
Effort and Cost Estimation Using Decision Tree Techniques and Story Points in Agile Software Development

Abstract

1. Introduction
1.1. Related Work
1.2. Background
1.2.1. Decision Tree
1.2.2. Ensemble Learning
1.2.3. Random Forest
1.2.4. AdaBoost
1.2.5. Discretization of Continuous Features
- Uniform: the uniform strategy uses intervals of constant width;
- Quantiles: the quantile strategy uses the quantile values to have equally populated intervals in each feature;
- K-means: The k-means strategy defines intervals based on a clustering procedure (k-means) performed on each function independently. The values in each interval have the same nearest center of a set of k-means.
1.2.6. Cross-Validation
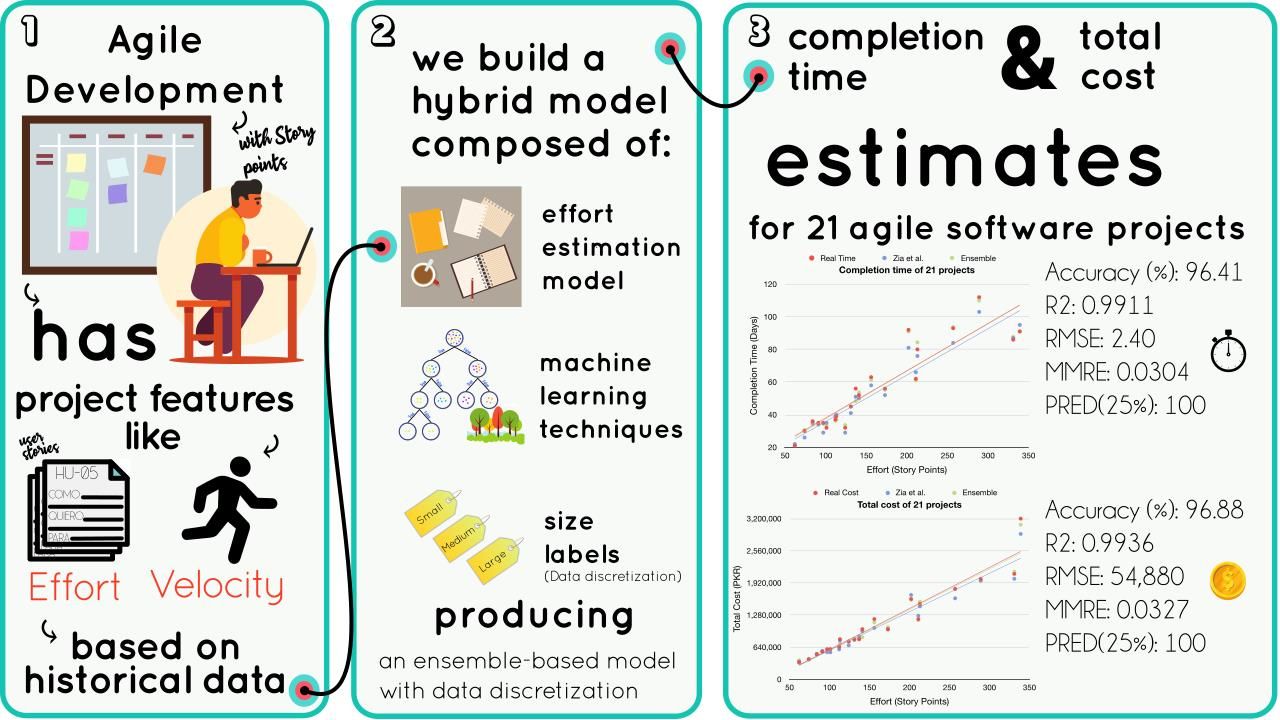
2. Materials and Methods
2.1. Proposed Approach
2.1.1. Data Augmentation
2.1.2. Evaluation Criteria
2.2. Dataset Discretization
2.3. Coding Algorithms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| regrDT = DecisionTreeRegressor(max_depth = 5, min_samples_split = 2, random_state = 0) |
| regrRF = RandomForestRegressor(n_estimators = 10, max_depth = 6, random_state = 0) |
| regrAda = AdaBoostRegressor(regrDT,random_state = 0, n_estimators = 10) |
| n_splits = 10 |
| n_repeats = 2 |
| rkf = RepeatedKFold(n_splits = n_splits,n_repeats = n_repeats,random_state = 30) |
| cv_results = cross_validate(reg, x_train_scaled, y_train_scaled, cv = rkf, return_estimator = |
| True, return_train_score = True, scoring = (‘r2’, ‘neg_mean_squared_error’, |
| ‘explained_variance’, ‘neg_root_mean_squared_error’) ) |
| est = KBinsDiscretizer(n_bins = 3, encode = ‘ordinal’, strategy = ‘uniform’) |
| est.fit(effort) |
| est2 = KBinsDiscretizer(n_bins = 3, encode = ‘ordinal’, strategy = ‘uniform’) |
| est2.fit(time) |
| est3 = KBinsDiscretizer(n_bins = 3, encode = ‘ordinal’, strategy = ‘uniform’) |
| est3.fit(cost) |
| DiscEff = est.transform(effort) |
| DiscTime = est2.transform(time) |
| DiscCost = est3.transform(cost) |
3. Results
3.1. Single-Model Experiments
3.2. Multi-Model Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABC | Artificial Bee Colony |
| ABC-PSO | Artificial Bee Colony with Particle Swarm Optimization |
| AI | Artificial Intelligence |
| ALO | Antlion Optimization Algorithm |
| ANFIS | Adaptive Neuro-Fuzzy Interface System |
| Bagging | Bootstrap aggregation |
| CCNN | Cascade-Correlation Neural Network |
| CNN | Convolutional Neural Network |
| COCOMO | Constructive Cost Model |
| CONACYT | Consejo Nacional de Ciencia y Tecnología |
| CPU | Central Processing Unit |
| DBN | Deep Belief Network |
| Deep-SE | Deep learning model for Story point Estimation |
| DL | Deep learning |
| DT | Decision Tree |
| EEBAT | Energy-Efficient BAT |
| FFNN | Feed-Forward Neural Network |
| FPA | Function Point Analysis |
| FWA | Fireworks Algorithm |
| GA | Genetic Algorithm |
| GB | Gigabyte |
| GMDH-PNN | Group Method of Data Handling Polynomial Neural Network |
| GPU | Graphics Processing Units |
| GRNN | General Regression Neural Network |
| GRU | Gated Recurrent Unit |
| GS | Grid Search |
| HGNN | Heterogeneous Graph Neural Network |
| IT | Information Technology |
| KNN | K-Nearest Neighbors |
| LM | Levenberq–Marquardt |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MAR | Mean Absolute Residual |
| MHz | Megahertz |
| MLP | Multilayer Perceptron |
| MdMRE | Median or Mean Relative Error |
| MLP | Multilayer Perceptron |
| MMER | Mean of Magnitude of Error Relative |
| MMRE | Mean Magnitude of Relative Error |
| MRE | Mean Relative Error |
| MSE | Mean Squared Error |
| newGRNN | Generalized Regression Neural Networks |
| OLS | Ordinary Least Squares |
| PCA | Principal Component Analysis |
| PKR | Pakistani Rupees |
| PNN | Probabilistic Neural Network |
| PRED | Prediction Accuracy |
| PSO | Particle Swarm Optimization |
| RAM | Random Access Memory |
| RBFN | Radial Basis Function Networks |
| RF | Random Forest |
| RHN | Recurrent Highway Network |
| RMSE | Root Mean Squared Error |
| RNN | Recurrent Neural Network |
| SA | Standard Accuracy (SA) |
| SGB | Stochastic Gradient Boosting |
| SLIM | Software Lifecycle Management |
| SPEE | Software Project Effort Estimation |
| SPEM | Story Points Estimation Model |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| Text GNN | Text Graph Neural Network |
| UCP | Use Case Point |
| WBS | Work Breakdown Structure |
| XP | eXtreme Programming |
| TDD | Test-Driven Development |
References
- Wysocki, R.K. Effective Project Management: Traditional, Agile, Hybrid, Extreme; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Hohl, P.; Klünder, J.; van Bennekum, A.; Lockard, R.; Gifford, J.; Münch, J.; Stupperich, M.; Schneider, K. Back to the future: Origins and directions of the ‘Agile Manifesto’—Views of the originators. J. Softw. Eng. Res. Dev. 2018, 6, 1–27. [Google Scholar] [CrossRef]
- Sommerville, I. Software Engineering, 10th ed.; Pearson Education: London, UK, 2019. [Google Scholar]
