
Enhancing Fault Diagnosis in Mechanical Systems with Graph Neural Networks Addressing Class Imbalance


Abstract
:1. Introduction
- (1)
- The MRS-GNN incorporates the MeanRadius-SMOTE algorithm into GNNs, improving the balance between minority and majority classes through interpolation within the embedded representation spaces of the nodes. This improves the model performance under conditions of class imbalance.
- (2)
- The framework includes an edge generator that synthesizes new nodes and connects them to existing ones, preserving the topology and structural integrity of the graph. This is crucial for maintaining a high performance in node classification.
- (3)
- Extensive testing on three public datasets shows that the MRS-GNN surpasses some popular current methods in classification accuracy and robustness regarding class imbalance. The framework’s adaptability and utility in various environments are also demonstrated.
2. Related Work
2.1. Class Imbalance Problems
2.2. Graph Neural Networks
3. Problem Modeling
4. Proposed Methods
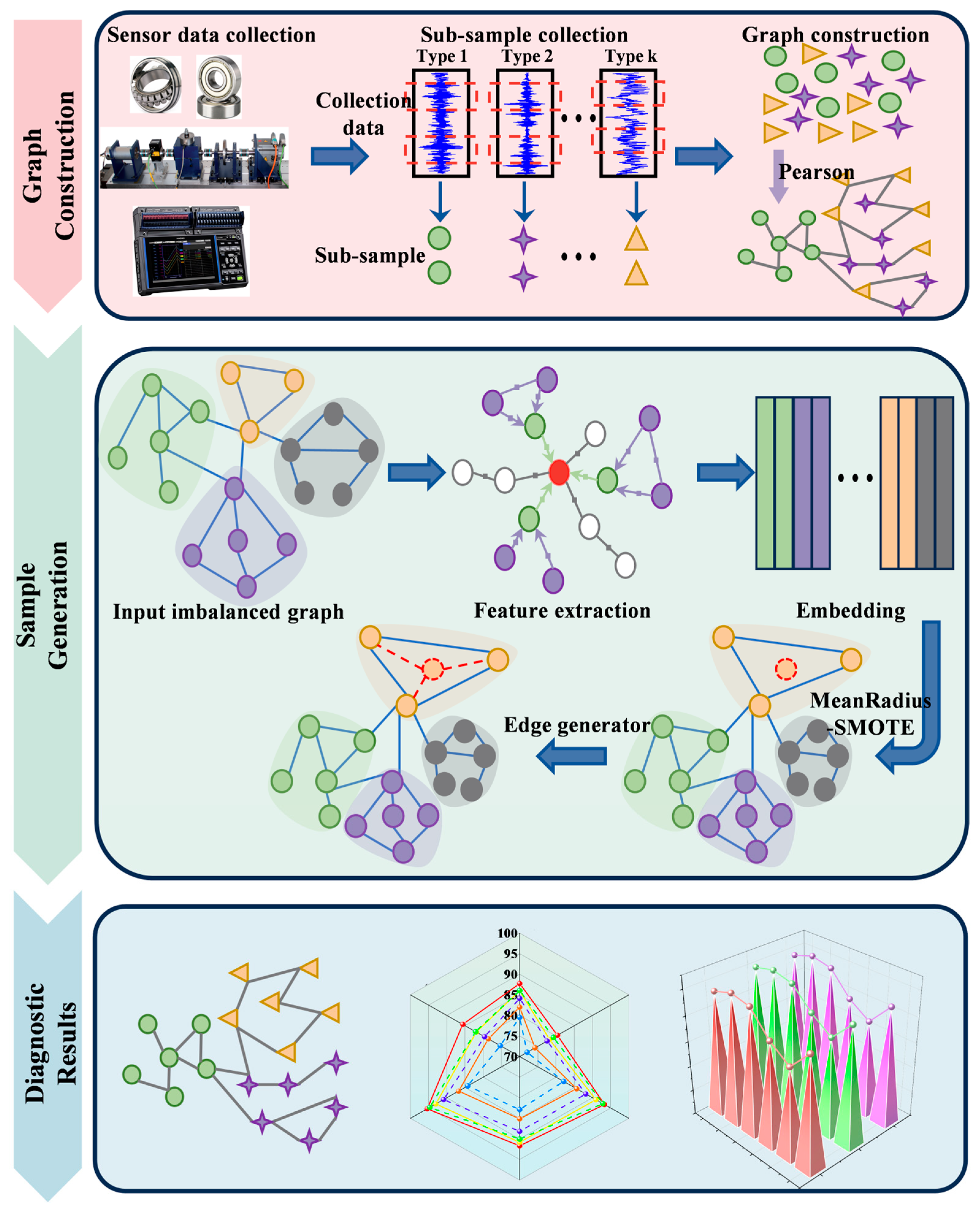
4.1. Graph Data Generation
4.2. Feature Extractor
4.3. Generation of New Sample Nodes
- (1)
- First, the geometric center of each minority class sample, denoted as sample center Z, is calculated.
