
A Novel Hybrid Deep Neural Network for Predicting Athlete Performance Using Dynamic Brain Waves

Abstract
:1. Introduction
- Extending the literature regarding dynamic brain waves of cognitive neuroscience on open skills;
- Creating a new categorization model for deep learning for distinguishing the brain waves of elite table tennis athletes when performing well;
- Identifying the key features of brain waves on elite table tennis athletes when performing well.
2. Materials and Methods
2.1. Data Collection
2.1.1. Participants
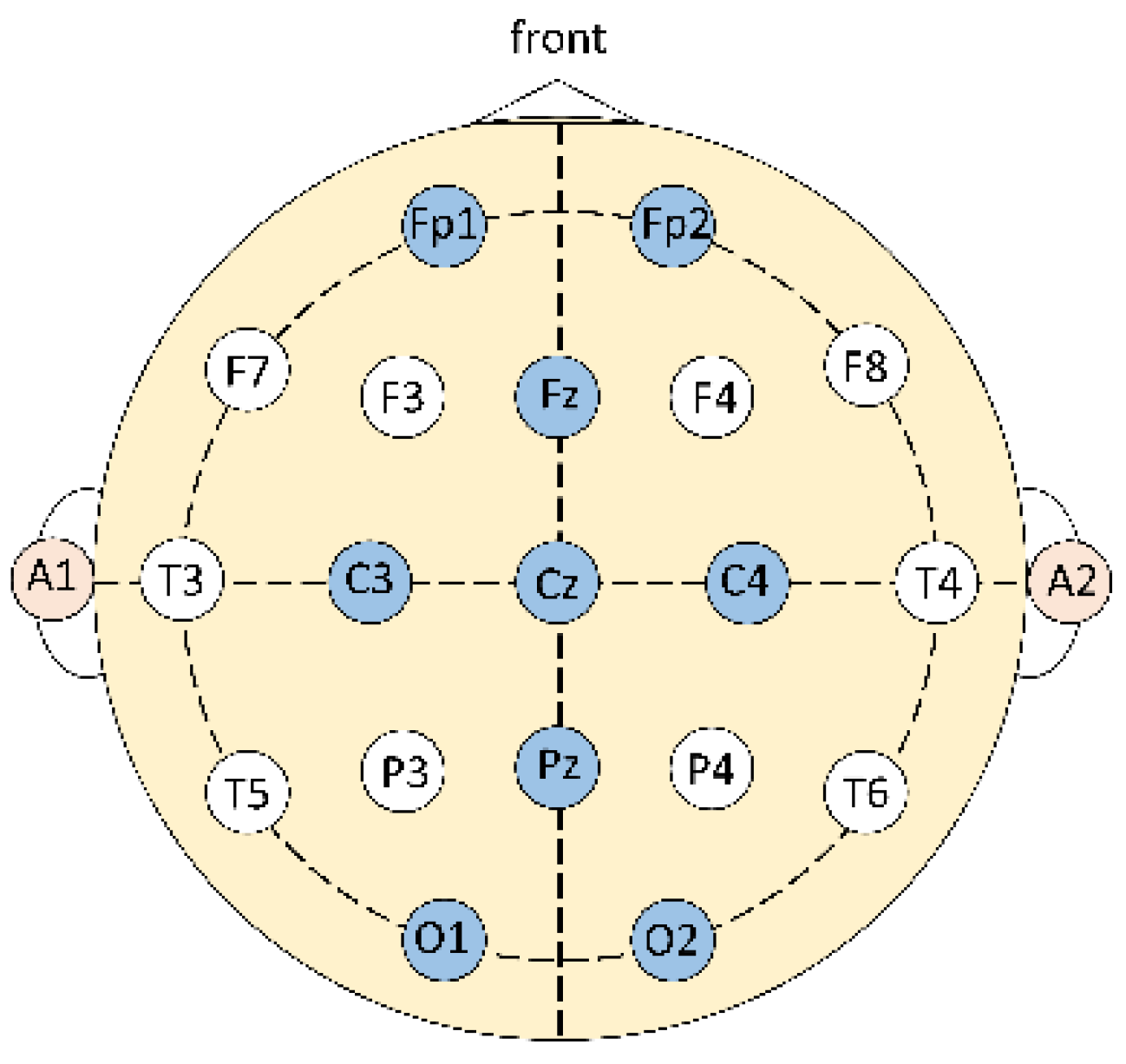
2.1.2. Tools
- EEG device;
- The EEG device is a commercially available porTable 40-lead neuroimaging potential recording system, including a dry electrode cap, a power amplifier, a computer cable, and a set of data acquisition software Curry 8. When in use, the electrode cap is connected to the power amplifier, and then connected to the laptop. The current EEG status is displayed through the data acquisition software in the laptop, and the EEG can be saved as a file.