- Vyas, M.; Bohra, A.; Lamba, D.C.S.; Vyas, A. A Review on Software Cost and Effort Estimation Techniques for Agile Development Process. Int. J. Recent Res. Asp. 2018, 5, 1–5. [Google Scholar]
- Mahnič, V.; Hovelja, T. On using planning poker for estimating user stories. J. Syst. Softw. 2012, 85, 2086–2095. [Google Scholar] [CrossRef]
- Rashid, J.; Nisar, M.W.; Mahmood, T.; Rehman, A.; Syed, Y.A. A study of software development cost estimation techniques and models. Mehran Univ. Res. J. Eng. Technol. 2020, 39, 413–431. [Google Scholar] [CrossRef]
- Fedotova, O.; Teixeira, L.; Alvelos, A.H. Software effort estimation with multiple linear regression: Review and practical application. J. Inf. Sci. Eng. 2013, 29, 925–945. [Google Scholar]
- Sharma, B.; Purohit, R. Review of current software estimation techniques. In Data Science and Analytics: 4th International Conference on Recent Developments in Science, Engineering and Technology; Springer: Singapore, 2018. [Google Scholar]
- Hoc, H.T.; Hai, V.V.; Nhung, H.L.T.K. A Review of the Regression Models Applicable to Software Project Effort Estimation. Comput. Stat. Math. Model. Methods Intell. Syst. Adv. Intell. Syst. Comput. 2019, 2, 399–407. [Google Scholar]
- Barenkamp, M.; Rebstadt, J.; Thomas, O. Applications of AI in Classical Software Engineering. AI Perspect. 2020, 2, 1. [Google Scholar] [CrossRef]
- Hidmi, O.; Sakar, B.E. Software Development Effort Estimation Using Ensemble Machine Learning. Int. J. Comput. Commun. Instrum. Eng. 2017, 4, 143–147. [Google Scholar]
- Ziauddin, K.Z.K.; Tipu, S.K.; Zia, S. An Intelligent Software Effort Estimation System. J. Expert Syst. (JES) 2012, 1, 4. [Google Scholar]
- Khan, M.W.; Qureshi, I. Neural Network based Software Effort Estimation: A Survey. Int. J. Adv. Netw. Appl. 2014, 5, 1990–1995. [Google Scholar]
- Abnane, I.; Hosni, M.; Idri, A.; Abran, A. Analogy Software Effort Estimation Using Ensemble KNN Imputation. In Proceedings of the 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Kallithea-Chalkidiki, Greece, 28–30 August 2019. [Google Scholar]
- Kumar, P.S.; Behera, H.S.; Nayak, J.; Naik, B. A pragmatic ensemble learning approach for effective software effort estimation. Innov. Syst. Softw. Eng. 2021, 18, 283–299. [Google Scholar] [CrossRef]
- Kumar, P.S.; Behera, H.; Nayak, A.K.K.J.; Naik, B. Advancement from neural networks to deep learning in software effort estimation: Perspective of two decades. Comput. Sci. Rev. 2020, 38, 100288. [Google Scholar] [CrossRef]
- Hussein, L.A.; Nassar, K.A.; Naser, M.A.U. Recurrent Neural Network based Prediction of Software Effort. Int. J. Comput. Appl. 2017, 177, 8887. [Google Scholar] [CrossRef]
- Mittal, K.; Khanduja, D.; Tewari, P.C. An insight into decision tree analysis. World Wide J. Multidiscip. Res. Dev. 2017, 3, 111–115. [Google Scholar]
- Loh, W.-Y. Fifty years of classification and regression trees. Int. Stat. Rev. 2014, 82, 329–348. [Google Scholar] [CrossRef]
- Anitha, K.K.; Varadarajan, V. Estimating Software Development Efforts Using a Random Forest-Based Stacked Ensemble Approach. Electronics 2021, 10, 1195. [Google Scholar] [CrossRef]
- Nassif, A.B.; Azzeh, M.; Capretz, L.F.; Ho, D. A comparison between decision trees and decision tree forest models for software development effort estimation. In Proceedings of the 2013 Third International Conference on Communications and Information Technology (ICCIT), Beirut, Lebanon, 19–21 June 2013. [Google Scholar]
- Srinivasan, K.; Fisher, D. Machine learning approaches to estimating software development effort. IEEE Trans. Softw. Eng. 1995, 21, 126–137. [Google Scholar] [CrossRef]
- Najm, A.; Zakrani, A.; Marzak, A. Decision trees based software development effort estimation: A systematic mapping study. In Proceedings of the 2019 International Conference of Computer Science and Renewable Energies (ICCSRE), Agadir, Morocco, 22–24 July 2019. [Google Scholar]
- Coelho, E.; Basu, A. Effort Estimation in Agile Software Development using Story Points. Int. J. Appl. Inf. Syst. 2012, 3, 7–10. [Google Scholar] [CrossRef]
- Fernandez-Diego, M.; Mendez, E.R.; Gonzalez-Ladron-De-Guevara, F.; Abrahao, S.; Insfran, E. An Update on Effort Estimation in Agile Software Development: A Systematic Literature Review. IEEE Access 2020, 8, 166768–166800. [Google Scholar] [CrossRef]
- Dave, C.V. Estimation approaches of machine learning in scrum projects: A Review. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 1110–1118. [Google Scholar] [CrossRef]
- Sudarmaningtyas, P.; Mohamed, R. A review article on software effort estimation in agile methodology. Pertanika J. Sci. Technol. 2021, 29. [Google Scholar] [CrossRef]
- Mahmood, Y.; Kama, N.; Azmi, A. A systematic review of studies on use case points and expert-based estimation of software development effort. J. Softw. Evol. Process. 2020, 32, 7. [Google Scholar] [CrossRef]
- Horgan, G.; Khaddaj, S.; Forte, P. Construction of an FPA-type metric for early lifecycle estimation. Inf. Softw. Technol. 1998, 40, 409–415. [Google Scholar] [CrossRef]
- Giray, G. A software engineering perspective on Engineering Machine Learning Systems: State of the art and Challenges. J. Syst. Softw. 2021, 180, 111031. [Google Scholar] [CrossRef]
