Abstract
Regarding the existing models for feature extraction of complex similar entities, there are problems in the utilization of relative position information and the ability of key feature extraction. The distinctiveness of Chinese named entity recognition compared to English lies in the absence of space delimiters, significant polysemy and homonymy of characters, diverse and common names, and a greater reliance on complex contextual and linguistic structures. An entity recognition method based on DeBERTa-Attention-BiLSTM-CRF (DABC) is proposed. Firstly, the feature extraction capability of the DeBERTa model is utilized to extract the data features; then, the attention mechanism is introduced to further enhance the extracted features; finally, BiLSTM is utilized to further capture the long-distance dependencies in the text and obtain the predicted sequences through the CRF layer, and then the entities in the text are identified. The proposed model is applied to the dataset for validation. The experiments show that the precision (P) of the proposed DABC model on the dataset reaches 88.167%, the recall (R) reaches 83.121%, and the F1 value reaches 85.024%. Compared with other models, the F1 value improves by 3∼5%, and the superiority of the model is verified. In the future, it can be extended and applied to recognize complex entities in more fields.
MSC:
68T50
1. Introduction
Named entity recognition (NER) is a basic task of natural language processing, and is also one of the sub-tasks of knowledge extraction. The main objective is to identify and extract specific categories of entities, such as people’s names, places, aliases, etc., or domain-specific vocabulary from a large amount of text [1]. Chinese named entity recognition plays an important role in natural language processing technology as a component of information extraction, information retrieval, knowledge mapping, machine translation, and question answering systems [2].
In the development process of named entity recognition, people firstly mainly relied on lexicons and rule-based methods. These methods depended on hand-constructed rule templates by linguists, making them prone to errors and unable to be transplanted between different domains. Consequently, this approach could only handle simple text data but could not address complex unstructured data. Subsequently, with the advancement of machine learning, neural networks like word2vec [3] began to be applied in entity recognition. This model efficiently represents words into vector form based on a given corpus with an optimized training model, providing a new tool for applied research in natural language processing. For instance, Anil Sharma et al. [4] applied such methods for the ontology-based semantic retrieval of documents, enhancing the similarity index and accuracy of query results. With the advent of deep learning methods, pretrained models like BERT have been employed in named entity recognition. For instance, Zhao Xintong et al. [5] applied the BERT model in materials science named entity recognition, achieving promising results on the dataset. Gülsüm Kayabaşi Koru et al. [6] detected Turkish fake news from tweets using the BERT model, obtaining an precision (P) of 94% on the corpus set. However, BERT-based named entity recognition methods often neglect the relative positional information between text messages, exhibit insufficiently fine-grained feature extraction, and adopt a static masking strategy during masking. With the widespread application of the BERT model, the Facebook team led by Liu et al. [7] improved upon it by proposing the RoBERTa model. This model utilizes a larger training dataset compared to BERT and changes the masking strategy from static to dynamic, thereby enhancing performance. The RoBERTa model achieved an F1 value of 94.08% on the Chinese electronic medical record recognition domain dataset, surpassing previous models. Yin [8] et al. demonstrated that the NER model trained by their proposed method achieved an F1 value of 93.56% on actual winter sports textual news. Similarly, Li et al. [9] applied the RoBERTa model to predict nanoantibody paracrine sites, achieving excellent performance. Liang et al. [1] utilized the RoBERTa model for crop pest and disease name recognition, achieving precision, recall, and F1 values of 89.23%, 90.90%, and 90.04%, respectively. However, the RoBERTa model still underutilizes positional information of text data. Following this, He et al. [10] from the Microsoft team further improved BERT and introduced the DeBERTa model. Compared to BERT and RoBERTa, DeBERTa focuses on the impact of the relative position of text data on model performance. Yuna Jeong et al. [2] applied the DeBERTa model to information extraction from scientific and technical documents, demonstrating its superior performance in entity recognition tasks.
In previous work, Luo et al. [11] achieved better performance using the BiLSTM-CRF model, with F1 values of 91.14% and 92.57% for named entity recognition in the field of chemistry. Addressing the limitation of global probabilistic transfer modeling when using the BERT model alone for named entity recognition, Fábio Souza et al. [12] replaced the Softmax function with a CRF layer, resulting in a 1% to 4% improvement in the corpus of Portuguese named entity recognition. Building upon this, Dai et al. [13] utilized the BERT-BiLSTM-CRF model for named entity recognition of Chinese e-health records, achieving an F1 value of approximately 75%, which outperformed all other models during testing. Zhang et al. [14] further combined the RoBERTa-BiLSTM-CRF model for tourist attraction name extraction, outperforming other models on the dataset. Riyanto et al. [15] employed the BERT-BiLSTM-CRF model, achieving positive results on CLUENER2020. Arslan [16] utilized the BiLSTM-CRF model with FastText embeddings, achieving an F1 score value of 57.40%, a precision value of 55.78%, and a recall value of 59.12% in a Turkish e-commerce dataset. Chen et al. [17] applied the BERT-Bilstm-Selfatt-CRF model to public security department case records, holding significant implications for further utilization of this information. Jeong [18] utilized transfer learning to design an end-to-end information extraction framework based on BERT. Shibata et al. [19] evaluated the performance of named entity recognition (NER) and relation extraction (RE) using machine learning methods, revealing maximum micro-averaged F1 scores of 0.912 and 0.759 for NER and RE, respectively. Cai et al. [20] proposed a nested NER model based on span boundary perception, while Cai et al. [21] proposed an NER model that combines BERT, BiLSTM, and CRF based on adversarial training (ATBBC), achieving an F1 score of 85.39% on the test dataset. Cui et al. [22] designed a method based on prompt learning to reformulate the entity recognition task into a language inference-based task. Fan et al. [23] created a specialized training corpus and introduced a novel few-shot NER framework, yielding precision, recall, and F1 of 91.08%, 88.96%, and 90.00%, respectively. Farhan et al. [24] proposed a new NER solution by leveraging state-of-the-art NLP tools, while Goyal et al. [25] proposed a deep learning-based NER system using hybrid embedding, which is a combination of FastText and bidirectional LSTM-based character embedding. Mao et al. [26] proposed a simple yet effective span-level tagging scheme for discontinuous NER. Wang et al. [27] proposed a multi-modal feature fusing module based on the RoBERTa network, achieving state-of-the-art performance in recall and F1 score on three public datasets. Wu et al. [28] proposed an improved bidirectional gated recurrent unit neural network (BIGRU) method. Xu et al. [29] introduced a novel NER methodology tailored for the Chinese cybersecurity corpus, termed CSBERT-IDCNN-BiLSTM-CRF, surpassing existing Chinese NER frameworks with an F1 score of 87.30% and a precision rate of 85.89%. Cao et al. [30] introduced a new pretraining scheme that uses large-scale online question–answer pairs to enhance the model capacity on online biomedical text. Chu et al. [31] developed a named entity recognition model called Multi-Feature Fusion Transformer (MFT), which combines features such as words and radicals to enhance the semantic information of the sentences. Hu et al. [32] highlighted the potential of large language models, specifically GPT-3.5 and GPT-4, in processing complex clinical data and extracting meaningful information with minimal training data. Li et al. [33] proposed the Semantic Embedding with Chinese Character Structural Features (SECCSF) method to improve the accuracy of segmentation boundary detection and entity category determination in CNER. Mengliev [34] developed two algorithms that identify named entities in Uzbek language texts using a dictionary. Qiu et al. [35] established standards and principles governing engineering geology reports, achieving an impressive F1 value of 79.60% on the constructed datasets. Wang et al. [36] combined discourse topic and attention mechanism and proposed the Attention-based SoftLexicon with TF-IDF (ASLT) for agricultural diseases and pests entity recognition, achieving favorable recognition on CCNEDP, with the recognition accuracy, the recall rate, and the value of F1 of 93.57, 92.79, and 93.18%. Abdelghani Dahou et al. [37] proposed a framework that harnesses the potential of an MTL approach and a state-of-the-art pretrained transformer-based model, enabling the extraction of comprehensive contextual features from Arabic social media posts. The framework attained an accuracy rate of 87% and 69% for binary and multi-classification, respectively. Nasir Ayub et al. [38] presented a novel approach called the Ensemble of DenseNet based on Aquila Optimizer (EDAO); the model achieved accuracy rates of 95%, 97%, and 96%, respectively, with DenseNet-AO. However, the above models do not address the problem of further refinement of features.