- (2)
- Next, the Euclidean distance between each minority class sample and the sample center is calculated, and the average distance, denoted as the minority class sample radius R, is computed.
- (3)
- There is a random selection of M minority class samples, and the vector V is computed from the sample center Z to these M samples. The synthetic vector is obtained by synthesizing these M vectors.
- (4)
- The distance between the new sample and the sample center is determined using a normal distribution (mean , variance ), and the new sample is generated according to Equation (7):
- (5)
- The above steps are repeated until the number of samples in the minority and majority classes is balanced.
| Algorithm 1: MeanRadius-SMOTE |
| Input: , a dataset of minority class samples. |
| Output: , the new generated minority class samples. |
| Hyperparameters: , |
| 1. |
| 2. |
| 3. while do |
| 4. |
| 5. |
| 6. |
| 7. |
| 8. |
| 9. end |
| 10. return |
4.4. Edge Generator
4.5. Classifier Design
4.6. Overall Framework
5. Experimental Results and Comparisons
5.1. Experimental Settings
5.1.1. Dataset Descriptions
- (a)
- CWRU dataset [63]: Provided by Case Western Reserve University, the CRWU dataset is a widely used public dataset in the field of fault diagnosis. The dataset contains bearing test data obtained from a test rig, which includes a torque transducer, a power test meter, an electric motor, and an electronic controller, under both normal and various fault conditions. Each file in the dataset includes the data corresponding to different fault conditions, including the following: normal, inner ring fault (IF), outer ring fault (OF), and ball fault (BF).
- (b)
- JNU dataset [64]: In recent years, the open-source bearing dataset from Jiangnan University has also been popular with many researchers and scholars in the field of fault diagnosis. The JNU Bearing Dataset was created and is maintained by a research team at the School of Mechanical Engineering at JNU to provide a standardized and rich data resource for research on the fault diagnosis and predictive maintenance of bearings. The dataset contains data on the operation of rolling bearings under various operating conditions, including normal operating conditions and multiple fault conditions. The dataset includes several typical bearing faults, including inner ring faults, outer ring faults, and rolling element faults. Each type of fault has different levels of damage to simulate different fault conditions that may occur in real applications. Meanwhile, the bearing data were collected at different rotational speeds, including 600 rpm, 800 rpm, and 1000 rpm, to simulate different operating conditions, where the sampling rate is 48 kHz. In this experiment, as with the CWRU dataset, the four types of faults were selected as follows: normal, inner ring fault (IF), outer ring fault (OF), and ball fault (BF) under the rotational speed of 800 rpm for the experiment.