- Ziauddin, S.K.T.; Zia, S. An Effort Estimation Model for Agile Software Development. Adv. Comput. Sci. Its Appl. 2012, 2, 314–324. [Google Scholar]
- Popli, R.; Chauhan, N. Cost and effort estimation in agile software development. In Proceedings of the 2014 International Conference on Reliability Optimization and Information Technology (ICROIT), Faridabad, India, 6–8 February 2014; pp. 57–61. [Google Scholar] [CrossRef]
- Raslan, A.T.; Darwish, N.R. Effort Estimation in Agile Software Projects using Fuzzy Logic and Story Points. In Proceedings of the 50th Annual Conference on Statistics, Computer Sciences, and Operation Research, Cairo, Egypt, 27–30 December 2015; pp. 27–30. [Google Scholar]
- Choudhari, J.; Suman, U. Story Points Based Effort Estimation Model for Software Maintenance. Procedia Technol. 2012, 4, 761–765. [Google Scholar] [CrossRef]
- Scott, E.; Pfahl, D. Using developers features to estimate story points. In Proceedings of the 2018 International Conference on Software and System Process, Gothenburg, Sweden, 26–27 May 2018. [Google Scholar]
- Malgonde, O.; Chari, K. An ensemble-based model for predicting agile software development effort. Empir. Softw. Eng. 2018, 24, 1017–1055. [Google Scholar] [CrossRef]
- Garg, S.; Gupta, D. PCA based cost estimation model for agile software development projects. In Proceedings of the 2015 International Conference on Industrial Engineering and Operations Management (IEOM), Dubai, United Arab Emirates, 3–5 March 2015. [Google Scholar]
- Durán, M.; Juárez-Ramírez, R.; Jiménez, S.; Tona, C. User Story Estimation Based on the Complexity Decomposition Using Bayesian Networks. Program. Comput. Softw. 2020, 46, 569–583. [Google Scholar] [CrossRef]
- Gultekin, M.; Kalipsiz, O. Story Point-Based Effort Estimation Model with Machine Learning Techniques. Int. J. Softw. Eng. Knowl. Eng. 2020, 30, 43–66. [Google Scholar] [CrossRef]
- Adnan, M.; Afzal, M. Ontology Based Multiagent Effort Estimation System for Scrum Agile Method. IEEE Access 2017, 5, 25993–26005. [Google Scholar] [CrossRef]
- Sembhoo, A.; Gobin-Rahimbux, B. A SLR on Deep Learning Models Based on Textual Information for Effort Estimation in Scrum. 2023. Available online: https://www.researchsquare.com/article/rs-2461583/latest.pdf (accessed on 30 January 2023).
- Choetkiertikul, M.; Dam, H.K.; Tran, T.; Pham, T.; Ghose, A.; Menzies, T. A Deep Learning Model for Estimating Story Points. IEEE Trans. Softw. Eng. 2019, 45, 637–656. [Google Scholar] [CrossRef]
- Panda, A.; Satapathy, S.M.; Rath, S. Empirical validation of neural network models for agile software effort estimation based on story points. Procedia Comput. Sci. 2015, 57, 772–781. [Google Scholar] [CrossRef]
- Satapathy, S.M.; Rath, S.K. Empirical assessment of machine learning models for agile software development effort estimation using story points. Innov. Syst. Softw. Eng. 2017, 13, 191–200. [Google Scholar] [CrossRef]
- Rao, C.P.; Kumar, P.S.; Sree, S.R.; Devi, J. An Agile Effort Estimation Based on Story Points Using Machine Learning Techniques. In Proceedings of the Second International Conference on Computational Intelligence and Informatics Advances in Intelligent Systems and Computing; Springer: Singapore, 2018; pp. 209–219. [Google Scholar]
- Sharma, A.; Chaudhary, N. Linear regression model for agile software development effort estimation. In Proceedings of the 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Online, 1–3 December 2020. [Google Scholar]
- Zakrani, A.; Najm, A.; Marzak, A. Support vector regression based on grid-search method for agile software effort prediction. In Proceedings of the 2018 IEEE 5th International Congress on Information Science and Technology (CiSt), Marrakech, Morocco, 21–27 October 2018. [Google Scholar]
- Sharma, A.; Chaudhary, N. Analysis of software effort estimation based on Story Point and lines of code using machine learning. Int. J. Comput. Digit. Syst. 2022, 12, 131–140. [Google Scholar] [CrossRef]
- Arora, M.; Verma, S.; Kavita; Wozniak, M.; Shafi, J.; Ijaz, M.F. An efficient ANFIS-EEBAT approach to estimate effort of Scrum projects. Sci. Rep. 2022, 12, 7974. [Google Scholar] [CrossRef] [PubMed]
- Kaushik, A.; Tayal, D.K.; Yadav, K. A comparative analysis on effort estimation for agile and Non-agile Software Projects using DBN-ALO. Arab. J. Sci. Eng. 2019, 45, 2605–2618. [Google Scholar] [CrossRef]
- Khuat, T.T.; Le, M.H. A novel hybrid ABC-PSO algorithm for effort estimation of Software Projects Using Agile Methodologies. J. Intell. Syst. 2018, 27, 489–506. [Google Scholar] [CrossRef]
- Khuat, T.T.; Le, M.H. An effort estimation approach for agile software development using fireworks algorithm optimized neural network. Int. J. Comput. Sci. Inf. Secur. (IJCSIS) 2016, 14, 122–130. [Google Scholar]
- Sanchez, E.R.; Maceda, H.C.; Santacruz, E.V. Software effort estimation for Agile Software Development using a strategy based on K-nearest neighbors algorithm. In Proceedings of the 2022 IEEE Mexican International Conference on Computer Science (ENC), Xalapa, Veracruz, Mexico, 24–26 August 2022. [Google Scholar]
