
Multi-Camera Multi-Vehicle Tracking Guided by Highway Overlapping FoVs
 , , , , , and
, , , , , and
Abstract
:1. Introduction
- Due to the large camera field of view, the scale of vehicle targets changes as they travel through narrow tunnels. In the near field of view, vehicle confidence is high and there is no occlusion; in the middle field of view, confidence is relatively high and vehicles begin to occlude each other; in the far field of view, confidence is low and occlusion is severe. During long-term tracking, there is a risk of fragmentation and loss of vehicle trajectories, especially for large trucks;
- The appearance of flares on both sides of the tunnel walls may cause glare in the camera field of view. Due to intense lighting within the highway tunnel, the camera faces difficulty accurately capturing the features of various vehicles, especially when their appearances are similar. This situation may result in false positives, missing, and other issues, affecting the effectiveness of target detection and tracking. Consequently, it impacts the accuracy and robustness of the overall MCMVT;
- According to the road topology structures of each camera field of view, within the narrow and lengthy highway tunnel, the camera field of view is larger near the camera and smaller in the distance. Additionally, due to the highway movement of vehicles, they appear to move rapidly in the near field of each camera view and have a longer transition time in the distance. The lower resolution in the distant field is not conducive to effective vehicle detection and tracking. Furthermore, in order to provide more field of view coverage and obtain more continuous target