
Software Fault Localization Based on Weighted Association Rule Mining and Complex Networks


Abstract
:1. Introduction
- (1)
- FL-WARMCN assigns different weights to test cases and utilizes complex networks to obtain the importance of statements. By simultaneously considering the importance of test cases and statements, it enhances the differentiation of statements to break the elements tie.
- (2)
- FL-WARMCN visualizes the complex relationships between statements by modeling a network. It also takes into account the correlation between the target and related statements, and the importance of related statements through the eigenvector centrality.
- (3)
- We conducted experimental comparisons between FL-WARMCN and five baseline algorithms on 10 datasets of Defects4J. The results demonstrated that this algorithm outperformed the optimal baseline, with an improvement of 8.29% in the EXAM score and 18.31% in the MWE.
2. Materials and Methods
2.1. Overview of FL-WARMCN
| Algorithm 1: Pseudo-code of FL-WARMCN model |
Inputs: program spectrum S, maximum length of frequent itemsets , support threshold , and confidence threshold ; Outputs: ranked list of statement suspiciousness ; 1 ; /* maximum length of frequent itemsets is set to 2 */ 2 ;/* support threshold is set to 0 */ 3 ;/* confidence threshold is set to 0 */ 4 ;/* create transaction weights, statement weights, and suspiciousness dictionaries, respectively. */ 5 ); 6 C in : 7 ;/* test case importance calculation */ 8 ;/* generate rules through weighted association rule mining */ 9 ; 10 ; 11 ; 12 in P:/*iterate over each statement in the given program*/ 13 ; 14 15 |
2.2. Test Case Importance Calculation
2.3. Statement Importance Calculation
2.4. Fault Location Combining Complex Networks and Weighted Association Rule Mining
3. Results
3.1. Research Questions
3.2. Experimental Subjects
3.3. Evaluation Metrics
- (1)
- Exam
- (2)
- ACC@n
- (3)
- Mean Wasted Effort
3.4. Results Analysis
3.4.1. RQ1: What Impact Do Different Suspiciousness Values as Node Weights of the FL-WARMCN Model Have on Fault Location Performance?
