
Research on the Automatic Detection of Ship Targets Based on an Improved YOLO v5 Algorithm and Model Optimization
Abstract
1. Introduction
2. Related Work
3. Methodology
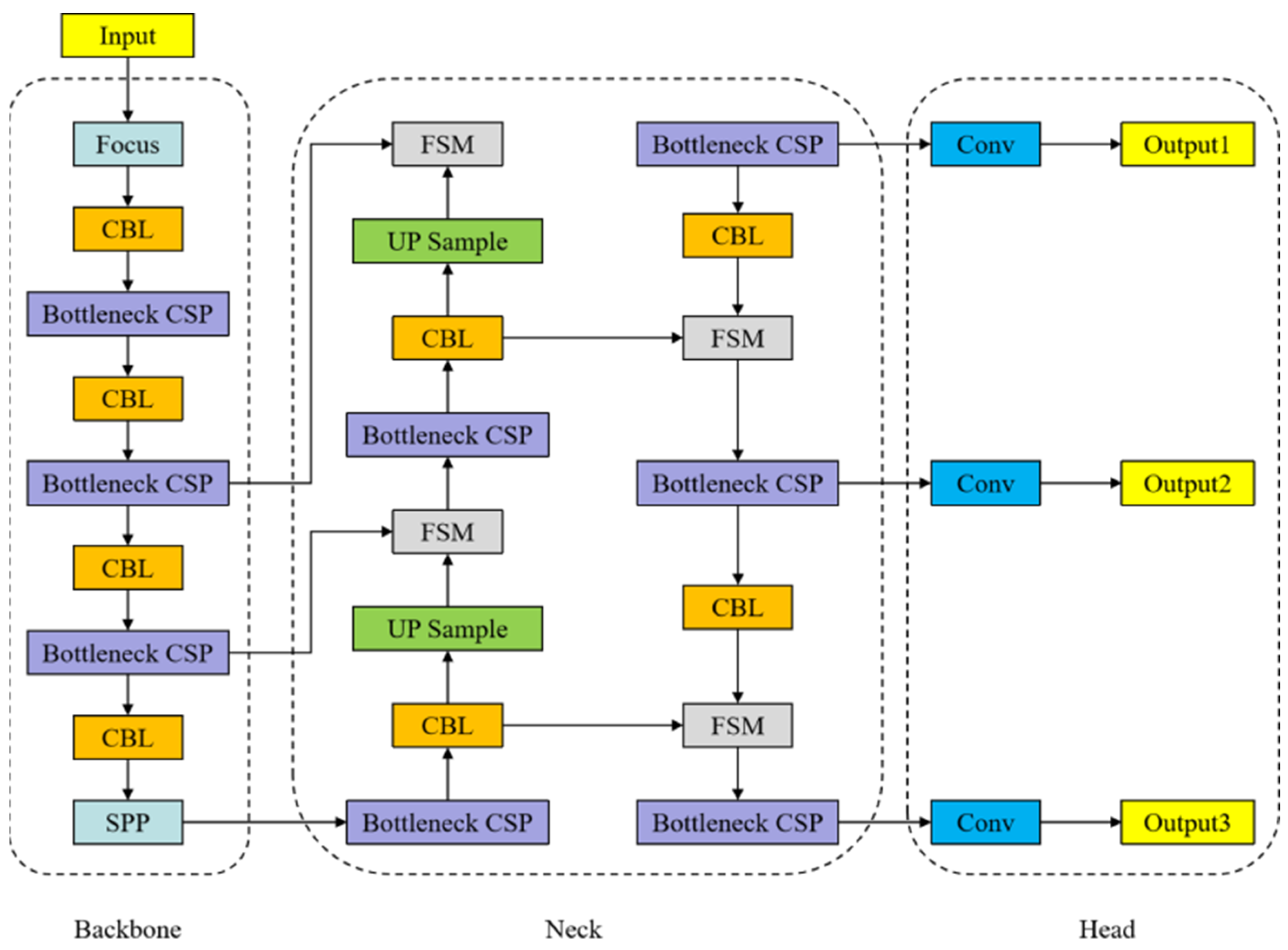
3.1. YOLO v5 Algorithm Improvements
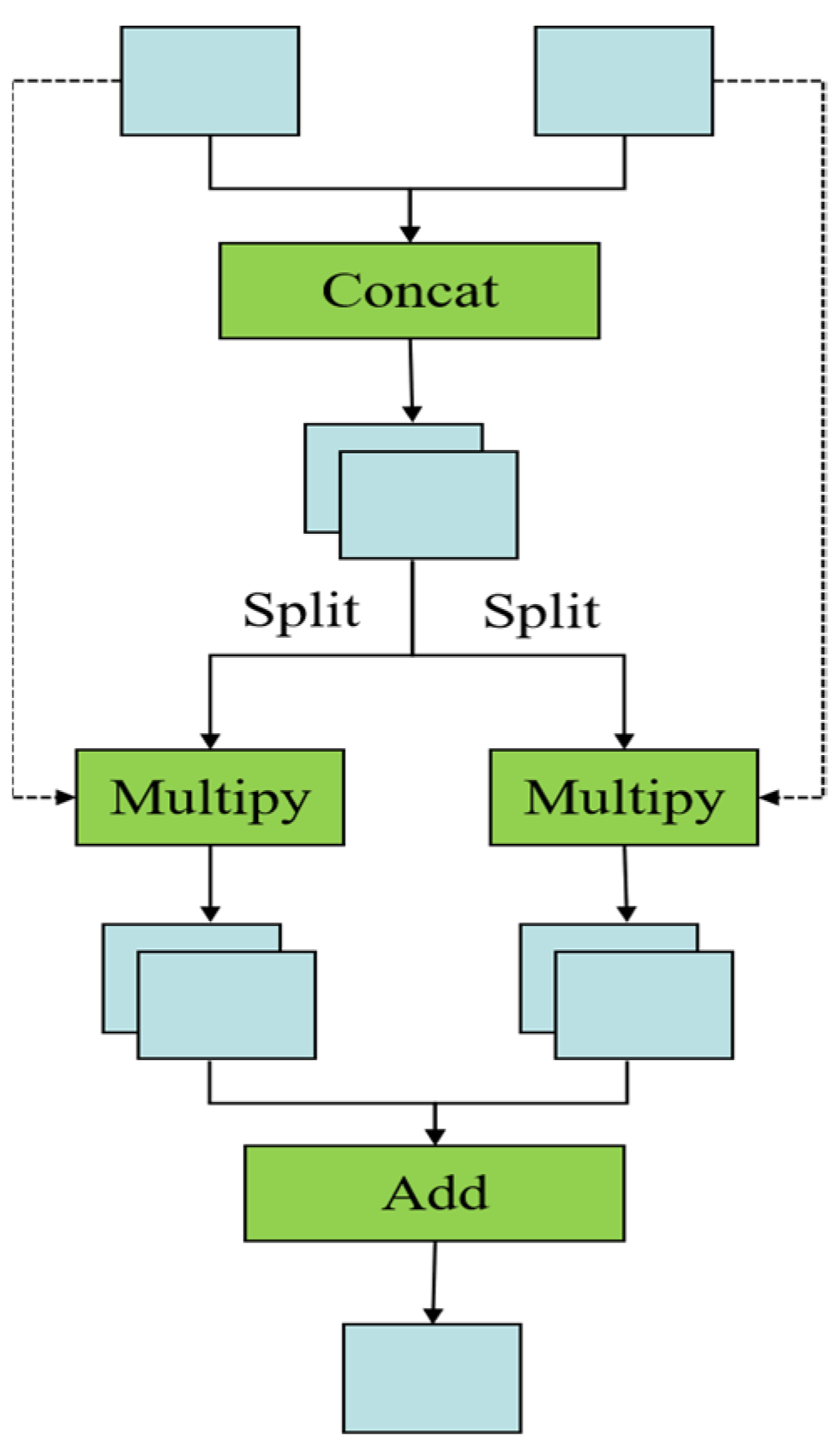
3.2. Model Optimization and Improvement
3.3. Image Data Enhancement
4. Data Set and Implementation Settings
4.1. Remote Sensing Ship Data Set Acquisition
4.2. Data Set Ship Target Labeling
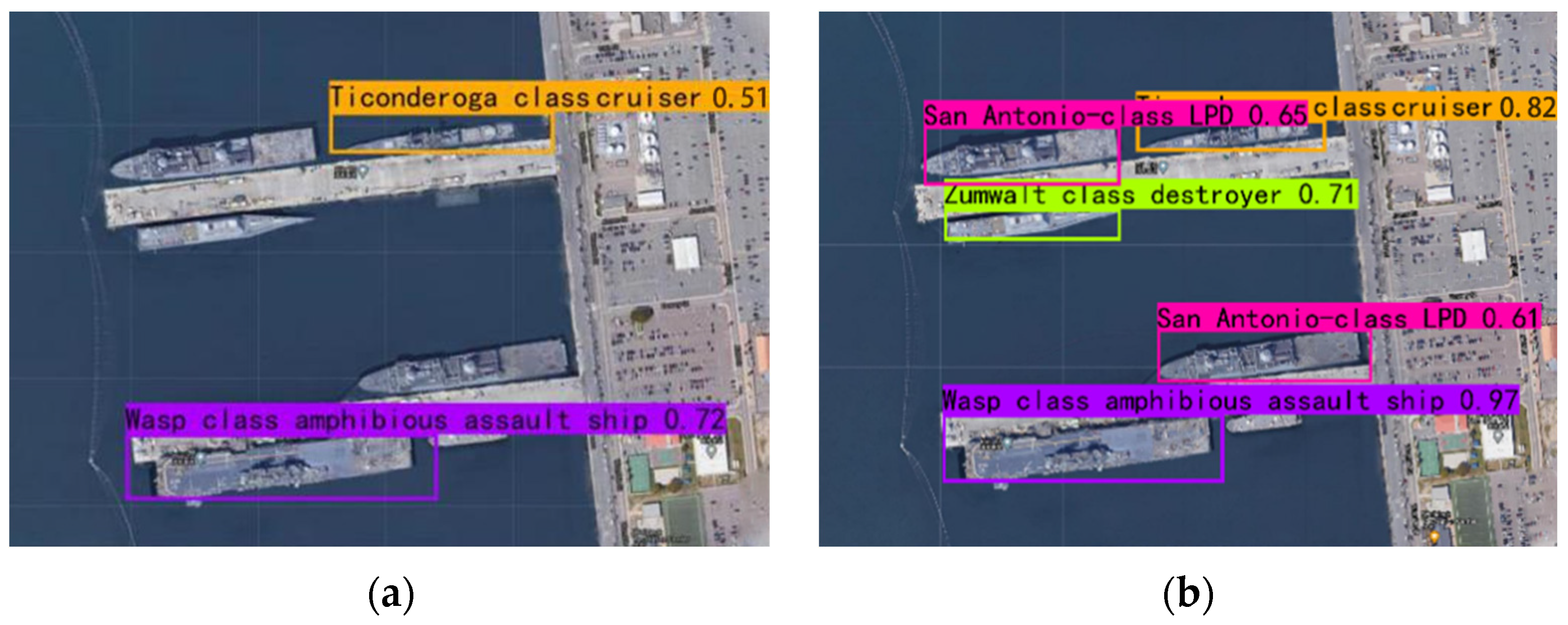
5. Experiments and Results
5.1. Implementation Settings
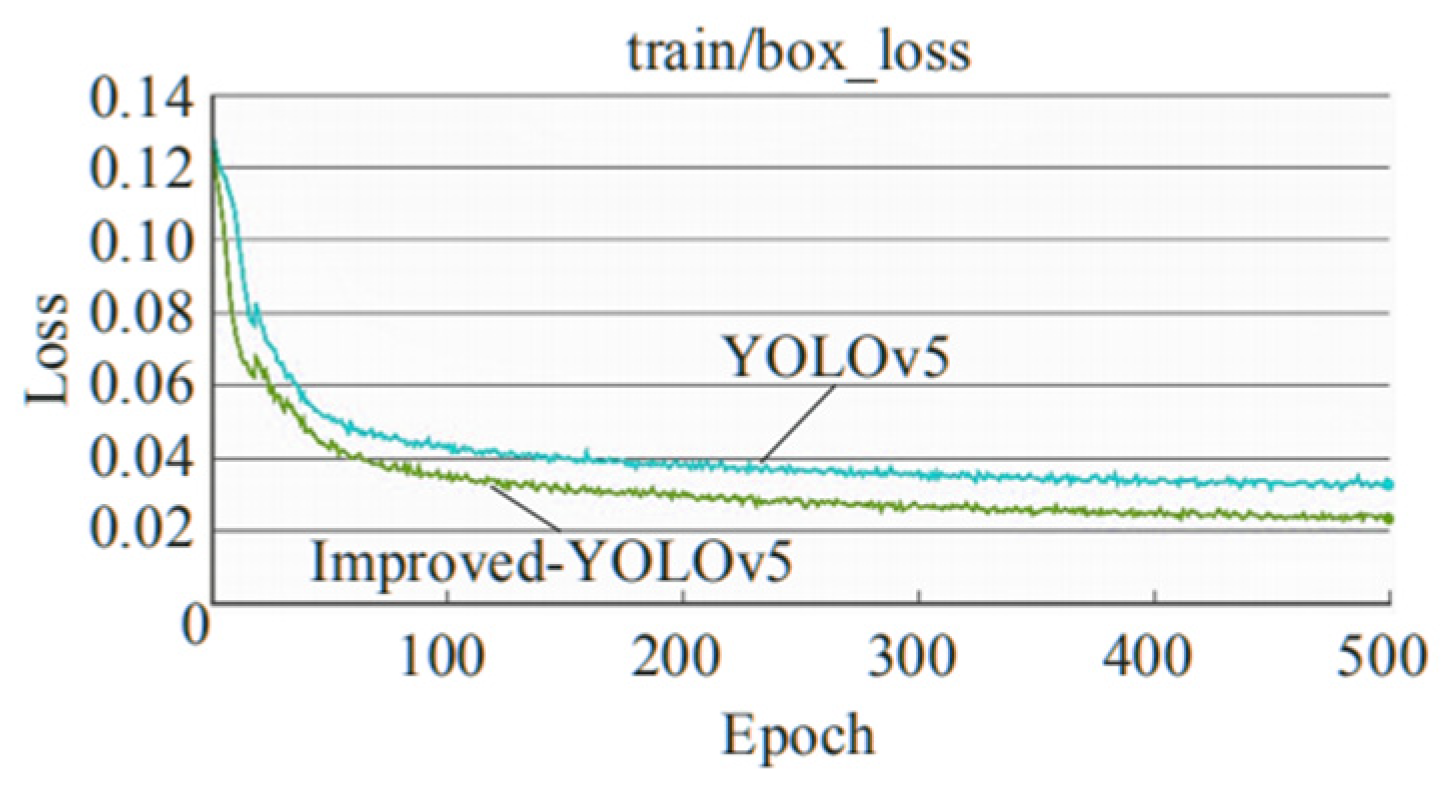
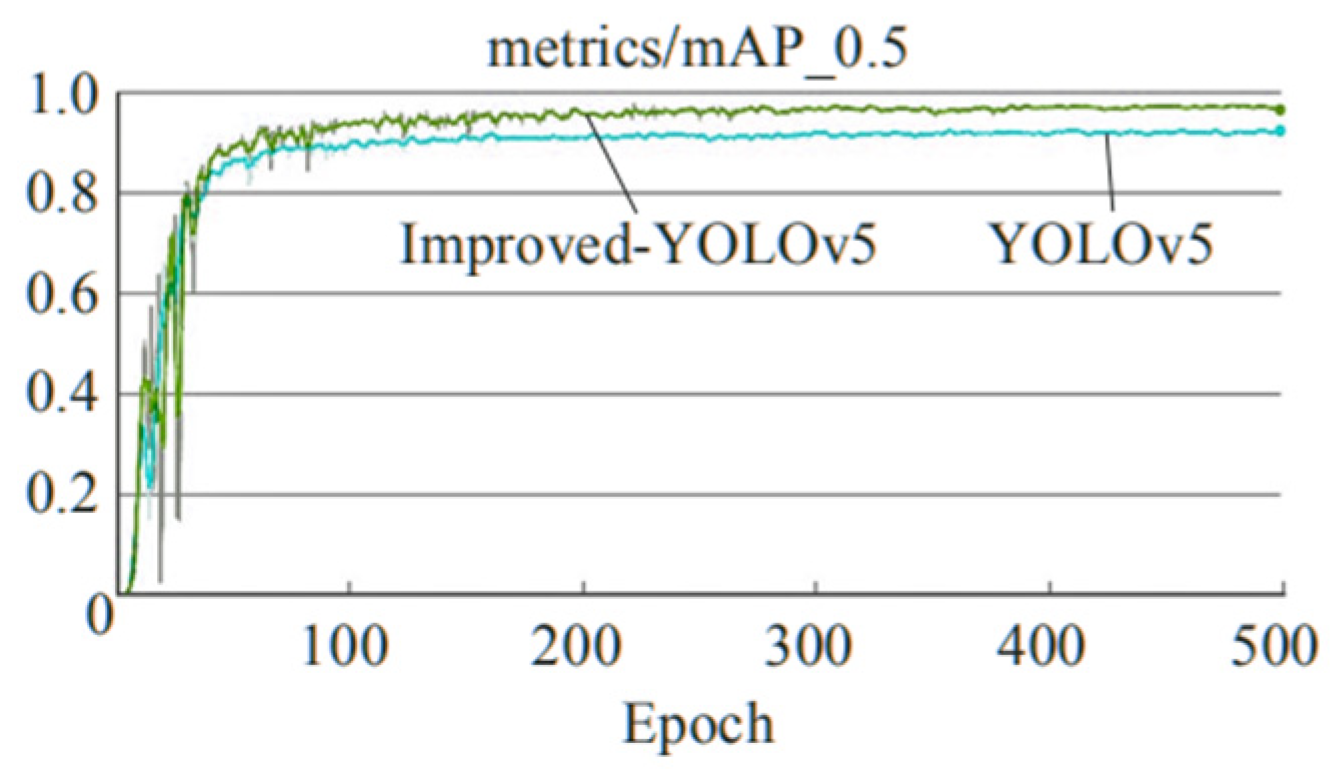
5.2. Pre-Training and Training Details
5.3. Robustness Testing
5.4. Algorithm Evaluation Indicators
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, C.; Wang, X.; Yang, Y. Attention YOLO: YOLO Detection Algorithm Introducing Attention Mechanism. Comput. Eng. Appl. 2019, 55, 13–23. [Google Scholar]
- Liu, X. Research on Image Object Detection Algorithm Based on YOLO Deep Learning Model. Comput. Program. Ski. Maint. 2022, 7, 131–134. [Google Scholar]
- Shuai, T.; Sun, K.; Wu, X.; Zhang, X.; Shi, B. A Ship Target Automatic Detection Method for High-resolution Remote Sensing. In Proceedings of the Geoscience & Remote Sensing Symposium, Beijing, China, 10–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1258–1261. [Google Scholar]
