1. Introduction
With the introduction of some large-scale datasets with sufficient label information, Convolutional Neural Networks (CNNs) have achieved great success in machine learning and computer vision tasks [
1,
2,
3]. CNNs can learn highly non-linear feature representations, thereby improving the discrimination ability of a model. However, when there are obvious differences between the training set and test set, such as multi-modal data, the CNN model trained on the training set may degenerate on the test set. At the same time, since the test set does not contain label information, we cannot directly fine-tune the trained model to fit the test set data. Therefore, it is an important and challenging task to learn a model with domain generalization while maintaining sufficient discrimination ability.
To solve this problem, a more specific task, Unsupervised Domain Adaptation (UDA), is widely studied. The UDA task aims to transfer the features or models learned on a labeled training set (source domain) to an unlabeled test set (target domain) [
4,
5]. In the UDA task, the source domain and target domain have the same learning task but different data distributions. A diagram of UDA is shown in
Figure 1a. It can be seen that there is an obvious distribution discrepancy between the source and target domains.
Previous UDA methods have mainly been based on shallow models, which achieve domain knowledge transfer through sample reweighting strategies [
5] or learning a shared feature space [
6,
7]. However, limited by the representation capacity of models, the performance of these methods does not exceed the deep UDA approach. In recent years, with the development of deep learning, more deep UDA models [
8] have been proposed to deal with UDA tasks. Mainstream deep UDA methods learn a domain-invariant feature space based on aligning the distribution of deep features [
9,
10,
11,
12,
13]. According to different alignment strategies, these methods can be roughly divided into two categories, i.e., marginal-distribution-based methods [
9,
10] and conditional-distribution-based methods [
12,
13]. Marginal-distribution-based methods use two-sample testing [
14] or adversarial training [
15] to reduce the difference between the marginal distributions of features in the source and target domains. Such methods often suffer from negative transfer due to ignoring the dependencies between features and labels [
13]. Conditional-distribution-based methods reduce the difference between the conditional distributions of features in the source and target domains. Common strategies include conditional generative adversarial networks [
16] and conditional maximum mean discrepancy [
13]. However, these methods ignore the discrimination learning of features, which makes it difficult for them to fully utilize the discrimination information in the data, thereby affecting the performance of the model. In particular, excessive alignment learning often leads to a loss of feature discriminability. As shown in
Figure 1b, excessive alignment learning causes samples belonging to different categories in the target domain to incorrectly cluster around a certain category in the source domain.
Recently, there has been a trend to improve the discrimination ability of UDA models by adding additional discrimination learning modules [
17,
18,
19,
20]. The most common strategy is to introduce a metric learning loss, e.g., center-based loss or triplet-based loss, to learn a compact feature space shared by the source and target domains [
17,
18]. Most of the existing methods use different losses to control the discrimination learning and alignment learning, respectively. These models need to find appropriate weight hyperparameters to balance discrimination learning and alignment learning. However, during the training process, the optimal weight hyperparameters are constantly changing, which causes the model to over-emphasize discrimination learning or alignment learning. An over-emphasis on alignment learning may lead to a loss of feature discriminability, while an over-emphasis on discrimination learning may reduce the feature transferability. As shown in
Figure 1c, excessive discrimination learning leads to feature misalignment between source and target domains. Some recent research works [
20,
21] have introduced a dynamic weight to balance discrimination learning and alignment learning in real time. However, updating dynamic weights in real time introduces additional calculations and takes more training time. Additionally, these methods only consider the discrimination information within the source and target domains, while ignoring the discrimination information between the source and target domains. Since the similarity information between source domain samples and target domain samples is not effectively exploited, the performance of the model may be limited.