- This EEG device has dedicated data collection software, and it is not possible to make software to read real-time data. Unlike some EEG devices that use an open architecture, they can read real-time data by themselves [28].
- Software.
- The data analysis is performed in the Google Colab environment, and the software uses Python 3.8.10, Tensorflow 2.9.2, and Keras 2.9.0 to design the models and execute them.
2.1.3. Table Tennis Test
2.2. Data Pre-Processing
2.2.1. Filter
2.2.2. Feature Transform
2.2.3. Data Labeling
2.2.4. Convert 1D Array to 2D Array
2.3. Data Analysis
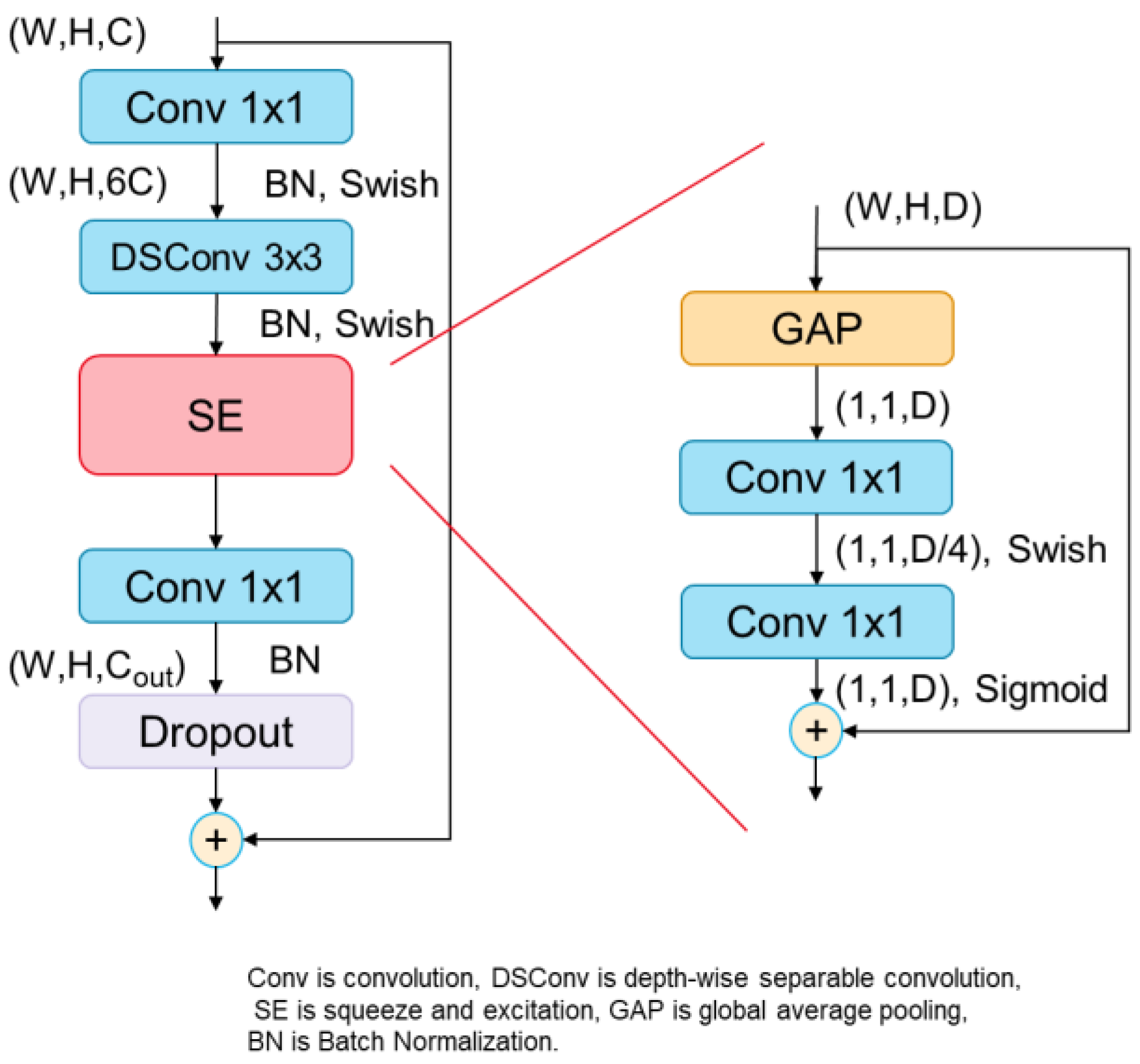
2.3.1. Hybrid Architecture
2.3.2. MBConv Block
- Convolutional Layer;
- Equations for the convolutional layer are as Equations (3) and (4) shows.
