Abstract
With the surge in cloud storage popularity, more individuals are choosing to store large amounts of data on remote cloud service providers (CSPs) to save local storage resources. However, users’ primary worries revolve around maintaining data integrity and authenticity. Consequently, several cloud auditing methods have emerged to address these concerns. Many of these approaches rely on traditional public-key cryptography systems or are grounded in identity-based cryptography systems or certificateless cryptography systems. However, they are vulnerable to the increased costs linked with certificate management, key escrow, or the significant expenses of establishing a secure channel, respectively. To counter these limitations, Li et al. introduced a certificate-based cloud auditing protocol (LZ22), notable for its minimal tag generation overhead. Nonetheless, this protocol exhibits certain security vulnerabilities. In this paper, we devise a counterfeiting technique that allows the CSP to produce a counterfeit data block with an identical tag to the original one. Our counterfeiting method boasts a 100% success rate ∀ data block and operates with exceptional efficiency. The counterfeiting process for a single block of 10 kB, 50 kB, and 100 kB takes a maximum of 0.08 s, 0.51 s, and 1.04 s, respectively. By substituting the exponential component of homomorphic verifiable tags (HVTs) with non-public random elements, we formulate a secure certificate-based cloud auditing protocol. In comparison to the LZ22 protocol, the average tag generation overhead of our proposed protocol is reduced by 6.80%, 13.78%, and 8.66% for data sizes of 10 kB, 50 kB, and 100 kB, respectively. However, the auditing overhead of our proposed protocol shows an increase. The average overhead rises by 3.05%, 0.17%, and 0.45% over the LZ22 protocol’s overhead for data sizes of 10 kB, 50 kB, and 100 kB, correspondingly.
Keywords:
certificate-based cryptography; cloud auditing protocol; data integrity auditing; homomorphic verifiable tags (HVTs); forgery method MSC:
68P27
1. Introduction
In recent times, as wireless sensor technology advances continuously, the integration of wireless sensor technique with implantable medical electronic devices has progressively supplanted traditional portable medical devices as a focal point in global medical research and development [1]. In contrast to conventional portable medical electronic devices, implantable medical devices exhibit greater flexibility and convenience in appearance and usage. They can provide real-time health monitoring and even predict diseases. Implantable medical devices necessitate a simple chip implantation procedure within the body. Whether it involves monitoring diverse health metrics or restoring bodily functions, implantable chips offer enhanced ease, speed, accuracy, and cost efficiency. The utilization of implantable medical sensors enables users to monitor their health anytime, anywhere, thereby enhancing the efficient allocation of hospital resources to some extent.
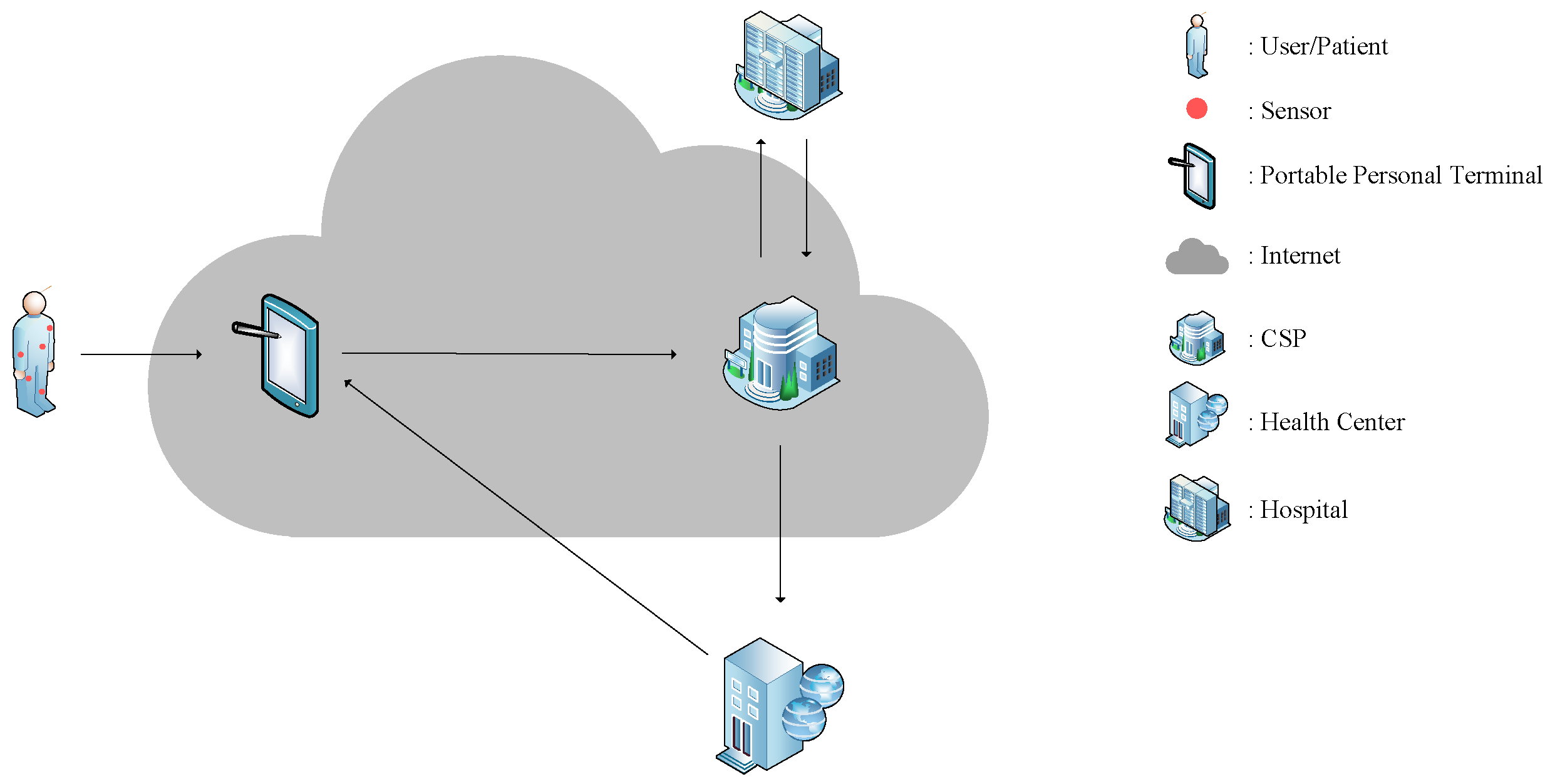
Nevertheless, the escalating volume of health monitoring data poses challenges in terms of data storage, potentially reducing the efficiency of medical sensors. This challenge can be mitigated by cloud service providers (CSPs) equipped with robust computational capabilities and ample storage resources. The operational framework of a typical medical sensor network is depicted in Figure 1. Initially, medical sensors gather health data from users regularly, which are then transmitted via the Internet to the CSP through associated mobile Portable Personal Terminals (e.g., smartphones, smart wristbands). Subsequently, the Health Center can analyze these health data and provide feedback to users, while hospitals can leverage the monitoring data within the CSP to gain precise insights into a patient’s condition and upload diagnosis outcomes to the CSP.
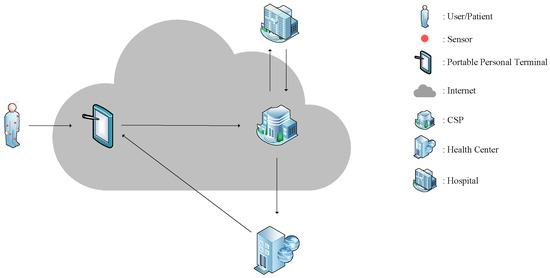
Figure 1.
The operation of a typical medical sensor network.
However, as concerns about privacy protection continue to grow, two major issues have arisen regarding the choice of CSPs for data storage outsourcing. One concern relates to potential data leakage by the CSP, while the other focuses on ensuring the integrity of data stored within the CSP. Consequently, safeguarding the privacy and integrity of health data within CSPs is crucial for users. Data encryption technology is widely recognized as a pivotal tool for preserving data privacy, involving the encryption of data locally before transferring it to the CSP. Furthermore, data auditing techniques play a crucial role in verifying the integrity of data stored within a CSP. This method entails issuing an audit challenge to the CSP to evaluate its ability to accurately respond to the challenge, thereby ensuring data integrity.
Therefore, the data storage outsourcing capability provided by CSPs effectively addresses the challenge of overloaded local storage for wireless sensors. By utilizing outsourced storage integrated with data encryption and auditing technologies, users can ensure the privacy and integrity of their data.
1.1. Related Works
With the swift progress in wireless communication technology, wireless sensor technology has become a focal point of investigation. The small size, minimal energy consumption, and scalability of wireless sensors have established them as the preferred option for IoT applications, such as electronic medical health monitoring. Due to the limited computing and storage capacities of wireless sensors, they frequently collaborate with CSPs to securely store encrypted data in the cloud. As a result, the attention on ensuring data integrity within CSPs has significantly increased in recent years in the domain of outsourced storage security protection research.
Homomorphic encryption [2,3,4,5] enables cryptographic computing, providing secure calculations with guaranteed confidentiality, making it a significant research focus in cloud computing. However, homomorphic encryption does not ensure the integrity of the calculation process.
Some data integrity-checking protocols were proposed between 2004 and 2006 [6,7,8]. However, all of these protocols required downloading the complete data file to check the integrity of the data. This took up a lot of communication overhead, which was not practical in the era of big data with huge data volumes.
The initial introduction of the Provable Data Possession (PDP) model by Ateniese et al. in 2007 [9] marked a significant milestone. This model utilized homomorphic verifiable tags (HVTs) and random sampling methods to empower users to authenticate remote data integrity with a high level of certainty. However, the computational and storage resources demanded by the protocol were substantial due to the homomorphic nature of the RSA cryptosystem on which the HVTs were founded. In 2008, Shacham et al. led the way in integrating a third-party auditor (TPA) into the model for validating remote data integrity [10]. By delegating the verification to a TPA, the protocol alleviated the verification burden on users. By employing BLS signatures [11] to create HVTs, this protocol generated shorter tags compared to the method proposed by [9]. Nonetheless, the length of these HVTs still exceeded that of the data block itself, resulting in a storage overhead for the CSP that surpassed that of the data block.
Subsequently, in order to cater to diverse user needs and reduce the computational and storage overhead of the protocol, scholars developed a range of third-party cloud auditing protocols based on various cryptographic systems. Initially, numerous researchers devised third-party cloud auditing protocols [9,10,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26] grounded in the Public Key Infrastructure (PKI) cryptosystem [27]. While PKI-based protocols are widely used, the substantial certificate management burden associated with them cannot be ignored. To tackle this challenge, other researchers suggested protocols [28,29,30,31,32,33,34,35,36,37,38,39,40,41] based on the identity (ID) cryptosystem [42]. In the ID cryptosystem, the Private Key Generator (PKG) only needs to generate and retain the private key corresponding to the user’s , leading to reduced storage overhead compared to the PKI-based protocols. However, the susceptibility of PKG to hacking and private key theft poses a challenge, rendering ID-based auditing protocols vulnerable to private key escrow attacks. To streamline key management and mitigate key escrow vulnerabilities, researchers have also proposed cloud auditing protocols [43,44,45,46,47,48] based on the certificateless cryptosystem [49]. These protocols prevent the exposure of the private key by distributing the key generation process between the Key Generation Center (KGC) and the user, thereby addressing the key escrow issue. However, establishing a trusted channel for transmitting part of the private key between KGC and users presents a communication overhead challenge in the certificateless cryptosystem.
To resolve the issue of communication overhead in certificate-less cryptosystems, Gentry introduced the certificate-based cryptosystem in 2003 [50]. The certificate-based cryptosystem eliminated the necessity to establish a trusted channel for each user; the certificate distribution could occur in the open channel, reducing the communication overhead resulting from establishing a trusted channel. Building upon the certificate-based cryptosystem, Ref. [51] devised an efficient third-party cloud auditing protocol. This protocol reduced the computational cost on both the user and the TPA sides compared to the aforementioned protocols by cleverly constructing the HVTs. Nonetheless, this protocol did raise some security concerns.
1.2. Our Contributions
In this paper, we design a third-party cloud auditing protocol that leveraged secure certificates to address the susceptibility of encrypted data blocks to forgery within the LZ22 protocol [51]. Our contributions are detailed below.
To begin, we devise a method for generating forged data blocks with identical tags to the original ones. This technique is capable of forging lost data blocks, enabling the successful completion of TPA challenges in cases where the user’s data block is missing due to CSP errors. Our forgery approach boasts a 100% success rate ∀ data block. Furthermore, we conduct simulation experiments to evaluate the computational overhead associated with forgery for data sizes of 10 kB, 50 kB, and 100 kB. The results demonstrate that the computational overhead for forgery is remarkably minimal, with a maximum forging time of 1.04 s per data block.
Subsequently, we develop a robust certificate-based data integrity auditing protocol to resolve the security issues present in the LZ22 protocol. By reconfiguring the homomorphic verifiable tags (HVTs) and integrating these enhanced HVTs into our cloud auditing protocols, we enhance the security of our protocol significantly. A comprehensive overview of our protocol is provided, along with an in-depth analysis of its correctness and security aspects.
Lastly, we validate the practicality and efficiency of our protocol through experimental assessments. By simulating the time overhead of Tag Generation and Auditing for various auditing protocols, including the latest PKI auditing protocol [26], ID-based auditing protocol [30], certificateless auditing protocol [46], certificate-based auditing protocol [51], and our auditing protocol, we demonstrate the superior efficiency of our protocol in Tag Generation compared to the other protocols. Additionally, our auditing efficiency matches that of the auditing protocol proposed by [51], ensuring a high level of security while maintaining operational efficiency.
1.3. Outline of the Article
The overall structure of the remaining sections in this article is outlined as follows. In Section 2, we present pertinent background information regarding the Certificate-Based Data Integrity Auditing Protocol (CBDIAP). Subsequently, in Section 3, we delve into the security vulnerabilities of the LZ22 protocol and put forth a potential forgery attack strategy. Moving on to Section 4, we introduce and scrutinize the protocol proposed in this paper, conducting both correctness and security analyses. Subsequently, in Section 5, we evaluate the overhead associated with Tag Generation and Auditing for the proposed protocol through theoretical and experimental assessments. Finally, we encapsulate the key findings and delineate future research avenues in Section 6.
