1. Introduction
Query optimization is the overall process of generating the most-efficient query plan given a SQL statement. The query optimizer, responsible for this process, applies equivalence rules to reorganize and merge the operations in the query to find the fastest execution plan and feeds it to the executor. It examines multiple access methods, such as sequential table scans or index scans, different join methods, such as nested loops and hash joins, different join orders, sub-query normalization, materialized views, and other possible transformations. Almost all existing systems adopt a cost-based optimization approach, with roots back to the architecture of System R [
1] and Volcano/Cascades [
2,
3].
In cost-based query optimization, the optimizer estimates the cost of the alternative query plans and chooses the plan with the minimum cost. The cost is estimated in terms of the CPU and I/O resources that the query plan will use. A central component in cost estimation is the Selectivity Estimation (SE). SE collects statistics for all attributes in a relation, such as data distribution histograms, the most-common values, the null percentage, etc. These statistics are then used during planning time to estimate the number of tuples generated by a predicate in the query. A smaller selectivity value means a smaller size for intermediate results, which is favorable for a more efficient execution. The cost-based optimizer, thus, reorders the selection and join predicates to quickly reduce the sizes of intermediate results.
Since, in general, the cost of each operator depends on the size of its input relations, it is important to provide good estimations of their selectivity, that is of their result size, to the query optimizer [
4,
5]. Inaccurate selectivity estimations can lead to inefficient query plans being chosen, sometimes leading to orders of magnitude longer execution times [
6].
There is a trade-off between the size of the stored statistics and the complexity of the estimation algorithm, on the one hand, and the estimation accuracy, on the other. Recent research thus focuses on using machine learning methods to capture the data distribution into compact models. While there are good results in this research direction [
7], common relational database systems continue to use traditional statistics structures, mostly based on histograms. A histogram can be used as a discrete approximation of the probability density function of an attribute.
Despite the popularity of histograms, there is a lack of a theory of how to use them in estimating inequality join selectivity. In addition, we found that common database systems lack accurate implementations for such an estimator. This paper thus aimed to fill this gap and makes the following main contributions:
A formal model for describing a selectivity estimation problem using probability theory;
A novel algorithm for join selectivity estimation of inequality operators using histogram statistics;
An extension of the algorithm that also takes advantage of additional statistics (e.g., MCV), when available.
Section 2 starts by describing the research problem, together with a running example, which will be used throughout the paper. In the same section, we also introduce some definitions, notations, and terminology.
Section 3 then reviews the existing related work in selectivity estimation. The algorithm presented in this paper consists of mapping the problem of selectivity estimation to a probability theory problem, as described in
Section 4. The algorithm of join selectivity estimation is developed in
Section 5. This section also develops a way to incorporate the null values and Most-Common Values (MCVs) statistics in the estimation model. A mapping of this model for several range operators is also presented. Finally, an implementation in PostgreSQL and the experimental evaluation are provided in
Section 6.
2. Preliminaries
This paper presents a formal model to compute two different selectivity estimation types:
Restriction selectivity estimation: when one of the sides of the operator is an attribute of a relation and the other is a constant value:
- –
Example: SELECT * FROM R1 WHERE R1.X < 100.
Join selectivity estimation: when both sides of the operator are attributes of different relations:
- –
Example: SELECT * FROM R1, R2 WHERE R1.X < R2.Y.
The selectivity estimation of operations where both sides of the operator are attributes of the same relation, with no join or Cartesian product involved (example: SELECT * FROM R1 WHERE R1.x < R1.y), is not addressed by this paper.
The selectivity of an operator is the fraction of values kept in the result after selection. In the case of restriction selectivity, the denominator is the input relation’s size. In the case of join selectivity, the denominator is the input relations’ Cartesian product size (their sizes multiplied). This fraction can be interpreted as the probability that a given randomly selected tuple from the input relation, or from the Cartesian product of input relations in the case of joins, is selected by the operator being considered.
2.1. Problem Definition
In this paper, we developed an algorithm to perform the join selectivity estimation of inequality joins described above. The restriction selectivity estimation is already implemented by all common database systems, thus not a novel contribution of this work. We, however, formulated it as a probability problem and developed the join selectivity estimation on top of it, to maximize the code reuse in these systems.
The focus of the next sections will be on the restriction selectivity estimation of the less than (<) operator. The restriction selectivity estimation of all scalar inequality operators was derived from this initial estimation. We also built/generalized it to develop the join selectivity estimation.
