
WT-CNN: A Hybrid Machine Learning Model for Heart Disease Prediction


Abstract
:1. Introduction
- The proposed work introduces a new hybrid model that combines continuous wavelet transform (CWT), CNN, and random undersampling boost (RUSBoost) that could make a significant contribution to improving the early diagnosis of cardiac issues.
- An accurate and automated diagnostic tool could potentially be more cost effective than manual diagnosis, leading to broader access to cardiac care.
- The experimental evaluation concealed that the performance of the proposed work surpassed the existing benchmark methods by yielding 97.2% accuracy.
2. Literature Review
3. Proposed Method
3.1. Preprocessing and Data Blancing
- N: total number of instances;
- Nmin: number of minority class instances;
- Nmaj: number of majority class instances.
- Dt(i): the weight of instance i in round t;
- αt: amount of say of weak classifier t (calculated based on its error rate);
- ht(x): weak classifier at round t.
| Algorithm 1 RUSBoost for Data Balancing |
| Initialize instance weights: (i) = for i = 1, 2, …, N. |
| For t = 1 to T (where T is the total number of boosting rounds): |
|
|
|
|
|
|
3.2. Feature Extraction
- represents the wavelet coefficient at scale a and shift b;
- is the wavelet function (mother wavelet);
- a,b are the scale and translation parameters, repectively.
- Wx(a,b) represents the wavelet coefficients at scale a and shift b, respectively;
- ψ(t) denotes the complex conjugate of the mother wavelet function;
- A, b are the scale and translation parameters, respectively.
- Peak amplitudes: The local maxima in the scalogram are identified to extract the corresponding peak amplitudes. Peaks in the scalogram often correspond to specific frequency components that carry important information about heart diseases.
- Wavelet energy: The energy distribution across different scales and time intervals is computed in the scalogram, which represents the strength of various frequency components present in the ECG signals. This provides insights into their contribution to heart disease patterns.
- Frequency band power: The power within specific frequency bands of interest, such as the low-frequency (LF) and high-frequency (HF) bands, are also computed. This enables the spectral characteristics associated with heart diseases to be captured that potentially differentiate between different stages of heart disease.
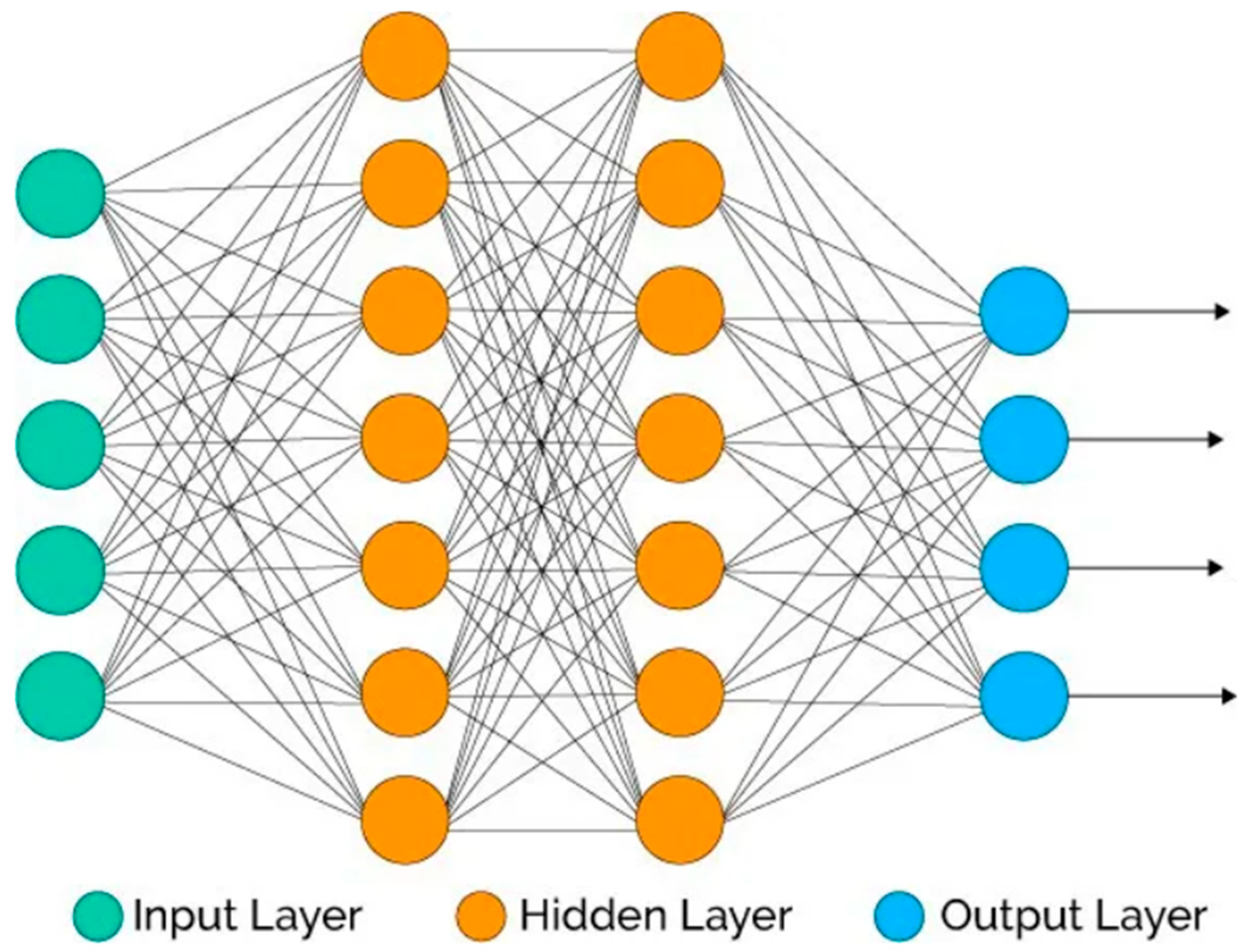
3.3. Disease Prediction
- Input Layer:
- Convolutional Layer
- Activation Layer Using ReLU
- Pooling Layer
- Fully Connected (FC) Layer Using Softmax
4. Experimental Results
4.1. Dataset
4.2. Performance Matrices
- The confusion matrix: A 2 × 2 table that contained four outputs from the implemented classifier consisted of the following elements: (1) true positive (tp), which shows that the predicted results indicate “yes” and that subjects have heart disease; (2) true negative (tn), which shows that the predicted results indicate “no” and that subjects do not have heart disease; (3) false positive (fp), which shows that the predicted results indicate “yes” and that subjects do not actually have heart disease; and (4) false negative (fn), which shows that the predicted results indicate “no” and that subjects have heart disease. Other measures like model accuracy, model specificity, model sensitivity, model precision, and f-measure are calculated using this.
