


Dynamic Optimization Method of Knowledge Graph Entity Relations for Smart Maintenance of Cantilever Roadheaders




Abstract
:1. Introduction
2. Smart Maintenance Knowledge Graph Model for Fault Cause Analysis
- (1)
- Data collection
- (2)
- Identification of a core set of concepts
- (3)
- Fault maintenance knowledge graph modeling
- (4)
- Dynamic optimization of graphical entity relationships
- (5)
- Knowledge graph visualization display

3. Modeling the Static Full-Connected Fault Maintenance Knowledge Graph of Cantilever Roadheader
- (1)
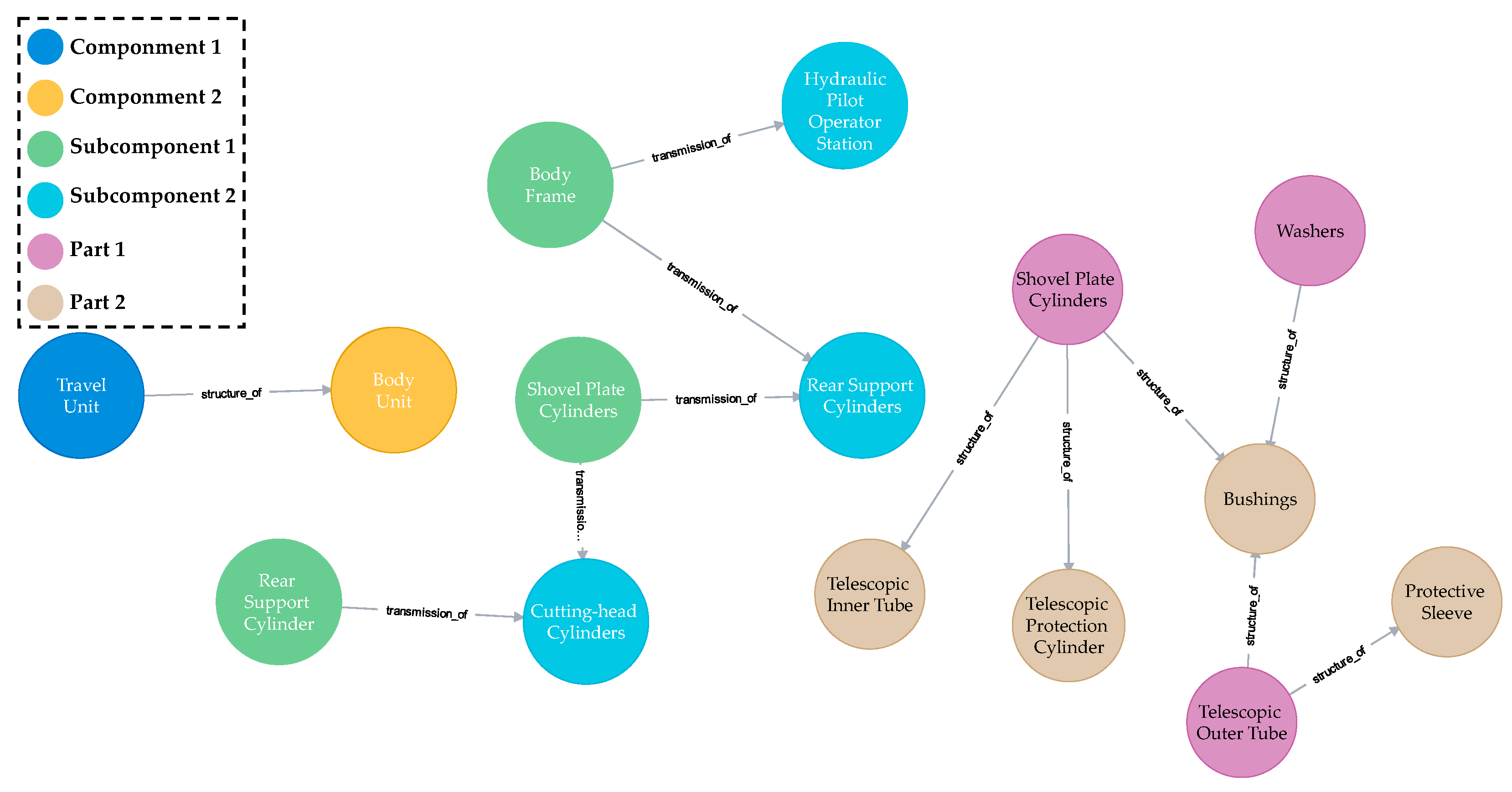
- Mainline of physical structure
- (2)
- Mainline of internal correlation
- (3)
- Mainline of condition monitoring
- (4)
- Mainline of fault maintenance
- (5)
- Merging Networks to Construct a Knowledge Graph Model for Fault Maintenance of Roadheaders
4. Dynamic Optimization of Knowledge Graph Entity Relationships
4.1. Optimization Process Based on Information Entropy and Density-Based DBSCAN Algorithm
4.1.1. Sample Information Entropy
4.1.2. Similarity Measures and Threshold Setting
- (1)
- Select the dataset X = {x1, x2, …, xn} to normalize the data.