2. Preliminaries
In this section, we introduce some basic knowledge, including symmetric bilinear mapping, security assumptions, and the formal definition of the CBDIAP. The details are as follows.
2.1. Symmetric Bilinear Mapping
The concept of symmetric bilinear mapping was first introduced by John Milnor, and Dale Husemoller et al. in 1973 in their published book Symmetric Bilinear Forms [52]. The details are as follows.
Choose two cyclic groups . Suppose , and there exists a mapping satisfying the following properties:
- Bilinear: , such that .
- Nondegeneracy: if g is the generator of , such that ( is the identity element in the group ) is the generator of .
- Computability: , such that can be calculated efficiently.
2.2. Security Assumptions
Definition 1
(k-Collusion Attack Algorithm Problem (k-CAA) Assumption [53]). In a cyclic group with order p where p is prime, ∀ and , given and pairs , the task is to output a new pair where . The k-CAA assumption is deemed valid under if there exists no probabilistic polynomial time (PPT) algorithm that can generate in with a success rate of at least ε.
Definition 2
(Weak k-CAA Problem Assumption [54]). In a cyclic group with order p where p is prime, ∀ and , given , and pairs , the objective is to output a new pair or solve where . The weak k-CAA assumption is considered valid under if there exists no PPT algorithm that can generate or solve in with a success rate of at least ε.
Definition 3
(Computational Diffie–Hellman Problem (CDH) Assumption [11]). In a cyclic group with order p where p is prime, ∀ and , given , the aim is to solve . The CDH assumption is considered valid under if there exists no PPT algorithm that can solve in with a success rate of at least ε.
2.3. The Formal Definition of the CBDIAP
The CBDIAP is a third-party data integrity auditing protocol that relies on certificate-based cryptographic systems. The protocol involves three key entities: the CSP, TPA, and user, each with distinct responsibilities. The CSP is tasked with system initialization, user certificate distribution, and encrypted data block storage. On the other hand, the TPA’s role is to audit the CSP to guarantee the integrity of the data stored within it. The formal specification of this protocol can be found in Definition 4.
Definition 4.
The CBDIAP consists of four PPT algorithms [51]:
- 1.
- System setup with input security parameter λ, CSP initializes the data integrity auditing system to generate the system master private key and broadcast the system parameters .
- 2.
- User registration The user sends their and public key to the CSP. Then, the CSP returns a valid certificate to the user.
- 3.
- Outsourcing storage Given an encrypted dataset named , timestamp t, the user uploads the encrypted dataset , the dataset label τ, and the data block tags to the CSP.
- 4.
- Auditing (0/1): The TPA sends the user’s , , and the audit challenge to the CSP. The CSP generates a Data Integrity Proof to be returned to the TPA. The TPA output is one, which proves that the data are intact on the CSP, or, conversely, outputs zero.
2.3.1. Correctness
Definition 5.
If the CBDIAP is correct, the following conditions need to be met [51]:
- 1.
- For the certificate returned by the CSP, the user must verify that the certificate sent by the CSP matches his or her own and to check whether the certificate is valid.
- 2.
- , if the CSP received from the TPA, the CSP can generate . Then, the CSP sends PF to the TPA. Finally, the TPA checks whether the matches the dataset label τ and checks whether the is evidence of the dataset .
- 3.
- For , the TPA checks the integrity of the data in the CSP by testing whether and match.
2.3.2. Security Model
In the CBDIAP, the forgery of adversary is said to be successful if the forged can pass the auditing algorithm, and the forged dataset with arbitrary data block is not interrogated.
Definition 6.
If the probability that any PPT adversary can win the following game is negligible, then we consider CBDIAP secure.
Initialization: challenger generates system parameters and system master private key , stores the itself, and sends the to adversary .
TagGen query: Adversary sends the user’s , the encrypted dataset named , and the corresponding timestamp t to challenger . Then, returns the corresponding dataset label and all the data block tags to .
ProofCheck query: ∀ dataset, sends to , generates the corresponding .
Forge: generates , where corresponds to an unvisited dataset, i.e., none of the data blocks in the new dataset have undergone the TagGen query process.
3. Data Block Forgery of LZ22 Protocol
First, we analyze the security problems of the LZ22 protocol in the outsourcing storage process in detail and propose our forgery method. Then, we experimentally analyze the time overhead required for forgery.
3.1. Security Problems of LZ22
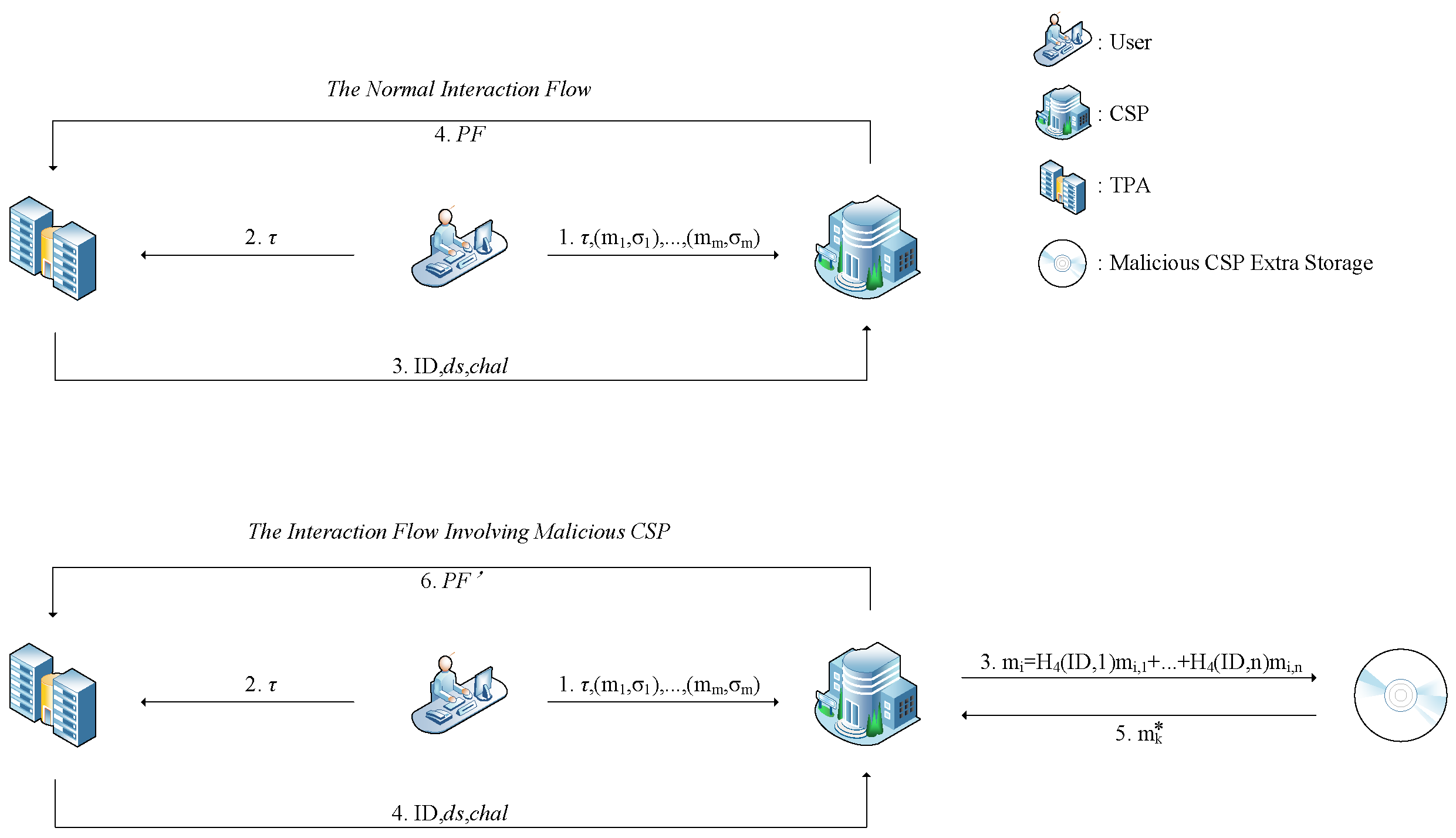
In reality, a secure cloud auditing protocol requires that the CSP cannot generate a valid attestation without having the complete raw data [55]. Here, we first assume that the TPA needs to audit the integrity of an encrypted dataset with identity ID and dataset name . Then, after the CSP receives the audit challenge from the TPA, it generates a valid proof , where , . At this point, if the CSP is still able to generate a proof that can be verified despite the loss of a data block , then this cloud auditing protocol is unsafe.
In the LZ22 protocol [51], the data block has a tag . For each data block , the CSP can pre-determine an intermediate value for tag and store in the CSP. In this way, when a certain data block is lost, the CSP can forge a data block . As long as , then the forged data block has the same tag as the real data block . In this way, the CSP can send a proof , where . We verify the algorithm by substituting into the Equation (1):
That is, the proof returned by the CSP to the TPA can pass the verification. Since data block is forged by the CSP, the LZ22 protocol is not secure.
Below, we consider specifically how to construct the data block such that . Since are all values that can be calculated by the CSP, can be chosen arbitrarily. It is sufficient that holds, at which point holds. An extreme case is to make , hold, when . From the analysis, it is clear that the forging success rate of our proposed method for forging data blocks is 100%.
Note that this method of masking data loss by the CSP requires an additional value to be computed for each data block when storing the user dataset, and thus the CSP needs to prepare an additional of the original dataset size of the storage space for storing . Figure 2 compares the difference between the legitimate CSP and the dishonest CSP in the auditing phase.
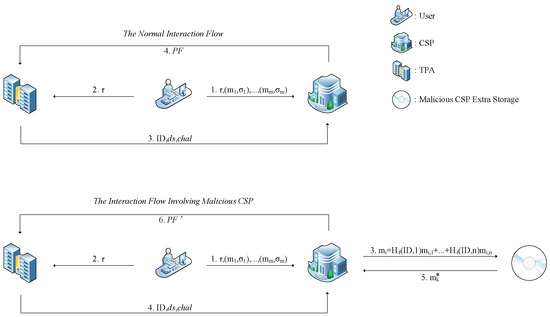
Figure 2.
The difference between the legitimate CSP and the dishonest CSP.
3.2. Data Block Forgery Experiments
In this section, we delve into the time overhead associated with the CSP’s ability to counterfeit a data block. Given that the data block targeted for forgery shares an identical tag with the authentic data block , there is no necessity to fabricate the tag .
Our simulation used the Pycharm IDE, with the compiler version being Python 3.8. Our simulation ran on a Linux 5.10.0-8-generic system, using the 11th Gen Intel (R) Core (TM) i7-11800H @ 2.30-GHz processor. The parameters used in the simulation were all standard parameters of the Pypbc library [56]. To design an 80-bit secure auditing algorithm, the length of any element in the group needed 160 bits (20 bytes). We analyzed the time overhead required for forgery with dataset sizes of 10 kB, 50 kB, and 100 kB, respectively.
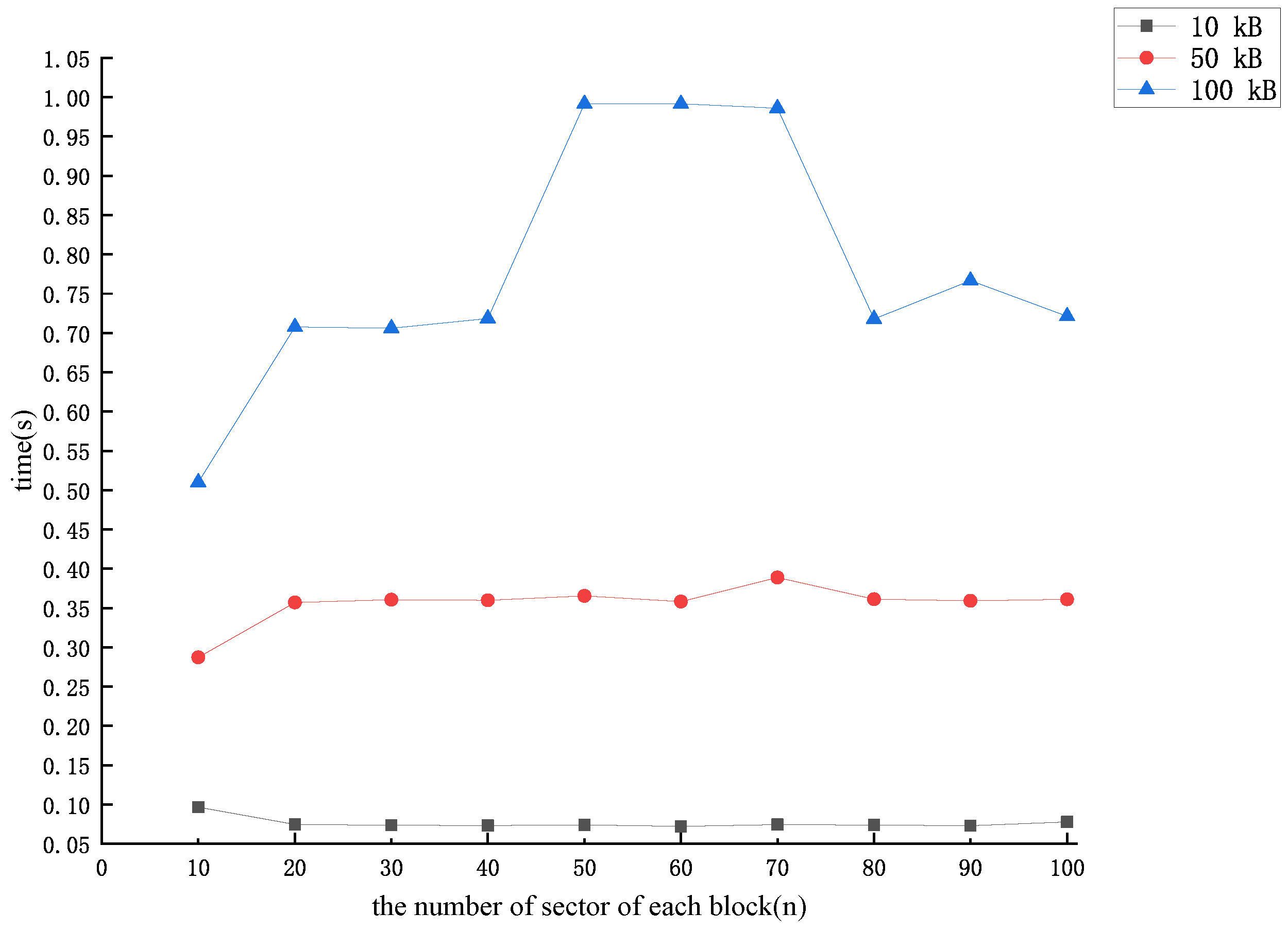
In the data block forgery method proposed in the previous section, the CSP needs to additionally compute a value for each data block and store locally after receiving the dataset uploaded by the user. After an experimental simulation, we concluded that the time overhead required by the CSP to compute each was related to the number of sector n in each data block as shown in Figure 3.