In this paper, we propose a novel deep UDA method, Gaussian Process-based Transfer Kernel Learning (GPTKL), to simultaneously improve the discriminability and transferability of the model. First, GPTKL uses the kernel similarity between all samples in the source and target domains as a priori information to establish a cross-domain Gaussian process. The likelihood function of the cross-domain Gaussian process reflects the domain discrepancy between the source and target domains in a Reproducing Kernel Hilbert Space. GPTKL maximizes the likelihood function of the cross-domain Gaussian process to learn a transfer kernel function. This process effectively improves the transferability of the model. This transfer kernel function can better measure the similarity between samples of multi-domain data. In particular, GPTKL introduces the deep kernel learning strategy to convert the learning of transfer kernel function into the learning of a deep feature space suitable for measuring sample similarity. With deep transfer kernel learning in the cross-domain Gaussian process, GPTKL learns a deep feature space of inter-domain alignment, intra-class compactness and inter-class separation. As shown in
Figure 1d, GPTKL learns a deep feature space with both discriminability and transferability. Second, in order to further extract discriminant information, GPTKL uses cross-entropy loss and mutual information to learn a classification model shared by the source and target domains. The contributions of this work are concluded as follows:
We propose a new deep UDA method, GPTKL, which introduces a cross-domain Gaussian process and shared classification model to achieve domain knowledge transfer and improve the discrimination ability of the model.
We introduce the deep kernel learning strategy into the cross-domain Gaussian process to learn a deep feature space with both discriminability and transferability.
We conduct experiments to verify the effectiveness of GPTKL and the transfer kernel function.
The rest of this article is organized as follows.
Section 2 briefly reviews the related work on deep UDA and the Gaussian process.
Section 3 introduces the proposed method in detail.
Section 4 reports the experiment settings and experiment results, and gives an analysis.
Section 5 summarizes the conclusions and proposes future research directions.
2. Related Work
In this section, we briefly review the related work from two directions, i.e., deep UDA and the Gaussian process.
2.1. Deep UDA Methods
Deep networks are proven to be able to learn generalized feature representations, which promotes the development of deep UDA methods [
22,
23]. Most of these deep UDA methods are based on aligning the marginal distribution or conditional distribution of the source and target domains. Among them, a common strategy is to use specific statistical information to measure domain discrepancy. Deep Adaptation Network (DAN) [
9] uses maximum mean discrepancy (MMD) [
14] to measure the difference between the source and target domains, while Deep CORAL [
24] explores the second-order statistics (covariance matrices) to align the source and target domains. Deep Subdomain Adaptation Network (DSAN) [
25] effectively aligns the conditional distributions of the source and target domains by reducing the MMD in the subspace. Deep Conditional Adaptation Network (DCAN) [
13] introduces an effective metric, i.e., conditional maximum mean discrepancy (CMMD), which can measure the distance between conditional distributions in a Reproducing Kernel Hilbert Space. By reducing the CMMD between the conditional distributions of the source and target domains, DCAN learns a conditional domain-invariant deep feature space. There are also some methods that introduce an additional discriminator to distinguish between source domain features and target domain features [
10,
26]. These methods aim to obtain feature representations that can fool the discriminator. Specially, Domain Adversarial Neural Network (DANN) [
10] uses the discriminant network to align the marginal distributions, while Conditional Domain Adversarial Network (CDAN) [
12] uses the category information in the classifier to align the conditional distributions. Maximum Classifier Discrepancy (MCD) [
27] uses the difference between the classification results of multiple classifiers to measure domain discrepancy.
Recent UDA methods suggest that the discriminability of features plays an important role in the transfer of category information [
19,
20]. Joint domain alignment and Discriminative feature learning Domain Adaptation (JDDA) [
17] introduces instance-based and center-based discriminative losses on the source domain to learn a feature space with better discriminability. Batch Spectral Penalization (BSP) [
19] discusses the relationship between transferability and discriminability, and boosts the discriminability of deep features by constraining the largest singular value of feature matrixes. Stepwise Adaptive Feature Norm (SAFN) [
28] improves the discrimination ability of the model by increasing the feature norms. Enhanced Transport Distance (ETD) [
29] uses optimal transfer theory to reduce the domain discrepancy between the source and target domains, and introduces the attention mechanisms to enhance the discrimination ability of the model. Discriminative Manifold Propagation (DMP) [
30] introduces manifold learning losses on the source and target domains respectively to learn discriminative low-dimensional manifold embeddings. These methods all consider the transferability and discriminability of features. However, these methods require careful balance between domain alignment loss and discrimination learning loss, as they ignore the interaction between alignment learning and discrimination learning. To solve this problem, Dynamic Weighted Learning (DWL) [
20] introduces a dynamic weight to adjust the importance of domain alignment loss and discrimination learning loss in real time. Similarly, Dynamically Aligning both the Feature and Label (DAFL) [
21] introduces a dynamic balancing weight in adversarial training to balance the generating and discrimination abilities of the model. However, updating dynamic weights in real time introduces additional calculations and takes more training time. Different from the above methods, GPTKL introduces the deep kernel learning strategy into the cross-domain Gaussian process framework to learn deep features with both discriminability and transferability. Note that this process does not introduce the weight parameter for balancing alignment learning and discrimination learning.
