
Binary Encoding-Based Federated Learning for Traffic Sign Recognition in Autonomous Driving

Abstract
1. Introduction
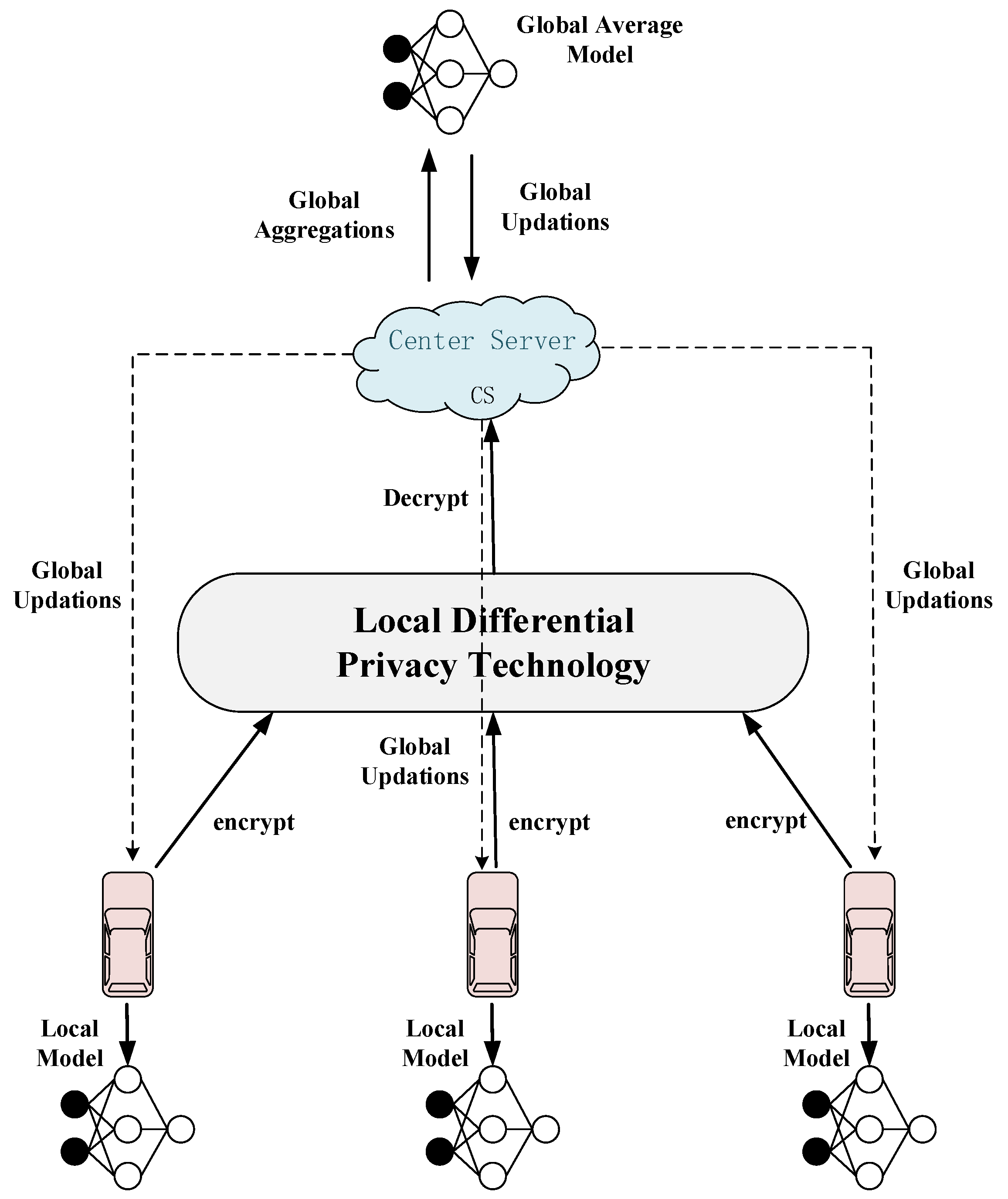
- A local differential privacy-based federated learning method is proposed. The model is trained locally in vehicles, and then the model parameters are uploaded to the central server. The advantage is that the original data can be saved in the vehicle itself, which can achieve higher recognition accuracy while protecting the privacy of vehicle users.