- Accuracy: this is the ratio of the number of truly classified samples to the total number of samples.
- Specificity (P): This is the fraction of the total number of true positive samples predicted as true to the total number of sample predicted as true.
- Sensitivity (S): This is the fraction of the number of correctly classified positive samples to the total number of positive examples.
- F-measure (F): This is used for algorithm comparison, and it consists of the harmonic mean of sensitivity and precision.
- The ROC curve: The ROC curve is a graphical representation that illustrates the discriminatory ability of a binary classification model by plotting the true positive rate (sensitivity) against the false positive rate (1-specificity) across various probability thresholds. This visualization allows for an in-depth assessment of the model’s capability to distinguish between positive and negative cases.
- Matthews correlation coefficient (MCC): MCC is a single-value classification metric that helps to summarize a confusion matrix or an error matrix.
4.3. Baseline Method
- ○
- Hussain et al. [29]: They significantly addressed congestive heart failure through a robust method. In addition to this, their work also focused on data balancing, multimodal feature extraction, and oversampling strategies to improve heart condition detection.
- ○
- Iqbal et al. [23]: This work presented an optimized machine learning algorithm with an artificial bee colony technique. The utilization of optimization techniques offered insights into improving algorithmic performance.
- ○
- Reddy et al. [31]: They presented a new prediction system for coronary heart disease risk using principal component analysis and hyper-parameter optimization.
- ○
4.4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fekih, R.T.; Atri, P.M. Electrocardiogram heartbeat classification based on a deep convolutional neural network and focal loss. Comput. Biol. Med. 2020, 123, 103866. [Google Scholar]
- Chao, C.; Peiliang, Z.; Min, Z.; Qu, Y.; Bo, J. Constrained transformer network for ecg signal processing and arrhythmia classification. BMC Med. Inf. Decis. Mak. 2021, 21, 184. [Google Scholar] [CrossRef]
- Jabbar, M.A.; Deekshatulu, B.L.; Chandra, P. Intelligent heart disease prediction system using random forest and evolutionary approach. J. Netw. Innov. Comput. 2016, 4, 175–184. [Google Scholar]
- Jabbar, M.A.; Deekshatulu, B.L.; Chandra, P. Computational intelligence technique for early diagnosis of heart disease. In Proceedings of the 2015 IEEE International Conference on Engineering and Technology (ICETECH), Coimbatore, India, 20–20 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Lichman, M. UCI Machine Learning Repository. 2013. Available online: https://archive.ics.uci.edu/ (accessed on 11 August 2023).