2.2. Gaussian Process
The Gaussian process is an important Bayes’ non-parametric model, which directly defines the prior distribution on the function space of samples . Consider a general prediction model: , where denotes random noise, . Let . The Gaussian process generally assumes that the prior distribution of satisfies , where is the kernel matrix of samples, . Based on the total probability theorem, the marginal distribution of satisfies , where , and is an N-dimensional identity matrix. The Gaussian process directly models the sample distribution based on the kernel matrix, which can effectively describe the structural information between samples.
The Gaussian process can learn generalization models, and thus is widely used in multi-task learning and transfer learning tasks. For instance, Kai Yu et al. propose a hierarchical Bayesian framework based on a non-parametric Gaussian process to handle multi-label text classification problems [
31]. Bin Cao et al. propose a Gaussian process-based adaptive transfer learning algorithm to deal with the transfer learning problem [
32]. Pengfei Wei et al. design a learnable kernel in the transfer Gaussian process model to measure the similarity between domains, thereby effectively solving the multi-source transfer regression problem [
33]. Transfer Gaussian Process Regression (TrGP) [
34] proposes a formal definition of the transfer kernel and two advanced general forms of the transfer kernel. These transfer kernels can effectively capture the domain relatedness and are used to deal with transfer regression problems. There are three key differences between TrGP and our GPTKL: (1) TrGP addresses supervised cross-domain regression problems, while GPTKL addresses unsupervised cross-domain classification problems. (2) TrGP learns a transfer kernel to capture domain relatedness, while GPTKL learns a general kernel function to measure the similarity between all samples in the source and target domains. (3) TrGP learns the kernel function on the original data space. GPTKL introduces the deep kernel learning strategy to convert the learning of transfer kernel function into learning a deep feature space; thus, GPTKL can benefit from the powerful representation capacity of deep networks. Aiadi Oussama et al. propose a multi-view Gaussian-based Bayesian learning scheme, which can efficiently address text-based image retrieval problems [
35]. Benefiting from assigning a weight to each view, it can better deal with intra-class variation. This idea can also be applied to UDA tasks. Multi-view Gaussian learning can represent the data distribution accurately, thereby promoting the distribution alignment of the source and target domains. Gaussian Process Domain Adaptation (GPDA) [
36] proposes a systematic UDA method to achieve hypothesis consistency by learning a Gaussian process on the source domain. Both GPTKL and GPDA use the Gaussian process to deal with UDA problems, but there are two key differences between them: (1) GPDA lacks an explicit domain alignment strategy, while GPTKL learns a domain-invariant deep feature space by introducing the deep kernel learning strategy into the cross-domain Gaussian process. (2) GPDA uses variational inference to solve for the parameters of the Gaussian process. This process requires iterative updating of the variational distribution to learn the posterior distribution of the Gaussian process, so multiple network calculations are required at each network iteration. GPTKL introduces the kernel learning strategy to directly learn the parameters of Gaussian process, which avoids multiple network calculations and reduces the training time of the model.
3. Our Method
In this section, we introduce the proposed method in detail. First, we introduce the motivation and notations in
Section 3.1. Second, we introduce how to use the cross-domain Gaussian process and deep kernel learning technique to learn a deep feature space with both discriminability and transferability in
Section 3.2. Then, classification model learning on the source and target domains is introduced in
Section 3.3. Finally, the overall loss function and training procedure of GPTKL are introduced in
Section 3.4.
3.1. Motivation and Notations
The goal of UDA tasks is to reduce the classification error on the target domain. Reference [
37] proposes that the classification error on the target domain is controlled by the classification error on the source domain, the distance between the source and target domains and the error of an ideal joint hypothesis. The upper bound of the classification error on the target domain
is defined as follows:
where
h denotes the classification model and
represents the classification error on the source domain. The
distance between the source and target domains is defined as follows:
and the error of the ideal joint hypothesis is
where
is the ideal joint hypothesis.