- (2)
- Determine the number of clusters M = {M1, M2, …, Mn} based on the normalized data obtained in the first step.
- (3)
- Calculate each cluster’s clustering results and the center coordinate position (xt, yt, zt) using a Python program.
- (4)
- Calculate the distances from each data point to the hyperplane in the clustered data and form a distance matrix.
- (5)
- Discretize the data and count the number of sample labels.
- (6)
- Calculate the probability p(xi) and q(yi) of the occurrence of the data sample, and then calculate the information entropy of each data point in the hyperplane projection according to Equations (13) and (14).
- (7)
- Calculate the information entropy of the real dataset of the fault information and the information entropy of the data of the associated entities. Utilize the absolute difference method for comparison.
- (8)
- Based on the entropy value of the real data, calculate the absolute difference between the two entities. If the information entropy of the sample data and the real entropy value are close, the output results are generated directly, otherwise, return to the first step, and continue to optimize the judgment of the other data. Through this result, the relationship between the entities in the graph is dynamically optimized.

4.2. Analysis Process of Information Entropy and Density-Based DBSCAN Clustering Algorithm Based on a Static Graph
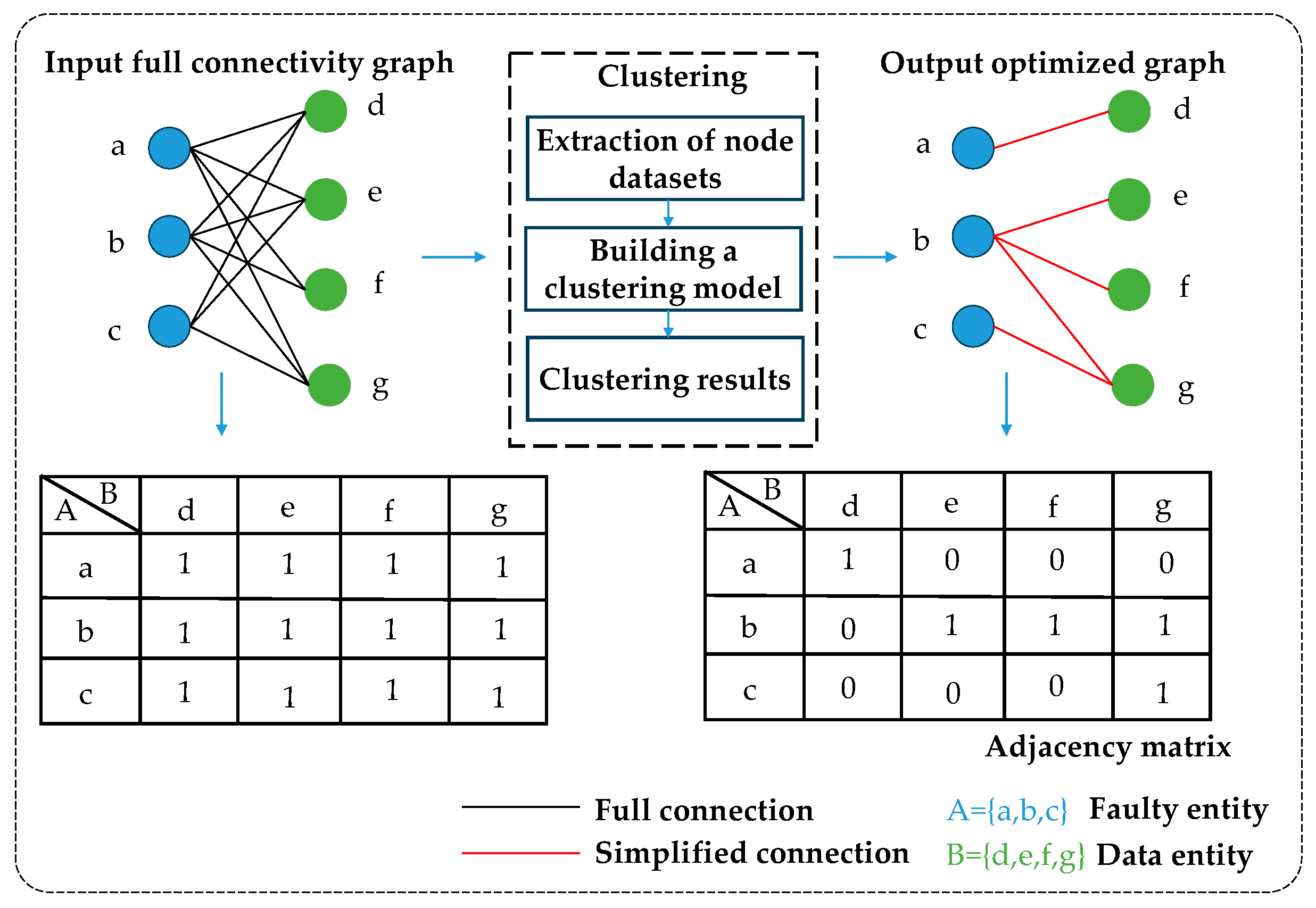
- (1)
- First, the network connected by the input condition monitoring mainline and the fault maintenance mainline is the neighbor matrix corresponding to the static full-connected network, where A = {a, b, c} denotes the fault node set and B = {d, e, f, g} denotes the original data node set, and a link set exists between A and B.
- (2)
- Extract the monitoring history dataset, establish a local clustering model based on data entities, determine the information entropy of the data in each dimension on the projection plane, and compare the requested information entropy with the information entropy of the data known to be absolutely related to the fault phenomenon. Finally, determine the weight size of the relationship between entities using the comparison results.
- (3)
- Output the optimization graph (output the optimization adjacency matrix).
4.3. Dynamic Optimization Process of Entity Relationships Based on Condition Monitoring Dataset
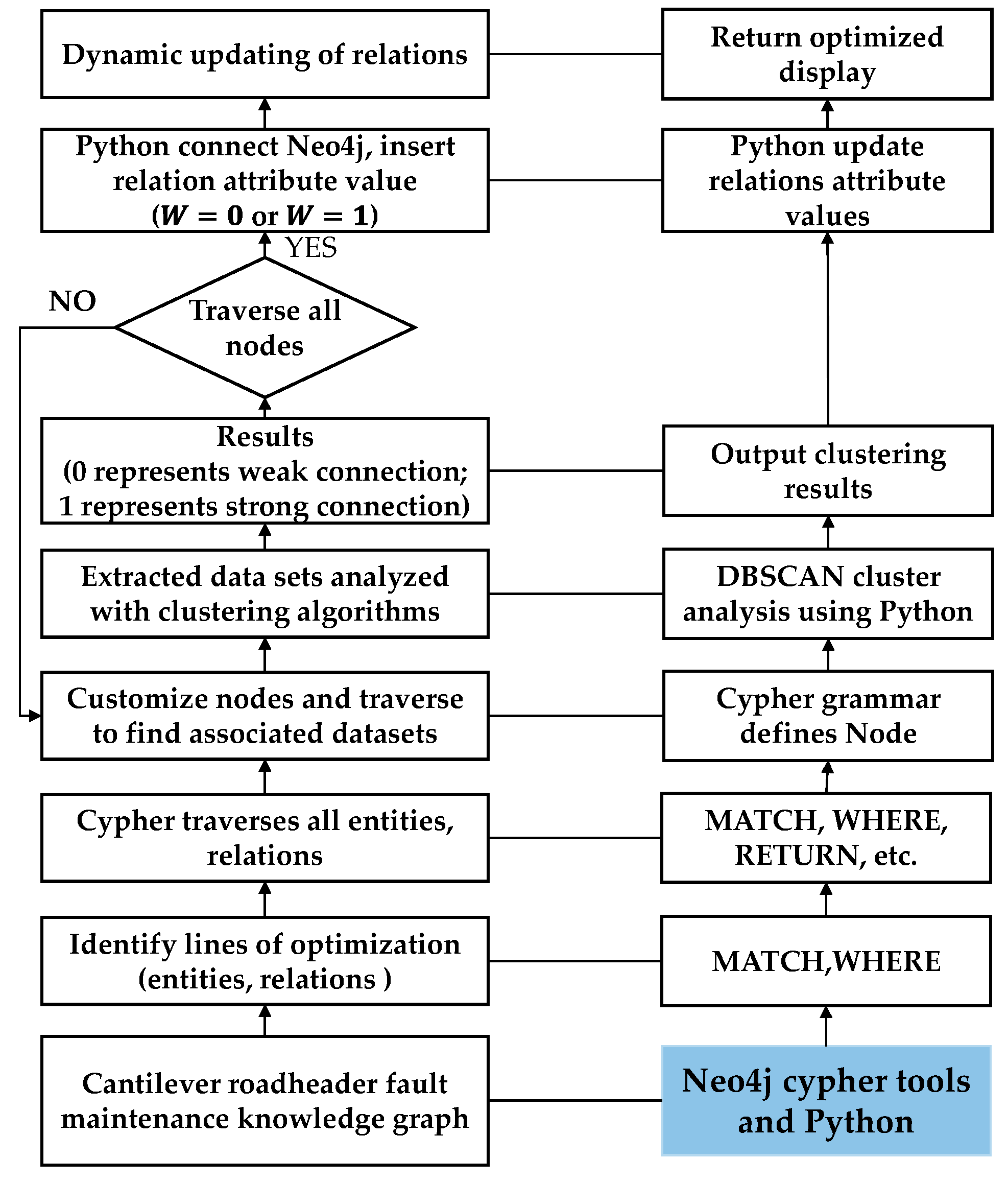
- (1)
- Determine the analysis object according to the optimization objective, narrow down the relationship optimization path, and use Neo4j-based Match and Where statements to find all nodes and relationships in the condition monitoring mainline global graph.
- (2)
- Use the Cypher tool to find the specific nodes and relationships in the local graph that must be optimized, such as the three subnetworks of fault phenomena and data, data, and fault causes, and characteristic indicators and fault causes.
- (3)
- Select the starting point of any subnetwork, customize the starting point node, query the relevant dataset nodes, traverse all the fault nodes, and repeat the above steps for the remaining lines until all the fault nodes are traversed. N represents the total number of fault nodes.
- (4)
- Extract the node dataset and data feature index node set associated with each fault node, analyze and model the data according to the data characteristics, analyze the data using information entropy and density-based DBSCAN clustering algorithm by using Python tools, output the analysis results, and cycle through all the local dataset nodes, where S represents the total number of datasets.
- (5)
- Use information entropy and clustering results to judge the strength of the relationship by further calculating the absolute difference and threshold setting. Determine whether all nodes and clustered datasets have been traversed; if so, proceed to the next step; otherwise, return to step 3 and repeat.
- (6)
- Use Python to connect to the Neo4j database and use the results to add weight value attributes to each relationship to dynamically optimize the relationship. Return to step 2, select the faulty nodes again, and repeat the previous steps until all the relationships between the faulty nodes are optimized.