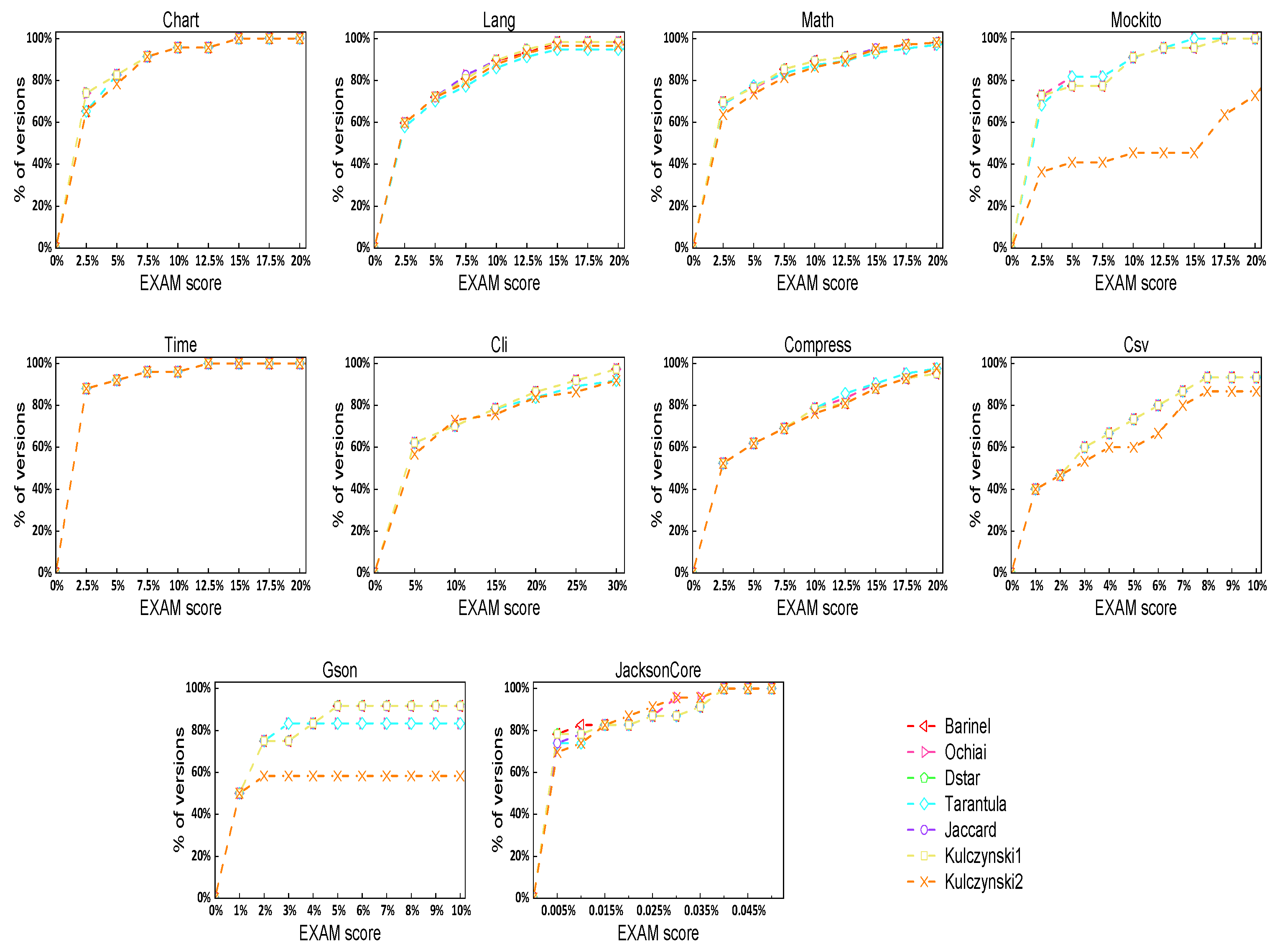
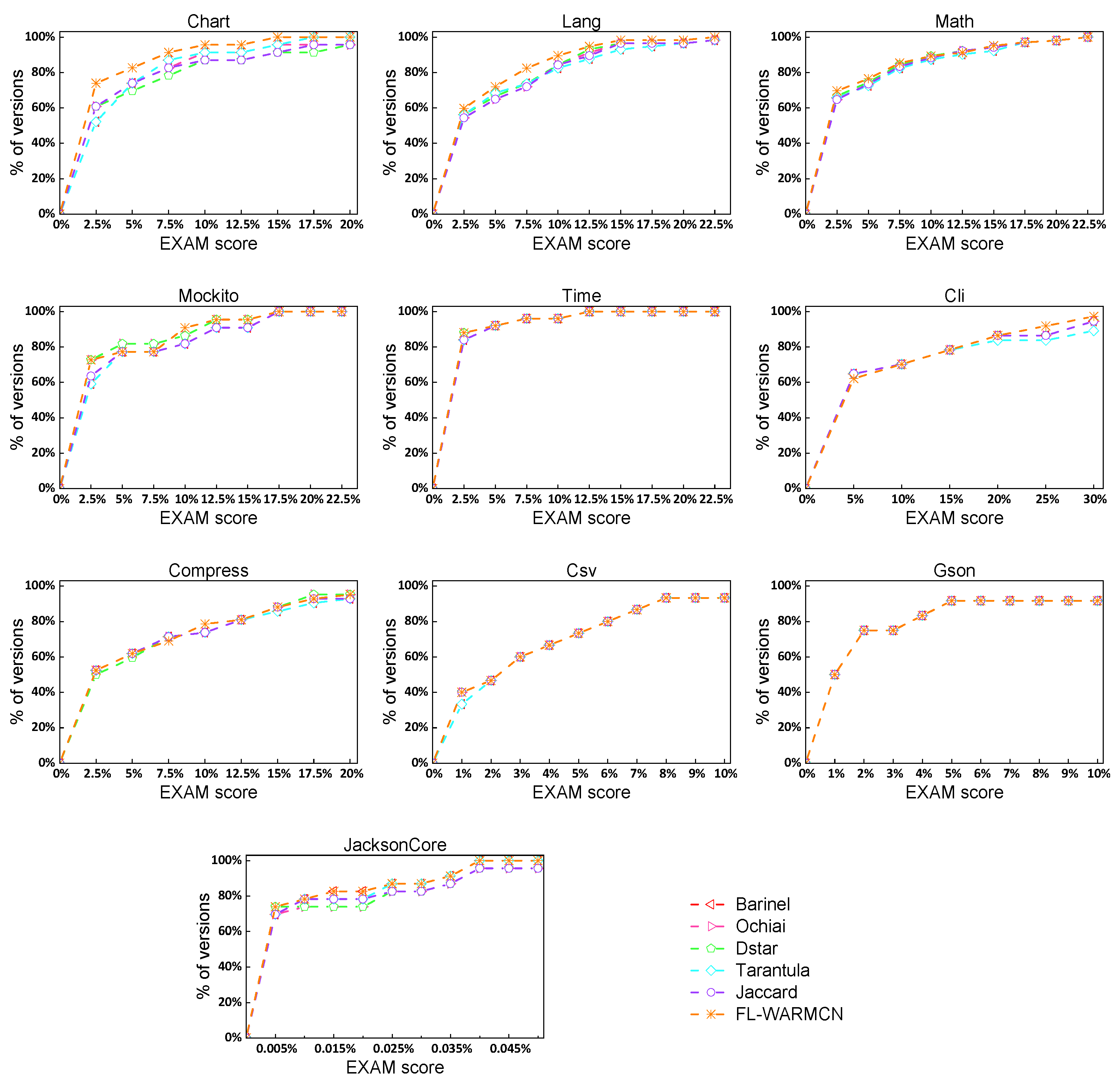
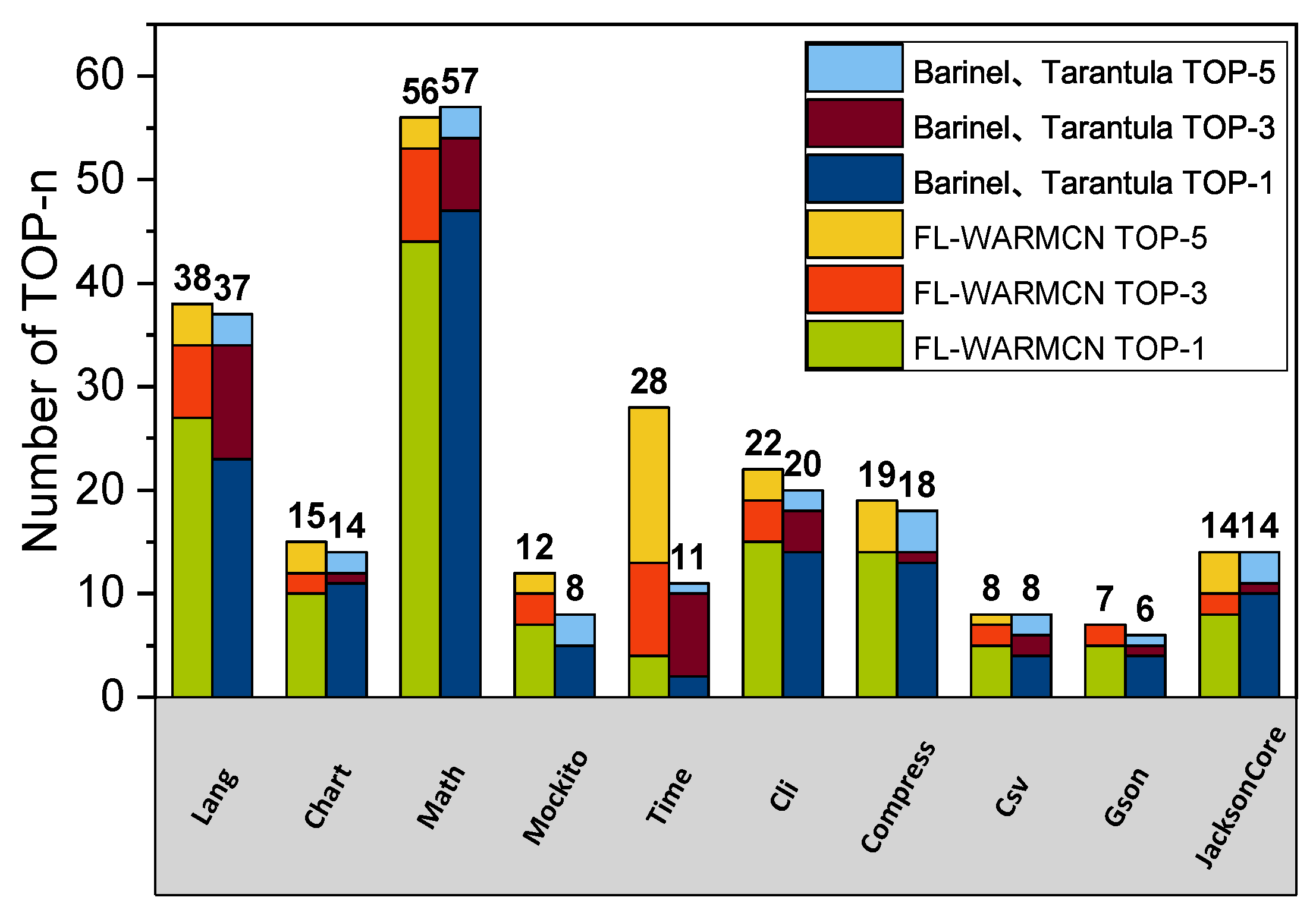
3.4.2. RQ2: Is the FL-WARMCN Model Better Than Other Baseline Fault Location Methods?
4. Discussion
4.1. How Much Improvement Has Been Made in the Fault Localization Efficiency of the FL-WARMCN Model?
4.2. What Is the Impact of Different EDGE weights on the Localization Performance of FL-WARMCN?
4.3. What Is the Computational Complexity of the FL-WARMCN Model?
5. Threats to Validity
5.1. Internal Validity
5.2. External Validity
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SBFL | Spectrum-based Software Fault Location |
| ARM | Association Rule Mining |
| WARM | Weighted Association Rule Mining |
| MWE | Mean Wasted Effort |
References
- Sohn, J.; Yoo, S. Empirical evaluation of fault localisation using code and change metrics. IEEE Trans. Softw. Eng. 2019, 47, 1605–1625. [Google Scholar] [CrossRef]
- Sarhan, Q.I.; Beszédes, Á. A survey of challenges in spectrum-based software fault localization. IEEE Access 2022, 10, 10618–10639. [Google Scholar] [CrossRef]
- Abreu, R.; Zoeteweij, P.; Van Gemund, A.J. Spectrum-based multiple fault localization. In Proceedings of the 2009 IEEE/ACM International Conference on Automated Software Engineering, Auckland, New Zealand, 16–20 November 2009; pp. 88–99. [Google Scholar]
- Abreu, R.; Zoeteweij, P.; Van Gemund, A.J. On the accuracy of spectrum-based fault localization. In Proceedings of the Testing: Academic and Industrial Conference Practice and Research Techniques-MUTATION (TAICPART-MUTATION 2007), Windsor, UK, 10–14 September 2007; pp. 89–98. [Google Scholar]
- Wong, W.E.; Debroy, V.; Choi, B. A family of code coverage-based heuristics for effective fault localization. J. Syst. Softw. 2010, 83, 188–208. [Google Scholar] [CrossRef]
- Jones, J.A.; Harrold, M.J.; Stasko, J. Visualization of test information to assist fault localization. In Proceedings of the 24th International Conference on Software Engineering, Orlando, FL, USA, 25 May 2002; pp. 467–477. [Google Scholar]
- Golagha, M.; Pretschner, A. Challenges of operationalizing spectrum-based fault localization from a data-centric perspective. In Proceedings of the 2017 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Tokyo, Japan, 13–17 May 2017; pp. 379–381. [Google Scholar]
