

A Photovoltaic Prediction Model with Integrated Attention Mechanism

Abstract
1. Introduction
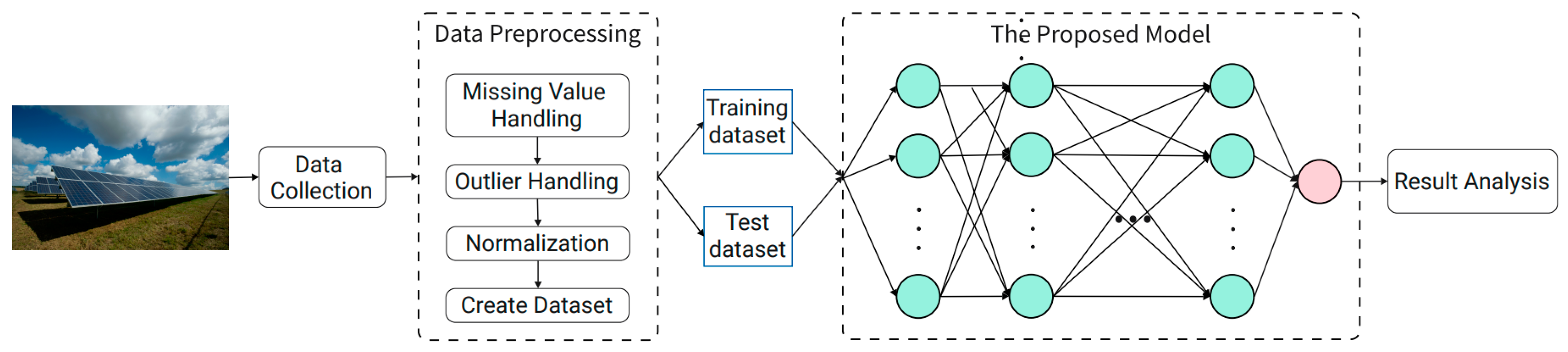
2. Materials and Methods Proposed Photovoltaic Prediction Model
2.1. Description of the Prediction Problem
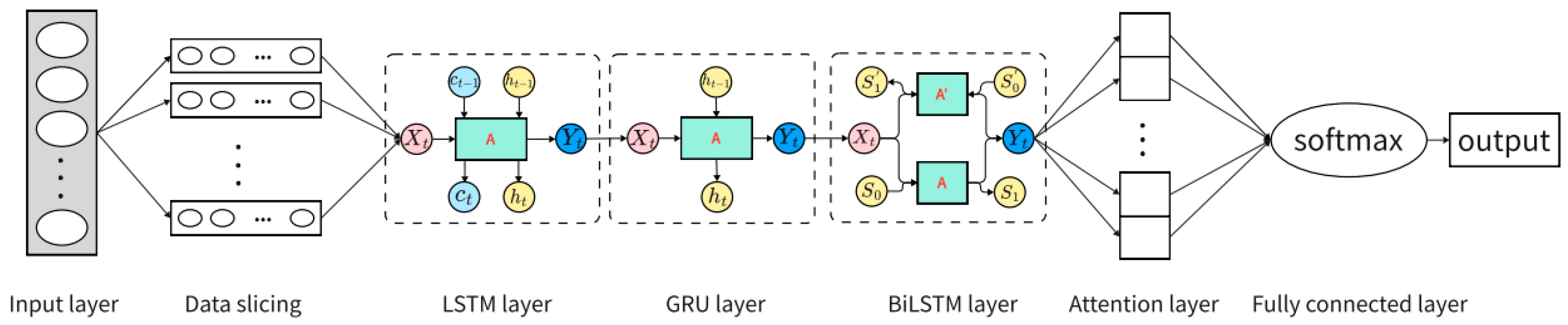
2.2. The Structure of the Network
2.2.1. Long Short-Term Memory Networks (LSTM)
2.2.2. Gated Recurrent Unit Neural Network (GRU)
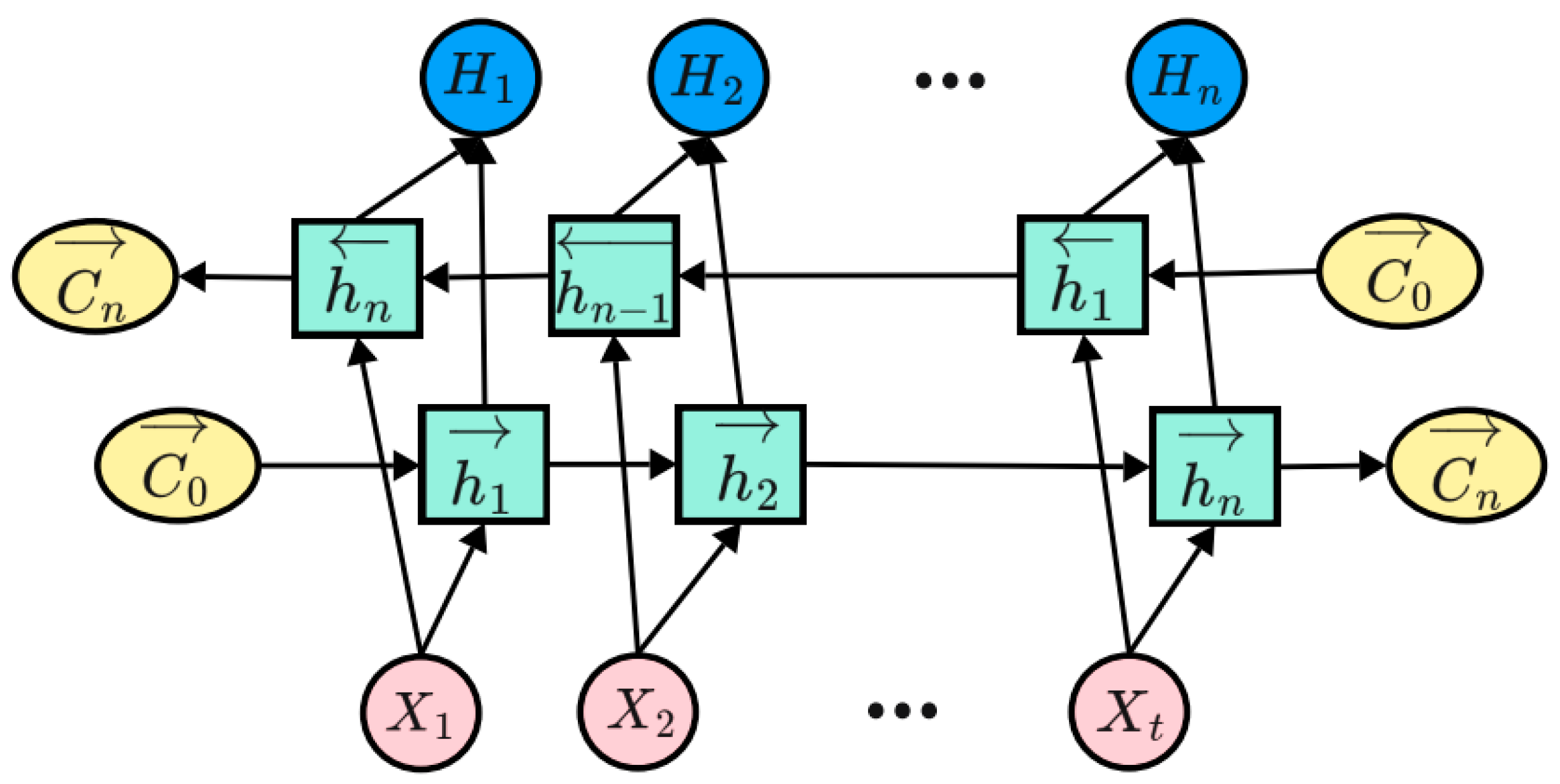
2.2.3. Bidirectional Long Short-Term Memory (BiLSTM) Neural Network
2.2.4. Attention Mechanism
2.3. The Prediction Model Composition
2.4. Training Strategy of the Proposed Model
| Algorithm 1: The strategy of our dataset creation. |
| Input: the raw data table dataset, the predicted step size of the slide look_back. |
| Output: Training Sample , Training Label , Test Sample , Test Label . |
| 1: Data preprocessing (dataset) |
| 2: DataInitialize (X, Y) |
| 3: For i in len (dataset) |
| 4: X, Y ← CreateData (dataset, look_back) |
| 5: End For |
| 6: (, ), (, ) ← (α*X, (1 − α)*X), (α*Y, (1 − α)*Y) |
| 7: End |
| Algorithm 2: Training strategy of the proposed model for PV Prediction. |
| Input: number of training iterations epoch, batch size of the dataset B, learning rate , training set , test set |
| Output: model training loss function , parameters of the network model trained for the i th time . |
| 1: Initialize |
| 2: For i in epoch |
| 3: , ← GetMiniBatch (, , B) |
| 4: ← LSTM () |
| 5: ← GRU () |