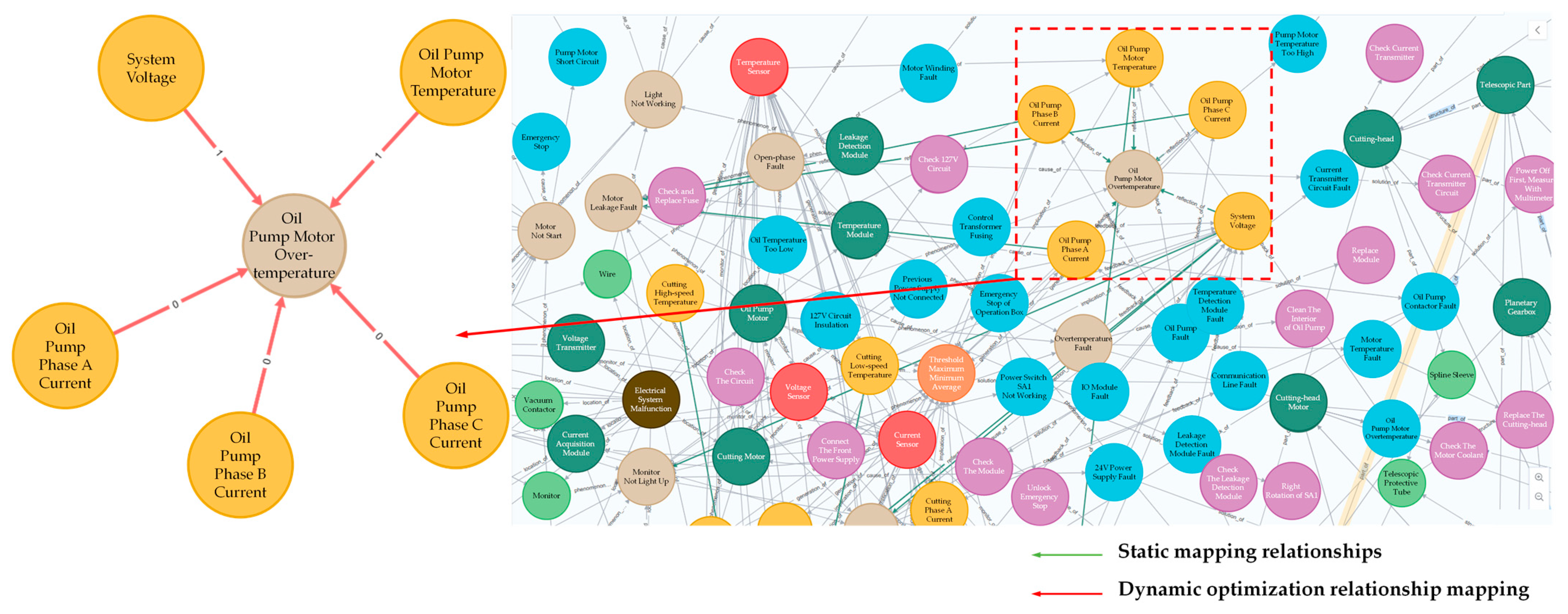
5. Implementation of Cantilever Roadheader Smart Maintenance Knowledge Graph
5.1. Neo4j-Based Knowledge Graph Visualization Display
5.2. Visualization after Dynamic Optimization of Entity Relations
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, G.F. Discussion on the latest technological progress and problems of coal mine intelligentization. Coal Sci. Technol. 2022, 50, 1–27. [Google Scholar]
- Li, E.L.; Wen, B.G. Development trend of cantilever roadheader in China. Coal Min. Mach. 2013, 34, 4–7. [Google Scholar]
- Tian, W.Q.; Tian, Y.; Jia, Q.; Zhang, K. Research status and development trend of navigation technology of cantilever type roadheader. Coal Sci. Technol. 2022, 50, 267–274. [Google Scholar]
- Zhang, X.H.; Liu, Y.W.; Mao, Q.H.; Yang, W.J. Research and progress of intelligent control technology of coal mine cantilever roadheader. Heavy Mach. 2018, 342, 22–27. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, Z.; Yang, Y.; Geng, C.; Zuo, M.J. Time-frequency ridge estimation: An effective tool for gear and bearing fault diagnosis at time-varying speeds. Mech. Syst. Signal Process. 2023, 189, 110108. [Google Scholar] [CrossRef]
- Li, Y.; Geng, C.; Zuo, M.J.; Liang, X. Use of vibration signal to estimate instantaneous angular frequency under strong nonstationary regimes. Mech. Syst. Signal Process. 2023, 200, 110571. [Google Scholar] [CrossRef]
- Duan, Y.; Cao, X.; Zhao, J.; Xu, X. Health indicator construction and status assessment of rotating machinery by spatio-temporal fusion of multi-domain mixed features. Measurement 2022, 205, 112170. [Google Scholar] [CrossRef]
- Duan, Y.; Cao, X.; Zhao, J.; Li, M.; Yang, X. A Spatio-temporal Fusion Autoencoder-based Health Indicator Automatic Construction Method for Rotating Machinery Considering Vibration Signal Expression. IEEE Sens. J. 2023, 23, 24822–24838. [Google Scholar] [CrossRef]
- Zhang, T.R.; Yu, T.B.; Zhao, H.F.; Wang, W.S. Application of data mining technology in fault diagnosis of full-section roadheading machine. J. Northeast. Univ. (Nat. Sci. Ed.) 2015, 36, 527–531+541. [Google Scholar]
- Yang, J.J.; Tang, Z.W.; Wang, Z.R.; Wu, M. Fault diagnosis of cutoff section of roadheader based on PSO-BP neural network. Coal Sci. Technol. 2017, 45, 129–134. [Google Scholar]
- Yin, T.Z. Fault Diagnosis Method of Cantilever Type Roadheader Based on Composite Network Topology; China University of Mining and Technology: Xuzhou, China, 2017. [Google Scholar]
- Jin, X.H.; Wang, Y.; Zhang, B. Industrial big data-driven fault prediction and health management. Comput. Integr. Manuf. Syst. 2022, 28, 1314–1336. [Google Scholar]
- Suo, M. Research and Application of Data-Driven Fault Detection Technology. Ph.D. Thesis, Harbin Institute of Technology, Harbin, China, 2018. [Google Scholar]
- Liu, S.; Liu, Q. Research status and prospect of health management of roadway boring machine. Ind. Min. Autom. 2021, 47, 32–37. [Google Scholar]
- Yang, C.Y.; Cao, B.S.; Zhang, X.; Ji, M.J. A review of fault diagnosis methods for belt conveyor systems. Ind. Min. Autom. 2023, 49, 149–158. [Google Scholar]
