
Addressing Noisy Pixels in Weakly Supervised Semantic Segmentation with Weights Assigned

Abstract
:1. Introduction
- We recognize that the elimination of noisy labels is challenging to achieve. Therefore, we focus on transforming the uncertainty of pixels into loss weights, thereby mitigating the impact of noisy pixels on model performance.
- The uncertainty-weight transform module is proposed to dynamically transform pixel uncertainty into loss weight. The critical aspect of the module lies in a set of functions with different thresholds but of the same form.
- The experimental results illustrate the effectiveness of the proposed method. The designed functions are also efficient in mitigating the impact of noisy pixels from other datasets under different threshold controls.
2. Related Work
2.1. Weakly Supervised Semantic Segmentation
2.2. Label Noise Learning
- (1)
- Loss correction: The method modifies the loss for each example by multiplying the estimated label transition probability with the output of the specified DNN. Several advanced methods have been proposed to validate the effectiveness of loss correction. Clean validation data were utilized by Gold loss correction [38] as additional information to obtain a more accurate transition matrix, thereby further improving the robustness of loss correction. T-revision [39] was proposed to infer the transition matrix without anchor points. However, the effectiveness of loss correction depends on the accuracy of estimating the transition matrix. Obtaining a precise transition matrix typically requires prior knowledge, such as anchor points or clean validation data.
- (2)
- Loss reweighting: Loss reweighting alleviates the harm of noisy labels by modifying the weights of the loss function. Specifically, it aims to assign smaller weights to the pixels with false labels and greater weights to those with true labels [14]. DualGraph [40] leveraged graph neural networks to adjust the weights of examples based on the structural relationships among labels, effectively filtering out anomalous noisy examples. Active bias [41] focused on examples with inconsistent label predictions, utilizing the variances of their predictions as weights during the training process. However, these methods need the manual prespecification of weight functions and the selection of additional hyperparameters, which can be challenging to implement in practice due to the significant variations in appropriate weights.
- (3)
- Label refurbishment: Refurbished labels are a convex combination of noisy labels and DNN output labels. Bootstrapping [42] is the first method to propose the concept of label refurbishment to update the target labels of training samples, and a more coherent network is used to improve the ability to evaluate noisy labels consistency. AdaCorr [43] selectively refurbishes the label of noisy examples, but it comes with a theoretical error bound. Alternatively, SEAL [44] calculates the average of the softmax output of a DNN for each sample during the entire training process and subsequently retrains the DNN using the averaged soft labels. Unlike loss correction and reweighting, label refurbishment explicitly replaces all noisy labels with approximate clean labels. However, when the proportion of noisy labels is high, there is a risk of overfitting to the incorrectly refurbished samples.
3. Methodology
3.1. Overview
3.2. Preliminaries
3.2.1. Dense-CRF
3.2.2. Class Activation Map
3.2.3. Problem Definition
3.3. Label Noise Learning in WSSS