- (c)
- PU dataset [65]: Published by the University of Paderborn, the PU dataset aims to facilitate the application of data-driven classification methods for monitoring bearing damage in electromechanical drive systems using motor current signals. The dataset includes three damage categories: real damage, artificial damage, and no damage. The experimental process involves three main operating parameters: speed, load torque, and radial force. During each bearing test, 20 datasets were collected with a vibration signal sampling frequency of 64 kHz. The experimental process involved healthy bearings, artificial outer ring damage (electrical discharge machining, ORD), artificial inner ring damage (electrical discharge machining, IRD), real outer ring damage (fatigue pitting, ROD), and real inner and outer ring composite damage (fatigue pitting, RCD). These five different types of faulty bearings were tested under the following conditions: a rotational speed of 900 rpm, a load torque of 0.7 Nm, and a radial force of 1000 N. The vibration signal is used for the model performance verification. Table 1 shows the specific design of the working conditions for the above three datasets.
5.1.2. Dataset Preprocessing
5.1.3. Comparison to Some Popular Methods
- (1)
- Oversampling: A frequently employed technique for addressing class imbalanced data. It aims to balance the sample distribution across different classes through increasing the number of minority class samples. In this study, the dataset is balanced by replicating a substantial number of minority class nodes along their edges in the original space.
- (2)
- SMOTE: A classical oversampling method that addresses class imbalance through synthesizing new minority class samples. The SMOTE algorithm generates new samples with similar characteristics through interpolation between minority class samples. Through randomly selecting a minority class sample and its nearest neighbor, the SMOTE interpolates between the two samples to create synthetic samples. These synthetic samples provide additional information and assist the classifier in better capturing the features of the minority class.
- (3)
- Reweight [66]: A technique used to address class imbalance through adjusting the sample weights. It achieves dataset balance by increasing the weight of the minority class samples or decreasing the weight of the majority class samples. Through assigning different weights to the samples, the reweighting method enables the classifier to focus more on the minority class samples, thereby enhancing the classifier’s performance on the minority class.
- (4)
- GraphSMOTE [67]: An enhanced method derived from the SMOTE and specifically designed to address class imbalances in graphical data. While the traditional SMOTE measures sample similarity using Euclidean distance in the feature space, the GraphSMOTE leverages graph structures to identify similarities and to generate synthetic samples. It creates new minority class samples through selecting suitable nodes for interpolation based on neighborhood and similarity measures within the graph data.
- (5)
- MRS-GNNS: In this variant, the predicted edges are represented as continuous values, employing a soft edge design that enables gradient computation and propagation by the GNN-based classifier. Training encompasses other components and utilizes data from both the node classification task and the edge task.
- (6)
- MRS-GNNT: In this variant, the edges generated for predicting new nodes are transformed into binary values through thresholding, before being inputted to the classifier. Meanwhile, the edge generator is solely trained using losses from the edge prediction task.
5.2. Experimental Results and Analysis
5.2.1. Performance Validation of the MRS-GNN Model