The attributes being restricted or joined were treated as random variables that follow a distribution modeled by a Probability Density Function (PDF) and/or a Cumulative Distribution Function (CDF).
2.2. Running Example
For demonstration purposes, relations R1 and R2 are used throughout this paper. For each relation, 12 integers were manually selected to cover as many corner cases as possible when using equi-depth histograms (introduced in
Section 2.3), such as skew and common bin boundaries.
2.3. Histogram Statistics
Histograms are commonly used to approximate the PDF of an attribute by grouping the values in uniform bins. Each bin is an interval of the form: , where are values from the domain of the attribute. It is important to note that the side on which the interval is open or closed has nothing to do with the purposes of this paper, as all estimations correspond to integration over a continuous domain, where singular points do not affect the final result. By defining a bin this way (using intervals), this paper restricted itself to domains where total order exists. This excludes categorical data, for which the idea of an equi-depth histogram does not apply.
Let be the fraction of values of the attribute X that is represented by the histogram bin , i.e., the height/depth of the histogram bin:
Singleton histograms are such that each bin refers to the frequency of a single element, typically used to collect most-common values statistics (introduced in
Section 5.3).
Equi-width histograms are such that each bin has the same width. That is, is constant.
Equi-depth histograms are such that each bin has the same depth (height), but a varying width. That is, , where n is the total number of bins.
For selectivity estimation, equi-depth histograms are favored because the resolution of the histogram adapts to skewed value distributions. Typically, the histogram is smaller than the original data. Thus, it cannot represent the true distribution entirely, and some assumptions are induced, e.g., uniformity on a single attribute, with the independence assumption among different attributes. The use of equi-depth histograms is also motivated by their prevalence in current RDBMS. These are usually constructed through the use of random sampling of the original relations.
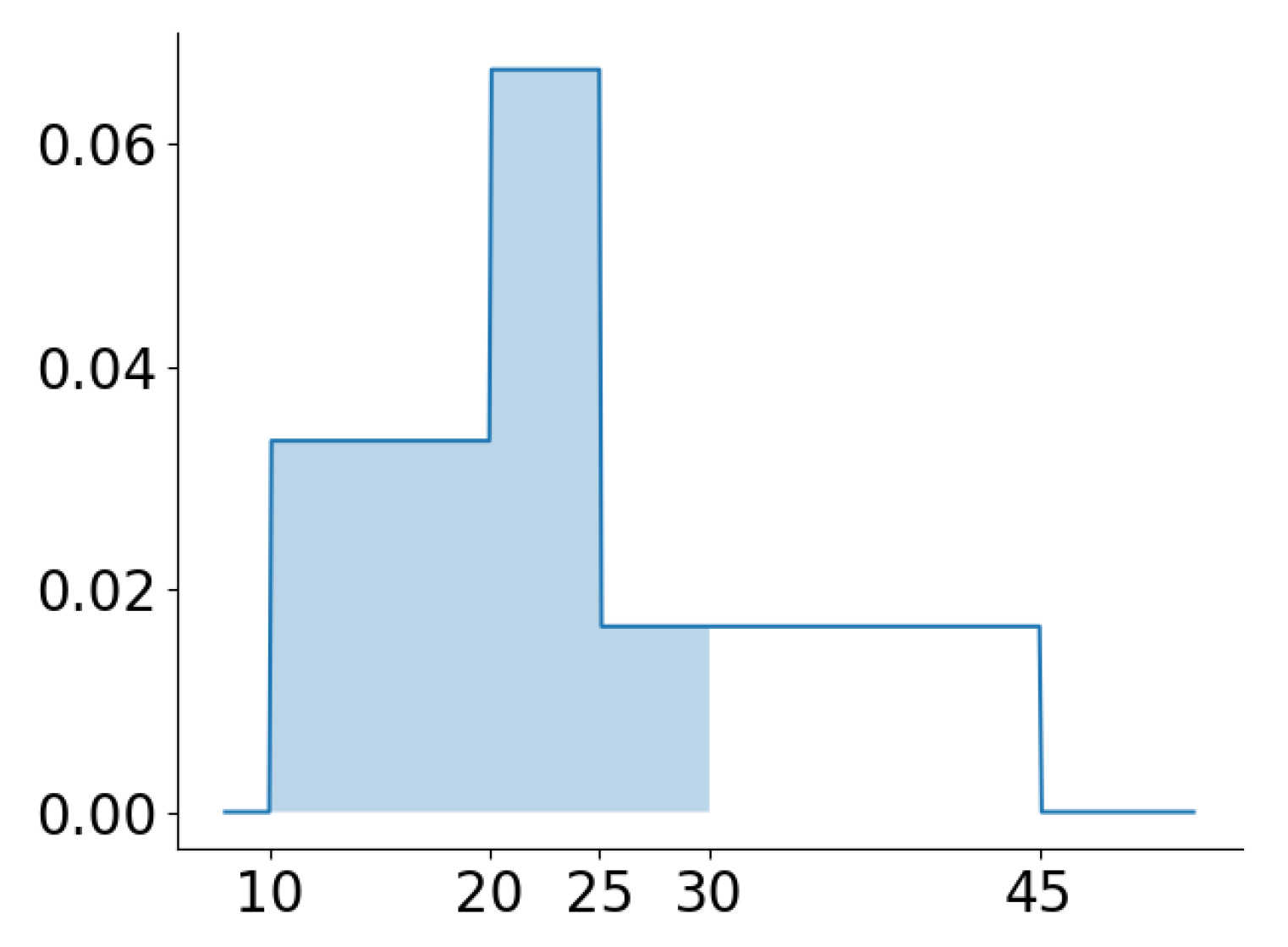
For demonstration purposes,
Figure 1 shows a graphical representation of equi-depth histograms for the attributes
and
of the running example. For both histograms, there are three bins, meaning that the fraction accounted for by each bin is
. For attribute
,
, which means that
,
, and
. For attribute y,
, which means that
,
, and
.
Using histograms as a statistical representation of attributes involves the following implicit assumptions:
The data are distributed uniformly inside each bin;
The histograms are complete (they account for all the data points), that is:
- –
;
- –
.
In practice, these two assumptions do not strictly hold. The data are usually not uniformly distributed inside each bin. The more bins used in the histograms, the smaller the error introduced by this assumption is. Database systems, e.g., PostgreSQL, typically create the histogram using a random sample of the attribute values, especially when the number of tuples is too large. The assumption of the completeness of the histogram might be broken in the presence of sampling. When the sample is representative of the underlying data, the estimation is still fairly accurate.