- Peng, D.; Ye, Z.; Ping, J. Ship Detection on Sea Surface Based on Multi-feature and Multi-scale Visual Attention. Opt. Precis. Eng. 2017, 25, 2461–2468. [Google Scholar] [CrossRef]
- Liu, Y.; Cui, H.; Li, G. A Novel Method for Ship Detection and Classification on Remote Sensing Images. In 2017 International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2017; pp. 556–564. [Google Scholar]
- Zhao, Q. Ship Target Recognition Research Based on Multi Physics Field Features; Harbin Institute of Technology: Harbin, China, 2017. [Google Scholar]
- Klepko, R. Classification of SAR Ship Images with Aid of a Syntactic Pattern Recognition Algorithm; Defence Research Establishment Ottawa: Ottawa, ON, Canada, 1991. [Google Scholar]
- Wang, B. Research on Deep Learning-Based Ship Detection; Xiamen University: Xiamen, China, 2017. [Google Scholar]
- Yuan, Y.; Jiang, Z.; Zhao, D. Ship Detection in Optical Remote Sensing Images based on Deep Convolutional Neural Networks. J. Appl. Remote Sens. 2017, 11, 135–149. [Google Scholar]
- Wang, T. Ship Detection Technology in High Resolusion Remote Sensing Image Using Deep Learning; Harbin Institute of Technology: Harbin, China, 2017. [Google Scholar]