- John, M.; John, M.; Flora, M.; Daphne, K. Classification techniques for cardio-vascular diseases using supervised machine learning. Med. Arch. 2020, 74, 39. [Google Scholar]
- Shah, S.M.S.; Shah, F.A.; Hussain, S.A.; Batool, S. Support vector machines-based heart disease diagnosis using feature subset, wrapping selection, and extraction methods. Comput. Electr. Eng. 2020, 84, 106628. [Google Scholar] [CrossRef]
- Sharmila, R.; Chellammal, S. A conceptual method to enhance the prediction of heart diseases using the data and Engineering. Int. J. Comput. Sci. Eng. 2018, 6, 21–25. [Google Scholar]
- Beyene, C.; Kamat, P. Survey on prediction and analysis the occurrence of heart disease using data mining techniques. Int. J. Pure Appl. Math. 2018, 118, 165–174. [Google Scholar]
- Ahsan, M.M.; Siddique, Z. Machine learning-based heart disease diagnosis: A systematic literature review. Artif. Intell. Med. 2022, 128, 102289. [Google Scholar] [CrossRef] [PubMed]
- Ramesh, T.R.; Lilhore, U.K.; Poongodi, M.; Simaiya, S.; Kaur, A.; Hamdi, M. Predictive analysis of heart diseases with machine learning approaches. Malays. J. Comput. Sci. 2022, 1, 132–148. [Google Scholar]
- Yahaya, L.; Oye, N.D.; Garba, E.J. A comprehensive review on heart disease prediction using data mining and machine learning techniques. Am. J. Artif. Intell. 2020, 4, 20–29. [Google Scholar] [CrossRef]
- Ali, S.; Heasoo, H. A robust deep convolutional neural network withbatch-weighted loss for heartbeat classification. Expert Syst. Appl. 2019, 122, 75–84. [Google Scholar]
- Aya, A.; Mohamed, B.-E.-D.; James, M.; Jim, B. Early hospital mortality prediction of intensive care unit patients using an ensemble learning approach. Int. J. Med. Inf. 2017, 108, 185–195. [Google Scholar]
- Sakr, S.; Elshawi, R.; Ahmed, A.M.; Qureshi, W.T.; Brawner, C.A.; Keteyian, S.J.; Blaha, M.J.; Al-Mallah, M.H. Comparison of machinelearning techniques to predict all-cause mortality using fitness data: The henry fordexercise testing (fit) project. BMC Med. Inform. Decis. Mak. 2017, 17, 174. [Google Scholar] [CrossRef] [PubMed]
- Ejaz, A.S.; Mohammed, B.; Ferdous, S.; Mario, S.F.; Girish, D. Machine learning-based prediction of heart failure readmission ordeath: Implications of choosing the right model and the right metrics. ESC Heart Fail. 2019, 6, 428–435. [Google Scholar]
- Chaurasia, V.; Pal, S. Data mining approach to detect heart diseases. Int. J. Adv. Comput. Sci. Inf. Technol. (IJACSIT) 2014, 2, 56–66. [Google Scholar]
- Islam, M.A.; Jia, S.; Bruce, N.D. How much position information do convolutional neural networks encode? arXiv 2020, arXiv:2001.08248. [Google Scholar]
- Dan, G.; Jiang, S.; Bang, A.; Xu, M.; Na, L. Integrating tanbn with cost sensitive classification algorithm for imbalanced data in medical diagnosis. Comput. Ind. Eng. 2020, 140, 106266. [Google Scholar]
- Tan, K.C.; Teoh, E.J.; Yu, Q.; Goh, K.C. A hybrid evolutionary algorithm for attribute selection in data mining. Expert Syst. Appl. 2009, 36, 8616–8630. [Google Scholar] [CrossRef]
- Dileep, K.M.; Ramana, K.V. Cardiovascular disease prognosis and severity analysis using hybrid heuristic methods. Multimed. Tools Appl. 2021, 80, 7939–7965. [Google Scholar]
- Samit, B.; Abeer, A.; Prasad, P.W.C.; Al, A.S.; Hisham, A.O. A novel solution of using deep learning for early prediction cardiac arrestin sepsis patient: Enhanced bidirectional long short-term memory (lstm). Multimed. Tools Appl. 2021, 80, 32639–32664. [Google Scholar]
- Iqbal, F.; Raziq, A.; Tirink, C.; Fatih, A.; Yaqoob, M. Using the artificial bee colony technique to optimize machine learning algorithms in estimating the mature weight of camels. Trop. Anim. Health Prod. 2023, 55, 86. [Google Scholar] [CrossRef]
- Shivam, D.; Rahul, K. Early detection of heart diseases using a low-cost compact ecg sensor. Multimed. Tools Appl. 2021, 80, 32615–32637. [Google Scholar]
- Devansh, S.; Samir, P.; Kumar, B.S. Heart disease prediction using machine learning techniques. SN Comput. Sci. 2020, 1, 345. [Google Scholar]