trajectories in high-speed tunnels, the distance between adjacent cameras is usually shortened to provide higher-resolution data. This results in the same vehicle identity existing within the field of view of a single camera. It takes a long time, but it takes a relatively short time to appear in the next camera field of view.
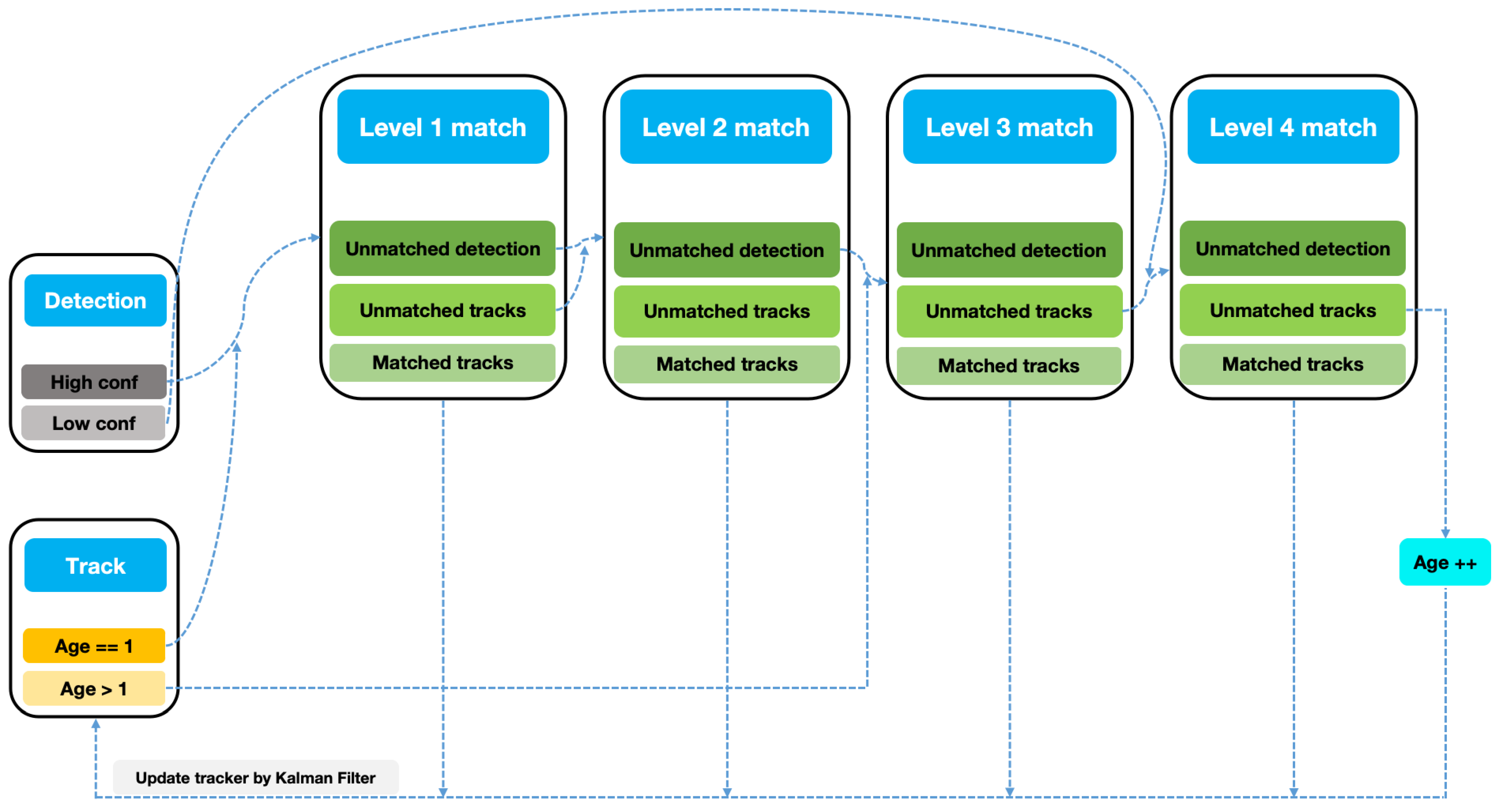
- Introduce a Cascade Multi-Level Multi-Target Tracking strategy, grouping vehicles based on the scores of detection boxes. Prioritizing cascade matching helps minimize uncertainties introduced by occlusion. The multi-level association process, considering the changing scales of targets as vehicles traverse narrow tunnels, maximizes the advantages of high-quality appearance features from high-scoring boxes in the near field. This strategy effectively associates and tracks both small target vehicles in the distant field and large target vehicles in the tunnel;
- Implement a scene modeling and candidate trajectory filtering module based on road topology structures. This module defines predefined sub-regions for each field of view based on highway entry–exit flow, allowing vehicles to transition through ordered regions. This helps alleviate motion blur and detector false positives caused by static traffic signs on both sides of the tunnel. The module aims to filter and obtain reliable cross-camera candidate matching trajectories and improve the performance of Multi-Camera Multi-Vehicle Tracking;