- Wong, W.E.; Gao, R.; Li, Y.; Abreu, R.; Wotawa, F. A survey on software fault localization. IEEE Trans. Softw. Eng. 2016, 42, 707–740. [Google Scholar] [CrossRef]
- Wang, T.; Yu, H.; Wang, K.; Su, X. Fault localization based on wide & deep learning model by mining software behavior. Future Gener. Comput. Syst. 2022, 127, 309–319. [Google Scholar]
- Liu, H.; Li, Z.; Wang, H.; Liu, Y.; Chen, X. CRMF: A fault localization approach based on class reduction and method call frequency. Softw. Pract. Exp. 2023, 53, 1061–1090. [Google Scholar] [CrossRef]
- Youm, K.C.; Ahn, J.; Lee, E. Improved bug localization based on code change histories and bug reports. Inf. Softw. Technol. 2017, 82, 177–192. [Google Scholar] [CrossRef]
- Peng, Z.; Xiao, X.; Hu, G.; Sangaiah, A.K.; Atiquzzaman, M.; Xia, S. ABFL: An autoencoder based practical approach for software fault localization. Inf. Sci. 2020, 510, 108–121. [Google Scholar] [CrossRef]
- Li, X.; Li, W.; Zhang, Y.; Zhang, L. Deepfl: Integrating multiple fault diagnosis dimensions for deep fault localization. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, Beijing, China, 15–19 July 2019; pp. 169–180. [Google Scholar]
- Wong, W.E.; Debroy, V.; Golden, R.; Xu, X.; Thuraisingham, B. Effective software fault localization using an RBF neural network. IEEE Trans. Reliab. 2011, 61, 149–169. [Google Scholar] [CrossRef]
- Xiao, X.; Pan, Y.; Zhang, B.; Hu, G.; Li, Q.; Lu, R. ALBFL: A novel neural ranking model for software fault localization via combining static and dynamic features. Inf. Softw. Technol. 2021, 139, 106653. [Google Scholar] [CrossRef]
- Qian, J.; Ju, X.; Chen, X. GNet4FL: Effective fault localization via graph convolutional neural network. Autom. Softw. Eng. 2023, 30, 16. [Google Scholar] [CrossRef]
- Dorogovtsev, S.N.; Mendes, J.F. Evolution of Networks: From Biological Nets to the Internet and WWW; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Prignano, L.; Moreno, Y.; Díaz-Guilera, A. Exploring complex networks by means of adaptive walkers. Phys. Rev. E 2012, 86, 066116. [Google Scholar] [CrossRef] [PubMed]
- Zakari, A.; Lee, S.P.; Chong, C.Y. Simultaneous localization of software faults based on complex network theory. IEEE Access 2018, 6, 23990–24002. [Google Scholar] [CrossRef]
- Zakari, A.; Lee, S.P.; Hashem, I.A.T. A single fault localization technique based on failed test input. Array 2019, 3, 100008. [Google Scholar] [CrossRef]
