


A Cross-Modal Feature Fusion Model Based on ConvNeXt for RGB-D Semantic Segmentation

Abstract
1. Introduction
2. Related Work
3. Method
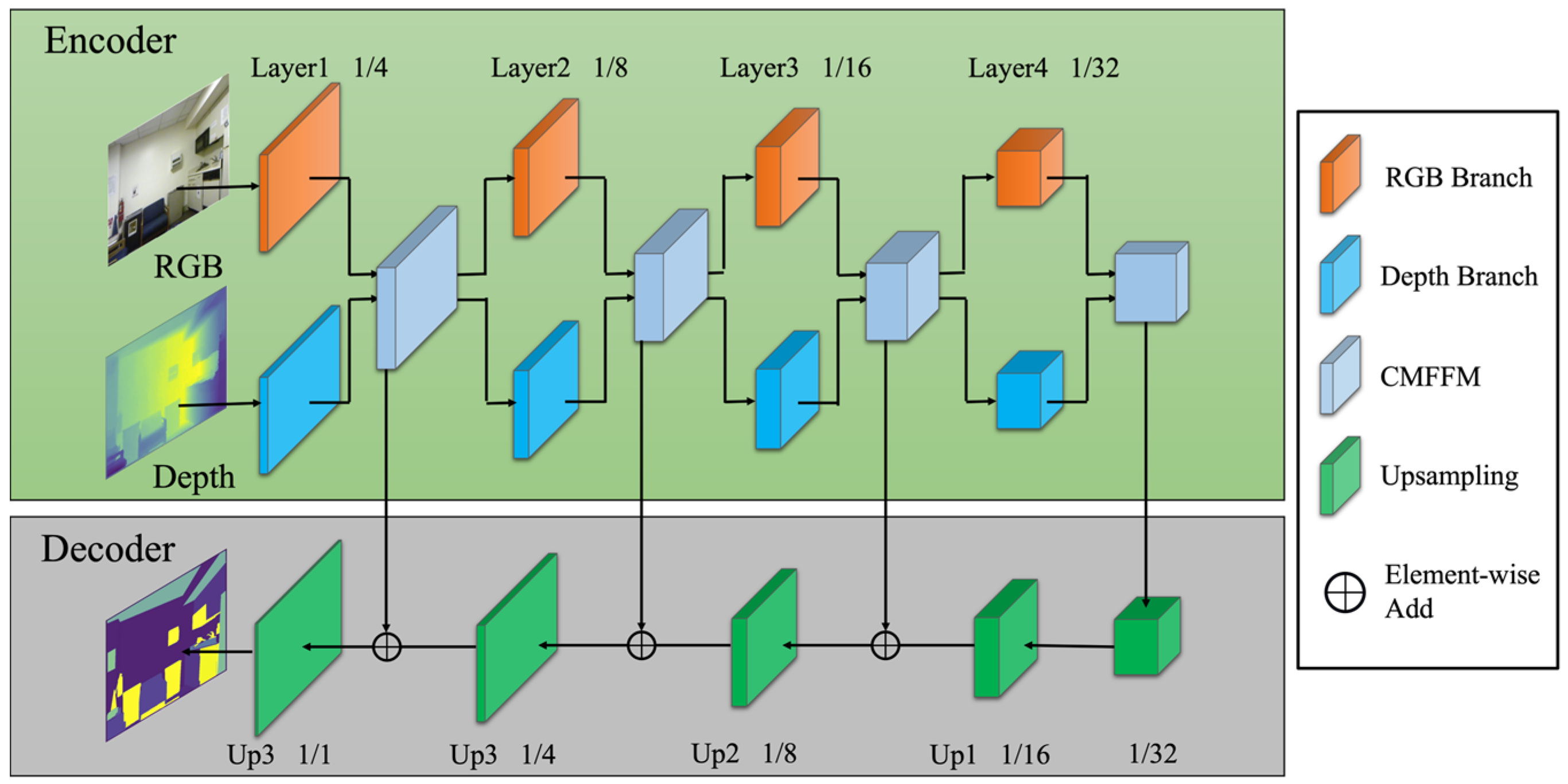
3.1. Framework Overview
3.2. ConvNeXt
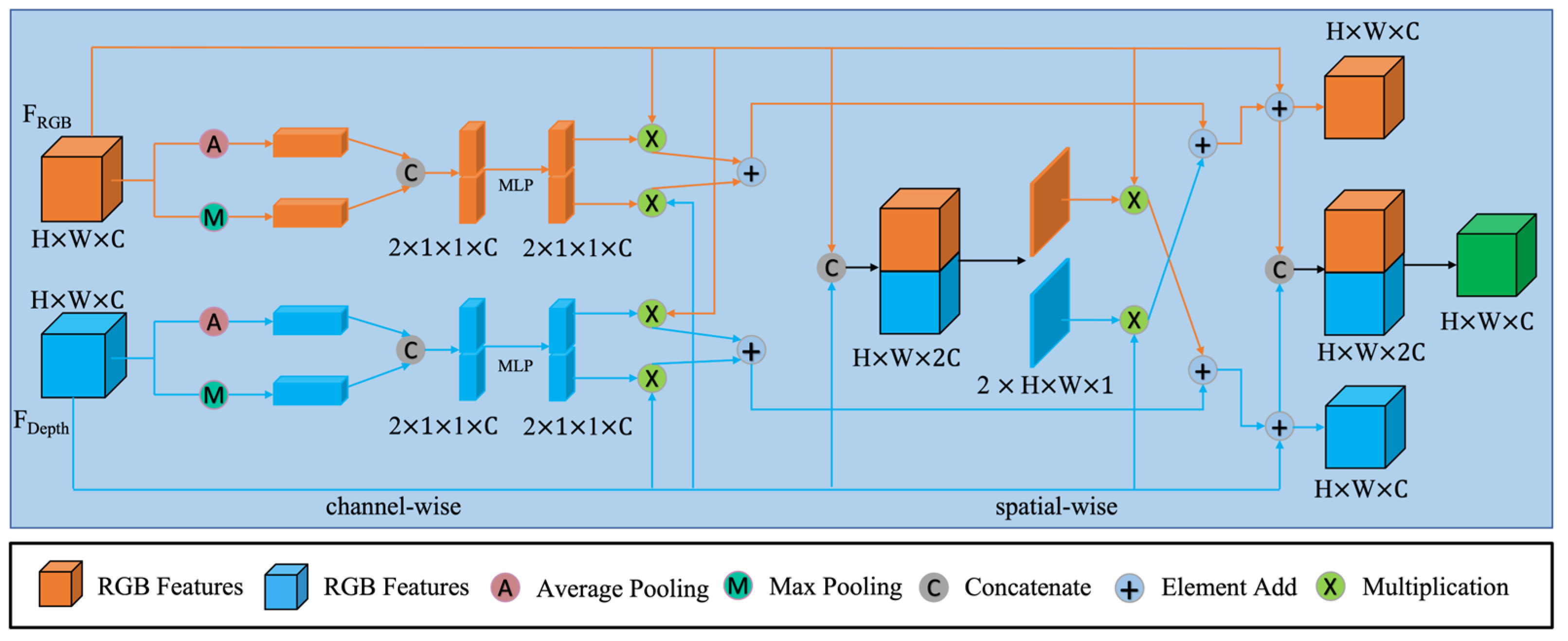
3.3. Cross-Modal Feature Fusion Module (CMFFM)
4. Results
4.1. Experimental Parameters and Evaluation Indexes
4.2. Public Datasets
4.3. Our Rice Dataset
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, L.; Yang, K.; Hu, X.; Hu, W.; Wang, K. Real-Time fusion network for RGB-D semantic segmentation incorporating unexpected obstacle detection for road-driving images. IEEE Robot. Autom. Lett. 2020, 5, 5558–5565. [Google Scholar] [CrossRef]
- Seichter, D.; Köhler, M.; Lewandowski, B.; Wengefeld, T.; Gross, H.M. Efficient RGB-D semantic segmentation for indoor scene analysis. In Proceedings of the IEEE International Conference on Robotics and Automation, Hongkong, China, 21–23 April 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; Volume 2021, pp. 13525–13531. [Google Scholar]
- Mohammed, M.S.; Abduljabar, A.M.; Faisal, M.M.; Mahmmod, B.M.; Abdulhussain, S.H.; Khan, W.; Liatsis, P.; Hussain, A. Low-cost autonomous car level 2: Design and implementation for conventional vehicles. Results Eng. 2023, 17, 100969. [Google Scholar] [CrossRef]
- Faisal, M.M.; Mohammed, M.S.; Abduljabar, A.M.; Abdulhussain, S.H.; Mahmmod, B.M.; Khan, W.; Hussain, A. Object de-tection and distance measurement using AI. In Proceedings of the International Conference on Developments in Esystems Engineering, DeSE, Sharjah, United Arab Emirates, 7–10 December 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; Volume 2021, pp. 559–565. [Google Scholar]
- Duarte, J.; Martínez-Flórez, G.; Gallardo, D.I.; Venegas, O.; Gómez, H.W. A bimodal extension of the epsilon-skew-normal model. Mathematics 2023, 11, 507. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–23 June 2022; pp. 11976–11986. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNET: Attention based network to exploit complementary features for RGBD semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Malik, J. Perceptual organization and recognition of indoor scenes from RGB-D images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 564–571. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based CNN architecture. In Proceedings of the Computer Vision—ACCV 2016, Taipei, Taiwan, 20–24 November 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 213–228. [Google Scholar]
