
DQN-GNN-Based User Association Approach for Wireless Networks



Abstract
:1. Introduction
- A novel DQN with a GNN-based approach is proposed for efficient user-to-base station association in wireless networks.
- A comprehensive evaluation of our proposed method is conducted in terms of (a) average rewards, (b) average returns, and (c) success rate.
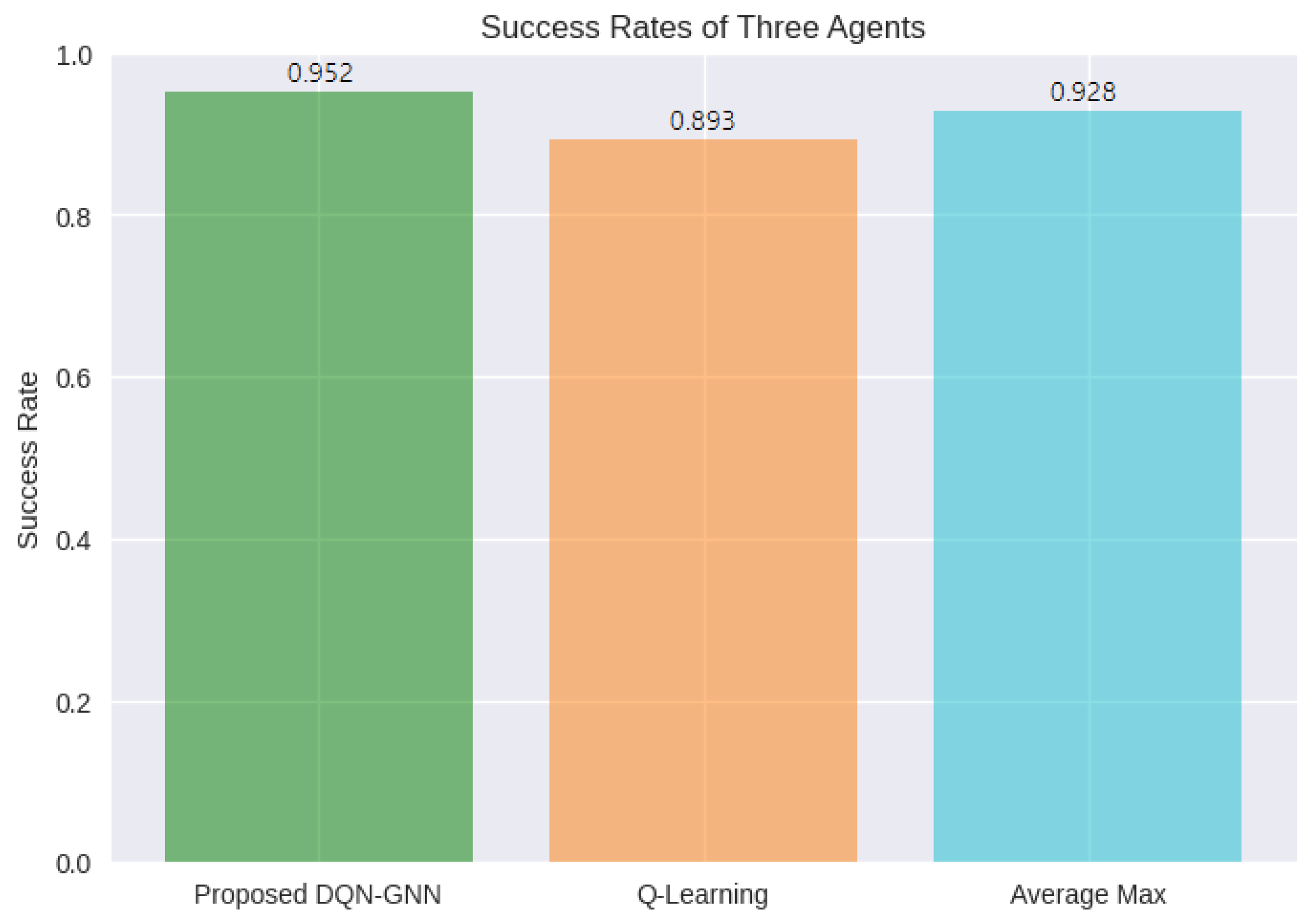
- The DQN-GNN approach outperforms current recent work, such as Q-learning and max average approaches, achieving a success rate of 95.2%, which is higher than other methods by up to 5.9%.
- The combination of DQN and GNN enhances performance by capturing complex relationships and spatial dependencies in wireless networks, leading to more accurate and efficient associations.