5.2.2. Exploring the Effect of Different Base Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, P.; Chen, S.; He, Q.; Wang, D.; Peng, Z. Rotating machinery fault-induced vibration signal modulation effects: A review with mechanisms, extraction methods and applications for diagnosis. Mech. Syst. Signal Process. 2023, 200, 110489. [Google Scholar] [CrossRef]
- Xu, J.; Liang, S.; Ding, X.; Yan, R. A zero-shot fault semantics learning model for compound fault diagnosis. Expert Syst. Appl. 2023, 221, 119642. [Google Scholar] [CrossRef]
- Han, T.; Xie, W.; Pei, Z. Semi-supervised adversarial discriminative learning approach for intelligent fault diagnosis of wind turbine. Inf. Sci. 2023, 648, 119496. [Google Scholar] [CrossRef]
- He, C.; Shi, H.; Liu, X.; Li, J. Interpretable physics-informed domain adaptation paradigm for cross-machine transfer diagnosis. Knowl. Based Syst. 2024, 288, 111499. [Google Scholar] [CrossRef]
- Yu, X.; Yang, Y.; Du, M.; He, Q.; Peng, Z. Dynamic model-embedded intelligent machine fault diagnosis without fault data. IEEE Trans. Ind. Inform. 2023, 19, 11466–11476. [Google Scholar] [CrossRef]
- Han, T.; Li, Y.F. Out-of-distribution detection-assisted trustworthy machinery fault diagnosis approach with uncertainty-aware deep ensembles. Reliab. Eng. Syst. Saf. 2022, 226, 108648. [Google Scholar] [CrossRef]
- Wang, D.; Dong, Y.; Wang, H.; Tang, G. Limited fault data augmentation with compressed sensing for bearing fault diagnosis. IEEE Sens. J. 2023, 23, 14499–14511. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, H.; Kumar, A.; Xiang, J. Dynamic model-driven intelligent fault diagnosis method for rotary vector reducers. Eng. Appl. Artif. Intell. 2023, 124, 106648. [Google Scholar] [CrossRef]
- Niu, D.; Song, D. Model-based robust fault diagnosis of incipient ITSC for PMSM in elevator traction system. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Fan, C.; Wu, Q.; Zhao, Y.; Mo, L. Integrating active learning and semi-supervised learning for improved data-driven HVAC fault diagnosis performance. Appl. Energy 2024, 356, 122356. [Google Scholar] [CrossRef]
- Irani, F.N.; Yadegar, M.; Meskin, N. Koopman-based deep iISS bilinear parity approach for data-driven fault diagnosis: Experimental demonstration using three-tank system. Control. Eng. Pract. 2024, 142, 105744. [Google Scholar] [CrossRef]
- Liu, H. Application of industrial Internet of things technology in fault diagnosis of food machinery equipment based on neural network. Soft Comput. 2023, 27, 9001–9018. [Google Scholar] [CrossRef]
- Wan, W.; Chen, J.; Xie, J. Graph-Based Model Compression for HSR Bogies Fault Diagnosis at IoT Edge via Adversarial Knowledge Distillation. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1787–1796. [Google Scholar] [CrossRef]
- Kumar, U.; Mishra, S.; Dash, K. An IoT and semi-supervised learning-based sensorless technique for panel level solar photovoltaic array fault diagnosis. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, Z.; Yang, J. Feature trend extraction and adaptive density peaks search for intelligent fault diagnosis of machines. IEEE Trans. Ind. Inform. 2018, 15, 105–115. [Google Scholar] [CrossRef]
- Yang, C.; Cai, B.; Zhang, R.; Zou, Z.; Kong, X.; Shao, X.; Liu, Y.; Shao, H.; Khan, J.A. Cross-validation enhanced digital twin driven fault diagnosis methodology for minor faults of subsea production control system. Mech. Syst. Signal Process. 2023, 204, 110813. [Google Scholar] [CrossRef]
- Vo, T.T.; Liu, M.K.; Tran, M.Q. Harnessing attention mechanisms in a comprehensive deep learning approach for induction motor fault diagnosis using raw electrical signals. Eng. Appl. Artif. Intell. 2024, 129, 107643. [Google Scholar] [CrossRef]