- Zhu, L.Z.; Yin, B.B.; Cai, K.Y. Software fault localization based on centrality measures. In Proceedings of the 2011 IEEE 35th Annual Computer Software and Applications Conference Workshops, Munich, Germany, 18–22 July 2011; pp. 37–42. [Google Scholar]
- He, H.; Ren, J.; Zhao, G.; He, H. Enhancing spectrum-based fault localization using fault influence propagation. IEEE Access 2020, 8, 18497–18513. [Google Scholar] [CrossRef]
- Bandyopadhyay, A.; Ghosh, S. Proximity based weighting of test cases to improve spectrum based fault localization. In Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011), Lawrence, KS, USA, 6–10 November 2011; pp. 420–423. [Google Scholar]
- Yoshioka, H.; Higo, Y.; Kusumoto, S. Improving Weighted-SBFL by Blocking Spectrum. In Proceedings of the 2022 IEEE 22nd International Working Conference on Source Code Analysis and Manipulation (SCAM), Limassol, Cyprus, 3 October 2022; pp. 253–263. [Google Scholar]
- Yang, X.; Liu, B.; An, D.; Xie, W.; Wu, W. A Fault Localization Method Based on Similarity Weighting with Unlabeled Test Cases. In Proceedings of the 2022 IEEE 22nd International Conference on Software Quality, Reliability, and Security Companion (QRS-C), Guangzhou, China, 5–9 December 2022; pp. 368–374. [Google Scholar]
- Zhang, M.; Li, Y.; Li, X.; Chen, L.; Zhang, Y.; Zhang, L.; Khurshid, S. An empirical study of boosting spectrum-based fault localization via pagerank. IEEE Trans. Softw. Eng. 2019, 47, 1089–1113. [Google Scholar] [CrossRef]
- Yi, Z.; Wei, L.; Wang, L. Research on association rules based on Complex Networks. In Proceedings of the 2016 2nd Workshop on Advanced Research and Technology in Industry Applications (WARTIA-16), Dalian, China, 14–15 May 2016; pp. 1627–1632. [Google Scholar]
- Choobdar, S.; Silva, F.; Ribeiro, P. Network node label acquisition and tracking. In Proceedings of the Progress in Artificial Intelligence: 15th Portuguese Conference on Artificial Intelligence (EPIA 2011), Lisbon, Portugal, 10–13 October 2011; pp. 418–430. [Google Scholar]
