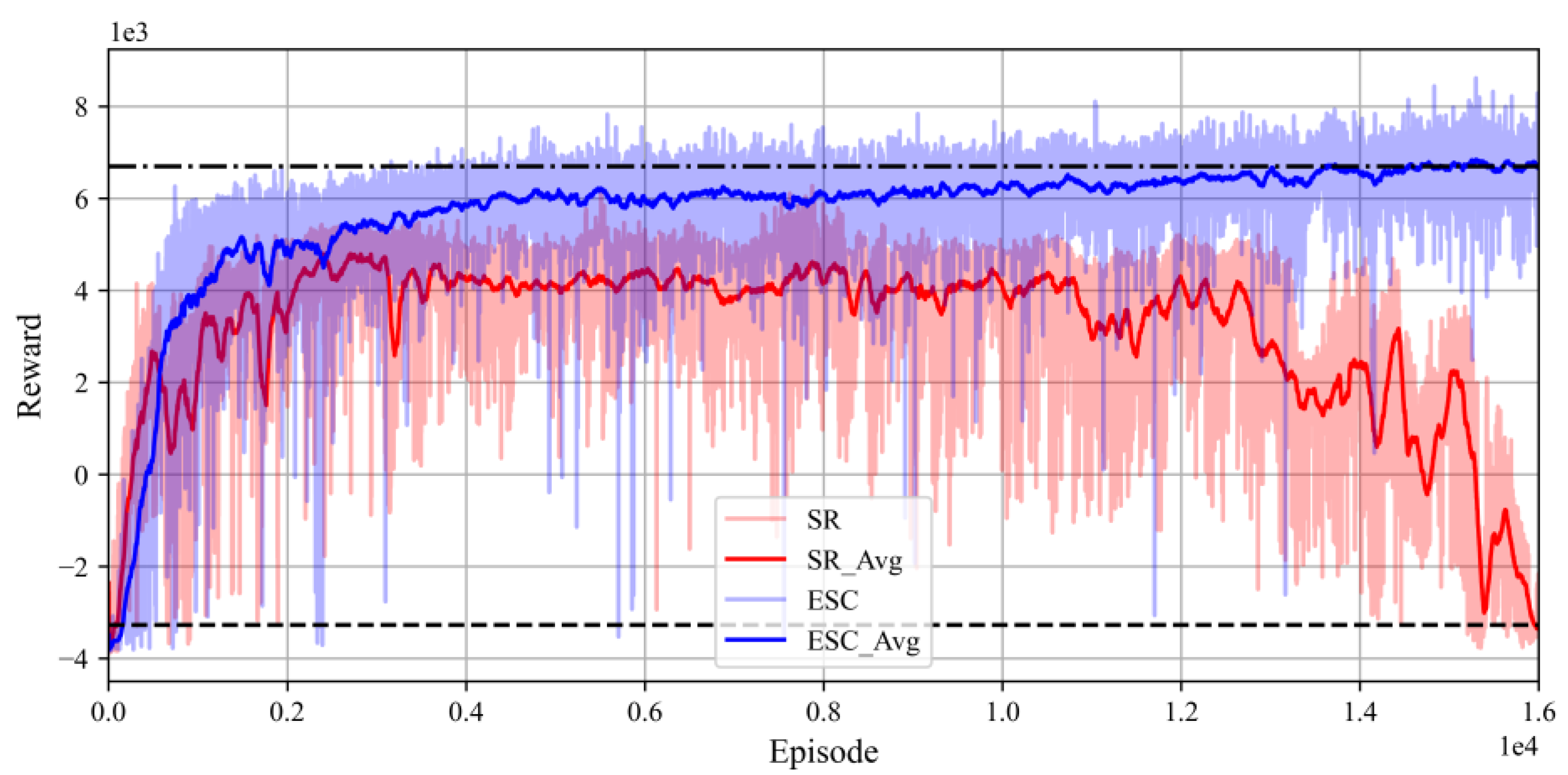
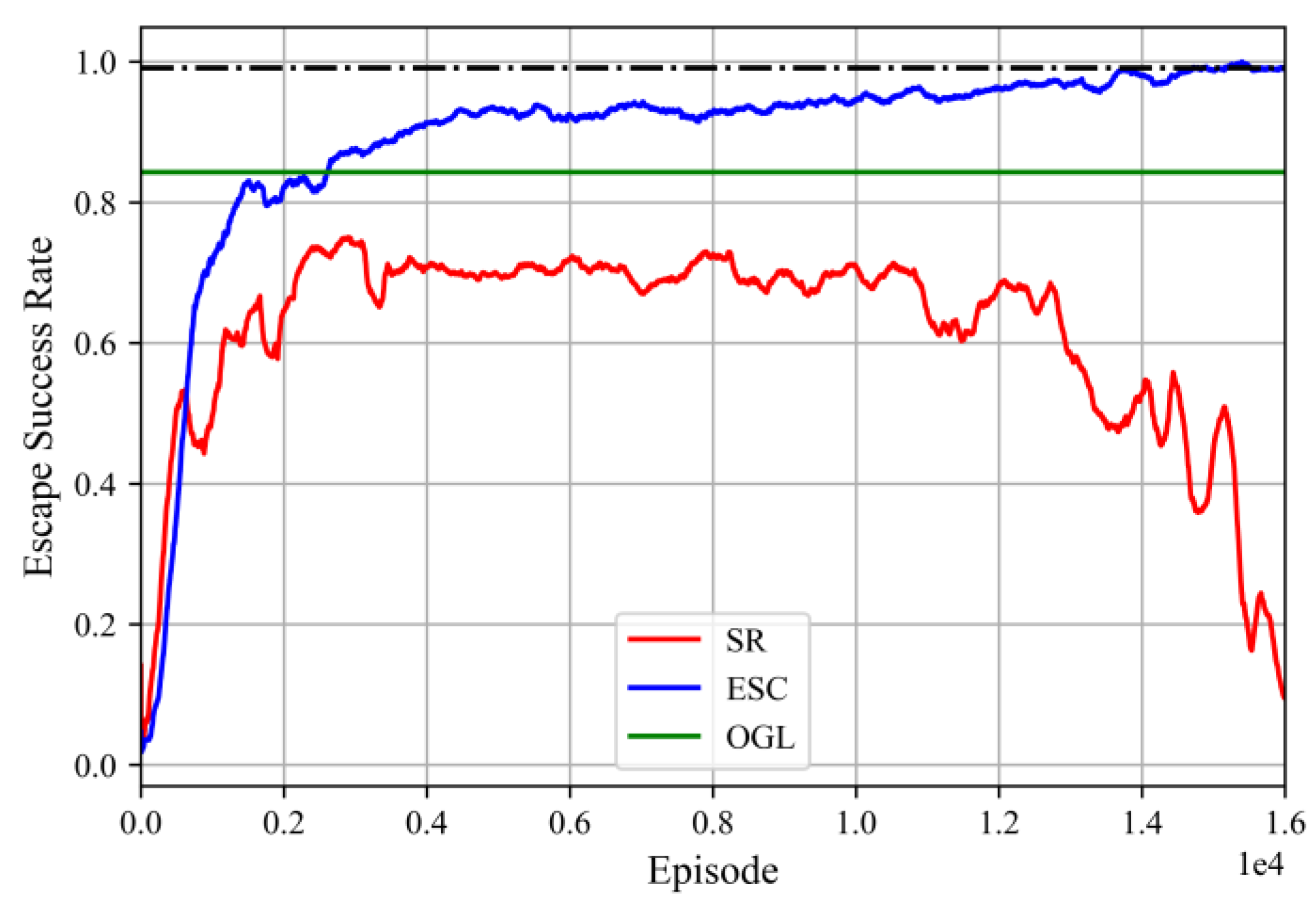
4.4.2. Convergence and Escape Success Rate
4.4.3. Performance Test