As mentioned above, this paper proposes a new named entity recognition model, DABC, with the aim of enhancing accuracy and robustness in Chinese entity recognition. Firstly, considering the ineffective utilization of text data location information in the BERT-BiLSTM-CRF model, the DeBERTa module is introduced to address this deficiency and improve the utilization of location information. Subsequently, to address the issue of insufficient refinement in key feature extraction within the DeBERTa-BiLSTM-CRF model, a multi-attention mechanism is incorporated to enhance key feature extraction refinement. The DABC model introduced in this paper exhibits enhanced entity recognition capabilities and improved model robustness.
However, existing models still face challenges in performing named entity recognition tasks:
1. The utilization of relative position information in text for feature extraction remains flawed.
2. Insufficient attention is given to key features during entity feature extraction.
Therefore, further improvements are necessary for the model.
2. The BERT-BiLSTM-CRF Model
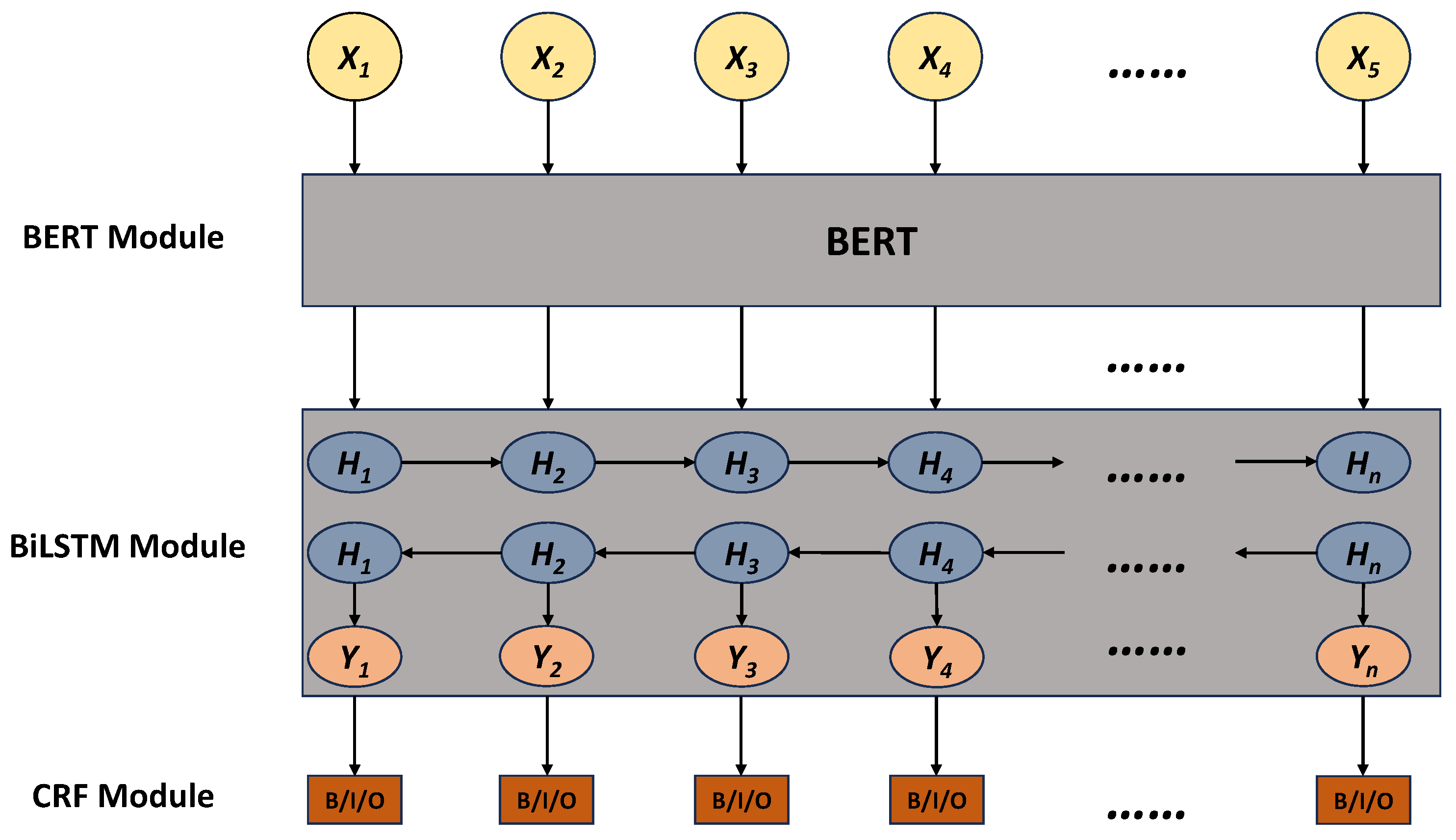
Named entity recognition, as a fundamental task in natural language processing, has been the focus of this research. As a named entity recognition model that has been widely recognized, the BERT-BiLSTM-CRF model has been applied in named entity recognition work in several fields with good results. Its basic framework is shown in Figure 1.
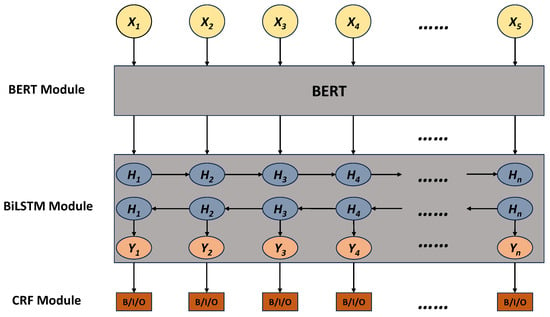
Figure 1.
BERT-BiLSTM-CRF model framework.
Firstly, word vectors based on contextual information are generated through pre-processing with the BERT model. Secondly, the trained word vectors are fed into the BiLSTM-CRF model for further training [16]. BERT is a transformer-based pretrained language model that extracts contextual representations of text. It learns rich linguistic knowledge through unsupervised pretraining on large-scale corpora and can be fine-tuned for downstream tasks [13]. BiLSTM is a recurrent neural network with hidden states in both forward and backward directions, capturing sentence structure and dependencies in text. It effectively models contextual information and better understands the relationship between labels at the current location and the preceding and following text through bidirectional computation [11]. CRF is a conditional random field for labeling sequences, considering label interactions and using a global inference algorithm to optimize labeling results for entire sequences. The CRF model captures contextual constraints and transition patterns between labels in sequence labeling tasks [12].