- Zhang, H.; Wang, M.; Deng, W.; Zhou, J.; Liu, L.; Li, J.; Li, R. Identification of Key Factors and Mining of Association Relations in Complex Product Assembly Process. Int. J. Aerosp. Eng. 2022, 2022, 2583437. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, C.; Ding, L.; Sekula, P.; Love, P.E.; Zhou, C. Combining association rules mining with complex networks to monitor coupled risks. Reliab. Eng. Syst. Saf. 2019, 186, 194–208. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Baralis, E.; Cagliero, L.; Cerquitelli, T.; Chiusano, S.; Garza, P. Digging deep into weighted patient data through multiple-level patterns. Inf. Sci. 2015, 322, 51–71. [Google Scholar] [CrossRef]
- Sun, K.; Bai, F. Mining weighted association rules without preassigned weights. IEEE Trans. Knowl. Data Eng. 2008, 20, 489–495. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. J. ACM (JACM) 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Weng, C.H.; Huang, T.C.K. Knowledge acquisition of association rules from the customer-lifetime-value perspective. Kybernetes 2018, 47, 441–457. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, S.; Wu, W.; Qiu, W.; Xie, W. A Software Multi-Fault Clustering Ensemble Technology. In Proceedings of the 2022 IEEE 22nd International Conference on Software Quality, Reliability, and Security Companion (QRS-C), Guangzhou, China, 5–9 December 2022; pp. 352–358. [Google Scholar]
- Shao, Y.; Liu, B.; Wang, S.; Li, G. A novel software defect prediction based on atomic class-association rule mining. Expert Syst. Appl. 2018, 114, 237–254. [Google Scholar] [CrossRef]
- He, Z.; Huang, D.; Fang, J. Social stability risk diffusion of large complex engineering projects based on an improved SIR model: A simulation research on complex networks. Complexity 2021, 2021, 7998655. [Google Scholar] [CrossRef]
- Adeleye, O.; Yu, J.; Wang, G.; Yongchareon, S. Constructing and evaluating evolving web-API Networks-A complex network perspective. IEEE Trans. Serv. Comput. 2021, 16, 177–190. [Google Scholar] [CrossRef]
- Mheich, A.; Wendling, F.; Hassan, M. Brain network similarity: Methods and applications. Netw. Neurosci. 2020, 4, 507–527. [Google Scholar] [CrossRef]
- Wandelt, S.; Shi, X.; Sun, X. Estimation and improvement of transportation network robustness by exploiting communities. Reliab. Eng. Syst. Saf. 2021, 206, 107307. [Google Scholar] [CrossRef]
- Pearson, S.; Campos, J.; Just, R.; Fraser, G.; Abreu, R.; Ernst, M.D.; Pang, D.; Keller, B. Evaluating and improving fault localization. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 609–620. [Google Scholar]