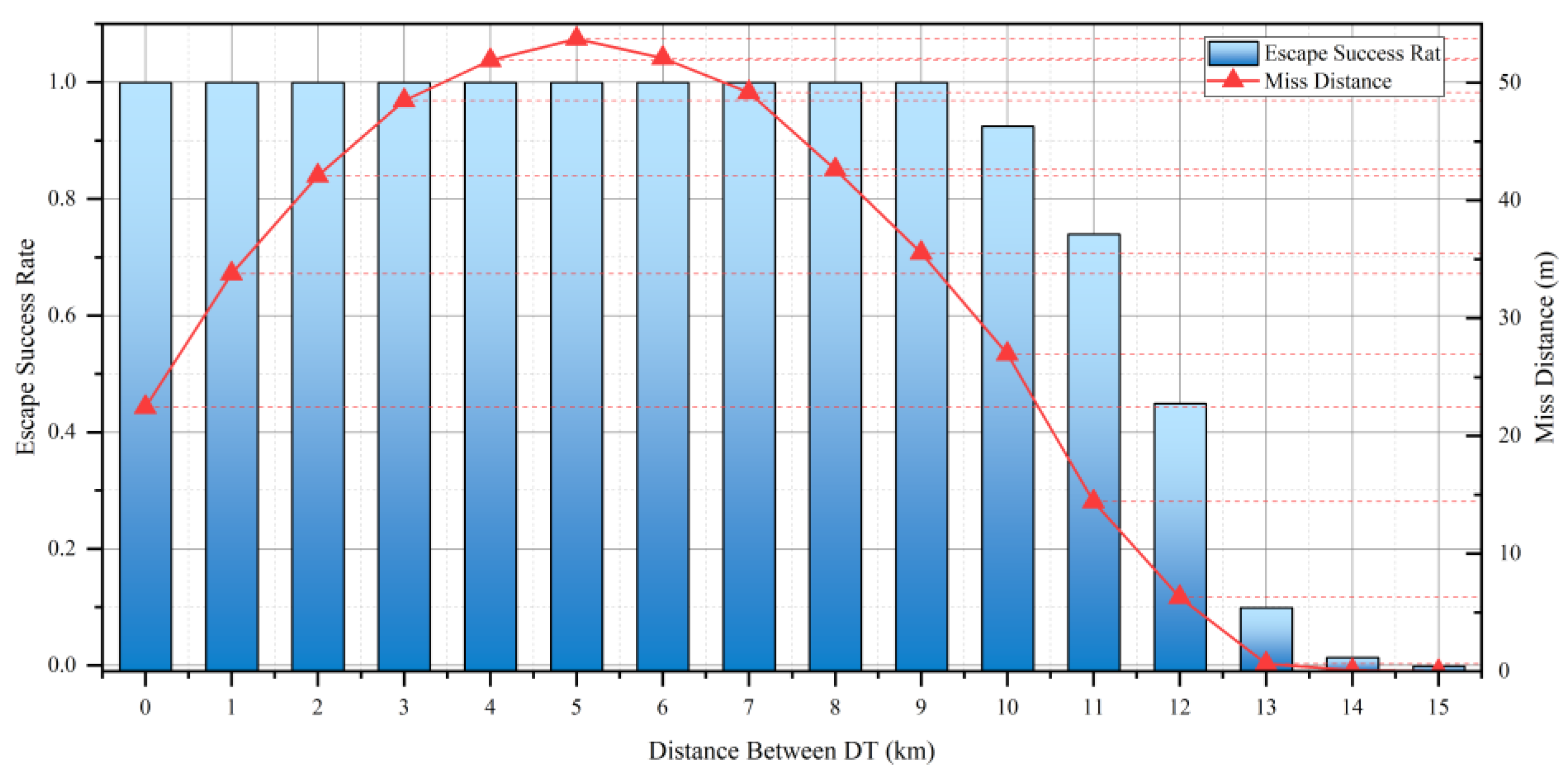
4.5. Experiment 3: Adaptiveness of the ICAAI Guidance
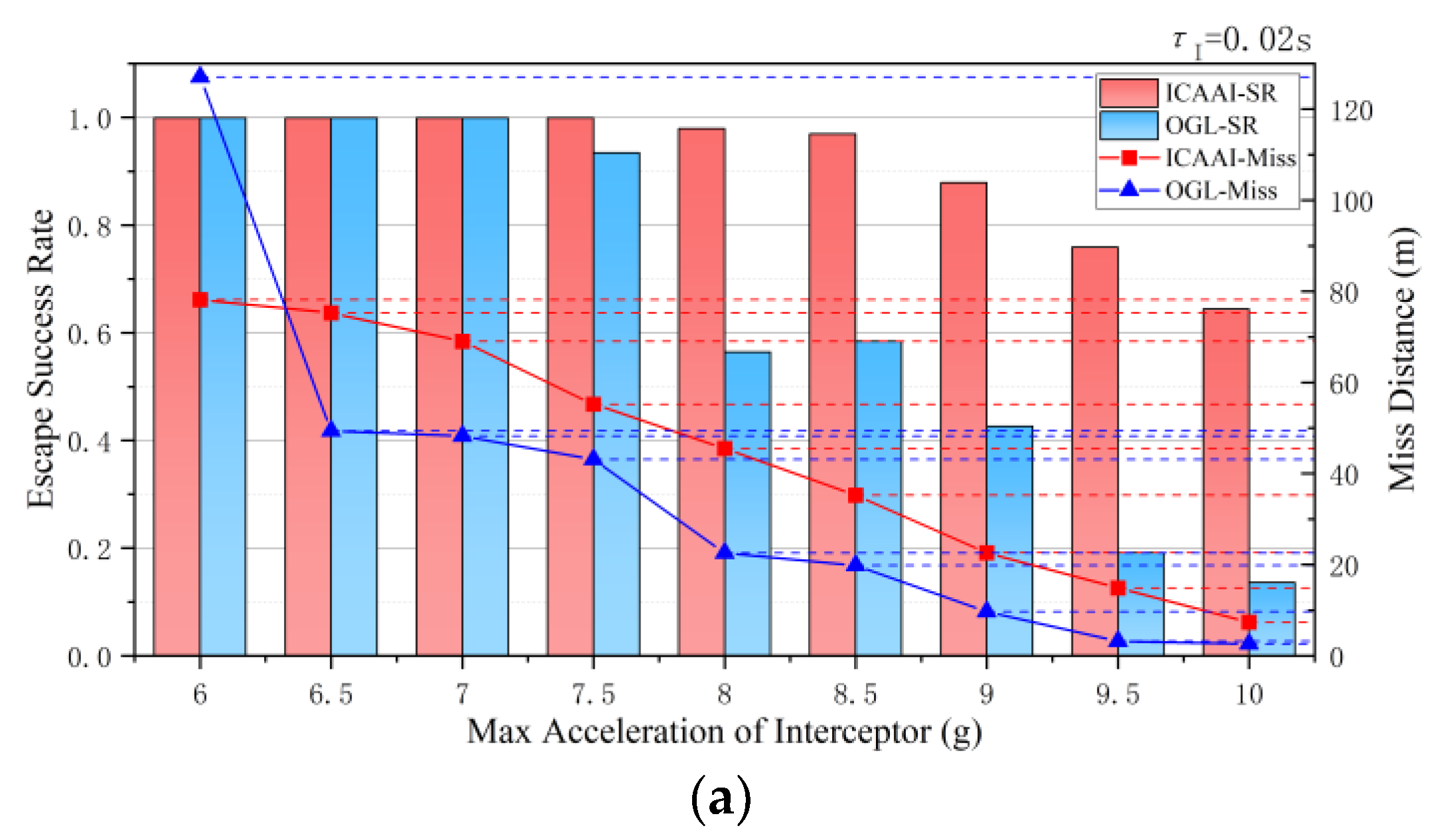
