1. Introduction
Social media is one of the quickest ways for individuals to express themselves, leading to a flood of content on newsfeeds that reflects their opinions [
1]. Analysing these newsfeeds is a direct method for capturing their sentiments and emotions. Sentiment analysis (SA), also known as opinion mining, is the process of identifying, extracting, and categorizing specific information from unstructured texts using text analysis and computational linguistic techniques in Natural Language Processing (NLP) [
2]. SA involves classifying opinionated textual content into polarity categories such as positive, negative, or neutral [
3,
4,
5,
6]. LRL processing has a profound effect on SA by extending the scope of languages that can be analysed. It facilitates the inclusion of languages with limited digital resources into SA application, thereby making sentiment analysis culturally diverse and more inclusive. This enables organizations to gain insights into sentiment trends, consumer preferences, and brand perception in previously underserved regions and languages, improving their global market understanding. Furthermore, LRL processing allows for cross-cultural analysis, supports humanitarian efforts in crisis responses, and contributes to the preservation of endangered languages, representing its wide-ranging implications for SA in our increasingly interconnected world.
LRLs, frequently spoken by underserved or marginalized populations, present unique challenges in the field of NLP. These languages lack the abundance of digital resources that are readily available for high-resource languages like English (such as large, labelled datasets and pre-trained models). Despite this scarcity in terms of resources, the significance of addressing LRL processing is vital for many compelling reasons. The major concern this research study aims to address is the limited accessibility and utilization of NLP technology for LRLs. This faces countless barriers, including the absence of well-established language technologies, the scarcity of labelled datasets, and limited linguistic resources. Subsequently, there is an urgent need for innovative approaches that make LRL processing more accessible, impactful, and effective.
The classification of text based on various features remains an interesting topic of study [
7]. SA and opinion mining employ rule-based systems, deep learning (DL), and machine learning (ML) to continually enhance this area of research. Consequently, the advent of highly complex language models able to use previous knowledge and adapt it to the particular tasks in which it is utilized has improved performance and decreased the expenditure of computing resources [
8]. Of particular interest are language models dependent upon deep neural networks (DNNs), which have the significant capability of classifying sentiments by automatically learning important features from databases [
9]. However, these outcomes are highly dependent upon the language considered and especially on the accessibility of the extensive databases used to train the model in its early stages. This condition generally only applies to Chinese and English languages, while other languages are typically classified as LRLs [
10].
This paper introduces LRL Processing using Improved Deep Learning with the Hunter–Prey Optimization (LRLP-IDLHPO). The LRLP-IDLHPO technique begins with data preprocessing to improve the usability of the data. Next, it applies the SentiBERT algorithm for word embedding purposes. Then, the sentiment classification process is performed by the Element-Wise–Attention GRU network (EWAG-GRU), an enhanced variant of the RNN. The HPO approach is applied for fine-tuning to further improve the performance of the EWAG-GRU algorithm. A comprehensive set of simulations was performed to validate and ensure the better performance of the LRLP-IDLHPO method. The key contributions of this paper are as follows:
The LRLP-IDLHPO method, which confronts the challenges of LRL processing for SA by integrating SentiBERT, EWAG-GRU-based classification, and HPO-based parameter tuning is proposed. To the best of our knowledge, the proposed model has never been described previously in the literature.
SentiBERT helps convert text data into a numerical representation that captures semantic context, enabling accurate SA in LRL settings.
The EWAG-GRU model, an advanced variant of the RNN which can effectually process temporal features was employed, and its results improved using the attention mechanism for sentiment classification.
The addition of the HPO technique for fine-tuning the EWAG-GRU algorithm illustrates a commitment to optimizing model performance, ensuring it operates at its best in the SA task.