- Liu, Y. Research on Ship Detection from High-Resolution Optical Remote Sensing Images; Xiamen University: Xiamen, China, 2017. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Reconstruction, Columbus, OH, USA, 23–28 June 2014; pp. 2117–2125. [Google Scholar]
- Yu, J.; Jia, Y. Improving YOLOv5’s Small Object Detection Algorithm. Comput. Eng. Appl. 2023, 59, 203–204. [Google Scholar]
- Xiao, J.J. Masked face detection and standard wearing mask recognition based on YOLOv3 and YCrCb. Comput. Eng. Softw. 2020, 41, 164–169. [Google Scholar]
- Huang, F.; Chen, M.; Feng, G. Improved YOLO object detection algorithm based on deformable convolutions. Comput. Eng. 2021, 47, 269–275. [Google Scholar]
- Song, Z.; Sui, H.; Li, Y. Overview of Ship Target Detection in High Resolution Visible Light Remote Sensing Images. J. Wuhan Univ. (Inf. Sci. Ed.) 2021, 11, 1703–1715. [Google Scholar]
- Wang, Q. Introduction to Deep Learning: Theory and Implementation Based on Python; People’s Posts and Telecommunications Press: Beijing, China, 2018. [Google Scholar]
- Xu, C.; Cheng, W.; Yang, Y. Basic Research on YOLO Object Detection Algorithms. Comput. Inf. Technol. 2020, 28, 45–47. [Google Scholar]
- Long, F.; Wang, Y. Introduction and Practice of Deep Learning; Tsinghua University Press: Beijing, China, 2017. [Google Scholar]
- Li, J.; Qu, C.; Peng, S.; Deng, B. SAR Image Ship Target Detection Based on Convolutional Neural Network. Syst. Eng. Electron. 2018, 40, 1953–1959. [Google Scholar]