2. DQN and GNN: A Mathematical Perspective
3. Related Work
- Limited scalability: Some of the related works face scalability issues when applied to large-scale wireless networks due to the high computational complexity and communication overhead of the proposed algorithms.
- Limited generalization: Many of the related works are not generalized well to different wireless network scenarios, as the performance relies heavily on the quality and quantity of training data or may only address specific problems, such as load balancing or power allocation.
- Limited flexibility: Some of the related works lack flexibility in adapting to rapid changes in the radio environment or may require high signaling overhead due to the direct information exchange among agents or nodes.
- Limited efficiency: Some of the related works suffer from inefficient resource allocation or may not fully utilize available resources, leading to suboptimal performance in terms of energy efficiency or network throughput.
4. The Proposed Approach
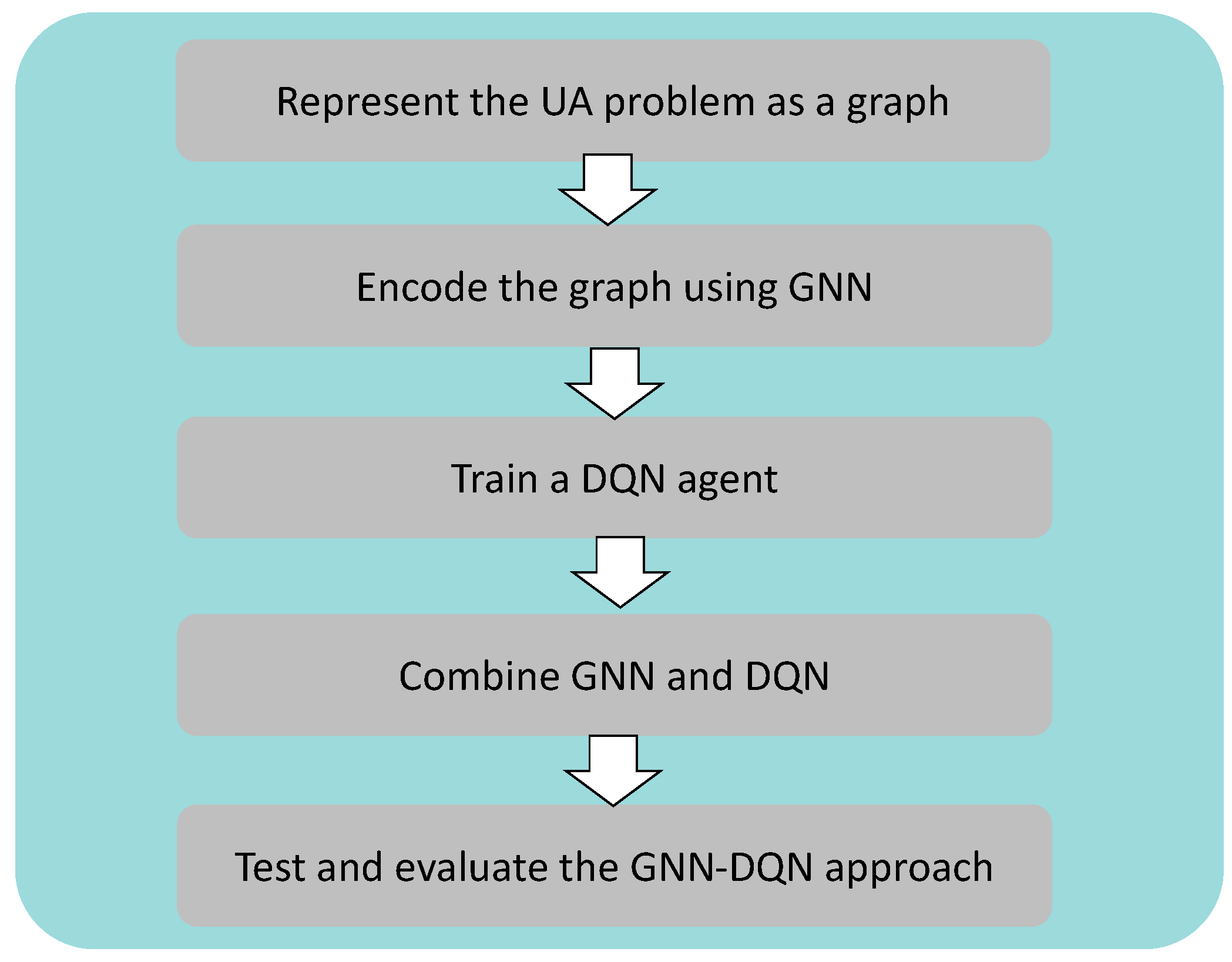
4.1. Building the Proposed DQN-GNN Approach
- Represent the UA problem as a graph: The user association problem is represented as a graph, where each node corresponds to a user or a base station, and the edges represent the wireless connections between them.