2. Related Works
In [
11], the authors proposed the extraction of sentiments from tweets dependent on their topical subject. The model employs NLP techniques for recognizing sentiments related to a specific problem. In this research study, three different methods were utilized to identify sentiments: classification depending on subjectivity, semantic association, and classification depending on polarity. AlBadani et al. [
12] employed deep learning (DL) methods in various real-time applications across multiple domains, including sentiment analysis (SA). This study introduced an innovative and efficient approach to SA, utilizing DL techniques by integrating “universal language model fine-tuning” (ULMFiT) with a Support Vector Machine (SVM) to enhance recognition accuracy and effectiveness. Additionally, a novel DL method was employed for Twitter SA to recognize the opinions of individuals. Anand et al. [
13] aimed to address MOLD_DL (Multilingual Offensive Language Detection using DL) approaches and utilized NLP in FS and classification. This FS was implemented to segment information using a fuzzy-based FCNN. Later, the extraction of chosen features and classification was executed by combining the model of the Bi-LSTM method with a hybrid NB framework with a SVM.
Kumar et al. [
14] presented a technique that employed Graph Neural Networks (GNNs) for classifying texts based on their content. GNNs were implemented because they work effectively with 2D vectors, and through using GNNs, textual data can be represented in a 2D format. The computation of Self-Organizing Maps (SOM) was carried out to compute the adjacent neighbours in the graphs and determine the actual distances among the neighbours. In [
15], the tweets of individuals were analysed using hybrid deep learning (DL) algorithms. SA was conducted through a five-point scale classification, which includes categories such as positive, negative, highly negative, highly positive, and neutral. This approach was found to require less time when handling a larger number of tweets compared to other methods, namely Decision Trees (DT), Random Forest (RF), and Naive Bayes (NB) classifiers. Alyoubi and Sharma [
16] presented a new hybrid embedding technique aimed at augmenting word embeddings through the integration of NLP techniques. This study also introduced a novel DL algorithm for feature extraction and BiRNN for temporal and contextual feature application.
Rodrigues et al. [
17] suggested a technique that can identify whether tweets are “ham” or “spam” and estimate the sentiment of tweets. The extracted features after pre-processing the tweets can be classified using different classifiers, such as LR, DT, multinomial NB, Bernoulli NB, RF, and SVM to detect spam, and these methods have been utilized for SA. Zuheros et al. [
18] recommended the SA-based Multiperson Multicriteria Decision Making (SA-MpMcDM) technique for aiding smarter decisions. This involved combining an end-to-end multitask DL algorithm for feature-based SA, called the DOC-ABSADeepL approach, which was capable of detecting the feature classifications stated in an expert analysis and extracting their conditions and opinions.