- A new random perturbation method of binary string bits is proposed. Before the model parameters are uploaded to the central server, binary encoding and disturbance are carried out. Therefore, even if the model parameters are leaked, the attacker cannot obtain any valid information.
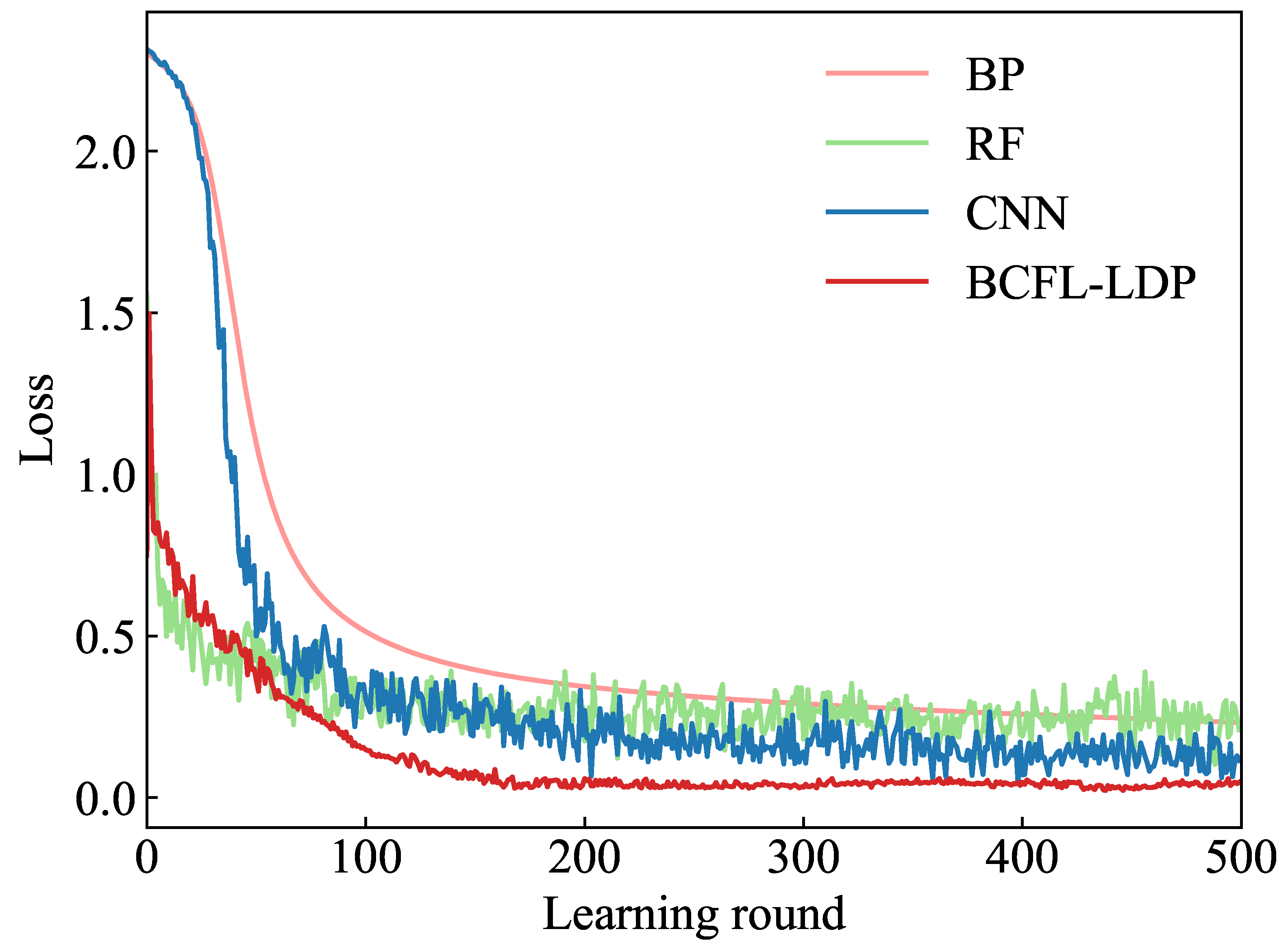
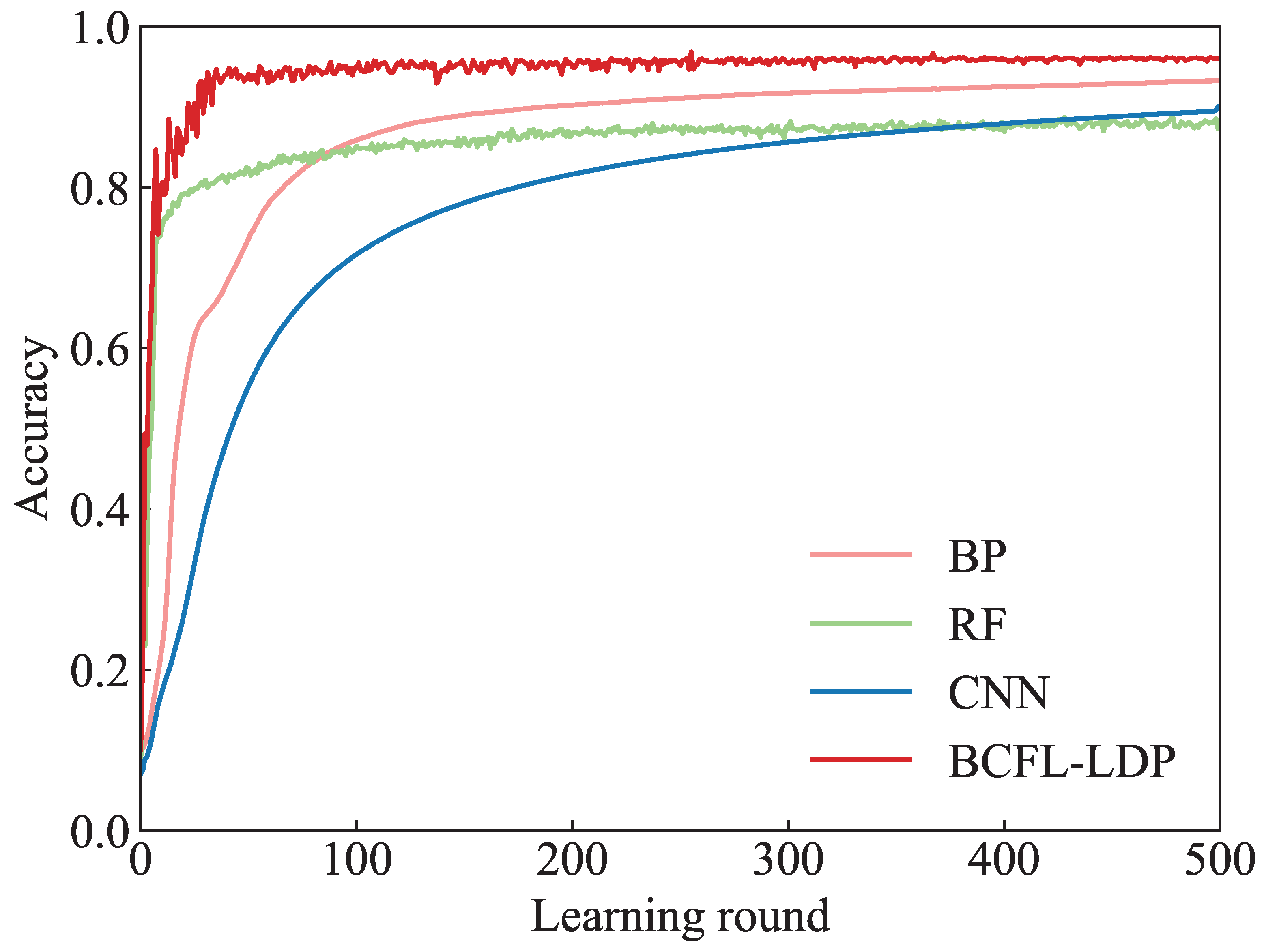
- Through the training of the GTSRB dataset, the proposed BCFL-LDP is verified to be superior to the existing traffic sign recognition methods. The proposed BCFL-LDP has a faster convergence speed than the baselines and is more suitable for actual autonomous driving scenes.
2. Related Work
2.1. Federated Learning
2.2. Differential Privacy
2.2.1. Centralized Differential Privacy
2.2.2. Local Differential Privacy
2.3. Secure Multi-Party Computation
3. Model Definition
3.1. A Basic Model Structure
3.2. Problem Definition
4. BCFL-LDP
4.1. Convolutional Neural Network
4.2. Federated Learning Based on Local Differential Privacy
4.2.1. Vehicle Layer
- The initial value of a binary string of length l is set to 0.
