
Novel Creation Method of Feature Graphics for Image Generation Based on Deep Learning Algorithms



Abstract
:1. Introduction
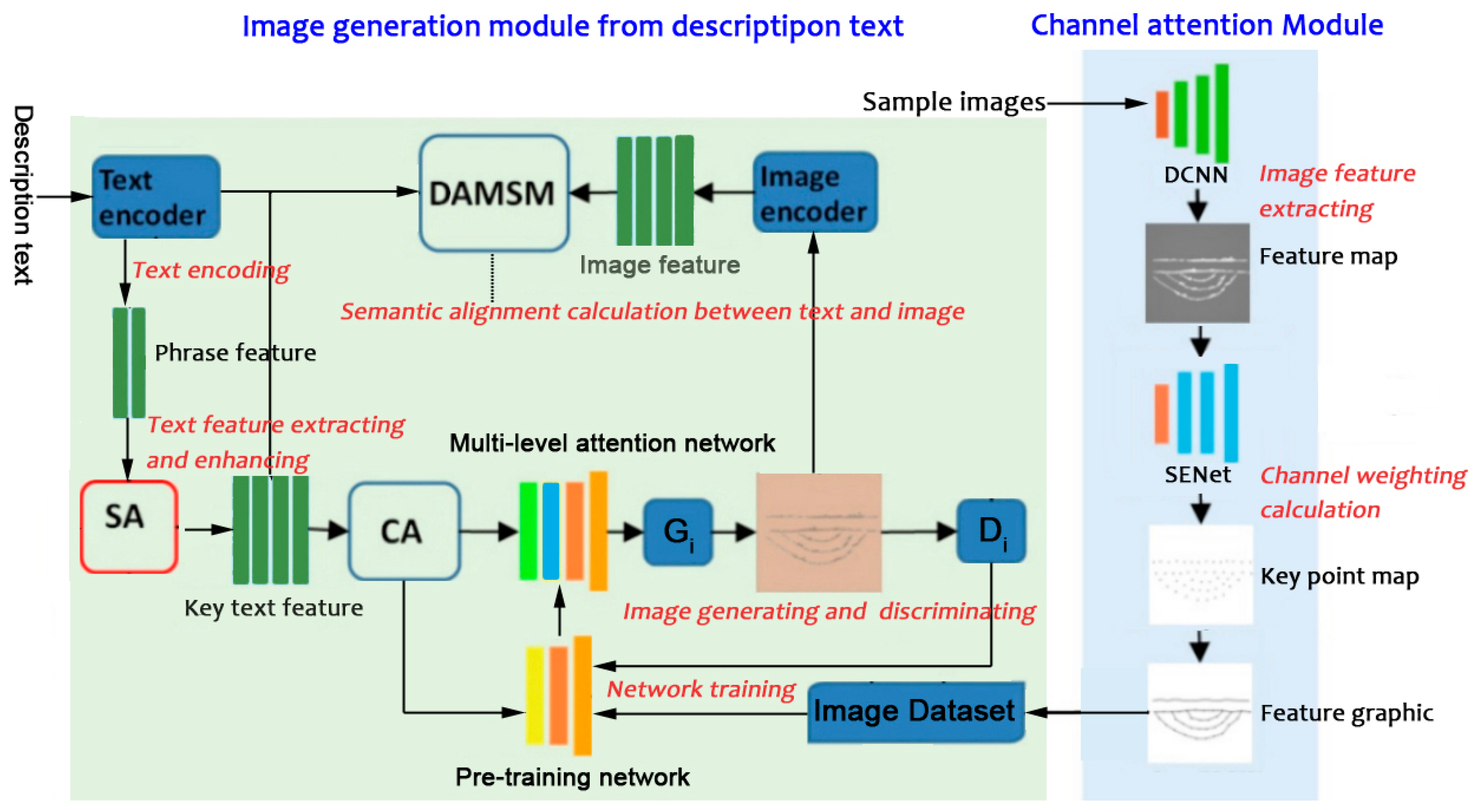
2. Creation Method of Feature Graphics Based on Channel Attention Module
2.1. Image Feature Extraction by Convolution Operation
2.2. Feature Graphic Creation by the Channel Weighting Calculation
- 1.