- Rodríguez, E.; Vazquez, E.; Cervantes, H. Estimación de esfuerzo en desarrollo de software ágil utilizando redes neuronales artificiales. In Proceedings of the Presented at XIV Congreso Mexicano de Inteligencia Artificial, Oaxaca, México, 3–7 April 2022. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Faul, A. A Concise Introduction to Machine Learning; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Kubat, M. An Introduction to Machine Learning; Springer International Publishing: Cham, Switzerland, 2017; Volume 2. [Google Scholar]
- Matloff, N. Statistical Regression and Classification From Linear Models to Machine Learning; Chapman & Hall CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- Hastie, T.; Friedman, J.; Tisbshirani, R. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2017. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. WIREs Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- de Ville, B. Decision trees. Wiley Interdiscip. Rev. Comput. Stat. 2013, 5, 448–455. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Harlow, UK, 2021. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. WIRES Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, Y. Ensemble Machine Learning; Springer: New York, NY, USA, 2012. [Google Scholar]
- Kumar, A.; Jain, M. Ensemble Learning for AI Developers: Learn Bagging, Stacking, and Boosting Methods with Use Cases; Apress: Berkeley, CA, USA, 2020. [Google Scholar]
- Maslove, D.M.; Podchiyska, T.; Lowe, H.J. Discretization of continuous features in clinical datasets. J. Am. Med Inform. Assoc. 2013, 20, 544–553. [Google Scholar] [CrossRef] [PubMed]
- Albon, C. Machine Learning with Python Cookbook: Practical Solutions from Preprocessing to Deep Learning; OReilly: Sebastopol, Ukraine, 2018. [Google Scholar]
- Munakata, T. Fundamentals of the New Artificial Intelligence Neural, Evolutionary, Fuzzy and More; Springer: London, UK, 2007. [Google Scholar]
- Claeskens, G.; Hjort, N.L. Model Selection and Model Averaging; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of prediction error by using k-fold cross-validation. Stat. Comput. 2009, 21, 137–146. [Google Scholar] [CrossRef]
- A Guide to the Project Management Body of Knowledge: (PMBOK Guide); Project Management Institute: Newtown Square, PA, USA, 2017.
- Sehra, S.K.; Kaur, J.; Sehra, S.S. Effect of data preprocessing on software effort estimation. Int. J. Comput. Appl. 2013, 69, 29–32. [Google Scholar]
- Agile Practice Guide; Project Management Institute: Newton Square, PA, USA, 2017.
- Cohn, M. Agile Estimating and Planning, 1st ed.; Prentice Hall: Hoboken, NJ, USA, 2005. [Google Scholar]
- Labedzki, M.; Promiński, P.; Rybicki, A.; Wolski, M. Agile effort estimation in software development projects-case study. Cent. Eur. Rev. Econ. Manag. 2017, 1, 135–152. [Google Scholar]
- Picard, R.R.; Cook, R.D. Cross-validation of Regression Models. J. Am. Stat. Assoc. 1984, 79, 575–583. [Google Scholar] [CrossRef]
- Shao, J. Linear model selection by cross-validation. J. Am. Stat. Assoc. 1993, 88, 486–494. [Google Scholar] [CrossRef]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation: Rejoinder. J. Am. Stat. Assoc. 1987, 82, 548. [Google Scholar] [CrossRef]
- Song, L. Learning to Cope with Small Noisy Data in Software Effort Estimation. Ph.D. Dissertation, School of Computer Science, The University of Birmingham, Birmingham, UK, 2019. [Google Scholar]
- Moocarme, M.; Abdolahnejad, M.; Bhagwat, R. The Deep Learning with Keras Workshop; PACKT Publishing: Birmingham, UK, 2020. [Google Scholar]
- Tawosi, V.; Moussa, R.; Sarro, F. Deep Learning for Agile Effort Estimation Have We Solved the Problem Yet? arXiv 2022, arXiv:2201.05401. [Google Scholar]
- Song, L.; Minku, L.L.; Yao, X. A novel automated approach for software effort estimation based on data augmentation. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018. [Google Scholar]
- Brown, W.M.; Gedeon, T.D.; Groves, D.I. Use of Noise to Augment Training Data: A Neural Network Method of Mineral–Potential Mapping in Regions of Limited Known Deposit Examples. Nat. Resour. Res. 2003, 12, 141–152. [Google Scholar] [CrossRef]
- Figura, C.; Khoshgoftaar, T.M. A survey on image data augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar]
- Rashid, K.M.; Louis, J. Times-series data augmentation and deep learning for construction equipment activity recognition. Adv. Eng. Inform. 2019, 42, 100944. [Google Scholar] [CrossRef]
- Rao, C.R.; Toutenburg, H. Linear Models Least Squares and Alternatives; Springer: New York, NY, USA, 1999. [Google Scholar]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]