| 6: ← BiLSTM () |
| 7: ← Dropout () |
| 8: A ← Attention () |
| 9: ← Matmul () |
| 10: O ← Dense (Flatten (A)) |
| 11: ← mean_squared_error () |
| 12: ← Adam (, ) |
| 13: End For |
| 14: Evaluate () |
| 15: End |
3. Experimental Evaluations
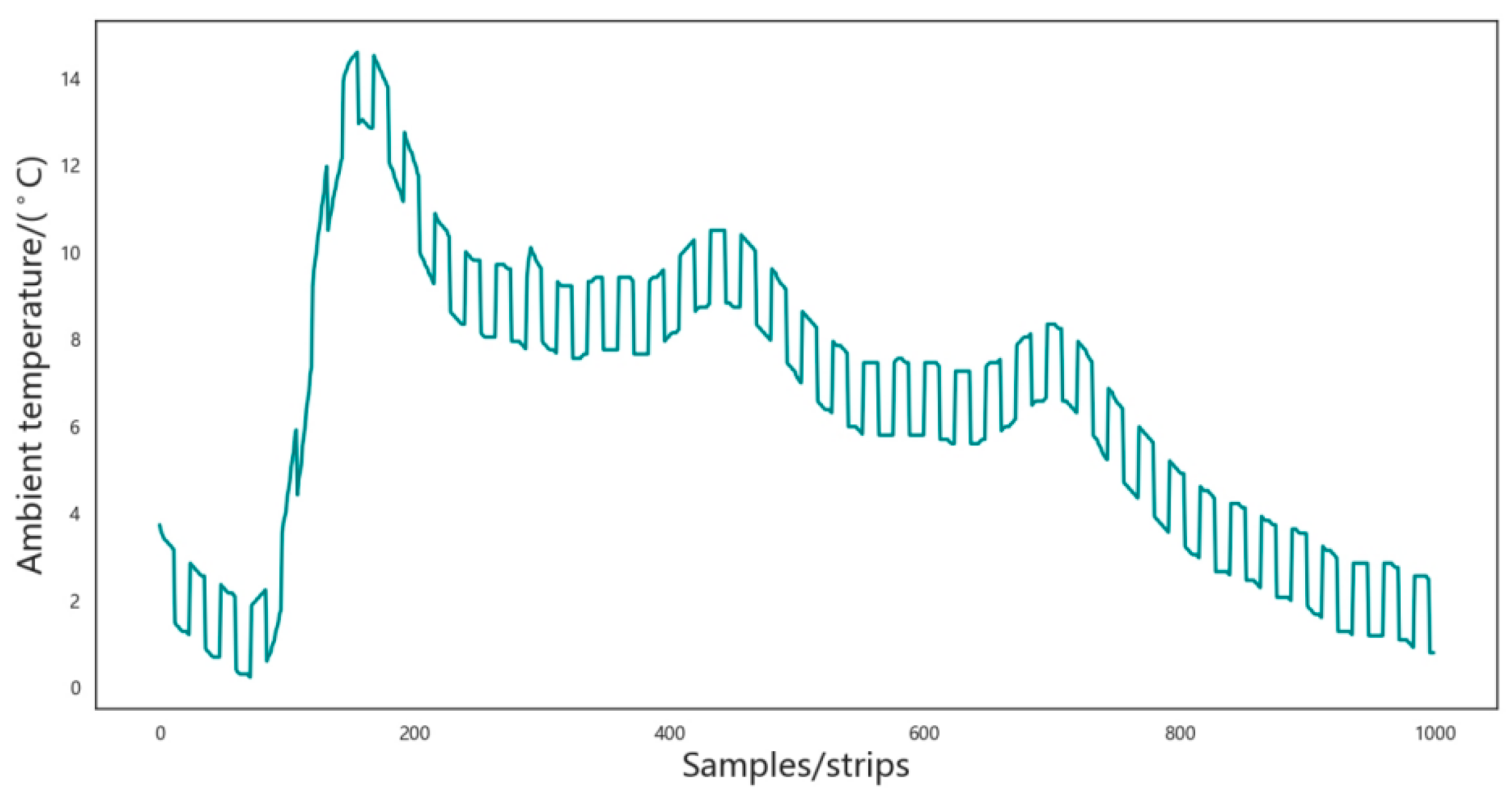
3.1. Data Description
3.2. Data Pre-Processing
3.3. Evaluation Indicators
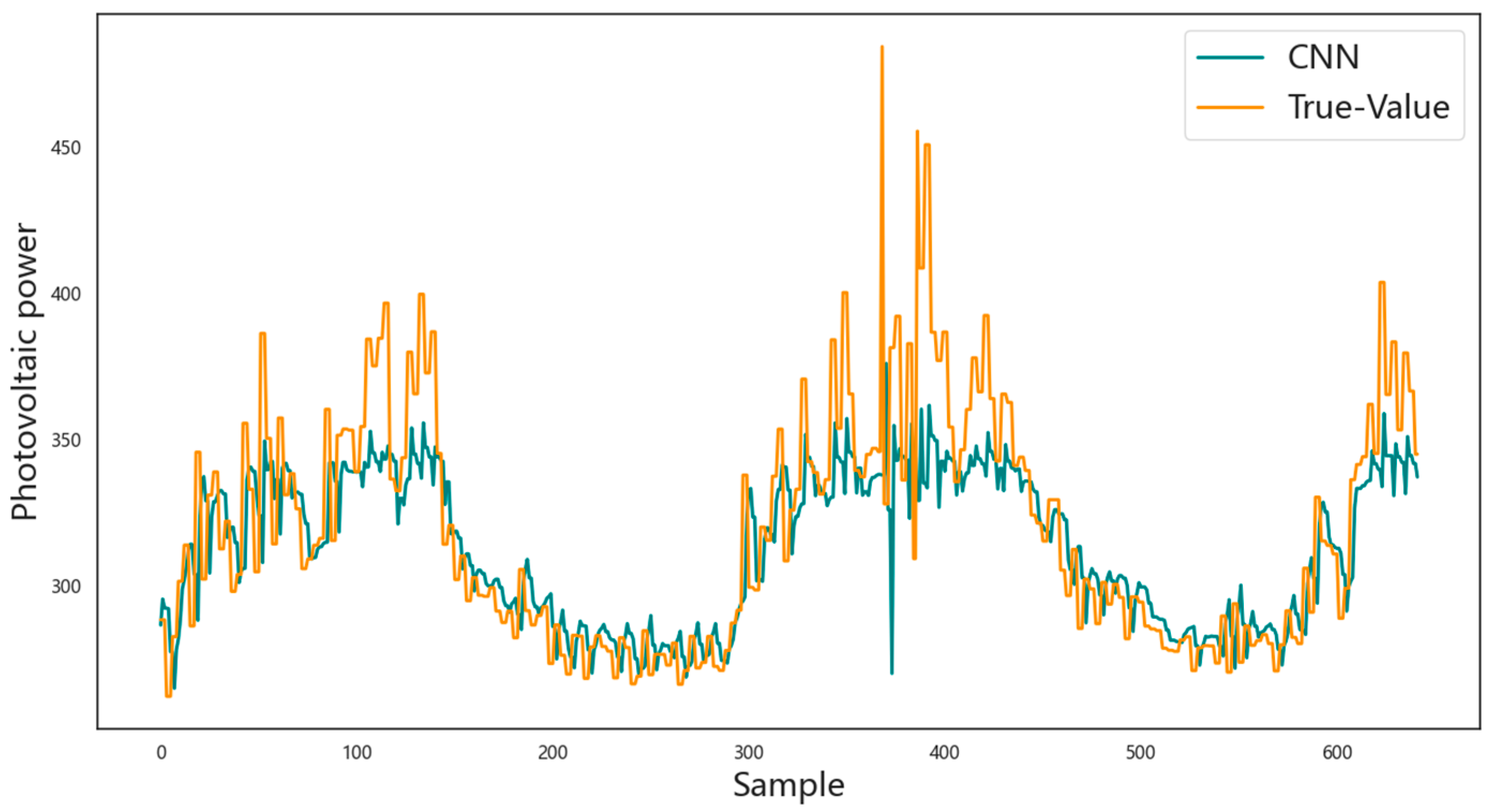
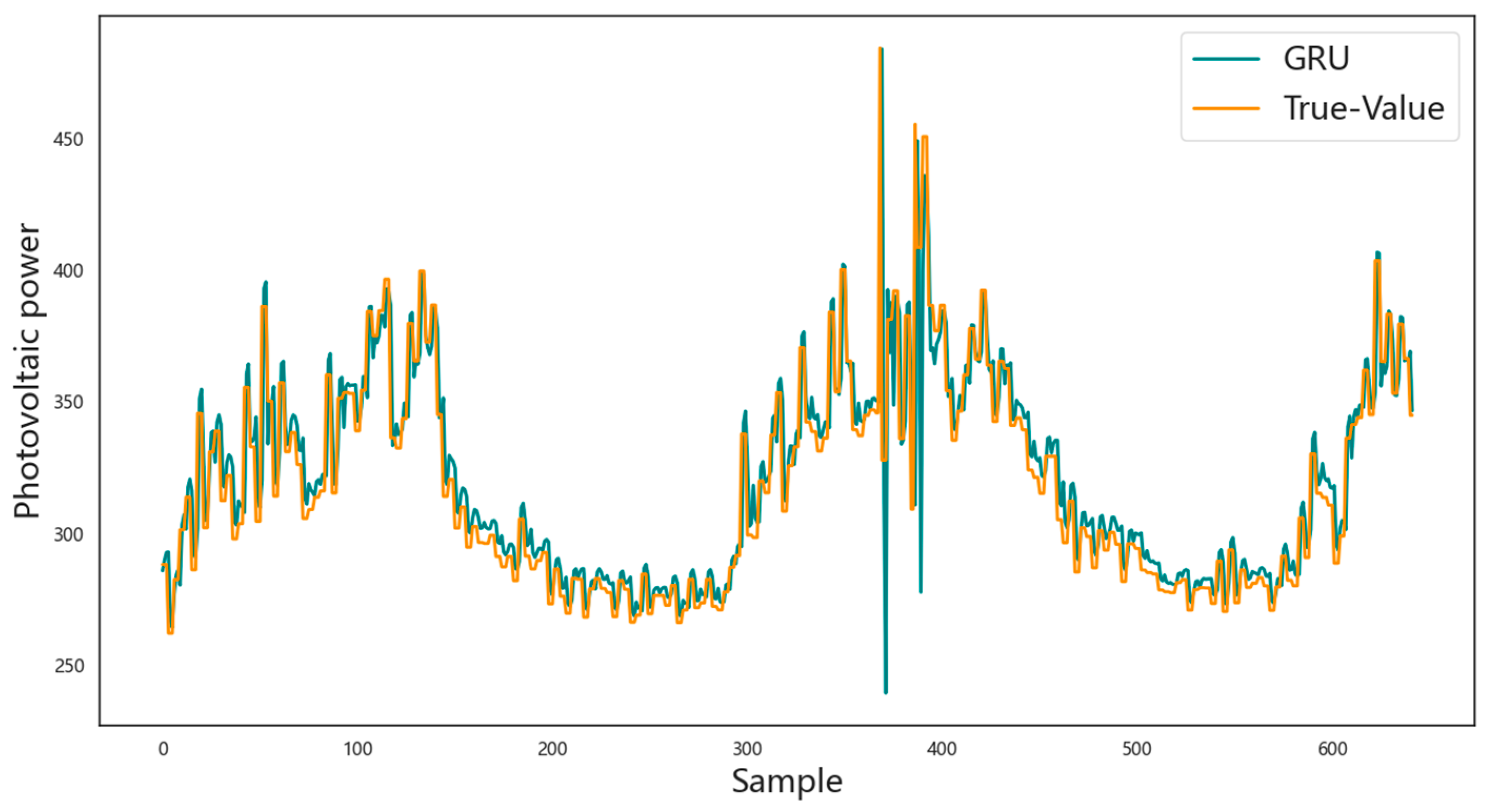
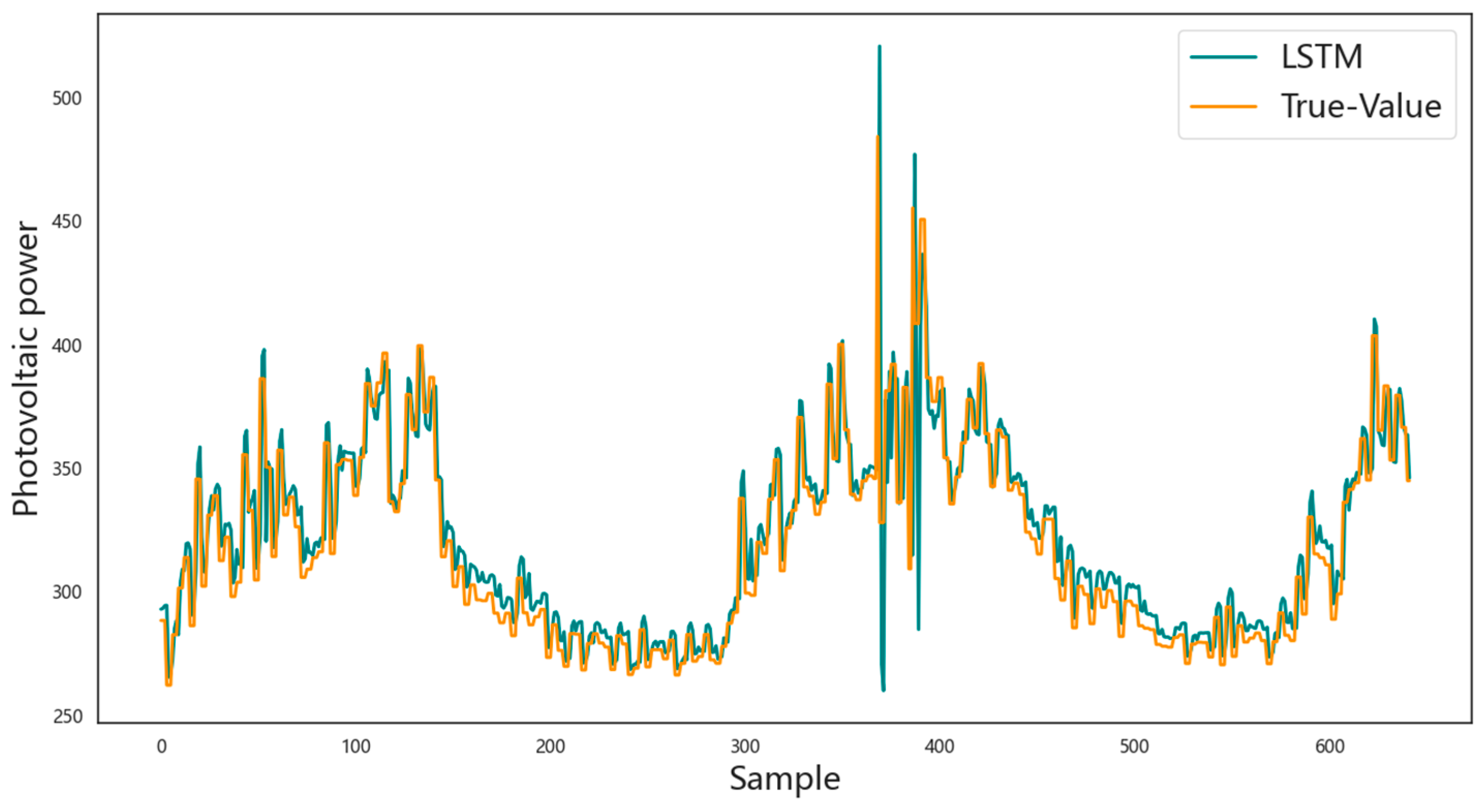
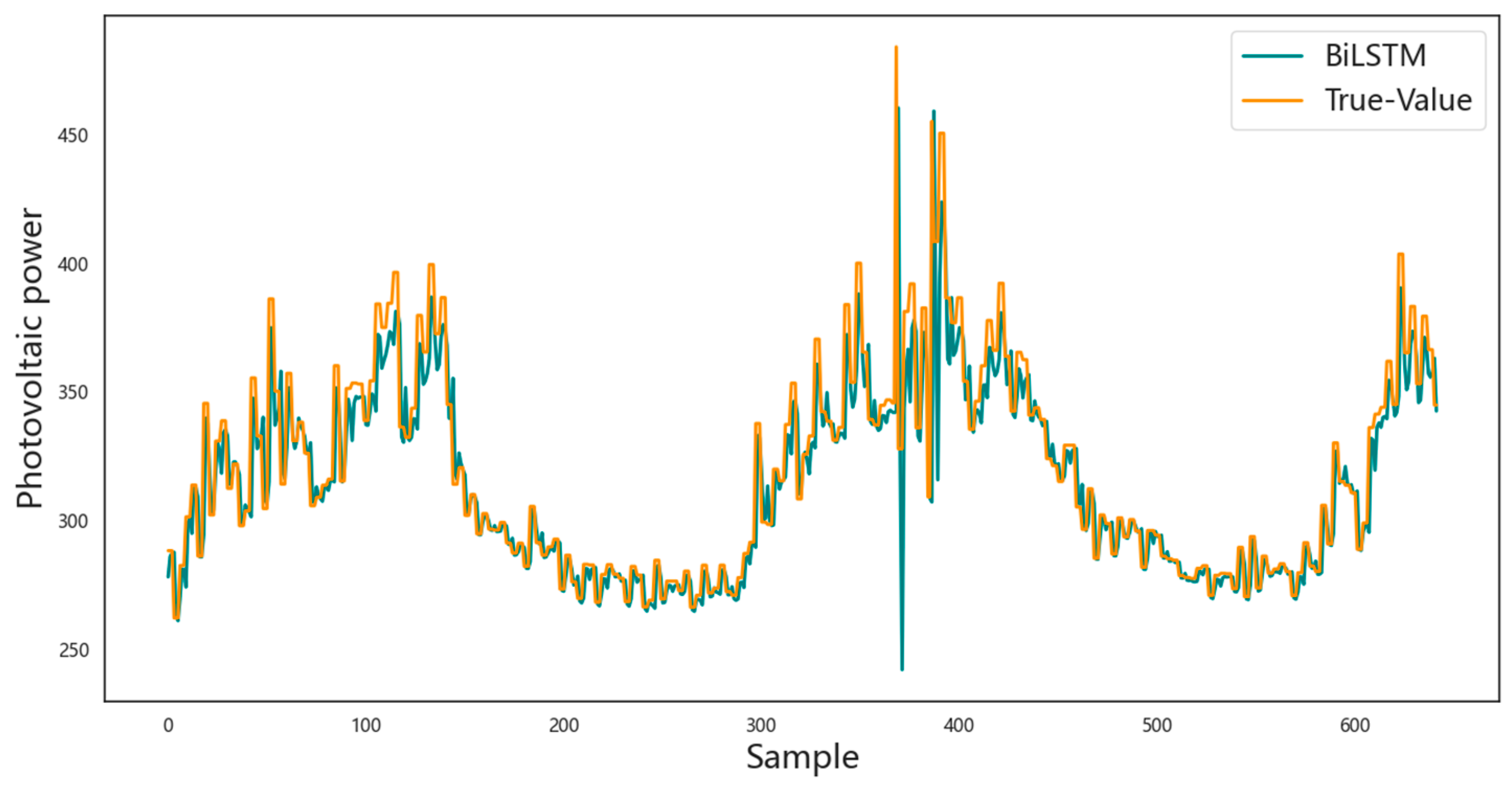
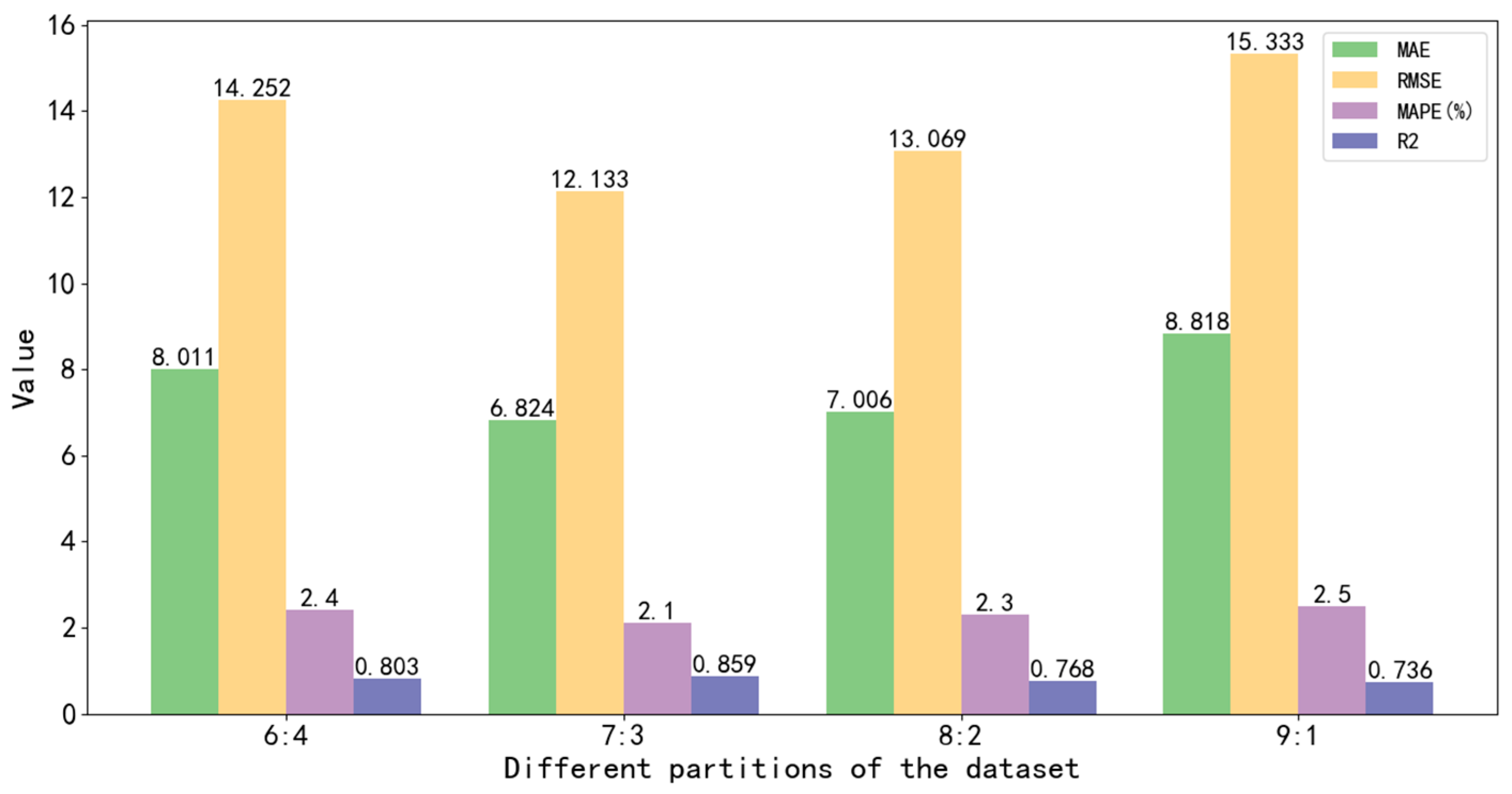
3.4. Prediction Results Analysis
4. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dubey, S.; Sarvaiya, J.N.; Seshadri, B. Temperature dependent photovoltaic (PV) efficiency and its effect on PV production in the world–a review. Energy Proc. 2013, 33, 311–321. [Google Scholar] [CrossRef]
- Li, Y.; Song, L.; Zhang, S.; Kraus, L.; Adcox, T.; Willardson, R.; Lu, N. A TCN-based hybrid forecasting framework for hours-ahead utility-scale PV forecasting. IEEE Trans. Smart Grid 2023, 14, 4073–4085. [Google Scholar] [CrossRef]
- Das, U.K.; Tey, K.S.; Seyedmahmoudian, M.; Mekhilef, S.; Idris, M.Y.I.; Van Deventer, W.; Stojcevski, A. Forecasting of photovoltaic power generation and model optimization: A review. Renew. Sustain. Energy Rev. 2018, 81, 912–928. [Google Scholar] [CrossRef]
- Raza, M.Q.; Nadarajah, M.; Ekanayake, C. On recent advances in PV output power forecast. Sol. Energy 2016, 136, 125–144. [Google Scholar] [CrossRef]