- Squeeze operation
- 2.
- Excitation operation
- 3.
- Scale operation
2.3. Method Summary Based on Practice of Feature Graphic Creation
- Image features of sample images are extracted by a convolution operation. It improves the image feature extraction effect that enhance the brightness feature by taking image brightness feature processing in advance. Additionally, it highlights the key image features by removing the scattered small areas afterwards.
- A key point matrix is obtained by the channel weighting calculation including squeeze, excitation, and scale operations. It obtains the key point feature map with a relatively clear display by taking interval sampling to the key point matrix afterwards.
- Feature graphics are created with the method of drawMatches() by connecting the key feature points with the limited conditions that the distance between two points is lower than a certain value, which is set as 6 pixels in this practice.
3. Method of Image Generation from Description Text
3.1. Text-to-Image Generation Network Model
3.2. Image Generating and Discriminating
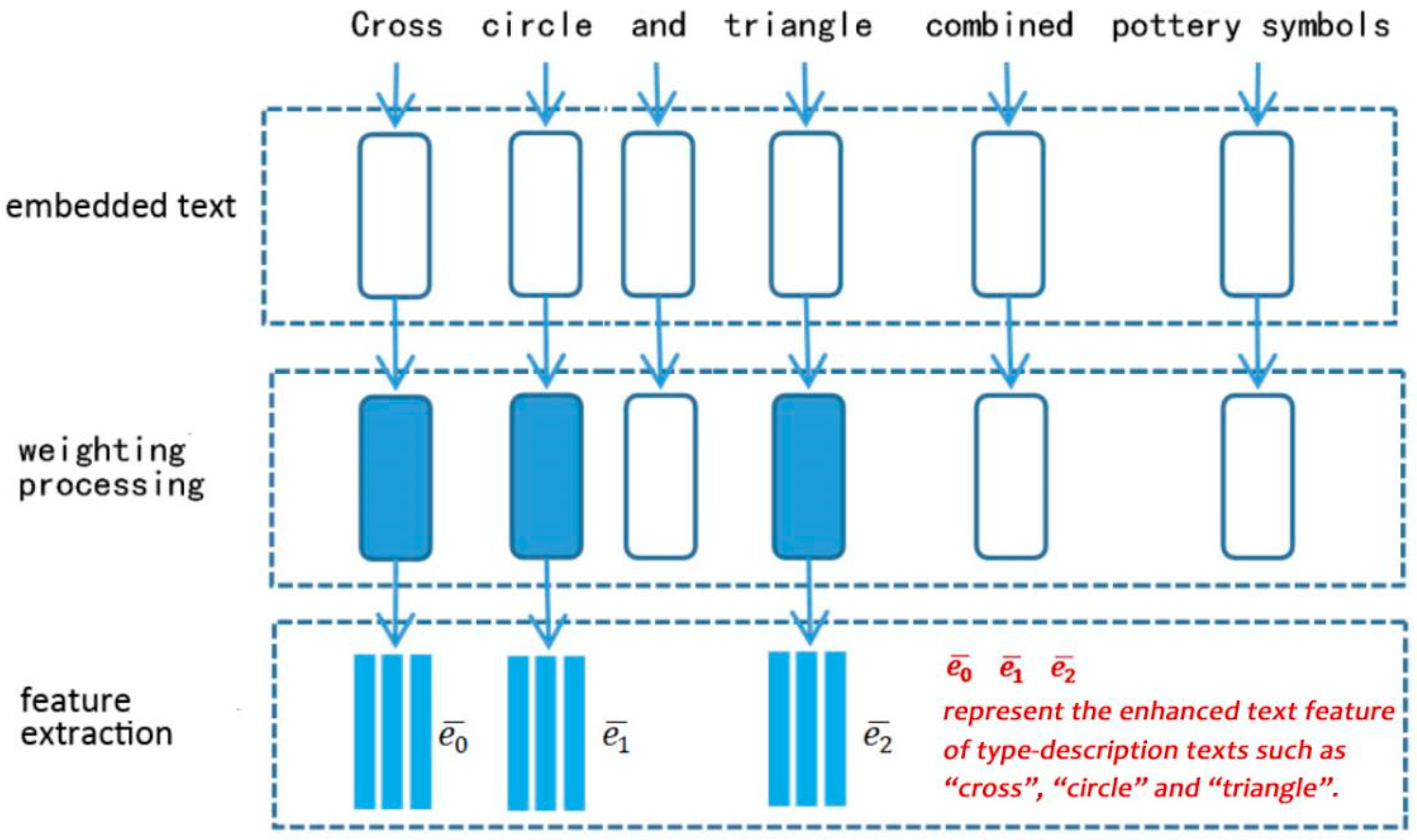
3.3. Text Feature Extracting and Enhancing
- The LSTM text encoder is applied to encode the sentences or phrases in the description text, and then they are divided into a text matrix that includes several text units according to semantics, which can be described as:where is the encoded text feature, () represents the phrase feature divided from the sentence, and is the number of phrases.
- The word matrix is weighted by the text encoder. The word context vector for each sub-region of the image is calculated by the hidden layer feature. Additionally, the calculating method for the th sub-area can be described as:where:where is the weight of the ith word. , is the text feature vector of the th word, and represents the hidden layer feature from the type-description text feature calculated by Equation (7).