- Encode the graph using GNN: A GNN is used to encode the graph structure of the network and learn a representation for each node that captures its importance and connectivity within the network. This allows the system to reason about the relationships between users and BSs and make more informed decisions about user association. In this work, we use a GNN model called LocalGNN for both the policy network and the target network, which was proposed by Shaddad et al. in [39]. A notable feature of the LocalGNN is its ability to locally aggregate information for each node, and this aggregation is also extended to include neighboring nodes within K hops. This means that the feature extraction and computation for each node can be performed locally, which greatly supports the scalability of the proposed algorithm.
- Train a DQN agent: A DQN agent is trained to learn a policy that selects the best BS for each user to connect to based on the current state of the network. The state can be defined as the current set of user-BS associations, as well as additional network parameters such as signal strength, traffic load, and interference levels. The DQN agent can learn to optimize the network performance by selecting the best user-BS associations.
- Combine GNN and DQN: The GNN and DQN models are combined by using the GNN to encode the graph structure of the network and provide input to the DQN agent. The DQN agent can then use the learned representation of each node to make more informed decisions about user association. This combination of models can lead to more efficient and effective user-BS associations and better overall network performance.
- Test and evaluate the GNN-DQN approach: Once the models are trained, the system can be tested and evaluated using wireless network data. To assess the effectiveness of our proposed GNN-DQN approach for user association, we compared its results to those obtained using other user association methods. This comparison allows us to evaluate the performance of our approach relative to existing methods and determine its efficacy in solving the user association problem in wireless networks.
4.2. The System Model
- The current state in the agent-environment system, denoted as s, is a fusion of the condition of the base station and the user situation, according to [40]. The state of the base station encapsulates the number of linked users and the average utility achieved thus far, along with the existing state of the system and the features of the new user. The user’s state, on the other hand, includes the Received Signal Strength Indicator (RSSI) from the associated base stations and a specific demand that must be met.
- The action that the agent takes in a particular state, symbolized as a, involves choosing a base station from the options available, according to [41]. However, an action is not necessary at every time interval. To ensure a well-defined Markov process, decision-making is incorporated into the state. If no user is present, the demand drops to zero, and the only task required is to update the system state without any action needed.
- T denotes the succeeding state in which the environment transitions after the agent executes a specific action, as described in [42]. The descriptors of the base station are updated to reflect the effects of the action, which could be an increase in the number of connected users and a new mean utility, as well as the impact of time, which could be a decrease in the number of connected users if a user’s demand has been satisfied. The characteristics of the new user are revised every time a new user joins. It is important to note that while the transitions over the base station’s features are deterministic, given the action a and the state s, they are stochastic for the new user’s features.
- The reward that the agent earns for executing a particular action in a specific state is represented as r, as per [43]. In the context of our research, the reward is the logarithm of the sum of the throughput between users, which supports equity in resource allocation and is commonly used in related literature.
- The parameter signifies the discount factor utilized to prioritize future rewards in the agent’s decision-making process, as per [44]. The agent aims to optimize the expected discounted cumulative reward by updating a policy () using one of Bellman’s equations. The action-value function for policy is utilized, and the state-action value function is refreshed using the optimality equation.
| Algorithm 1: DQN-GNN User Association Approach |
 |
5. Mathematical Formulation and Optimization
5.1. Problem Formulation
- The state at time t is defined by the current user-BS associations and network conditions, such as the number of connected users and the average utility achieved up to time t.
- The action at time t is the decision made by the DQN-GNN agent to associate a user with a specific BS.
- The transition probability is determined by the dynamics of the wireless network, such as the arrival and departure of users and changes in network conditions.
- The reward is the utility of the system after taking action in state , which is defined as the logarithm of the sum of the throughput between users.