- Sobri, S.; Koohi-Kamali, S.; Rahim, N.A. Solar photovoltaic generation forecasting methods: A review. Energy Convers. Manage. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Leva, S.; Dolara, A.; Grimaccia, F.; Mussetta, M.; Ogliari, E. Analysis and validation of 24 hours ahead neural network forecasting of photovoltaic output power. Math. Comput. Simul. 2017, 131, 88–100. [Google Scholar] [CrossRef]
- Wang, H.; Yi, H.; Peng, J.; Wang, G.; Liu, Y.; Jiang, H.; Liu, W. Deterministic and probabilistic forecasting of photovoltaic power based on deep convolutional neural network. Energy Convers. Manage. 2017, 153, 409–422. [Google Scholar] [CrossRef]
- Yang, H.T.; Huang, C.M.; Huang, Y.C.; Pai, Y.S. A weather-based hybrid method for 1-day ahead hourly forecasting of PV power output. IEEE Trans. Sustain. Energy 2014, 5, 917–926. [Google Scholar] [CrossRef]
- Yang, Z.; Mourshed, M.; Liu, K.; Xu, X.; Feng, S. A novel competitive swarm optimized RBF neural network model for short-term solar power generation forecasting. Neurocomputing 2020, 397, 415–421. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M.D. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Liu, D.; Sun, K. Random Forest Solar Power Forecast Based on Classification Optimization. Energy 2019, 187, 115940. [Google Scholar] [CrossRef]
- Agoua, X.G.; Girard, R.; Kariniotakis, G. Short-term spatio-temporal forecasting of photovoltaic power production. IEEE Trans. Sustain. Energy 2017, 9, 538–546. [Google Scholar] [CrossRef]