- Zhang, J.; He, X. Compound-Fault Diagnosis of Integrated Energy Systems Based on Graph Embedded Recurrent Neural Networks. IEEE Trans. Ind. Inform. 2023, 20, 3478–3486. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Yao, J.; Li, M.; Gai, Z. Multi-sensor fusion fault diagnosis method of wind turbine bearing based on adaptive convergent viewable neural networks. Reliab. Eng. Syst. Saf. 2024, 245, 109980. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Z.; Li, S.; Sun, C.; Yan, R.; Chen, X. The emerging graph neural networks for intelligent fault diagnostics and prognostics: A guideline and a benchmark study. Mech. Syst. Signal Process. 2022, 168, 108653. [Google Scholar] [CrossRef]
- Revathy, V.R.; Pillai, A.S.; Daneshfar, F. LyEmoBERT: Classification of lyrics’ emotion and recommendation using a pre-trained model. Procedia Comput. Sci. 2023, 218, 1196–1208. [Google Scholar] [CrossRef]
- Peng, X.; Xu, H.; Wang, J.; Liu, Z.; He, C. Ensemble multiple distinct ResNet networks with channel-attention mechanism for multi-sensor fault diagnosis of hydraulic systems. IEEE Sens. J. 2023, 23, 10706–10717. [Google Scholar] [CrossRef]
- Wei, Z.; He, D.; Jin, Z.; Liu, B.; Shan, S.; Chen, Y.; Miao, J. Density-based affinity propagation tensor clustering for intelligent fault diagnosis of train bogie bearing. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6053–6064. [Google Scholar] [CrossRef]
- Li, H.; Liu, F.; Kong, X.; Zhang, J.; Jiang, Z.; Mao, Z. Knowledge features enhanced intelligent fault detection with progressive adaptive sparse attention learning for high-power diesel engine. Meas. Sci. Technol. 2023, 34, 105906. [Google Scholar] [CrossRef]
- Tian, J.; Jiang, Y.; Zhang, J.; Luo, H.; Yin, S. A novel data augmentation approach to fault diagnosis with class-imbalance problem. Reliab. Eng. Syst. Saf. 2024, 243, 109832. [Google Scholar] [CrossRef]
- Lee, J.; Ko, J.U.; Kim, T.; Kim, Y.; Jung, J.; Youn, B. Domain adaptation with label-aligned sampling (DALAS) for cross-domain fault diagnosis of rotating machinery under class imbalance. Expert Syst. Appl. 2024, 243, 122910. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, J.; Zhong, X.; Wang, W.; Chen, H.; Chang, Y. A Novel Composite Graph Neural Network. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Yuan, X.; Radfar, M.; Marendy, P.; Ni, W.; Brien, T.; Casillas-Espinosa, P. Graph signal processing, graph neural network and graph learning on biological data: A systematic review. IEEE Rev. Biomed. Eng. 2021, 16, 109–135. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Li, W.; Tang, T.; Wang, D.; Wang, Q. Denoising graph neural network based hydraulic component fault diagnosis method. Mech. Syst. Signal Process. 2023, 204, 110828. [Google Scholar] [CrossRef]
- Liu, R.; Wang, X.; Kumar, A.; Sun, B.; Zhou, Y. WPD-Enhanced Deep Graph Contrastive Learning Data Fusion for Fault Diagnosis of Rolling Bearing. Micromachines 2023, 14, 1467. [Google Scholar] [CrossRef]
- Tao, H.; Shi, H.; Qiu, J.; Jin, G. Planetary gearbox fault diagnosis based on FDKNN-DGAT with few labeled data. Meas. Sci. Technol. 2023, 35, 025036. [Google Scholar] [CrossRef]
- Han, S.; Zhu, K.; Zhou, M.C.; Liu, X. Evolutionary weighted broad learning and its application to fault diagnosis in self-organizing cellular networks. IEEE Trans. Cybern. 2022, 53, 3035–3047. [Google Scholar] [CrossRef] [PubMed]
- Ganaie, M.A.; Sajid, M.; Malik, A.K.; Tanveer, M. Graph Embedded Intuitionistic Fuzzy Random Vector Functional Link Neural Network for Class Imbalance Learning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Raeisi, K.; Khazaei, M.; Tamburro, G.; Croce, P.; Comani, S.; Zappasodi, F. A class-imbalance aware and explainable spatio-temporal graph attention network for neonatal seizure detection. Int. J. Neural Syst. 2023, 33, 2350046. [Google Scholar] [CrossRef] [PubMed]
