1. Introduction
The optimization of cash flow management has a long history in the area of actuarial science. The original study on the cash flow optimization can be traced back to 1957. At that time, De Finetti [
1] proposed the maximization problem of the expected present value of the dividend payments of the insurance company. From then on, the management of cash leakages played an important role to measure the performance of the insurance company and also attracted the public attentions in the academic area. As an example, Ref. [
2] considered the optimal dividend problem of diffusion process with transaction fees. Ref. [
3] explored the optimal dividend pay-out optimization when the surplus follows the controlled diffusion risk model. Ref. [
4] generalized the Brownian motion to the compound Poisson risk process and studied the corresponding optimal dividend with bounded dividend rate. Ref. [
5] explored the optimal investment and dividend problem for the renewal process by viscosity solution approach. In the setting of continuous-time model, the dividend optimization has been investigated under various modellings in recent years. For more relevant references, one can see [
6,
7,
8]. We also refer the reader to [
9] for the exhaustive references to seek the past development on the issue of dividend optimization.
A lot of references such as [
10,
11] considered the optimal dividend problem under the condition that the discount factor is a constant. As we know, compared with the constant interest rate, the stochastic interest rate can simulate market changes more realistically. The optimal dividend policy with random interest rates of continuous time was studied in [
12] in which the authors considered the effects of financial markets and concluded that a firm will pay more dividend if the interest rate is high and pay less dividend if the interest rate is low. Ref. [
13] also considered the optimal dividend problem with stochastic interest rate while the stochastic interest rates are modelled by the geometric Brownian motion and the Ornstein–Uhlenbeck process, respectively. Moreover, the authors derived the explicit solution of the optimal strategy for the first case and switched to the viscosity solution analysis for the second case. In our paper, we also consider the optimal dividend under different interest rates.
To the best of our knowledge, compared with the continuous time model, there are fewer articles dealing with discrete time model. However, the discrete-time model’s advantage is that it is more close to the reality. In reality, all transactions are conducted on weekdays. In the setting of discrete-time model, Ref. [
14] assumed that in one period the surplus risk process follows a time-homogenous Markov process with possible values
and proved that the optimal dividend policy is of band type. Ref. [
15] considered the optimal dividend of the compound binomial model with bounded dividend rate. The discrete-time dividend problem under random interest rate was studied in [
16] in which the authors consider a constant penalty should be paid when the ruin occurs. Inspired by [
17], instead of a ruin penalty, we consider that a subsidy must be paid to shareholders each unit time as long as the company is not bankrupt. The company aims to maximize the cumulative discounted dividends and subsidies before ruin. In our paper, we use mathematical method to explore such financial optimization problem for the insurance company.
There are various approaches to solve the optimal strategy in the field of stochastic optimal control. In our paper, the dynamic programming principle is applied to analyze this optimization problem. We first show the dynamic programming equation (or in other words, the discrete Hamilton–Jacobi–Bellman equation) and then the contraction mapping is applied to show that the dynamic programming equation has a unique solution. Later, a numerical algorithm based on the fixed-point theory is put forward to solve the dynamic equation as well as the optimal policy. In the last, two examples are shown to demonstrate the applicability of the algorithm.
The paper is constructed as follows.
Section 2 introduces the model of surplus, interest rates and the optimization problem.
Section 3 proves that the optimal value function satisfies the dynamic programming equation. Based on Banach contraction mapping principle from fixed-point theory, it is shown that the dynamic programming equation has a unique solution. Based on the uniqueness of the solution,
Section 4 constructs an algorithm to solve the dynamic programming equation as well as the optimal policy.
Section 5 lists two examples to demonstrate the applicability of the algorithm and some economic reasons are explained.
2. The Model and Preliminaries
In this paper, we assume that the wealth of the insurance company is given as follows:
Let
be written as the initial wealth of the company and the constant
as the premium each unit time. At time
, the claim
occurs with a probability
, where
is a positive constant. Mathematically speaking, the distribution of
is written by
We also assume that the claim a amount
are independent and identically distributed. Furthermore,
are also assumed to be positive integer-valued random variables with common distribution
F. For simplicity, we denote the distribution of the claim amount
S as
We assume that there are
m different interest rates
on the financial market and the interest rates are driven by a stationary Markov chain with the transition matrix
Apparently, we know that for all , . The Markov chain shows that if the current interest rate at time i is , then at next time , the interest rate becomes with probability .
Now we define the discount rate , . Obviously, the discount factor satisfies and the corresponding switching transition matrix of discount rate is still the matrix . Denote as a filtered probability space, here is generated by the Markov chain which drives the interest rate and the processes we defined before.
In the following, we always denote
as the set of all positive integers,
as the set of all non-negative positive integers. Denote
as the dividend amount at time
k and
as the cumulative dividend before time
n. The controlled dynamics of the wealth can be formulated mathematically by
We call the dividend strategy admissible if the following conditions are satisfied:
- (1)
The dividend amount at time k is non-negative integer-valued and predictable with respect to the filtration .