- Pan, M.; Li, C.; Gao, R.; Huang, Y.; You, H.; Gu, T.; Qin, F. Photovoltaic power forecasting based on a support vector machine with improved ant colony optimization. J. Clean. Prod. 2020, 277, 123948. [Google Scholar] [CrossRef]
- Jung, Y.; Jung, J.; Kim, B.; Han, S. Long short-term memory recurrent neural network for modeling temporal patterns in long-term power forecasting for solar PV facilities: Case study of South Korea. J. Clean. Prod. 2020, 250, 119476. [Google Scholar] [CrossRef]
- Son, N.; Jung, M. Analysis of Meteorological Factor Multivariate Models for Medium- and Long-Term Photovoltaic Solar Power Forecasting Using Long Short-Term Memory. Appl. Sci. 2021, 11, 316. [Google Scholar] [CrossRef]
- Sodsong, N.; Yu, K.M.; Ouyang, W. Short-term solar PV forecasting using gated recurrent unit with a cascade model. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 292–297. [Google Scholar]
- Cao, W.; Zhou, J.; Xu, Q.; Zhen, J.; Huang, X. Short-Term Forecasting and Uncertainty Analysis of Photovoltaic Power Based on the FCM-WOA-BILSTM Model. Front. Energy Res. 2022, 10, 926774. [Google Scholar] [CrossRef]
- Tahir, M.F.; Tzes, A.; Yousaf, M.Z. Enhancing PV power forecasting with deep learning and optimizing solar PV project performance with economic viability: A multi-case analysis of 10 MW Masdar project in UAE. Energy Convers. Manag. 2024, 311, 118549. [Google Scholar] [CrossRef]