- Wong, W.E.; Debroy, V.; Gao, R.; Li, Y. The DStar method for effective software fault localization. IEEE Trans. Reliab. 2013, 63, 290–308. [Google Scholar] [CrossRef]
- Wolfe, A.W. Social network analysis: Methods and applications. Am. Ethnol. 1997, 24, 219–220. [Google Scholar] [CrossRef]
- Tudisco, F.; Arrigo, F.; Gautier, A. Node and layer eigenvector centralities for multiplex networks. SIAM J. Appl. Math. 2018, 78, 853–876. [Google Scholar] [CrossRef]
- Just, R.; Jalali, D.; Ernst, M.D. Defects4J: A database of existing faults to enable controlled testing studies for Java programs. In Proceedings of the 2014 International Symposium on Software Testing and Analysis, San Jose, CA, USA, 21–25 July 2014; pp. 437–440. [Google Scholar]
- Yan, X.; Liu, B.; Wang, S. A Test Restoration Method based on Genetic Algorithm for effective fault localization in multiple-fault programs. J. Syst. Softw. 2021, 172, 110861. [Google Scholar] [CrossRef]
- Lei, Y.; Xie, H.; Zhang, T.; Yan, M.; Xu, Z.; Sun, C. Feature-fl: Feature-based fault localization. IEEE Trans. Reliab. 2022, 71, 264–283. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Gao, R.; Wong, W.E.; Chen, Z.; Wang, Y. Effective software fault localization using predicted execution results. Softw. Qual. J. 2017, 25, 131–169. [Google Scholar] [CrossRef]
- Besharati, M.M.; Tavakoli Kashani, A. Which set of factors contribute to increase the likelihood of pedestrian fatality in road crashes? Int. J. Inj. Control Saf. Promot. 2018, 25, 247–256. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Wang, S.; Liu, B.; Shao, Y.; Xie, W. A novel software defect prediction approach via weighted classification based on association rule mining. Eng. Appl. Artif. Intell. 2024, 129, 107622. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node Weight | Formula |
|---|---|
| Barinel | |
| Ochiai | |
| DStar | |
| Tarantula | |
| Jaccard | |
| Kulczynski1 | |
| Kulczynski2 |
| Subject | FL-WARMCN | Top-1 | Top-3 | Top-5 | EXAM | MWE | Subject | FL-WARMCN | Top-1 | Top-3 | Top-5 | EXAM | MWE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lang | Barinel | 27 | 34 | 38 | 0.0378 | 14.54 | Cli | Barinel | 15 | 19 | 22 | 0.0825 | 48.26 |
| Ochiai | 27 | 34 | 38 | 0.0375 | 14.52 | Ochiai | 15 | 19 | 22 | 0.0816 | 47.61 | ||
| Dstar | 27 | 34 | 38 | 0.0378 | 14.54 | Dstar | 15 | 19 | 22 | 0.0825 | 48.26 | ||
| Tarantula | 27 | 34 | 38 | 0.0542 | 26.89 | Tarantula | 14 | 19 | 23 | 0.0964 | 57.74 | ||
