1. Introduction
In the modern era, service robots heavily rely on their robotic system, robotic arm, and robotic vision to carry out their operations effectively. Numerous proposals have emerged for integrating the robotic system with robotic vision, each presenting its own set of advantages and disadvantages. The primary objective is to employ high-quality cameras for robotic vision, reliable hardware components, and a robust robotic algorithm capable of interpreting the data obtained from robotic vision to enable smooth movement and precise gripper motion [
1]. Grasping, a vital and intricate capability of service robots, demands varied techniques depending on the object’s type and size. Therefore, it becomes imperative to accurately classify objects to ensure successful and appropriate grasping with enhanced learning capabilities [
2].
Predicting the shape, size, and texture of an object in real time poses a considerable challenge due to its inherent complexity. The precision of such predictions holds paramount importance, as even the slightest error can result in significant consequences. Hence, the need arises for an efficient algorithm capable of accurately anticipating an object’s features across diverse scenarios. Additionally, multi-DoF robotic hand grasping enables the robot to grasp multiple objects using various hand surface regions, guided by a reachability map, and validated through successful real-world replication [
3]. To facilitate proficient grasping, prior categorization and weight training of objects become essential. Through our exploration of various algorithms for object detection, we determined that the you only look once (YOLO) algorithm delivers remarkably precise outcomes when deployed within a domestic environment. The study in [
4] presents the Fast-YOLO-Rec algorithm, which enhances real-time vehicle detection by achieving a balance between speed and accuracy through a novel YOLO-based detection network. Evaluation of a large Highway dataset demonstrates its superiority over baseline methods in both speed and accuracy.
In an aging society with fewer children, service robots are expected to play an increasingly important role in people’s lives. To realize a future with service robots, a generic object recognition system is necessary to recognize a wide variety of objects with a high degree of accuracy [
5]. Both RGB and depth images are used in [
6] to improve the accuracy of a generic object recognition system, aiming to integrate it into service robots. Object recognition and pose estimation from RGB-D images are important tasks for manipulation robots, which can be learned from examples. However, creating and annotating datasets for learning is an expensive process [
7]. The REBMIX algorithm [
8], an improved initialization method of the Expectation-Maximization algorithm, could be capable of addressing the challenges of object manipulations, where it demonstrates its effectiveness in terms of clustering, density estimation, and computational efficiency.
The cognitive and learning capabilities of traditional service robots have been a major bottleneck, creating a significant disparity between these robots and human intelligence. Consequently, the widespread application of service robots has been hindered. However, with the introduction of deep learning theory, there is potential for a significant breakthrough in the field of machine learning, thereby enhancing the cognitive algorithms of traditional robots [
9]. The proposed algorithm primarily focuses on integrating various elements such as obstacle information (position and motion), human states (human position, human motion), social interactions (human group, human–object interaction), and social rules, such as maintaining minimum distances between the robot and regular obstacles, individuals, and human groups. These elements are incorporated into the deep reinforcement learning model of a mobile robot [
10].
As the term ’Pick and Place’ implies, the robotic arm holds a pivotal role in the operations of a service robot, particularly in the act of picking up and placing objects. The arm is equipped with a gripper and necessitates precise speed and direction control, along with a higher degree of freedom. The position of the arm within the environment is determined using inverse kinematics techniques. Numerous papers have explored the design of robots, leveraging the advantages of various algorithms and structures developed in previous works. In this regard, we present a compilation of different algorithms and methods discussed in these papers. Grasp detection, which requires expert human knowledge, involves devising an algorithm to identify the grasping pose of objects using a suitable detection method. One such method utilizes a deep learning algorithm, incorporating an image dataset for surface decluttering, with additional support from IoT technology, aiming to enhance the performance of surface decluttering [
11]. Another approach involves a grasping robot that utilizes GANN and is trained using the Dex-Net 4.0 framework. The robot employs a combination of a single parallel jaw gripper and a suction cup gripper, with grasp planning based on depth images obtained from an overhead camera. This method has been applied to the ABB YuMi grasping robot, as previously mentioned [
12]. In [
13], the authors introduced a model predictive control (MPC) strategy for a differential-drive mobile robot by employing input-output linearization on its nonlinear mathematical model. The MPC is designed using quadratic criterion minimization and optimized using torque and settling time graphs, demonstrating its effectiveness through simulation results.