- The A1-dimensional deep convolutional neural network is applied to perform the convolution operation on the weighted text matrix , and the result is input into LSTM to encode and extract the key text feature vector matrix . For the ith text unit, the extracted text feature vector can be expressed as:where represents the convolution operation, is the convolution kernel, b is the offset value, and is the operation of text coding and feature extraction in LSTM.
3.4. Semantic Alignment Calculation between Text and Image
3.5. Loss Calculation for Image Generation
4. Network Training and Test Experiment
4.1. Network Model Training with the Feature Graphic Maps
4.2. Test Experiment on Image Dataset
4.3. Comparative Experiment for Image Generation
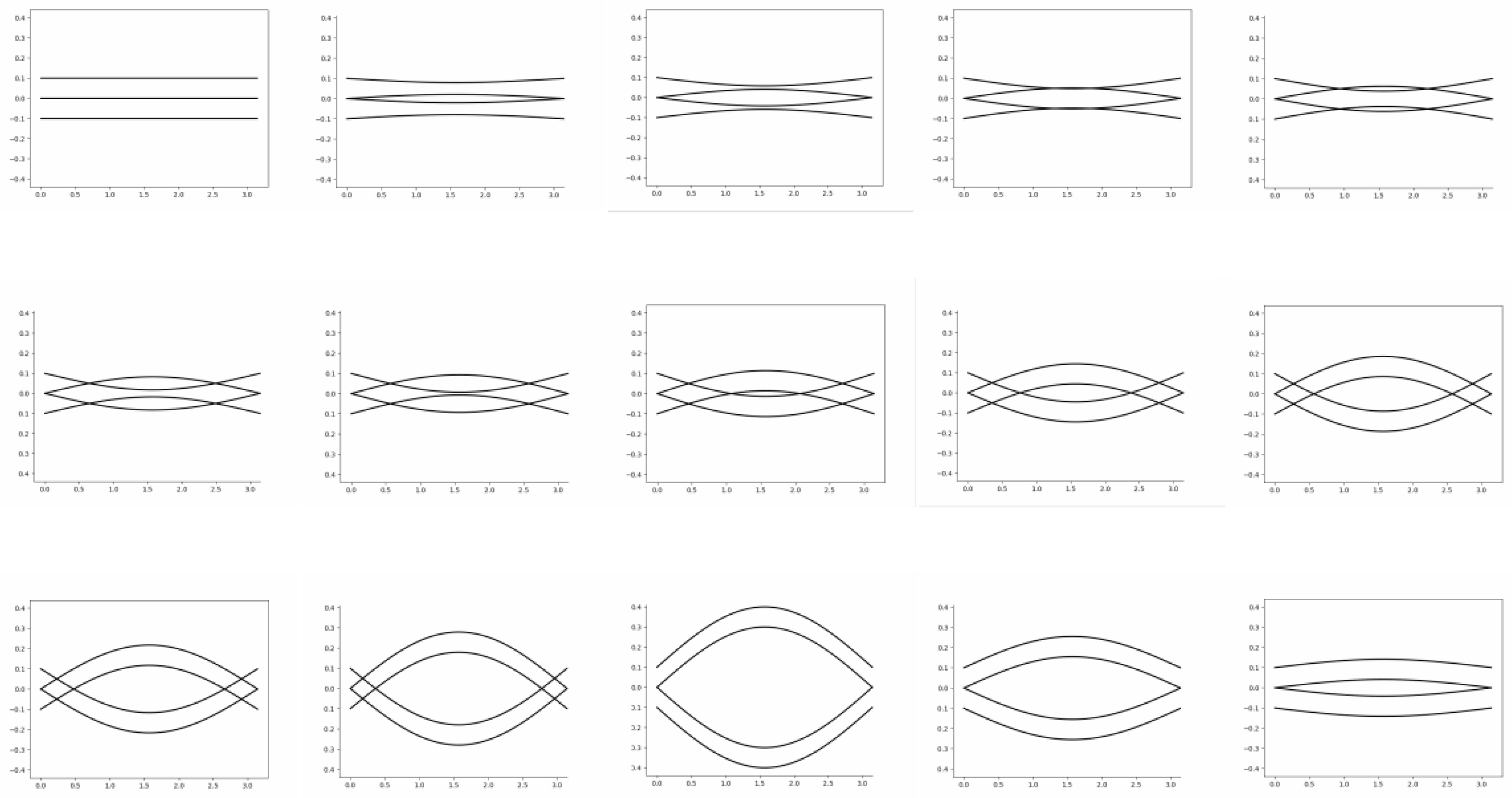
5. Generation Method of Dynamic Graphics
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Ciano, G.; Andreini, P.; Mazzierli, T.; Bianchini, M.; Scarselli, F. A multi-Stage GAN for multi-organ chest x-ray image generation and segmentation. Mathematics 2021, 9, 2896. [Google Scholar] [CrossRef]
- Lee, D.; Lee, J.; Ko, J.; Yoon, J.Y.; Hyun, R.K.; Nam, Y. Deep Learning in MR Image Processing. Investig. Magn. Reson. Imaging 2019, 23, 81–99. [Google Scholar] [CrossRef]
- Marginean, R.; Andreica, A.; Diosan, L.; Balint, Z. Feasibility of automatic seed generation applied to cardiac MRI image analysis. Mathematics 2020, 8, 1511. [Google Scholar] [CrossRef]
- Kim, J.; Jin, K.; Jang, S.; Kang, S.; Kim, Y. Game effect sprite generation with minimal data via conditional GAN. Expert Syst. Appl. 2011, 211, 118491. [Google Scholar] [CrossRef]
- Omri, M.; Abdel-Khalek, S.; Khalil, E.M.; Bouslimi, J.; Joshi, G.P. Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning. Mathematics 2022, 10, 288. [Google Scholar] [CrossRef]
- Zhang, L.Z.; Yin, H.J.; Hui, B.; Liu, S.J.; Zhang, W. Knowledge-Based Scene Graph Generation with Visual Contextual Dependency. Mathematics 2022, 10, 2525. [Google Scholar] [CrossRef]
- Xue, Y.; Guo, Y.C.; Zhang, H.; Xu, T.; Zhang, S.H.; Huang, X.L. Deep image synthesis from intuitive user input: A review and perspectives. Comput. Vis. Media 2021, 8, 3–31. [Google Scholar] [CrossRef]