5.2. Optimization Process
6. Performance Evaluation
6.1. Performance Metrics
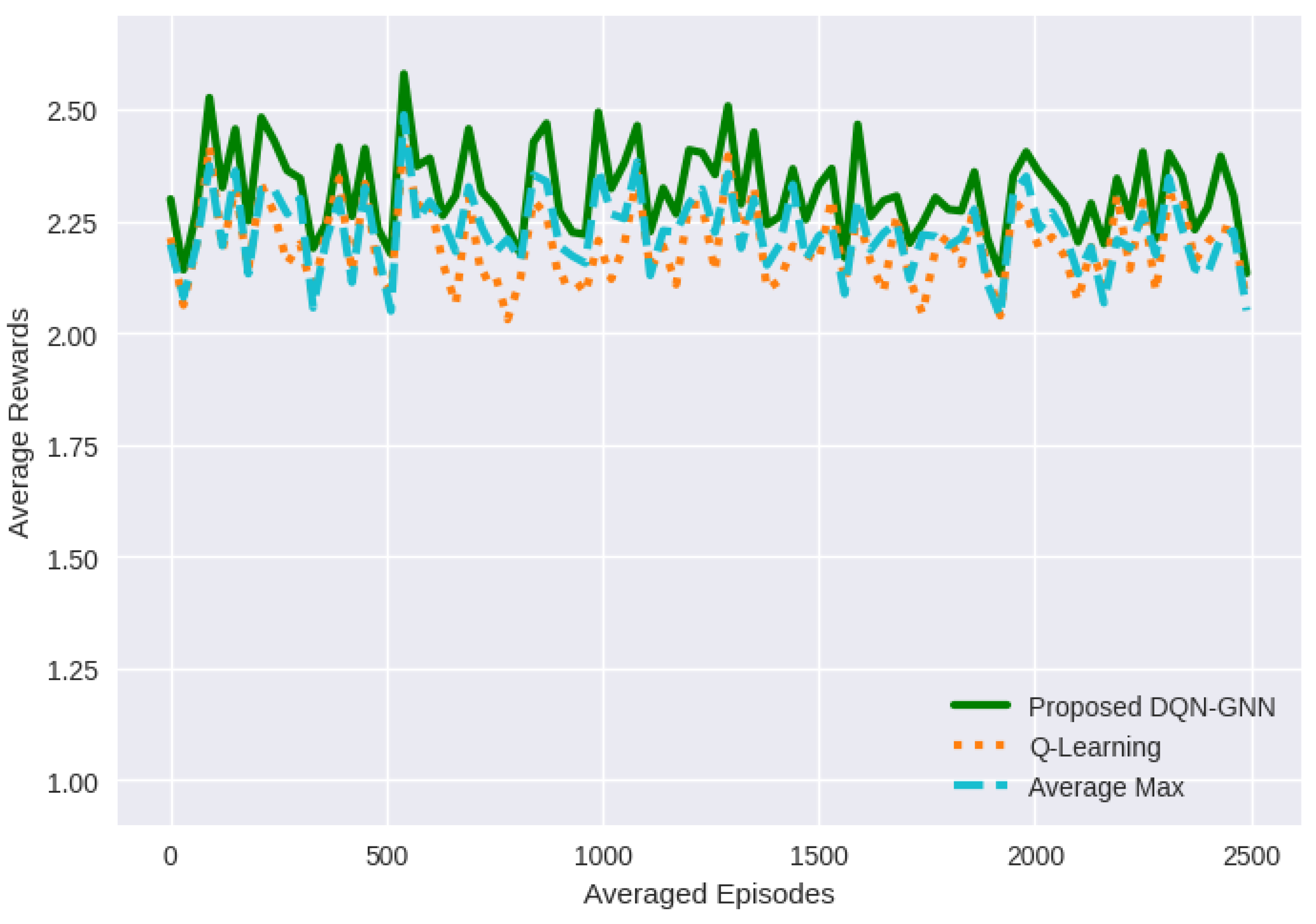
- Average Rewards: The average rewards metric measures the average amount of reward that agents receive over a specific period of time. It is calculated as follows:where m is the total number of episodes, and is the reward obtained by the agent in the episode.
- Average Returns: The average returns metric measures the average sum of discounted rewards that agents receive over a specific period of time. It is calculated as follows:where S is the total number of time steps in each episode, is the reward obtained by the agent at time step t in the episode and is the discount factor.
- Success Rate of Agents: The success rate of agents metric measures the percentage of successful episodes in which the agents achieve the desired goal. Specifically, this metric measures the percentage of episodes in which the agent achieved an average return that meets or exceeds a success threshold. The success threshold is set to 3.5; this value was chosen based on the difficulty of the task and the performance of the baseline models. The success rate of agents is calculated using Equation (9).where represents the success rate of agents. In this context, it is the ratio of the number of successful episodes to the total number of episodes, expressed as a percentage. represents the number of episodes in which the average return is greater than or equal to a success threshold (). The success threshold is a predetermined value that the average return of episodes should meet or exceed for the episode to be considered successful. The total count of episodes is represented by .