Object detection employs a fully convolutional grasped quality CNN and is tested on a 4 DOF robot. One promising strategy involves training deep policies using synthetic datasets of point clouds and grasps, incorporating stochastic noise models for domain randomization [
14]. Another approach utilizes a robot grasp detection system with an RGB-D Object dataset and a Deep CNN model [
15]. Furthermore, a review highlights the deployment of a robotic grasping function for robotic hardware, leveraging simulated 3D grasp data [
16]. Simulated 3D-based learning proves to be more efficient, enabling robots to quickly adapt to different environmental systems without the requirement of a physical environment. An additional approach employs a sliding window for grasp object detection, utilizing Single Shot Detection based on deep learning techniques [
17]. However, it should be noted that identifying appropriate training data remains a significant challenge.
The need for a large volume of data for training purposes presents a challenge, as it leads to exponentially increased training time. Such time requirements are impractical in real-time domestic environments, necessitating the development of algorithms with reduced time complexity. Grasping unknown objects with a soft hand poses a significant challenge, as it requires the hand to possess sensing and actuation capabilities. In this regard, the utilization of 2D and 2.5D image datasets, combined with the application of 3D CNN techniques, enables the grasping of previously unseen objects [
12]. Additionally, computing grasping data using a pneumatic suction gripper is implemented, employing Dex-Net 3.0 training datasets. The GQ-CNN methodology proves beneficial for grasping, with the processing task involving the classification of robust suction targets within point clouds containing a single object.
The incorporation of signaling based on object detection, facilitated by the single shot detector algorithm, compels robot navigation and provides parameterization at the conclusion of detection [
18]. This concept is vital for enabling robots to navigate intricate environments in real-world scenarios autonomously. By utilizing a dataset and employing deep reinforcement learning techniques, such as a deep recurrent neural network, robots can comprehend and follow human-provided directions, thereby enhancing their ability to navigate effectively in unfamiliar situations. The approach utilizes an end-to-end neural architecture, which has proven effective in autonomous robot navigation. Machine learning and inverse reinforcement learning techniques are implemented in conjunction with motion data [
19]. This approach demonstrates effectiveness in navigating complex and dynamic environments, leveraging global plan information and sensor data to generate velocity commands. A key requirement for successful localization, with or without a map, is the integration of obstacle avoidance strategies.
Researchers in robotics are increasingly interested in employing meta-heuristic algorithms for robot motion planning, due to their simplicity and effectiveness. In the study [
20], various meta-heuristic algorithms are explored in different motion planning scenarios, comparing their performance with traditional methods in challenging environments, and considering metrics like travel time, collisions, distances, energy consumption, and displacement errors. Conclusively, constrained particle swarm optimization emerges as the top-performing meta-heuristic approach in unknown environments. In a separate context, the beetle antennae olfactory recurrent neural network [
21] is introduced for tracking control of surgical robots, emphasizing compliance with crucial remote center-of-motion constraints to ensure patient safety. These constraints are integrated with tracking control using a penalty-term optimization technique. This framework guarantees real-time tracking of surgeon commands while upholding compliance standards, supported by theoretical stability and convergence analysis.