| No | Title | Input | Output | Technique | Pred(%) | Evaluation Criteria | MSE/RMSE | MMRE/MMER | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | An Effort Estimation Model for Agile Software Development [31] | No of User Stories, Team Velocity, Sprint Size, No of Working days per Month, Team Salary, Confidence Level in Estimation | Effort, Init Velocity, Friction Factors, Dynamic Forces, Deceleration, Velocity, Time and Cost | Linear-based regression model | Time: 57.14 | Mean Magnitude of Relative Error (MMRE), PRED(7.19) | NA | NA | 7.19 |
| Cost: 61.90 | MMRE PRED(5.76) | NA | NA | 5.76 | |||||
| 2 | Empirical Validation of Neural Network Models for Agile Software Effort Estimation based on Story Points [43] | Effort, Velocity | Completion Time | General Regression Neural Network (GRNN) | 85.9182 | Mean Square Error (MSE), Squared correlation coefficient , MMRE, Prediction Accuracy (PRED) | 0.0244 | 0.7125 | 0.3581 |
| Probabilistic Neural Network (PNN) | 87.6561 | 0.0276 | 0.6614 | 1.5776 | |||||
| Group Method of Data Handling Polynomial Neural Network (GMDH-PNN) | 89.6689 | 0.0317 | 0.6259 | 0.1563 | |||||
| Cascade-Correlation Neural Network (CCNN) | 94.7649 | 0.0059 | 0.9303 | 0.1486 | |||||
| 3 | An Agile Effort Estimation Based on Story Points Using Machine Learning Techniques [45] | Effort, Velocity | Completion Time, Total Cost | Adaptive Neuro-Fuzzy Interface System (ANFIS) | Time: 76.19 Cost: 57.14 | MMRE, Mean of Magnitude of Error Relative (MMER), PRED(x) | NA | NA | Time: 8.4277 Cost: 3.9079 |
| Generalized Regression Neural Networks (newGRNN) | 76.1905 | NA | NA | Time: 2.7864 Cost: 4.8335 | |||||
| Radial Basis Function Networks (RBFN) | 76.1905 | NA | NA | Time: 8.0909 Cost: 9.9604 | |||||
| 4 | Empirical assessment of machine learning models for agile software development effort estimation using story points [44] | Effort, Velocity | Completion Time | Decision Tree (DT) | 38.0952 | Mean Absolute Error (MAE), MMER, PRED (0.25) | NA | NA | 0.3820 |
| Stochastic Gradient Boosting (SGB) | 85.7143 | NA | NA | 0.1632 | |||||
| Random Forest (RF) | 66.6667 | NA | NA | 0.2516 | |||||
| 5 | Linear Regression Model for Agile Software Development Effort Estimation [46] | Effort, Velocity, product of friction and dynamic factors, initial velocity and workdays | Completion Time | 2 linear models and 1 polynomial model, Model1 Time | NA | , MSE, MMRE | 718.1487 | 0.9476 | 0.099 |
| 6 | Support Vector Regression Based on Grid-Search Method for Agile Software Effort Prediction [47] | Effort, Velocity | Completion Time | Support Vector Regression (SVR) optimized by grid search method (GS) | 80.952 | Pred(0.25), MMRE and MdMRE | NA | NA | 0.1640 |
| 7 | Analysis of Software Effort Estimation Based on Story Point and Lines of Code using Machine Learning [48] | Effort, Velocity | Completion Time | Feed-forward Neural Network (FFNN) | NA | , MMRE, MSE | 17.0356 | 0.9739 | 6.2207 |
| Genetic Algorithm (GA) | 21.46326 | 0.9671 | 6.742859 | ||||||
| 8 | An efficient ANFIS-EEBAT approach to estimate effort of Scrum projects [49] | Effort, Velocity | Completion Time | Adaptive neuro-fuzzy inference system (ANFIS) along with the novel Energy-Efficient BAT (EEBAT) | 100 | , RMSE, MAE, MAPE, MMRE, PRED(0.25) | 0.74579 | 0.9993 | 1.518311 |
| 9 | A Comparative Analysis on Effort Estimation for Agile and Non-agile Software Projects Using DBN-ALO [50] | Effort, Velocity | Completion Time | Deep Belief Network (DBN) - Antlion Optimization Algorithm (ALO) | 98.4321 | MMRE, MdMRE, Standard Accuracy (SA), mean absolute residual (MAR), Pred(0.25) | NA | NA | 0.0225 |
| 10 | A Novel Hybrid ABC-PSO Algorithm for Effort Estimation of Software Projects Using Agile Methodologies [51] | Effort, Velocity | Completion Time | Particle Swarm Optimization (PSO) | 61.9 | , MMRE, PRED(8), MdMRE, MAR | NA | 0.9626 | 6.69 |
| Artificial Bee Colony (ABC) | 61.9 | NA | 0.9732 | 5.84 | |||||
| ABC-PSO | 66.67 | NA | 0.9734 | 5.69 | |||||
| 11 | An Effort Estimation Approach for Agile Software Development using Fireworks Algorithm Optimized Neural Network [52] | Effort, Velocity | Completion Time | FFNN with Fireworks Algorithm (FWA) and Levenberq- Marquardt (LM) | 100 | , MMRE, PRED(7.19) | 3.7983 | 0.9946 | 2.9339 |
| 12 | Software Effort Estimation for Agile Software Development Using a Strategy Based on k-Nearest Neighbors Algorithm [53] | Effort, Velocity, Effort Size, Time Size, Cost Size | Completion Time, Total Cost | K-Nearest Neighbors (KNN) | Time: 94.70 | , MMRE, RMSE | 3.23 | 0.984 | 0.053 |
| Cost: 94.54 | 81,388 | 0.986 | 0.0546 |
| Parameter | Decision Tree Model | ||||
|---|---|---|---|---|---|
| Setup | Max depth | 5 | |||
| min_samples_split | 2 | ||||
| k-Fold Cross Validation | RepeatedKFold with 10-Fold and n_repeats = 2 | ||||
| Standardization | MinMaxScaler with values between (0,1) | ||||
| Input | Effort, Vi | Effort, Vi + Size Labels | Effort, Vi | Effort, Vi + Size Labels | |
| Output | Time | Cost | |||
| Parameter | Random Forest Model | ||||
|---|---|---|---|---|---|
| Setup | Num estimator | 10 | |||
| Max depth | 6 | ||||
| min_samples_split | 2 | ||||
| k-Fold Cross Validation | RepeatedKFold with 10-Fold and n_repeats = 2 | ||||
| Standardization | MinMaxScaler with values between (0,1) | ||||