Given the equi-depth histogram of an attribute
X, with
n bins, one can derive its approximate PDF and CDF as shown next. Let
and
denote the PDF and the CDF of
X, respectively, at a given value
c, then
When
, Formula (
1) is derived from the definition of the equi-depth histogram, where each bin represents
of the data, spread over a width of
.
Formula (
2) is derived from the following:
where
This last formula performs linear interpolation within the bin where
c is contained, thus assuming a uniform distribution of values within the bin. The assumption that the histogram is complete is reflected in substituting the infinite bounds by
. In the running example, the PDF and CDF of
can be derived from the formulas presented in this section as follows:
3. Review of Related Work
A survey on DBMS query optimizer was proposed in 2021 [
6], which categorizes cardinality estimation methods into synopsis-based methods, sampling-based methods, and learning-based methods. Many learning-based methods [
8,
9,
10,
11,
12] have been proposed in recent years and show better accuracy than traditional methods. However, there are still many missing parts to be solved to put them into real systems, such as the cost of model training and updating and the black-box property of learning algorithms [
7]. Sampling-based methods estimate selectivity by executing a (sub)query on samples collected from tables, whose accuracy depends on the degree to which the samples fit the original data distribution [
6]. These methods, however, suffer from a high cost of storage and retrieval time, especially when the tables are very large. Another limitation of sampling-based methods is that they currently only support equality join selectivity estimation [
6].
A third class of methods collects data summaries in the form statistics, to then estimate the size of the query results [
13]. Histograms, as a form of synopsis-based methods, have been extensively studied [
6,
8] and are widely adopted in common database systems [
14] for the purpose of selectivity estimation, including MySQL, PostgreSQL, Oracle, and SQL-Server [
15,
16,
17,
18]. Histograms are commonly used in databases for other tasks, including, for instance, data security and watermarking [
19,
20].
MySQL uses two histogram types for selectivity estimation [
15]. One is the singleton histogram, which stores the distinct values and their cumulative frequency. Another is the equi-depth histogram, called equi-height in the MySQL documentation. This histogram stores the lower and upper bounds, the cumulative frequency, and the number of distinct values for each bucket. However, the usage of histograms is limited to restriction selectivity estimation [
15], i.e., the selection operator. For join selectivity estimation, MySQL naively returns a constant: 0.1 for equality joins and 0.3333 for inequality joins [
21]. Listing 1 displays an excerpt of the MySQL source code in which these constants are defined [
22]:
Listing 1. MySQL Defaul Selectivity Values.