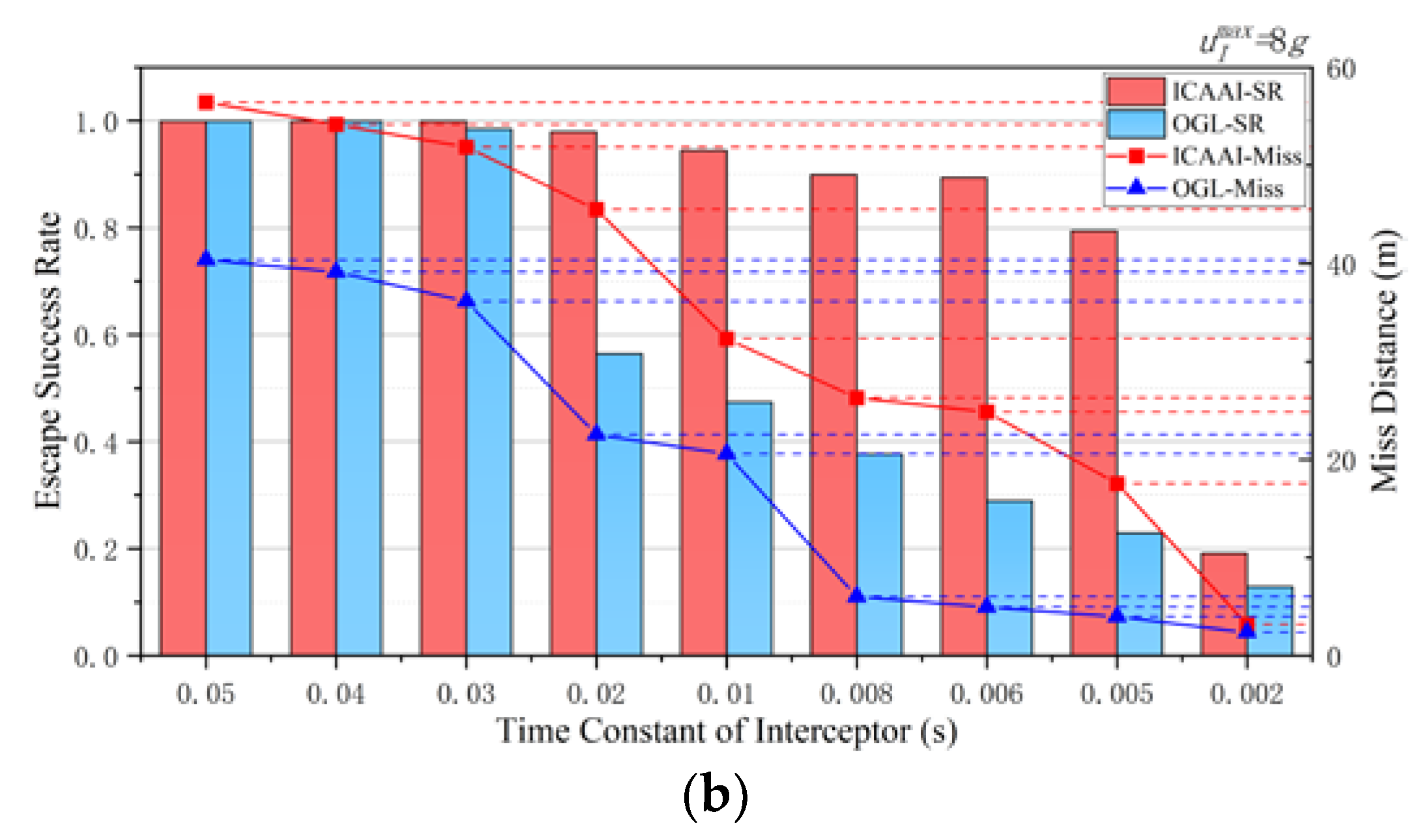
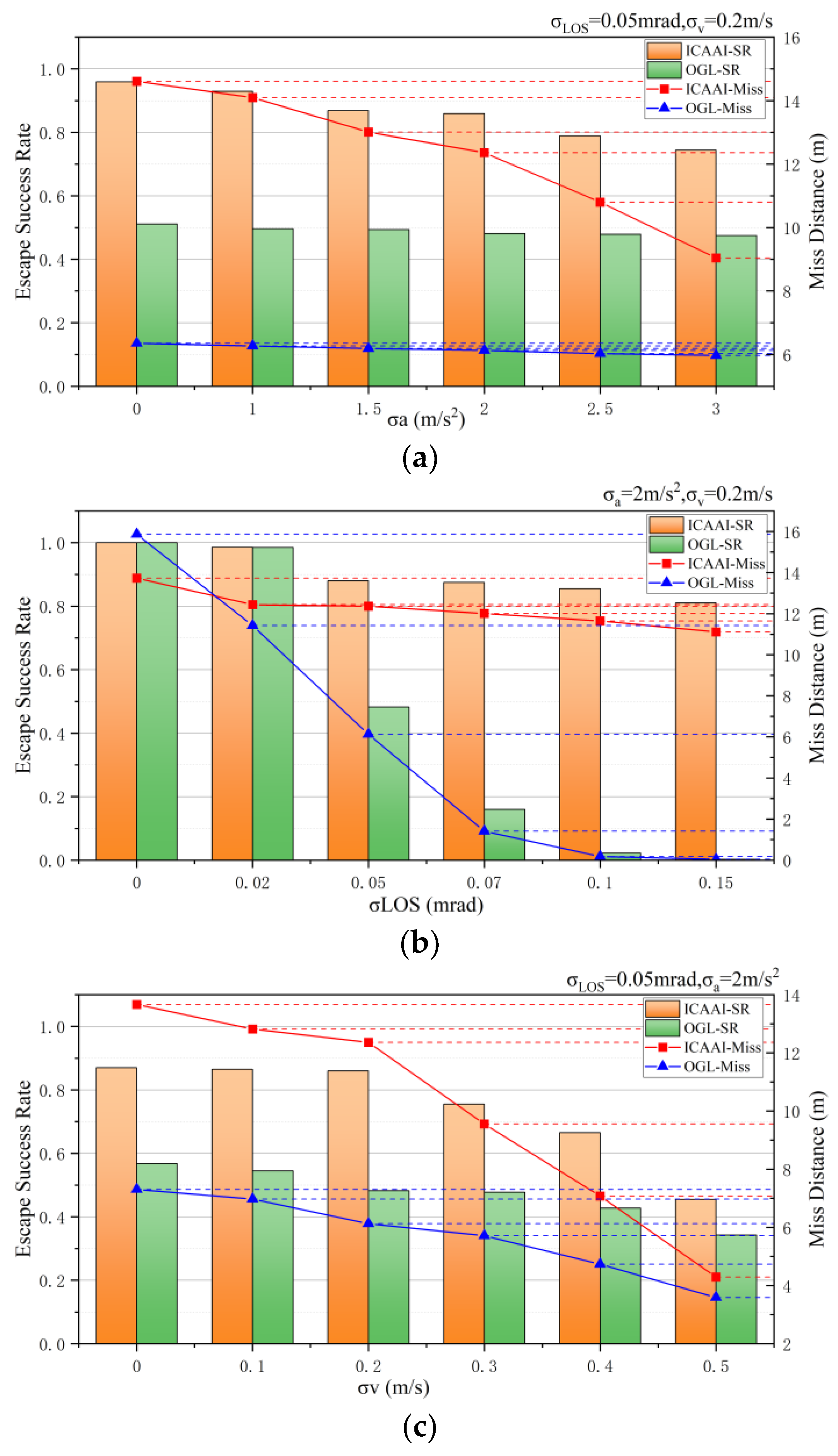
4.6. Experiment 4: Robustness of the RL-Based Guidance Method
5. Conclusions
- (1)
- In the presence of less prior knowledge and observation noise, the proposed ICAAI guidance strategy is effective in achieving a higher success rate of target evasion by guiding the target to coordinate maneuvers with defensive spacecraft.