3.3.1. Probability Statistic
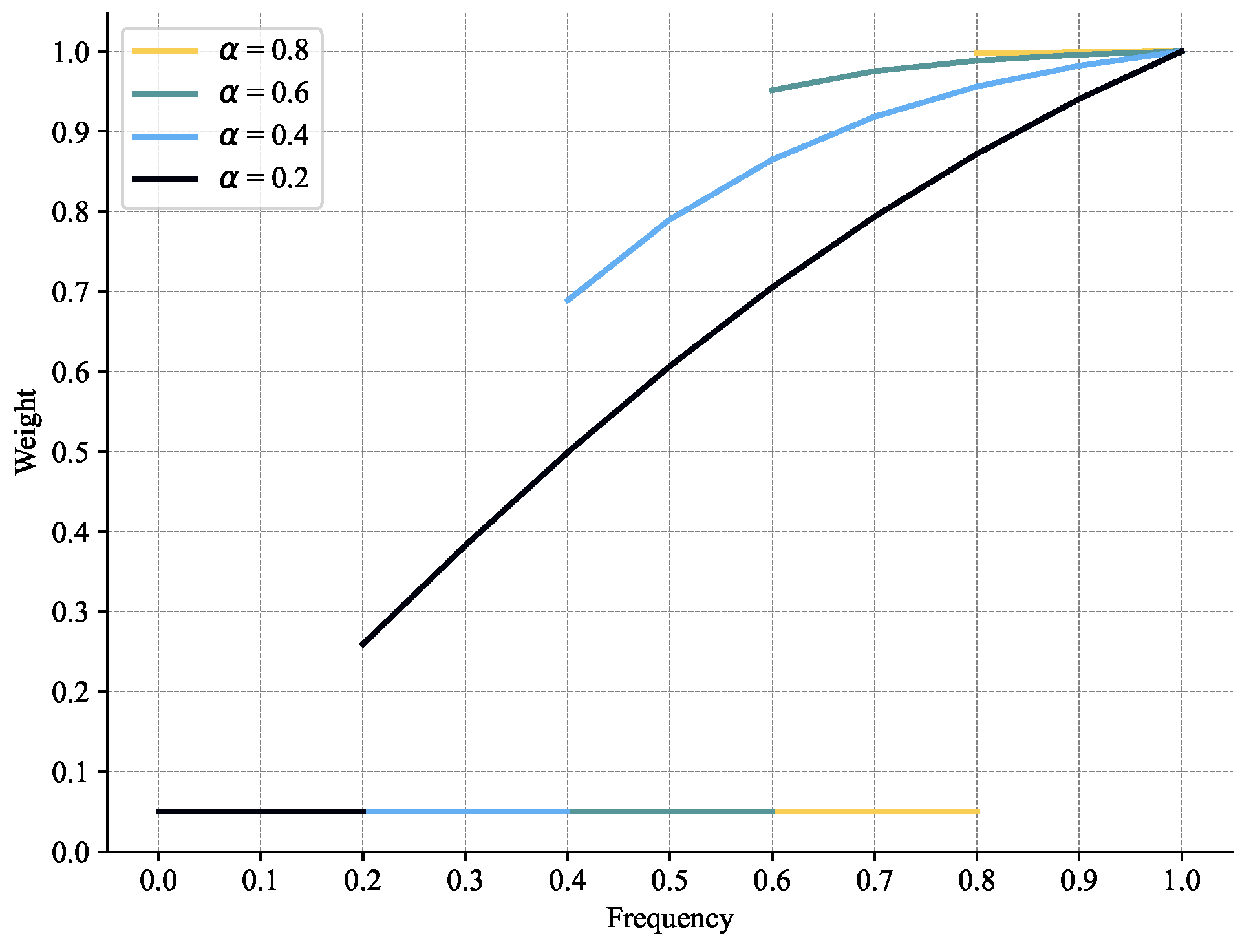
3.3.2. Uncertainty-Weight Transform Module
3.4. Loss Function
4. Experiments
4.1. Experiments Setting
4.1.1. Dataset
4.1.2. Baseline
4.1.3. Hyperparameters Setting
4.2. Experimental Results and Analysis
4.2.1. Comparisons with Baseline
4.2.2. Ablation Studies
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kong, L.; Ren, J.; Pan, L.; Liu, Z. Lasermix for semi-supervised lidar semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21705–21715. [Google Scholar]
- Xie, B.; Li, S.; Li, M.; Liu, C.H.; Huang, G.; Wang, G. Sepico: Semantic-guided pixel contrast for domain adaptive semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9004–9021. [Google Scholar] [CrossRef]
- Shen, W.; Peng, Z.; Wang, X.; Wang, H.; Cen, J.; Jiang, D.; Xie, L.; Yang, X.; Tian, Q. A survey on label-efficient deep image segmentation: Bridging the gap between weak supervision and dense prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9284–9305. [Google Scholar] [CrossRef] [PubMed]
- Lai, X.; Tian, Z.; Jiang, L.; Liu, S.; Zhao, H.; Wang, L.; Jia, J. Semi-supervised semantic segmentation with directional context-aware consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1205–1214. [Google Scholar]
- Hu, R.; Dollár, P.; He, K.; Darrell, T.; Girshick, R. Learning to segment every thing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4233–4241. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12414–12424. [Google Scholar]
- Tang, M.; Perazzi, F.; Djelouah, A.; Ben Ayed, I.; Schroers, C.; Boykov, Y. On regularized losses for weakly-supervised cnn segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 507–522. [Google Scholar]
- Oh, Y.; Kim, B.; Ham, B. Background-aware pooling and noise-aware loss for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6913–6922. [Google Scholar]
- Sun, W.; Zhang, J.; Barnes, N. 3d guided weakly supervised semantic segmentation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November 2020; pp. 585–602. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12275–12284. [Google Scholar]
- Fan, J.; Zhang, Z.; Tan, T.; Song, C.; Xiao, J. Cian: Cross-image affinity net for weakly supervised semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10762–10769. [Google Scholar]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5495–5505. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8135–8153. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Liu, K.; Zhu, W.; Shen, Y.; Fernandez-Granda, C. Adaptive early-learning correction for segmentation from noisy annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2606–2616. [Google Scholar]
- Hendrycks, D.; Mazeika, M.; Wilson, D.; Gimpel, K. Using Trusted Data to Train Deep Networks on Labels Corrupted by Severe Noise. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; Mcguinness, K. Unsupervised Label Noise Modeling and Loss Correction. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; ML Research Press: Maastricht, Dutch, 2019; Volume 97, pp. 312–321. [Google Scholar]
- Zhang, B.; Xiao, J.; Wei, Y.; Sun, M.; Huang, K. Reliability does matter: An end-to-end weakly supervised semantic segmentation approach. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12765–12772. [Google Scholar]
- Chen, Z.; Wang, T.; Wu, X.; Hua, X.S.; Zhang, H.; Sun, Q. Class re-activation maps for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 24 June 2022; pp. 969–978. [Google Scholar]