- Lee, S.; Park, S.J.; Hong, K.S. RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2017; Volume 2017, pp. 4990–4999. [Google Scholar]
- Chen, X.; Lin, K.Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with seperation-and-aggregation gate for RGB-D semantic segmentation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 561–577. [Google Scholar]
- Cheng, Y.; Cai, R.; Li, Z.; Zhao, X.; Huang, K. Locality-sensitive deconvolution networks with gated fusion for RGB-D indoor semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1475–1483. [Google Scholar]
- Wang, W.; Neumann, U. Depth-aware CNN for RGB-D segmentation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 144–161. [Google Scholar]
- Lin, D.; Chen, G.; Cohen-Or, D.; Heng, P.A.; Huang, H. Cascaded feature network for semantic segmentation of RGB-D images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2017; Volume 2017, pp. 1320–1328. [Google Scholar]
- Lin, D.; Zhang, R.; Ji, Y.; Li, P.; Huang, H. SCN: Switchable context network for semantic segmentation of RGB-D images. IEEE Trans. Cybern. 2020, 50, 1120–1131. [Google Scholar] [CrossRef] [PubMed]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3D graph neural networks for RGBD semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2017; Volume 2017, pp. 5209–5218. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Jie, Z.; Li, X.; Yang, J. Joint task-recursive learning for RGB-D scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2608–2623. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Cui, Z.; Xu, C.; Zhang, Z.; Wang, C.; Zhang, T.; Yang, J. Pattern-structure diffusion for multi-task learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE Computer Society: Washington DC, USA, 2020; pp. 4513–4522. [Google Scholar]
- Fan, J.; Zheng, P.; Lee, C.K.M. A multi-granularity scene segmentation network for human-robot collaboration environment perception. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Kyoto, Japan, 23–27 October 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; Volume 2022, pp. 2105–2110. [Google Scholar]
- Yang, E.; Zhou, W.; Qian, X.; Yu, L. MGCNet: Multilevel gated collaborative network for RGB-D semantic segmentation of indoor scene. IEEE Signal Process. Lett. 2022, 29, 2567–2571. [Google Scholar] [CrossRef]