- (2)
- Utilizing a heuristic continuous reward function and an adaptive progressive curriculum learning method, we devised the ESC training approach to effectively tackle issues of low convergence efficiency and training process instability in ICAAI.
- (3)
- The ICAAI guidance strategy outperforms the linear–quadratic optimal guidance law (LQOGL) [10] in real-time performance. This framework also achieved an impressive update frequency of Hz, demonstrating substantial potential for onboard applications.
- (4)
- Simulation results confirm ICAAI’s effectiveness in reducing the relative distance between interceptor and defender, enabling successful target evasion. In contrast to traditional OGL methods, our approach exhibits enhanced robustness in noisy environments, particularly in mitigating line-of-sight (LOS) noise.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| acceleration, | |
| state-space model of the linearized equations of motion | |
| Hamiltonian | |
| identity matrix | |
| cost function | |
| constant vector | |
| inverse Laplace transform | |
| light-of-sight | |
| reward signal | |
| reward signal | |
| state defined in Markov decision process | |
| observation of the agent | |
| time, time to go, and final time, respectively, s | |
| guidance command, | |
| velocity, | |
| Cartesian reference frame | |
| state vector of the linearized equations of motion | |
| lateral distance, m | |
| zero-effort-miss, m | |
| design parameters of the reward function | |
| flight path angle, rad | |
| transition matrix | |
| discount factor | |
| killing radius, m | |
| the angle between the corresponding light-of-sight and X-axis, rad | |
| Lagrange multiplier vector | |
| policy function | |
| relative distance between the adversaries, m | |
| time constant | |
| design parameters of the optimal guidance law (OGL) | |
| interceptor, target, and defender, respectively | |
| maximum | |
| optimal solution |
References
- Ye, D.; Shi, M.; Sun, Z. Satellite proximate pursuit-evasion game with different thrust configurations. Aerosp. Sci. Technol. 2020, 99, 105715. [Google Scholar] [CrossRef]
- Boyell, R.L. Defending a moving target against missile or torpedo attack. IEEE Trans. Aerosp. Electron. Syst. 1976, AES-12, 522–526. [Google Scholar] [CrossRef]
- Rusnak, I. Guidance laws in defense against missile attack. In Proceedings of the 2008 IEEE 25th Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, 3–5 December 2008; pp. 090–094. [Google Scholar]
- Rusnak, I. The lady, the bandits and the body guards—A two team dynamic game. IFAC Proc. Vol. 2005, 38, 441–446. [Google Scholar] [CrossRef]
- Shalumov, V. Optimal cooperative guidance laws in a multiagent target–missile–defender engagement. J. Guid. Control Dyn. 2019, 42, 1993–2006. [Google Scholar] [CrossRef]
- Weiss, M.; Shima, T.; Castaneda, D.; Rusnak, I. Combined and cooperative minimum-effort guidance algorithms in an active aircraft defense scenario. J. Guid. Control Dyn. 2017, 40, 1241–1254. [Google Scholar] [CrossRef]
- Weiss, M.; Shima, T.; Castaneda, D.; Rusnak, I. Minimum effort intercept and evasion guidance algorithms for active aircraft defense. J. Guid. Control Dyn. 2016, 39, 2297–2311. [Google Scholar] [CrossRef]
- Shima, T. Optimal cooperative pursuit and evasion strategies against a homing missile. J. Guid. Control. Dyn. 2011, 34, 414–425. [Google Scholar] [CrossRef]
- Perelman, A.; Shima, T.; Rusnak, I. Cooperative differential games strategies for active aircraft protection from a homing missile. J. Guid. Control Dyn. 2011, 34, 761–773. [Google Scholar] [CrossRef]
- Liang, H.; Wang, J.; Wang, Y.; Wang, L.; Liu, P. Optimal guidance against active defense ballistic missiles via differential game strategies. Chin. J. Aeronaut. 2020, 33, 978–989. [Google Scholar] [CrossRef]
- Anderson, G.M. Comparison of optimal control and differential game intercept missile guidance laws. J. Guid. Control 1981, 4, 109–115. [Google Scholar] [CrossRef]
- Dong, J.; Zhang, X.; Jia, X. Strategies of pursuit-evasion game based on improved potential field and differential game theory for mobile robots. In Proceedings of the 2012 Second International Conference on Instrumentation, Measurement, Computer, Communication and Control, Harbin, China, 8–10 December 2012; pp. 1452–1456. [Google Scholar]