| Jaccard | 27 | 34 | 38 | 0.0375 | 14.52 | Jaccard | 15 | 19 | 22 | 0.0825 | 48.26 | ||
| Kulczynski1 | 27 | 34 | 38 | 0.0378 | 14.54 | Kulczynski1 | 15 | 19 | 22 | 0.0825 | 48.26 | ||
| Kulczynski2 | 27 | 34 | 38 | 0.0402 | 15.54 | Kulczynski2 | 15 | 20 | 22 | 0.0958 | 54.70 | ||
| Chart | Barinel | 10 | 12 | 15 | 0.0255 | 74.59 | Csv | Barinel | 5 | 7 | 8 | 0.0492 | 16.33 |
| Ochiai | 10 | 12 | 15 | 0.0232 | 29.76 | Ochiai | 5 | 7 | 8 | 0.0492 | 16.33 | ||
| Dstar | 10 | 12 | 15 | 0.0235 | 29.63 | Dstar | 5 | 7 | 8 | 0.0492 | 16.33 | ||
| Tarantula | 11 | 12 | 15 | 0.0250 | 74.15 | Tarantula | 5 | 7 | 8 | 0.0489 | 16.20 | ||
| Jaccard | 10 | 12 | 15 | 0.0235 | 30.24 | Jaccard | 5 | 7 | 8 | 0.0492 | 16.33 | ||
| Kulczynski1 | 10 | 12 | 15 | 0.0235 | 30.24 | Kulczynski1 | 5 | 7 | 8 | 0.0492 | 16.33 | ||
| Kulczynski2 | 10 | 12 | 13 | 0.0276 | 31.20 | Kulczynski2 | 5 | 7 | 8 | 0.0505 | 16.33 | ||
| Math | Barinel | 44 | 52 | 55 | 0.0336 | 54.33 | Compress | Barinel | 14 | 14 | 19 | 0.0606 | 78.80 |
| Ochiai | 45 | 54 | 56 | 0.0367 | 55.26 | Ochiai | 15 | 15 | 19 | 0.0583 | 78.82 | ||
| Dstar | 44 | 52 | 55 | 0.0336 | 54.33 | Dstar | 14 | 14 | 19 | 0.0607 | 78.85 | ||
| Tarantula | 43 | 54 | 57 | 0.0392 | 64.12 | Tarantula | 15 | 15 | 19 | 0.0576 | 78.61 | ||
| Jaccard | 44 | 53 | 56 | 0.0332 | 54.25 | Jaccard | 14 | 14 | 19 | 0.0608 | 78.87 | ||
| Kulczynski1 | 44 | 52 | 55 | 0.0336 | 54.33 | Kulczynski1 | 14 | 14 | 19 | 0.0607 | 78.85 | ||
| Kulczynski2 | 47 | 56 | 58 | 0.0390 | 72.02 | Kulczynski2 | 15 | 15 | 19 | 0.0610 | 80.39 | ||
| Mockito | Barinel | 7 | 10 | 12 | 0.0308 | 42.41 | Gson | Barinel | 5 | 7 | 7 | 0.0557 | 140.50 |
| Ochiai | 7 | 10 | 12 | 0.0276 | 38.45 | Ochiai | 4 | 6 | 6 | 0.0783 | 140.00 | ||
| Dstar | 7 | 10 | 12 | 0.0308 | 42.41 | Dstar | 5 | 7 | 7 | 0.0557 | 140.50 | ||
| Tarantula | 6 | 8 | 10 | 0.0296 | 45.18 | Tarantula | 4 | 6 | 6 | 0.0779 | 139.33 | ||
| Jaccard | 7 | 10 | 12 | 0.0308 | 42.41 | Jaccard | 5 | 7 | 7 | 0.0557 | 140.50 | ||
| Kulczynski1 | 7 | 10 | 12 | 0.0308 | 42.41 | Kulczynski1 | 5 | 7 | 7 | 0.0557 | 140.50 | ||
| Kulczynski2 | 5 | 7 | 7 | 0.1173 | 181.11 | Kulczynski2 | 4 | 6 | 6 | 0.1051 | 198.58 | ||
| Time | Barinel | 4 | 9 | 15 | 0.0130 | 74.26 | JacksonCore | Barinel | 9 | 11 | 14 | 0.0072 | 28.20 |
| Ochiai | 4 | 9 | 15 | 0.0130 | 74.30 | Ochiai | 9 | 12 | 14 | 0.0067 | 28.83 | ||