3. The Proposed Model
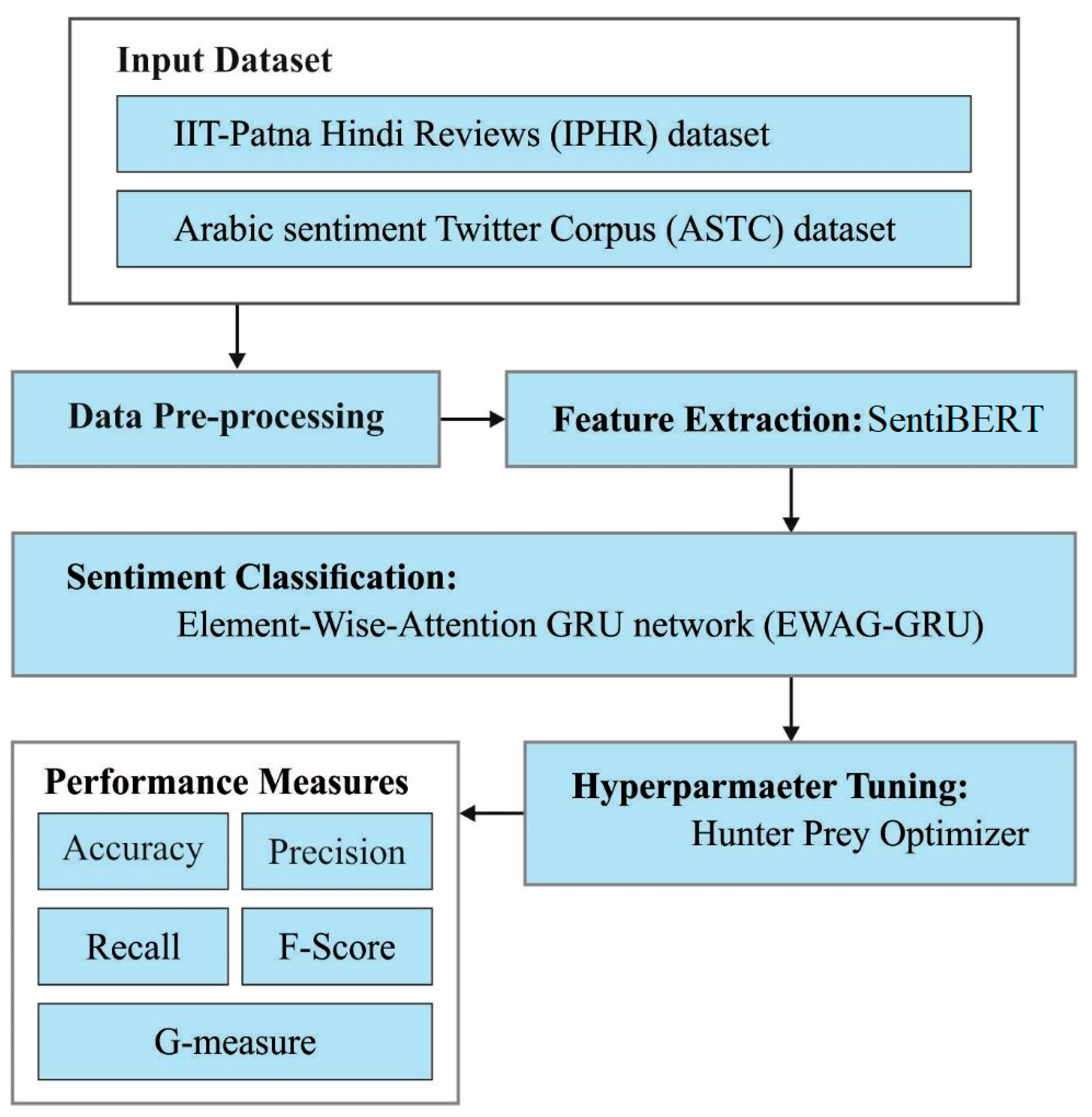
In this manuscript, we propose the use of the LRLP-IDLHPO system for the processing of LRLs. The LRLP-IDLHPO technique enables the detection and classification of the different kinds of sentiments present in LRL data. To accomplish this, the presented LRLP-IDLHPO technique incorporates pre-processing, SentiBERT, a EWAG-GRU model, and a HPO algorithm for hyperparameter tuning.
Figure 1 shows the overall flow of the LRLP-IDLHPO approach.
3.1. Data Pre-Processing
Data pre-processing phases differ based on the SA task and the features of the database. Executing suitable pre-processed approaches is vital to generating a clean and informative database that allows for correct sentiment forecasting via ML approaches. Text cleaning, tokenization, and lowercasing are employed to eliminate irrelevant noise from the text. However, techniques such as stemming and lemmatization further reduce words to their base forms, thereby enhancing the model’s ability to recognize sentiment-related patterns. Special attention is paid to the handling of emojis, negations, and emoticons that change sentiment context.
3.2. SentBERT Model
BERT is an attention-based language method that employs a stack of transformers encoded and decoded for learning textual data [
19]. It also employs a multi-head attention mechanism for extracting helpful features for tasks. The bi-directional transformer NN, as the encoded feature of BERT, changes the entire word token to a numeric vector to process a word embedded for words that are semantically connected, which will be decoded to the numerically close embeddings. BERT and its variations are executed for several NLP tasks, including named entity detection, relation extraction, machine translation, and question and answer, accomplishing the desired outcomes.
The proposed approach employs the Sent-iBERT approach for word embedding. SentiBERT is instrumental in converting words or tokens from the LRL data into numerical representations that capture semantic and contextual information. This embedding process is fundamental for the sentiment analysis task, as it enables the model to understand the meaning and sentiment associated with each word or phrase. SentiBERT adjusts BERT by adding a phrase node forecast unit and semantic composition unit. Specifically, the semantic composition unit’s purpose is to attain phrase representation, which is led by contextual word embedding and an attentive constituency parsing tree. SentiBERT tokenizes input text, generates contextualized word embeddings, and utilizes a classification head to predict sentiment labels. Its ability to capture context and adapt to LRLs makes SentiBERT a powerful tool for accurate sentiment analysis in languages with limited linguistic resources.