The BERT-BiLSTM-CRF model is a mature and widely recognized named entity recognition model. It was selected because its advantage lies in eliminating the need for pretraining word vectors and inputting sequences directly into BERT, which automatically extracts rich features. However, the BERT-BiLSTM-CRF model still has certain shortcomings:
(1) The BERT model does not make further use of the location information of text data when extracting features.
(2) The features extracted by the BERT model are not prominent and refined enough.
3. DABC Model
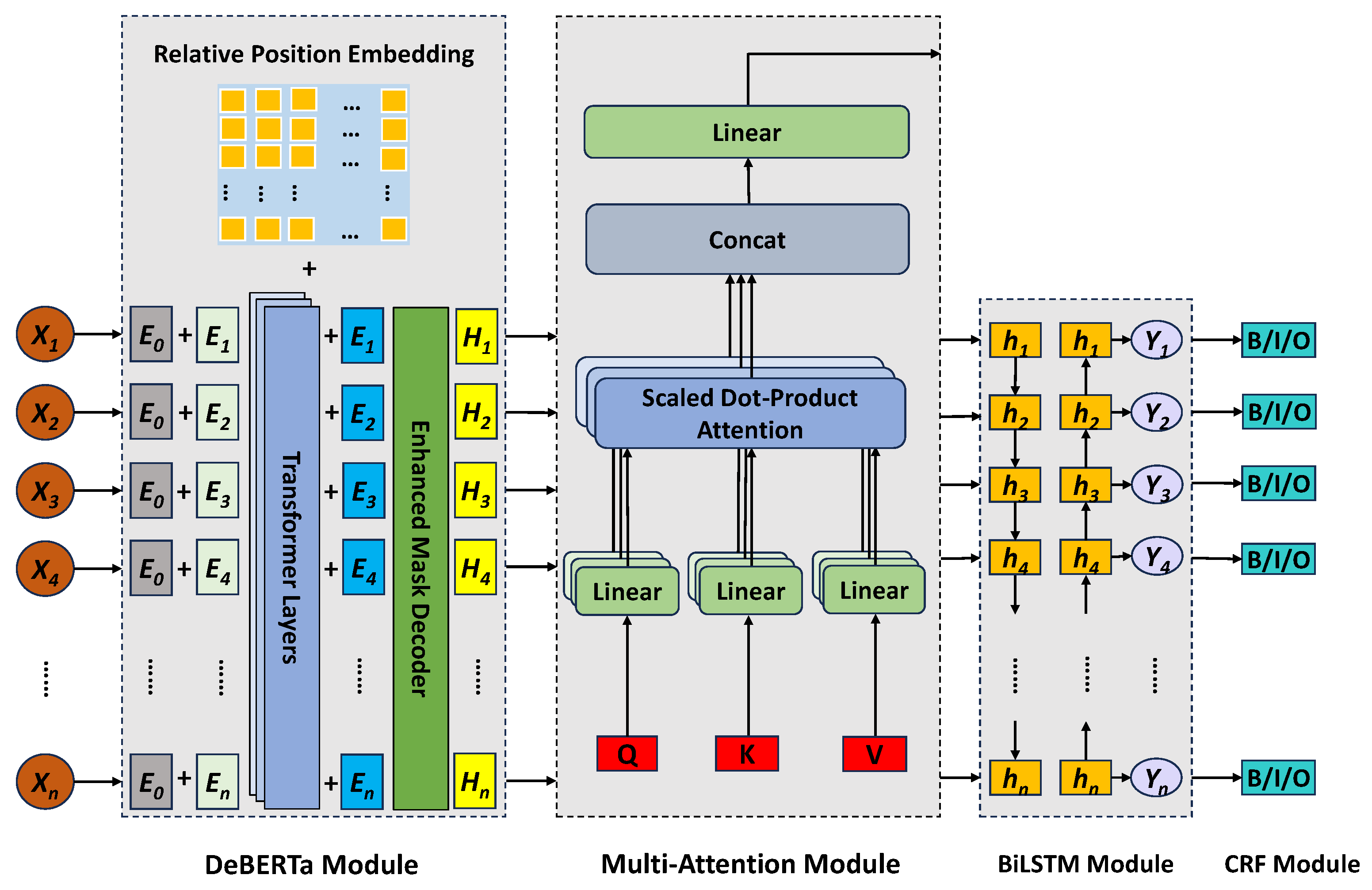
In this paper, we propose a new entity recognition model called DABC, which aims to enhance the accuracy and robustness of Chinese entity recognition. The model is based on BERT-BiLSTM-CRF, with the introduction of the DeBERTa model. Addressing the issue of insufficient refinement in the BERT model’s feature extraction process, a multi-attention mechanism is incorporated into the DeBERTa-BiLSTM-CRF model to enhance the model’s focus on key information. The proposed model framework is depicted in Figure 2.
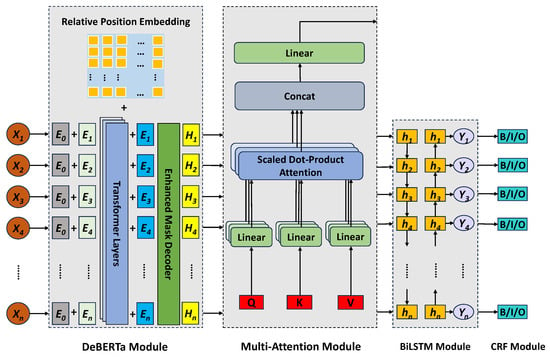
Figure 2.
DABC model framework.
Firstly, the feature extraction capability of the DeBERTa model is utilized to extract the data features. Then, the attention mechanism is introduced to further enhance the extracted features. Finally, BiLSTM is employed to capture the long-distance dependencies in the text and obtain the predicted sequences through the CRF layer, thus identifying the entities in the text.
3.1. DeBERTa Module
As a further improvement of the BERT model by the Microsoft team led by He et al. [10], the DeBERTa model enhances the model’s ability to focus on the relative position of text data as information during feature extraction by introducing a decoupled attention mechanism. Unlike BERT, where each word in the input layer is represented by the sum of its word (content) embedding and positional embedding, each word in DeBERTa is represented by two vectors encoding its content and position, respectively. The attention weights between words are computed using matrices based on their content and relative position. This is because attention between words depends not only on their textual content but also on their relative positions. The attention calculation is represented as in Equation (1):
where represents the calculated weights, and H and P represent the content information and position information, respectively. In the equation, i and j are tokens, and and represent content and position. The whole formula can be divided into four parts: content–content (content-to-content), content–position (content-to-position), position–content (position-to-content), and position–position (position-to-position). Taking a single header as an example, the standard self-attention is given in Equations (2)–(6) below:
where denotes the input hidden vector, denotes the output of self-attention, denotes the corresponding projection matrix, is the attention matrix, N is the length of the input sequence, and d is the dimensionality of the hidden state. The decoupled attention formulation with the addition of relative position information becomes the following Equations (7)–(13):
where , , and are the projected content vectors generated using the projection matrices , , and , respectively; denotes the relative positional embedding vector shared across all layers (i.e., it remains unchanged during forward propagation); and and are the projected relative position vectors generated using the projection matrices , and , respectively. are elements in the attention matrix denoting the attention between token i to token j, denotes the row of , denotes the row of , denotes the row of , and denotes the row. It should be noted that is used here instead of ; this is because given the position, the position–content calculates the attention weight of the content at position j in the key with respect to position i in the query, and thus the relative distance is . The position–content term is computed as . The content–position term is computed similarly. is divided by a scaling factor to stabilize the training process of the model.
