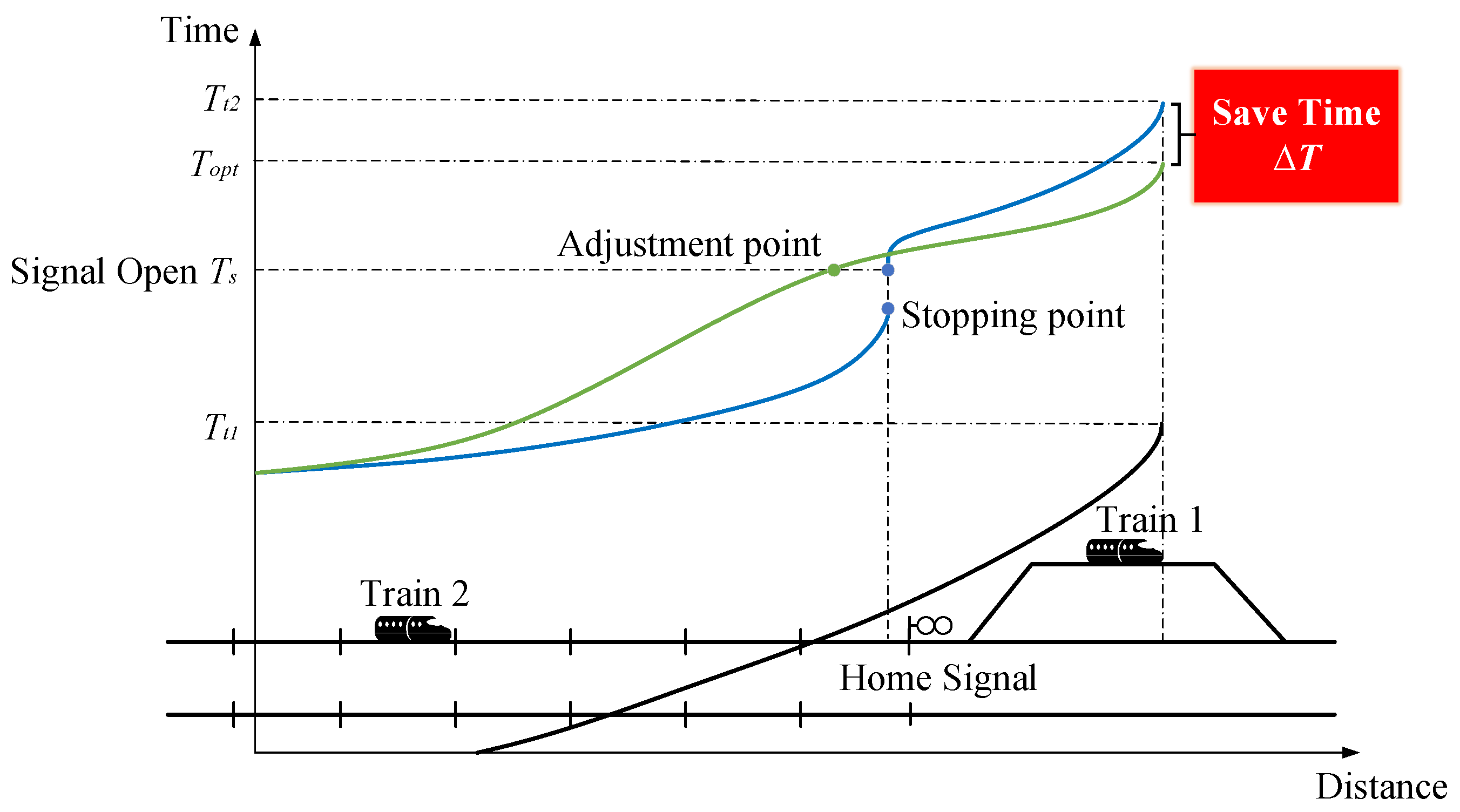
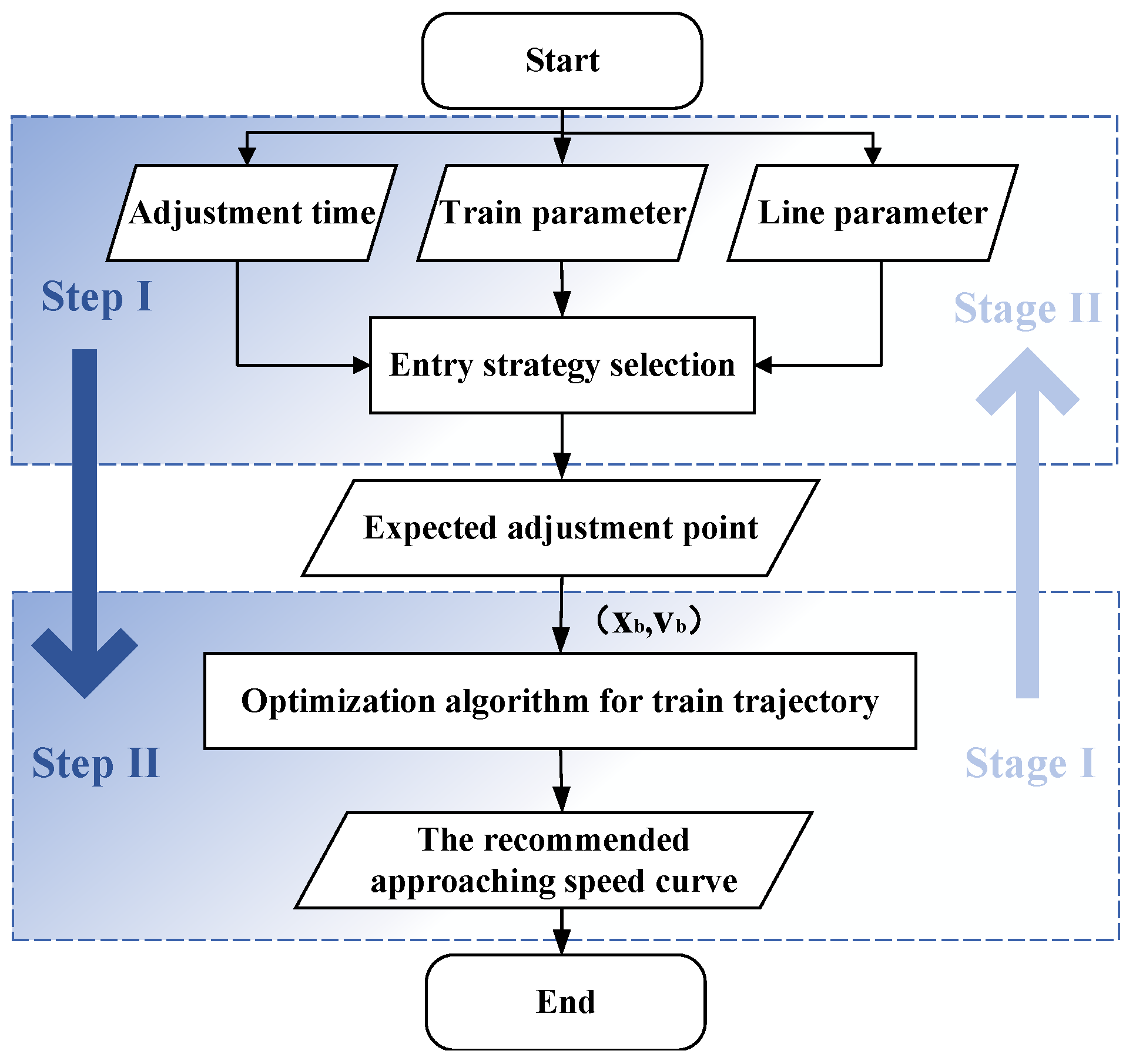
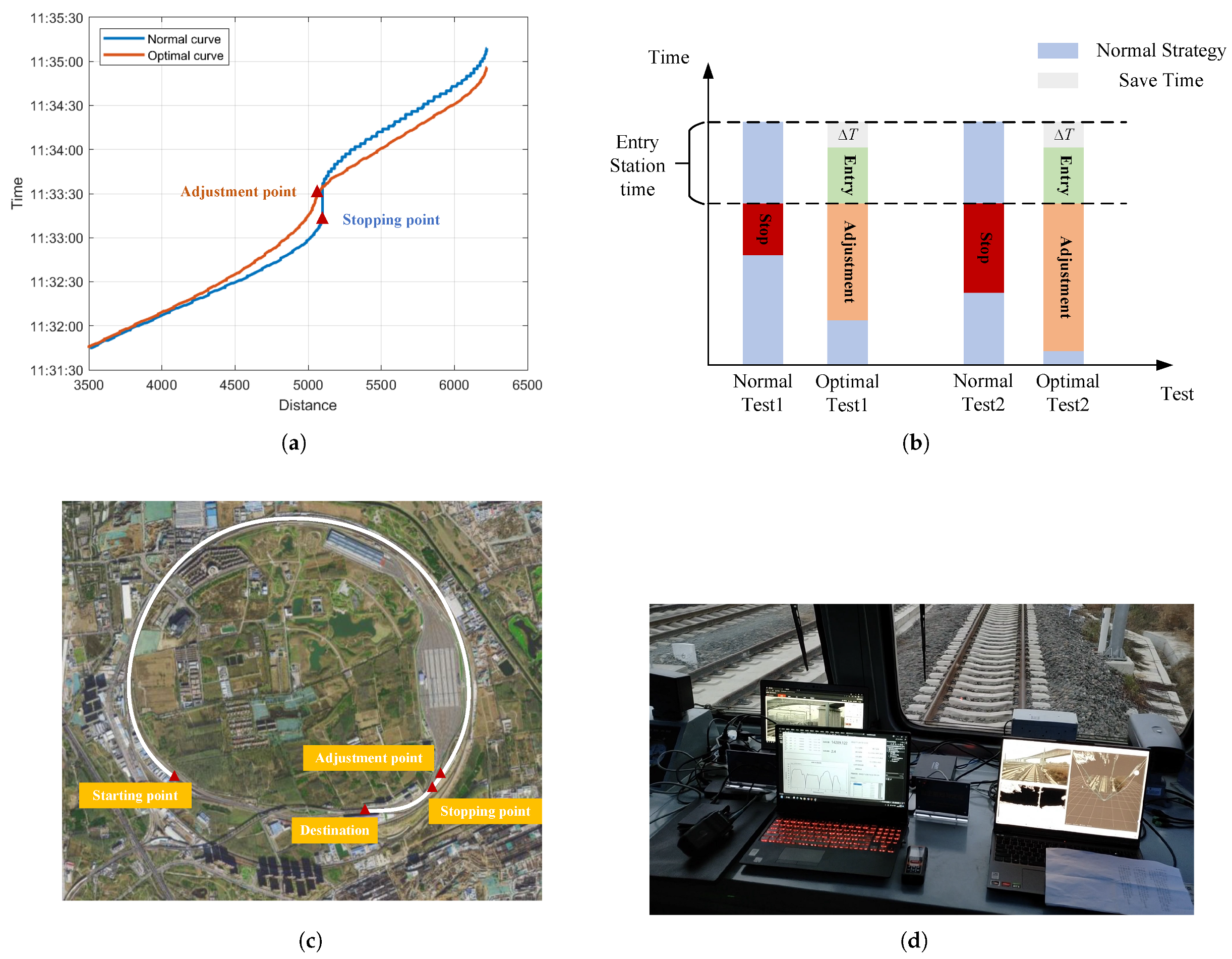
In the next step, we apply the meta-heuristic algorithm and Q-learning algorithm to solve the optimal adjustment trajectory based on the strategy calculation in the first step at the stage I. The train operation trajectory is the movement from the initial state to the target state after a certain running time, where the running time is predicted by the train dispatching system. Specifically, the optimal trajectory should satisfy the condition that the train reaches the adjustment point in time, during the total adjustment time , at which time the home signal opens.