- Lee, H.; Kim, G.; Hur, Y.; Lim, H. Visual thinking of neural networks: Interactive text to image generation. IEEE Access 2021, 9, 64510–64523. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks an overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.Q.; Yu, W.J.; Yi, X.K.; Khan, A.; Yuan, F.; Zheng, Y.H. Recent progress on Generative Adversarial Networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Frolov, S.; Hinz, T.; Raue, F.; Hees, J.; Dengel, A. Adversarial text-to-image generation: A review. Neural Netw. 2021, 144, 187–209. [Google Scholar] [CrossRef] [PubMed]
- Agnese, J.; Herrera, J.; Tao, H.C.; Zhu, X.Q. A survey and taxonomy of adversarial neural networks for text-to-image generation. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1345. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; We, S.P.; Shi, K.B.; Yang, Y.; Huang, T.W. Neural architecture search with a light-weight transformer for text-to- image generation. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1567–1576. [Google Scholar] [CrossRef]
- Quan, F.N.; Lang, B.; Liu, Y.X. ARRPNGAN: Text-to-image GAN with attention regularization and region proposal networks. Signal Process. Image Commun. 2022, 106, 116728. [Google Scholar] [CrossRef]
- Zhang, H.; Zhu, H.Q.; Yang, S.Y.; Li, W.H. DGattGAN: Cooperative up-sampling based dual generator attentional GAN on text-to-image generation. IEEE Access 2021, 9, 29584–29598. [Google Scholar] [CrossRef]
- Chen, H.G.; He, X.H.; Yang, H.; Feng, J.X.; Teng, Q.Z. A two-stage deep generative adversarial quality enhancement network for real-world 3D CT images. Expert Syst. Appl. 2022, 193, 116440. [Google Scholar] [CrossRef]
- Zhang, Z.Q.; Zhang, Y.Y.; Yu, W.X.; Lu, J.W.; Nie, L.; He, G.; Jiang, N.; Fan, Y.B.; Yang, Z. Text to image generation based on multiple discrimination. In Proceedings of the International Conference on Artificial Neural Networks: Artificial Neural Networks and Machine Learning, Munich, Germany, 10–13 September 2019. [Google Scholar]
- Tan, Y.X.; Lee, C.H.; Neo, M.; Lim, K.M. Text-to-image generation with self-supervised learning. Pattern Recognit. Lett. 2022, 157, 119–126. [Google Scholar] [CrossRef]