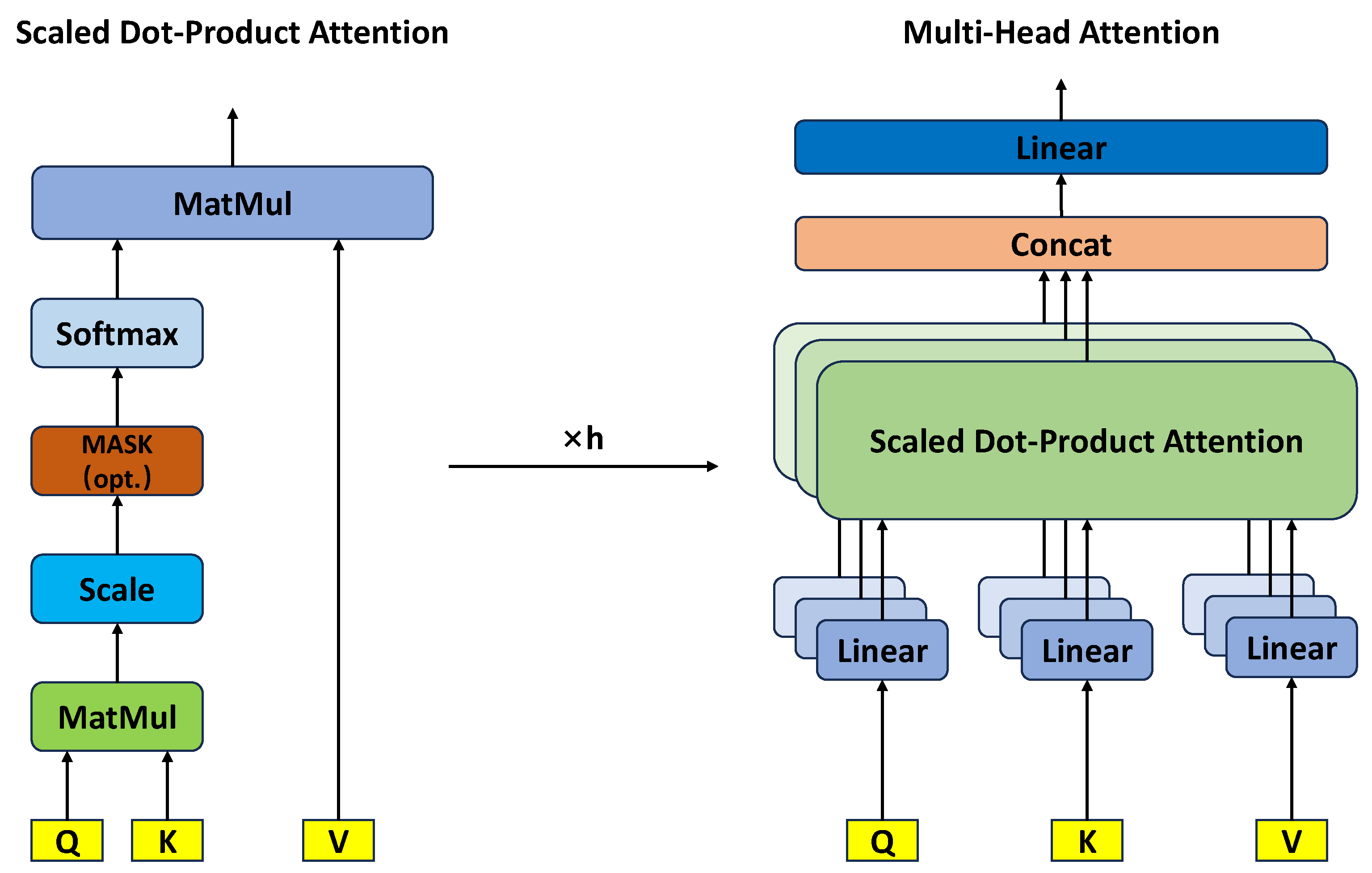
3.2. Multi-Attention Mechanisms
The concept of attention was first introduced by Dzmitry Bahdanau et al. [39]. Subsequently, the paper “Attention Is All You Need” by Ashish Vaswani et al. [40] elevated the attention mechanism to a new level. In the standard attention mechanism, a weighted context vector is computed to represent the information in the input sequence. In contrast, in multi-head attention, multiple sets of attention weights are used, each of which learns different information and produces a context vector. Finally, these context vectors are concatenated together, followed by a linear transformation to obtain the final output. The framework is illustrated in Figure 3.
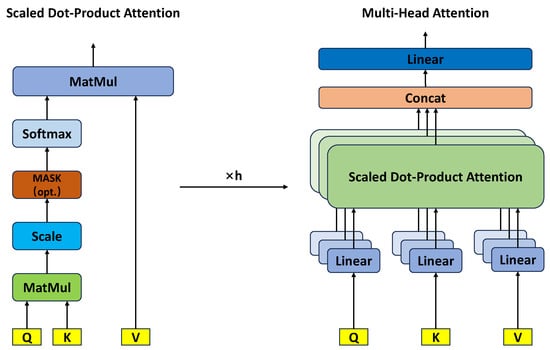
Figure 3.
Multi-attention framework.
Attention need linear transformation.The attention calculation process for the input matrix X (which includes the query Q, key K, and value V) is as Equations (14)–(16):
where , , and are the learnable parameter matrices.
The advantages of the multi-attention mechanism are as follows:
1. The features of input data can be learned from multiple dimensions, which improves the model’s ability to capture information.
2. Each head can perform computation independently, which is suitable for parallel processing and improves computational efficiency.
3. The complexity and performance of the model can be flexibly controlled by adjusting the number and dimension of the heads. The mathematical formula is given in Equation (17) below:
Multi-head attention takes the process of Scaled Dot-Product Attention and performs it h times, outputting its sum.
4. Experimentation and Analysis
4.1. Experimental Datasets and Evaluation Methods
The datasets used in this experiment are the Liaoning island dataset and Resume dataset. The Liaoning island dataset is mainly derived from the “China Island Journal (Liaoning Volume)”. In order to make the dataset larger in order of magnitude, this paper uses the network to crawl public information and a small amount of the People’s Daily dataset for a supplement and expansion. This is so that the information in it is more complex and varied, so as to construct a large dataset. Using the “BIO” labeling method, “LOC” presents location, “DOM” presents topography and landscapes, and “TOZ” presents soil and tree. For example, “厦 B-LOC” and “门 I-LOC” represent the cities of China and “岩 B-DOM”, “壁 I-DOM”, “陡 I-DOM”, and “峭 I-DOM” represent topography and landscapes. A total of seven tags are set up as follows: “B-LOC”, “I-LOC”, “B-DOM”, and “I-DOM”, “B-TOZ”, “I-TOZ”, and “O”, where the number of LOC entity tags is 3143, there are 3129 DOM tags, and 2410 TOZ entity tags, as shown in Table 1.