/// Filtering effect for equalities: col1 = col2
#define COND_FILTER_EQUALITY 0.1f
/// Filtering effect for inequalities: col1 > col2
#define COND_FILTER_INEQUALITY 0.3333f
PostgreSQL also uses the histogram as the optimizer statistics [
16]. By analyzing its manual [
23], as well as its source code, it uses equi-depth histograms. In contrast to MySQL, the number of distinct values in each bucket is not stored. For this reason, PostgreSQL does not use these histogram statistics in estimating equi-join selectivity. It rather uses a singleton histogram of the Most-Common Values (MCVs) [
23]. As for inequality join selectivity estimation (<, ≤, >, ≥), a default constant value of
is returned [
24].
Listing 2 displays an excerpt of the PostgreSQL source code in which these constants are defined [
25]:
Listing 2. PostgreSQL Defaul Selectivity Values.
/∗ default selectivity estimate for equalities such as "A = b"∗/
#define DEFAULT_EQ_SEL 0.005
/∗ default selectivity estimate for inequalities such as "A < b"∗/
#define DEFAULT_INEQ_SEL 0.3333333333333333
Oracle Database uses three types of histograms to capture the data distribution of a relation’s attribute [
17]: singleton histograms (referred to as frequency histograms and top frequency histograms in the official documentation), equi-depth histograms (referred to as height-balanced in the official documentation), and hybrid histograms (a combination of equi-depth and frequency histograms). The type of histogram is determined based on specific criteria to fit different situations. The official documentation [
17] also states some factors behind their selectivity estimation algorithms, such as endpoint numbers (the unique identifier of a bucket, e.g., the cumulative frequency of buckets in frequency and hybrid histograms) and values (the highest value in a bucket), and whether column values are popular (an endpoint value that appears multiple times in a histogram) or non-popular (every column value that is not popular). However, the details of these estimation algorithms are not published. Few online articles, in the form of hacker blogs, made experimental analyses to guess how selectivity estimation works in Oracle Database, but did not yield a clear algorithm [
26,
27].
SQL-Server is another popular closed-source DBMS. Due to its proprietary nature, the implementation details are scarce. According to the official documentation [
18], a proprietary kind of histogram with a density vector associated is built in three steps for each attribute. The official documentation [
28,
29] describes four core assumptions for the selectivity estimation: independence when no correlation information is available, uniformity in histogram bins, inclusion when filtering a column with a constant, and containment when joining distinct values from two histograms [
30]. Although the white paper [
29] is a publication from SQL-Server that deals with the problem of selectivity estimation, it does not explain the algorithm used for join selectivity. Similar to Oracle, the implemented algorithm is a secret.
To identify if any informed selectivity estimation is taking place when performing inequality joins in SQL-Server and Oracle, we performed the following experiment. Two different attributes, T1 and T2, with 1000 and 200 rows, respectively, were randomly generated by sampling the range [0, 100] uniformly. They were then joined using the < (less than) operator. Both databases made a quite accurate selectivity estimation of this inequality join. Oracle Database had an estimation error of 3%, and SQL-Server had a smaller error of just 0.29%. As such, we know that both systems implement good estimation algorithms.
In conclusion, although learning-based methods have become a popular research direction for selectivity estimation in recent years, histograms are still the most-commonly used statistics in existing DBMS for this purpose. The recurring types of used histogram statistics are equi-depth histograms approximating the distribution of values and singleton histograms of most-common values. As our investigation indicates, MySQL and PostgreSQL do not have algorithms implemented for join selectivity estimation, and they use predefined constants. On the other hand, popular commercial DBMS (SQL-Server and Oracle) have implemented some algorithms based on the histograms, but we could not find any source describing them. This paper addresses this gap by proposing such an algorithm.
4. A Formal Model for Selectivity Estimation
We first start by formalizing the problem of restriction selectivity estimation for the less than (<) operator. Suppose that the goal is to estimate the selectivity of the following operation (expressed in SQL):
SELECT ∗
FROM R1
WHERE R1.X < c
where c is a constant. Treating the attribute
as a random variable
X, estimating the selectivity of the above operation is equivalent to finding
. Given the PDF or the CDF of
X,
, or
, respectively, the selectivity of the operation above can be formalized as
Suppose now that the goal is to estimate the join selectivity for the less than (<) operator. That is, we want to estimate the selectivity of the following operation (expressed in SQL):
SELECT ∗
FROM R1, R2
WHERE R1.X < R2.Y
Treating the attributes and as random variables X and Y, respectively, estimating the selectivity of the above operation can be formulated as finding .