- Hua, Z.; Qi, L.; Du, D.; Jiang, W.; Sun, Y. Dual attention based multi-scale feature fusion network for indoor RGBD semantic segmentation. In Proceedings of the International Conference on Pattern Recognition, Montreal, QC, Canada, 21–25 August 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; Volume 2022, pp. 3639–3644. [Google Scholar]
- Wu, P.; Guo, R.; Tong, X.; Su, S.; Zuo, Z.; Sun, B.; Wei, J. Link-RGBD: Cross-guided feature fusion network for RGBD semantic segmentation. IEEE Sensors J. 2022, 22, 24161–24175. [Google Scholar] [CrossRef]
- Chen, J.; Zhan, Y.; Xu, Y.; Pan, X. FAFNet: Fully aligned fusion network for RGBD semantic segmentation based on hierarchical semantic flows. IET Image Process. 2023, 17, 32–41. [Google Scholar] [CrossRef]
- Bai, L.; Yang, J.; Tian, C.; Sun, Y.; Mao, M.; Xu, Y.; Xu, W. DCANet: Differential convolution attention network for RGB-D semantic segmentation. arXiv 2022, arXiv:2210.06747. [Google Scholar] [CrossRef]
- Wu, Z.; Allibert, G.; Stolz, C.; Ma, C.; Demonceaux, C. Depth-adapted CNNs for RGB-D semantic segmentation. arXiv 2022, arXiv:2206.03939. [Google Scholar] [CrossRef]
- Cai, Y.; Chen, X.; Zhang, C.; Lin, K.Y.; Wang, X.; Li, H. Semantic scene completion via integrating instances and scene in-the-loop. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE Computer Society: Washington DC, USA, 2021; pp. 324–333. [Google Scholar]
- Price, A.; Huang, K.; Berenson, D. Fusing RGBD tracking and segmentation tree sampling for multi-hypothesis volumetric segmentation. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; Volume 2021, pp. 9572–9578. [Google Scholar]
- Li, S.; Zou, C.; Li, Y.; Zhao, X.; Gao, Y. Attention-based multi-modal fusion network for semantic scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11402–11409. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar] [CrossRef]
- Zhang, G.; Xue, J.H.; Xie, P.; Yang, S.; Wang, G. Non-local aggregation for RGB-D semantic segmentation. IEEE Signal Process. Lett. 2021, 28, 658–662. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2012; IEEE Computer Society: Washington DC, USA, 2015; pp. 567–576. [Google Scholar]
- Kong, S.; Fowlkes, C. Recurrent scene parsing with perspective understanding in the loop. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE Computer Society: Washington DC, USA, 2018; pp. 956–965. [Google Scholar]
- Yan, X.; Hou, S.; Karim, A.; Jia, W. RAFNet: RGB-D attention feature fusion network for indoor semantic segmentation. Displays 2021, 70, 102082. [Google Scholar] [CrossRef]