- Huang, C.M.; Chen, S.J.; Yang, S.P. A Parameter Estimation Method for a Photovoltaic Power Generation System Based on a Two-Diode Model. Energies 2022, 15, 1460. [Google Scholar] [CrossRef]
- Peng, J.; Lu, L.; Yang, H.; Ma, T. Validation of the Sandia Model with Indoor and Outdoor Measurements for Semi-Transparent Amorphous Silicon PV Modules. Renew. Energy 2015, 80, 316–323. [Google Scholar] [CrossRef]
- Wang, M.; Peng, J.; Luo, Y.; Shen, Z.; Yang, H. Comparison of Different Simplistic Prediction Models for Forecasting PV Power Output: Assessment with Experimental Measurements. Energy 2021, 224, 120162. [Google Scholar] [CrossRef]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manage. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Markovics, D.; Mayer, M.J. Comparison of machine learning methods for photovoltaic power forecasting based on numerical weather prediction. Renew. Sustain. Energy Rev. 2022, 161, 112364. [Google Scholar] [CrossRef]
- Tahir, M.F.; Yousaf, M.Z.; Tzes, A.; El Moursi, M.S.; El-Fouly, T.H. Enhanced solar photovoltaic power prediction using diverse machine learning algorithms with hyperparameter optimization. Renew. Sustain. Energy Rev. 2024, 200, 114581. [Google Scholar] [CrossRef]
- Louzazni, M.; Mosalam, H.; Khouya, A.; Amechnoue, K. A non-linear auto-regressive exogenous method to forecast the photovoltaic power output. Sustain. Energy Technol. Assess. 2020, 38, 100670. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, CA, USA, 2016. [Google Scholar]