Table 1.
Labels dstribution of the Liaoning island dataset.
The Liaoning island dataset training set, validation set, and test set are divided according to an 8:1:1 ratio. The dataset we used has 9517 sentences in which the training set is 7566 sentences, validation set is 856 sentences, and test set is 1095 sentences, as shown in Table 2.
Table 2.
Dataset distribution of the Liaoning island dataset.
Another dataset used is the Resume dataset, which is published by the Alibaba Tianchi Competition, and it uses the “BIO” labeling method. This dataset has 8 types of entity, including “CONT” representing nation, “EDU” representing education, “LOC” representing location, “NAME” representing name, “ORG” representing organization, “PRO” representing, “RACE” representing race, and “TITLE” representing title. For example, “汉 B-RACE” and “族 I-RACE” represent the race of interviewee and “本 B-EDU”, “科 I-EDU”, “学 I-EDU”, and “历 I-EDU” represent whether this interviewee is holding a bachelor’s degree. A total of seven tags are set up as follows: “B-CONT”, “I-CONT”, “B-EDU”, “I-EDU”, “B-LOC”, “I-LOC”, “B-ORG”, “I-ORG”, “B-NAME”, “I-NAME”,“B-PRO“, “I-PRO“, “B-RACE”, “I-RACE”, “B-TITLE”, “I-TITLE”, and “O”.
Additionally, the Resume dataset training set, validation set, and test set are divided according to a 8:1:1 ratio. The dataset we uses has 4761 sentences in which the training set is 3821 sentences, validation set is 463 sentences, and test set is 477 sentences, as shown in Table 3.
Table 3.
Dataset distribution of the Resume dataset.
4.2. Experimental Environment
4.2.1. Environmental Setup
This experiment is built based on the Pytorch platform, and the specific training environment configuration is shown in Table 4.
Table 4.
Experimental environment.
4.2.2. Parameterization
In the process of performing model training, this paper chooses Adam in terms of optimizer; the learning rate is set to , the length is set to 128, the dropout is set to 0.5 to prevent the model from overfitting, and the number of heads of the multi-head attention mechanism is set to 8. The specific parameter settings are shown in Table 5.
Table 5.
Parameter configuration.
4.3. Model Validation
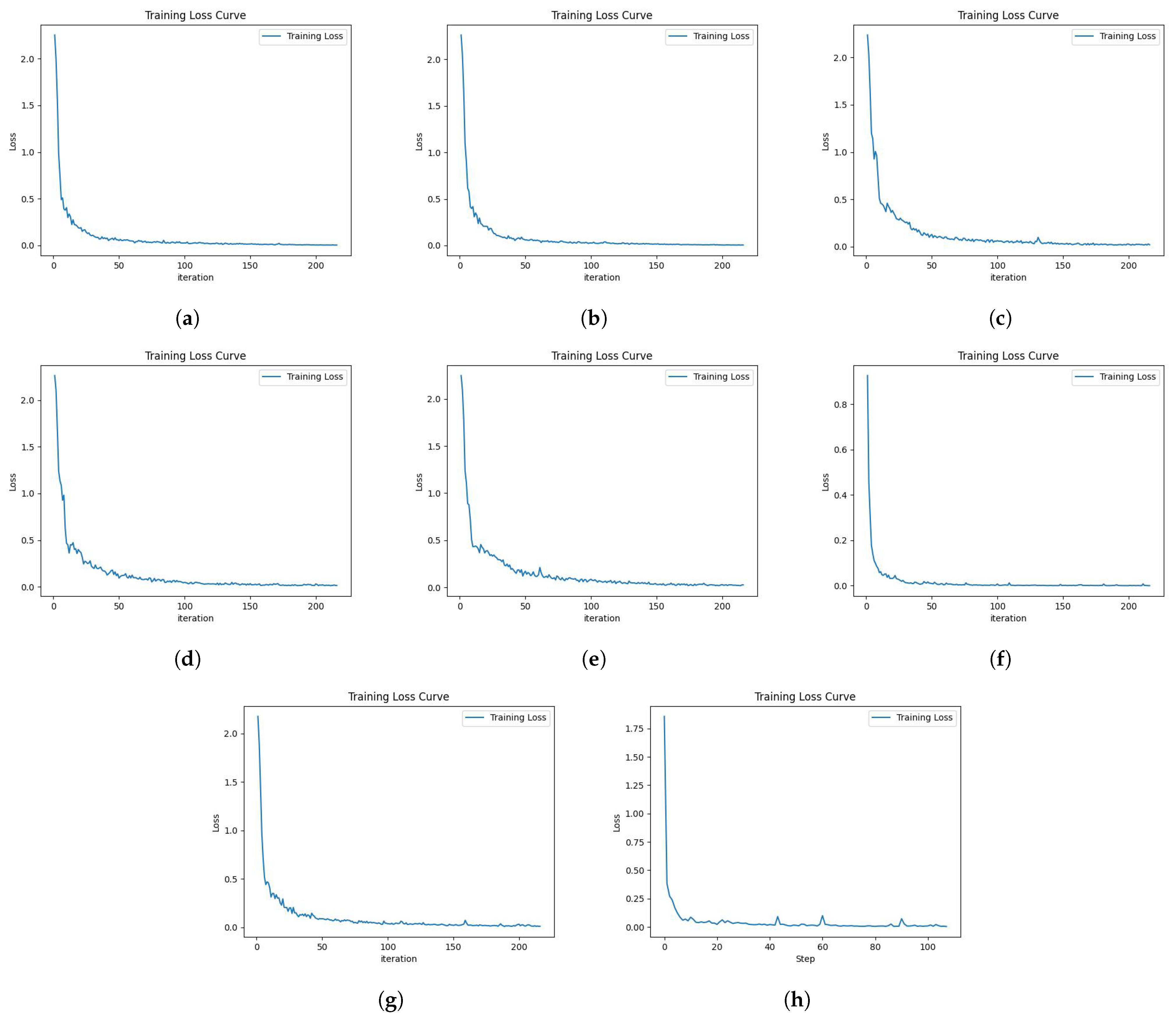
When the model is trained, it can be observed that the training loss curve converges from high to low eventually and is close to 0, which proves the correctness of the model’s training process; the loss curve is shown in Figure 4.
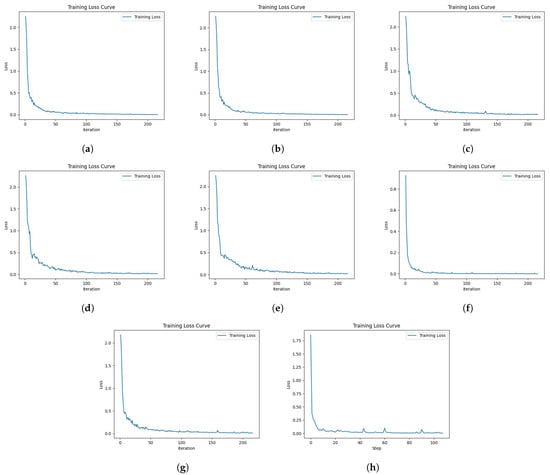
Figure 4.