Based on this theory, an effective UDA method should be able to reduce three items in (
1) at the same time. Since the label information of the source domain is known, the classification error in the source domain can be controlled to be very small. For the second item, existing UDA methods propose a variety of effective feature alignment strategies to reduce domain discrepancy. The third item in (
1) represents the joint classification error of an ideal joint hypothesis, which is closely related to the discriminability of features. Existing UDA methods usually ignore this item because they believe that
is small. However, recent research results indicate that there is an interaction between alignment learning and discrimination learning in UDA tasks [
19,
20]. Excessive pursuit of domain alignment will weaken the discriminability of features, which will increase
and affect the final classification performance. Therefore,
cannot simply be ignored. It is necessary to investigate a UDA method that can perform alignment learning and discrimination learning simultaneously.
In this work, GPTKL first establishes a cross-domain Gaussian process to learn a transfer kernel function that can measure the similarity between samples of multi-domain data, and then introduces deep kernel learning strategy to convert the learning of transfer kernel function into learning deep features with both discriminability and transferability. This process simultaneously reduces the second and third items in Equation (
1); thus, it can effectively solve the interaction between alignment learning and discrimination learning.
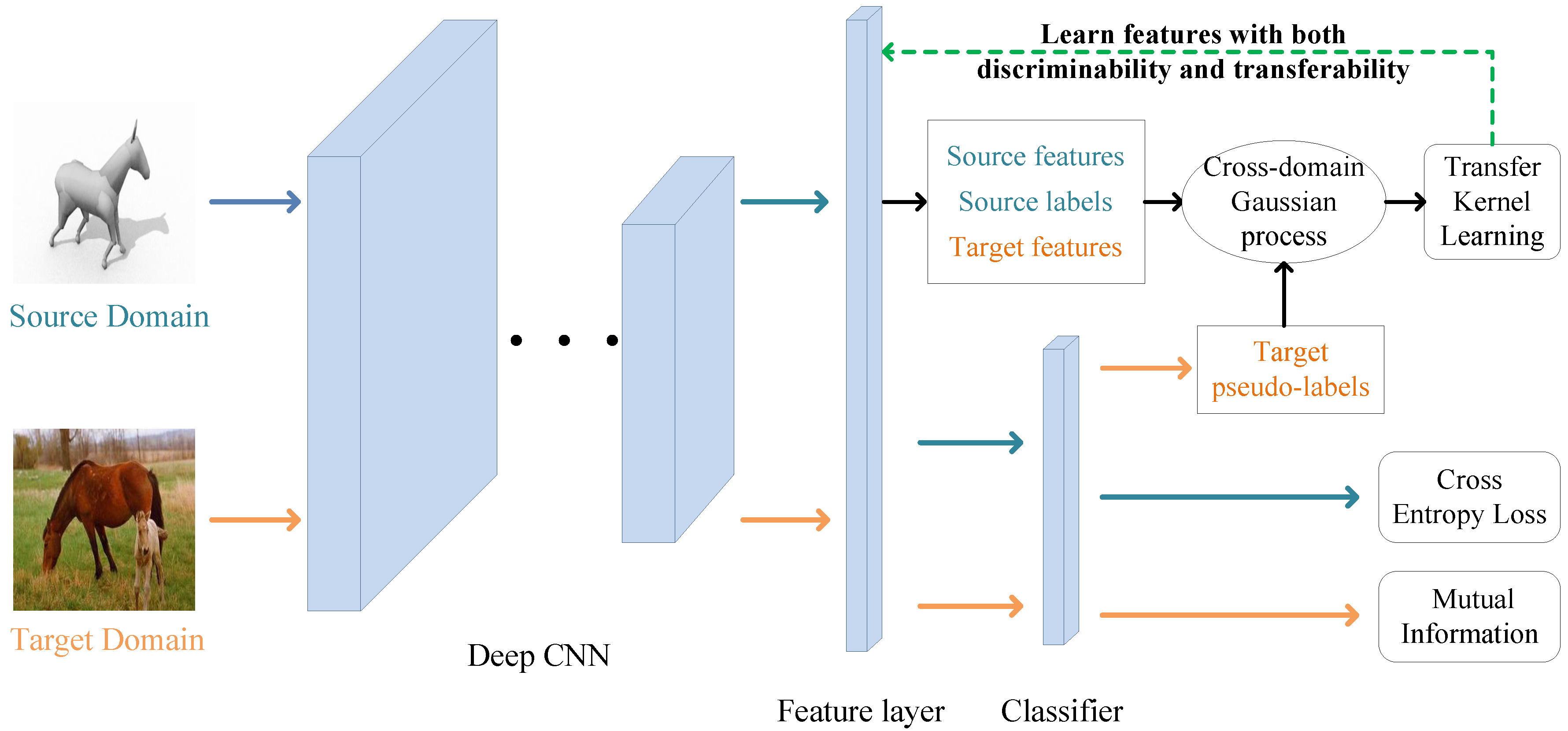
Figure 2 shows the network architecture of GPTKL. The shared deep CNN and classifier are used to obtain deep features and prediction categories, respectively. Transfer kernel learning (TKL) based on Gaussian processes is used to learn deep features with both discriminability and transferability. The cross-entropy loss and mutual information are used to learn the discriminative classification network in the source and target domains, respectively.