Consider the joint distribution of
X and
Y,
. The probability that a sample (
a,
b) taken at random from the Cartesian product of the values in
and
can be defined as follows:
or, equivalently,
which is the definition of independent random variables. Note that, when a Cartesian product is involved, either explicitly as in the SQL statement above or implicitly through a join clause, the two variables are independent.
Given a joint PDF of
X and
Y,
. With
X and
Y being independent, it is known that
, with
and
the PDFs of
X and
Y, respectively. Considering
to be the CDF of
X, the selectivity of the less than (<) operator can be formalized as follows:
This formula, thus, presents a solution for estimating the join selectivity estimation. Next, we discuss how to translate it into an algorithm.
5. Implementation in a Database System
In RDBMS implementations, histograms are used as a discrete approximation of the PDF and CDF of attributes. This section maps the theory above into an implementable solution in databases using equi-depth histograms.
5.1. Selectivity Estimation
5.1.1. Restriction Selectivity Estimation
Recall that restriction selectivity estimation is about estimating the selectivity of a predicate in the following form:
SELECT ∗
FROM R1
WHERE R1.X < c
As described in
Section 4, restriction selectivity estimation can be calculated using the CDF of
X (Equation (
3)). Deriving the CDF from an equi-depth histograms is presented in Equation (
2). To find the bin,
, where
c is contained, one can perform a binary search over the histogram boundaries.
Algorithm 1 illustrates the estimation of restriction selectivity. The
array represents the equi-depth histogram, stored as an ordered array of bin boundaries. The function binary_search returns the greatest index in this array that is less than or equal to a given constant, effectively finding the bin where such a constant falls. The rest of the algorithm computes the CDF at c using Equation (
2).
| Algorithm 1: Restriction selectivity estimation for the expression R1.X < c. |
![Mathematics 11 01383 i001]() |
Using the running example and the following query:
SELECT ∗
FROM R1
WHERE R1.X < 30
This query yields eight rows, which corresponds to a selectivity of . Using Algorithm 1 with the histograms presented in the running example, the number 30 will be found in , meaning that the estimated selectivity will be . After multiplying by the attribute’s cardinality (12), we obtain the estimated row count of nine, which is a close estimate to the actual result size.
Figure 2 shows a graphical depiction of the PDF of the
, which is directly obtainable from its equi-depth histogram. The integral in Equation (
2), as well as the estimation calculated above using Algorithm 1 correspond to the highlighted area in the figure.
5.1.2. Join Selectivity Estimation
Join selectivity estimation is mapped into a double integral involving the two PDFs. Equation (
4) illustrates that join selectivity can be estimated by using the CDF of
X and the PDF of
Y. These can be calculated using Equations (
1) and (
2).
The CDF of
X is linear piecewise, each piece being defined in a bin of
X’s histogram. The PDF of
Y is a step function, i.e., constant piecewise, where each piece is defined in a bin of
Y’s histogram. This leads to the conclusion that their product, which is needed in Equation (
4), is a linear piecewise function, with every piece being defined in an intersection of
X and
Y’s bins (see
Figure 3 for a graphical depiction of this using the running example introduced in
Section 2.2). By merging the bounds of the two histograms of
X and
Y in a single sorted array,
, the intersections of
X and
Y’s bins will be of the form
.
From Equation (
1), we know that
is 0 for all values until the first value of
, and it is 0 after the last value of
. From Equation (
2), we know that
is 0 for all values until the first value of
, and it is 1 after the last value of
.
Analyzing the product
piecewise:
Since the product of
and
is linear in each interval of the form
, Equation (
4) can be discretized as follows:
To maximize code re-use, it is possible to reorganize this equation into a sum of the CDFs of both
X and
Y, i.e., so that we can reuse Algorithm 1. The following is derived directly from Equation (
3):
and the first two steps rely on the fact that
is constant in the interval
.