The authors in [
22] introduced an enhanced heuristic ant colony optimization (ACO) algorithm for fast and efficient path planning for mobile robots in complex environments. It incorporates four strategies, including improved heuristic distance calculation, a novel pheromone diffusion gradient formula, backtracking, and path merging, leading to superior performance in optimality and efficiency, particularly in large and intricate maps compared to state-of-the-art algorithms. By introducing random ant positions in obstacle-free areas and integrating A* concepts, the improved ACO in [
23] reduces turns and iterations, leading to faster and more efficient path planning for robots. The study [
24] focuses on enhancing the scalability, flexibility, and performance of mobile robot path planning systems and introduces the hybrid particle swarm optimization (PSO) algorithm. Compared to other heuristic algorithms, it exhibits superior performance by reducing the chances of becoming stuck in local optima, achieving faster convergence, and lower time consumption in path optimization, with a goal of minimizing the path length and ensuring collision-free, smooth paths for the robots. A quartic Bezier transition curve with overlapped control points and an improved PSO algorithm helps to achieve smooth path planning for mobile robots [
25]. Here, the problem with criteria like length, smoothness, safety, and robot kinematics were simulated to demonstrate the effectiveness and superiority of this approach in achieving high-order smooth paths.
The paper [
26] presents a practical implementation of an optimal collision-free path planning algorithm for mobile robots using an improved Dijkstra algorithm. The approach models the robot’s environment as a digraph, updates it when obstacles are detected using an ultrasonic sensor, and demonstrates efficiency through simulations and real-world implementation on a hand-made mobile robot, highlighting the practicality of the approach. A hybrid path planning approach for mobile robots in variable workspaces combines offline global path optimization using the artificial bee colony algorithm with online path planning using Dijkstra’s algorithm in [
27]. The approach efficiently adapts to changing worker and obstacle positions, providing satisfactory paths with minimal computational effort in real-time planning.
This paper introduces an innovative algorithm called mouse-based motion planning (MoMo) and localization. The proposed algorithm addresses trajectory planning and obstacle avoidance control challenges for a specific class of mobile robot systems. The primary objective is to design a novel hybrid virtual force controller capable of adjusting the distance between the mobile robot and obstacles. This is achieved by leveraging the power of multilayer feedforward neural networks (NNs) and deep learning techniques. The introduction of the developed multi-layer feed-forward NN deep learning compensator relaxes the control and design conditions, further enhancing the system’s performance [
28].
The remainder of this article is structured as follows:
Section 2 frames the layout of the problem definition for object detection, path planning, and grasping of the objects to declutter the environment.
Section 3 then broadly discusses the methodology meant for object detection, the kinematics involved in the navigation, the importance of the MoMo algorithm, and the path planning strategies.
Section 4 then explores the mathematical framework for the proposed MoMo algorithm, which is meant to analyze the sensor data for the localization of the robot by computing the error model.
Section 5 discusses the implementation phase of the mobile robotic manipulator along with its structural design and the working principle. Subsequently,
Section 6 focuses on the results and observations made through this study with visual illustrations. Finally,
Section 7 concludes this work with the key findings of this study.
3. Methodology
This section explains objection detection with YOLO, followed by necessary details of the inverse kinematics. At the end of this section, MOMO is discussed.
3.1. Object Detection with YOLO
In order to facilitate navigation, searching, picking, and placing tasks, robots require detailed information extracted from images. High-definition cameras are employed to capture the images, which are subsequently processed using computer vision techniques. Computer vision plays a crucial role in providing object position and orientation within a real-world environment. In this context, the CNN algorithm is utilized due to its ability to handle multiple object classes simultaneously and accurately classify them. CNN stands out as a highly reliable and efficient method for object detection compared to other approaches. Various models exist for object detection, with some relying on CNN. For the development of object detection code, Python is utilized due to its open environment, expressive and readable syntax, and the availability of sophisticated libraries that facilitate the creation of utility programs.
YOLO is widely acknowledged for its superior speed compared to other algorithms. It possesses the ability to detect objects in an image with just a single pass, examining the image only once through the network [
31]. This efficiency enables YOLO to deliver remarkably accurate results. In contrast, alternative algorithms often require multiple scans of the image to detect
N number of objects [
32]. To facilitate the implementation of YOLO, a framework is essential. Darknet or Darkflow framework can be employed in conjunction with YOLO, where specifically the Darkflow framework combines TensorFlow with YOLO [
33]. Additionally, the OpenCV framework, known for its compatibility with YOLO, has gained traction in recent scenarios [
34]. In this work, we opt for the OpenCV framework to conduct our experimentations.