- Forward:
- Backward, see Equations (6)–(9):
- 2.
- Average Pooling Layer;
- 3.
- Batch Normalization (BN).
2.3.3. Transformer Block
2.3.4. Mixer Block
- Fully Connected Layer;
- 2.
- Layer Normalization (LN).
2.3.5. Activation Function
- Softmax;
- 2.
- Swish;
- 3.
- Sigmoid;
- 4.
- Gaussian Error Linear Units (GELU).
3. Results and Discussion
3.1. Dataset
3.2. Evaluation Metrics
3.3. Validation Type
3.4. Performance Evaluation of Models
3.5. Comparison of Performance between This Study and Other Models
3.6. Key Feature
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scharfen, H.-E.; Memmert, D. Measurement of cognitive functions in experts and elite athletes: A meta-analytic review. Appl. Cognit. Psychol. 2019, 33, 843–860. [Google Scholar] [CrossRef]
- Fang, Q.; Fang, C.; Li, L.; Song, Y. Impact of sport training on adaptations in neural functioning and behavioral performance: A scoping review with meta-analysis on EEG research. J. Exerc. Sci. Fit. 2022, 20, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Hramov, A.-E.; Pisarchik, A.-N. Kinesthetic and Visual Modes of Imaginary Movement: MEG Studies for BCI Development. In Proceedings of the 2019 3rd School on Dynamics of Complex Networks and Their Application in Intellectual Robotics (DCNAIR), Innopolis, Russia, 9–11 September 2019; pp. 66–68. [Google Scholar] [CrossRef]
- Zhang, L.; Qiu, F.; Zhu, H.; Xiang, M.; Zhou, L. Neural efficiency and acquired motor skills: An fMRI study of expert athletes. Front. Psychol. 2019, 10, 2752. [Google Scholar] [CrossRef] [PubMed]
- Magan, D.; Yadav, R.K.; Bal, C.S.; Mathur, R.; Pandey, R.M. Brain Plasticity and Neurophysiological Correlates of Meditation in Long-Term Meditators: A 18Fluorodeoxyglucose Positron Emission Tomography Study Based on an Innovative Methodology. J. Altern. Complement. Med. 2019, 25, 1172–1182. [Google Scholar] [CrossRef]
- Carius, D.; Kenville, R.; Maudrich, D.; Riechel, J.; Lenz, H.; Ragert, P. Cortical processing during table tennis—An fNIRS study in experts and novices. Eur. J. Sport Sci. 2021, 17, 1315–1325. [Google Scholar] [CrossRef]
- Giannakakis, G.; Grigoriadis, D.; Giannakaki, K.; Simantiraki, O.; Roniotis, A.; Tsiknakis, M. Review on psychological stress detection using biosignals. IEEE Trans. Affect. Comput. 2019, 3, 440–460. [Google Scholar] [CrossRef]
- Jawabri, K.H.; Sharma, S. Physiology, Cerebral Cortex Functions; StatPearls Publishing: Treasure Island, FL, USA, 2022. [Google Scholar]
- Chuang, L.Y.; Huang, C.J.; Hung, T.M. The differences in frontal midline theta power between successful and unsuccessful basketball free throws of elite basketball players. Int. J. Psychophysiol. 2013, 90, 321–328. [Google Scholar] [CrossRef]
- Wang, C.-H.; Tsai, C.-L.; Tu, K.-C.; Muggleton, N.G.; Juan, C.-H.; Liang, W.-K. Modulation of brain oscillations during fundamental visuo-spatial processing: A comparison between female collegiate badminton players and sedentary controls. Psychol. Sport Exerc. 2015, 16, 121–129. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Hung, C.L.; Huang, C.J.; Chang, Y.K.; Lo, L.C.; Shen, C.; Hung, T.M. Expert-novice differences in SMR activity during dart throwing. Biol. Psychol. 2015, 110, 212–218. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.-Y.; Wang, K.-P.; Hung, C.-L.; Tu, Y.-L.; Huang, C.-J.; Koester, D.; Schack, T.; Hung, T.-M. Higher power of sensorimotor rhythm is associated with better performance in skilled air-pistol shooters. Psychol. Sport Exerc. 2017, 32, 47–53. [Google Scholar] [CrossRef]