Equation (
6) can now be re-written using only CDFs of
X and
Y as follows:
Algorithm 2 illustrates the estimation of the join selectivity of the less than (<) operator using this equation. It, thus, has the advantage of re-using Algorithm 1 to compute
and
. The creation of the
array in Algorithm 2 comes at the expense of the time and space of O(
), for duplicating and merging the two sorted histograms. To optimize this, the two histograms can be scanned in parallel, without the need to materialize the sync array. This also allows for further optimization. The algorithm only needs to iterate over the overlapping region of both histograms. All the partial sums before that will be zero, as can be verified in
Figure 4. After the overlapping region, the remaining partial sums are equal to what is left of the histogram of
Y,
, because all remaining values of Y will be greater than the maximum value in
X. We adopted these optimizations in our implementation, yet we omitted them here for the clarity of presentation.
| Algorithm 2: Join selectivity estimation algorithm for the less than (<) operator re-using Algorithm 1 as and . |
![Mathematics 11 01383 i002]() |
The goal of Algorithm 2 is to calculate the area under the curve of the product
, represented in
Figure 4. Taking the three-bin histograms calculated in
Section 2.3 from the running example attributes
and
, a materialized
array would have the values [10, 15, 20, 25, 39, 45, 50] after merging, sorting, and removing duplicates. These correspond to the boundaries of the pieces in which the product
is linear. Stepping through Algorithm 2 with k from 1 to 5, corresponding to the six pieces represented by the sync array, we arrive at the following sum:
The correct result will have 95 rows, which corresponds to a selectivity of . After multiplying by the cardinality of the Cartesian product of both attributes (144) and rounding the result to the nearest integer, we obtain the estimated row count of , which is close to the correct result size.
Figure 4 shows a graphical depiction of the product of the CDF of
and the PDF of
, which is directly obtainable from their equi-depth histograms. The integral in Equation (
6), as well as the estimation calculated above using Algorithm 2 correspond to the area under the curve in the figure.
Figure 4 illustrates the multiplication of the CDF(
) and the PDF(
). The integral in Equation (
4), as well as its estimation in Algorithm 4 correspond to calculating the area under the curve in the figure.
Note that the code re-use in Algorithm 2 has a small performance impact. This algorithm has a time complexity of O(), since it performs a binary search (twice) for each element of each histogram. This binary search is not necessary since the two histograms are being scanned sequentially and the current indices are known at each iteration. One way to avoid this overhead would be to optionally specify j as an input parameter of Algorithm 1, thus reducing the time complexity to O().
5.2. Extending to All Scalar Inequality Operators
Given the restriction and join selectivity estimators for the less than inequality, all scalar inequality operators can be implemented by noting the following equivalences:
Restriction selectivity:
Join selectivity:
Estimators for equality selections and joins are already implemented by almost all common systems. In case they are missing, one could assume P(X = c) and P(X = Y) to be zero, thus leading to under-/over-estimation of the selectivity.
5.3. Making Use of Other Statistics
Typically, RDBMS will collect statistics about nulls, in the form of a fraction of null values, and Most-Common Values (MCVs), in the form of a singleton histogram. Histograms will, thus, be constructed for the remaining part of the data. When the histogram statistics only refer to a fraction of the data, the methods described up to this point only provide an estimation for this fraction. The final estimation must, thus, take nulls and MCV into account.
As a general way to integrate such other statistics in the estimation besides the histograms, we note the following: given a non-overlapping partitioning of the data, if each partition j corresponds to a fraction of the original data and selectivity within that partition is , the final selectivity can be calculated by the inner product .
Since a value is either null, a most-common value, or accounted for by the histogram, the overall restriction selectivity can be calculated by the following formula:
5.3.1. Null Values
All inequality operators are strict; this means that the selectivity of null values is 0. For this reason, the first term in Equation (
9) is also 0.
5.3.2. Most-Common Values
MCV statistics maintain pairs of values and their frequencies in the table. They are maintained for the top k frequent values, where k is a statistics collection parameter. Since MCVs represent the data in their original form, it is possible to accurately compute the selectivity for these values.
To estimate the restriction selectivity of an operator using the most-common values, Algorithm 3 can be used. This algorithm computes the selectivity of a Boolean operator on a list of most-common values by adding the frequencies of the most-common values satisfying this Boolean condition.
| Algorithm 3: mcv_selectivity(values, fractions, n, op), estimates the restriction selectivity, using only the MCV statistics, for a given Boolean operator op. |
![Mathematics 11 01383 i003]() |
For join selectivity estimation, since there is the need to combine statistics from null values, MCVs, and equi-depth histograms for both X and Y, there are nine cases that need consideration, depending on the combination of the values of X and Y, as shown in
Figure 5.