Training loss curves; (a) BERT-BiLSTM-CRF training loss curve; (b) DeBERTa-BiLSTM-CRF training loss curve; (c) BERT-Attention-BiLSTM-CRF training loss curve; (d) DeBERTa-BiLSTM-Attention-CRF training loss curve; (e) DebERTa-Self Attention-BiLSTM-CRF training loss curve; (f) DABC training loss curve; (g) RoBERTa-BiLSTM-CRF training loss curve; (h) XLNET training loss curve.
From the descending process of the loss curve, it can be seen that the model in this paper converges from about 1.4 to near 0.1 after iteration, which proves that the model has stability after many rounds of iteration, and the performance of the model in the training and validation sets is more stable compared to the time when the training was first started. The underperforming model is improved by constantly updating the model, so that we can finally obtain the model that is stable and has excellent performance.
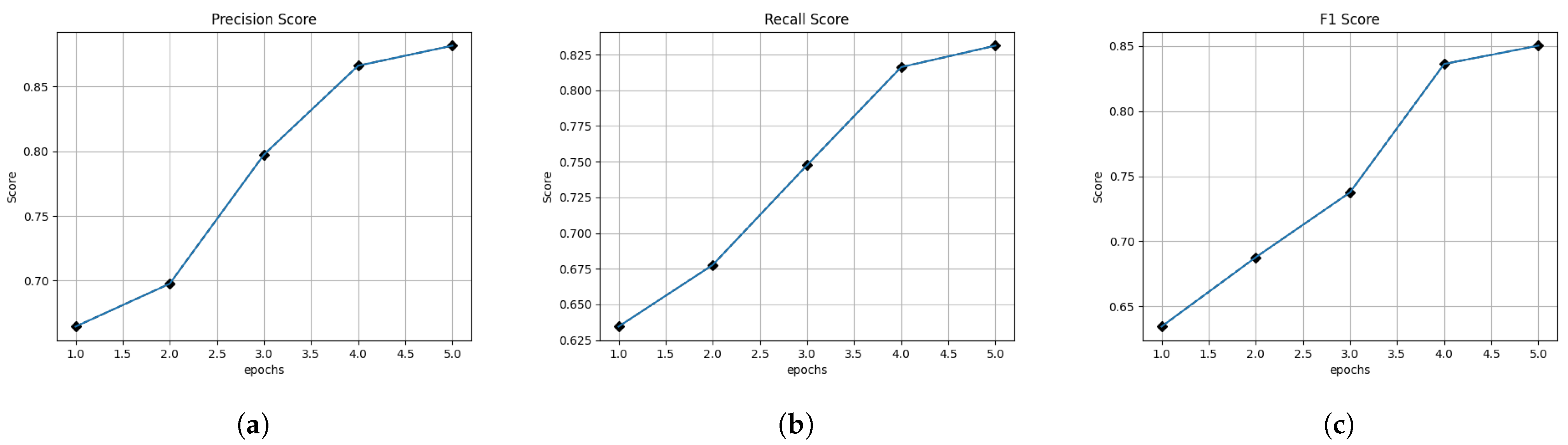
It can be seen that the model proposed in this paper has strong robustness after many rounds of iterations. The variation of its scores is shown in Figure 5.
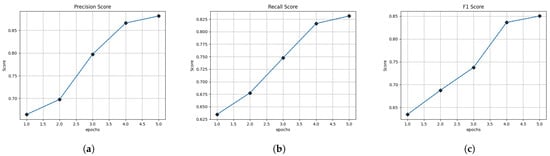
Figure 5.
Variation in scores. (a) Variation in precision scores. (b) Variation in recall scores. (c) Variation in F1 scores.
From the data, it is proved that the difference between the performance of the model proposed in this paper on the training set and the test set is within the acceptable range, thus the effectiveness of the model proposed in this paper is verified.
From the figure, it can be seen that as the number of training rounds grows, the F1 value of the model on the validation set also grows, which indicates that the performance of the model becomes better with the increase in the number of rounds, which proves the error-free training of the model.
At the time of model validation, the performance on the training set and test set is shown in Table 5.
The data in Table 6 show the performance of the model on the training and test sets. In terms of precision (P), the model has a value of 88.055% on the training set and 88.167% on the test set, with a difference in value of 0.112%. In terms of recall (R), the model has a value of 83.110% on the training set and 83.121% on the test set, with a difference in value of 0.010%. In terms of F1 value, the model has a value of 85.013% on the training set and 85.024% on the test set with a difference of 0.011%.
Table 6.
Model performance.
The experiments show that the DABC model sometimes treats island names and place names as similar. Such as “大三山岛 (Da Sanshan island)” and “大连 (Dalian city)”; that is why the DABC model can still be improved. In “TOZ” tags, the model sometimes treats soil and empty lots as similar, such as “苔藓 (moss)” and “无土壤和植被 (no soil and vegetation)”. And in “DOM” tags, the model sometimes treats stone and landscapes as similar, such as “基岩 (bedrock)” and “岩壁陡峭 (cliff)”.
In the Resume dataset, the model also mixes up similar entities. Because these category words in Chinese have a high similarity, the performance of model is influenced by this factor.
Due to the unpredictability and randomness of random errors, they cannot be completely eliminated. However, through repeated experiments, we have managed to control them within a reasonable range, thereby improving the accuracy of the results. The precision (P), recall (R), and F1 of every tag are shown in Table 7 and Table 8.
Table 7.
Model performance in Liaoning island dataset.
Table 8.
Model performance in Resume dataset.
4.4. Ablation Experiments
When module substitution and introduction are performed, the paper validates their effects respectively, and the results are shown in Table 9.
Table 9.
Ablation experiments.
The results of the ablation experiments show that, compared with the baseline model, the introduction of the DeBERTa module improves the precision (P) from 80.919% to 85.016%, with an improvement of 4.097%; the recall (R) from 75.299% to 80.210%, with an improvement of 4.911%; and the F1 value from 77.102% to 81.854%, with an improvement of 4.752%. The model has a significant improvement in performance, thus proving the effectiveness of replacing the BERT module with the DeBERTa module in this paper.
After the introduction of the attention mechanism compared to the baseline model, the precision (P) decreases from 80.919% to 76.050%; the F1 value decreases from 77.102% to 76.449%; and the model performance decreases. After replacing the BERT module with the DeBERTa module, compared to the baseline model the precision (P) improves from 80.919% to 86.402%, with a 5.483% improvement; recall (R) from 75.299% to 80.300%, with a 5.001% improvement; and F1 value from 77.102% to 82.490%, with a 5.388% improvement. Compared with the baseline model, there is an increase in performance, and it can be concluded that the integration between the BERT module and the attention module is not as good as that between the DeBERTa module and the attention module in the Liaoning sea island dataset. It can be concluded that the fusion between the BERT module and the attention module in the Liaoning island dataset is not as effective as the fusion between the DeBERTa module and the attention module.