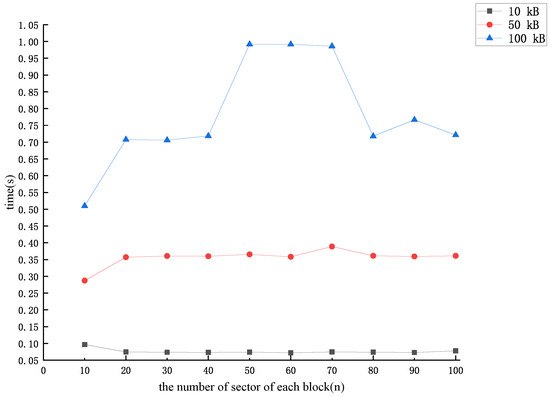
Figure 3.
The time cost of computing intermediate value .
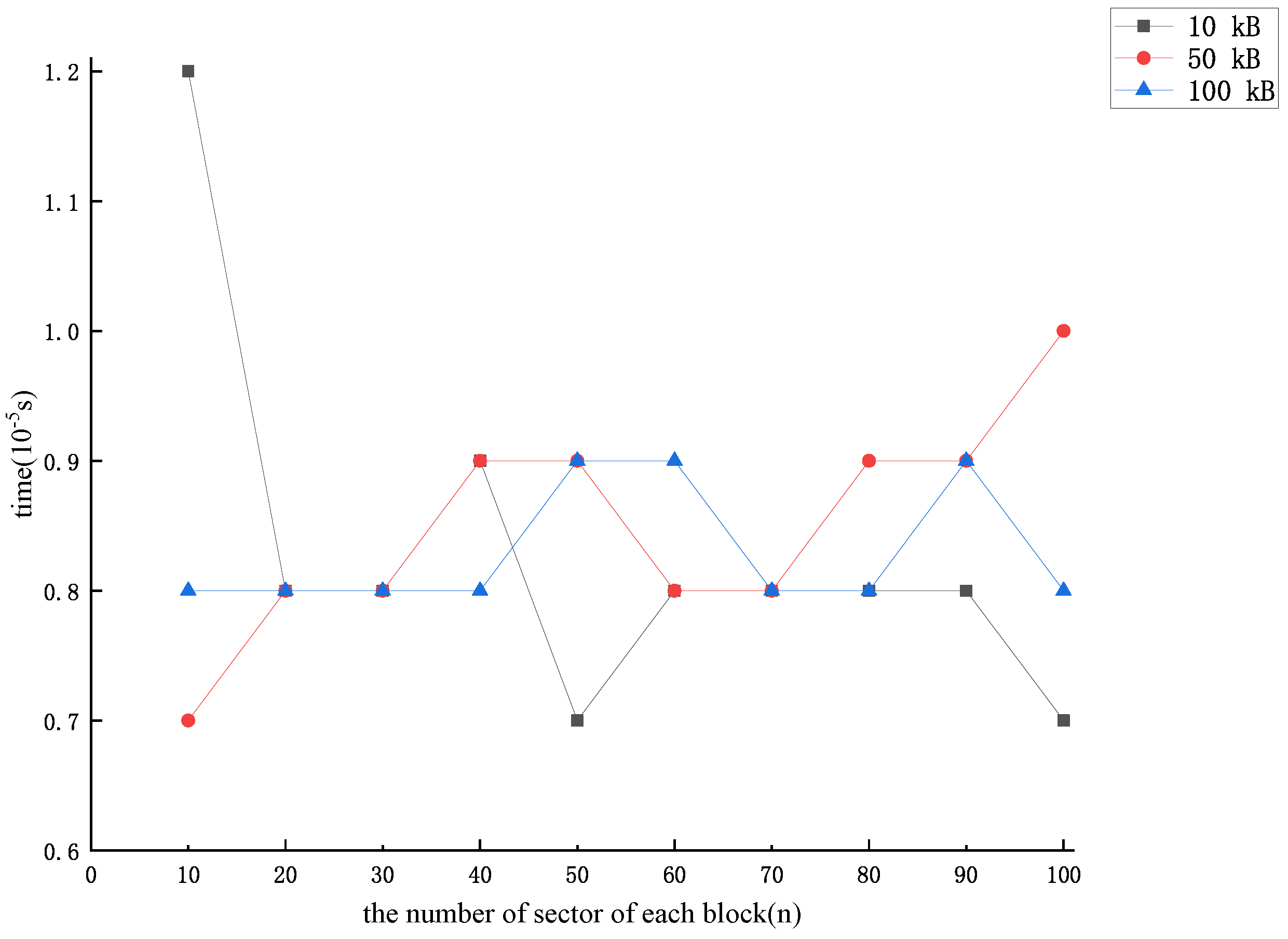
After the CSP receives an audit challenge from the TPA, if it finds that a block of data is missing, it can then forge a block of data using the previously stored value . The forgery method that minimizes the time overhead is to make , and obtain . When the number of missing data blocks is more than one, the same method can be used to forge the other missing data blocks. We derived the time required by the forgery method with the lowest overhead for the CSP forgery of each related to the number of sector n in each data block as shown in Figure 4.
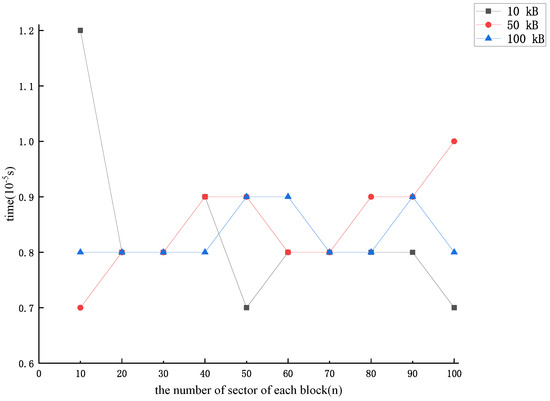
Figure 4.
The lowest time cost of forging each data block .
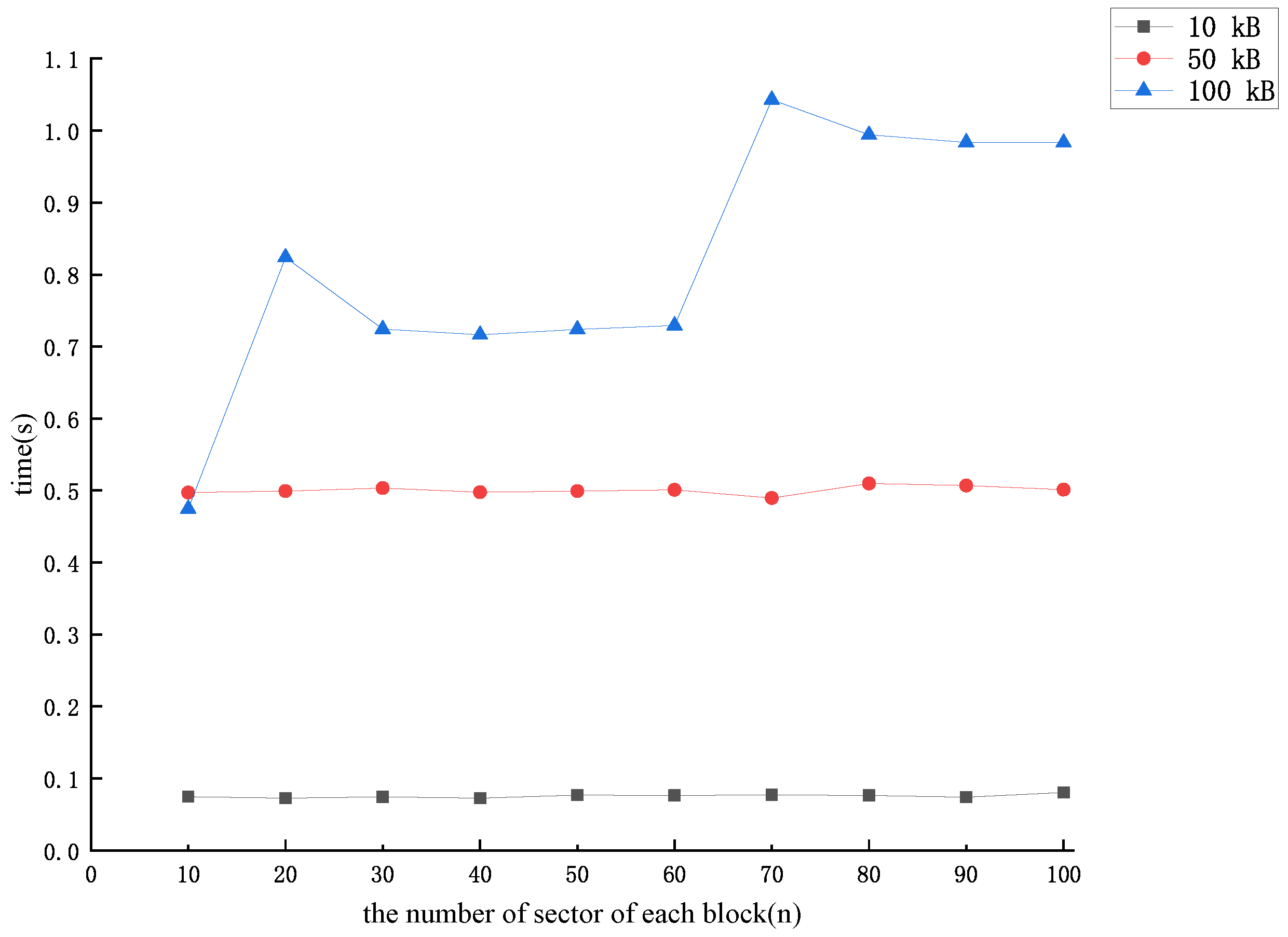
To make the forged data block look more real, the values of can be assigned one by one by the CSP according to the numerical characteristics of the existing data block, as long as the last element of the forged data block satisfies . At this point, , and the forgery process will require a greater amount of calculation. When the number of missing data blocks is more than one, the same method can be used to forge the other missing data blocks. The time required for the CSP to forge each more realistic versus the number of sector n in each data block is shown in Figure 5.
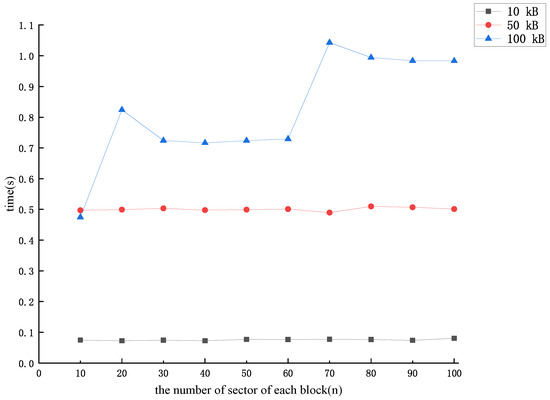
Figure 5.
The time cost of forging each more realistic data block .
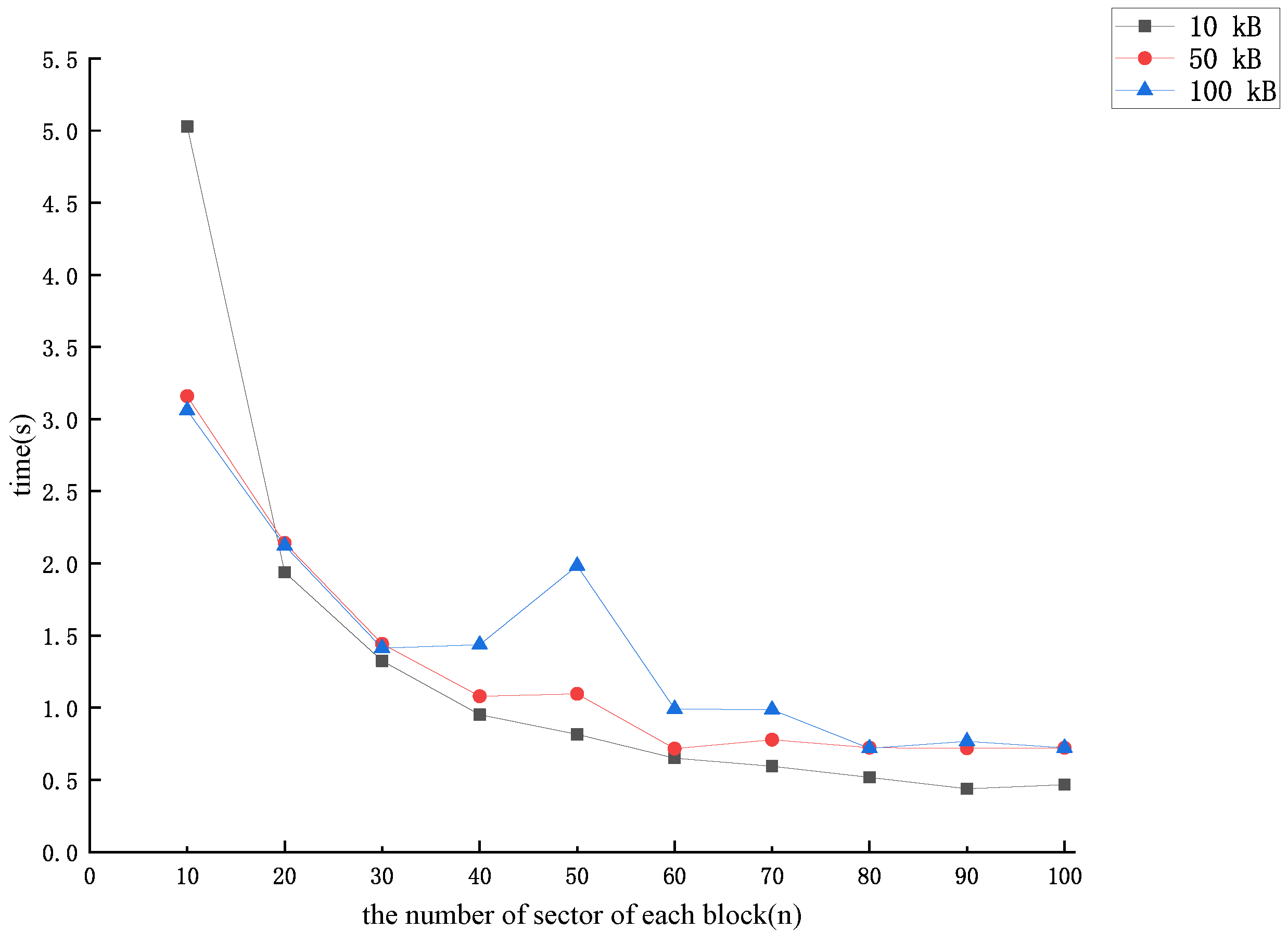
In the following, we analyze the total time overhead required for CSPs to forge data blocks in the LZ22 protocol using the forgery method proposed in this paper. First, for a given encrypted dataset , the CSP needs to compute an extra value for each data block . Then, the CSP forges the lost data block through the challenge. If the CSP uses the lowest overhead forgery method, the number of sectors n for each data block versus the total time overhead is shown in Figure 6. If the CSP uses a more realistic forgery method, the number of sectors n of each data block versus the total time overhead is shown in Figure 7.