For strict operators, such as inequalities, only Cases 5, 6, 8, and 9 need to be calculated. This is because nulls result in empty joins. Case 9 was already handled in Algorithm 2. For Case 5, we iterate over the values in the MCV of Y. For each value, we multiply the fraction represented by that value in Y times the MCV restriction selectivity of the operator in question with the current value of the MCV of Y as the constant. This process is described in Algorithm 4.
| Algorithm 4: Join selectivity estimation algorithm for any binary Boolean operator re-using Algorithm 3 as mcv_selectivity(values, fractions, n, op). |
![Mathematics 11 01383 i004]() |
For Cases 6 and 8, Algorithm 5 is used, by swapping the arguments. For each common value in the statistics of X, multiply its fraction by the histogram restriction selectivity of Y using the current value of X as the constant.
| Algorithm 5: Join selectivity estimation algorithm for the less than (<) operator re-using Algorithm 1 as . |
![Mathematics 11 01383 i005]() |
In terms of Algorithms 4 and 5, the selectivity of the less than (<) operator involving histograms and most-common values can be estimated by the following formula:
The final selectivity taking null values into account can be estimated as follows:
5.4. Implementation for Ranges and Multiple Ranges
The algorithms described above are for scalar types. An advanced type, which is implemented by many database systems, is the range type. A range type is a tuple (left, right, lc, rc), where left <= right are two values of a domain with a total order. lc and rc specify whether, respectively, the left and right bounds are included in the range. The range type can be parameterized by the type of its bounds, e.g., range (float), range (timestamp), etc. In this section, we describe how the selectivity estimation in previous sections can be applied to the range type and the respective operators.
PostgreSQL, as an example of a DBMS that has range types, collects the statistics for range attributes in the form of two equi-depth histograms: one for the lower bounds of the ranges and one for the upper bounds. In the following, let be attributes of the same range type. Furthermore, let be the variable that represents all the lower bounds of X, be the variable that represents all the upper bounds of X, and similarly for Y. Then, it is possible to estimate the selectivity of the different range operators as follows:
, where , reads strictly left of, yields true when X ends before Y starts;
, where , reads strictly right of, yields true when X starts after Y ends;
&, where &<, reads X does not extend to the right of Y, yields true when X ends before the end of Y;
&, where &>, reads X does not extend to the left of Y, yields true when X starts before Y starts;
, where indicates the overlapping between X and Y;
And so on.
It is, however, not possible to accurately estimate the join selectivity of the operators that express total or partial containment. This is mainly because the lower and upper histograms assume independence between the range bounds. For containment operators, we need to relate the two bounds, which explicitly breaks this assumption.
Another consideration in estimating the selectivity of range operators is the fraction of empty ranges since these are not accounted for by the histograms. Depending on the operator, empty ranges are either always included or always excluded when compared to non-empty ranges and, similarly, when compared to other empty ranges.
6. Experiments
This section evaluates the proposed algorithm in two ways. Firstly, we evaluated the join selectivity estimation accuracy of the algorithm and its relation to the size of the histogram statistics, i.e., the number of bins. In a second step, the accuracy of the proposed solution was compared to the existing solutions in Oracle, SQL-Server, MySQL, and PostgreSQL. The algorithm was implemented in PostgreSQL 15, including support for range operators as described in
Section 5.4. The code has been submitted as a patch, and it is currently under review for inclusion in the next release of PostgreSQL. The patch is also included as an artifact with this paper.
The experiments described in this section were run using our implementation in PostgreSQL 15-develop on a Debian virtual machine with 32 GB of disk and 8 GB of RAM. For the first set of experiments, we created two relations, R1 and R2, with range attributes R1.X and R2.Y and cardinalities of 20,390 and 20,060 rows, respectively. Note that, for range types, we used the same algorithm as for scalar types, so the results of this experiment hold for both.
The range values in the two relations were generated to cover a mixture of short, medium, and long ranges. We also included corner cases such as ranges with infinite bounds, empty ranges, and null values in the two relations. The following query was executed varying the number of histogram bins:
SELECT ∗
FROM R1, R2
WHERE x << y
Note that << denotes the “strictly left of” operator, which returns true if and only if the upper bound of x is less than the lower bound of y. PostgreSQL collects bounds’ histogram statistics for range attributes. To estimate the selectivity of the query above, the histograms of the upper bound of X and lower bound of Y were used as the input for Algorithm 2.
The optimizer statistics collector of PostgreSQL has a parameter called statistics target, which controls the number of bins in the equi-depth histograms. The default value is 100, and it can be increased up to 10,000. The experiments described in this section were run by incrementing the statistics target by steps of 100 starting with the default value till the maximum value.