| Input | Effort, Vi | Effort, Vi + Size Labels | Effort, Vi | Effort, Vi + Size Labels | |
| Output | Time | Cost | |||
| Parameter | Adaboost Model | ||||
|---|---|---|---|---|---|
| Setup | Num estimator | 10 | |||
| Max depth | 6 | ||||
| min_samples_split | 2 | ||||
| k-Fold Cross Validation | RepeatedKFold with 10-Fold and n_repeats = 2 | ||||
| Standardization | MinMaxScaler with values between (0,1) | ||||
| Input | Effort, Vi | Effort, Vi + Size Labels | Effort, Vi | Effort, Vi + Size Labels | |
| Output | Time | Cost | |||
| Algorithm | Main Features | Advantages |
|---|---|---|
| Decision Tree | Builds a tree-like model that partitions the feature space into disjoint regions | Simple to interpret, computationally efficient, handles nonlinear relationships, can handle missing data and can handle a mix of continuous and categorical variables |
| Random Forest | Ensemble of decision trees, where each tree is built on a bootstrap sample of the data and a random subset of features | Reduces overfitting and variance by averaging multiple trees, handles high-dimensional data, can handle noisy data and can estimate feature importance |
| AdaBoost | Iteratively fits weak learners to the residuals of the previous learner, and combines them into a strong predictor | Boosts accuracy by focusing on misclassified data, handles high-dimensional data, can handle noisy data, can estimate feature importance and less prone to overfitting than decision tree or random forest |
| Ensemble Learning | Ensemble learning combines the predictions of different types of models to create a single, more accurate prediction | Reduces overfitting and increases generalization by combining the strengths of multiple diverse models, and can be used in context with little data. It is a divide and conquer strategy |
| No | Effort | Vi | ActualTime | ActualCost | SizeEffort | SizeTime | SizeCosto |
|---|---|---|---|---|---|---|---|
| 1 | 156 | 4.2 | 63 | 1,200,000 | M | L | M |
| 2 | 202 | 3.7 | 92 | 1,600,000 | L | L | L |
| 3 | 173 | 4 | 56 | 1,000,000 | M | M | M |
| 4 | 331 | 4.5 | 86 | 2,100,000 | L | L | L |
| 5 | 124 | 4.9 | 32 | 750,000 | M | S | M |
| 6 | 339 | 4.1 | 91 | 3,200,000 | L | L | L |
| 7 | 97 | 4.2 | 35 | 600,000 | S | S | S |
| 8 | 257 | 3.8 | 93 | 1,800,000 | L | L | L |
| 9 | 84 | 3.9 | 36 | 500,000 | S | S | S |
| 10 | 211 | 4.6 | 62 | 1,200,000 | L | M | M |
| 11 | 131 | 4.6 | 45 | 800,000 | M | M | M |
| 12 | 112 | 3.9 | 37 | 650,000 | S | M | S |
| 13 | 101 | 3.9 | 32 | 600,000 | S | S | S |
| 14 | 74 | 3.9 | 30 | 400,000 | S | S | S |
| 15 | 62 | 3.9 | 21 | 350,000 | S | S | S |
| 16 | 289 | 4 | 112 | 2,000,000 | L | L | L |
| 17 | 113 | 4 | 39 | 800,000 | M | M | M |
| 18 | 141 | 4 | 52 | 1,000,000 | M | M | M |
| 19 | 213 | 4 | 80 | 1,500,000 | L | L | L |
| 20 | 137 | 3.7 | 56 | 800,000 | M | M | M |
| 21 | 91 | 3.7 | 35 | 550,000 | S | S | S |
| Completion Time, l = 0.0719 | Total Cost, l = 0.0576 | |||
|---|---|---|---|---|
| Criteria | Unlabeled Data | Labeled Data | Unlabeled Data | Labeled Data |
| MMRE | 0.0234 | 0.0322 | 0.0352 | 0.0266 |
| MdMRE | 0.0179 | 0.0286 | 0.0165 | 0.0127 |
| Pred(MMRE) | 61.90 | 57.14 | 80.95 | 85.71 |
| Pred(l) | 90.48 | 95.24 | 85.71 | 90.48 |
| Pred(0.25) | 100 | 100 | 100 | 100 |
| Parameter | Decision Tree Model | ||||
|---|---|---|---|---|---|
| Setup | Max depth | 5 | |||
| min_samples_split | 2 | ||||
| k-Fold Cross Validation | RepeatedKFold with 10-Fold and n_repeats = 2 | ||||
| Standardization | MinMaxScaler with values between (0,1) | ||||
| Input | Effort, Vi | Effort, Vi + Size Labels | Effort, Vi | Effort, Vi + Size Labels | |
| Output | Time | Cost | |||
| Training | Mean Squared Error (MSE) | 0.0002 | 0.0002 | 2.9304 | 2.0226 |
| Root of MSE (RMSE) | 0.0136 | 0.0122 | 0.0049 | 0.0039 | |
| Coefficient of determination | 0.9971 | 0.9980 | 0.9995 | 0.9997 | |
| Explained Variance | 0.9971 | 0.9980 | 0.9995 | 0.9997 | |
| Validation | MSE | 0.0027 | 0.0064 | 0.0057 | 0.0048 |
| RMSE | 0.0417 | 0.0531 | 0.0392 | 0.0383 | |
| 0.9472 | 0.8599 | 0.9314 | 0.9156 | ||
| Explained Variance | 0.9596 | 0.9038 | 0.9581 | 0.9441 | |
| Test | Accuracy (%) | 97.45 | 96.57 | 96.49 | 97.33 |
| 0.9963 | 0.9910 | 0.9924 | 0.9944 | ||
| Mean Relative Error (MRE) | 0.0255 | 0.0343 | 0.0351 | 0.0267 | |
| MSE | 2.43 | 5.86 | 3,612,415,756 | 2,637,510,055 | |
| RMSE | 1.56 | 2.42 | 60,103 | 51,357 | |
| Explained Variance | 0.9964 | 0.9914 | 0.9934 | 0.9953 | |
| Completion Time, l = 0.0719 | Total Cost, l = 0.0576 | |||
|---|---|---|---|---|
| Criteria | Unlabeled Data | Labeled Data | Unlabeled Data | Labeled Data |
| MMRE | 0.0478 | 0.0331 | 0.0406 | 0.0311 |
| MdMRE | 0.0435 | 0.0313 | 0.0232 | 0.0190 |
| Pred(MMRE) | 57.14 | 61.90 | 61.90 | 61.90 |
| Pred(l) | 80.95 | 90.48 | 76.19 | 80.95 |
| Pred(0.25) | 100 | 100 | 100 | 100 |
| Parameter | Random Forest Model | ||||
|---|---|---|---|---|---|
| Setup | Num estimators | 10 | |||
| Max depth | 6 | ||||
| min_samples_split | 2 | ||||
| k-Fold Cross Validation | RepeatedKFold with 10-Fold and n_repeats = 2 | ||||