- Liu, Q.; Zhang, C.; Wei, M.; Chen, Q.; Li, N.W. Fault diagnosis of cut-off arm of roadheader based on optimized BP neural network. Coal Mine Mach. 2020, 41, 146–149. [Google Scholar]
- Bei, Y.J.; Zhou, Y.; Gao, K.W. Knowledge quiz technology for CNC machine tool equipment maintenance. Comput. Integr. Manuf. Syst. 2022, 28, 2881–2893. [Google Scholar]
- Xu, Z.L.; Sheng, Y.P.; He, L.R.; Wang, Y.F. An overview of knowledge graph technology. J. Univ. Electron. Sci. Technol. 2016, 45, 589–606. [Google Scholar]
- Chai, Z.; Liu, C.; Zhu, M.; Han, Y. Fault detection method for power plant equipment based on correlation analysis of multi-source sensing data. Comput. Digit. Eng. 2019, 47, 682–688. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef]
- Honga, A.; Blomqvist, E.; Cochez, M.; D’amato, C.; Melo, D.G.; Gutierrez, C.; Kirrane, S.; Gayo, L.E.; Navigli, R.; Ngomo, N.A.C.; et al. Knowledge Graphs. ACM Comput. Surv. 2022, 54, 1–37. [Google Scholar]
- Zhang, Y.Q.; Ding, K.; Hui, J.Z.; Liu, S.C.; Guo, W.J.; Wang, L.H. Skeleton-RGB integrated highly similar human action prediction in human–robot collaborative assembly. Robot. Cim-Int. Manuf 2024, 86, 102659. [Google Scholar] [CrossRef]
- Tao, L.F.; Liu, H.F.; Zhang, J.K.; Su, X.Y.; Li, S.Y.; Jie, H.; Chen, L.; Suo, M.L.; Wang, C. Associated Fault Diagnosis of Power Supply Systems Based on Graph Matching: A Knowledge and Data Fusion Approach. Mathematics 2022, 10, 4306. [Google Scholar] [CrossRef]
- He, L.L.; Jiang, P.Y. Manufacturing Knowledge Graph: A Connectivism to Answer Production Problems Query With Knowledge Reuse. IEEE Access 2019, 7, 101231–101244. [Google Scholar] [CrossRef]
- Yahya, M.; Breslin, J.G.; Ali, M.I. Semantic Web and Knowledge Graphs for Industry 4.0. Appl. Sci. 2021, 11, 5110. [Google Scholar] [CrossRef]
- Lou, P.; Yu, D.; Jiang, X.; Hu, J.; Zeng, Y.; Fan, C. Knowledge Graph Construction Based on a Joint Model for Equipment Maintenance. Mathematics 2023, 11, 3748. [Google Scholar] [CrossRef]
- Chen, C.; Wang, T.; Yu, Z.; Liu, Y.; Xie, H.J.; Deng, J.F.; Liang, L.C. Reinforcement Learning-Based Distant Supervision Relation Extraction for Fault Diagnosis Knowledge Graph Construction under Industry 4.0. Adv. Eng. Inform. 2023, 55, 101900. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, X.H.; Cao, X.G.; Zhao, Y.J.; Yang, W.J.; Du, Y.Y.; Shi, S. Construction of digital twin and parallel intelligent control method for excavation face. J. China Coal Soc. 2022, 47, 384–394. [Google Scholar]
- Cai, A.J.; Zhang, Y.; Ren, Z.G. Construction of fault knowledge map for coal mining equipment. Ind. Min. Autom. 2023, 49, 46–51. [Google Scholar]
- Qiu, Y.F.; Xing, H.R.; Li, G. A review of research on the construction of knowledge graph for mine construction. Comput. Eng. Appl. 2023, 59, 64–79. [Google Scholar]
- Li, Z.; Zhou, B.; Li, W.H.; Li, X.Y.; Zhou, Y.; Feng, Z.K.; Zhao, H. Construction and application of knowledge mapping of coal mine electromechanical equipment accidents. Ind. Min. Autom. 2022, 48, 109–112. [Google Scholar]