In the experiment, we observed two quantities: (1) the planning time, which is the time taken by the query optimizer to enumerate the alternative query plans and estimate their costs, and (2) the cost estimation error defined as the absolute difference between the estimated and the actual number of rows returned by the query, divided by the cardinality of the Cartesian product of the two relations, which is 409,013,259.
Figure 6 shows the change in planning time (in milliseconds) as the statistics target increases. Apart from two outliers, the planning time showed approximately linear behavior, indicating that the binary search does not have a significant impact on it in the allowed range of statistics targets. Recall that the analytical complexity is O(
).
Figure 7 shows the estimation error (in a logarithmic scale) against the number of histogram bins, i.e., by varying the statistics target. As expected, using more bins lead to a lower estimation error. Even with a small histogram of 100 histogram bins, the estimation error was insignificant, amounting to about 1.112%. This error dropped rapidly to less than 0.002% at 900 bins, which corresponds to less than 5% of each relation size. The error stayed consistently around this value for the histograms bigger than 900 bins.
Figure 8 plots the selectivity estimation error against the planning time in milliseconds. The significance of this figure is to illustrate the relation of the expenditure in terms of planning time versus the gain in terms of reduced error. This figure shows that, for the relations used, the planning time did not need to exceed 2 milliseconds to obtain extremely accurate estimations.
Next, we compared our algorithm with the existing solutions used in Oracle, SQL-Server, MySQL, and PostgreSQL. For this experiment, we generated three relations, U, N, and Z, with 1000 rows each. Relation U contains 10 columns (U.A to U.J) with uniformly sampled data from a range starting at , respectively, with each range being 1000 units wide. Relations N and Z each contain 10 column (N.A to N.J, and Z.A to Z.J) with data sampled from a normal distribution with a mean of 1000 and a standard deviation of 300 and a Zipfian distribution with coefficient , respectively. The following three queries were then run for each pair of columns:
Q1: SELECT ∗ FROM U AS U1, U AS U2 WHERE U1.A < U2.column
Q2: SELECT ∗ FROM U, N WHERE U.column < N.column
Q3: SELECT ∗ FROM U, Z WHERE U.column < Z.column
Figure 9 shows the average estimation error for each query, as returned by the tested DBMS. Our solution is denoted as PostgreSQL Patched. Note that we used a logarithmic scale for the y-axis; otherwise, our solution would not be visible on the graph. As we can see, the results for MySQL and the existing PostgreSQL solution were equally bad. This was expected, as both system returned a constant selectivity of
for all queries. Oracle and SQL-Server returned better estimates for Query 1 (below 0.5% error), but struggled with the normal and Zipfian distribution. Our estimator consistently computed fairly accurate estimates for all data distributions, with average estimation errors of 0.02%, 0.05%, and 0.04% for Q1, Q2, and Q3 respectively.
As explained in the Introduction, providing accurate selectivity estimations is crucial for the database optimizer to choose the best execution plan for a specific query. To illustrate the impact of choosing a good or a bad plan, the following simple query will be used:
Since this query combines two inequality joins, it is beneficial to first compute the join with the lowest selectivity. In this case, this corresponds to the join between U and Z. However, the execution plan returned by the current PostgreSQL optimizer computes the join between U and N first. This is because the returned selectivity estimates are not accurate enough for the optimizer to apply the reordering. In our current implementation, however, the optimizer receives accurate selectivity estimates and is able to reorder the joins. This reordering decreases the query duration from 89 s to 48 s, which is a 1.8× increase in speed. This shows how important accurate selectivity estimations can be when combining multiple joins in the same query.
7. Conclusions and Possible Future Work
This paper proposed an algorithm for estimating the selectivity of inequality join predicates. It is a fundamental problem in databases that has not been solved before to our knowledge. This work covered this theoretical gap and further implemented the solution in the open-source database PostgreSQL.
We estimated the inequality join selectivity of two relations using the joint probability density function of the common join attribute. In database systems, the integral is discretized using equi-depth histogram synopses for the join attributes. We further structured the join selectivity calculations to reuse the selectivity estimation when one of the arguments is a constant. Since the latter is already implemented in common database systems, the estimator of join selectivity builds on existing implementations in a modular fashion. The experimental results validated the high accuracy of estimation, while the query planning time remained in the acceptable range of a few milliseconds.
This paper generalized the selectivity estimation algorithm to support scalar and 1D range types. As an extension, it would be interesting to support multi-dimensional ranges. This is of particular interest to spatial (2D, 3D) and spatiotemporal (3D, 4D) databases.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