| Standardization | MinMaxScaler with values between (0,1) | ||||
| Input | Effort, Vi | Effort, Vi + Size Labels | Effort, Vi | Effort, Vi + Size Labels | |
| Output | Time | Cost | |||
| Training | Mean Squared Error (MSE) | 0.0011 | 0.0008 | 0.0007 | 0.0006 |
| Root of MSE (RMSE) | 0.0330 | 0.0274 | 0.0252 | 0.0236 | |
| Coefficient of determination | 0.9854 | 0.9900 | 0.9880 | 0.9896 | |
| Explained Variance | 0.9859 | 0.9908 | 0.9882 | 0.9898 | |
| Validation | MSE | 0.0046 | 0.0035 | 0.0066 | 0.0061 |
| RMSE | 0.0603 | 0.0504 | 0.0519 | 0.0486 | |
| 0.8980 | 0.9223 | 0.9211 | 0.9298 | ||
| Explained Variance | 0.9262 | 0.9499 | 0.9444 | 0.9534 | |
| Test | Accuracy (%) | 95.44 | 96.92 | 96.08 | 97.03 |
| 0.9794 | 0.9869 | 0.9858 | 0.9885 | ||
| Mean Relative Error (MRE) | 0.0456 | 0.0308 | 0.0392 | 0.0297 | |
| MSE | 13.38 | 8.52 | 6,723,275,745 | 5,443,614,797 | |
| RMSE | 3.66 | 2.92 | 81,996 | 73,781 | |
| Explained Variance | 0.9795 | 0.9869 | 0.9870 | 0.9890 | |
| Completion Time, l = 0.0719 | Total Cost, l = 0.0576 | |||
|---|---|---|---|---|
| Criteria | Unlabeled Data | Labeled Data | Unlabeled Data | Labeled Data |
| MMRE | 0.0429 | 0.0378 | 0.0542 | 0.0497 |
| MdMRE | 0.0357 | 0.0317 | 0.0297 | 0.0295 |
| Pred(MMRE) | 52.38 | 57.14 | 71.43 | 66.67 |
| Pred(l) | 76.19 | 90.48 | 71.43 | 71.43 |
| Pred(0.25) | 100 | 100 | 100 | 100 |
| Parameter | Adaboost Model | ||||
|---|---|---|---|---|---|
| Setup | Num estimators | 10 | |||
| Max depth | 6 | ||||
| min_samples_split | 2 | ||||
| k-Fold Cross Validation | RepeatedKFold with 10-Fold and n_repeats = 2 | ||||
| Standardization | MinMaxScaler with values between (0,1) | ||||
| Input | Effort, Vi | Effort, Vi + Size Labels | Effort, Vi | Eff, Vi + Size Labels | |
| Output | Time | Cost | |||
| Training | Mean Squared Error (MSE) | 0.0007 | 0.0005 | 0.0004 | 0.0003 |
| Root of MSE (RMSE) | 0.0261 | 0.0220 | 0.0209 | 0.0180 | |
| Coefficient of determination | 0.9910 | 0.9935 | 0.9922 | 0.9943 | |
| Explained Variance | 0.9910 | 0.9936 | 0.9924 | 0.9944 | |
| Validation | MSE | 0.0027 | 0.0022 | 0.0061 | 0.0055 |
| RMSE | 0.0471 | 0.0399 | 0.0492 | 0.0398 | |
| 0.9357 | 0.9408 | 0.8813 | 0.9246 | ||
| Explained Variance | 0.9507 | 0.9584 | 0.9143 | 0.9516 | |
| Test | Accuracy (%) | 95.49 | 96.44 | 94.74 | 95.19 |
| 0.9883 | 0.9926 | 0.9903 | 0.9923 | ||
| Mean Relative Error (MRE) | 0.0451 | 0.0356 | 0.0526 | 0.0481 | |
| MSE | 7.62 | 4.81 | 4,611,014,418 | 3,651,980,200 | |
| RMSE | 2.76 | 2.19 | 67,904 | 60,432 | |
| Explained Variance | 0.9886 | 0.9930 | 0.9912 | 0.9930 | |
| Completion Time, l = 0.0719 | Total Cost, l = 0.0576 | |
|---|---|---|
| Criteria | Labeled Data | Labeled Data |
| MMRE | 0.0304 | 0.0327 |
| MdMRE | 0.0190 | 0.0190 |
| Pred(MMRE) | 66.67 | 71.43 |
| Pred(l) | 95.24 | 85.71 |
| Pred(0.25) | 100 | 100 |
| No. | Effort | ActualTime | Zia et al. [31] | Ensemble | ActualCost | Zia et al. [31] | Ensemble |
|---|---|---|---|---|---|---|---|
| 1 | 156 | 63 | 58 | 61 | 1,200,000 | 1,023,207 | 1,134,745 |
| 2 | 202 | 92 | 81 | 91 | 1,600,000 | 1,680,664 | 1,583,169 |
| 3 | 173 | 56 | 52 | 55 | 1,000,000 | 992,270 | 1,038,781 |
| 4 | 331 | 86 | 87 | 88 | 2,100,000 | 2,002,767 | 2,143,033 |
| 5 | 124 | 32 | 29 | 34 | 750,000 | 676,081 | 761,998 |
| 6 | 339 | 91 | 95 | 91 | 3,200,000 | 2,895,133 | 3,079,933 |
| 7 | 97 | 35 | 29 | 34 | 600,000 | 540,114 | 599,667 |
| 8 | 257 | 93 | 84 | 94 | 1,800,000 | 1,614,079 | 1,807,526 |
| 9 | 84 | 36 | 35 | 34 | 500,000 | 507,265 | 498,726 |
| 10 | 211 | 62 | 66 | 61 | 1,200,000 | 1,267,180 | 1,179,763 |
| 11 | 131 | 45 | 41 | 45 | 800,000 | 786,732 | 792,706 |
| 12 | 112 | 37 | 39 | 36 | 650,000 | 597,143 | 637,656 |
| 13 | 101 | 32 | 35 | 34 | 600,000 | 538,495 | 601,809 |
| 14 | 74 | 30 | 26 | 31 | 400,000 | 394,546 | 409,164 |
| 15 | 62 | 21 | 22 | 21 | 350,000 | 330,561 | 379,850 |
| 16 | 289 | 112 | 103 | 110 | 2,000,000 | 1,971,485 | 1,951,407 |
| 17 | 113 | 39 | 40 | 37 | 800,000 | 770,857 | 704,895 |
| 18 | 141 | 52 | 50 | 54 | 1,000,000 | 961,866 | 838,379 |
| 19 | 213 | 80 | 76 | 84 | 1,500,000 | 1,453,032 | 1,545,680 |
| 20 | 137 | 56 | 51 | 48 | 800,000 | 854,348 | 796,084 |
| 21 | 91 | 35 | 34 | 34 | 550,000 | 567,484 | 552,589 |
| Algorithm | RF | AdaBoost | DT | Ensemble | RF | AdaBoost | DT | Ensemble | |
|---|---|---|---|---|---|---|---|---|---|
| Data | Input | Effort, Vi + Size Labels | |||||||
| Output | Time | Cost | |||||||
| Results | Accuracy (%) | 96.92 | 96.44 | 96.57 | 96.41 | 97.03 | 95.19 | 97.33 | 96.88 |
| 0.9869 | 0.9926 | 0.9910 | 0.9911 | 0.9885 | 0.9923 | 0.9944 | 0.9936 | ||
| MRE | 0.0308 | 0.0356 | 0.0343 | 0.0359 | 0.0297 | 0.0481 | 0.0267 | 0.0312 | |
| RMSE | 2.92 | 2.19 | 2.42 | 2.40 | 73,781 | 60,432 | 51,357 | 54,880 | |
| Explained Variance | 0.9869 | 0.9930 | 0.9914 | 96.4068 | 0.9890 | 0.9930 | 0.9953 | 96.8768 | |
| Technique | R2 | MAE | MMRE | MdMRE | Pred (25%) | Pred (7.19%) |
|---|---|---|---|---|---|---|
| ANFIS [49] | 0.982857 | 0.57697 | 4.310884 | 100 | NA | |
| ANFIS-GA [49] | 0.973329 | 2.025023 | 6.568641 | 100 | NA | |