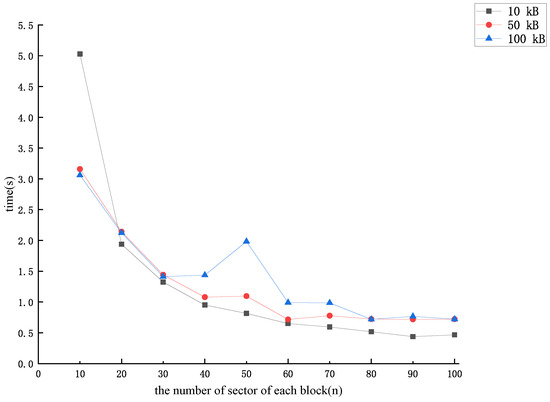
Figure 6.
The total time cost of forging each data block (lowest overhead forgery method).
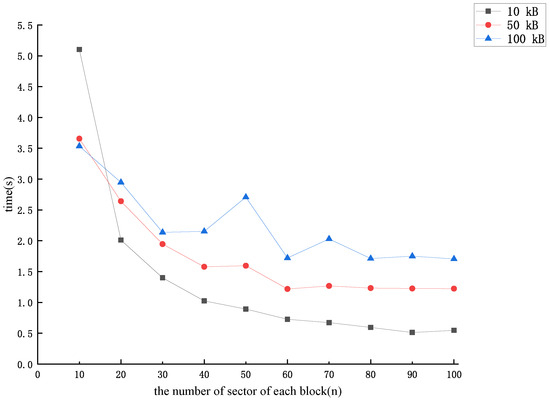
Figure 7.
The total time cost of forging each data block (more realistic forgery method).
From Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7, we can see that the time overhead of our forgery method is minimal. With sufficient storage resources (i.e., sufficient storage space to store the intermediate value ), the CSP needs at most 1.1 s to forge a lost data block and pass the audit challenge. Otherwise, even if auditing is required during the user outsourcing storage process (i.e., the CSP needs to calculate the intermediate value and forge the missing data block at the same time), it takes at most 5.5 s for the CSP to be able to complete the forgery of a particular missing data block and pass the auditing challenge.
4. The Proposed Protocol
In this section, we introduce an enhanced protocol designed to address the security vulnerabilities present in the LZ22 protocol. Subsequently, a comprehensive analysis of the correctness of our protocol is conducted. Finally, we provide a rigorous proof of the security guarantees offered by our proposed protocol.
4.1. Concrete Structure
From Section 3, it is clear that the encrypted data block stored by the CSP in the LZ22 protocol can be forged with 100% probability. In our protocol, we make it impossible for the attacker to calculate the exponential part of by changing the function of tag in the LZ22 protocol to pick n random numbers , which makes it impossible to forge any data block. The specific details of our protocol are as follows.
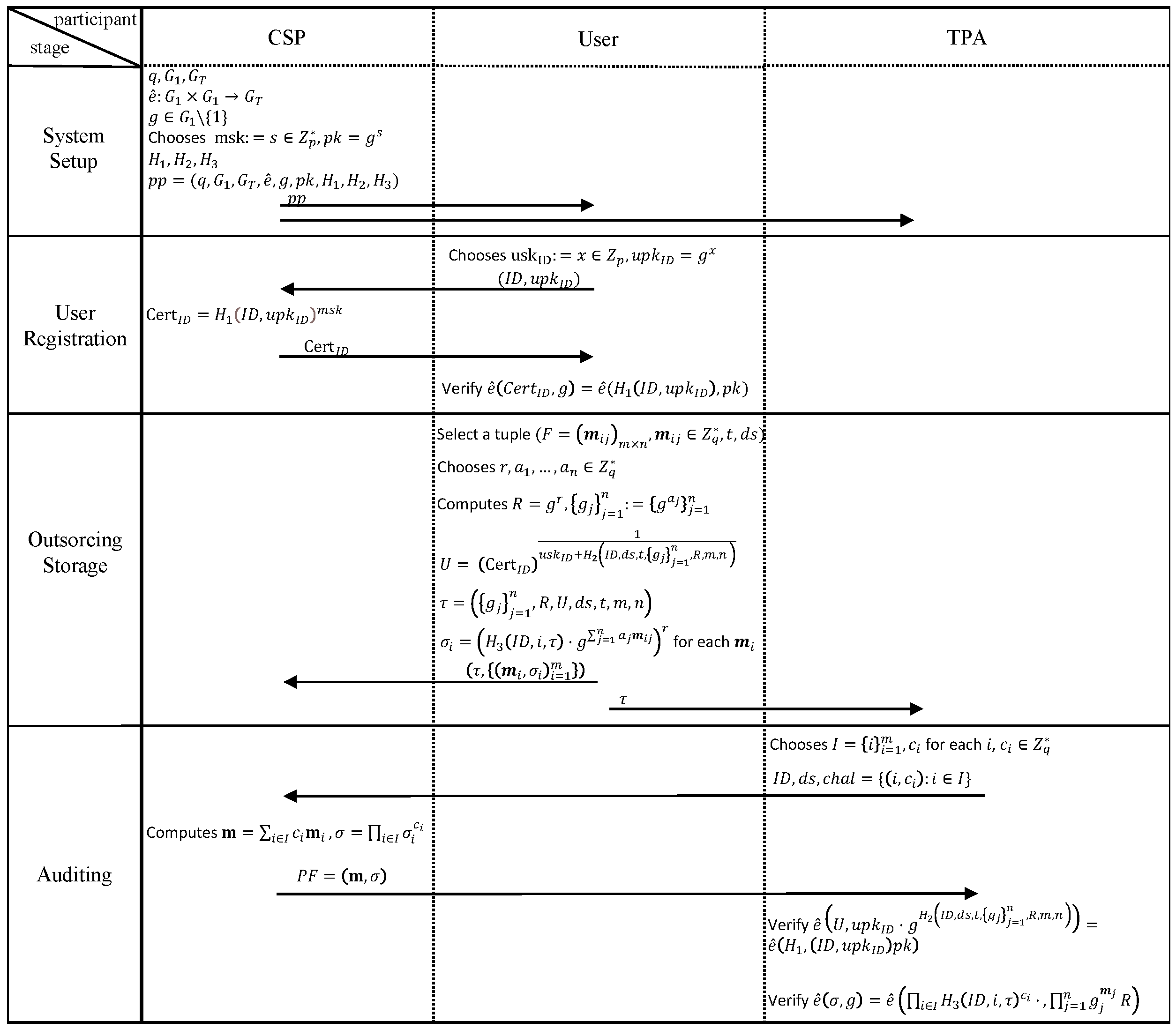
The proposed protocol comprises four algorithms illustrated in Figure 8. Initially, the system setup algorithm is executed by the CSP to generate initialization parameters . Then, the CSP sends to the user and TPA. Subsequently, in the user registration algorithm, the user creates and transmits it to the CSP. The CSP then responds by sending to the user. Then, the user verifies the legitimacy of the certificate. Following this, the outsourcing storage algorithm is activated by the user, tasked with labeling encrypted datasets and transmitting to the CSP and to the TPA. Lastly, the auditing algorithm is initiated by the TPA, responsible for issuing audit challenges to the CSP to verify the integrity of the stored data. Upon receiving an audit challenge from the TPA, the CSP must present the necessary proof of integrity () to the TPA for assessment in order to verify the data integrity. A detailed description of each algorithm is provided below.
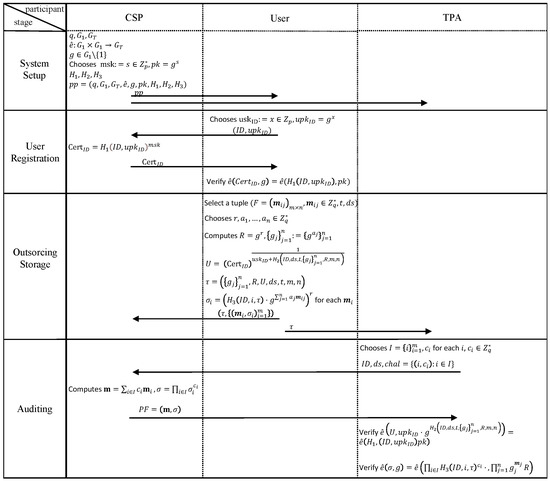
Figure 8.
Flowchart of the proposed protocol.
4.1.1. System Setup
Input security parameter ; then, the CSP randomly selects the cyclic group of order prime q, and the symmetric bilinear mapping . Then, the CSP randomly selects the generator element and an integer to compute the master public key . Then, the CSP randomly selects three collision-resistant hash functions: , , . Finally, the CSP announces the above system public parameter and sets s as the system master key .
4.1.2. User Registration
The user registration algorithm is divided into three phases: UserKeyGen, certify, and authentication.
- UserKeyGen: the user randomly chooses as secret key , computes the user public key as , and then sends and to CSP.
- Certify: The CSP generates certificate and sends it to the user.
- Authentication: The user verifies the legitimacy of the certificate through equation .
4.1.3. Outsourcing Storage
The outsourcing storage algorithm is divided into two phases: data processing and data uploading.
- Data processing:
- (1)
- Given an encrypted dataset with timestamp t and dataset name , the user initially divides the dataset F into m data blocks , each comprising n sectors. Specifically, , where .
- (2)
- The user then randomly selects , calculates , and . The user assigns the label of dataset F and retains .
- (3)
- For each data block , the user computes the corresponding tag into Equation (2):
- Data uploading: The user uploads dataset label , data blocks , and corresponding tags to the CSP. At the same time, the user sends dataset label to the TPA.
4.1.4. Auditing
In the Auditing algorithm, three distinct phases, namely challenge, proof generation, and proof verification, are delineated for execution.
- Challenge: The TPA randomly selects a non-empty subset I with element . For each i, the TPA randomly chooses . Subsequently, the TPA transmits the user , dataset name and challenge to the CSP.
- Proof generation: Upon reception of , the CSP computes and in Equation (3):Subsequently, the CSP sends back to the TPA.
- Proof verification: Upon receipt of , the TPA initially verifies the validity of the label using Equation (4).
4.2. Correctness
According to Definition 5, in this section, we verify the correctness of the proposed protocol in terms of certificate validity, legitimacy of dataset label , and data integrity verification. To verify the correctness of the proposed protocol, we assume that all participants in this section faithfully execute the proposed protocol.
4.2.1. Certificate Validity
Claim 1.
is constant holds.
Proof.
□
4.2.2. Legitimacy of Dataset Label
Claim 2.
,
is constant holds. (here we let ).
Proof.
□
4.2.3. Data Integrity Verification
Claim 3.
, is constant holds.
Proof.
□
4.3. Security Analysis
In our proposed protocol, following Definitions 1–3, we delineate three classes of PPT algorithmic adversaries. Adversary simulates an eavesdropper with the ability to substitute the of the user yet lacks access to . On the other hand, adversary behaves like a malicious CSP possessing knowledge of but lacking the capability to alter . Lastly, adversary replicates a compromised CSP with the capacity to fabricate but without the ability to retrieve the user’s randomly generated . None of the three adversaries, , , and , have privileges to access , or . The security guarantees of our protocol are substantiated by Theorems 1–3.
Theorem 1.
Assuming the weak k-CAA problem assumption holds in , it is infeasible ∀ PPT adversary to generate a valid proof with a significant advantage .
Proof.
The detailed proof is elaborated in Appendix A. □
Theorem 2.
Given the k-CAA assumption in , no PPT adversary can counterfeit a valid proof with a non-negligible advantage .
Proof.
The thorough proof is accessible in Appendix B. □
Theorem 3.
In the scenario where the CDH assumption holds in , it is computationally infeasible ∀ PPT adversary to generate a valid proof with a notable advantage .
Proof.
The detailed proof can be found in Appendix C. □
5. Performance Analysis
In this section, we conduct a theoretical analysis of the computational complexity associated with Tag Generation and Auditing in various cryptographic protocols, including those proposed by Han et al. [26], Li et al. [30], Shen et al. [46], Li et al. [51], and the protocol presented in this work. Then, we also experimentally simulate these two properties. The specific theoretical and experimental analyses are as follows.