- Design a spatio-temporal constraint module tailored for highway overlapping fields of view. Building upon high-quality cross-camera candidate vehicle tracking trajectories, this module reduces the spatial matching domain, identifying effective matching segments within the long, narrow tunnel for each camera field of view. It combines highway entry–exit flow spatio-temporal masks to rationalize the ordered transition time sequence of vehicles. This significantly reduces the ReID search space during cross-matching and accelerates the matching process. The result is the generation of complete cross-camera vehicle tracking chains.
2. Related Work
2.1. Vehicle Detection
2.2. Re-Identification
2.3. Single-Camera Multi-Target Tracking
2.4. Inter-Camera Association
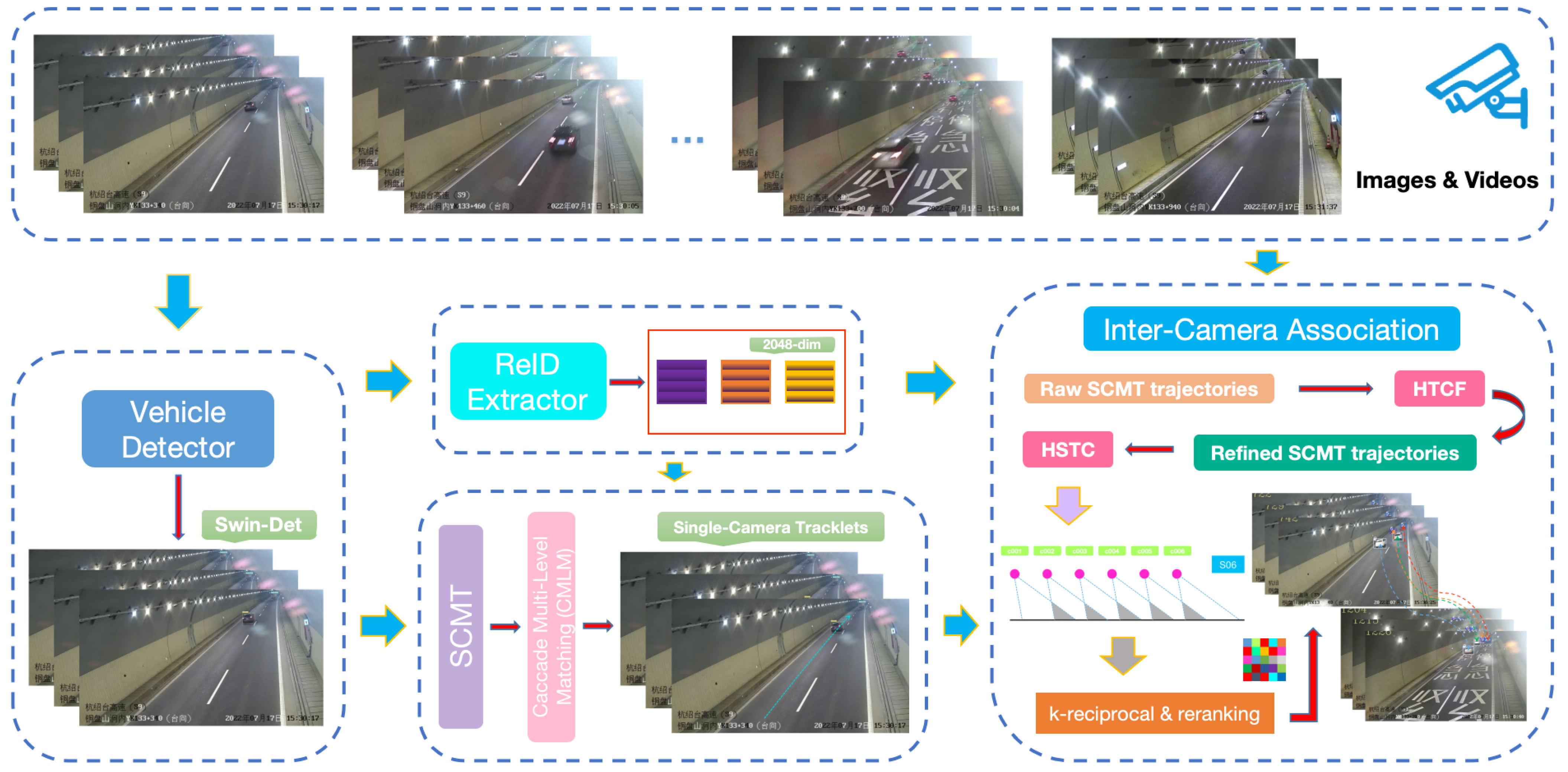
3. Method
3.1. Vehicle Detection
3.2. Vehicle Re-Identification
3.3. Single-Camera Multi-Target Tracking
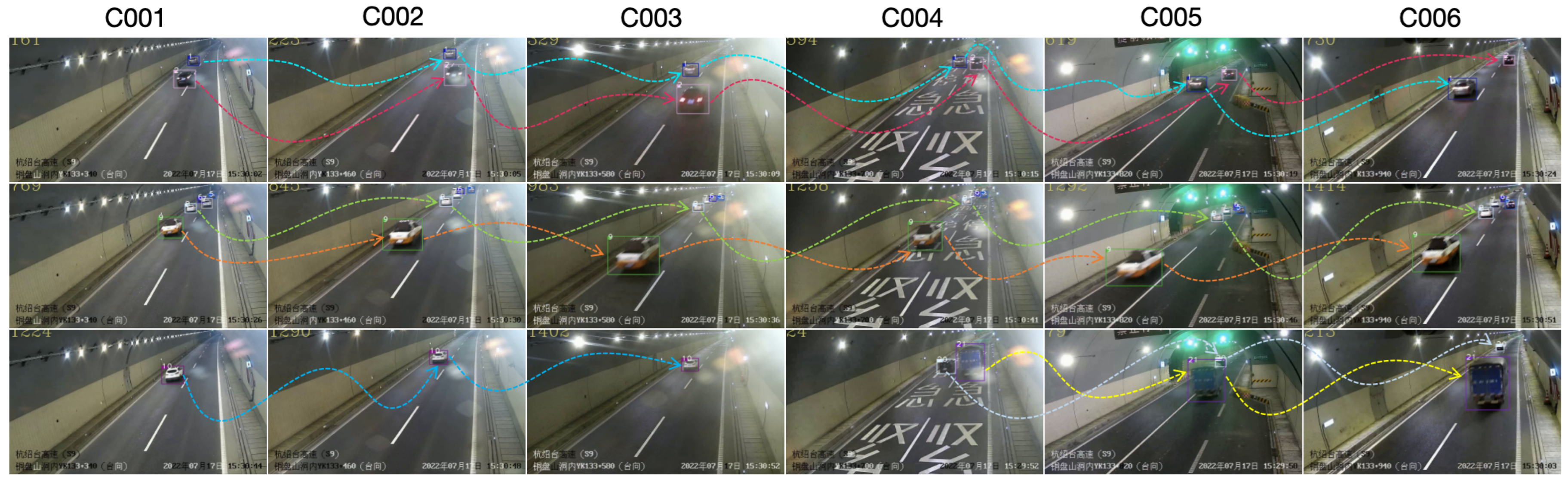
3.4. Inter-Camera Association
3.4.1. Highway Entry–Exit Flow
3.4.2. Highway Tracklets Candidate Filter
3.4.3. Highway Spatio-Temporal Constraint
| Algorithm 1 Inter-Camera Association |
| Require: The distance d between each camera (i = 1,2,3,4,5), vehicle transition time under each camera [], the average speed , the average time for the vehicle to enter the current camera N and appear in the next camera , tracking trajectory . Average characteristics of trajectory (N = 1,2,3,4,5). |
| Ensure matching trajectory across cameras |
| 1. CAM_DIST = A, ; |
| 2. for each camera N, N belongs to [1, 5] do |
| 3. , . (Overlapping-Fovs Dist); |
| 4. end for |
| 5. for each trajectory transition time [] do |
| 6. Get overlapping-fovs transition time ; |
| 7. end for |
| 8. for each trajectory do |
| 9. Judge whether , conflict based on the spatio-temporal mask of highway |
| entry-exit flow; |
| 10. end for |
| 11. for rest trajectory do |