| ANFIS-PSO [49] | 0.977309 | 0.366967 | 4.498164 | 100 | NA | |
| ANFIS-BAT [49] | 0.955252 | 1.386903 | 5.78877 | 100 | NA | |
| Zia [31] | 0.9638 | NA | 0.0719 | 0.0714 | NA | 57.14 |
| DBN-ALO [50] | NA | NA | 0.0225 | 0.0222 | 98.4321 | NA |
| ANFIS-EEBAT [49] | 0.99935 | 0.35558 | 1.518 | 100 | NA | |
| Linear Model [46] | 0.9476 | NA | 0.099 | NA | NA | NA |
| SVR-RBF-GS [47] | NA | NA | 0.0620 | 0.0426 | 100 | 66.667 |
| FFNN [48] | 0.973897 | NA | 6.220651 | NA | NA | NA |
| GA [48] | 0.967112 | NA | 6.742859 | NA | NA | NA |
| ABC-PSO [51] | 0.9734 | NA | 5.69 | 3.33 | NA | 66.67 |
| ABC [51] | 0.9732 | NA | 5.84 | 5.18 | NA | 61.9 |
| PSO [51] | 0.9626 | NA | 6.69 | 7.14 | NA | 61.9 |
| FWA-LM [52] | 0.9946 | NA | 2.9339 | NA | NA | 100 |
| GRNN [43] | 0.7125 | NA | 0.3581 | NA | 85.9182 | NA |
| PNN [43] | 0.6614 | NA | 1.5776 | NA | 87.6561 | NA |
| GMDH-PNN [43] | 0.6259 | NA | 0.1563 | NA | 89.6689 | NA |
| CCNN [43] | 0.9303 | NA | 0.1486 | NA | 94.7649 | NA |
| ANFIS [45] | NA | NA | 8.4277 | NA | 76.1905 | NA |
| newGRNN [45] | NA | NA | 2.7864 | NA | 76.1905 | NA |
| RBFN [45] | NA | NA | 8.0909 | NA | 76.1905 | NA |
| DT [44] | NA | NA | MMER 0.3820 | MdMER 0.2896 | 38.0952 | NA |
| SGB [44] | NA | NA | MMER 0.1632 | MdMER 0.1151 | 85.7143 | NA |
| RF [44] | NA | NA | MMER 0.2516 | MdMER 0.2033 | 66.6667 | NA |
| KNN [53] | 0.984 | NA | 0.0530 | 0.0313 | 100 | 76.19 |
| Our Bagging Ensemble Approach | 0.9911 | NA | 0.0304 | 0.0190 | 100 | 95.24 |
| No. | ActualTime | Ensemble | (days) | ActualCost | Ensemble | (PKR) |
|---|---|---|---|---|---|---|
| 1 | 63 | 61 ± 0 | 2 | 1,200,000 | 1,134,745 ± 18,648 | 65,255 |
| 2 | 92 | 91 ± 1 | 1 | 1,600,000 | 1,583,169 ± 11,129 | 16,831 |
| 3 | 56 | 55 ± 1 | 1 | 1,000,000 | 1,038,781 ± 33,226 | 38,781 |
| 4 | 86 | 88 ± 0 | 2 | 2,100,000 | 2,143,033 ± 70,970 | 43,033 |
| 5 | 32 | 34 ± 0 | 2 | 750,000 | 761,998 ± 2345 | 11,998 |
| 6 | 91 | 91 ± 1 | 0 | 3,200,000 | 3,079,933 ± 87,462 | 120,067 |
| 7 | 35 | 34 ± 0 | 1 | 600,000 | 599,667 ± 4666 | 333 |
| 8 | 93 | 94 ± 1 | 1 | 1,800,000 | 1,807,526 ± 5646 | 7,526 |
| 9 | 36 | 34 ± 0 | 2 | 500,000 | 498,726 ± 10,684 | 1274 |
| 10 | 62 | 61 ± 1 | 1 | 1,200,000 | 1,179,763 ± 41,896 | 20,237 |
| 11 | 45 | 45 ± 0 | 0 | 800,000 | 792,706 ± 12,393 | 7294 |
| 12 | 37 | 36 ± 1 | 1 | 650,000 | 637,656 ± 8295 | 12,344 |
| 13 | 32 | 34 ± 0 | 2 | 600,000 | 601,809 ± 3610 | 1809 |
| 14 | 30 | 31 ± 1 | 1 | 400,000 | 409,164 ± 13,970 | 9164 |
| 15 | 21 | 21 ± 1 | 0 | 350,000 | 379,850 ± 30,960 | 29,850 |
| 16 | 112 | 110 ± 1 | 2 | 2,000,000 | 1,951,407 ± 8142 | 48,593 |
| 17 | 39 | 37 ± 1 | 2 | 800,000 | 704,895 ± 16,684 | 95,105 |
| 18 | 52 | 54 ± 0 | 2 | 1,000,000 | 838,379 ± 24,395 | 161,621 |
| 19 | 80 | 84 ± 3 | 4 | 1,500,000 | 1,545,680 ± 16,771 | 45,680 |
| 20 | 56 | 48 ± 1 | 8 | 800,000 | 796,084 ± 4320 | 3916 |
| 21 | 35 | 34 ± 0 | 1 | 550,000 | 552,589 ± 8010 | 2589 |
| Summary | Description |
|---|---|
| Approach | A combination of an algorithmic model that sets the base of project effort and a machine learning model to produce time and cost estimates |
| Discretization | Data label for clustering and future unsupervised analysis |
| Single model | Use of decision tree due to its interpretability, capability of learning nonlinear relationships and relative fast computing time with small data |
| Multi model | Random forest, AdaBoost and a mixing method ensemble technique help to reduce overfitting and boost accuracy of misclassified data |
| Criteria | We used as many metrics as possible for each phase so that we could better evaluate the performance of the models |
| Performance | The simple integration of the three models and the discretization allowed the approach to perform better than other techniques when comparing , MMRE and Pred (7.19%) |
| Open Source resources | The implementation using Python allows other users to replicate the experiments without spending resources on licenses and expensive software |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez Sánchez, E.; Vázquez Santacruz, E.F.; Cervantes Maceda, H. Effort and Cost Estimation Using Decision Tree Techniques and Story Points in Agile Software Development. Mathematics 2023, 11, 1477. https://doi.org/10.3390/math11061477
Rodríguez Sánchez E, Vázquez Santacruz EF, Cervantes Maceda H. Effort and Cost Estimation Using Decision Tree Techniques and Story Points in Agile Software Development. Mathematics. 2023; 11(6):1477. https://doi.org/10.3390/math11061477
Chicago/Turabian StyleRodríguez Sánchez, Eduardo, Eduardo Filemón Vázquez Santacruz, and Humberto Cervantes Maceda. 2023. "Effort and Cost Estimation Using Decision Tree Techniques and Story Points in Agile Software Development" Mathematics 11, no. 6: 1477. https://doi.org/10.3390/math11061477
APA StyleRodríguez Sánchez, E., Vázquez Santacruz, E. F., & Cervantes Maceda, H. (2023). Effort and Cost Estimation Using Decision Tree Techniques and Story Points in Agile Software Development. Mathematics, 11(6), 1477. https://doi.org/10.3390/math11061477