5.1. Analysis of Theoretical Effectiveness
We provide the operational notations in Table 1. The theoretical analysis outcomes of the above protocols are presented in Table 2.

Table 1.
Notations.
Table 2.
Theoretical analysis.
5.2. Analysis of Experimental Simulations
In this section, we present the results of the experimental simulations conducted to evaluate the computational costs associated with Tag Generation and Auditing in various protocols, including the above five protocols. The simulations were performed using the PyCharm IDE with Python 3.8 compiler version. The experiments were conducted on a Linux 5.10.0-8-generic system equipped with an 11th Gen Intel Core i7-11800H @ 2.30-GHz processor. For the design of an 80-bit secure auditing protocol, each element in the group was required to have a length of 160 bits (20 bytes).
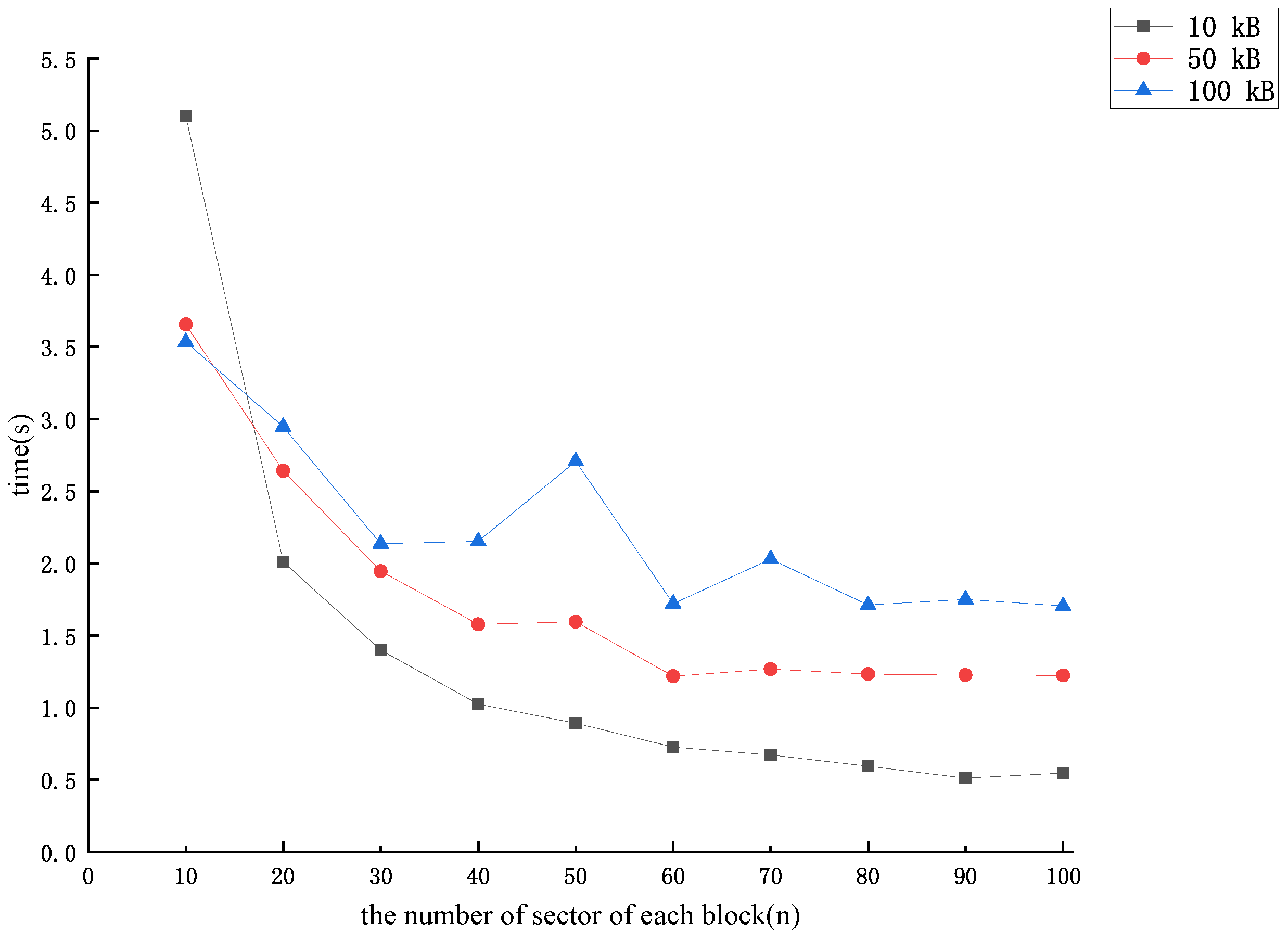
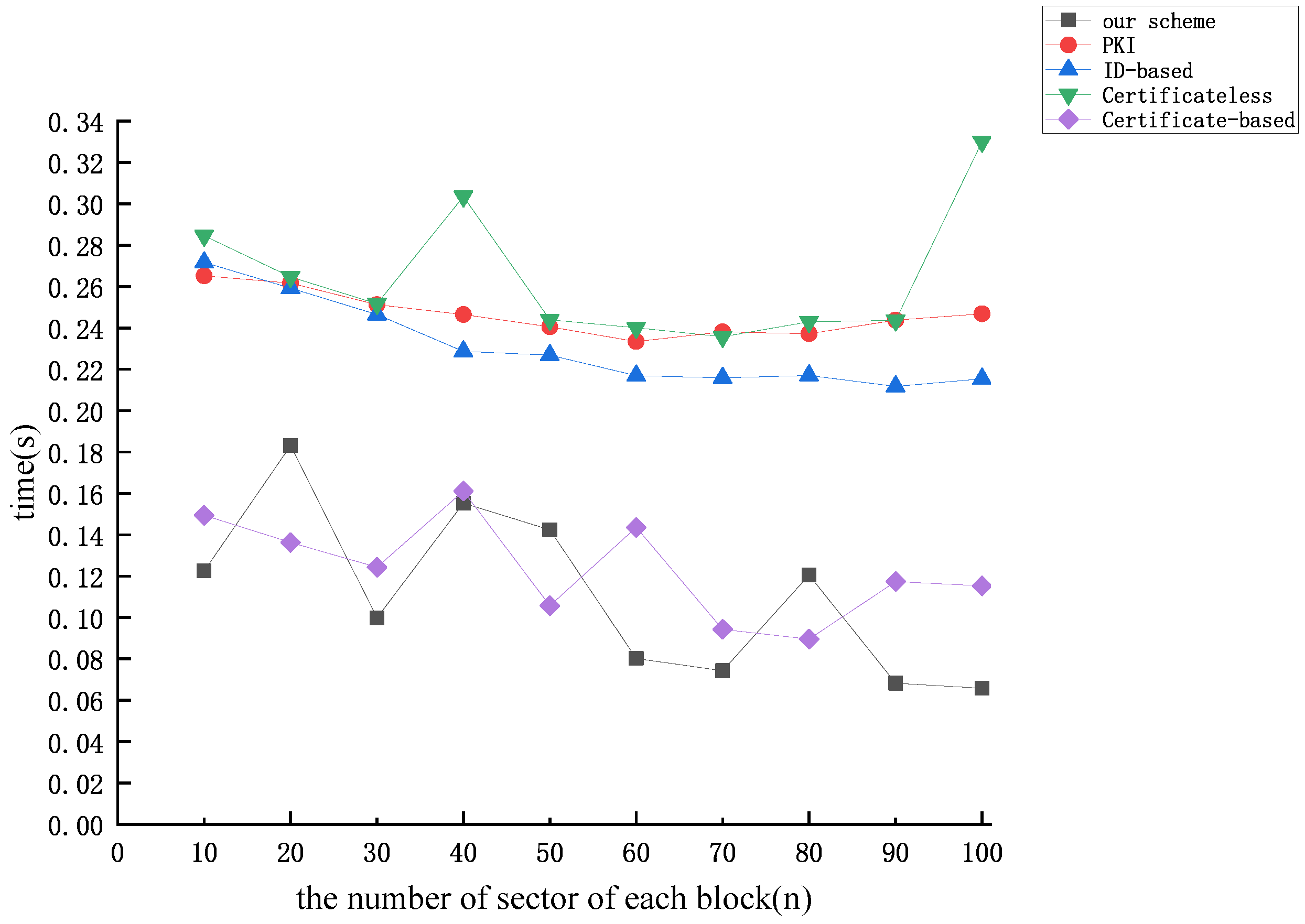
Figure 9, Figure 10 and Figure 11 illustrate the correlation between the time cost of tag generation and the number of data block sectors (n) for the aforementioned protocols, considering dataset sizes of 10 kB, 50 kB, and 100 kB, respectively. From Figure 9, Figure 10 and Figure 11, we find that the time overhead of the protocol proposed in this paper and the time overhead of the protocol proposed by [51] exhibit a gradual decrease as the number of sectors of each block increases. Upon analysis, it is evident that when the dataset size is constant, an increase in the number of sectors for each data block n results in a decrease in the relative value of m. Operations related to m predominantly involve operations on the group, while those associated with n involve operations on the finite field. It is noteworthy that the efficiency of operations on the group is notably lower compared to operations on the finite field, which gives rise to the aforementioned phenomenon. The figures indicate that the computational overhead of the protocol proposed by [51] and our protocol is the lowest among the five protocols. Nevertheless, our proposed protocol exhibits superior security performance.
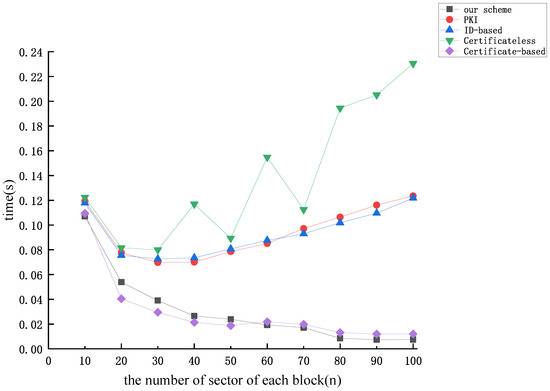
Figure 9.
The time cost of tag generation (dataset size = 10 kB).
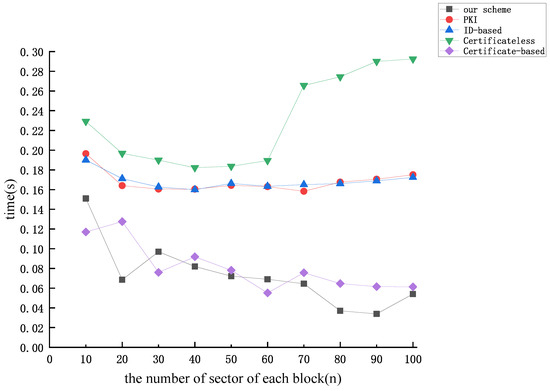
Figure 10.
The time cost of tag generation (dataset size = 50 kB).
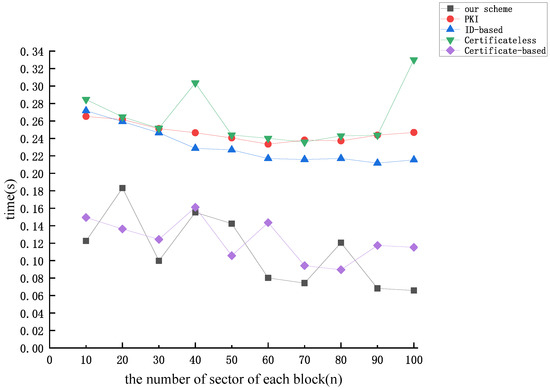
Figure 11.
The time cost of tag generation (dataset size = 100 kB).