By changing the location of the attention module, precision (P) improves from 82.983% to 86.402%, recall (R) from 77.507% to 80.300%, and F1 value from 79.130 to 82.490%. It can be determined that the attention module is more suitable to be located between the DeBERTa module and BiLSTM module for the Liaoning sea island dataset. Finally, replacing the self attention module with multi-head attention module improves the precision (P) from 80.919% to 88.167% with 7.248%, recall (R) from 75.299% to 83.121% with 7.822%, and F1 value from 77.102% to 83.121% with a 7.822% improvement. The F1 value increases from 77.102% to 85.024% with a 7.922% improvement, and the model achieves the best results compared with other models on the Liaoning sea island dataset. The experiment illustrates the effectiveness and superiority of the DABC model proposed in this paper.
4.5. Comparative Experiments
In order to make an objective evaluation of the proposed model in this paper, the performance of the XLNet, RoBERTa-wwm-BiLSTM-CRF, and DeBERTa-BiLSTM-CRF models on the Liaoning island dataset of this paper are selected to compare with the model of this paper to validate the performance level of the model.
Table 10.
Comparative experiments On the Liaoning sea island dataset.
Table 11.
Comparative experiments on Resume dataset.
On the Liaoning sea island dataset used in this paper, the proposed DABC model is compared with the BERT-BiLSTM-CRF model. It showed improvement in terms of precision (P) from 80.919% to 88.167%, with a 7.248% improvement; recall (R) increased from 75.299% to 83.121%, with a 7.822% improvement; and in terms of F1 value, it rose from 77.102% to 85.024%, with a 7.922% increase.
Compared with the XLNET model there is a 2.603% improvement in the precision (P) from 85.564% to 88.167%, a 0.842% improvement in the recall (R) from 82.279% to 83.121%, and a 1.141% improvement in the F1 value from 83.889% to 85.024%.
Compared with the RoBERTa-wwm-BiLSTM-CRF model, it improves from 83.703% to 88.167% in terms of precision (P), with an improvement of 4.464%; from 78.651% to 83.121% in terms of recall (R), with an improvement of 4.47%; and from 80.169% to 85.024% in terms of F1 values. The F1 value increased from 80.169% to 85.024%, with an improvement of 4.855%.
Compared with DeBERTa-BiLSTM-CRF model, in terms of precision (P), it increased from 85.016% to 88.167%, so there is a 3.151% improvement; in terms of recall (R) from 80.201% to 83.121%, so there is a 2.920% improvement; and in terms of F1 value from 81.854% to 85.024%, so there is a 3.17% improvement in F1 value.
On the Resume dataset used in this paper, the proposed DABC model is compared with the BERT-BiLSTM-CRF model. In terms of precision (P), it increased from 80.937% to 90.130%, with a 9.193% improvement; recall (R) went from 80.836% to 88.599%, with a 7.763% improvement; and in terms of F1 value, it rose from 80.732% to 88.918%, with a 8.186% increase.
Compared with the XLNET model, there is a 3.462% improvement in the precision (P) from 86.668% to 90.130%, a 4.144% improvement in the recall (R) from 84.455% to 88.599%, and a 3.371% improvement in the F1 value from 85.547% to 88.599%.
Compared with the RoBERTa-wwm-BiLSTM-CRF model, it improves from 90.013% to 90.130% in terms of precision (P), with an improvement of 0.117%; from 85.668% to 88.599% in terms of recall (R), with an improvement of 2.931%; and from 87.081% to 88.918% in terms of F1 values with an improvement of 1.837%.
Compared with DeBERTa-BiLSTM-CRF model, in terms of precision (P) it increased from 88.505% to 90.130%, so there is a 1.625% improvement; in terms of recall (R) from 86.162% to 88.599%, so there is a 2.437% improvement; and in terms of F1 value from 86.287% to 88.918%, so there is a 2.631% improvement in F1 value. These comparative experiments verify the superiority of the proposed model in this paper.
5. Conclusions
To address the issue of underutilized relative position information in text data and insufficient attention to key features during feature extraction, this paper proposes a new entity recognition model called DABC. The aim is to enhance the accuracy and robustness of recognizing Chinese entities. Building upon the BERT-BiLSTM-CRF model, the DeBERTa model is introduced to rectify the deficiency in BERT’s utilization of relative position information in text data and improve overall model performance. Additionally, to address the issue of insufficient attention to key features in the DeBERTa-BiLSTM-CRF model, a multi-attention mechanism is incorporated to enhance the model’s ability to focus on key features. The proposed model is validated and analyzed using the Liaoning sea island dataset. Experimental results show that the DABC model has an improvement in F1 values compared to the other models. This validates the effectiveness of the proposed model. Compared to other models, the DABC model shows an improvement in the F1 value ranging from 2% to 5%, further confirming its superiority. The results indicate that the DABC model proposed in this paper effectively utilizes the location information of text data and focuses on key information. The model we proposed still has efficiency shortcomings compared to previous models. Further research is needed in the future; future work will explore additional domains in named entity recognition to uncover further opportunities for improvement.
Author Contributions
Conceptualization, F.L. (Fan Li); Methodology, F.L. (Fangling Leng); Software, F.L. (Fan Li); Validation, F.L. (Fan Li); Investigation, T.Z.; Data curation, F.L. (Fan Li); Writing—original draft, F.L. (Fangling Leng); Writing—review and editing, G.Y.; Supervision, Y.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant numbers 62137001 and 62272093).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Liang, J.; Li, D.; Lin, Y.; Wu, S.; Huang, Z. Named entity recognition of Chinese crop diseases and pests based on RoBERTa-wwm with adversarial training. Agronomy 2023, 13, 941. [Google Scholar] [CrossRef]
- Jeong, Y.; Kim, E. Scideberta: Learning deberta for science technology documents and fine-tuning information extraction tasks. IEEE Access 2022, 10, 60805–60813. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Sharma, A.; Kumar, S. Ontology-based semantic retrieval of documents using Word2vec model. Data Knowl. Eng. 2023, 144, 102110. [Google Scholar] [CrossRef]
- Zhao, X.; Greenberg, J.; An, Y.; Hu, X.T. Fine-tuning BERT model for materials named entity recognition. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 3717–3720. [Google Scholar]