- Tong, W.; Chen, W.T.; Han, W.; Li, X.J.; Wang, L.Z. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Li, H.F.; Qiu, K.J.; Chen, L.; Mei, X.M.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 905–909. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the Twenty-Eighth Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Costa, P.; Galdran, A.; Meyer, M.I.; Niemeijer, M.; Abramoff, M.; Mendonca, A.M.; Campilho, A. End-to-end adversarial retinal image generation. IEEE Trans. Med. Imaging 2018, 37, 781–791. [Google Scholar] [CrossRef] [PubMed]
- Feng, F.X.; Niu, T.R.; Li, R.F.; Wang, X.J. Modality disentangled discriminator for text-to-image generation. IEEE Trans. Multimed. 2021, 24, 2112–2124. [Google Scholar] [CrossRef]
- Yang, Y.Y.; Ni, X.; Hao, Y.B.; Liu, C.Y.; Wang, W.S.; Liu, Y.F.; Xie, H.Y. MF-GAN: Multi-conditional fusion Generative Adversarial Network for text-to-image generation. In Proceedings of the 28th International Conference on MultiMedia Modeling, Phu Quoc, Vietnam, 6–10 June 2022. [Google Scholar]
- Zhou, R.; Jiang, C.; Xu, Q.Y. A survey on Generative Adversarial Network-based text-to-image generation. Neurocomputing 2021, 451, 316–336. [Google Scholar] [CrossRef]
- Elasri, M.; Elharrouss, O.; Al-Maadeed, S.; Tairi, H. Image Generation: A Review. Neural Process. Lett. 2022, 54, 4609–4646. [Google Scholar] [CrossRef]
- Maheshwari, A.; Goyal, A.; Hanawal, M.K.; Ramakrishnan, G. DynGAN: Generative Adversarial Networks for dynamic network embedding. In Proceedings of the NeurlPS, Vancouver, BC, Canada, 8–14 September 2019. [Google Scholar]
- Otberdout, N.; Daoudi, M.; Kacem, A.; Ballihi, L.; Berretti, S. Dynamic facial expression generation on hilbert hypersphere with conditional Wasserstein Generative Adversarial Nets. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 848–863. [Google Scholar] [CrossRef]
- Yi, P.; Wang, Z.Y.; Jiang, K.; Jiang, J.J.; Lu, T.; Ma, J.Y. A progressive fusion Generative Adversarial Network for realistic and consistent video super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2264–2280. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Line-Shape (249) | Polygon- Shape (201) | Circular Arc- Shape (288) | Cross-Shape (235) | Chinese Character- Shape (112) | Pictographic- Shape (208) |