- Yang, Y. Ship Target Detection and Classification Recognition Based on Deep Learning. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 2019. [Google Scholar]
- Yasuhiri, S. Introduction to Deep Learning Based on the Theory and Implementation of Python; China Industry and Information Technology Publishing Group: Beijing, China, 2021. [Google Scholar]
- Zhang, Y. Research on Intelligent Detection and Recognition of Ship Targets on the Sea Surface in Optical Images; University of Chinese Academy of Sciences: Beijing, China, 2021. [Google Scholar]
- Xu, Z.; Ding, Y. Ship target detection in remote sensing images using adaptive rotating region generation network. Prog. Laser Optoelectron. 2020, 57, 408–415. [Google Scholar]
- Liu, J.; Li, Z.; Zhang, X. Overview of Sea Surface Target Detection Technology in Visible Light Remote Sensing Images. Comput. Sci. 2020, 3, 116–123. [Google Scholar]
- Li, Q. Research on Target Detection Methods of Fast and Efficient Deep Neural Network. Master’s Thesis, Beijing Jiaotong University, Beijing, China, 2019. [Google Scholar]
- Ye, Q.; Zha, X.; Li, H. High resolution remote sensing image ship detection based on visual saliency. Ocean. Surv. Mapp. 2018, 38, 48–52. [Google Scholar]
- Yan, Y. Image Recognition of Deep Learning: Core Technology and Case Practice; China Machine Press: Beijing, China, 2019. [Google Scholar]
