

Prediction of Carbon Emissions Level in China’s Logistics Industry Based on the PSO-SVR Model
Abstract
:1. Introduction
2. PSO-SVR Predictive Mode
2.1. Support Vector Regression Model
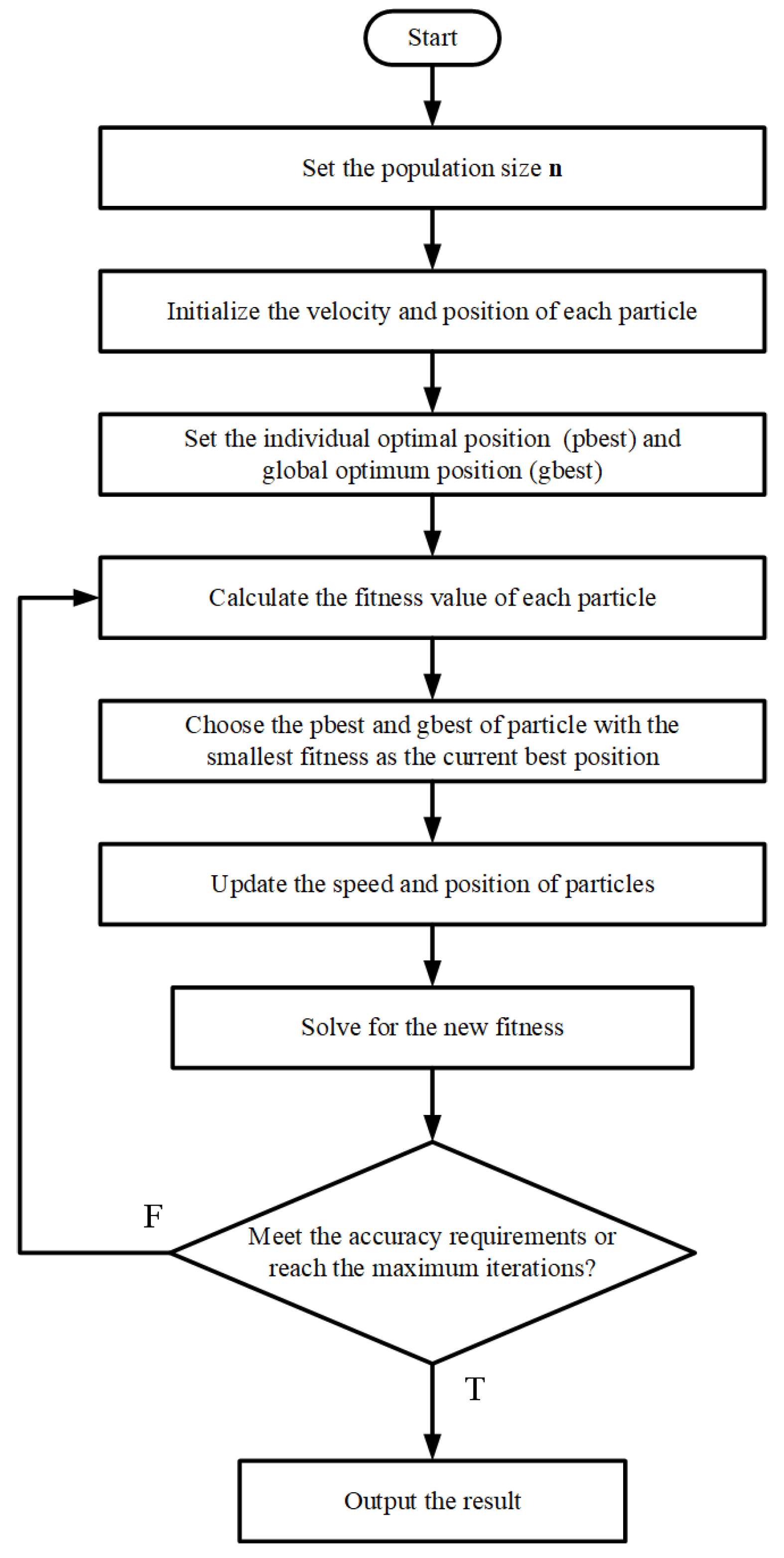
2.2. Particle Swarm Optimization Algorithm
2.3. PSO-SVR Model for Carbon Emissions Prediction
3. Case Study
3.1. Data Sources
3.2. Selection of Influencing Factors
3.3. Prediction of the Carbon Emissions Level of China’s Logistics Industry Based on the PSO-SVR Model
3.3.1. Prediction of Carbon Emissions Level of China’s Logistics Industry
3.3.2. Prediction Result Comparison
4. Results and Discussion
- (1)
- The gray correlation analysis was conducted on 12 influencing factors that affected carbon emissions in the logistics industry, and seven significant variables were finally screened out. These variables include total energy consumption, the number of registered scientific and technological achievements, the actual amount of foreign capital used in the logistics industry, the total amount of import and export trade, the number of employees in the tertiary industry, the proportion of the national urban population, and total national energy consumption. Gray relational analysis adopts a nonlinear approach, which effectively reduces the dimensionality of the predictive input set and enhances the practicability of the model [57]. Based on these analyses, the government should prioritize optimizing energy structures, strengthening technological innovation [58], utilizing foreign capital rationally, promoting balanced trade development [59], adjusting industrial structures, optimizing urban population distribution [60,61], and enhancing regulatory and law enforcement efforts. These policy recommendations will contribute to reducing carbon emissions in the logistics industry and facilitate its transition toward a green and low-carbon development path.
- (2)
- The SVR regression model was optimized using the particle swarm optimization algorithm. The mean absolute percentage error (MAPE) was merely 0.82%, significantly outperforming traditional forecasting methods. This result demonstrates the effectiveness and accuracy of the model in predicting carbon emissions from complex systems. The model is capable of capturing the dynamic characteristics of carbon emissions in the logistics industry and effectively forecasting future carbon emissions trends. Based on the forecasting results of the PSO-SVR model, the carbon emissions from China’s logistics industry are expected to reach 178.4295 million tons in the next year.
- (3)