To ensure accurate object detection, we utilize a pre-trained weight file since training a model with thousands of images is an arduous and time-consuming process. By leveraging the pre-trained weight file, we expedite the detection process. However, it is also possible to train YOLO and create a custom weight file (if desired). YOLO demonstrates the capability to perform both object detection and classification simultaneously. Following input to the network, bounding box coordinates and class predictions are generated. The input image is initially divided into SxS grids, with each grid assigned bounding boxes accompanied by confidence scores. If the pixels within a region exhibit similarity, the region expands, while dissimilar pixel values prevent region growth. Subsequently, the region is compared against pre-trained features of known objects, enabling classification and the display of the corresponding class name on the image [
35]. The extracted features from multiple images are collected and stored in a weight file, while layer information is stored in a configuration file. The configuration file contains various layers such as convolution, shortcut, YOLO, and route layers, totaling 107 layers. Additionally, the class names associated with the detected objects are stored, with YOLO capable of detecting 80 classes of objects [
11,
36].
3.2. Inverse Kinematics
Inverse kinematics involves the mathematical calculation of variable parameters necessary for moving the robotic arm to a desired position. It requires the use of kinematic equations to determine the joint parameters. While considerable attention has been given to object detection and localization algorithms, inverse kinematics has received relatively less focus [
37]. Once the location of an object is identified using image processing techniques, inverse kinematics is employed to guide the movement of the robotic arm toward the object, enabling the bot to successfully grasp it. Although we have implemented a simplified approach of moving the bot vehicle toward the center of the object for picking, further advancements in inverse kinematics algorithms can be explored in the future [
38]. It is worth noting that our bot’s structural design is designed to accommodate future improvements and enhancements.
3.3. MoMo
MoMo is an innovative algorithm developed in this work, as described in the subsequent section. The algorithm utilizes mouse sensors and ultrasonic sensors to create a map of the environment, referred to as the raw map. The raw map has dimensions of mouse pixels, where a mouse pixel represents the minimum measurable distance by the mouse sensor. However, due to the large size of the raw map file, it becomes challenging to process and extract data efficiently. Therefore, a compression and conversion process is applied to transform the map file into a usable, accessible, and readable format, as explained below.
Assuming the raw map file is of size , it consists of sequences of 0 s and 1 s, where 0 denotes areas without obstacles and 1 denotes areas with obstacles. The obstacle-free areas are divided into squares for improved readability and efficient pathfinding. This square division is adopted to facilitate easy navigation and expedite the search for the shortest path. The algorithm for square formation is described below. Starting from the first pixel, a square-based region-growing technique is employed. If the square formation is not possible or the size of the square exceeds the maximum limit, the square formation is halted, and the previous square is marked as a new one, assigned a unique number to represent it. By recursively following these steps, the entire map is divided into multiple squares.
Each square contains a central point known as the local eccentric point. The subsequent step involves determining if there are any direct paths between these eccentric points. If such paths exist, they are added as edges in Dijkstra’s map, resulting in a list of complete paths. When an object needs to move from one location to another, the corresponding eccentric point is identified, and the object moves toward it. Dijkstra’s algorithm is then employed to find the shortest path, and the object follows this path to reach its destination. If temporary obstacles obstruct the path, they are marked on the map. The object proceeds to the next eccentric point, determines the path, and continues these steps if any obstacles are encountered along the way.
However, it is worth noting that larger free space squares correspond to longer distances that the robot needs to travel to reach its destination. To address this, we designed the algorithm to be adaptable in all scenarios. We have set a constant minimum time for the algorithm to find the shortest path. If the actual time required to find the shortest path falls below this minimum threshold, the maximum size of the free space squares is reduced, and the map is compressed and parsed again. This approach aims to minimize the distance the robot needs to travel [
39]. As a result, this algorithm, combined with Dijkstra’s algorithm, offers significant advantages in various domestic environments.
5. Implementation
In this section, we provide detailed implementation insights. We delve into the operational mechanisms and structural design of the robotic manipulator utilized for accomplishing object-decluttering tasks. The implementation phase of the proposed MoMo path planning, localization, and navigation frameworks was implemented using the MATLAB R2022b tool in the system with Intel i5 configuration.