- Model parameters are converted to binary strings and represented as .
- Each bit i on is added with random perturbation to obtain a new string .
4.2.2. Central Server Layer
- The binary string is received by the central server from the vehicles.
- The value 1 corresponding to each bit i of in the central server is summed to obtain .
- Each is corrected to obtain the statistical value :
- The model parameter is obtained by aggregating the binary string T according to its corresponding weights.
4.3. Model Aggregation Update
4.4. BCFL-LDP Method
| Algorithm 1 Traffic sign recognitin based on BCFL-LDP. |
| Input: A set of raw provided by data owners Participated data owners Deep learning model Output: A trained global object detection model M
|
5. Experiment and Analysis
5.1. Dataset and Experiment Setup
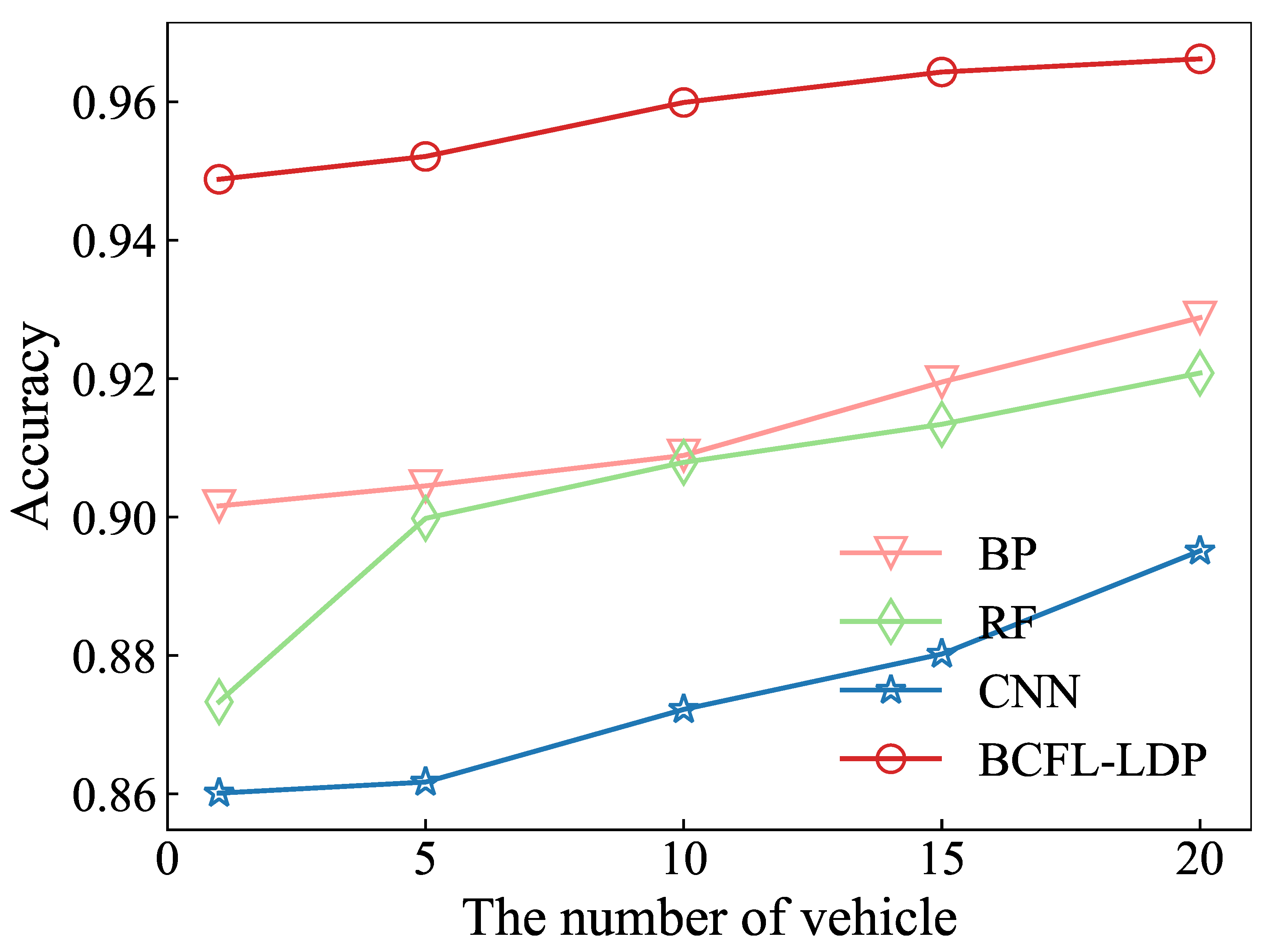
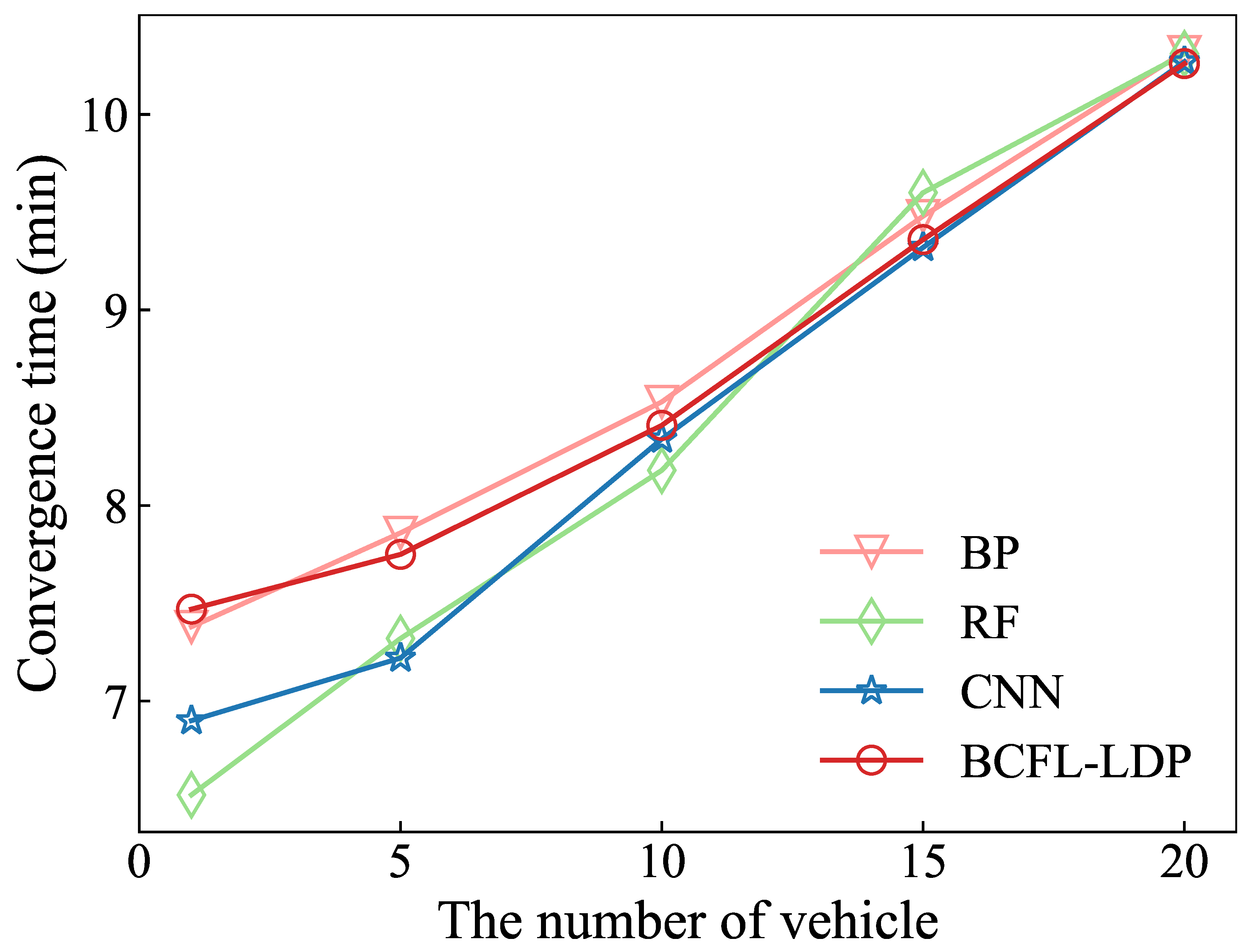
5.2. Experiment Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Garg, S.; Kaur, K.; Kaddoum, G.; Ahmed, S.H.; Jayakody, D.N.K. SDN-based secure and privacy-preserving scheme for vehicular networks: A 5G perspective. IEEE Trans. Veh. Technol. 2019, 68, 8421–8434. [Google Scholar] [CrossRef]
- Yang, F.; Wang, S.; Li, J.; Liu, Z.; Sun, Q. An overview of internet of vehicles. China Commun. 2014, 11, 1–15. [Google Scholar] [CrossRef]
- Lin, X.; Sun, X.; Ho, P.; Shen, X. GSIS: A secure and privacy-preserving protocol for vehicular communications. IEEE Trans. Veh. Technol. 2007, 56, 3442–3456. [Google Scholar]
- Zhou, X.; Liang, W.; She, J.; Yan, Z.; Wang, K.I.-K. Two-Layer Federated Learning with Heterogeneous Model Aggregation for 6G Supported Internet of Vehicles. IEEE Trans. Veh. Technol. 2021, 70, 5308–5317. [Google Scholar] [CrossRef]
- Zhou, X.; Chen, M.; Peng, L.; Li, H. ACPP: An effective privacy preserving scheme for precise location sharing in internet of vehicles. In Proceedings of the 2017 IEEE International Conference on Information and Automation (ICIA), Macau, China, 18–20 July 2017; pp. 883–887. [Google Scholar]