3.3. Design of the EWAG-GRU Model for Classification
The EWAG-GRU model is an enhanced version of the RNN used for the classification process, and it has the ability to process temporal features with the inclusion of an attention strategy [
20]. Integrating the attention and gating mechanism in the DL model, we use an element-wise attention Gate (EQAG) to provide attention to the RNN neuron, which allows the RNN neuron to gain the capability to concentrate on the building blocks of input. It can apply a shareable EWAG with a similar size to the outcome attention vector as input to execute each neuron of the RNN blocks.
The RNN architecture better demonstrates the features of EWAG-GRU. The outcome response
of the
t time step is evaluated in the input
, and the output
is as follows:
In Equation (1), and , where represents the weight matrix for and , and represents the bias vector.
EWAG provides the aforementioned RNN neuron attention capability;
represents the response vector, and the dimension is similar to the prior RNN’s input
. The computation formula is as follows:
In Equation (2), The significance level of the input
can be defined by the existing input
and the prior hidden layer (HL)
.
represents the Sigmoid activation function. The input
is updated using the attentional response model as follows:
Then, the GRU model implements a recursive computation dependent upon upgraded input
Figure 2 depicts the infrastructure of the GRU.
The GRU is a kind of RNN that is developed to address the problem of long-term memory and vanishing gradients. It involves updating and resetting the gating units. The former defines what amount of the prior data is to be given to the existing state, whereas the latter controls the amount of novel input that needs to be integrated into the existing state. Once the EWAG was applied to the GRU block, it provided RNN neurons with the capability to selectively attend to the crucial components from the input series. The computation formula for the EWAG-GRU block is given below:
where
represents the update gate, and
represents the reset gate.
denotes the output vector of HL.
refers to the response vectors,
represents the respective weight matrix,
, and
represents the activation function.
denotes the bias vector, and
represents the vector after activation. Then, use the response of
, the EWAG, to control
to
and replace
with
to perform the follow-up. This is known as EWAG-GRU.
The network selectively focuses on the features significant to all the inputs, which analyse various components with different levels of attention to attain more specific outcomes. The network resolves the problems of reducing long-term dependency, along with the problems of time-series exclusion (produced via data analysis for managing the correlation). This contributed to an enhancement in detection performance amidst continuous activity.
3.4. Processes Involved in HPO-Based Hyperparameter Tuning
In this work, the HPO algorithm was utilized for the tuning of the hyperparameters related to the EWAG-GRU approach. The HPO algorithm is a new swarm-based optimizer technique that stimulates the behaviours among the prey and predators [
21]. The HPO updates its features as it imitates the predictor behaviours but hunts the target; meanwhile, the target moves towards a safer position to escape from the predators. Consequently, the safer position is updated dynamically, and the predator needs to adapt its position according to the safer position. In HPO, Since the HPO is the metaheuristic algorithm, it begins with the group of random solutions that is calculated by the subsequent equation.
In Equation (8),
represents the uniformly distributed random number.
and
denote the upper and lower boundaries of the searching region (vector form with dimensional
, and the
and
symbols are the overall size of populations and the amount of problem variables. The fitness function (FF) can be evaluated by the first set of solutions to identify the bad and good performances. Next, according to the fundamental steps of the HPA method, the initial phase of the solution is updated in the set of independent runs. During the exploration phase, the searching agent with a higher chance is used to determine the global and local points in the searching region. At the same time, the exploitation stage retakes the randomized minimum to circulate the potential solution. Iraj et al. developed the following equation for modelling the exploitation and exploration stages.
In Equation (9),
denote the existing and future locations of
hunter, respectively. The prey location is represented as
; the
, and
symbols are the balancing parameters, adaptive parameters, and mean of each location, respectively. These parameters can be calculated using the following equations:
where
,
, and
indicate the random vector within
, and
represents the index number of vector
that meets the conditions of
. The balance variables
are calculated by Equation (11). The
operator has a value that declines from 1 to 0.02 in the iteration.
refers to the maximum amount of iterations.