| 12. According on the mean feature of the trajectory to calculate the cosine similarity between a and b; |
| 13. Calculate similarity distance matrix ; |
| 14. end for |
| 15. K-reciprocal nearest reranking to refine ; |
| 16. Hierarchical clustering: |
| 17. (1) Set a distance threshold of 0.5 within a single camera for tracklets clustering; |
| 18. (2) Set a distance threshold of 0.9 between adjacent cameras and select the tracklets pairs with the smallest distance for clustering; |
| 19. Assign same global ID of trajectory; |
| 20. return Visual tracking chain |
4. Experiment
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparative Experiment
- YOLOv8 [26]: the YOLOv8 model enhances its detection capabilities by combining state-of-the-art backbone and neck architectures and introducing an anchor-free split Ultralytics head. This approach eliminates the need for anchor boxes and balances optimization accuracy and speed, further enhancing the model’s detection abilities;
- Swin Transformer [22]: the Swin Transformer leverages a sliding window self-attention mechanism to effectively handle both global and local information through hierarchical partitioning, achieving outstanding performance in object detection tasks with strong scalability and computational efficiency;
- YOLOv9 [27]: YOLOv9 introduces the concept of Programmable Gradient Information (PGI) to address information loss during data transmission in deep networks. Additionally, it designs a lightweight network architecture called the General Efficient Layer Aggregation Network (GELAN) based on gradient path planning, achieving better parameter utilization using traditional convolution operators alone.