- Relying solely on energy coefficient estimation methods as a basis for prediction has significant limitations. This approach tends to be based on static or macro-level assumptions. The logistics industry involves multiple processes and factors, such as the choice of transportation modes, the length of transportation distances, differences in cargo types, and the efficiency of warehouse management, all of which have significant impacts on carbon emissions and place higher demands on data. Furthermore, with the continuous development of technology, new optimization techniques are emerging, which may include predictive models based on large models [62] and machine learning. These techniques can more flexibly adapt to industry changes and more accurately simulate and predict carbon emissions in the logistics industry. This paper also acknowledges the need for continuous learning and updating.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, R.; Gao, G. Chinese Pathway and Construction of Ecological Perspectives in the Context of Dual Carbon Goals—Taking English Reports on “Dual Carbon” in China Daily and Xinhua News Agency as Examples. J. Univ. Sci. Technol. Beijing (Soc. Sci. Ed.) 2024, 40, 94–103. [Google Scholar]
- He, D. “New Blueprint” for High-quality Development of Modern Logistics—Interpretation of “14th Five-Year Plan for Modern Logistics Development”. China Storage Transp. 2023, 3, 17–19. [Google Scholar]
- Yao, X.; Zhang, H.; Wang, X. Which model is more efficient in carbon emission prediction research? A comparative study of deep learning models, machine learning models, and econometric models. Environ. Sci. Pollut. Res. Int. 2024, 31, 19500–19515. [Google Scholar] [CrossRef]
- Yang, D.; Li, Y.; Tian, C. Research on the natural peak characteristics and peak prediction of carbon emissions in the transportation industry. Transp. Syst. Eng. Inf. 2024, 24, 34–44. [Google Scholar]
- Ju, K.; Li, S.; Ma, Y. Decomposition of influencing factors and peak scenario prediction of carbon emissions in China’s water transport industry. Logist. Technol. 2024, 47, 89–93. [Google Scholar]
- Zhu, W.; Cheng, Y. Analysis of influencing factors of carbon emissions in China’s construction industry and prediction of carbon peak carbon neutrality. J. Hebei Inst. Environ. Eng. 2024, 34, 1–7. [Google Scholar]
- Wang, J.; Wei, J. Change characteristics and scenario simulation of building operation carbon emissions in Beijing under time series. J. Beijing Univ. Technol. 2022, 48, 220–229. [Google Scholar]
- Cheng, M.; Liu, Y.; Li, J. A new modeling method of gray GM (1, N) model and its application to predicting China’s clean energy consumption. Commun. Stat.-Simul. Comput. 2023, 52, 3712–3723. [Google Scholar] [CrossRef]
- Cheng, M.; Li, J.; Liu, Y.; Liu, B. Forecasting Clean Energy Consumption in China by 2025: Using Improved Gray Model GM (1, N). Sustainability 2020, 12, 698. [Google Scholar] [CrossRef]
- Deng, W.; Xu, Z. Characteristics of agricultural carbon emissions and carbon peak analysis in Hunan Province. Chin. J. Eco-Agric. 2024, 32, 206–217. [Google Scholar]
- Shu, F. Forecast of China’s corrugated paper production based on FGM (1,1). China Pap. Ind. 2023, 44, 6–9. [Google Scholar]
- Chen, T.; Wang, M. Deep Learning-Based Carbon Emission Forecasting and Peak Carbon Pathways in China’s Logistics Industry. Sustainability 2024, 16, 1826. [Google Scholar] [CrossRef]