6.2. Performance Results
7. Qualitative Analysis and Comparison
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3GPP | Third Generation Partnership Project |
| AC | Actor-Critic |
| AP | Access Points |
| BS | Base Station |
| CFG | Coalition Formation Game |
| CSI | Channel State Information |
| D3QN | Dueling Double Deep Q-Network |
| DDPG | Deep Deterministic Policy Gradient |
| DEC-POMDP | Decentralized Partially Observed Markov Decision Process |
| DQN | Deep Q-Network |
| DRL | Deep Reinforcement Learning |
| GNN | Graph Neural Network |
| GUs | Ground Users |
| HAPS | High-Altitude Platform Station |
| HetNets | Heterogeneous Networks |
| IoT | Internet of Things |
| IoV | Internet of Vehicles |
| KPIs | Key Performance Indicators |
| MADRL | Multi-Agent Deep Reinforcement Learning |
| MDP | Markov Decision Process |
| mmWave | Millimeter Wave |
| NGW | Next Generation Wireless |
| OFDMA | Orthogonal Frequency Division Multiple Access |
| O-RANs | Open Radio Access Networks |
| ORLA | Online Reinforcement Learning Approach |
| P-DQN | Parameterized Deep Q-Network |
| QoE | Quality of Experience |
| QoS | Quality of Service |
| RA | Resource Allocation |
| RBs | Resource Blocks |
| RL | Reinforcement Learning |
| RLH | Reinforcement Learning Handoff |
| RSSI | Received Signal Strength Indicator |
| RUs | Radio Units |
| RVI | Relative Value Iteration |
| SBS | Small Base Stations |
| SNIR | Signal-to-Noise-and-Interference Ratio |
| TBS | Terrestrial Base Station |
| UA | User Association |
| UAVs | Unmanned Aerial Vehicles |
| UDN | Ultra-Dense Network |
| UE | User Equipment |
References
- Lombardi, M.; Pascale, F.; Santaniello, D. Internet of things: A general overview between architectures, protocols and applications. Information 2021, 12, 87. [Google Scholar] [CrossRef]
- Ramazanali, H.; Mesodiakaki, A.; Vinel, A.; Verikoukis, C. Survey of user association in 5G HetNets. In Proceedings of the 2016 8th IEEE Latin-American Conference on Communications (LATINCOM), Medellin, Colombia, 15–17 November 2016; pp. 1–6. [Google Scholar]
- Ge, X.; Cheng, H.; Guizani, M.; Han, T. 5G wireless backhaul networks: Challenges and research advances. IEEE Netw. 2014, 28, 6–11. [Google Scholar] [CrossRef]
- Elfatih, N.M.; Hasan, M.K.; Kamal, Z.; Gupta, D.; Saeed, R.A.; Ali, E.S.; Hosain, M.S. Internet of vehicle’s resource management in 5G networks using AI technologies: Current status and trends. IET Commun. 2022, 16, 400–420. [Google Scholar] [CrossRef]
- Randall, M.; Belzarena, P.; Larroca, F.; Casas, P. GROWS: Improving decentralized resource allocation in wireless networks through graph neural networks. In Proceedings of the 1st International Workshop on Graph Neural Networking, Rome, Italy, 9 December 2022; pp. 24–29. [Google Scholar]
- Panesar, A.; Panesar, A. Machine learning algorithms. In Machine Learning and AI for Healthcare: Big Data for Improved Health Outcomes; Springer: Berlin/Heidelberg, Germany, 2021; pp. 85–144. [Google Scholar]
- Fayaz, S.A.; Jahangeer Sidiq, S.; Zaman, M.; Butt, M.A. Machine learning: An introduction to reinforcement learning. In Machine Learning and Data Science: Fundamentals and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2022; pp. 1–22. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Moos, J.; Hansel, K.; Abdulsamad, H.; Stark, S.; Clever, D.; Peters, J. Robust reinforcement learning: A review of foundations and recent advances. Mach. Learn. Knowl. Extr. 2022, 4, 276–315. [Google Scholar] [CrossRef]
- Yu, F.R.; He, Y. Deep Reinforcement Learning for Wireless Networks; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Kurek, M.; Jaśkowski, W. Heterogeneous team deep Q-learning in low-dimensional multi-agent environments. In Proceedings of the 2016 IEEE Conference on Computational Intelligence and Games (CIG), Santorini, Greece, 20–23 September 2016; pp. 1–8. [Google Scholar]