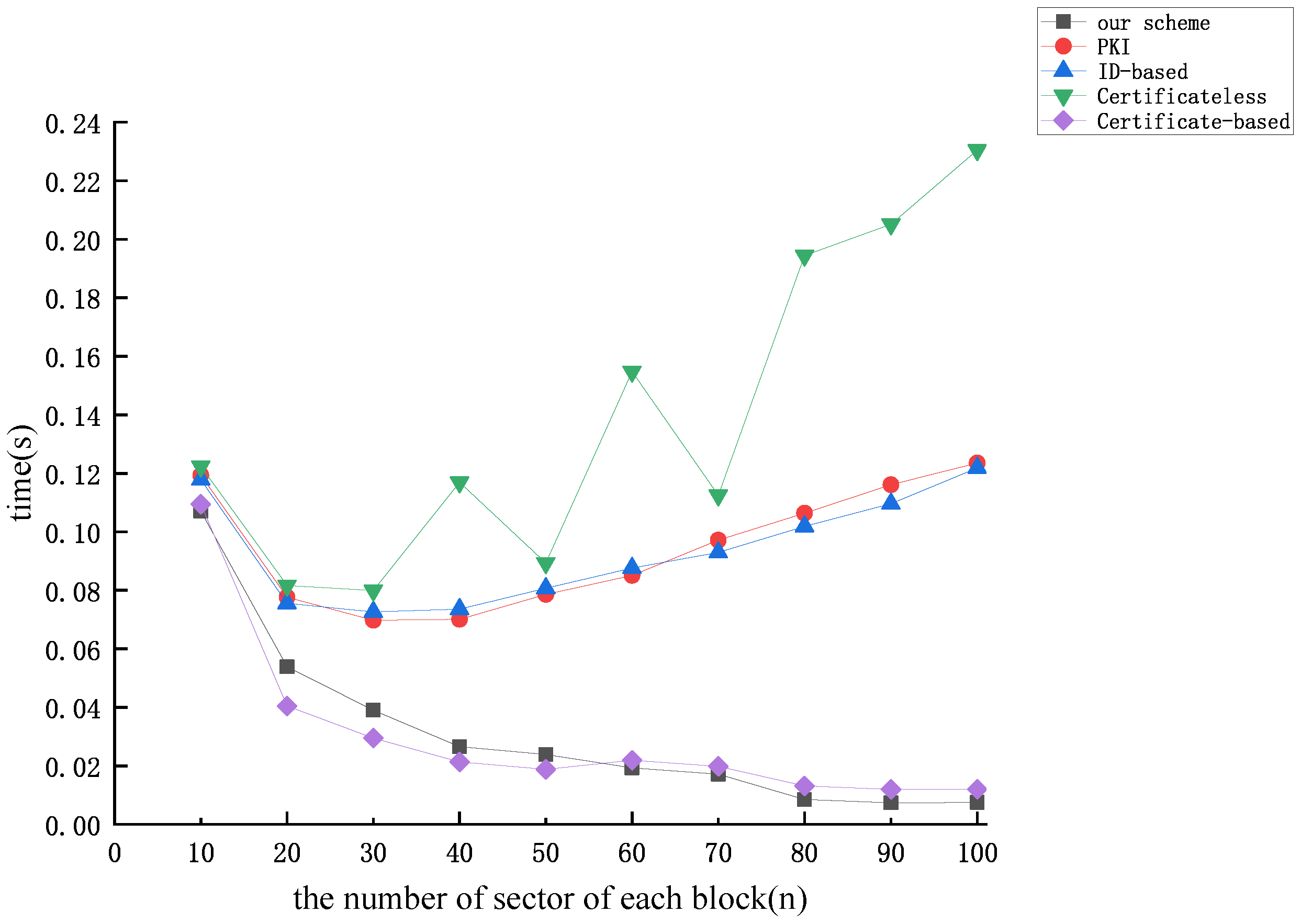
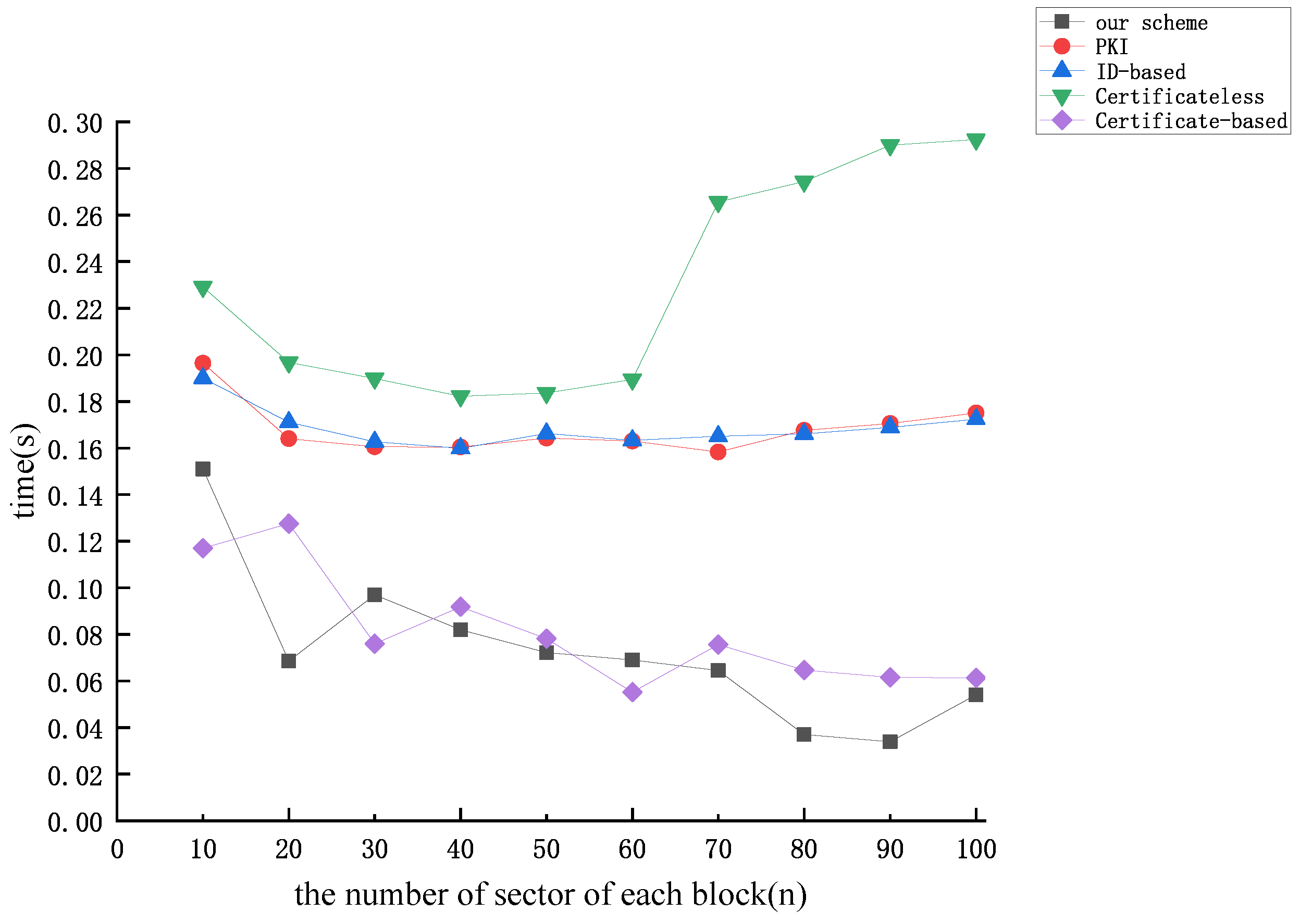
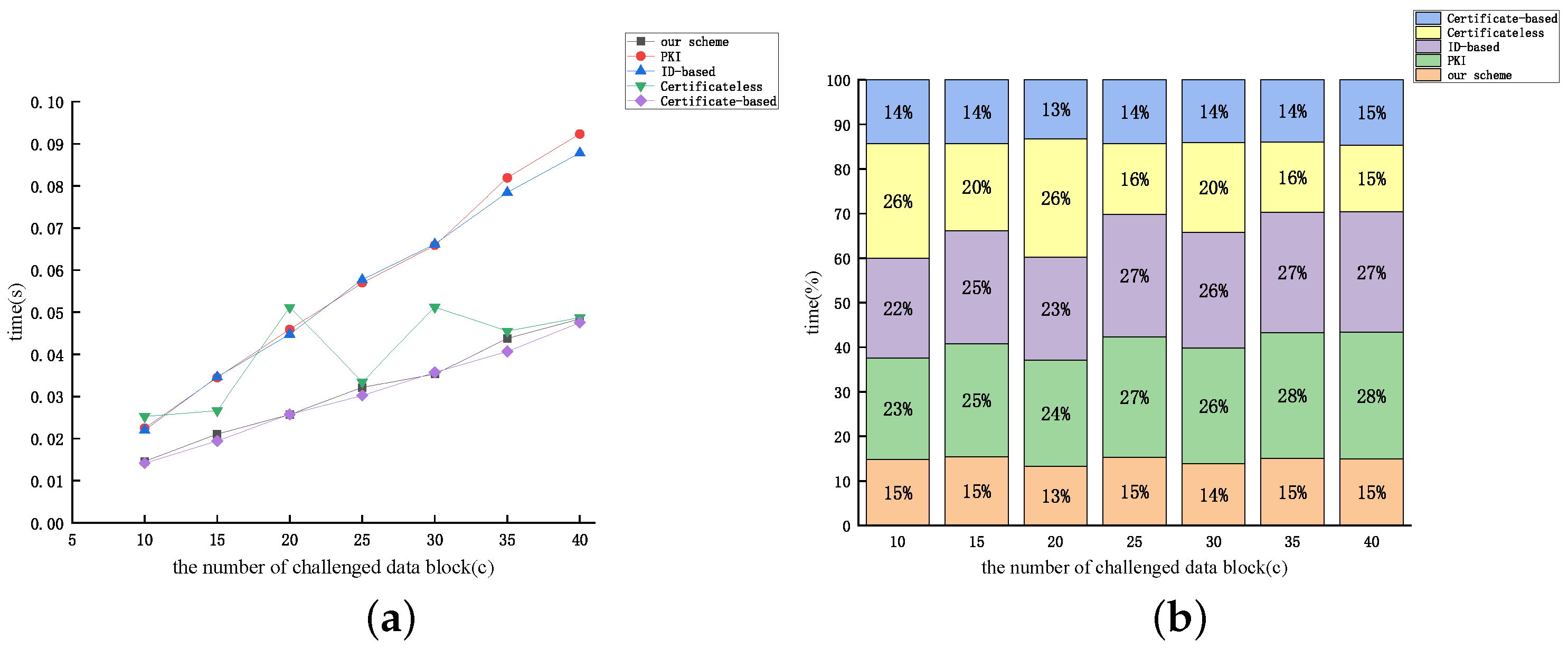
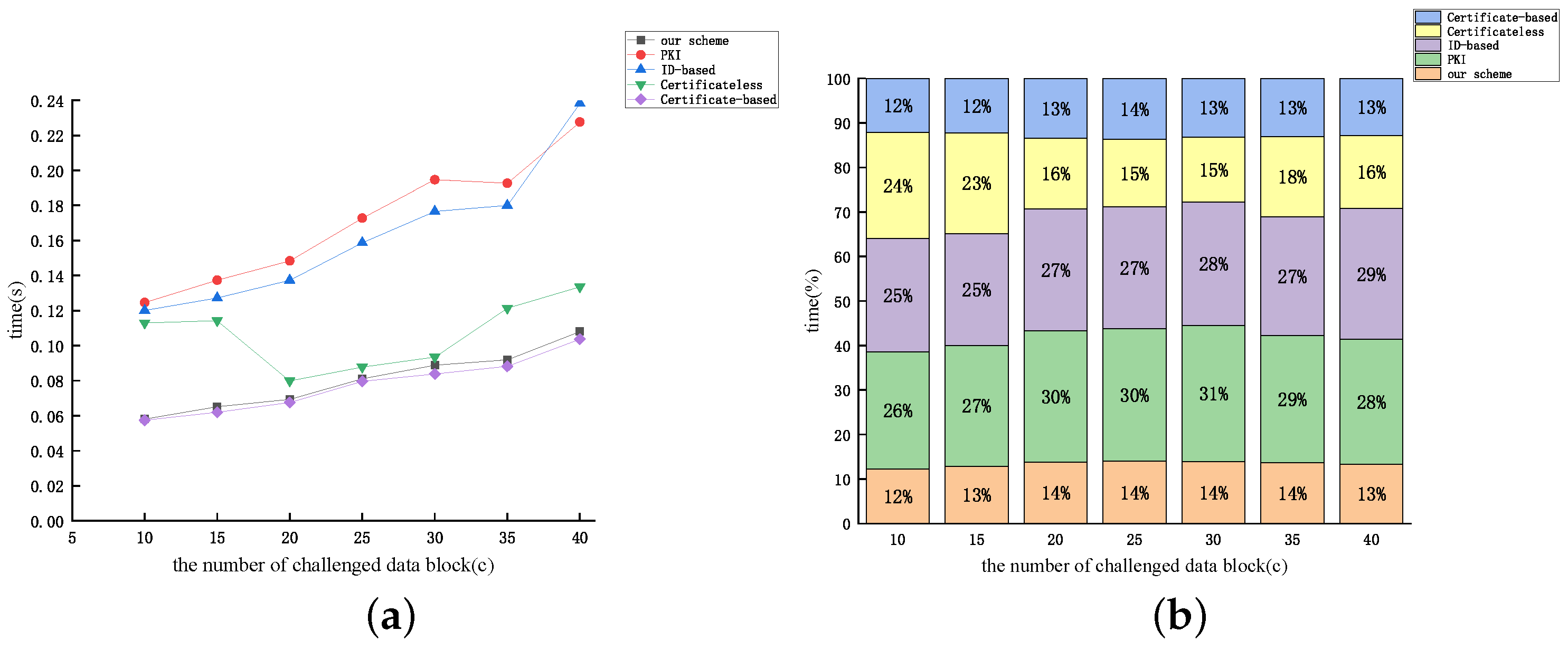
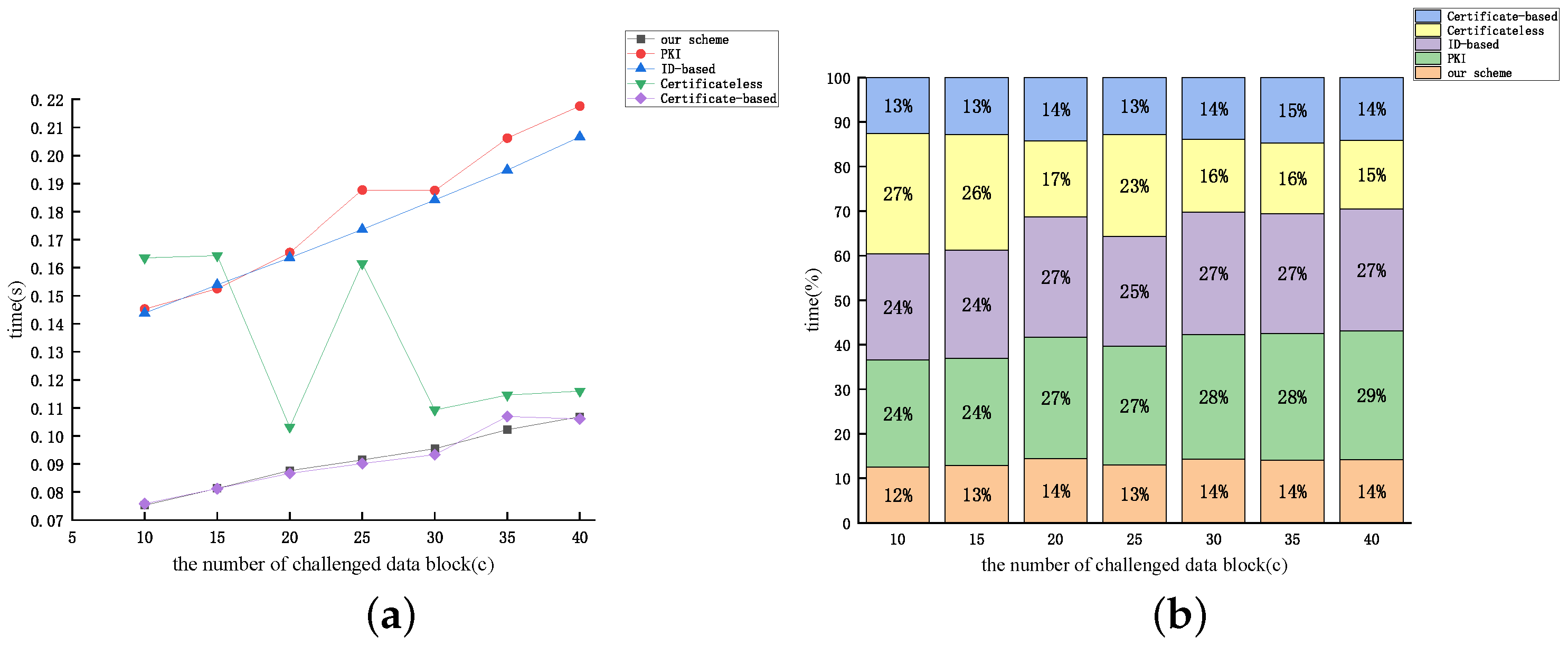
Figure 12, Figure 13 and Figure 14 display the relationship between the time cost of auditing and the number of auditing challenges (c) for the aforementioned protocols, considering dataset sizes of 10 kB, 50 kB, and 100 kB, respectively. From Figure 12, Figure 13 and Figure 14, the time overhead of the five protocols discussed earlier (excluding the protocol proposed by [46]) increases proportionally with the number of audit challenges. The examination reveals that as the audit file size remains constant, the value of n diminishes with the increase in c. Therefore, based on the expression, it can be inferred that the audit overhead exhibits an almost linear correlation with the rise in c (excluding the protocol proposed by [46]). The figures reveal that the computational overhead of the protocol proposed by [51] and our protocol is the lowest among the five protocols. However, our proposed protocol demonstrates superior security performance.