- Zhang, X.; Wei, Z.; Chen, Z.; Han, Y. Research on industrial carbon emission prediction method based on LASSO-GWO-KELM. Environ. Eng. 2023, 41, 141–149. [Google Scholar]
- Shao, C.; Ning, J. Construction and application of carbon emission prediction model for China’s textile and garment industry based on improved WOA-LSTM. J. Beijing Inst. Fash. Technol. (Nat. Sci. Ed.) 2023, 43, 73–81. [Google Scholar]
- Jiao, L.; Liu, Y.; Wu, Y. Research on carbon emission prediction of transportation industry based on convolutional neural network. Railw. Transp. Econ. 2024, 1–9. [Google Scholar]
- Zhang, G.; Wang, T.; Lou, Y. Analysis of China’s provincial carbon peak path based on LSTM neural network. Chin. Manag. Sci. 2024, 1–12. [Google Scholar]
- Wei, B.; Liu, C.; Liu, J. Multi-factor carbon emissions trading price prediction based on Transformer-LSTM model. Price Mon. 2024, 1–13. [Google Scholar]
- Weige, N.; Ou, A.; Huiming, D. A novel gray prediction model with a feedforward neural network based on a carbon emission dynamic evolution system and its application. Environ. Sci. Pollut. Res. Int. 2022, 30, 20704–20720. [Google Scholar]
- Wang, Q.; Wang, J.; Zhu, C. Research on carbon emission prediction of the transportation industry integrating VMD and SSA-LSSVR. Environ. Eng. 2023, 41, 124–132. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Liu, B.; Fu, C.; Li, J. Research on prediction of CO2 emissions in China based on PCA-SVR model. Arid Land Resour. Environ. 2018, 32, 56–61. [Google Scholar]
- Yu, S.; Zou, H.; Yu, F.; Fu, C.; Han, N. Application of Fuzzy Neural Network in Short-Term Load Forecasting of Power Systems. Smart Grid 2018, 46, 88–91+97. [Google Scholar]
- Fu, Y.; Cai, L.; Zheng, G. Failure diagnosis of electro hydraulic servo valve based on SA-PSO-SVM. J. Mech. Sci. Technol. 2022, 36, 5971–5976. [Google Scholar] [CrossRef]
- Peng, N.; Zhang, Y.; Wang, X.; Zhao, P. Research on Classification Method of Acoustic Emission Signals of Welding Cold Cracks Based on VMD Energy Entropy and GA-SVM. China Meas. Test 2024, 50, 47–53. [Google Scholar]
- Ren, W.; Yang, X.; Feng, Y.; Yang, L.; Wei, J. Prediction of Slope Deformation Based on GNSS Monitoring Using SSA-SVR Model. Saf. Environ. Eng. 2024, 31, 160–169. [Google Scholar]
- Ding, Y.; Zhang, Z.; Liu, H. Fault Detection of Transformer Resonance Overvoltage Based on Multi-source Feature Fusion. Electr. Eng. Econ. 2024, 162–164+167. [Google Scholar]
- Fan, S.; Zhao, Z.; Guo, J. A Review of Data-Driven Methods for Transient Stability Assessment of Power Systems. Proc. CSEE 2024, 44, 3408–3429. [Google Scholar]
- Singla, M.; Shukla, K.K. Robust statistics-based support vector machine and its variants: A survey. Neural Comput. Appl. 2020, 32, 11173–11194. [Google Scholar] [CrossRef]
- Shu, H.; Wu, D.; Chen, C. Analysis of Airtightness Detection Method for the Main Brake Cylinder of Electric Vehicles. China Mach. 2023, 77–80. [Google Scholar]