- He, Y.; Liang, C.; Yu, F.R.; Zhao, N.; Yin, H. Optimization of cache-enabled opportunistic interference alignment wireless networks: A big data deep reinforcement learning approach. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Xiong, S.; Li, B.; Zhu, S. DCGNN: A single-stage 3D object detection network based on density clustering and graph neural 40 network. In Complex & Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–10. [Google Scholar]
- Sathana, V.; Mathumathi, M.; Makanyadevi, K. Prediction of material property using optimized augmented graph-attention layer in GNN. Mater. Today Proc. 2022, 69, 1419–1424. [Google Scholar] [CrossRef]
- Bhadra, J.; Khanna, A.S.; Beuno, A. A Graph Neural Network Approach for Identification of Influencers and Micro-Influencers in a Social Network:* Classifying influencers from non-influencers using GNN and GCN. In Proceedings of the IEEE 2023 International Conference on Advances in Electronics, Communication, Computing and Intelligent Information Systems (ICAECIS), Bangalore, India, 19–21 April 2023; pp. 66–71. [Google Scholar]
- Zheng, X.; Huang, W.; Li, H.; Li, G. Research on Generalized Intelligent Routing Technology Based on Graph Neural Network. Electronics 2022, 11, 2952. [Google Scholar] [CrossRef]
- Munikoti, S.; Agarwal, D.; Das, L.; Halappanavar, M.; Natarajan, B. Challenges and opportunities in deep reinforcement learning with graph neural networks: A comprehensive review of algorithms and applications. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef] [PubMed]
- Hara, T.; Sasabe, M. Deep Reinforcement Learning with Graph Neural Networks for Capacitated Shortest Path Tour based Service Chaining. In Proceedings of the 2022 IEEE 18th International Conference on Network and Service Management (CNSM), Thessaloniki, Greece, 31 October–4 November 2022; pp. 19–27. [Google Scholar]
- Long, Y.; He, H. Robot path planning based on deep reinforcement learning. In Proceedings of the 2020 IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), Shenyang, China, 11–13 December 2020; pp. 151–154. [Google Scholar]
- Wang, X.; Gu, Y.; Cheng, Y.; Liu, A.; Chen, C.P. Approximate policy-based accelerated deep reinforcement learning. IEEE Trans. Neural Networks Learn. Syst. 2019, 31, 1820–1830. [Google Scholar] [CrossRef]
- Pérez-Gil, Ó.; Barea, R.; López-Guillén, E.; Bergasa, L.M.; Gomez-Huelamo, C.; Gutiérrez, R.; Diaz-Diaz, A. Deep reinforcement learning based control for Autonomous Vehicles in CARLA. Multimed. Tools Appl. 2022, 81, 3553–3576. [Google Scholar] [CrossRef]
- Zhu, X.; Dong, H. Shear Wave Velocity Estimation Based on Deep-Q Network. Appl. Sci. 2022, 12, 8919. [Google Scholar] [CrossRef]
- Li, Z.; Wang, C.; Jiang, C.J. User association for load balancing in vehicular networks: An online reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2217–2228. [Google Scholar] [CrossRef]
- Li, Q.; Ding, M.; Ma, C.; Liu, C.; Lin, Z.; Liang, Y.C. A reinforcement learning based user association algorithm for UAV networks. In Proceedings of the 2018 IEEE 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, Australia, 21–23 November 2018; pp. 1–6. [Google Scholar]
- Ding, H.; Zhao, F.; Tian, J.; Li, D.; Zhang, H. A deep reinforcement learning for user association and power control in heterogeneous networks. Ad Hoc Netw. 2020, 102, 102069. [Google Scholar] [CrossRef]
- Chou, P.Y.; Chen, W.Y.; Wang, C.Y.; Hwang, R.H.; Chen, W.T. Deep reinforcement learning for MEC streaming with joint user association and resource management. In Proceedings of the ICC 2020 IEEE International Conference on Communications (ICC), Virtually, 7–11 June 2020; pp. 1–7. [Google Scholar]
- Guan, X.; Huang, Y.; Dong, C.; Wu, Q. User association and power allocation for uav-assisted networks: A distributed reinforcement learning approach. China Commun. 2020, 17, 110–122. [Google Scholar] [CrossRef]