As previously stated, the aim is to catch the target; thus, the prey updates the position, employing the average of location (
) using Equation (10), and later calculates the distance of all the searching agents from the mean location.
The distance can be measured according to Euclidean distance
The searching agent with the maximum distance in the mean of placement is considered prey
based on the following expression:
where
and
represents the solution counts. Once the target is attacked, it attempts to run away to escape towards the safer region. Iraj et al. considered the better safer position as the optimum global location, and the hunter updates its location to choose another target as follows:
In Equation (15),
represents the optimum global position (safer location), and
represents the random integer.
In Equation (16), represents the random integer within [], and denotes the regulatory parameter with a value of 0.1.
The HPO algorithm derives an FF to attain enhanced classifier outcomes. It explains a positive integer to represent the best outcomes for the candidate performances. In this case, the minimized classification error rate is assumed as FF, as expressed in Equation (17).
4. Results and Discussion
The proposed model was simulated using the Python 3.10.10 tool with the following packages: tensorflow-gpu == 2.10.0, pandas, nltk, tqdm, scikit-learn, pyqt5, matplotlib, seaborn, gensim, prettytable, and numpy. The proposed model was experimented on using PC i5-8600k, GeForce 1050Ti 4GB, 16GB RAM, 250GB SSD, and 1TB HDD.
The experimental validation of the LRLP-IDLHPO technique was tested on the IIT-Patna Hindi reviews (IPHR) [
22] database and the Arabic Sentiment Twitter Classification (ASTC) [
23] Database. This dataset was built to provide an Arabic sentiment corpus for the research community to investigate DL approaches for Arabic SA. The dataset includes tweets annotated with positive and negative labels. The dataset is balanced and consists of data that use positive and negative emojis. For experimental validation, we used 70% of the training dataset and 30% of the testing dataset.
The measures used to examine the performance of the proposed model were accuracy, precision, recall, F-score, and Geometric mean (
) [
24].
Figure 3 demonstrates the classifier analysis of the LRLP-IDLHPO system on the IPHR database.
Figure 3a,b represent the confusion matrix achieved via the LRLP-IDLHPO technique at 70:30 of the TR set/TS set. The outcome value signified that the LRLP-IDLHPO method classified and detected all three classes accurately. Also,
Figure 3c shows the PR curve of the LRLP-IDLHPO system. The outcome value specified that the LRLP-IDLHPO algorithm attained higher PR outcomes on three class labels.
Figure 3d demonstrates the ROC study of the LRLP-IDLHPO methodology. The outcome showed that the LRLP-IDLHPO method resulted in effective experimental results, with higher ROC values on three classes.
In
Table 1 and
Figure 4, the outcomes resulting from using the LRLP-IDLHPO technique on the IPHR database are provided. The table values imply that the LRLP-IDLHPO technique properly recognizes three classes. Under the 70% TR set, the LRLP-IDLHPO technique reaches an effectual
of 98.18%, a
of 97.38%, a
of 96.35%, an
of 96.84%, and a
of 96.85%. Likewise, under the 30% TS set, the LRLP-IDLHPO technique attains an efficient
of 97.43%, a
of 96.01%, a
of 95.03%, an
of 95.51%, and a
of 95.51%.
Figure 5 shows the training accuracy (
and validation accuracy (
values derived from using the LRLP-IDLHPO system on the IPHR database. The
is defined by the estimation of the LRLP-IDLHPO method on the TR database, whereas the
is calculated by evaluating the performance of an individual testing database. The outcomes revealed that
and
rise with an increase in epochs. Therefore, the performance of the LRLP-IDLHPO algorithm improves on the TR and TS database with an increase in the number of epochs.
In
Figure 6, the
and
curves derived from using the LRLP-IDLHPO system on the IPHR database are shown. The
determines the error between the predicted performance and original values on the TR data. The
measures the performance of the LRLP-IDLHPO algorithm on separate validation data. The outcomes specified that the
and
tend to reduce with increasing epochs. It implies the improved performance of the LRLP-IDLHPO method and its ability to generate accurate classification. The decreased values of
and
indicate the superiority of the LRLP-IDLHPO system in capturing relationships and patterns.