- Beigi, M.; Beigi Harchegani, H.; Torki, M.; Kaveh, M.; Szymanek, M.; Khalife, E.; Dziwulski, J. Forecasting of power output of a PVPS based on meteorological data using RNN approaches. Sustainability 2022, 14, 3104. [Google Scholar] [CrossRef]
- Qing, X.; Niu, Y. Hourly Day-Ahead Solar Irradiance Prediction Using Weather Forecasts by LSTM. Energy 2018, 148, 461–468. [Google Scholar] [CrossRef]
- Wang, F.; Xuan, Z.; Zhen, Z.; Li, K.; Wang, T.; Shi, M. A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers. Manag. 2020, 212, 112766. [Google Scholar] [CrossRef]
- Lim, S.C.; Huh, J.H.; Hong, S.H.; Park, C.Y.; Kim, J.C. Solar power forecasting using CNN-LSTM hybrid model. Energies 2022, 15, 8233. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, J.; Cheng, X.; Ma, X. Hybrid models based on LSTM and CNN architecture with Bayesian optimization for shorterm photovoltaic power forecasting. In Proceedings of the 2021 IEEE/IAS Industrial and Commercial Power System Asia (I&CPS Asia), Chengdu, China, 18–21 July 2021; pp. 1415–1422. [Google Scholar]
- Wang, K.; Qi, X.; Liu, H.; Song, J. Deep Belief Network Based K-Means Cluster Approach for Short-Term Wind Power Forecasting. Energy 2018, 165, 840–852. [Google Scholar] [CrossRef]
- Li, P.; Zhou, K.; Lu, X.; Yang, S. A hybrid deep learning model for short-term PV power forecasting. Appl. Energy 2020, 259, 114216. [Google Scholar] [CrossRef]