4.2.1. The Improved Meta-Heuristic Algorithm
The meta-heuristic algorithm is one of the important directions in the development of artificial intelligence today, and it embodies characteristics that are different from the traditional intelligent optimization algorithms of the past [
35]. The algorithm is a valuable optimization strategy that solves complex optimization problems by simulating the search behavior of nature with a core of swarm intelligence algorithms. It contains a variety of algorithms, such as classical particle swarm optimization (PSO) and the genetic algorithm (GA). In recent years, a variety of new algorithms have emerged, such as grey wolf optimizer (GWO). In this section, the classic PSO algorithm of heuristic algorithms and the popular GWO algorithm are used to solve the problem.
- (1)
PSO Algorithm
The basic principle of the particle swarm algorithm can be summarized by a flock of birds allowing other birds to discover the location of the food source by passing information about their own location to each other throughout the search process. The other birds constantly update their flying speed and direction, and eventually the whole flock can gather around the food source, that is, the optimal solution has been found.
Each particle continuously updates its position and speed through the fitness value determined by the objective function to find the optimal solution of the problem. The objective function set by the algorithm is an error function. The closer the particle is to the target state point, the smaller the value of the objective function. That is consistent with how birds forage for food.
Assuming that the dimension of the search space is
d and the coordinates of each particle are
, the speed of flight of each particle is
. For the first
i particles, the best historical position through which it passes is denoted as
. The best position of all particles found so far in the whole population is noted as
. The particle constantly updates its speed and position according to the changes in these two best positions:
where
w (
w > 0),
and
are the learning factors, and
and
are random numbers between [0, 1]. Usually the range of the position change is limited to [
], and the range of speed change is limited to [
]:
The grey wolf optimizer algorithm was proposed by Mirjalili et al. based on the cooperative predatory behavior of grey wolf packs [
36]. The leader of the wolf pack is at the top of the population pyramid. The
has the highest decision-making power and is responsible for matters in the pack, such as hunting and roosting. The second layer is the intelligent group
of the wolf group, which mainly assists the
in making decisions and conveying instructions downward. The
will take over the position of
if the leader position is missing. The third layer
wolves obey the leadership of
and
wolves and are mainly responsible for such matters as sentry watching and scouting. The bottom layer of the pyramid is
wolves, who obey the leadership of the superior and are mainly responsible for the balance of the internal relationship of the middle group. Each grey wolf represents a potential solution, and the objective function value indicates the degree of merit of each solution. During the iteration of the algorithm, the goal is to gradually bring the grey wolf population closer to the global optimal solution, which means that the objective function value gradually decreases. The grey wolves with lower objective function values are considered to be closer to the solution of the optimization problem, and thus they play a role similar to that of prey in the grey wolf population, a target for other grey wolves to find.
The hunting behavior of the grey wolf population is mainly divided into three steps:
Tracking, chasing and approaching the prey;
Chasing and encircling the prey and harassing until it stops moving;
Attacking the prey.
After the leader of the wolves
determines the location of the target prey, it will give the command for the wolf to surround the prey and update the location of the search in each iteration of the calculation, defining the behavior of the wolf pack in surrounding the prey by the succeeding equation:
where
is the distance between individual wolves and their prey, and
t represents number of algorithm iterations.
is the position vector of the prey in
t iterations.
is the position vector of the wolf in
t iterations.
,
are coefficient vectors expressed by the succeeding equation:
where
is convergence factor that decreases linearly from 2 to 0 with the number of iterations.
and
are random numbers between [0, 1]. With the help of the coefficient vector
indicating that the wolves explore outward and
indicating that the wolves explore inward and converge toward the prey, the convergence factor
ensures convergence to the optimal value in the global search.