- NCCU: NCCU focuses on optimizing the matching of vehicle image features and geometric factors, such as trajectory continuity, vehicle movement direction, and the continuous travel duration under different camera views;
- ELECTRICITY: ELECTRICITY is an efficient and accurate multi-camera vehicle tracking system that combines aggregation loss with a rapid multi-target cross-camera tracking strategy, enabling real-time and robust vehicle tracking across diverse surveillance scenarios;
- DyGlip: DyGlip introduces attention mechanisms into dynamic graphs. It includes a structured attention layer that considers embedded feature information and camera-specific information. Additionally, it incorporates a time attention layer containing temporal information. These components are then encoded and decoded;
- BUPT: BUPT employs clustering loss and trajectory consistency loss to extract robust visual vehicle features optimized for the MTMCT task. By leveraging clustering techniques and trajectory consistency measures, the goal is to enhance the robustness and accuracy of vehicle tracking across multiple cameras, facilitating effective multi-target tracking in complex surveillance scenarios.
4.5. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MCMVT | Multi-Camera Multi-Vehicle Tracking |
| CMLM | Cascade Multi-Level Multi-Target Tracking |
| HTCF | Highway Trajectory Candidate Filtering |
| HSTC | Highway Spatio-Temporal Constraints |
| HST | Highway Surveillance Traffic |
| Swin-Det | Swin Transformer Detection |
References
- Liu, C.; Zhang, Y.; Luo, H.; Tang, J.; Chen, W.; Xu, X.; Wang, F.; Li, H.; Shen, Y.D. City-scale multi-camera vehicle tracking guided by crossroad zones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4129–4137. [Google Scholar]
- Yang, X.; Ye, J.; Lu, J.; Gong, C.; Jiang, M.; Lin, X.; Zhang, W.; Tan, X.; Li, Y.; Ye, X.; et al. Box-grained reranking matching for multi-camera multi-target tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 3096–3106. [Google Scholar]
- Yao, H.; Duan, Z.; Xie, Z.; Chen, J.; Wu, X.; Xu, D.; Gao, Y. City-scale multi-camera vehicle tracking based on space-time-appearance features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 3310–3318. [Google Scholar]
- Huang, H.W.; Yang, C.Y.; Hwang, J.N. Multi-target multi-camera vehicle tracking using transformer-based camera link model and spatial-temporal information. arXiv 2023, arXiv:2301.07805. [Google Scholar]
- Hsu, H.M.; Cai, J.; Wang, Y.; Hwang, J.N.; Kim, K.J. Multi-target multi-camera tracking of vehicles using metadata-aided re-id and trajectory-based camera link model. IEEE Trans. Image Process. 2021, 30, 5198–5210. [Google Scholar] [CrossRef] [PubMed]
- Ye, J.; Yang, X.; Kang, S.; He, Y.; Zhang, W.; Huang, L.; Jiang, M.; Zhang, W.; Shi, Y.; Xia, M.; et al. A robust mtmc tracking system for ai-city challenge 2021. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4044–4053. [Google Scholar]
- Hsu, H.M.; Huang, T.W.; Wang, G.; Cai, J.; Lei, Z.; Hwang, J.N. Multi-camera tracking of vehicles based on deep features re-id and trajectory-based camera link models. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 416–424. [Google Scholar]
- Li, F.; Wang, Z.; Nie, D.; Zhang, S.; Jiang, X.; Zhao, X.; Hu, P. Multi-camera vehicle tracking system for AI City Challenge 2022. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 3265–3273. [Google Scholar]
- Castañeda, J.N.; Jelaca, V.; Frías, A.; Pizurica, A.; Philips, W.; Cabrera, R.R.; Tuytelaars, T. Non-overlapping multi-camera detection and tracking of vehicles in tunnel surveillance. In Proceedings of the 2011 International Conference on Digital Image Computing: Techniques and Applications, Noosa, QLD, Australia, 6–8 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 591–596. [Google Scholar]
- Rios-Cabrera, R.; Tuytelaars, T.; Van Gool, L. Efficient multi-camera vehicle detection, tracking, and identification in a tunnel surveillance application. Comput. Vis. Image Underst. 2012, 116, 742–753. [Google Scholar] [CrossRef]
- Xu, D.; Jiang, Q.; Gu, Y.; Chen, Y.; Wang, Y.; Li, Y.; Gao, M. A Kind of Cross-Camera Tracking Strategy in Tunnel Environment. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 5390–5395. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics; Zenodo: Geneva, Switzerland, 2020. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Lin, J.; Yang, C.; Lu, Y.; Cai, Y.; Zhan, H.; Zhang, Z. An improved soft-YOLOX for garbage quantity identification. Mathematics 2022, 10, 2650. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6748–6758. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO, 2023.