- Lin, P.; Peng, Z.; Lai, Y.; Cheng, S.; Chen, Z.; Wu, L. Short-term power prediction for photovoltaic power plants using a hybrid improved Kmeans-GRA-Elman model based on multivariate meteorological factors and historical power datasets. Energy Convers. Manag. 2018, 177, 704–717. [Google Scholar] [CrossRef]
- Gao, M.; Li, J.; Hong, F.; Long, D. Day-ahead power forecasting in a large-scale photovoltaic plant based on weather classification using LSTM. Energy 2019, 187, 115838. [Google Scholar] [CrossRef]
- Liu, L.; Zhao, Y.; Chang, D.; Xie, J.; Ma, Z.; Sun, Q.; Wennersten, R. Prediction of short-term PV power output and uncertainty analysis. Appl. Energy 2018, 228, 700–711. [Google Scholar] [CrossRef]
- Van der Meer, D.W.; Widén, J.; Munkhammar, J. Review on probabilistic forecasting of photovoltaic power production and electricity consumption. Renew. Sustain. Energy Rev. 2018, 81, 1484–1512. [Google Scholar] [CrossRef]
- Jawaid, F.; NazirJunejo, K. Predicting daily mean solar power using machine learning regression techniques. In Proceedings of the 2016 Sixth International Conference on Innovative Computing Technology (INTECH), Dublin, Ireland, 24–26 August 2016; pp. 355–360. [Google Scholar]
- Cinar, Y.G.; Mirisaee, H.; Goswami, P.; Gaussier, E.; Aït-Bachir, A.; Strijov, V. Position-based content attention for time series forecasting with sequence-to-sequence RNNs. In Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Proceedings, Part, V; Springer International Publishing: New York, NY, USA, 2017; Volume 24, pp. 533–544. [Google Scholar]