The formula description of the UDA task is listed here. The UDA task contains two similar but different datasets: the source domain contains labeled samples, and the target domain contains samples without label information. The source and target domains have the same category space but different data distributions. Let denote the deep features extracted by the deep network, represent the kernel function used in GPTKL and c represent the number of categories.
3.2. Gaussian Process-Based Transfer Kernel Learning
Let
denote the dataset consisting of all samples in the source and target domains, and
. To realize the domain fusion of the source and target domains, GPTKL learns a cross-domain Gaussian process on the joint dataset
, i.e.,
, where
denotes random noise,
. The prior distribution of
satisfies
, where
denotes the kernel matrix between
and
. Noting that this cross-domain Gaussian process is established on the joint dataset
of the source and target domains, the dimension of
is thus
. Based on the total probability theorem, the probability distribution of the
j-th class
can be calculated as follows:
where
. Assuming that different categories are independent of each other, then the marginal distribution of
can be calculated as
. To learn a transfer kernel function adapted to both the source and target domains, GPTKL maximizes the log-likelihood function of
. The log-likelihood function of
can be calculated as
where the last item is a constant, which will be omitted for simplicity. In Equation (
5), the kernel function
is the parameter to be trained. However, due to limited computing power, we cannot traverse all kernel functions to find the maximum value of Equation (
5). An effective solution is the deep kernel learning strategy [
38], which transforms the selection of the kernel function into learning a deep network mapping of the constructing kernel, and then learns a deep feature space suitable for measuring sample similarity.
Based on the deep kernel learning strategy, GPTKL inputs the deep features
obtained from the deep CNN into a Gaussian kernel function to calculate the deep kernel matrix, i.e.,
. Furthermore, we can learn a better transfer kernel function by training the deep CNN, and the transfer kernel learning loss
is
where
is the linear kernel matrix of
.
contains two items: the first item minimizes the log determinant of the kernel matrix, which is a penalty term for the model complexity; the second term minimizes the trace of the matrix obtained by multiplying
and
, which connects the sample similarity and the category similarity. We call it similar consistency loss
. Next, we will illustrate the role of
in feature learning through an example.
Consider a 2-tuple , whose kernel matrix is , where . Ignoring the effects of random noise, the inverse matrix of is calculated as . When and belong to the same category and different categories, has different effects. When and belong to the same category, the category kernel matrix , and the similar consistency loss . In this case, minimizing will increase the kernel similarity between and . Conversely, when and belong to two different categories, and . At this time, minimizing will reduce the kernel similarity between and . GPTKL maximizes the similarity of samples with the same label while minimizing the similarity of samples in different classes; thus, it plays a role of discriminant learning in the feature space. Since the cross-domain Gaussian process is based on all data in the source and target domains, GPTKL effectively increases the similarity between source domain features and target domain features from the same category. This process effectively reduces the domain discrepancy between the source and target domains in the deep feature space.