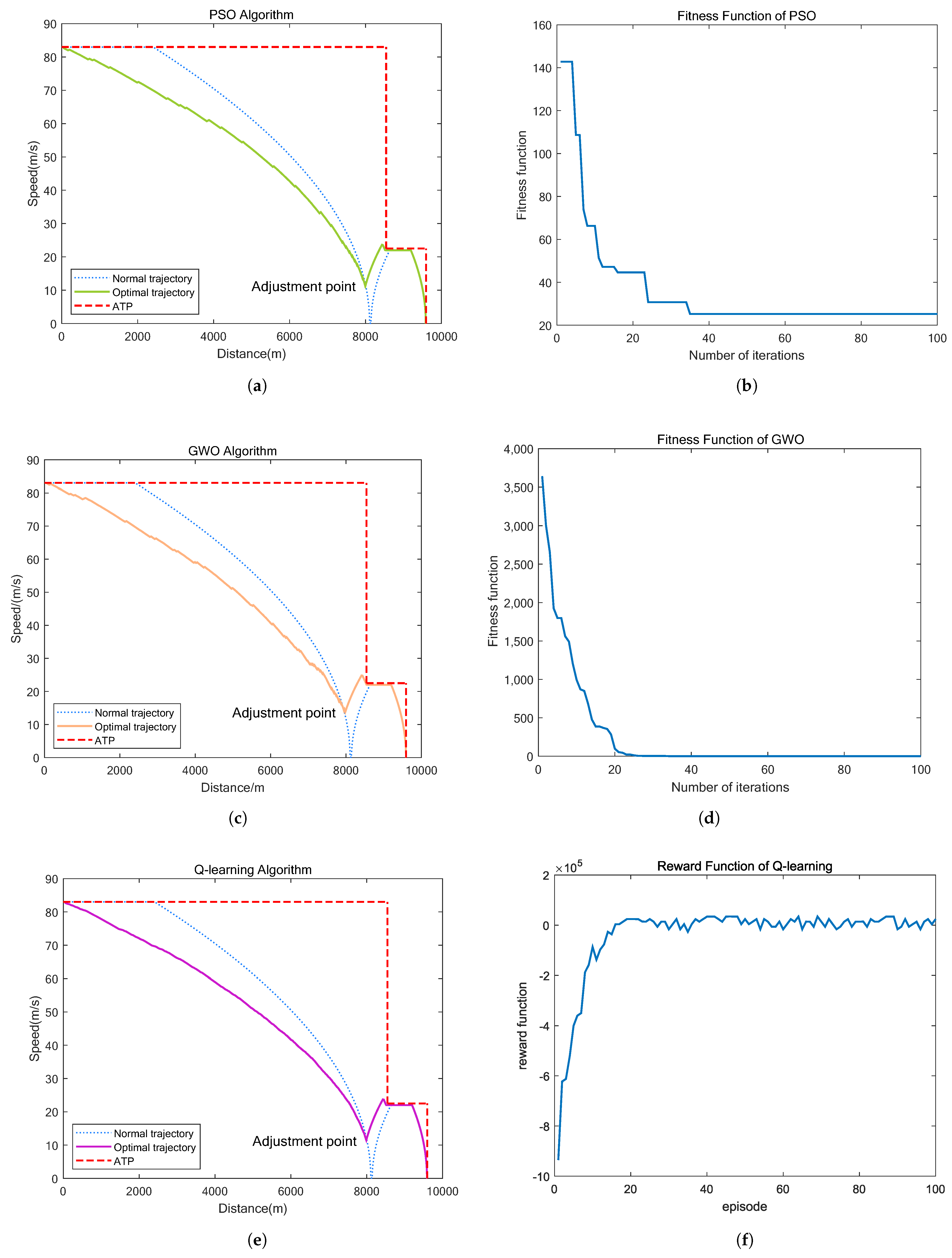
The standard GWO and PSO algorithms have position updates in the continuous domain, which are only suitable for solving continuous optimization problems and cannot directly solve problems in the discrete domain. Therefore, we improve the metaheuristic algorithm by using a coding transformation method that converts continuous spaces to discrete spaces and real numbers to integers based on the idea of mathematical mapping. The whole train operation process is discretized, and the algorithm searches in the discretized space for feasible solutions and converges to the optimal solution. After each iteration is completed, an integer conversion of the condition sequence code is required. Assuming that the train operation curve optimization process contains N discrete substage, the condition code corresponding to each discrete substage process is . Each substage corresponds to a different rate of speed change, which is .