- (2)
The dividend amount shall not exceed , where denotes the wealth at time k before the dividend is paid. In other words, the dividend should not leads to ruin.
- (3)
The dividend strategy is time-consistent, which means that the amount paid at time k only depends on the surplus and the current interest rate instead of the time k.
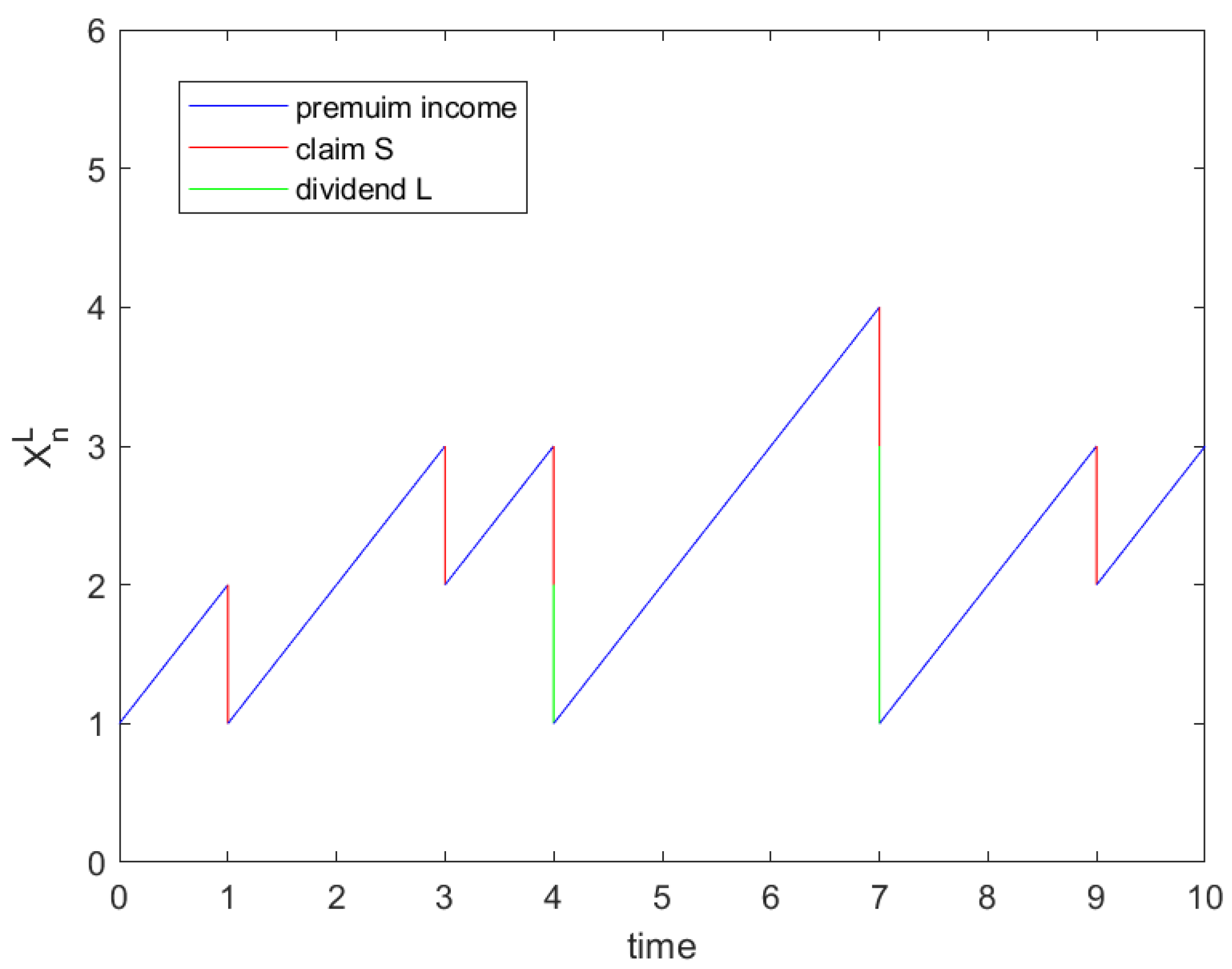
For better presentation, a diagram of one trajectory of the surplus process
is shown in
Figure 1.
Denote
the set of all admissible strategies and define the ruin time of the insurance company as follows:
For the initial wealth
x, the initial interest rate
(the initial discount rate
), and the given dividend policy
, we define the following cumulative discounted dividend value with subsidies:
where
),
is a constant representing the subsidy of unit time. In [
16], the authors considered the dividend optimization if a constant penalty is paid when the ruin occurs. Whereas, in our model, we consider that the shareholders can get a subsidy each unit time as long as the company is not ruined. We aim to find an optimal dividend strategy
to maximize
. For notational simplicity we define the following value function:
Apparently, the value function V is a m-dimensional vector-valued function. From the definition of the value function, we can easily obtain the following property.