- Wei, F.; Zeadally, S.; Vijayakumar, P.; Kumar, N.; He, D. An Intelligent Terminal Based Privacy-Preserving Multi-Modal Implicit Authentication Protocol for Internet of Connected Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3939–3951. [Google Scholar] [CrossRef]
- Sermanet, P.; LeCun, Y. Traffic sign recognition with multi-scale convolutional networks. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2809–2813. [Google Scholar]
- Yao, C.; Wu, F.; Chen, H.-J.; Hao, X.-L.; Shen, Y. Traffic sign recognition using hog-svm and grid search. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014; pp. 962–965. [Google Scholar]
- Kuang, X.; Fu, W.; Yang, L. Real-Time Detection and Recognition of Road Traffic Signs Using MSER and Random Forests. Int. J. Online Eng. 2018, 14, 34–51. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, J.; Zhang, N.; Fang, X.; Liu, D. A federated bidirectional connection broad learning scheme for secure data sharing in Internet of Vehicles. China Commun. 2021, 18, 117–133. [Google Scholar] [CrossRef]
- Aadhavan, A.; Ahmed, A.; Vellaian, V.M.; Dhanush, K.P.; Rajkumar, S. Prediction and classification of traffic data with KNN and RFR for a smart internet of vehicles system. In Proceedings of the 4th Smart Cities Symposium (SCS 2021), Online, 21–23 November 2021; pp. 146–151. [Google Scholar]
- Manoj, T.; Makkithaya, K.; Narendra, V.G. A Federated Learning-Based Crop Yield Prediction for Agricultural Production Risk Management. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; pp. 1–7. [Google Scholar]
- Nasajpour, M.; Karakaya, M.; Pouriyeh, S.; Parizi, R.M. Federated Transfer Learning For Diabetic Retinopathy Detection Using CNN Architectures. SoutheastCon 2022, 2022, 655–660. [Google Scholar]
- Abdel-Basset, M.; Moustafa, N.; Hawash, H.; Razzak, I.; Sallam, K.M.; Elkomy, O.M. Federated Intrusion Detection in Blockchain-Based Smart Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2523–2537. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Tchaye-Kondi, J.; Zhai, Y.; Shen, J.; Zhu, L. Privacy-Preserving Offloading in Edge Intelligence Systems with Inductive Learning and Local Differential Privacy. IEEE Trans. Netw. Serv. Manag. 2023, 20, 5026–5037. [Google Scholar] [CrossRef]