The fitness function of the improved meta-heuristic algorithm (Algorithm 1) is calculated for each particle or grey wolf during each iteration. In the iterative process of the algorithm, the optimal fitness is obtained by comparison. The goal is to keep approaching the target optimal adjustment point:
| Algorithm 1 The improved meta-heuristic algorithms |
- Input:
: The maximum iteration; M: The population quantity; : Train control circle; : The total adjustment time; : The target state - Output:
The near optimal working condition solution; The fitness function; - 1:
Calculate the substage numbers N, - 2:
Initialize the population and algorithm parameters - 3:
while do - 4:
while do - 5:
Update the position of by fitness - 6:
Operated by the heuristic algorithm structure - 7:
- 8:
end while - 9:
Calculate the fitness F by ( 12) - 10:
Record the fitness of each optimal state - 11:
- 12:
end while
|
4.2.2. The Improved Q-Learning Algorithm (Algorithm 2)
Q-learning is a classic value-based reinforcement learning algorithm, and the
Q value represents the expected cumulative reward in a given state and action:
where
S denotes the state space explored by Q-learning and
A is the action space. The reward is an evaluation of the changes in the state of the environment caused by the action taken, which is an important guidance for the training process. It is divided into active reward and negative reward, and the merit of the reward function design directly determines the effect of reinforcement learning. The reward function is shown in (
14), in which
r is a set reward constant:
The algorithm is initialized with an initial value
Q of 0. At the moment of
t, the state of the environment is defined as
, the intelligent agent selects an action
, and receives the reward
. Specifically, the deviation from the target state is calculated for the current state during training, and the action is decided to be positive or negative based on the size of the error. And then, the environment changes its state to a new state
as the result of the agent’s action. The main idea of the algorithm is to construct a Q-table of states and actions to store the
Q-values, and then based on the
Q-values to select the action that can obtain the maximum benefit. The specific form of Bellman’s equation used to update the
Q-values is as follows:
where
denotes the reward value obtained from state
to state
.
is the learning factor (
), which defines the weight that an old
Q-value will learn from a new
Q-value, with a value of 0 meaning that the agent will not learn anything (the old information is important), and a value of 1 meaning that the newly discovered information is the only information that matters.
is the discount factor (
), which defines the importance of future rewards. A value of 0 means that only short-term rewards are considered, where a value of 1 gives more importance to long-term rewards.
The Q-table built by the algorithm is discrete and contains only a limited number of states and actions, corresponding to the way that the train state space discretized in the previous section. Each row in the Q-table represents the state of the train’s operating position, and each column represents the value of the working condition taken. We refer to each exploration of the agent as an episode. In each episode, an episode ends when the agent reaches the target state from the initial state, and then proceeds to another episode. In order to avoid the exploration process falling into a locally optimal solution, a dynamic
optimization strategy is used for exploration during the training process. When the train position is at
, the action is randomly selected with probability of
, that is, the operating condition is shown in
Table 2. And the action corresponding to the maximum value in row
of states in Q-table is selected with probability
. Initially, a larger
is used to achieve higher exploration efficiency, and the epsilon decay factor is set to reduce the value of
with state migration.
| Algorithm 2 The improved Q-learning algorithm |
- Input:
: The learning factor; : the discount factor; : The initial epsilon; epsilon decay factor; episode maximum; the Q-table size; : Train control circle; : The total adjustment time; : The target state - Output:
The near optimal working condition solution; The reward function; - 1:
for Episode = 1, 2, … do - 2:
Initialize the initial state - 3:
Dynamically update using epsilon decay factor - 4:
repeat - 5:
is selected based on Q-table using strategy - 6:
Perform , observe the reward by ( 14) and the next state - 7:
- 8:
- 9:
reward = reward + ; - 10:
until reaches the terminal state - 11:
Record the reward of each episode - 12:
end for
|

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}