- Mu, S.; Shen, W.; Lv, D.; Song, W.; Tan, R. Research Progress on Electronic Nose Technology and Its Applications. Mater. Rep. 2024, 1–34. [Google Scholar]
- Yang, Y.; Liu, J.; Chen, T.; Wei, W.; Wang, S. Short-term natural gas load forecasting based on the PSO-SVR model. Sci. Technol. Eng. 2023, 23, 15210–15216. [Google Scholar]
- Liu, H.; Wang, L.; Wang, Y.; Xi, L. Wheat yield prediction method in Henan Province based on PSO-SVR model. J. Jiangsu Agric. Sci. 2023, 51, 157–163. [Google Scholar]
- Zhou, Q.; Zhang, X.; Chen, J.; Shen, W.; Bai, J.; Huang, Y.; Tang, S. Photovoltaic power station power generation prediction method based on genetic algorithm wavelet neural network. Smart Electr. 2024, 52, 78–84. [Google Scholar]
- Liu, Y.; Ding, S. Research on energy loss in green building design. Housing 2024, 104–107. [Google Scholar]
- Bao, X.; Liu, S.; Zhang, N. Computing power flexible migration optimization algorithm based on improved ant colony algorithm. Electr. Power Inf. Commun. Technol. 2024, 22, 1–8. [Google Scholar]
- Feng, L.; You, W. Short-term prediction technology of photovoltaic power generation based on ant colony algorithm. Commun. Inf. Technol. 2023, 36–39. [Google Scholar]
- Chen, K.; Ding, M.; Liu, J.; Duan, J.; Liu, C.; Xu, D. Short-term wind power forecasting based on improved grey wolf algorithm to optimize WLSSVM. Inn. Mong. Electr. Power Technol. 2024, 42, 1–7. [Google Scholar]
- Chen, P.; Zhou, J.; Wu, M. Research on online metering error prediction method for DC charging piles based on the improved GWO-GM(1,1) model. Mod. Electron. Technol. 2024, 47, 112–117. [Google Scholar]
- Chen, Y.; Ma, X.; Cheng, K.; Bao, T.; Chen, Y.; Zhou, C. Ultra-short-term power prediction of new energy based on meteorological feature selection and SVM model parameter optimization. J. Sol. Energy 2023, 44, 568–576. [Google Scholar]
- Liang, Z.; Zhou, Y.; Feng, D.; Guo, L.; Du, Y. Day-ahead optimal dispatch of the park’s comprehensive energy system considering the coupling of the electricity carbon green certificate market. Electr. Power Constr. 2023, 44, 43–53. [Google Scholar]
- Yao, H.; Li, C.; Yang, P. Building cooling capacity prediction based on the Sine-SSA-BP algorithm. Comput. Simul. 2023, 40, 525–529+540. [Google Scholar]
- Xie, S.; He, S.; Yan, X.; Zhang, Q. Photovoltaic short-term power prediction based on SSA-BP neural network. J. Zhejiang Univ. Technol. 2022, 50, 628–633. [Google Scholar]
- Yang, Y.; Li, L.; Lin, H. Parameter Parallelization: A Machine Learning Parameter Optimization Method Based on Swarm Heuristic Algorithm. Sci. Technol. Eng. 2022, 22, 1972–1980. [Google Scholar]
- Ni, D. Research on Corporate Credit Risk Prediction Based on High-Dimensional Small Sample Data. Ph.D. Thesis, Chongqing University, Chongqing, China, 2021; pp. 127–130. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995. [Google Scholar]