Property 1. For any with , it follows that Proof. For the initial wealth
and initial interest rate
(discount rate
), we choose a special strategy
L such that
is paid as dividend at the initial time and then follows the strategy
, where
denotes any arbitrary strategy with initial data
. According to the definition of admissibility of dividend strategy, the lump dividend
is allowed. Then, we can see that
Since
is arbitrary, we have
One can also find the similar idea which was used in other relevant references, for example, the proposition 2.2 of [
18]. □
Now we show some preliminaries about the Banach fixed-point theorem which we will use in following paragraphs. We first show the definition of fixed point.
Definition 1. Let E be a metric space. We call a point z in E a fixed point of the mapping if
Definition 2. Let be a complete metric space. We call a mapping a contraction mapping on E if there exists a constant such thatfor all Now we are ready to present the Banach contraction principle.
Theorem 1 (The Banach Contraction Principle). Let E be a complete metric space and the mapping be a contraction. Then has only one fixed point.
We omit the proof here. The Banach fixed-point theorem guarantees the existence and uniqueness of the fixed point and provides a method to find the fixed point. For more details about the Banach fixed-point theorems and its applications, we refer the interested reader to [
19,
20].
3. The Dynamic Programming Principle
Before stating our theorems, we first define the following notations for simplicity. Denote
the set of all mappings from
to
. Given the function
,
, define the function
Utilize the classical dynamic programming principle, the value function has the following property.
Theorem 2. For the initial wealth x and the initial interest rate (in other words, the initial discount rate ), the value function satisfiesWhen the surplus is x and the interest rate is the optimal dividend is Proof. The dynamic programming equation has been proved in a lot of references, for example, the excellent books [
21,
22], hence we omit the detailed proof here. □
For the sake of notational simplicity, we define the operator
as follows:
It is easy to see that the dynamic programming Equation (
1) can be rewritten as
Now we show that there exists a unique solution for Equation (
2). To this end, we only need to show that the mapping
is a contraction mapping. Accordingly, we have the following theorem:
Theorem 3. The Equation (1) has a unique solution. Proof. For any function
, define the norm by
where
denotes the transpose matrix of the matrix
A.
For any functions
, define the metric
d on
by
Then is a complete metric space.
Assume that
then
Obviously, is a m-dimensional column vector, we first consider the first item of such column vector.
It is not hard to verify that
Similarly, we can show that for each
the
i-th item of the vector
satisfies
Eventually, substituting the inequalities (
4) and (
5) into (
3), we have
where
. Until now, we show that the mapping
is a contraction mapping. Therefore, by using Banach contraction mapping principle, there exists a unique solution to the Equation (
2) as well as the Equation (
1). □
4. Algorithm
In this section, based on the proof of the uniqueness, we show an algorithm to solve the value function via Banach contraction mapping principle which is similar to the Bellman’s recursive algorithm used in [
14].
- (i)
We start from any real-valued function
. Choose
on
and define the new function
by
- (ii)
After calculating , we choose again and iterate the sequences and until both and converge.
Since the value function
is a fixed point of the contraction mapping
, we can see that the value function
Consequently, as long as we choose n large enough, can be seen as a numerical solution of the value function .
Put
. On account of
we get that
For any two positive integer
with
it holds that
Substituting (
6) into (
7) gives
Since the optimal value function
, letting
in (
8) shows that the error estimation can be calculated as
In the meanwhile, when the current surplus is
x and the current interest rate is
, the optimal policy is
Remark 1. In the real financial market, the dividend is paid with taxes (including fixed and proportional transaction costs). For example, Ref. [23] considered the optimal dividend problem considering fixed and proportional transaction costs and the equity issuance. In our model, if we consider the fixed and proportional transaction costs each time the dividend is paid, then the corresponding cumulative discounted dividend with the consideration of ruin time is defined aswhere denotes the indicator function of the event the constant represents the proportion of transaction fee and the constant denotes the fixed transaction fee. Then the dynamic programming principle can be rewritten as The optimal policy is calculated as All the above dynamic principles and algorithms can be rewritten similarly, thus, in this paper we only focus on the optimal dividend problem without transaction fees.
Remark 2. The classical method of solving optimal dividend problem is to solve an explicit solution for the value function or analytically explore the structure of the optimal strategy, see, for example, Refs. [4,14]. In our paper, based on the fixed-point theory, we construct an algorithm to numerically calculate the optimal policy and the value function. Although there is no explicit expression for the value function, the advantages of using the fixed-point theory can be listed as: (1) There is no need to use the boundary condition. (2) The algorithm is easy to be used and constructed. (3) The complex theoretical calculation can be avoided. 



{kind=link}