- Lee, X.Y.; Kumar, A.; Vidyaratne, L.; Rao, A.R.; Farahat, A.; Gupta, C. An ensemble of convolution-based methods for fault detection using vibration signals. arXiv 2023, arXiv:2305.05532. [Google Scholar]
- Kemal, F. Similarity-based attribute weighting methods via clusteringalgorithms in the classification of imbalanced medical datasets. Neural Comput. Appl. 2018, 30, 987–1013. [Google Scholar]
- Alberto, F.; Salvador, G.; Francisco, H. Addressing theclassification with imbalanced data: Open problems and new challenges on class distribution. In International Conference on Hybrid Artificial Intelligence System; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–10. [Google Scholar]
- Houda, B.; Ali, I.; Fernandez-Aleman, J.L. Data preprocessing for heart disease classification: A systematic literature review. Comput. Methods Programs Biomed. 2020, 195, 105635. [Google Scholar]
- Adyasha, R.; Debahuti, M.; Ganapati, P.; Chandra, S.S. An exhaustive review of machine and deep learning based diagnosis of heart diseases. Multimed. Tools Appl. 2021, 81, 36069–36127. [Google Scholar]
- Reddy, K.V.V.; Elamvazuthi, I.; Aziz, A.A.; Paramasivam, S.; Chua, H.N.; Pranavanand, S. An Efficient Prediction System for Coronary Heart Disease Risk Using Selected Principal Components and Hyperparameter Optimization. Appl. Sci. 2023, 13, 118. [Google Scholar] [CrossRef]
- Simran, V.; Abhishek, G. Effective prediction of heart disease using datamining and machine learning: A review. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 249–253. [Google Scholar]
- Hussain, L.; Lone, K.J.; Awan, I.A.; Abbasi, A.A.; Pirzada, J.U.R. Detecting congestive heart failure by extracting multimodal features with synthetic minority oversampling technique (SMOTE) for imbalanced data using robust machine learning techniques. Waves Random Complex Media 2022, 32, 1079–1102. [Google Scholar] [CrossRef]
- Anggoro, D.A.; Kurnia, N.D. Comparison of accuracy level of support vector machine (SVM) and K-nearest neighbors (KNN) algorithms in predicting heart disease. Int. J. 2020, 8, 1689–1694. [Google Scholar] [CrossRef]
- Kavitha, M.; Gnaneswar, G.; Dinesh, R.; Sai, Y.R.; Suraj, R.S. Heart disease prediction using hybrid machine learning model. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1329–1333. [Google Scholar]
- Mahesh, T.R.; Dhilip Kumar, V.; Vinoth Kumar, V.; Asghar, J.; Geman, O.; Arulkumaran, G.; Arun, N. AdaBoost ensemble methods using K-fold cross validation for survivability with the early detection of heart disease. Comput. Intell. Neurosci. 2022, 2022, 9005278. [Google Scholar] [CrossRef] [PubMed]
- Nancy, A.A.; Ravindran, D.; Raj Vincent, P.M.D.; Srinivasan, K.; Gutierrez Reina, D. IoT-Cloud-Based Smart Healthcare Monitoring System for Heart Disease Prediction via Deep Learning. Electronics 2022, 11, 2292. [Google Scholar] [CrossRef]
- Ahmad, A.A.; Polat, H. Prediction of Heart Disease Based on Machine Learning Using Jellyfish Optimization Algorithm. Diagnostics 2023, 13, 2392. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Name | No. of Records | Weblink |
|---|---|---|---|
| 1 | MIT-BIH Arrhythmia Dataset | 22,275 | https://www.physionet.org/content/mitdb/1.0.0/ (accessed on 5 July 2023) |
| 2 | PTB Diagnostic ECG Database | 21,445 | https://www.physionet.org/content/ptbdb/1.0.0/ (accessed on 10 August 2023) |
| 3 | Ch. Pervaiz Elahi Institute of Cardiology | 11,148 | https://data.mendeley.com/datasets/gwbz3fsgp8/2 (accessed on 22 July 2023) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammad, F.; Al-Ahmadi, S. WT-CNN: A Hybrid Machine Learning Model for Heart Disease Prediction. Mathematics 2023, 11, 4681. https://doi.org/10.3390/math11224681
Mohammad F, Al-Ahmadi S. WT-CNN: A Hybrid Machine Learning Model for Heart Disease Prediction. Mathematics. 2023; 11(22):4681. https://doi.org/10.3390/math11224681
Chicago/Turabian StyleMohammad, Farah, and Saad Al-Ahmadi. 2023. "WT-CNN: A Hybrid Machine Learning Model for Heart Disease Prediction" Mathematics 11, no. 22: 4681. https://doi.org/10.3390/math11224681