- Wang, C.Y.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Chang, H.S.; Wang, C.Y.; Wang, R.R.; Chou, G.; Liao, H.Y.M. YOLOR-Based Multi-Task Learning. arXiv 2023, arXiv:2309.16921. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6398–6407. [Google Scholar]
- Zheng, Z.; Jiang, M.; Wang, Z.; Wang, J.; Bai, Z.; Zhang, X.; Yu, X.; Tan, X.; Yang, Y.; Wen, S.; et al. Going beyond real data: A robust visual representation for vehicle re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 598–599. [Google Scholar]
- Luo, H.; Chen, W.; Xu, X.; Gu, J.; Zhang, Y.; Liu, C.; Jiang, Y.; He, S.; Wang, F.; Li, H. An empirical study of vehicle re-identification on the AI City Challenge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4095–4102. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1318–1327. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A deep learning-based approach to progressive vehicle re-identification for urban surveillance. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 869–884. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Bishop, G.; Welch, G. An introduction to the kalman filter. Proc. SIGGRAPH Course 2001, 8, 41. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9686–9696. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. Poi: Multiple object tracking with high performance detection and appearance feature. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 36–42. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 107–122. [Google Scholar]
- Jin, J.; Wang, L.; You, Q.; Sun, J. Multi-Object Tracking Algorithm of Fusing Trajectory Compensation. Mathematics 2022, 10, 2606. [Google Scholar] [CrossRef]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-pedestrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Chu, P.; Wang, J.; You, Q.; Ling, H.; Liu, Z. Transmot: Spatial-temporal graph transformer for multiple object tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4870–4880. [Google Scholar]
- He, Y.; Wei, X.; Hong, X.; Shi, W.; Gong, Y. Multi-target multi-camera tracking by tracklet-to-target assignment. IEEE Trans. Image Process. 2020, 29, 5191–5205. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pan, X.; Luo, P.; Shi, J.; Tang, X. Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 464–479. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 2736–2746. [Google Scholar]
- Tang, Z.; Naphade, M.; Liu, M.Y.; Yang, X.; Birchfield, S.; Wang, S.; Kumar, R.; Anastasiu, D.; Hwang, J.N. Cityflow: A city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8797–8806. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera | Time | Conflict |
|---|---|---|
| True (, ) |
| Camera Pairs | (C001, C002) | (C002, C003) | (C003, C004) | (C004, C005) | (C005, C006) |
|---|---|---|---|---|---|
| Average Transition time (s) | 4.2 | 5.6 | 5.3 | 5.3 | 5.2 |
| Model | Param | IDF1 | IDP | IDR | MOTA |
|---|---|---|---|---|---|
| YOLOv8-x | 64.97 M | 73.53 | 74.67 | 72.41 | 61.32 |