- Cao, X.G.; Zhang, M.Y.; Lei, Z.; Duan, X.Y.; Chen, R.H. Construction and application of knowledge mapping for coal mine equipment maintenance. Ind. Min. Autom. 2021, 47, 41–45. [Google Scholar]
- Sharma, K.K.; Seal, A.; Yazidi, A.; Krejcar, O. A New Adaptive Mixture Distance-Based Improved Density Peaks Clustering for Gearbox Fault Diagnosis. IEEE Trans. Instrum. Meas. 2022, 71, 3528716. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, B.; Li, X.; Tang, W.; Zhang, G. An Optimized k-means Algorithm Based on Information Entropy. Comput. J. 2021, 64, 1130–1143. [Google Scholar] [CrossRef]
- Zhao, S.Z. Research and application of clustering algorithm based on relative density. Mod. Comput. 2013, 13, 3–7+20. [Google Scholar]
- Lin, T.; Ma, T.; Qin, D.Y.; Dong, S. Research on fault diagnosis of wind turbine based on improved DBSCAN algorithm. Mod. Electron. Technol. 2018, 41, 146–149+155. [Google Scholar]
- Chen, G.; Wen, G.H.; Yu, W.W. A review of research on urban public transportation network based on complex network. J. Nanjing Univ. Inf. Eng. (Nat. Sci. Ed.) 2018, 10, 401–408. [Google Scholar]
- Li, J.; Huang, T. Research on the evaluation of fault diagnosis effect of optical communication system based on graph theory. Laser J. 2022, 43, 136–140. [Google Scholar]
- Bales, M.E.; Johnson, S.B. Graph Theoretic Modeling of Large-Scale Semantic Networks. J. Biomed. Inform. 2006, 39, 451–464. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.S.; Xiao, G.; Meng, H.C.; Zhuang, C.B.; Zhang, Y.M.; Cheng, Z.B. Design-oriented computing multi-layer knowledge graph construction method and application. Computer Integrated Manufacturing Systems. Comput. Integr. Manuf. Syst. 2023, 29, 1–20. [Google Scholar]
- Wang, Y.; Cao, X.G.; Zhang, X.H.; Fan, H.W.; Duan, Y.; Huo, X.Q. Construction of knowledge base for intelligent maintenance of coal mining machine based on knowledge graph. Ind. Min. Autom. 2021, 47, 29–36. [Google Scholar]
- Bouarroudj, W.; Boufaida, Z.; Bellatreche, L. Named Entity Disambiguation in Short Texts over Knowledge Graphs. Knowl. Inf. Syst. 2022, 64, 325–351. [Google Scholar] [CrossRef]
- Al-Moslmi, T.; Ocana, M.G.; Opdahl, A.L.; Veres, C. Named Entity Extraction for Knowledge Graphs: A Literature Overview. IEEE Access 2020, 8, 32862–32881. [Google Scholar] [CrossRef]
- Weng, Y.; Zhang, N.; Yang, X. Improved Density Peak Clustering Based on Information Entropy for Ancient Character Images. IEEE Access 2019, 7, 81691–81700. [Google Scholar] [CrossRef]
- Lu, R.; Shen, H.; Feng, Z.; Li, H.; Zhao, W.; Li, X. HTDet: A Clustering Method using Information Entropy for Hardware Trojan Detection. Tsinghua Sci. Technol. 2021, 26, 48–61. [Google Scholar] [CrossRef]
- Jun-Jie, X.U.; Chen, R. Probabilistic Diagnosis Approach to Diagnosing Multiple-fault Programs with Fault Correlation. Comput. Sci. 2017, 44, 124–130. [Google Scholar]
- Wang, X.; Liu, M.; Liu, C.H.; Ling, L.; Zhang, X. Data-driven and Knowledge-based predictive maintenance method for industrial robots for the production stability of intelligent manufacturing. Expert Syst. Appl. 2023, 234, 121136. [Google Scholar] [CrossRef]