- Li, Z.; Wu, J.; Wu, Y.; Zheng, Y.; Li, M.; Liang, H. Real-time Guidance Strategy for Active Defense Aircraft via Deep Reinforcement Learning. In Proceedings of the NAECON 2021-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 16–19 August 2021; pp. 177–183. [Google Scholar]
- Liang, H.; Li, Z.; Wu, J.; Zheng, Y.; Chu, H.; Wang, J. Optimal Guidance Laws for a Hypersonic Multiplayer Pursuit-Evasion Game Based on a Differential Game Strategy. Aerospace 2022, 9, 97. [Google Scholar] [CrossRef]
- Liu, F.; Dong, X.; Li, Q.; Ren, Z. Cooperative differential games guidance laws for multiple attackers against an active defense target. Chin. J. Aeronaut. 2022, 35, 374–389. [Google Scholar] [CrossRef]
- Weintraub, I.E.; Cobb, R.G.; Baker, W.; Pachter, M. Direct methods comparison for the active target defense scenario. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 0612. [Google Scholar]
- Shalumov, V. Cooperative online guide-launch-guide policy in a target-missile-defender engagement using deep reinforcement learning. Aerosp. Sci. Technol. 2020, 104, 105996. [Google Scholar] [CrossRef]
- Liang, H.; Wang, J.; Liu, J.; Liu, P. Guidance strategies for interceptor against active defense spacecraft in two-on-two engagement. Aerosp. Sci. Technol. 2020, 96, 105529. [Google Scholar] [CrossRef]
- Salmon, J.L.; Willey, L.C.; Casbeer, D.; Garcia, E.; Moll, A.V. Single pursuer and two cooperative evaders in the border defense differential game. J. Aerosp. Inf. Syst. 2020, 17, 229–239. [Google Scholar] [CrossRef]
- Harel, M.; Moshaiov, A.; Alkaher, D. Rationalizable strategies for the navigator–target–missile game. J. Guid. Control Dyn. 2020, 43, 1129–1142. [Google Scholar] [CrossRef]
- Miljković, Z.; Mitić, M.; Lazarević, M.; Babić, B. Neural network reinforcement learning for visual control of robot manipulators. Expert Syst. Appl. 2013, 40, 1721–1736. [Google Scholar] [CrossRef]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H. Towards playing full moba games with deep reinforcement learning. arXiv 2020, arXiv:2011.12692. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv 2016, arXiv:1610.03295. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May 2017–3 June 2017; pp. 3357–3364. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Gaudeta, B.; Furfaroa, R.; Linares, R. Reinforcement meta-learning for angle-only intercept guidance of maneuvering targets. In Proceedings of the AIAA Scitech 2020 Forum AIAA 2020, Orlando, FL, USA, 6–10 January 2020; Volume 609. [Google Scholar]
- Gaudet, B.; Linares, R.; Furfaro, R. Adaptive guidance and integrated navigation with reinforcement meta-learning. Acta Astronaut. 2020, 169, 180–190. [Google Scholar] [CrossRef]
- Lau, M.; Steffens, M.J.; Mavris, D.N. Closed-loop control in active target defense using machine learning. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019; p. 0143. [Google Scholar]
- Zhang, G.; Chang, T.; Wang, W.; Zhang, W. Hybrid threshold event-triggered control for sail-assisted USV via the nonlinear modified LVS guidance. Ocean Eng. 2023, 276, 114160. [Google Scholar] [CrossRef]
- Li, J.; Zhang, G.; Shan, Q.; Zhang, W. A novel cooperative design for USV-UAV systems: 3D mapping guidance and adaptive fuzzy control. IEEE Trans. Control Netw. Syst. 2022, 10, 564–574. [Google Scholar] [CrossRef]
- Ainsworth, M.; Shin, Y. Plateau phenomenon in gradient descent training of RELU networks: Explanation, quantification, and avoidance. SIAM J. Sci. Comput. 2021, 43, A3438–A3468. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In PMLR, Proceedings of Machine Learning Research, Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; PMLR: New York, NY, USA, 2018; Volume 80, pp. 1587–1596. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Babaeizadeh, M.; Frosio, I.; Tyree, S.; Clemons, J.; Kautz, J. Reinforcement learning through asynchronous advantage actor-critic on a gpu. arXiv 2016, arXiv:1611.06256. [Google Scholar]