5.1. Structural Design
The hardware structure of the bot is designed to be robust, compact, and capable of carrying heavy objects while withstanding various environmental conditions. The key component of the bot is the robotic arm, which offers a high degree of freedom. Moreover, the structure is tailored to meet the specific needs of domestic environments. Taking into account these requirements, an autonomous robot equipped with a robust robotic arm has been developed specifically for domestic applications. This design also presents ample opportunities for expansion and enhancement. The main components include a web camera for robotic vision, an ultrasonic sensor for obstacle detection and mapping, a robotic arm for object manipulation, a Raspberry Pi for controlling the bot, and a dedicated node for image processing. These are the primary featured parts, while additional sub-parts, such as wheels, batteries, and a metal structure, are also included. The physical hardware design of the mobile robotic assembly can be found in
Figure 15 and
Figure 16. The robot’s hardware can be divided into two parts: the base and the robotic arm. The base, constructed from mild steel, serves as a four-wheeled vehicle and houses all internal circuits, including the Raspberry Pi controller, lithium–ion battery, and DC motor driver. This design is cost-efficient, but it does have the drawback of increased weight. The developed mobile robotic manipulator is composed of six parts, as shown in
Figure 15:
Base plate to arm connector—bearing bracket: This component serves to connect the robotic arm structure with the base segment. It ensures that the total weight of the top structure, including the object being lifted, is supported by the bearing bracket instead of the rotary motor. This design allows for the lifting of objects of various weights, including heavy loads, with less torque.
Vertical movement gears—pair of right-threaded screw rods: To enable the lifting of objects, even those with significant weight, we devised a unique structure using a pair of square-threaded right-threaded screw rods. The square thread design ensures long-term durability with minimal wear and tear. The vertical movement of the rods is facilitated by three gears and one motor. With a single motor, the rotation of each rod is precise, and the speed can be easily controlled. The largest gear at the center has 75 teeth, while the other two gears have 27 teeth, resulting in a rotation of the rod that is 2.7 times that of the motor. As a result, a lower RPM motor can be used in various operational conditions. This configuration allows the arm to lift objects to a height of 2 feet.
Hand holder—pair of movable plates: The hand holder consists of a pair of movable plates that secure the remaining arm structure and facilitate vertical movement. These plates play a crucial role in the arm’s functionality.
Shoulder joint—pan–tilt 2-axis servo motor: This joint, resembling the shoulder joint of a human arm, utilizes a pan–tilt 2-axis servo motor to provide rotational movement.
Elbow joint—pan–tilt 2-axis servo motor (tilted perpendicular): The elbow joint, similar to the human elbow, employs a pan–tilt 2-axis servo motor with a perpendicular tilt to enable rotational movement.
Arm: The arm segment of the robotic arm imitates the structure and function of a human arm, completing the resemblance to our natural limb.
Through the integration of these components, we successfully created a versatile and efficient robotic arm that closely emulates human-like movements and demonstrates exceptional capabilities in performing a wide range of tasks. The dimensions of the developed robotic system are shown in
Figure 16.
The inclusion of two pairs of pan–tilt 2-axis servo motors enables a high degree of freedom for the robotic arm. With a 360-degree azimuth angle and 180-degree elevation angle, this arm offers exceptional maneuverability. Additionally, the gripper operates based on the screw principle, allowing precise control over movements with a resolution of up to 1mm. Each gripper is equipped with a piezo disc sensor, enabling accurate handling of various objects, including fragile and heavy items, by determining the pressure exerted. The structure of the arm has been specifically designed to meet our requirements and offers ease of upgrade, modification, and repair. However, it is important to note that the vehicle’s weight is relatively heavy, and its usage is limited to smooth surfaces within domestic environments.