- Eberhart, R.C.; Kennedy, J. A New Optimizer Using Particle Swarm Theory. In Proceedings of the 6th International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995. [Google Scholar]
- Zou, H.; Song, J.; Liu, Y.; Duan, Z.; Zhang, X.; Song, L. Transmission Line Ice-Coating Galloping Prediction Model Based on PSO-SVM Algorithm. J. Vib. Shock 2023, 42, 280–286. [Google Scholar]
- Zhao, S.; Zhao, Z. A comparative study of landslide susceptibility mapping using SVR and PSO-SVR models based on grid and slope units. Math. Probl. Eng. 2021, 2021, 8854606. [Google Scholar]
- Zeng, Q.; Chen, G.; Li, W.; Meng, J.; Li, G.; Tong, J.; Tian, Z.; Zhang, X.; Li, G.; Guo, L.; et al. Rapid Detection and Classification of Steel Based on Particle Swarm Optimization-Support Vector Machine Algorithm Using Laser-Induced Breakdown Spectroscopy. Spectrosc. Spectr. Anal. 2024, 44, 1559–1565. [Google Scholar]
- Xu, H.; Tian, C.; Mao, R.; Gu, X.; Chang, C. Research on the Prediction Model of Air Material Consumption Based on PSO-SVM. Mod. Inf. Sci. Technol. 2024, 8, 142–145. [Google Scholar]
- Wang, K.; Niu, D.; Zhen, H.; Sun, L.; Xu, X. Research on China’s carbon emissions prediction based on the WOA-ELM model. Ecol. Econ. 2020, 36, 20–27. [Google Scholar]
- Wang, Y.; Li, Y.; Wang, H.; Dong, P.; Teng, Y.; Lin, Y.; Liu, L. Prediction of Carbon Emissions in Hebei Province Based on an Improved BP Neural Network. Ecol. Econ. 2024, 40, 30–37. [Google Scholar]
- Li, G.; Huang, Q. Scenario Prediction of Carbon Peak in Beijing-Tianjin-Hebei Region Based on Lasso-GRNN Neural Network Model. Environ. Sci. 2024, 1–21. [Google Scholar]
- Feng, M.; Zhou, D.; Yang, Y. SWOT Analysis and Countermeasure of Jilin Province Aviation Logistics Industry Development Strategy Based on Low Carbon and Environmental Protection. IOP Conf. Ser. Earth Environ. Sci. 2019, 252, 042043. [Google Scholar] [CrossRef]
- Shen, Y.; Liu, C. Mining of Users’ Key Needs Based on Opinion Leaders in Online Brand Communities. Comput. Technol. Dev. 2024, 34, 23–31. [Google Scholar]
- Li, Y.; Wang, Y. Urban rail transit section passenger flow prediction based on PSO-LSSVM algorithm. J. Chang. Univ. (Nat. Sci. Ed.) 2021, 41, 91–102. [Google Scholar]
- Hu, S.; Wang, P.; Zhao, X.; Zhang, G. Feature Extraction of Decision-Making Parameters in Spinning Production Process Based on Equidistant Feature Mapping. J. Mach. Des. 2024, 41, 82–90. [Google Scholar]
- Ma, Y.; Li, Y.; Ma, L. Spatial Correlation Effects and Influencing Factors of Green and Low-Carbon Development in China’s Logistics Industry. Environ. Sci. 2024, 1–13. [Google Scholar]
- The People’s Government of Jiangsu Province. Several Opinions of the CPC Jiangsu Provincial Committee and the Jiangsu Provincial People’s Government on Deeply Implementing the Strategy of Economic Internationalization and Comprehensively Improving the Development Level of an Open Economy. Bull. Jiangsu Prov. People’s Gov. 2012, 5–13.