- Li, Y.; Kuang, Z.; Liu, L.; Chen, Y.; Zhang, W. Pseudo-mask matters in weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 6964–6973. [Google Scholar]
- Li, Y.; Duan, Y.; Kuang, Z.; Chen, Y.; Zhang, W.; Li, X. Uncertainty estimation via response scaling for pseudo-mask noise mitigation in weakly-supervised semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 1447–1455. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? Adv. Neural Inf. Process. Syst. 2017, 30, 5574–5584. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Murphy, C.; Tawn, J.A.; Varty, Z. Automated threshold selection and associated inference uncertainty for univariate extremes. arXiv 2023, arXiv:2310.17999. [Google Scholar]
- Kamble, P.M.; Ruikar, D.D.; Houde, K.V.; Hegadi, R.S. Adaptive threshold-based database preparation method for handwritten image classification. In Proceedings of the International Conference on Recent Trends in Image Processing and Pattern Recognition, Msida, Malta, 8–10 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 280–288. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Song, C.; Ouyang, W.; Zhang, Z. Weakly Supervised Semantic Segmentation via Box-Driven Masking and Filling Rate Shifting. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15996–16012. [Google Scholar] [CrossRef]
- Zhang, D.; Li, H.; Zeng, W.; Fang, C.; Cheng, L.; Cheng, M.M.; Han, J. Weakly supervised semantic segmentation via alternate self-dual teaching. IEEE Trans. Image Process. 2023; early access. [Google Scholar] [CrossRef]
- Li, R.; Mai, Z.; Zhang, Z.; Jang, J.; Sanner, S. Transcam: Transformer attention-based cam refinement for weakly supervised semantic segmentation. J. Vis. Commun. Image Represent. 2023, 92, 103800. [Google Scholar] [CrossRef]
- Jiang, P.T.; Hou, Q.; Cao, Y.; Cheng, M.M.; Wei, Y.; Xiong, H.K. Integral object mining via online attention accumulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2070–2079. [Google Scholar]
- Chang, Y.T.; Wang, Q.; Hung, W.C.; Piramuthu, R.; Tsai, Y.H.; Yang, M.H. Weakly-supervised semantic segmentation via sub-category exploration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8991–9000. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Z.; Yang, F.; Qiu, F.; Coleman, S.; Kerr, D. A novel seminar learning framework for weakly supervised salient object detection. Eng. Appl. Artif. Intell. 2024, 126, 106961. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, Z.; Song, C.; Tan, T. Learning integral objects with intra-class discriminator for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4283–4292. [Google Scholar]
- Yao, Q.; Gong, X. Saliency guided self-attention network for weakly and semi-supervised semantic segmentation. IEEE Access 2020, 8, 14413–14423. [Google Scholar] [CrossRef]
- Ma, Z.; Chen, D.; Zhang, C.Y. A Weakly Supervised Semantic Segmentation Method Based on Local Superpixel Transformation. Neural Process. Lett. 2023, 55, 12039–12060. [Google Scholar] [CrossRef]
- Zhong, L.; Wang, G.; Liao, X.; Zhang, S. HAMIL: High-Resolution Activation Maps and Interleaved Learning for Weakly Supervised Segmentation of Histopathological Images. IEEE Trans. Med. Imaging 2023, 42, 2912–2923. [Google Scholar] [CrossRef]
- Bernhardt, M.; de Castro, D.C.; Tanno, R.; Schwaighofer, A.; Tezcan, K.C.; Monteiro, M.A.B.; Bannur, S.; Lungren, M.P.; Nori, A.; Glocker, B.; et al. Active label cleaning for improved dataset quality under resource constraints. Nat. Commun. 2021, 13, 1161. [Google Scholar] [CrossRef]
- Zhang, Y.; Sugiyama, M. Approximating Instance-Dependent Noise via Instance-Confidence Embedding. arXiv 2021, arXiv:2103.13569. [Google Scholar]