- Tsai, C.F.; Chen, K.C.; Lin, W.C. Feature selection and its combination with data over-sampling for multi-class imbalanced datasets. Appl. Soft Comput. 2024, 153, 111267. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F.; Kamalov, F. A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Mach. Learn. 2023, 113, 4903–4923. [Google Scholar] [CrossRef]
- Xie, Y.; Huang, X.; Qin, F.; Li, F.; Ding, X. A majority affiliation based under-sampling method for class imbalance problem. Inf. Sci. 2024, 662, 120263. [Google Scholar] [CrossRef]
- Soltanzadeh, P.; Feizi-Derakhshi, M.R.; Hashemzadeh, M. Addressing the class-imbalance and class-overlap problems by a metaheuristic-based under-sampling approach. Pattern Recognit. 2023, 143, 109721. [Google Scholar] [CrossRef]
- Rezvani, S.; Wang, X. A broad review on class imbalance learning techniques. Appl. Soft Comput. 2023, 143, 110415. [Google Scholar] [CrossRef]
- Fonseca, J.; Bacao, F. Geometric SMOTE for imbalanced datasets with nominal and continuous features. Expert Syst. Appl. 2023, 234, 121053. [Google Scholar] [CrossRef]
- Abhisheka, B.; Biswas, S.K.; Purkayastha, B. HBNet: An integrated approach for resolving class imbalance and global local feature fusion for accurate breast cancer classification. Neural Comput. Appl. 2024, 36, 8455–8472. [Google Scholar] [CrossRef]
- Dixit, A.; Mani, A. Sampling technique for noisy and borderline examples problem in imbalanced classification. Appl. Soft Comput. 2023, 142, 110361. [Google Scholar] [CrossRef]
- Ren, Z.; Lin, T.; Feng, K.; Zhu, Y.; Liu, Z.; Yan, K. A systematic review on imbalanced learning methods in intelligent fault diagnosis. IEEE Trans. Instrum. Meas. 2023, 72, 1–35. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl. Based System. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Mostafaei, S.; Ahmadi, A.; Shahrabi, J. USWAVG-BS: Under-Sampled Weighted AVeraGed BorderlineSMOTE to handle data intrinsic difficulties. Expert Syst. Appl. 2023, 227, 120379. [Google Scholar] [CrossRef]
- Guan, S.; Yang, H.; Wu, T. Transformer fault diagnosis method based on TLR-ADASYN balanced dataset. Sci. Rep. 2023, 13, 23010. [Google Scholar] [CrossRef]
- He, C.; Cao, Y.; Yang, Y.; Liu, Y.; Liu, X.; Cao, Z. Fault diagnosis of rotating machinery based on the improved multidimensional normalization ResNet. IEEE Trans. Instrum. Meas. 2023, 72, 3524311. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, H.; Guo, J.; Ji, Y.; Pecht, M. Imbalanced bearing fault diagnosis under variant working conditions using cost-sensitive deep domain adaptation network. Expert Syst. Appl. 2022, 193, 116459. [Google Scholar] [CrossRef]
- Liu, H.; Yang, Y.; Hu, N.; Chen, Z.; Cheng, J. Soft-margin hyperdisk tensor machine and its application to the intelligent fault diagnosis of rotating machinery. Meas. Sci. Technol. 2022, 33, 125902. [Google Scholar] [CrossRef]
- Liu, C.; She, W.; Chen, M.; Li, X.; Yang, S. Consistent penalizing field loss for zero-shot image retrieval. Expert Syst. Appl. 2024, 236, 121287. [Google Scholar] [CrossRef]
- Hwang, S.; Choi, J.; Choi, J. Uncertainty-Based Selective Clustering for Active Learning. IEEE Access 2022, 10, 110983–110991. [Google Scholar] [CrossRef]
- Duan, F.; Zhang, S.; Yan, Y.; Cai, Z. An oversampling method of unbalanced data for mechanical fault diagnosis based on MeanRadius-SMOTE. Sensors 2022, 22, 5166. [Google Scholar] [CrossRef]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Wu, F.; Zhang, T.; Souza, A.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Bouritsas, G.; Frasca, F.; Zafeiriou, S.; Bronstein, M. Improving graph neural network expressivity via subgraph isomorphism counting. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 657–668. [Google Scholar] [CrossRef]