- You, Y.; Ma, Y.; Ji, Z.; Meng, F.; Li, A.; Zhang, C. Unconscious Response Inhibition Differences between Table Tennis Athletes and Non-Athletes. PeerJ 2018, 6, e5548. [Google Scholar] [CrossRef]
- Pluta, A.; Williams, C.C.; Binsted, G.; Hecker, K.G.; Krigolson, O.E. Chasing the Zone: Reduced Beta Power Predicts Baseball Batting Performance. Neurosci. Lett. 2018, 686, 150–154. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.P.; Cheng, M.Y.; Chen, T.T.; Huang, C.J.; Schack, T.; Hung, T.M. Elite golfers are characterized by psychomotor refinement in cognitive-motor processes. Psychol. Sport Exerc. 2020, 50, 101739. [Google Scholar] [CrossRef]
- Jakhar, D.; Kaur, I. Artificial intelligence, machine learning and deep learning: Definitions and differences. Clin. Exp. Dermatol. 2020, 45, 131–132. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 604–624. [Google Scholar] [CrossRef]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef]
- Wang, Z.; Cao, L.; Zhang, Z.; Gong, X.; Sun, Y.; Wang, H. Short time Fourier transformation and deep neural networks for motor imagery brain computer interface recognition. Concurr. Comput. 2018, 30, e4413. [Google Scholar] [CrossRef]
- Alhagry, S.; Aly, A.; Reda, A. Emotion Recognition based on EEG using LSTM Recurrent Neural Network. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 355–358. [Google Scholar] [CrossRef]
- Sun, J.; Wang, X.; Zhao, K.; Hao, S.; Wang, T. Multi-Channel EEG Emotion Recognition Based on Parallel Transformer and 3D-Convolutional Neural Network. Mathematics 2022, 10, 3131. [Google Scholar] [CrossRef]
- Cui, F.; Wang, R.; Ding, W.; Chen, Y.; Huang, L. A Novel DE-CNN-BiLSTM Multi-Fusion Model for EEG Emotion Recognition. Mathematics 2022, 10, 582. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhong, Q. Differential Entropy Feature Signal Extraction Based on Activation Mode and Its Recognition in Convolutional Gated Recurrent Unit Network. Front. Phys. 2021, 8, 9620. [Google Scholar] [CrossRef]
- Jiao, Z.; Gao, X.; Wang, Y.; Li, J.; Xu, H. Deep Convolutional Neural Networks for mental load classification based on EEG data. Pattern Recognit. 2018, 76, 582–595. [Google Scholar] [CrossRef]
- Tabar, Y.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2017, 14, 016003. [Google Scholar] [CrossRef] [PubMed]
- Jacobsen, S.; Meiron, O.; Salomon, D.Y.; Kraizler, N.; Factor, H.; Jaul, E.; Tsur, E.E. Integrated Development Environment for EEG-Driven Cognitive-Neuropsychological Research. IEEE J. Transl. Eng. Health Med. 2020, 8, 2200208. [Google Scholar] [CrossRef]
- Jasper, H.H. The ten-twenty electrode system of the international federation. Electroencephalogr. Clin. Neurophysiol. 1958, 10, 371–375. [Google Scholar]
- Klem, G.H.; Lüders, H.O.; Jasper, H.H.; Elger, C. The ten-twenty electrode system of the International Federation of Clinical Neurophysiology. Electroencephalogr. Clin. Neurophysiol. Suppl. 1999, 52, 3–6. [Google Scholar]