- Xia, X.; Liu, T.; Wang, N.; Han, B.; Gong, C.; Niu, G.; Sugiyama, M. Are anchor points really indispensable in label-noise learning? Adv. Neural Inf. Process. Syst. 2019, 32, 6838–6849. [Google Scholar]
- Zhang, H.; Xing, X.; Liu, L. Dualgraph: A graph-based method for reasoning about label noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–15 June 2021; pp. 9654–9663. [Google Scholar]
- Chang, H.S.; Learned-Miller, E.; McCallum, A. Active bias: Training more accurate neural networks by emphasizing high variance samples. Adv. Neural Inf. Process. Syst. 2017, 30, 1002–1012. [Google Scholar]
- Reed, S.E.; Lee, H.; Anguelov, D.; Szegedy, C.; Erhan, D.; Rabinovich, A. Training Deep Neural Networks on Noisy Labels with Bootstrapping. arXiv 2014, arXiv:1412.6596. [Google Scholar]
- Zheng, S.; Wu, P.; Goswami, A.; Goswami, M.; Metaxas, D.; Chen, C. Error-bounded correction of noisy labels. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 11447–11457. [Google Scholar]
- Chen, P.; Ye, J.; Chen, G.; Zhao, J.; Heng, P.A. Beyond class-conditional assumption: A primary attempt to combat instance-dependent label noise. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 11442–11450. [Google Scholar]
- Zhang, S.X.; Zhu, X.; Chen, L.; Hou, J.B.; Yin, X.C. Arbitrary shape text detection via segmentation with probability maps. IEEE Trans. Pattern Anal. Mach. Intell 2022, 45, 2736–2750. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- MMSegmentation Contributors. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. 2023. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 3 July 2020).
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5267–5276. [Google Scholar]
- Li, X.; Zhou, T.; Li, J.; Zhou, Y.; Zhang, Z. Group-wise semantic mining for weakly supervised semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 1984–1992. [Google Scholar]
- Liu, Y.; Wu, Y.H.; Wen, P.; Shi, Y.; Qiu, Y.; Cheng, M.M. Leveraging instance-, image-and dataset-level information for weakly supervised instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1415–1428. [Google Scholar] [CrossRef]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Hua, X.S.; Sun, Q. Causal intervention for weakly-supervised semantic segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 655–666. [Google Scholar]
- Ahn, J.; Cho, S.; Kwak, S. Weakly supervised learning of instance segmentation with inter-pixel relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2209–2218. [Google Scholar]
- Shimoda, W.; Yanai, K. Self-supervised difference detection for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5208–5217. [Google Scholar]
- Sun, G.; Wang, W.; Dai, J.; Van Gool, L. Mining cross-image semantics for weakly supervised semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 347–365. [Google Scholar]
- Chen, Q.; Yang, L.; Lai, J.H.; Xie, X. Self-supervised image-specific prototype exploration for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4288–4298. [Google Scholar]
- Pan, J.; Zhu, P.; Zhang, K.; Cao, B.; Wang, Y.; Zhang, D.; Han, J.; Hu, Q. Learning self-supervised low-rank network for single-stage weakly and semi-supervised semantic segmentation. Int. J. Comput. Vis. 2022, 130, 1181–1195. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Supervision | VOC12 Val | VOC12 Test | COCO14 Val |
|---|---|---|---|---|---|
| FickleNet [48] | ResNet-101 | Image-level + Saliency | 64.9% | 65.3% | - |