|---|---|---|---|---|---|
| Horizontal line (66) | Triangle (41) | Dot (16) | Cross (103) | 万 shape (32) | Animal (107) |
| Vertical line (65) | Box (109) | Semi-circle (19) | Grid (48) | 田 shape (51) | Plant (36) |
| Polygonal line (43) | Semi-box (31) | Circle (111) | Fork (84) | 人 shape (29) | House (26) |
| Number (39) | Polygon (20) | Arc (58) | Other (39) | ||
| Hook (19) | Wave (31) | ||||
| Arrow (17) | Fish (53) |
| Method | Inception Score | Wasserstain-2 Distance | R-Precision (%) |
|---|---|---|---|
| GAN | 3.52 ± 0.03 | 28.02 | 52.23 ± 3.42 |
| Attn GAN | 4.08 ± 0.05 | 16.58 | 66.52 ± 4.28 |
| CA-Attn GAN | 6.34 ± 0.03 | 14.72 | 79.06 ± 4.64 |
| Method | Image Quality and Diversity | Accuracy and Efficiency |
|---|---|---|
| Compared with GAN | 47.47–80.11% | 33.73–71.48% |
| Compared with Attn GAN | 11.22–55.39% | 15.11–34.48% |
| Method | Inception Score | Wasserstain-2 Distance |
|---|---|---|
| multi-level attention module, | 4.08 ± 0.05 | 18.42 |
| multi-level attention module, | 4.32 ± 0.04 | 16.43 |
| multi-level attention module, | 4.56 ± 0.04 | 15.64 |
| multi-level attention module, | 4.23 ± 0.05 | 16.58 |
| Method | CC-Loss | GFLOPs |
|---|---|---|
| 98.72 ± 0.08 | 8.54 | |
| 98.53 ± 0.09 | 11.87 | |
| 97.87 ± 0.07 | 13.24 | |
| 97.42 ± 0.06 | 14.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Tang, Y. Novel Creation Method of Feature Graphics for Image Generation Based on Deep Learning Algorithms. Mathematics 2023, 11, 1644. https://doi.org/10.3390/math11071644
Li Y, Tang Y. Novel Creation Method of Feature Graphics for Image Generation Based on Deep Learning Algorithms. Mathematics. 2023; 11(7):1644. https://doi.org/10.3390/math11071644
Chicago/Turabian StyleLi, Ying, and Ye Tang. 2023. "Novel Creation Method of Feature Graphics for Image Generation Based on Deep Learning Algorithms" Mathematics 11, no. 7: 1644. https://doi.org/10.3390/math11071644
APA StyleLi, Y., & Tang, Y. (2023). Novel Creation Method of Feature Graphics for Image Generation Based on Deep Learning Algorithms. Mathematics, 11(7), 1644. https://doi.org/10.3390/math11071644