3.3. Classification Model Learning on the Source and Target Domains
In the previous section, through the cross-domain Gaussian process and deep kernel learning technology, GPTKL was able to learn a deep feature space with both discriminability and transferability. As with most deep UDA algorithms, GPTKL uses a fully connected network with a softmax activation function after the deep CNN to obtain the class prediction distribution . In order to obtain better prediction performance, we further train a classification model to extract discriminant information from the source and target domains simultaneously.
In the source domain, GPTKL extracts discriminant information by minimizing the cross-entropy loss
between the predicted distribution
and true label distribution
, i.e.,
GPTKL uses a shared classification model to process the source and target domains. If only
is considered, the learned model may fall into overfitting in the source domain, thereby increasing the classification error in the target domain. In addition, when calculating
, GPTKL needs to use the category information of the target domain, which does not exist in UDA tasks. GPTKL addresses this problem by assigning predicted category distributions as pseudo-labels to target domain samples. In this process, we need to extract the discriminant information in the target domain as much as possible to improve the accuracy of the pseudo-labels. In order to extract the discriminant information in the target domain, GPTKL follows the idea in unsupervised clustering methods [
39,
40] that maximize the mutual information
between target domain samples
and their predicted categorical variables
. The mutual information loss
is defined as the opposite value of
, i.e.,
where
is information entropy and
is conditional entropy. Note that
constrains the model to maintain the balance of predicted categories, while
constrains the classification boundary through the low-density regions of the feature space to reduce the uncertainty of classification.
3.4. Loss Function and Training Procedure
The optimization objective of GPTKL includes three items, i.e., TKL loss
, cross-entropy loss
and mutual information loss
. Combining Equations (
6)–(
8), the overall loss function of GPTKL is
where
represents all network parameters in the deep network, and
and
represent the weight hyper-parameters of
and
, respectively.
When GPTKL is implemented, it consists of two sequential phases. First, we pretrain the deep network using labeled data from the source domain. Next, samples from the source and target domains are used together to calculate the loss function in Equation (
9) and update the deep network parameters based on the gradient descent algorithm. The overall algorithm of GPTKL is summarized in Algorithm 1.
| Algorithm 1 The algorithm of GPTKL |
Input: , .
Output: The network parameters .
- 1:
Pre-train the deep network using cross-entropy loss ( 7) in . - 2:
while not converged do - 3:
Random sample a mini-batch dataset and from and , respectively; - 4:
Calculate the class prediction distribution for each sample by current deep network, and provide pseudo-labels for target domain samples; - 5:
Calculate the TKL loss , cross-entropy loss and mutual information loss by Equations ( 6)–( 8), respectively; - 6:
Compute the gradients of , , and w.r.t. ; - 7:
Update the network parameters by gradient descend algorithm to minimize Equation ( 9); - 8:
end while
|
We further discuss the computational complexity of GPTKL. The computational complexity of GPTKL can be calculated from the three loss functions in Equation (
9). Among them, cross entropy loss
and mutual information loss
have linear computational complexity. In TKL loss, the computation focuses on the inverse matrix operations in Equation (
6). Therefore, the computational complexity of TKL loss is close to
, where
represents the batch size of mini-batch data. Since
is usually very small in the training of deep networks (
in our experiments), the actual cost of GPTKL is smaller than most existing deep UDA methods.
5. Conclusions
This paper proposes a novel UDA method, GPTKL, which achieves domain knowledge transfer by learning a cross-domain Gaussian process and a shared classification model. GPTKL proposes a cross-domain Gaussian process to learn the transfer kernel function, which can better measure the similarity between multi-domain data samples. In order to learn transfer kernels efficiently, GPTKL introduces the deep kernel learning strategy, which can convert the learning of the kernel function into learning a deep feature space suitable for measuring sample similarity. Based on the cross-domain Gaussian process and deep kernel learning strategy, GPTKL learns a deep feature space with both discriminability and transferability. In addition, GPTKL uses cross-entropy loss and mutual information to learn a shared classification model on the source and target domains, respectively. Experiment results show that GPTKL achieves state-of-the-art classification performance on UDA tasks and learns a deep feature space of inter-domain alignment, intra-class compactness and inter-class separation. In the future, we will explore how to extend GPTKL to more machine learning tasks, such as Partial UDA, multi-modal learning and few-shot learning.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}