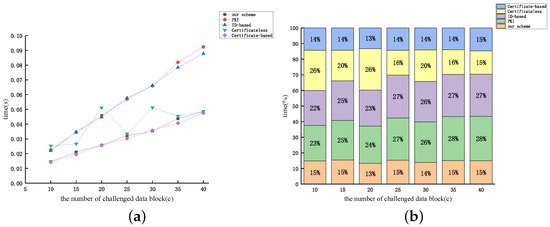
Figure 12.
The time cost of auditing: (a) line graph; (b) percentage bar graph (dataset size = 10 kB).
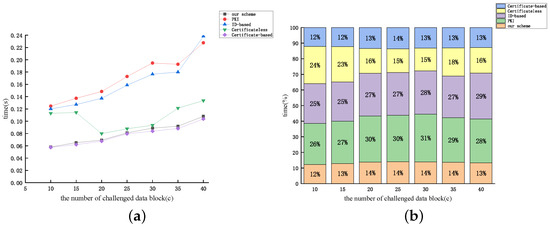
Figure 13.
The time cost of auditing: (a) line graph; (b) percentage bar graph (dataset size = 50 kB).
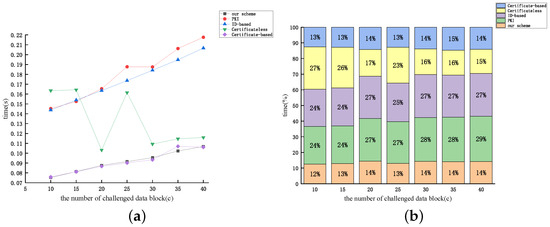
Figure 14.
The time cost of auditing: (a) line graph; (b) percentage bar graph (dataset size = 100 kB).
6. Conclusions
In this study, we initially identified a forgery method capable of forging arbitrary data blocks within the [51] protocol with minimal time overhead. Subsequently, we introduced a secure certificate-based cloud auditing protocol. Analyses affirmed that the efficiency of the protocol presented in this paper surpassed that of the five compared protocols.
Author Contributions
Conceptualization, X.Z. and T.Z.; Methodology, Y.T., X.Z. and T.Z.; Software, Y.T.; Formal analysis, Y.T., X.Z. and T.Z.; Investigation, Y.T.; Resources, T.Z. and W.Z.; Data curation, Y.T.; Writing—original draft, Y.T. and X.Z.; Writing—review & editing, Y.T., T.Z., W.Z., R.L. and X.Y.; Supervision, W.Z.; Project administration, X.Y.; Funding acquisition, T.Z. and X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (grant nos. 62172436, 62102452), Natural Science Foundation of Shaanxi Province (grant no. 2023-JC-YB-584).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
If a PPT adversary possesses the capability to compromise the proposed protocol with advantage , then there exists another PPT algorithm that can resolve the k-CAA dilemma. Let us assume that represent the maximum count of queries made by to the oracle, oracle, oracle, oracle, oracle, oracle, oracle, oracle, and oracle, respectively.
Game A1.
Suppose that is given a random instance of the weak k-CAA problem, where . Let or be the solution to the weak k-CAA problem. solves the weak k-CAA problem by interacting with . The details are as follows:
- Initialize: sets and creates a list of public parameters . Then, gives public parameters .
- Random oracle queries: randomly chooses and assumes denotes the tth time query to the oracle. responds to the query from as follows:
- (1)
- : maintains an initially empty list ; is used to store the following triples . If queries in , returns to . Otherwise, performs the following steps. If , randomly chooses and computes . Then, returns to and stores in . If , terminates the query.
- (2)
- : when received a new pair for (it can be any ID already in ), and holds, stores in .
- (3)
- maintains an initially empty list ; is used to store the following triples . If queries in , returns to . Otherwise, performs the following steps. If , randomly chooses and sets . If , sets . Then, returns to and stores in .
- (4)
- maintains an initially empty list ; is used to store the following binary group . If queries in , returns to . Otherwise, performs the following steps. If , sets . Then, returns to and stores in . If , terminates the query.
- (5)
- : If or , terminates the query. Otherwise, sends to from .
- (6)
- maintains an initially empty list ; is used to store the following pluralist group . If queries in , returns to . Otherwise, performs the following steps. Firstly, tosses a coin, whose . We specify that during the coin toss, . If , we randomly choose and set . If and , we randomly choose ; else, we randomly choose . Then, returns to and stores in .
- (7)
- maintains an initially empty list ; is used to store the following pluralist group . If queries in , returns to . Otherwise, randomly chooses . Then, returns to and stores in .
- (8)
- : maintains an initially empty list ; is used to store the following pluralist group . Firstly, randomly chooses an encrypted dataset with timestamp t. The dataset name is . Secondly, randomly chooses and sets . Then, performs the following steps. If , we set and . If and , we set ; else, terminates the query. Finally, sends to and stores in .
- (9)
- : maintains an initially empty list ; is used to store the following pluralist group . If queries tags in for dataset , is returned to . Otherwise, performs the following steps. If and , terminates the query; else, sets and stores in .Finally, sends to .
- (10)
- : First, generates a to . Then, generates a proof to , where . Finally, audits and sends or to .
- Forge: wins in Game A1 if the following conditions are met:
- (1)
- can forge a tuple .
- (2)
- has never queried on .
- (3)
- has never queried U on .
- (4)
- has never queried on .
- (5)
- outputs 1.
Therefore, wants to win Game A1 by constructing that satisfies the condition via Equation (A1).That is, can forge to win Game A1. - Outputs: From the above steps, it follows that can solve for by forging when satisfies the following two conditions:
- (1)
- does not terminate the query.
- (2)
- wins Game A1.
From Game A1, the following conditions need to be satisfied simultaneously to fulfill Condition (1):- (1)
- The probability that does not terminate the is minimized as .
- (2)
- The probability that does not terminate the is minimized as .
- (3)
- The probability that does not terminate the is minimized as .
- (4)
- The probability that does not terminate the is minimized as .
- (5)
- The probability that does not terminate the is minimized as .
From Game A1, the following conditions need to be satisfied simultaneously to fulfill Condition (2):- (1)
- In the , can ask within the number of queries, whose probability is minimized to .
- (2)
- In the , can ask within the number of queries, whose probability is minimized to .
Here, it is assumed that can attack the protocol with a non-negligible advantage . Then, can solve with a non-negligible advantage . Among them, (number of queries ). However, from Definition 2, there exists no that can solve the weak k-CAA problem in T queries with an advantage, and thus no that can attack the protocol with an advantage.
Appendix B
If an adversary in a PPT setting can successfully compromise the proposed protocol with advantage , then there exists another PPT algorithm capable of solving the k-CAA problem. Let us consider as the maximum allowable number of queries posed by to the oracle, oracle, oracle, oracle, oracle, oracle, and oracle, respectively.
Game A2.
Suppose that is given a random instance of the k-CAA problem, where . Let be the solution to the k-CAA problem. solves the k-CAA problem by interacting with . The details are as follows:
- Initialize: randomly chooses , sets , and creates a list of public parameters . Then, gives public parameters and s.
- Random oracle queries: randomly chooses and assumes denotes the tth time query to the oracle. responds to the query from as follows:
- (1)
- : maintains an initially empty list , is used to store the following triples . If queries in , returns to . Otherwise, performs the following steps. If , randomly chooses , and computes . And then, returns to and stores in . If , terminate the query.
- (2)
- maintains an initially empty list ; is used to store the following triples . If queries in , returns to . Otherwise, randomly chooses and sets . Then, returns to and stores in .
- (3)
- : If or , terminates the query. Otherwise, sends to from
- (4)
- maintains an initially empty list ; is used to store the following pluralist group . If queries in , returns to . Otherwise, performs the following steps. First, tosses a coin, whose . We specify that during the coin toss, . If , we randomly choose and set . If and , we randomly choose ; else, we randomly choose . Then, returns to and stores in .
- (5)
- maintains an initially empty list ; is used to store the following pluralist group . If queries in , returns to . Otherwise, randomly chooses . Then, returns to and stores in .
- (6)
- : maintains an initially empty list ; is used to store the following pluralist group . Firstly, randomly chooses encrypted dataset with timestamp t. The dataset name is . Secondly, randomly chooses , and sets . Then, performs the following steps. If , we set and set . If and , we set , else terminates the query. Finally, sends to and stores in .
- (7)
- : maintains an initially empty list ; is used to store the following pluralist group . If queries tags in for dataset , it returns to . Otherwise, performs the following steps. If and , terminates the query; else, sets and stores in .Finally, sends to .
- (8)
- : First, generates a to . Then, generates a proof to , where . Finally, audits and sends 0 or 1 to .
- Forge: For to win in Game A2, the following conditions need to be met.
- (1)
- can forge a tuple .
- (2)
- has never queried on .
- (3)
- has never queried U on .
- (4)
- has never queried on .
- (5)
- outputs 1.
Therefore, wants to win Game A2 by constructing that satisfies the condition via Equation (A2).That is, can forge to win Game A2. - Outputs: From the above steps, it follows that can solve for by forging when satisfies the following two conditions:
- (1)
- does not terminate the query.
- (2)
- wins Game A2.
From Game A2, the following conditions need to be satisfied simultaneously to fulfill Condition (1):- (1)
- The probability that does not terminate the is minimized as .
- (2)
- The probability that does not terminate the is minimized as .
- (3)
- The probability that does not terminate the is minimized as .
- (4)
- The probability that does not terminate the is minimized as .
From Game A2, the following conditions need to be satisfied simultaneously to fulfill Condition (2):- (1)
- In the , can ask within the number of queries, whose probability is minimized to .
- (2)
- In the , can ask within the number of queries, whose probability is minimized to .
Here, it is assumed that can attack the protocol with a non-negligible advantage . Then, can output a new pair with a non-negligible advantage . Among them, (number of queries ). However, from Definition 1, there exists no that can solve the k-CAA problem in T queries with an advantage, and thus no that can attack the protocol with an advantage.
Appendix C
If a PPT adversary is capable of undermining the proposed protocol with advantage , then another PPT algorithm exists that can effectively tackle the CDH problem. Let us assume represent the maximum allowable numbers of queries made by to the oracle, oracle, oracle, oracle, oracle, and oracle, respectively.
Game A3.
Suppose that is given a random instance of the CDH problem, where . Let be the solution to the CDH problem. solves the CDH problem by interacting with . The details are as follows:
- Initialize: sets and creates a list of public parameters . Then, gives public parameters .
- Random oracle queries: randomly chooses and assumes denotes the tth time query to the oracle. responds to the query from as follows:
- (1)
- : maintains an initially empty list ; is used to store the following triples . If queries in , returns to . Otherwise, performs the following steps. If , randomly chooses , and computes . Then, returns to and stores in . If , terminates the query.
- (2)
- : If queries in , returns to . Otherwise, performs the following steps.
- (1)
- If , randomly chooses , sets and , and then returns , to . stores in .
- (2)
- If , sets , and . Then, stores in and terminates the query.
- (3)
- : If queries in , returns it to . Otherwise, randomly chooses and performs the following steps:
- (1)
- If , sets andthen returns to . stores in .
- (2)
- If , tosses a coin, whose . We specify that during the coin toss, , and we terminate the query if and only if . When , we set . When , we set . Then, returns to and stores in .
- (4)
- : If queries U in , returns U to . Otherwise, performs the following steps:
- (1)
- If , performs the following steps. Firstly, extracts from ; if it does not exist, C extracts after executing the . Secondly, extracts from ; if not present, extracts after executing the . Then, extracts from ; if not present, extracts after executing the . Finally, calculates and stores in .
- (2)
- If , tosses a coin, whose . We specify that during the coin toss, . When , we set and terminate the query. When , extracts from ; if not present, extracts after executing . Then, extracts from ; if not present, extracts after executing . Finally, sets and stores in .
- (5)
- : If queries in , returnsit to . Otherwise, performs the following steps. randomly chooses and sets . Then, stores in and returns to .
- (6)
- : If queries in , returnsit to . Otherwise, performs the following steps. Firstly, randomly chooses and sets . Secondly, extracts from ; if it does not exist, executes the and then extracts . Thirdly, extracts r from ; if not present, extracts r after executing the . Then, looks at the corresponding coin value, and when , calculates and stores in . When , calculates and stores in . Finally, sends to .
- Auditing: We suppose that can forge for by the above steps and can pass the challenge of .
- (1)
- constructs by calculating Equation (A3).That is, can forge to pass the check.
- (2)
- derives for by calculating the following equation.
- (1)
- If , , that is, can forge = to pass the check.
- (2)
- If , , that is, can forge = to pass the check.