- Mills, J.; Hu, J.; Min, G. Multi-Task Federated Learning for Personalised Deep Neural Networks in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 630–641. [Google Scholar] [CrossRef]
- Lin, K.P.; Chang, Y.W.; Chen, M.S. Secure support vector machines out sourcing with random linear transformation. Knowl. Inf. Syst. 2015, 44, 147–176. [Google Scholar] [CrossRef]
- Ünal, A.B.; Akgün, M.; Pfeifer, N. Escaped: Efficient secure and private dot product framework for kernel-based machine learning algorithms with applications in healthcare. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 9988–9996. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Zhu, Y.; Liu, Y.; Yu, J.J.Q.; Yuan, X. Semi-Supervised Federated Learning for Travel Mode Identification from GPS Trajectories. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2380–2391. [Google Scholar] [CrossRef]
- Yu, Z.; Hu, J.; Min, G.; Zhao, Z.; Miao, W.; Hossain, M.S. Mobility-Aware Proactive Edge Caching for Connected Vehicles Using Federated Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5341–5351. [Google Scholar] [CrossRef]
- Poddar, M.; Ganta, S.; Swaraj, K.R.; Das, D. Privacy in the Internet of Vehicles: Models, Algorithms, and Applications. In Proceedings of the 2019 International Conference on Information Networking (ICOIN), Kuala Lumpur, Malaysia, 9–11 January 2019; pp. 78–83. [Google Scholar]
- Wang, S.; Li, J.; Wu, G.; Chen, H.; Sun, S. Joint Optimization of Task Offloading and Resource Allocation Based on Differential Privacy in Vehicular Edge Computing. IEEE Trans. Comput. Soc. Syst. 2022, 9, 109–119. [Google Scholar] [CrossRef]
- Nie, Y.; Zhao, J.; Gao, F.; Yu, F.R. Semi-Distributed Resource Management in UAV-Aided MEC Systems: A Multi-Agent Federated Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2021, 70, 13162–13173. [Google Scholar] [CrossRef]
- Karim, H.; Rawat, D.B. TollsOnly Please—Homomorphic Encryption for Toll Transponder Privacy in Internet of Vehicles. IEEE Internet Things J. 2022, 9, 2627–2636. [Google Scholar] [CrossRef]