- Wang, Y.; Ma, L.; Tian, Y. Overview of Ship Target Detection and Recognition in Optical Remote Sensing Images. J. Autom. 2011, 9, 1029–1039. [Google Scholar]
- Zhao, H.; Wang, P.; Dong, C.; Shang, Y. Ship target detection based on multi-scale visual salliency. Opt. Precis. Eng. 2020, 6, 1395–1403. [Google Scholar] [CrossRef]
- Dong, C.; Liu, J.; Xu, F.; Wang, R. Rapid detection method for ship targets in optical remote sensing images. J. Jilin Univ. (Eng. Ed.) 2019, 49, 1369–1376. [Google Scholar]
- Sun, L.; Jiang, Y.; Wang, J.; Xiang, B. Pytorch Machine Learning from Introduction to Practice; China Machine Press: Beijing, China, 2019. [Google Scholar]
- Gai, S.; Bao, Z. High noise image denoising algorithm based on deep learning. J. Autom. 2020, 12, 2672–2680. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conf Threshold | Number of Detections | Number of Missed Detections | False Alarm Number | Test Set | Detection Rate | False Alarm Rate |
|---|---|---|---|---|---|---|
| 0.8 | 183 | 117 | 0 | Positive samples: 300 Negative samples: 29 | 61.0% | 0 |
| 0.7 | 236 | 64 | 2 | 78.7% | 6.9% | |
| 0.6 | 265 | 35 | 5 | 88.3% | 17.2% | |
| 0.5 | 292 | 8 | 9 | 97.3% | 31.0% |
| Iou Threshold | Number of Detections | Number of Missed Detections | False Alarm Number | Test Set | Detection Rate | False Alarm Rate |
|---|---|---|---|---|---|---|