- Zhang, Q.; Liang, Y.C.; Poor, H.V. Intelligent user association for symbiotic radio networks using deep reinforcement learning. IEEE Trans. Wirel. Commun. 2020, 19, 4535–4548. [Google Scholar] [CrossRef]
- Sana, M.; De Domenico, A.; Yu, W.; Lostanlen, Y.; Strinati, E.C. Multi-agent reinforcement learning for adaptive user association in dynamic mmWave networks. IEEE Trans. Wirel. Commun. 2020, 19, 6520–6534. [Google Scholar] [CrossRef]
- Dinh, T.H.L.; Kaneko, M.; Wakao, K.; Kawamura, K.; Moriyama, T.; Abeysekera, H.; Takatori, Y. Deep reinforcement learning-based user association in sub6GHz/mmWave integrated networks. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–7. [Google Scholar]
- Hsieh, C.K.; Chan, K.L.; Chien, F.T. Energy-efficient power allocation and user association in heterogeneous networks with deep reinforcement learning. Appl. Sci. 2021, 11, 4135. [Google Scholar] [CrossRef]
- Chen, G.; Zhai, X.B.; Li, C. Joint optimization of trajectory and user association via reinforcement learning for UAV-aided data collection in wireless networks. IEEE Trans. Wirel. Commun. 2022, 22, 3128–3143. [Google Scholar] [CrossRef]
- Joda, R.; Pamuklu, T.; Iturria-Rivera, P.E.; Erol-Kantarci, M. Deep Reinforcement Learning-Based Joint User Association and CU–DU Placement in O-RAN. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4097–4110. [Google Scholar] [CrossRef]
- Alizadeh, A.; Vu, M. Reinforcement learning for user association and handover in mmwave-enabled networks. IEEE Trans. Wirel. Commun. 2022, 21, 9712–9728. [Google Scholar] [CrossRef]
- Khoshkbari, H.; Sharifi, S.; Kaddoum, G. User Association in a VHetNet with Delayed CSI: A Deep Reinforcement Learning Approach. IEEE Commun. Lett. 2023, 27, 2257–2261. [Google Scholar] [CrossRef]
- Moon, J.; Kim, S.; Ju, H.; Shim, B. Energy-Efficient User Association in mmWave/THz Ultra-Dense Network via Multi-Agent Deep Reinforcement Learning. IEEE Trans. Green Commun. Netw. 2023, 7, 692–706. [Google Scholar] [CrossRef]
- Kim, D.U.; Park, S.B.; Hong, C.S.; Huh, E.N. Resource Allocation and User Association Using Reinforcement Learning via Curriculum in a Wireless Network with High User Mobility. In Proceedings of the 2023 International Conference on Information Networking (ICOIN), Bangkok, Thailand, 11–14 January 2023; pp. 382–386. [Google Scholar]
- Zhao, N.; Liang, Y.C.; Niyato, D.; Pei, Y.; Wu, M.; Jiang, Y. Deep reinforcement learning for user association and resource allocation in heterogeneous cellular networks. IEEE Trans. Wirel. Commun. 2019, 18, 5141–5152. [Google Scholar] [CrossRef]
- Shaddad, R.Q.; Neda’a, A.A.; Alzylai, M.O.; Shami, T.M. Biased user association in 5G heterogeneous networks. In Proceedings of the IEEE 2021 International Conference of Technology, Science and Administration (ICTSA), Taiz, Yemen, 22–24 March 2021; pp. 1–4. [Google Scholar]
- Ji, Z.; Hu, Z.; Wang, Y.; Shao, Z.; Pang, Y. Reinforced pedestrian attribute recognition with group optimization reward. Image Vis. Comput. 2022, 128, 104585. [Google Scholar] [CrossRef]
- Lee, H.; Eom, C.; Lee, C. QoS-Aware UAV-BS Deployment Optimization Based on Reinforcement Learning. In Proceedings of the 2023 International Conference on Electronics, Information, and Communication (ICEIC), Beijing, China, 14–16 July 2023; pp. 1–4. [Google Scholar]
- Badakhshan, S.; Jacob, R.A.; Li, B.; Zhang, J. Reinforcement Learning for Intentional Islanding in Resilient Power Transmission Systems. In Proceedings of the 2023 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 13–14 February 2023; pp. 1–6. [Google Scholar]
- Kim, S.; Jang, M.G.; Kim, J.K. Process design and optimization of single mixed-refrigerant processes with the application of deep reinforcement learning. Appl. Therm. Eng. 2023, 223, 120038. [Google Scholar] [CrossRef]