5.2. Working Principle
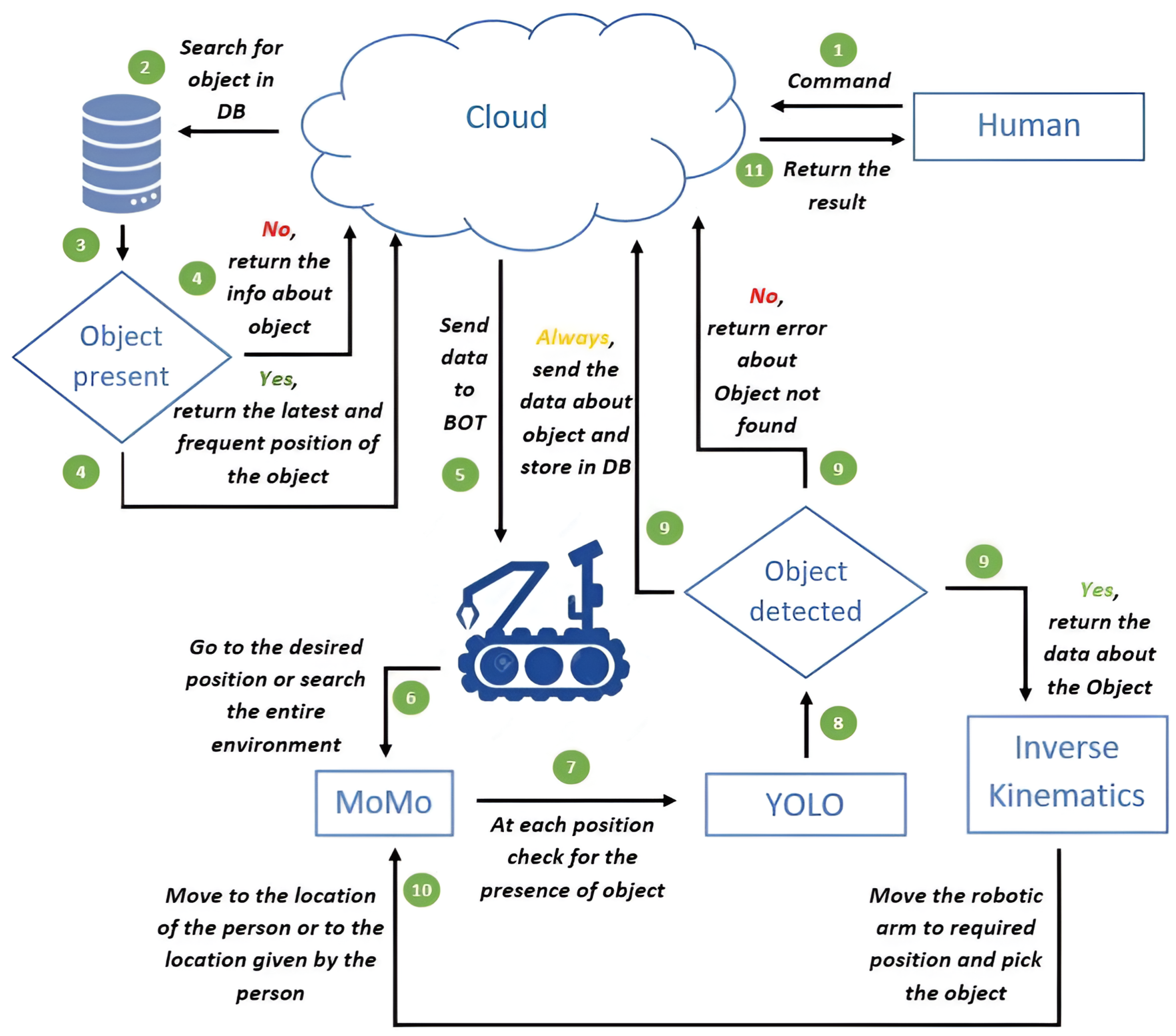
The initial phase involves generating a map file of the environment where the bot operates. A timeout is set for this process, ensuring that no movable objects are present during map generation. The time required to generate the map file for a typical-sized house can range from 30 min up to the specified timeout period. The map file contains coordinates representing the free movement path and obstacles, and it can be updated as needed. The next phase is focused on initializing the positions of the objects. In this stage, the bot traverses the environment, identifies objects, and stores their information in a database for future reference. This phase holds significant importance, as users expect fast and accurate technology for their domestic needs. By knowing the locations of specific objects, the bot can easily navigate to those locations without having to search the entire environment. However, it is important to consider the possibility of objects being re-positioned during operation.