| OAA [30] | ResNet-101 | Image-level + Saliency | 65.2% | 66.4% | - |
| SGAN [34] | ResNet-101 | Image-level + Saliency | 67.1% | 67.2% | 33.6% |
| ICD [33] | ResNet-101 | Image-level + Saliency | 67.8% | 68.0% | - |
| GWSM [49] | ResNet-101 | Image-level + Saliency | 68.2% | 68.5% | 28.4% |
| LIID [50] | ResNet-101 | Image-level + SOP | 66.5% | 67.5% | - |
| LIID [50] | Res2Net-101 | Image-level + SOP | 68.4% | 68.0% | - |
| AffinityNet [51] | ResNet-38 | Image-level | 61.7% | 63.7% | - |
| SEAM [10] | ResNet-38 | Image-level | 64.5% | 65.7% | 31.7% |
| CONTA [52] | ResNet-38 | Image-level | 66.1% | 66.7% | 32.8% |
| PMM [20] | ResNet-38 | Image-level | 68.5% | 69.0% | 34.7% |
| IRNet [53] | ResNet-50 | Image-level | 63.5% | 64.8% | - |
| OAA [30] | ResNet-101 | Image-level | 63.9% | 65.6% | - |
| ICD [33] | ResNet-101 | Image-level | 64.1% | 64.3% | - |
| SSDD [54] | ResNet-101 | Image-level | 64.9% | 65.5% | - |
| SC-CAM [31] | ResNet-101 | Image-level | 66.1% | 65.9% | - |
| MCIS [55] | ResNet-101 | Image-level | 66.2% | 66.9% | - |
| SIPE [56] | ResNet-101 | Image-level | 68.7% | 67.8% | 36.7% |
| SLRNet [57] | ResNet-101 | Image-level | 68.0% | 68.4% | 35.0% |
| PMM [20] | ScaleNet-101 | Image-level | 67.1% | 67.7% | 35.2% |
| PMM [20] | ResNett-101 | Image-level | 68.7% | 68.7% | 34.7% |
| URN [21] | ResNet-38 | Image-level | 67.1% | 67.9% | 34.8% |
| URN [21] | ResNet-101 | Image-level | 65.9% | 66.3% | 35.1% |
| URN [21] | ScaleNet-101 | Image-level | 68.4% | 69.0% | 35.2% |
| URN [21] | Res2Net-101 | Image-level | 67.6% | 67.7% | 36.0% |
| Our Method | ResNet-38 | Image-level | 67.9% | 69.1% | 36.7% |
| Our Method | ResNet-101 | Image-level | 67.6% | 68.1% | 36.5% |
| Our Method | ScaleNet-101 | Image-level | 69.0% | 69.9% | 36.6% |
| Our Method | Res2Net-38 | Image-level | 69.3% | 69.8% | 37.7% |
| Class | mIoU | |
|---|---|---|
| URN | Our Method | |
| background | 90.60% | 91.14% |
| aeroplane | 78.83% | 79.74% |
| bicycle | 33.56% | 35.13% |
| bird | 88.95% | 87.19% |
| boat | 53.42% | 57.88% |
| bottle | 61.60% | 71.48% |
| bus | 85.68% | 85.63% |
| car | 82.18% | 79.21% |
| cat | 89.24% | 88.50% |
| chair | 31.18% | 30.64% |
| cow | 87.06% | 85.88% |
| diningtable | 54.70% | 55.33% |
| dog | 82.16% | 85.34% |
| horse | 84.23% | 85.23% |
| motorbike | 74.70% | 73.87% |
| person | 76.12% | 76.66% |
| pottedplant | 46.03% | 48.08% |
| sheep | 72.36% | 81.04% |
| sofa | 45.32% | 44.45% |
| train | 56.81% | 57.81% |
| tvmonitor | 49.45% | 54.17% |
| Method | Backbone | VOC12 Val | VOC12 Test |
|---|---|---|---|
| LFCON/CONRF/RLF | ResNet-38 | 65.41%/66.64%/67.9% | 67.03%/66.28%/69.1% |
| LFCON/CONRF/RLF | ResNet-101 | 65.92%/66.21%/67.6% | 66.89%/67.30%/68.1% |
| LFCON/CONRF/RLF | ScaleNet-101 | 67.59%/68.14%/69.0% | 67.52%/68.46%/69.9% |
| LFCON/CONRF/RLF | Res2Net-101 | 67.49%/67.67%/69.3% | 67.70%/67.42%/69.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, F.; Yang, J.; Tang, S.; Chen, G.; Yan, J. Addressing Noisy Pixels in Weakly Supervised Semantic Segmentation with Weights Assigned. Mathematics 2024, 12, 2520. https://doi.org/10.3390/math12162520
Qian F, Yang J, Tang S, Chen G, Yan J. Addressing Noisy Pixels in Weakly Supervised Semantic Segmentation with Weights Assigned. Mathematics. 2024; 12(16):2520. https://doi.org/10.3390/math12162520
Chicago/Turabian StyleQian, Feng, Juan Yang, Sipeng Tang, Gao Chen, and Jingwen Yan. 2024. "Addressing Noisy Pixels in Weakly Supervised Semantic Segmentation with Weights Assigned" Mathematics 12, no. 16: 2520. https://doi.org/10.3390/math12162520