| Dstar | 4 | 9 | 15 | 0.0130 | 74.26 | Dstar | 8 | 10 | 13 | 0.0072 | 28.26 | ||
| Tarantula | 4 | 9 | 15 | 0.0130 | 73.86 | Tarantula | 9 | 11 | 14 | 0.0075 | 31.20 | ||
| Jaccard | 4 | 9 | 15 | 0.0130 | 74.26 | Jaccard | 8 | 10 | 14 | 0.0072 | 28.87 | ||
| Kulczynski1 | 4 | 9 | 15 | 0.0130 | 74.26 | Kulczynski1 | 8 | 10 | 14 | 0.0072 | 28.13 | ||
| Kulczynski2 | 4 | 9 | 15 | 0.0131 | 74.92 | Kulczynski2 | 10 | 11 | 13 | 0.0071 | 33.04 |
| Barinel | Ochiai | Dstar | Tarantula | Jaccard | FL-WARMCN | |
|---|---|---|---|---|---|---|
| EXAM | 0.0454 | 0.0434 | 0.0436 | 0.0469 | 0.0447 | 0.0398 |
| TOP-1 | 132 | 130 | 131 | 132 | 129 | 139 |
| TOP-3 | 169 | 167 | 168 | 169 | 166 | 175 |
| TOP-5 | 192 | 193 | 193 | 192 | 191 | 206 |
| MWE | 59.97 | 61.66 | 61.49 | 61.21 | 63.79 | 48.99 |
| Improvement | ||||||
| EXAM | 12.33% | 8.29% | 8.72% | 15.14% | 10.96% | - |
| TOP-1 | 5.30% | 6.92% | 6.11% | 5.30% | 7.75% | - |
| TOP-3 | 3.55% | 4.79% | 4.17% | 3.55% | 5.42% | - |
| TOP-5 | 7.29% | 6.74% | 6.74% | 7.29% | 7.85% | - |
| MWE | 18.31% | 20.55% | 20.33% | 19.96% | 23.20% | - |
| p-Value | |
|---|---|
| FL-WARMCN = Barinel | |
| FL-WARMCN = Ochiai | |
| FL-WARMCN = Dstar | |
| FL-WARMCN = Tarantula | |
| FL-WARMCN = Jaccard |
| Datasets | Accuracy | Lift | Support |
|---|---|---|---|
| Chart | 0.0251 | 0.0256 | 0.0754 |
| Lang | 0.0375 | 0.0376 | 0.0500 |
| Math | 0.0332 | 0.0346 | 0.0650 |
| Mockito | 0.0308 | 0.0316 | 0.0604 |
| Time | 0.0130 | 0.0132 | 0.0627 |
| Cli | 0.0825 | 0.0844 | 0.1296 |
| Compress | 0.0608 | 0.0622 | 0.0991 |
| Csv | 0.0492 | 0.0489 | 0.1160 |
| Gson | 0.0557 | 0.0542 | 0.0942 |
| JacksonCore | 0.0072 | 0.0073 | 0.0073 |
| W/T/L | - | 8/0/2 | 10/0/0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Wang, S.; Liu, B. Software Fault Localization Based on Weighted Association Rule Mining and Complex Networks. Mathematics 2024, 12, 2113. https://doi.org/10.3390/math12132113
Wu W, Wang S, Liu B. Software Fault Localization Based on Weighted Association Rule Mining and Complex Networks. Mathematics. 2024; 12(13):2113. https://doi.org/10.3390/math12132113
Chicago/Turabian StyleWu, Wentao, Shihai Wang, and Bin Liu. 2024. "Software Fault Localization Based on Weighted Association Rule Mining and Complex Networks" Mathematics 12, no. 13: 2113. https://doi.org/10.3390/math12132113