- Zhu, X. Research on Evaluation and Prediction of High-Quality Development of China’s Logistics Industry. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2021. [Google Scholar]
- Wang, L.; Chen, Z. Research on the Efficiency of China’s Logistics Industry under Energy and Environmental Constraints; Nankai University Press: Tianjin, China, 2020; 141p. [Google Scholar]
- Wei, X.; Feng, X.; Jiang, H. Research on Carbon Emission Prediction Based on Multi-head Attention CNN-LSTM. J. Chongqing Technol. Bus. Univ. (Nat. Sci. Ed.) 2024, 1–11. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Energy | Coal | Coke | Crude | Gasoline | Kerosene | Diesel Fuel | Fuel Oil | Natural Gas | Electricity |
|---|---|---|---|---|---|---|---|---|---|
| Standard Coal Conversion Coefficient | 0.7143 | 0.9714 | 1.4286 | 1.4714 | 1.4714 | 1.4571 | 1.4286 | 1.3300 | 0.1229 |
| Carbon Emissions Coefficient | 0.7476 | 0.1128 | 0.5854 | 0.5532 | 0.3416 | 0.5913 | 0.6176 | 0.4479 | 2.213 |
| Factor Category | Identification | Specific Indicators |
|---|---|---|
| Economic Factors | Gross domestic product (GDP) | |
| Logistics gross product | ||
| Total social fixed-asset investment in the logistics industry | ||
| Total import and export trade | ||
| Actual used amount of foreign capital | ||
| Residents’ consumption level (absolute number) | ||
| Demographic Factors | Population size | |
| The proportion of the urban population | ||
| Number of employees in the tertiary industry | ||
| Energy Factors | Forest cover rate | |
| Total energy consumption (standard coal) | ||
| Technical Factors | Tertiary-industry-employed population |
| Influencing Factors | Identification | Correlation |
|---|---|---|
| Total Energy Consumption | 0.903 | |
| Number of Technological Achievements Registered | 0.820 | |
| Actual Used Amount of Foreign Capital | 0.813 | |
| Total Import and Export Trade | 0.802 | |
| Tertiary-Industry-Employed Population | 0.789 | |
| The Proportion of Urban Population in China | 0.779 | |
| Logistics Gross Product | 0.764 |
| Number | Actual Value (10,000 Tons) | Prediction Value (10,000 Tons) | Relative Error |
|---|---|---|---|
| 1 | 5177.19 | 5210.35 | 0.64% |
| 2 | 7586.50 | 7566.99 | 0.26% |
| 3 | 11,601.80 | 11,672.03 | 0.61% |
| 4 | 15,185.33 | 14,817.34 | 2.42% |
| 5 | 17,497.62 | 17,510.34 | 0.07% |
| 6 | 18,243.89 | 18,072.51 | 0.94% |
| Prediction | — | 17,842.95 | — |
| MAPE | 0.82% |
| Model | GM(1,1) | FGM(1,1) (r = 0.25) | ARIMA (0,1,0) | SVR (C = 4, γ = 0.8) | GWO-SVR (C = 2.9826, γ = 0.6979) | GA-SVR (C = 1.9033, γ = 2.1408) | PSO-SVR (C = 3.6261, γ = 0.1202) |
|---|---|---|---|---|---|---|---|
| MAPE | 9.47% | 7.01% | 3.83% | 2.03% | 1.16% | 1.15% | 0.82% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Pan, Y.; Zhang, D. Prediction of Carbon Emissions Level in China’s Logistics Industry Based on the PSO-SVR Model. Mathematics 2024, 12, 1980. https://doi.org/10.3390/math12131980
Chen L, Pan Y, Zhang D. Prediction of Carbon Emissions Level in China’s Logistics Industry Based on the PSO-SVR Model. Mathematics. 2024; 12(13):1980. https://doi.org/10.3390/math12131980
Chicago/Turabian StyleChen, Liang, Yitong Pan, and Dongqing Zhang. 2024. "Prediction of Carbon Emissions Level in China’s Logistics Industry Based on the PSO-SVR Model" Mathematics 12, no. 13: 1980. https://doi.org/10.3390/math12131980