A comparison of the results derived from using the LRLP-IDLHPO technique on the IPHR databases are reported in
Table 2 and
Figure 7 [
24,
25,
26]. The results indicate that the NB approach yields worse outcomes, but the DT and LR approaches achieve closer values. Additionally, the RNN and GRU models yield reasonable performance. Although the LSTM and IAOADL-ABSA model achieve considerable results, the LRLP-IDLHPO technique exhibits superior results, with maximum
,
,
, and
values of 98.18%, 97.38%, 96.35%, and 96.84%, respectively.
Figure 8 illustrates the classifier performance of the LRLP-IDLHPO system on the ASTC database.
Figure 8a,b depict the confusion matrix achieved by the LRLP-IDLHPO algorithm at 70:30 of the TR set/TS set. The results suggest that the LRLP-IDLHPO approach detected and classified all three classes accurately.
Figure 8c depicts the results derived from the PR examination of the LRLP-IDLHPO approach. The simulation values suggest that the LRLP-IDLHPO approach achieved greater values of PR in three classes. However,
Figure 8d demonstrates the ROC curve of the LRLP-IDLHPO approach. This result shows that the use of the LRLP-IDLHPO approach led to proficient performance in terms of ROC in three classes.
In
Table 3 and
Figure 9, the experimental outcomes derived from using the LRLP-IDLHPO algorithm on the ASTC database are provided. The values in this table imply that the LRLP-IDLHPO method properly recognizes three class labels. Under the 70% TR set, the LRLP-IDLHPO system achieves an effectual
of 99%, a
of 99%, a
of 99%, an
of 99%, and a
of 99%. Similarly, under the 30% TS set, the LRLP-IDLHPO approach achieves an efficient
of 99%, a
of 99%, a
of 99%, an
of 99%, and a
of 99%.
Figure 10 illustrates the training accuracy (
and validation accuracy (
curves derived from using the LRLP-IDLHPO algorithm on the ASTC database. The
is determined by the estimation of the LRLP-IDLHPO system on the TR database, whereas the
is calculated by evaluating the performance on a separate testing database. The outcomes revealed that
and
rise with an increase in epochs. Thus, the performance of the LRLP-IDLHPO approach improves when used on the TR and TS databases with an increase in the number of epochs.
In
Figure 11, the
and
curves derived from using the LRLP-IDLHPO method on the ASTC database are shown. The
defines the error between the predictive outcome and original values on the TR data. The
measures the performance of the LRLP-IDLHPO algorithm on individual validation data points. The outcomes indicate that the
and
tend to reduce with increasing epochs. They also indicate the improved performance of the LRLP-IDLHPO system and its ability to generate accurate classification. The decreased
and
values suggest the superior performance of the LRLP-IDLHPO approach in terms of capturing relationships and patterns.
A comparison of the values obtained via using the LRLP-IDLHPO technique and other similar models on the ASTC databases are stated in
Table 4 and
Figure 12 [
25,
26,
27]. The outcomes specify that the NB model obtains worse results, whereas the DT and LR techniques exhibit performances closer to that achieved by the LRLP-IDLHPO technique. Additionally, the RNN and GRU systems exhibit reasonable performances. Although the LSTM and IAOADL-ABSA approaches achieve great outcomes, the LRLP-IDLHPO method shows superior outcomes, with higher
,
,
, and
values of 99%, 99%, 99%, and 99% respectively.
Thus, the results suggest that the LRLP-IDLHPO technique is an accurate tool for sentiment classification. The LRLP-IDLHPO method achieves better performance over existing approaches through a combination of innovative strategies tailored to the challenges of LRL SA. By incorporating data preprocessing to improve data usability, leveraging advanced word embeddings with SentiBERT, employing EWAG-GRU for effective sentiment classification, and fine-tuning model parameters with HPO, this technique addresses the key challenges posed by LRLs. The meticulous design of the LRLP-IDLHPO technique enhances each step of the SA pipeline, resulting in better robustness and accuracy, making it suitable to the unique linguistic characteristics and resource constraints of LRLs. Comprehensive simulation analyses validated these advancements, underscoring the method’s superiority and reinforcing its potential as a transformative solution in the realm of LRL processing.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}