- Zhou, H.; Qi, L.; Huang, H.; Yang, X.; Wan, Z.; Wen, X. CANet: Co-attention network for RGB-D semantic segmentation. Pattern Recognit. 2022, 124, 108468. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values | |
|---|---|---|
| Operating system | Ubuntu20.04 | |
| CPU | Intel(R) Core (TM) i9-10900K (3.70 GHz) | |
| GPU | GeForce RTX 3090 | |
| Development environment | Anaconda3.6 | |
| Framework | Pytorch1.8 | |
| Input size | NYUDv2 | 480 × 640 |
| SUN-RGBD | 480 × 640 | |
| RICE-RGBD | 512 × 160 | |
| Learning Rate | 2 × 10−5 | |
| Batch size | 8 | |
| Epoch | 200 | |
| Method | mIoU (%) | Pixel Acc. (%) |
|---|---|---|
| 3DGNN [20] | 43.1 | - |
| Kong et al. [39] | 44.5 | 72.1 |
| RAFNet [40] | 47.5 | 73.8 |
| ACNet [9] | 48.3 | - |
| CANet [41] | 51.2 | 76.6 |
| NANet [36] | 51.4 | 77.1 |
| DCANet [28] | 53.3 | 78.2 |
| MGCNet [24] | 54.5 | 78.7 |
| ConvNeXt-CMFFM | 51.9 | 76.8 |
| Method | mIoU (%) | Pixel Acc. (%) |
|---|---|---|
| 3DGNN [20] | 45.9 | - |
| Kong et al. [39] | 45.1 | 80.3 |
| RAFNet [40] | 47.2 | 81.3 |
| ACNet [9] | 48.1 | - |
| CANet [41] | 48.1 | 81.6 |
| NANet [36] | 48.8 | 82.3 |
| DCANet [28] | 49.6 | 82.6 |
| MGCNet [24] | 51.5 | 86.5 |
| ConvNeXt-CMFFM | 53.5 | 82.5 |
| Method | Dataset | mIoU (%) | Pixel Acc. (%) |
|---|---|---|---|
| ConvNeXt-CMFFM | NYUDv2 | 51.9 | 76.8 |
| SUN-RGB | 53.5 | 82.5 | |
| RICE-RGBD | 74.8 | 88.3 | |
| ConvNeXt | NYUDv2 | 50.2 | 76.1 |
| SUN-RGB | 50.9 | 79.9 | |
| RICE-RGBD | 71.5 | 86.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Li, B.; Guo, J.; Chen, W.; Zhang, D.; Huang, F. A Cross-Modal Feature Fusion Model Based on ConvNeXt for RGB-D Semantic Segmentation. Mathematics 2023, 11, 1828. https://doi.org/10.3390/math11081828
Tang X, Li B, Guo J, Chen W, Zhang D, Huang F. A Cross-Modal Feature Fusion Model Based on ConvNeXt for RGB-D Semantic Segmentation. Mathematics. 2023; 11(8):1828. https://doi.org/10.3390/math11081828
Chicago/Turabian StyleTang, Xiaojiang, Baoxia Li, Junwei Guo, Wenzhuo Chen, Dan Zhang, and Feng Huang. 2023. "A Cross-Modal Feature Fusion Model Based on ConvNeXt for RGB-D Semantic Segmentation" Mathematics 11, no. 8: 1828. https://doi.org/10.3390/math11081828
APA StyleTang, X., Li, B., Guo, J., Chen, W., Zhang, D., & Huang, F. (2023). A Cross-Modal Feature Fusion Model Based on ConvNeXt for RGB-D Semantic Segmentation. Mathematics, 11(8), 1828. https://doi.org/10.3390/math11081828