- Li, M.; Cai, X.; Xu, S.; Ji, H. Metapath-aggregated heterogeneous graph neural network for drug–target interaction prediction. Brief. Bioinform. 2023, 24, bbac578. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, W.; Sun, F.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Chen, D.; Liu, R.; Hu, Q.; Ding, S. Interaction-aware graph neural networks for fault diagnosis of complex industrial processes. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 6015–6028. [Google Scholar] [CrossRef]
- Xu, Y.; Ji, J.; Ni, Q.; Feng, K.; Beer, M.; Chen, H. A graph-guided collaborative convolutional neural network for fault diagnosis of electromechanical systems. Mech. Syst. Signal Process. 2023, 200, 110609. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64, 100–131. [Google Scholar] [CrossRef]
- Li, K.; Ping, X.; Wang, H.; Chen, P.; Cao, Y. Sequential fuzzy diagnosis method for motor roller bearing in variable operating conditions based on vibration analysis. Sensors 2013, 13, 8013–8041. [Google Scholar] [CrossRef] [PubMed]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the PHM Society European Conference, Bilbao, Spain, 5–8 July 2016; Volume 3. [Google Scholar]
- Yuan, B.; Ma, X. Sampling+ reweighting: Boosting the performance of AdaBoost on imbalanced datasets. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar]
- Zhao, T.; Zhang, X.; Wang, S. Graphsmote: Imbalanced node classification on graphs with graph neural networks. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 833–841. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type of Fault | Description |
|---|---|---|
| CWRU/JNU | Normal (N) | bearings with normal conditions. |
| Outer Fault (OF) | bearings with an outer ring fault condition. In the CWRU dataset, the size of the outer ring fault is 0.5334 mm. | |
| Inner Fault (IF) | bearings with an inner ring fault condition. In the CWRU dataset, the size of the outer ring fault is 0.5334 mm. | |
| Ball Fault (BF) | bearings with a ball fault condition. | |
| PU | Normal (N) | bearings with normal conditions. |
| Artificial Outer Damage (AOF) | bearings with an outer ring damage fault formed through artificial electrical discharge machining. | |
| Artificial Inner Damage (AIF) | bearings with an inner ring damage fault formed through artificial electrical discharge machining. | |
| Real Outer Damage (ROF) | bearings with an outer ring damage fault formed by fatigue spalling in real operating conditions. | |
| Real Combined Damage (RCF) | bearings with a composite inner and outer ring damage fault formed by fatigue spalling in real operating conditions. |
| Datasets | Node | The Number of Samples | IMR | IC | ||||
|---|---|---|---|---|---|---|---|---|
| N | OF (AOF) | IF (AIF) | BF (ROF) | (RCF) | ||||
| 450 | 450 | 450 | 450 | 1 | ||||
| 450 | 450 | 450 | 360 | 1 | ||||
| 450 | 450 | 360 | 360 | 2 | ||||
| CWRU/JNU | 450 | 450 | 450 | 270 | 0.6 | 1 | ||
| 450 | 450 | 270 | 270 | 2 | ||||
| 450 | 450 | 450 | 180 | 0.4 | 1 | |||
| 450 | 450 | 180 | 180 | 2 | ||||
| 450 | 450 | 450 | 450 | 450 | 1 | |||
| 450 | 450 | 450 | 360 | 360 | 0.8 | 2 | ||
| 450 | 450 | 360 | 360 | 360 | 3 | |||
| PU | 450 | 450 | 450 | 270 | 270 | 0.6 | 2 | |
| 450 | 450 | 270 | 270 | 270 | 3 | |||
| 450 | 450 | 450 | 180 | 180 | 0.4 | 2 | ||
| 450 | 450 | 180 | 180 | 180 | 3 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Wang, W.; Qin, X.; Cai, Z. Enhancing Fault Diagnosis in Mechanical Systems with Graph Neural Networks Addressing Class Imbalance. Mathematics 2024, 12, 2064. https://doi.org/10.3390/math12132064
Lu W, Wang W, Qin X, Cai Z. Enhancing Fault Diagnosis in Mechanical Systems with Graph Neural Networks Addressing Class Imbalance. Mathematics. 2024; 12(13):2064. https://doi.org/10.3390/math12132064
Chicago/Turabian StyleLu, Wenhao, Wei Wang, Xuefei Qin, and Zhiqiang Cai. 2024. "Enhancing Fault Diagnosis in Mechanical Systems with Graph Neural Networks Addressing Class Imbalance" Mathematics 12, no. 13: 2064. https://doi.org/10.3390/math12132064