- Koru, G.K.; Uluyol, Ç. Detection of Turkish Fake News from Tweets with BERT Models. IEEE Access 2024, 12, 14918–14931. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yin, X.; Zheng, S.; Wang, Q. Fine-grained chinese named entity recognition based on roberta-wwm-bilstm-crf model. In Proceedings of the 2021 6th International Conference on Image, Vision and Computing (ICIVC), Qingdao, China, 23–25 July 2021; pp. 408–413. [Google Scholar]
- Li, S.; Meng, X.; Li, R.; Huang, B.; Wang, X. NanoBERTa-ASP: Predicting nanobody paratope based on a pretrained RoBERTa model. BMC Bioinform. 2024, 25, 122. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. arXiv 2020, arXiv:2006.03654. [Google Scholar] [CrossRef]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics 2018, 34, 1381–1388. [Google Scholar] [CrossRef]
- Souza, F.; Nogueira, R.; Lotufo, R. Portuguese named entity recognition using BERT-CRF. arXiv 2019, arXiv:1909.10649. [Google Scholar]
- Dai, Z.; Wang, X.; Ni, P.; Li, Y.; Li, G.; Bai, X. Named entity recognition using BERT BiLSTM CRF for Chinese electronic health records. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, Biomedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; pp. 1–5. [Google Scholar]
- Zhang, C.; Zhang, Y.; Zhang, J.; Yao, J.; Liu, H.; He, T.; Zheng, X.; Xue, X.; Xu, L.; Yang, J.; et al. A Deep Transfer Learning Toponym Extraction and Geospatial Clustering Framework for Investigating Scenic Spots as Cognitive Regions. ISPRS Int. J. Geo-Inf. 2023, 12, 196. [Google Scholar] [CrossRef]
- Riyanto, S.; Sitanggang, I.S.; Djatna, T.; Atikah, T.D. Plant-Disease Relation Model through BERT-BiLSTM-CRF Approach. Indones. J. Electr. Eng. Inform. (IJEEI) 2024, 12, 113–124. [Google Scholar] [CrossRef]
- Arslan, S. Application of BiLSTM-CRF model with different embeddings for product name extraction in unstructured Turkish text. Neural Comput. Appl. 2024, 36, 8371–8382. [Google Scholar] [CrossRef]
- Chen, X.; Tong, X.; Lin, H.; Xing, Y. Entity Recognition Method for Key Information of Police Records Based on Bert-Bilstm-Selfatt-Crf. Acad. J. Comput. Inf. Sci. 2024, 7, 78–85. [Google Scholar]
- Jeong, H. A Transfer Learning-Based Pairwise Information Extraction Framework Using BERT and Korean-Language Modification Relationships. Symmetry 2024, 16, 136. [Google Scholar] [CrossRef]
- Shibata, D.; Shinohara, E.; Shimamoto, K.; Kawazoe, Y. Towards Structuring Clinical Texts: Joint Entity and Relation Extraction from Japanese Case Report Corpus. In MEDINFO 2023—The Future Is Accessible; IOS Press: Amsterdam, The Netherlands, 2024; pp. 559–563. [Google Scholar]
- Cai, Y.; Luo, D.; Gan, Y.; Hou, R.; Liu, X.; Liu, Q.; Shi, X. Nested Named Entity Recognition Based on Span Boundary Perception. J. Softw. 2024, 1–14. [Google Scholar] [CrossRef]
- Cai, B.; Tian, S.; Yu, L.; Long, J.; Zhou, T.; Wang, B. ATBBC: Named entity recognition in emergency domains based on joint BERT-BILSTM-CRF adversarial training. J. Intell. Fuzzy Syst. 2024, 46, 4063–4076. [Google Scholar] [CrossRef]
- Cui, Z.; Yu, K.; Yuan, Z.; Dong, X.; Luo, W. Language inference-based learning for Low-Resource Chinese clinical named entity recognition using language model. J. Biomed. Inform. 2024, 149, 104559. [Google Scholar] [CrossRef]
- Fan, Y.; Xiao, H.; Wang, M.; Wang, J.; Jiang, W.; Zhu, C. Few-shot named entity recognition framework for forestry science metadata extraction. J. Ambient. Intell. Humaniz. Comput. 2024, 15, 2105–2118. [Google Scholar] [CrossRef]
- Farhan, N.; Sarker Joy, S.; Binte Mannan, T.; Sadeque, F. Gazetteer-Enhanced Bangla Named Entity Recognition with BanglaBERT Semantic Embeddings K-Means-Infused CRF Model. arXiv 2024, arXiv:2401.17206. [Google Scholar] [CrossRef]
- Goyal, A.; Gupta, V.; Kumar, M. Deep learning-based named entity recognition system using hybrid embedding. Cybern. Syst. 2024, 55, 279–301. [Google Scholar] [CrossRef]
- Mao, T.; Xu, Y.; Liu, W.; Peng, J.; Chen, L.; Zhou, M. A simple but effective span-level tagging method for discontinuous named entity recognition. Neural Comput. Appl. 2024, 36, 7187–7201. [Google Scholar] [CrossRef]
- Wang, M.; Chen, H.; Shen, D.; Li, B.; Hu, S. RSRNeT: A novel multi-modal network framework for named entity recognition and relation extraction. PeerJ Comput. Sci. 2024, 10, e1856. [Google Scholar] [CrossRef]
- Wu, K.; Xu, L.; Li, X.; Zhang, Y.; Yue, Z.; Gao, Y.; Chen, Y. Named entity recognition of rice genes and phenotypes based on BiGRU neural networks. Comput. Biol. Chem. 2024, 108, 107977. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Tan, X.; Tong, X.; Zhang, W. A Robust Chinese Named Entity Recognition Method Based on Integrating Dual-Layer Features and CSBERT. Appl. Sci. 2024, 14, 1060. [Google Scholar] [CrossRef]
- Cao, L.; Wu, C.; Luo, G.; Guo, C.; Zheng, A. Online biomedical named entities recognition by data and knowledge-driven model. Artif. Intell. Med. 2024, 150, 102813. [Google Scholar] [CrossRef] [PubMed]
- Chu, J.; Liu, Y.; Yue, Q.; Zheng, Z.; Han, X. Named entity recognition in aerospace based on multi-feature fusion transformer. Sci. Rep. 2024, 14, 827. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Chen, Q.; Du, J.; Peng, X.; Keloth, V.K.; Zuo, X.; Zhou, Y.; Li, Z.; Jiang, X.; Lu, Z.; et al. Improving large language models for clinical named entity recognition via prompt engineering. J. Am. Med. Inform. Assoc. 2024, ocad259. [Google Scholar] [CrossRef]
- Li, P.; Zhou, G.; Guo, Y.; Zhang, S.; Jiang, Y.; Tang, Y. EPIC: An epidemiological investigation of COVID-19 dataset for Chinese named entity recognition. Inf. Process. Manag. 2024, 61, 103541. [Google Scholar] [CrossRef]
- Mengliev, D.; Barakhnin, V.; Abdurakhmonova, N.; Eshkulov, M. Developing named entity recognition algorithms for Uzbek: Dataset Insights and Implementation. Data Brief 2024, 54, 110413. [Google Scholar] [CrossRef]
- Qiu, Q.; Tian, M.; Huang, Z.; Xie, Z.; Ma, K.; Tao, L.; Xu, D. Chinese engineering geological named entity recognition by fusing multi-features and data enhancement using deep learning. Expert Syst. Appl. 2024, 238, 121925. [Google Scholar] [CrossRef]
- Wang, C.; Gao, J.; Rao, H.; Chen, A.; He, J.; Jiao, J.; Zou, N.; Gu, L. Named entity recognition (NER) for Chinese agricultural diseases and pests based on discourse topic and attention mechanism. Evol. Intell. 2024, 17, 457–466. [Google Scholar] [CrossRef]
- Dahou, A.; Ewees, A.A.; Hashim, F.A.; Al-qaness, M.A.; Orabi, D.A.; Soliman, E.M.; Tag-eldin, E.M.; Aseeri, A.O.; Abd Elaziz, M. Optimizing fake news detection for Arabic context: A multitask learning approach with transformers and an enhanced Nutcracker Optimization Algorithm. Knowl.-Based Syst. 2023, 280, 111023. [Google Scholar] [CrossRef]
- Ayub, N.; Tayyaba; Hussain, S.; Ullah, S.S.; Iqbal, J. An Efficient Optimized DenseNet Model for Aspect-Based Multi-Label Classification. Algorithms 2023, 16, 548. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).