- Xia, L.; Liang, Y.; Leng, J.; Zheng, P. Maintenance planning recommendation of complex industrial equipment based on knowledge graph and graph neural network. Reliab. Eng. Syst. Saf. 2023, 232, 109068. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Samples | Dimensions | Aggregate Data |
|---|---|---|---|
| System voltage | 1000 | 3 | 1000 |
| Oil pump a-phase current | 1000 | 3 | 1000 |
| Oil pump b-phase current | 1000 | 3 | 1000 |
| Oil pump c-phase current | 1000 | 3 | 1000 |
| Oil pump motor temp | 1000 | 3 | 1000 |
| Historical data | 1000 | 3 | 5000 |
| Name | System Voltage | Fuel Pump Current | Temperature of Fuel Pump Motor |
|---|---|---|---|
| Information entropy of real entities | 1.7358688 | 2.07710315 | 1.12312751 |
| 1.98780557 | 1.70744128 | 1.36216711 | |
| 1.96920776 | 1.91478088 | 1.04663344 | |
| 1.93631029 | 1.36318644 | 1.59836601 | |
| Real entities average entropy value | 1.9072981 | 1.76529742 | 1.28749876 |
| Information entropy of related entities | 1.71299956 | 2.08210018 | 1.32193058 |
| Absolute difference | 0.19429854 | 0.31680598 | 0.03443182 |
| Dataset | Dimensions | Clustering Algorithms | Eps | Mints | Running Time/s | Accuracy |
|---|---|---|---|---|---|---|
| Historical dataset for roadhead-ers | 3 | Traditional DBSCAN | 0.1 | 7 | 5.77993 | 85.9% |
| Information entropy and density-based DBSCAN | 0.15 | 6 | 6.99355 | 97.8% |
| Method | Result | Relationship Weight |
|---|---|---|
| Static fault knowledge graph cypher query | System voltage | 1 |
| Oil pump phase a current | 1 | |
| Oil pump phase b current | 1 | |
| Oil pump phase c current | 1 | |
| Temperature of fuel pump motor | 1 | |
| Traditional DBSCAN algorithm query | System voltage | 1 |
| Oil pump phase c current | 1 | |
| Temperature of fuel pump motor | 1 | |
| Information entropy and density-based DBSCAN query | System voltage | 1 |
| Temperature of fuel pump motor | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Liu, Y.; Ding, K.; Wei, S.; Zhang, X.; Zhao, Y. Dynamic Optimization Method of Knowledge Graph Entity Relations for Smart Maintenance of Cantilever Roadheaders. Mathematics 2023, 11, 4833. https://doi.org/10.3390/math11234833
Wang Y, Liu Y, Ding K, Wei S, Zhang X, Zhao Y. Dynamic Optimization Method of Knowledge Graph Entity Relations for Smart Maintenance of Cantilever Roadheaders. Mathematics. 2023; 11(23):4833. https://doi.org/10.3390/math11234833
Chicago/Turabian StyleWang, Yan, Yuepan Liu, Kai Ding, Shirui Wei, Xuhui Zhang, and Youjun Zhao. 2023. "Dynamic Optimization Method of Knowledge Graph Entity Relations for Smart Maintenance of Cantilever Roadheaders" Mathematics 11, no. 23: 4833. https://doi.org/10.3390/math11234833
APA StyleWang, Y., Liu, Y., Ding, K., Wei, S., Zhang, X., & Zhao, Y. (2023). Dynamic Optimization Method of Knowledge Graph Entity Relations for Smart Maintenance of Cantilever Roadheaders. Mathematics, 11(23), 4833. https://doi.org/10.3390/math11234833