| 0.6 | 274 | 26 | 11 | Positive samples: 300 Negative samples: 29 | 91.3% | 37.9% |
| 0.5 | 256 | 44 | 7 | 85.3% | 24.1% | |
| 0.4 | 215 | 85 | 3 | 71.7% | 10.3% | |
| 0.3 | 196 | 104 | 1 | 65.3% | 3.4% |
| Numbering | Algorithm Type | Detection Rate | False Alarm Rate |
|---|---|---|---|
| 1 | before optimization | 81.7% | 19.8% |
| 2 | after optimization | 83.5% | 11.2% |
| Name of the Ship | Training Set | Validation Set | Test Set | Number of Images |
|---|---|---|---|---|
| Nimitz class | 135 | 38 | 19 | 192 |
| Ticonderoga class | 273 | 78 | 39 | 390 |
| Zumwal class | 39 | 11 | 5 | 55 |
| Arleigh Burke class | 307 | 88 | 44 | 399 |
| Perry class | 41 | 12 | 6 | 59 |
| Independent class | 184 | 52 | 26 | 262 |
| Free class | 149 | 42 | 21 | 212 |
| Wasp class | 122 | 35 | 17 | 174 |
| San Antonio class | 118 | 34 | 17 | 169 |
| Total | 1368 | 390 | 194 | 1952 |
| Method | Recall | Precision | mAP |
|---|---|---|---|
| Faster R-CNN | 68.5% | 72.8% | 69.7% |
| SSD | 74.9% | 76.8% | 75.7% |
| YOLO v4 | 75.9% | 78.3% | 77.6% |
| YOLO v5 | 79.4% | 80.5% | 79.7% |
| Improved YOLO v5 | 80.1% | 82.7% | 81.4% |
| YOLO v7 | 79.6% | 81.2% | 80.1% |
| YOLO v8 | 80.1% | 82.1% | 80.9% |
| Category | TP | FP | Missed Detection | Total Samples | Recognition Rate |
|---|---|---|---|---|---|
| Nimitz class | 163 | 26 | 3 | 192 | 84.9% |