- Wang, J.; Cui, Q.; Sun, X.; He, M. Asian stock markets closing index forecast based on secondary decomposition, multi-factor analysis, and attention-based LSTM model. Eng. Appl. Artif. Intell. 2022, 113, 104908. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions, and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions, or products referred to in the content. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Indicators | MAE | RMSE | MAPE (%) | |
|---|---|---|---|---|
| GRU | 7.674 | 14.123 | 2.6 | 0.852 |
| LSTM | 7.334 | 13.978 | 2.5 | 0.874 |
| CNN | 12.912 | 25.589 | 3.3 | 0.743 |
| BiLSTM | 8.193 | 16.532 | 2.8 | 0.820 |
| CNN-LSTM | 10.559 | 19.056 | 3.0 | 0.761 |
| The proposed model | 6.824 | 12.133 | 2.1 | 0.895 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, X. A Photovoltaic Prediction Model with Integrated Attention Mechanism. Mathematics 2024, 12, 2103. https://doi.org/10.3390/math12132103
Lei X. A Photovoltaic Prediction Model with Integrated Attention Mechanism. Mathematics. 2024; 12(13):2103. https://doi.org/10.3390/math12132103
Chicago/Turabian StyleLei, Xiangshu. 2024. "A Photovoltaic Prediction Model with Integrated Attention Mechanism" Mathematics 12, no. 13: 2103. https://doi.org/10.3390/math12132103
APA StyleLei, X. (2024). A Photovoltaic Prediction Model with Integrated Attention Mechanism. Mathematics, 12(13), 2103. https://doi.org/10.3390/math12132103