- Ballard, T.; Luckman, A.; Konstantinidis, E. A systematic investigation into the reliability of inter-temporal choice model parameters. In Psychonomic Bulletin & Review; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–29. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cite | Authors | Year | RL Method | Main Goal |
|---|---|---|---|---|
| [23] | Li, Z. et al. | 2017 | Online historical-based RL | Balancing load in vehicular networks. |
| [24] | Li, Q. et al. | 2018 | Multi-agent RL | Reducing redundant handoffs in UAV networks. |
| [38] | Zhao et al. | 2019 | Multi-agent RL with D3QN | Optimizing network utility in heterogeneous cellular networks. |
| [25] | Ding et al. | 2020 | Multi-agent DQN | Jointly optimizing user association and power control in HetNets. |
| [26] | Chou et al. | 2020 | DDPG | Reformulating user association as MDP for QoE improvement. |
| [27] | Guan et al. | 2020 | Distributed RVI | Jointly optimizing user association and power allocation with reduced dimensionality. |
| [28] | Zhang et al. | 2020 | DRL | Associating IoT devices in wireless networks intelligently. |
| [29] | Sana et al. | 2020 | Multi-agent RL | Coordinating independent agents to optimize network sum-rate. |
| [30] | Dinh et al. | 2021 | DQN | Jointly optimizing user-AP association and beamforming in integrated sub-6GHz/mmWave system. |
| [31] | Hsieh et al. | 2021 | Parameterized DQN | Associating users in heterogeneous networks with wireless backhaul constraints. |
| [32] | Chen et al. | 2022 | MADRL | Decentralizing optimization of UAV trajectories over heterogeneous GUs. |
| [33] | Joda et al. | 2022 | DQN | Placing network functions and associating users in O-RAN networks. |
| [34] | Alizadeh and Vu | 2022 | MAB | Learning handover costs for reducing handover rate in dynamic networks networks. |
| [35] | Khoshkbari et al. | 2023 | DQN | Scheduling users in satellite networks with noisy CSI. |
| [36] | Moon et al. | 2023 | Multi-agent AC | Maximizing energy efficiency in user association for UDNs. |
| [37] | Kim et al. | 2023 | Curriculum learning | Allocating resources in wireless networks with high user mobility. |
| Parameters | Values |
|---|---|
| LEARNING_RATE | |
| BATCH_SIZE | 30 |
| GAMMA | 0.5 |
| EPS_START | 0.95 |
| EPS_END | 0.05 |
| EPS_DECAY | |
| TARGET_UPDATE | 5000 |
| UPDATE_FREQUENCY | 10 |
| DIMENSION_OF_NODE_SIGNALS | [4,1] |
| NUMBER_OF_FILTER_TAPS | 2 |
| ACTIVATION_FUNCTION | ReLU |
| OPTIMIZATION_ALGORITHM | Adam |
| Proposed Model | Average Max | Q-Learning | |
|---|---|---|---|
| Average Rewards | |||
| Minimum | 2.104 | 2.031 | 2.051 |
| Maximum | 2.623 | 2.518 | 2.487 |
| Mean | 2.357 | 2.228 | 2.223 |
| Average Returns | |||
| Minimum | 3.192 | 3.138 | 3.023 |
| Maximum | 5.773 | 5.474 | 5.725 |
| Mean | 4.637 | 4.445 | 4.420 |
| Approach | DQN-GNN | ORLA | RLH | D3QN |
|---|---|---|---|---|
| Spatial Dependencies | High | Moderate | Low | Moderate |
| Scalability | High | Moderate | Moderate | Low |
| Communication Overhead | Low | High | High | High |
| Optimization Objective | Network Performance | Load Balancing | Handoff Reduction | Network Utility |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alablani, I.; Alenazi, M.J.F. DQN-GNN-Based User Association Approach for Wireless Networks. Mathematics 2023, 11, 4286. https://doi.org/10.3390/math11204286
Alablani I, Alenazi MJF. DQN-GNN-Based User Association Approach for Wireless Networks. Mathematics. 2023; 11(20):4286. https://doi.org/10.3390/math11204286
Chicago/Turabian StyleAlablani, Ibtihal, and Mohammed J. F. Alenazi. 2023. "DQN-GNN-Based User Association Approach for Wireless Networks" Mathematics 11, no. 20: 4286. https://doi.org/10.3390/math11204286
APA StyleAlablani, I., & Alenazi, M. J. F. (2023). DQN-GNN-Based User Association Approach for Wireless Networks. Mathematics, 11(20), 4286. https://doi.org/10.3390/math11204286