| Ticonderoga class | 348 | 27 | 15 | 390 | 89.2% |
| Zumwal Class | 39 | 11 | 5 | 55 | 70.9% |
| Arleigh Burke class | 360 | 22 | 17 | 399 | 90.2% |
| Perry class | 44 | 12 | 3 | 59 | 74.6% |
| Standalone level | 226 | 20 | 16 | 262 | 86.3% |
| Free class | 160 | 35 | 17 | 212 | 75.5% |
| Wasp class | 136 | 21 | 17 | 174 | 78.1% |
| San Antonio class | 118 | 26 | 15 | 169 | 69.8% |
| Total | 1594 | 200 | 108 | 1952 | 81.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Wu, H.; Yu, G.; Zheng, N. Research on the Automatic Detection of Ship Targets Based on an Improved YOLO v5 Algorithm and Model Optimization. Mathematics 2024, 12, 1714. https://doi.org/10.3390/math12111714
Sun X, Wu H, Yu G, Zheng N. Research on the Automatic Detection of Ship Targets Based on an Improved YOLO v5 Algorithm and Model Optimization. Mathematics. 2024; 12(11):1714. https://doi.org/10.3390/math12111714
Chicago/Turabian StyleSun, Xiaorui, Henan Wu, Guang Yu, and Nan Zheng. 2024. "Research on the Automatic Detection of Ship Targets Based on an Improved YOLO v5 Algorithm and Model Optimization" Mathematics 12, no. 11: 1714. https://doi.org/10.3390/math12111714
APA StyleSun, X., Wu, H., Yu, G., & Zheng, N. (2024). Research on the Automatic Detection of Ship Targets Based on an Improved YOLO v5 Algorithm and Model Optimization. Mathematics, 12(11), 1714. https://doi.org/10.3390/math12111714