- Butterworth, S. On the theory of filter amplifiers. Wirel. Eng. 1930, 7, 536–541. [Google Scholar]
- Zhao, Y.; Wang, G.; Tang, C.; Luo, C.; Zeng, W.; Zha, Z.-J. A battle of network structures: An empirical study of CNN, Transformer, and MLP. arXiv 2021, arXiv:2108.13002. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnetv2: Smaller models and faster training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP architecture for vision. Adv. Neural Inf. Proc. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Int. Joint Conf. Artific. Intell. 1995, 14, 1137–1145. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierar-Chical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.; Tan, M. Coatnet: Marrying Convolution and Attention for All Data Sizes. Adv. Neural Inf. Proc. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Vapnik, V.; Chervonenkis, A. A note on class of perceptron. Autom. Remote Control 1964, 25, 103–109. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Özmen, N.G. EEG analysis of real and imaginary arm movements by spectral coherence. Uludağ Üniv. Mühendis. Fakültesi Derg. 2021, 26, 109–126. [Google Scholar]
- Honkanen, R.; Rouhinen, S.; Wang, S.H.; Palva, S.; Palva, S. Gamma Oscillations Underlie the Maintenance of Feature-Specific Information and the Contents of Visual Working Memory. Cereb. Cortex 2014, 25, 3788–3801. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Tong, L.; Shu, J.; Zhuang, N.; Yan, B.; Zeng, Y. High Gamma Band EEG Closely Related to Emotion: Evidence From Functional Network. Front. Hum. Neurosci. 2020, 14, 89. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Blocks |
|---|---|
| CNet | MBConv |
| TNet | Transformer |
| MNet | Mixer |
| CTNet | MBConv, Transformer |
| CMNet | MBConv, Mixer |
| TMNet | Transformer, Mixer |
| CTMNet | MBConv, Transformer, Mixer |
| Model | Accuracy | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|
| CNet | 0.9530 | 0.9041 | 0.9962 | 0.9423 | 0.9137 |
| TNet | 0.8799 | 0.7973 | 0.9470 | 0.8553 | 0.7750 |
| MNet | 0.8364 | 0.8062 | 0.8689 | 0.7911 | 0.7027 |
| CTNet | 0.9466 | 0.9067 | 0.9789 | 0.9380 | 0.8982 |
| CMNet | 0.9670 | 0.9443 | 0.9844 | 0.9638 | 0.9343 |
| TMNet | 0.9473 | 0.9155 | 0.9711 | 0.9419 | 0.8960 |
| Hyperparameter Name | Value |
|---|---|
| Output Layer Activation Function | Softmax |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Exponential decay rate β1 | 0.9 |
| Exponential decay rate β2 | 0.999 |
| Loss function | Cross Entropy |
| Epochs | 50 |
| Steps per epoch | 30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, Y.-H.; Wu, S.-K.; Yu, S.-S.; Tsai, M.-H. A Novel Hybrid Deep Neural Network for Predicting Athlete Performance Using Dynamic Brain Waves. Mathematics 2023, 11, 903. https://doi.org/10.3390/math11040903
Tsai Y-H, Wu S-K, Yu S-S, Tsai M-H. A Novel Hybrid Deep Neural Network for Predicting Athlete Performance Using Dynamic Brain Waves. Mathematics. 2023; 11(4):903. https://doi.org/10.3390/math11040903
Chicago/Turabian StyleTsai, Yu-Hung, Sheng-Kuang Wu, Shyr-Shen Yu, and Meng-Hsiun Tsai. 2023. "A Novel Hybrid Deep Neural Network for Predicting Athlete Performance Using Dynamic Brain Waves" Mathematics 11, no. 4: 903. https://doi.org/10.3390/math11040903