- Casas, N. Deep deterministic policy gradient for urban traffic light control. arXiv 2017, arXiv:1703.09035. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In PMLR, Proceedings of Machine Learning Research, Proceedings of the 31st International Conference on Machine Learning, Beijing China, 21–26 June 2014; PMLR: New York, NY, USA, 2014; Volume 32, pp. 387–395. [Google Scholar]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A Theoretical Analysis of Deep Q-Learning. In PMLR, Proceedings of Machine Learning Research, Proceedings of the 2nd Conference on Learning for Dynamics and Control, Online, 10–11 June 2020; PMLR: New York, NY, USA, 2020; Volume 120, pp. 486–489. [Google Scholar]
- Hasselt, H. Double Q-learning. In Advances in Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2010; Volume 23. [Google Scholar]
- Gullapalli, V.; Barto, A.G. Shaping as a method for accelerating reinforcement learning. In Proceedings of the 1992 IEEE International Symposium on Intelligent Control, Glasgow, UK, 11–13 August 1992; pp. 554–559. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Krueger, K.A.; Dayan, P. Flexible shaping: How learning in small steps helps. Cognition 2009, 110, 380–394. [Google Scholar] [CrossRef]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. LCML 1999, 99, 278–287. [Google Scholar]
- Randløv, J.; Alstrøm, P. Learning to Drive a Bicycle Using Reinforcement Learning and Shaping. ICML 1998, 98, 463–471. [Google Scholar]
- Wiewiora, E. Potential-based shaping and Q-value initialization are equivalent. J. Artif. Intell. Res. 2003, 19, 205–208. [Google Scholar] [CrossRef]
- Qi, N.; Sun, Q.; Zhao, J. Evasion and pursuit guidance law against defended target. Chin. J. Aeronaut. 2017, 30, 1958–1973. [Google Scholar] [CrossRef]
- Ho, Y.; Bryson, A.; Baron, S. Differential games and optimal pursuit-evasion strategies. IEEE Trans. Autom. Control 1965, 10, 385–389. [Google Scholar] [CrossRef]
- Shinar, J.; Steinberg, D. Analysis of Optimal Evasive Maneuvers Based on a Linearized Two-Dimensional Kinematic Model. J. Aircr. 1977, 14, 795–802. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Symbol | Value |
|---|---|---|
| Discount factor | 0.99 | |
| Learning rate | ||
| Buffer size | 5120 | |
| Batch size | 128 | |
| Soft update coefficient | ||
| Policy delay | 2 | |
| Train frequency | 6000 |
| Curriculum | Stage 1 | Stage 2 | Stage 3 |
|---|---|---|---|
| Interceptor guidance command | None | Square wave signal | OGL |
| Maximum interceptor acceleration | 0 | 8 g | 4 g/6 g/8 g |
| Interceptor | Interceptor | Target | Defender | |
|---|---|---|---|---|
| Parameters | ||||
| Horizonal location (km) | 100 | 0 | 0~15 | |
| Vertical location (km) | 499.8~500.2 | 500 | 500.05 | |
| Horizonal velocity (km/s) | −3 | 2 | 2 | |
| Vertical velocity | 0 | 0 | 0 | |
| Maximum acceleration (g) | 8 | 2 | 6 | |
| Time constant (s) | 0.02 | 0.1 | 0.05 | |
| Kill radius (m) | 0.25 | 0.5 | 0.15 | |
| Metrics | LQOGL | SOGL | ICAAI |
|---|---|---|---|
| Duration (1e3 step) | 2.773 s | 0.0145 s | 0.910 s |
| Update frequency |
| Measurement Noise | Parameter | Case 1 | Case 2 | Case 3 |
|---|---|---|---|---|
| LOS | 0.05 | 0~0.2 | 0.05 | |
| Velocity | 0.2 | 0.2 | 0~0.5 | |
| Acceleration | 1~3 | 2 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, W.; Liu, J.; Li, Z.; Liu, P.; Liang, H. Cooperative Guidance Strategy for Active Spacecraft Protection from a Homing Interceptor via Deep Reinforcement Learning. Mathematics 2023, 11, 4211. https://doi.org/10.3390/math11194211
Ni W, Liu J, Li Z, Liu P, Liang H. Cooperative Guidance Strategy for Active Spacecraft Protection from a Homing Interceptor via Deep Reinforcement Learning. Mathematics. 2023; 11(19):4211. https://doi.org/10.3390/math11194211
Chicago/Turabian StyleNi, Weilin, Jiaqi Liu, Zhi Li, Peng Liu, and Haizhao Liang. 2023. "Cooperative Guidance Strategy for Active Spacecraft Protection from a Homing Interceptor via Deep Reinforcement Learning" Mathematics 11, no. 19: 4211. https://doi.org/10.3390/math11194211
APA StyleNi, W., Liu, J., Li, Z., Liu, P., & Liang, H. (2023). Cooperative Guidance Strategy for Active Spacecraft Protection from a Homing Interceptor via Deep Reinforcement Learning. Mathematics, 11(19), 4211. https://doi.org/10.3390/math11194211