Figure 17 depicts and illustrates the tasks performed by the robot from the perspective of the user.
The third phase is dedicated to relocating objects at uniform time intervals, initially set at 1 hour but adjustable based on the size of the environment. For larger environments, the time interval should be reduced, and vice versa. During this phase, the new positions of the objects are updated in the database. These three phases together form step 1, the “Preparatory Step”. The subsequent step is the “Searching Step”. When the consumer issues a search command for a specific object, the bot first looks for the object’s location in the database, a process referred to as “retrieval of data from DB”. Two types of locations are considered: the expected location and frequent locations. The expected location corresponds to the object’s recent known position, typically obtained during the “relocating objects” phase.
By analyzing the object’s overall movement history, the most frequent position where the object is often found is calculated. The bot begins by moving to the expected location, and if the object is detected there, it informs the consumer of its location. However, if the object is not found in the expected location, the bot proceeds to the most frequent location. If the object is still not detected, the bot enters the third phase, known as the “complete search”, where it thoroughly searches the environment for the object. In the “complete search” phase, the bot thoroughly scans the environment for the object. If the object is found, it informs the consumer about its location. If the object is not found, the bot informs the consumer that the required object cannot be located. The same phases and steps are followed for the “Take” command. In addition to the aforementioned steps, the bot picks up the object from the identified position and places it near the consumer’s location.
6. Results and Discussion
In this section, we present the obtained results for various algorithms. By examining the outcomes of the MoMo algorithm, the timing required for path planning in the environment is observed with the deployment of implemented algorithms in a real-time environment. The majority of the results align with our expectations and have received positive responses. However, a few results have provided us with valuable insights beyond our initial predictions. To compress the raw map, we employed the square box–square-region growth algorithm.
In
Figure 18, the black boxes represent the obstacles present in the environment. The colored boxes, numbered accordingly, indicate the free area squares that are generated through the compression of the raw map. In a typical domestic environment, the average time required to find the optimal path for a minimum distance is less than 500 milliseconds.
Figure 19 illustrates a plot that demonstrates the exponential increase in time as the room area expands. As the algorithm is specifically designed for domestic environments, the average time required will always remain under 500 milliseconds. This graph also highlights the limitation of using this algorithm for larger environments exceeding the size of a typical house. The observations confirm the expected outcome with additional two parameters influencing the time required are the obstacle area and the distribution of obstacles within the environment, both of which are represented in the graph.
Table 1 evaluates ACO, PSO, Dijkstra, and the proposed MoMo method in various experiment trials, highlighting the superior performance of our approach over conventional methods in minimizing the path length. Subsequently,
Table 2 highlights the superior performance of MoMo approach in terms of minimum coverage time.
Based on the observations from
Figure 20 and
Figure 21, it is evident that the time taken for path planning is not consistent or precisely determinable due to the random distribution of obstacles within an environment. However, an approximation can be made. This finding also applies to the relationship between bounding box graphs and average time graphs. Moving on, let us discuss the results pertaining to the object detection algorithms.
Based on our extensive testing, the YOLO algorithm has demonstrated high efficiency and accuracy. The outcomes of the detection of various objects from the webcam mounted on the robotic manipulator using the YOLO object detection algorithm are shown in
Figure 22. In comparison to other algorithms that we experimented with (like faster-CNN), YOLO has shown significant advantages. As mentioned earlier, the combination of YOLO and MoMo algorithms makes the robot well-suited for real-time domestic applications.
The plot depicted in
Figure 23 illustrates a linear increase in time as the room area expands. This outcome aligns with our expectations, as it is a common behavior observed in various algorithms. Hence, the MoMo algorithm has demonstrated its efficiency and suitability for domestic environments.


 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}