| YOLOv9-e | 68.66 M | 74.11 | 74.04 | 74.18 | 61.69 |
| Ours | 92.65 M | 81.20 | 81.79 | 80.62 | 62.67 |
| Method | IDF1 | IDP | IDR | MOTA |
|---|---|---|---|---|
| NCCU | 43.38 | 62.05 | 33.35 | 12.99 |
| ELECTRICITY | 56.23 | 73.24 | 45.63 | 35.16 |
| DyGlip | 66.75 | 73.69 | 61.01 | 55.75 |
| BUPT | 70.94 | 71.24 | 70.64 | 54.62 |
| Ours | 81.20 | 81.79 | 80.62 | 62.67 |
| Method | IDF1 | IDP | IDR |
|---|---|---|---|
| NCCU | 45.97 | 48.91 | 43.35 |
| ELECTRICITY | 53.80 | - | - |
| DyGlip | 64.90 | 59.56 | 71.25 |
| Ours | 64.43 | 67.56 | 61.59 |
| Swin-Det | CMLM | HTCF | HSTC | IDF1 | IDP | IDR | MOTA |
|---|---|---|---|---|---|---|---|
| ✓ | 64.03 | 58.54 | 70.64 | 50.45 | |||
| ✓ | ✓ | 69.71 | 67.68 | 71.87 | 62.15 | ||
| ✓ | ✓ | 65.77 | 72.47 | 60.21 | 50.30 | ||
| ✓ | ✓ | ✓ | 77.52 | 78.98 | 76.11 | 61.31 | |
| ✓ | ✓ | ✓ | ✓ | 81.20 | 81.79 | 80.62 | 62.67 |
| Method | IDF1 | IDP | IDR | MOTA |
|---|---|---|---|---|
| IoU | 79.12 | 86.11 | 73.17 | 61.37 |
| CMLM/thr=0.1 | 80.38 | 81.64 | 79.17 | 61.36 |
| CMLM/thr=0.2 | 80.43 | 81.48 | 79.40 | 61.35 |
| CMLM/thr=0.3 | 81.20 | 81.79 | 80.62 | 62.67 |
| CMLM/thr=0.4 | 80.68 | 80.99 | 80.38 | 61.52 |
| CMLM/thr=0.5 | 80.43 | 81.31 | 79.57 | 61.28 |
| Backbone | IDF1 | IDP | IDR | MOTA |
|---|---|---|---|---|
| IBN-ResNet101 | 80.05 | 81.53 | 78.62 | 61.09 |
| IBN-ResNet101* | 80.30 | 81.81 | 78.84 | 61.31 |
| ResNest101 | 77.19 | 78.56 | 75.86 | 60.85 |
| IBN-ResNext101 | 76.75 | 78.19 | 75.36 | 61.25 |
| IBN-ResNext101* | 77.82 | 79.70 | 76.03 | 59.98 |
| IBN-Se-ResNet101 | 80.26 | 81.80 | 78.78 | 61.26 |
| IBN-ResNet101 | IBN-ResNet101* | ResNest101 | IBN-ResNext101 | IBN-ResNext101* | IBN-Se-ResNet101 | IDF1 | IDP | IDR | MOTA |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 80.50 | 80.74 | 80.27 | 61.38 | |||
| ✓ | ✓ | ✓ | 79.46 | 79.85 | 79.06 | 60.41 | |||
| ✓ | ✓ | ✓ | 80.55 | 80.72 | 80.38 | 61.18 | |||
| ✓ | ✓ | ✓ | 80.55 | 80.73 | 80.38 | 61.19 | |||
| ✓ | ✓ | 81.20 | 81.79 | 80.62 | 62.67 | ||||
| ✓ | ✓ | 80.37 | 80.38 | 80.36 | 60.75 | ||||
| ✓ | ✓ | 80.36 | 80.43 | 80.29 | 60.76 | ||||
| ✓ | ✓ | 80.18 | 80.09 | 80.27 | 60.58 | ||||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 80.50 | 80.63 | 80.36 | 61.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Fang, R.; Li, S.; Miao, Q.; Fan, X.; Hu, J.; Chan, S. Multi-Camera Multi-Vehicle Tracking Guided by Highway Overlapping FoVs. Mathematics 2024, 12, 1467. https://doi.org/10.3390/math12101467
Zhang H, Fang R, Li S, Miao Q, Fan X, Hu J, Chan S. Multi-Camera Multi-Vehicle Tracking Guided by Highway Overlapping FoVs. Mathematics. 2024; 12(10):1467. https://doi.org/10.3390/math12101467
Chicago/Turabian StyleZhang, Hongkai, Ruidi Fang, Suqiang Li, Qiqi Miao, Xinggang Fan, Jie Hu, and Sixian Chan. 2024. "Multi-Camera Multi-Vehicle Tracking Guided by Highway Overlapping FoVs" Mathematics 12, no. 10: 1467. https://doi.org/10.3390/math12101467