- Outputs: From the above steps, it follows that can solve for by forging when satisfies the following two conditions:
- (1)
- does not terminate the query.
- (2)
- wins Game A3.
From Game A3, the following conditions need to be satisfied simultaneously to fulfill Condition (1):- (1)
- The probability that does not terminate the is minimized as .
- (2)
- The probability that does not terminate the is minimized as .
- (3)
- The probability that does not terminate the is minimized as .
From Game A3, the following conditions need to be satisfied simultaneously to fulfill Condition (2):- (1)
- In the , can ask within the number of queries, whose probability is minimized to .
- (2)
- In the , can ask within the number of queries, whose probability is minimized to .
Here, it is assumed that can attack the protocol with a non-negligible advantage . Then, can solve with a non-negligible advantage . Among them, (number of queries ). However, from Definition 3, there exists no that can solve the CDH problem in T queries with an advantage, and thus no that can attack the protocol with an advantage.
References
- Kim, H.; Rigo, B.; Wong, G.; Lee, Y.J.; Yeo, W.H. Advances in Wireless, Batteryless, Implantable Electronics for Real-Time, Continuous Physiological Monitoring. Nano-Micro Lett. 2023, 16, 52. [Google Scholar] [CrossRef] [PubMed]
- Microsoft/SEAL. Microsoft. 2024. Available online: https://github.com/microsoft/SEAL (accessed on 18 April 2024).
- Di Matteo, S.; Gerfo, M.L.; Saponara, S. VLSI Design and FPGA Implementation of an NTT Hardware Accelerator for Homomorphic SEAL-Embedded Library. IEEE Access 2023, 11, 72498–72508. [Google Scholar] [CrossRef]
- Homenc/HElib. Homenc. 2024. Available online: https://github.com/homenc/HElib (accessed on 15 March 2024).
- PALISADE Homomorphic Encryption Software Library—An Open-Source Lattice Crypto Software Library. Available online: https://palisade-crypto.org/ (accessed on 15 March 2024).
- Deswarte, Y.; Quisquater, J.J.; Saïdane, A. Remote Integrity Checking. In Integrity and Internal Control in Information Systems VI, Proceedings of the IFIP TC11/WG11.5 Sixth Working Conference on Integrity and Internal Control in Information Systems (IICIS), Lausanne, Switzerland, 13–14 November 2003; Jajodia, S., Strous, L., Eds.; Springer: Boston, MA, USA, 2004; pp. 1–11. [Google Scholar] [CrossRef]
- Oprea, A.; Reiter, M. Space-Efficient Block Storage Integrity. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2005, San Diego, CA, USA, 1 January 2005. [Google Scholar]
- Schwarz, T.; Miller, E. Store, Forget, and Check: Using Algebraic Signatures to Check Remotely Administered Storage. In Proceedings of the 26th IEEE International Conference on Distributed Computing Systems (ICDCS’06), Lisboa, Portugal, 4–7 July 2006; p. 12. [Google Scholar] [CrossRef]
- Ateniese, G.; Burns, R.; Curtmola, R.; Herring, J.; Kissner, L.; Peterson, Z.; Song, D. Provable Data Possession at Untrusted Stores. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 31 October–2 November 2007; pp. 598–609. [Google Scholar] [CrossRef]
- Shacham, H.; Waters, B. Compact Proofs of Retrievability. In Proceedings of the Advances in Cryptology—ASIACRYPT 2008, Melbourne, Australia, 7–11 December 2008; Pieprzyk, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 90–107. [Google Scholar] [CrossRef]
- Boneh, D.; Lynn, B.; Shacham, H. Short Signatures from the Weil Pairing. J. Cryptol. 2004, 17, 297–319. [Google Scholar] [CrossRef]
- Armknecht, F.; Bohli, J.M.; Karame, G.; Li, W. Outsourcing Proofs of Retrievability. IEEE Trans. Cloud Comput. 2018, 9, 286–301. [Google Scholar] [CrossRef]
- Bowers, K.D.; Juels, A.; Oprea, A. Proofs of Retrievability: Theory and Implementation. In Proceedings of the 2009 ACM Workshop on Cloud Computing Security, Chicago, IL, USA, 13 November 2009; CCSW’09. pp. 43–54. [Google Scholar] [CrossRef]
- Cash, D.; Küpçü, A.; Wichs, D. Dynamic Proofs of Retrievability Via Oblivious RAM. J. Cryptol. 2017, 30, 22–57. [Google Scholar] [CrossRef]
- Cui, H.; Wan, Z.; Gao, R.; Wang, H. Outsourced Privately Verifiable Proofs of Retrievability Via Blockchain. IEEE Trans. Dependable Secur. Comput. 2023, 1–18. [Google Scholar] [CrossRef]
- Hao, Z.; Zhong, S.; Yu, N. A Privacy-Preserving Remote Data Integrity Checking Protocol with Data Dynamics and Public Verifiability. IEEE Trans. Knowl. Data Eng. 2011, 23, 1432–1437. [Google Scholar] [CrossRef]
- Nayak, S.K.; Tripathy, S. SEPDP: Secure and Efficient Privacy Preserving Provable Data Possession in Cloud Storage. IEEE Trans. Serv. Comput. 2018, 14, 876–888. [Google Scholar] [CrossRef]
- Wang, H. Proxy Provable Data Possession in Public Clouds. IEEE Trans. Serv. Comput. 2013, 6, 551–559. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, C.; Ren, K.; Lou, W.; Li, J. Enabling Public Auditability and Data Dynamics for Storage Security in Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 847–859. [Google Scholar] [CrossRef]
- Xiong, L.; Goryczka, S.; Sunderam, V. Adaptive, Secure, and Scalable Distributed Data Outsourcing: A Vision Paper. In Proceedings of the 2011 Workshop on Dynamic Distributed Data-Intensive Applications, Programming Abstractions, and Systems, San Jose, CA, USA, 8 June 2011; 3DAPAS ’11. pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; Xu, C.; Li, H.; Wang, H.; Zhang, Y. CIPPPA: Conditional Identity Privacy-Preserving Public Auditing for Cloud-Based WBANs against Malicious Auditors. IEEE Trans. Cloud Comput. 2019, 9, 1362–1375. [Google Scholar] [CrossRef]
- Zheng, Q.; Xu, S. Fair and Dynamic Proofs of Retrievability. In Proceedings of the First ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 21–23 February 2011; CODASPY’11. pp. 237–248. [Google Scholar] [CrossRef]
- Zhu, Y.; Hu, H.; Ahn, G.J.; Yu, M. Cooperative Provable Data Possession for Integrity Verification in Multicloud Storage. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 2231–2244. [Google Scholar] [CrossRef]
- Zhu, Y.; Hu, H.; Ahn, G.J.; Han, Y.; Chen, S. Collaborative Integrity Verification in Hybrid Clouds. In Proceedings of the 7th International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom), Orlando, FL, USA, 15–18 October 2011; pp. 191–200. [Google Scholar]
- Zhu, Y.; Wang, H.; Hu, Z.; Ahn, G.J.; Hu, H.; Yau, S.S. Efficient Provable Data Possession for Hybrid Clouds. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; CCS’10. pp. 756–758. [Google Scholar] [CrossRef]
- Han, J.; Li, Y.; Yu, Y.; Ding, Y. Cloud Auditing Scheme with Dynamic Revocation of Users and Real-Time Updates of Data. J. Softw. 2020, 31, 578–596. [Google Scholar] [CrossRef]
- Diffie, W. New Directions in Cryptography. IEEE Trans. Inf. Theory 1976, IT-22, 644–654. [Google Scholar] [CrossRef]
- Chang, J.; Shao, B.; Ji, Y.; Bian, G. Efficient Identity-Based Provable Multi-Copy Data Possession in Multi-Cloud Storage, Revisited. IEEE Commun. Lett. 2020, 24, 2723–2727. [Google Scholar] [CrossRef]
- Chen, D.; Yuan, H.; Hu, S.; Wang, Q.; Wang, C. BOSSA: A Decentralized System for Proofs of Data Retrievability and Replication. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 786–798. [Google Scholar] [CrossRef]
- Li, J.; Yan, H.; Zhang, Y. Efficient Identity-Based Provable Multi-Copy Data Possession in Multi-Cloud Storage. IEEE Trans. Cloud Comput. 2022, 10, 356–365. [Google Scholar] [CrossRef]
- Ni, J.; Zhang, K.; Yu, Y.; Yang, T. Identity-Based Provable Data Possession From RSA Assumption for Secure Cloud Storage. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1753–1769. [Google Scholar] [CrossRef]
- Shen, W.; Qin, J.; Yu, J.; Hao, R.; Hu, J. Enabling Identity-Based Integrity Auditing and Data Sharing With Sensitive Information Hiding for Secure Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2018, 14, 331–346. [Google Scholar] [CrossRef]
- Wang, H.; He, D.; Tang, S. Identity-Based Proxy-Oriented Data Uploading and Remote Data Integrity Checking in Public Cloud. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1165–1176. [Google Scholar] [CrossRef]
- Wang, H. Identity-Based Distributed Provable Data Possession in Multicloud Storage. IEEE Trans. Serv. Comput. 2015, 8, 328–340. [Google Scholar] [CrossRef]
- Wang, H.; He, D.; Yu, J.; Wang, Z. Incentive and Unconditionally Anonymous Identity-Based Public Provable Data Possession. IEEE Trans. Serv. Comput. 2019, 12, 824–835. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Q.; Qin, B.; Domingo-Ferrer, J. Identity-Based Remote Data Possession Checking in Public Clouds. IET Inf. Secur. 2014, 8, 114–121. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Q.; Qin, B.; Shi, W.; Deng, R.H.; Hu, J. Identity-Based Data Outsourcing with Comprehensive Auditing in Clouds. IEEE Trans. Inf. Forensics Secur. 2016, 12, 940–952. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, Y.; Chen, F.; Chen, J. An Efficient Identity-Based Provable Data Possession Protocol with Compressed Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1359–1371. [Google Scholar] [CrossRef]
- Yu, Y.; Au, M.H.; Ateniese, G.; Huang, X.; Susilo, W.; Dai, Y.; Min, G. Identity-Based Remote Data Integrity Checking with Perfect Data Privacy Preserving for Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2016, 12, 767–778. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J.; Hao, R.; Wang, C.; Ren, K. Enabling Efficient User Revocation in Identity-Based Cloud Storage Auditing for Shared Big Data. IEEE Trans. Dependable Secur. Comput. 2018, 17, 608–619. [Google Scholar] [CrossRef]
- Pang, X.; Wang, T.; Chen, W.; Ren, M. Batch Provable Data Possession Scheme with Error Locating. J. Softw. 2018, 30, 362–380. [Google Scholar] [CrossRef]
- Shamir, A. Identity-Based Cryptosystems and Signature Schemes. In Advances in Cryptology; Blakley, G.R., Chaum, D., Eds.; Springer: Berlin/Heidelberg, Germany, 1985; pp. 47–53. [Google Scholar] [CrossRef]
- Deng, L.; Chen, Z.; Ruan, Y.; Zhou, H.; Li, S. Certificateless Provable Data Possession Scheme Suitable for Smart Grid Management Systems. IEEE Syst. J. 2023, 17, 4245–4256. [Google Scholar] [CrossRef]
- He, D.; Kumar, N.; Zeadally, S.; Wang, H. Certificateless Provable Data Possession Scheme for Cloud-Based Smart Grid Data Management Systems. IEEE Trans. Ind. Inform. 2017, 14, 1232–1241. [Google Scholar] [CrossRef]
- Li, J.; Yan, H.; Zhang, Y. Certificateless Public Integrity Checking of Group Shared Data on Cloud Storage. IEEE Trans. Serv. Comput. 2018, 14, 71–81. [Google Scholar] [CrossRef]
- Shen, J.; Zeng, P.; Choo, K.K.R.; Li, C. A Certificateless Provable Data Possession Scheme for Cloud-Based EHRs. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1156–1168. [Google Scholar] [CrossRef]
- Wang, B.; Li, B.; Li, H.; Li, F. Certificateless Public Auditing for Data Integrity in the Cloud. In Proceedings of the 2013 IEEE Conference on Communications and Network Security (CNS), National Harbor, MD, USA, 14–16 October 2013; pp. 136–144. [Google Scholar] [CrossRef]
- Zhou, L.; Fu, A.; Yang, G.; Wang, H.; Zhang, Y. Efficient Certificateless Multi-Copy Integrity Auditing Scheme Supporting Data Dynamics. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1118–1132. [Google Scholar] [CrossRef]
- Al-Riyami, S.S.; Paterson, K.G. Certificateless Public Key Cryptography. In Advances in Cryptology—ASIACRYPT 2003; Laih, C.S., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 452–473. [Google Scholar] [CrossRef]
- Gentry, C. Certificate-Based Encryption and the Certificate Revocation Problem. In Advances in Cryptology—EUROCRYPT 2003; Biham, E., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 272–293. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, F. An Efficient Certificate-Based Data Integrity Auditing Protocol for Cloud-Assisted WBANs. IEEE Internet Things J. 2022, 9, 11513–11523. [Google Scholar] [CrossRef]
- Milnor, J.W.; Husemoller, D. Symmetric Bilinear Forms; Springer: Berlin/Heidelberg, Germany, 1973; Volume 73. [Google Scholar] [CrossRef]
- Mitsunari, S.; Sakai, R.; Kasahara, M. A New Traitor Tracing. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2002, 85, 481–484. [Google Scholar]
- Liu, J.K.; Bao, F.; Zhou, J. Short and Efficient Certificate-Based Signature. In NETWORKING 2011 Workshops; Casares-Giner, V., Manzoni, P., Pont, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 167–178. [Google Scholar] [CrossRef]
- Wang, C.; Chow, S.S.; Wang, Q.; Ren, K.; Lou, W. Privacy-Preserving Public Auditing for Secure Cloud Storage. IEEE Trans. Comput. 2013, 62, 362–375. [Google Scholar] [CrossRef]
- Maas, M. Pairing-Based Cryptography. Master’s Thesis, Technische Universiteit Eindhoven, Department of Mathematics and Computing Science, Eindhoven, The Netherlands, 2004. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).