- Thant, M.; Zaw, T.M. Authentication Protocols and Authentication on the Base of PKI and ID-Based. In Proceedings of the 2018 Wave Electronics and its Application in Information and Telecommunication Systems (WECONF), St. Petersburg, FL, USA, 26–30 November 2018; pp. 1–8. [Google Scholar]
- Peng, H.; He, M.; Li, L.; Yang, Y. A New Lightweight Key Exchange Protocol Based on T—Tensor Product. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 736–741. [Google Scholar]
- Boicea, A.; Radulescu, F.; Truica, C.-O.; Costea, C. Database Encryption Using Asymmetric Keys: A Case Study. In Proceedings of the 2017 21st International Conference on Control Systems and Computer Science (CSCS), Bucharest, Romania, 29–31 May 2017; pp. 317–323. [Google Scholar]
- Wu, X.; Zhu, X.; Kong, F. Routing and Data Security Scheme Based on Double Encryption in Mobile Ad Hoc Networks. In Proceedings of the 2015 Fifth International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), Qinhuangdao, China, 18–20 September 2015; pp. 1787–1791. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Methods | |||
|---|---|---|---|---|
| Performance | CNN | RF | BP | BCFL-LDP |
| Accuracy | 1 | 104% | 104% | 110% |
| Convergence time | 1 | 98% | 102% | 101% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, Y.; Zhou, Y.; Gao, K. Binary Encoding-Based Federated Learning for Traffic Sign Recognition in Autonomous Driving. Mathematics 2024, 12, 2229. https://doi.org/10.3390/math12142229
Wen Y, Zhou Y, Gao K. Binary Encoding-Based Federated Learning for Traffic Sign Recognition in Autonomous Driving. Mathematics. 2024; 12(14):2229. https://doi.org/10.3390/math12142229
Chicago/Turabian StyleWen, Yian, Yun Zhou, and Kai Gao. 2024. "Binary Encoding-Based Federated Learning for Traffic Sign Recognition in Autonomous Driving" Mathematics 12, no. 14: 2229. https://doi.org/10.3390/math12142229
APA StyleWen, Y., Zhou, Y., & Gao, K. (2024). Binary Encoding-Based Federated Learning for Traffic Sign Recognition in Autonomous Driving. Mathematics, 12(14), 2229. https://doi.org/10.3390/math12142229