Abstract
The classification of galaxies has significantly advanced using machine learning techniques, offering deeper insights into the universe. This study focuses on the typology of galaxies using data from the Galaxy Zoo project, where classifications are based on the opinions of non-expert volunteers, introducing a degree of uncertainty. The objective of this study is to integrate Fuzzy C-Means (FCM) clustering with explainability methods to achieve a precise and interpretable model for galaxy classification. We applied FCM to manage this uncertainty and group galaxies based on their morphological characteristics. Additionally, we used explainability methods, specifically SHAP (SHapley Additive exPlanations) values and LIME (Local Interpretable Model-Agnostic Explanations), to interpret and explain the key factors influencing the classification. The results show that using FCM allows for accurate classification while managing data uncertainty, with high precision values that meet the expectations of the study. Additionally, SHAP values and LIME provide a clear understanding of the most influential features in each cluster. This method enhances our classification and understanding of galaxies and is extendable to environmental studies on Earth, offering tools for environmental management and protection. The presented methodology highlights the importance of integrating FCM and XAI techniques to address complex problems with uncertain data.
Keywords:
Fuzzy C-Means; explainable AI; XAI; SHAP values; LIME; citizen science; astronomy; machine learning (ML) MSC:
85A35; 62H30
1. Introduction
Galaxy Zoo is a citizen science project that has revolutionized the way we classify galaxies [1]. Through the collaboration of volunteers worldwide, we have been able to analyze and classify millions of galaxy images obtained by telescopes like the Sloan Digital Sky Survey (SDSS) [2]. This approach popularizes science, allowing individuals without specialized training to contribute significantly while addressing the immense task of processing astronomical data that would otherwise be impossible for professional astronomers to manage alone.
The drive behind this type of galaxy classification is the need to better understand the universe we live in. Galaxies are the fundamental building blocks of the cosmos, and studying their shapes, structures, and distributions provides critical insights into the formation and evolution of the universe. However, classifying galaxies is not a trivial task; it requires detailed and careful analysis, traditionally dependent on human visual perception.
Human perception of the real world and what we visualize in cosmic images becomes a highly effective resource when properly channeled. In Galaxy Zoo, thousands of volunteers observe and classify galaxies according to various criteria, such as shape, presence of bars, orientation, and more. Each galaxy is evaluated by multiple individuals, introducing a degree of uncertainty into the data, as not all observers perceive the same characteristics in the same way.
In this context, artificial intelligence (AI) and machine learning (ML) play a significant role. We use advanced AI techniques to process these human classifications and convert them into data that are actionable and understandable by computers. One of the approaches we employ is Fuzzy C-Means (FCM) clustering [3], a technique that allows us to handle the inherent uncertainty in data aggregated from multiple observers. FCM helps us group galaxies into clusters based on their morphological characteristics, reflecting the diversity and variability in human perceptions.
Furthermore, to achieve greater interpretability of AI models, we implement explainability methods such as SHAP (SHapley Additive exPlanations) values [4]. These values enable us to better understand the key factors influencing galaxy classification, providing a clear and comprehensible explanation of how and why certain decisions are made by the model.
Furthermore, to achieve greater interpretability of AI models, we implement explainability methods such as LIME (Local Interpretable Model-agnostic Explanations) [5]. LIME enables us to understand the key factors influencing specific predictions by approximating the model locally around the prediction of interest, providing a clear and comprehensible explanation of how and why certain decisions are made by the model at a local level.
Human–machine collaboration in models of this type is key to obtaining explainability. While human intelligence allows us to offer interpretations and identify fundamental features in images, AI can support the classification of hundreds of thousands of images, making the process more efficient and scalable. This interaction is important for the future development of AI ethics, which combines human expertise with predictive modeling.
The novelty of this work lies in providing a methodology that unifies the processing of information collected through the opinions of individuals with diverse profiles, effectively mitigating the noise introduced by any single person’s opinion. Essentially, this approach leverages a group-based assessment to average the weight of each identified variable. Additionally, the use of FCM aids in obtaining a clear classification, enabling the analysis of trends and deviations relative to the most popular selections. Finally, the application of Explainable AI (XAI) techniques allows for a comprehensive understanding of the model’s classification process, utilizing SHAP values for global predictions and LIME for local predictions.
The primary purpose of this work is to demonstrate how human perceptions can be channeled and processed through AI techniques to generate actionable insights. By doing this, we enhance our understanding of the cosmos and illustrate how these methodologies can be applied to other fields, including sustainability and environmental management on Earth. This interdisciplinary approach highlights the importance of combining human perception with the power of automated data analysis to tackle complex problems and generate deep and practical insights.
In the remainder of this paper, we will develop and implement the Fuzzy C-Means (FCM) and Explainable AI (XAI) model, following the structure outlined below: In Section 2, we will review the current state of studies on galaxy classification using machine learning (ML) techniques, focusing specifically on Fuzzy C-Means. We will delve into studies that apply a combination of clustering metrics and explainability techniques. Section 3 will describe the Fuzzy C-Means and Explainable AI (FCM-XAI) methodological framework, which enhances both the accuracy and transparency of the classification models. In Section 4, we will apply the methodological framework, FCM-XAI, to galaxy classification based on the data provided by Galaxy Zoo. The analysis will demonstrate how the developed methodology can be used in various contexts that integrate human perception with AI. Finally, Section 5 and Section 6 will present the discussions, conclusions, and future work.
2. Related Work
In the related work review, we will follow a structured approach to explore the relevant work in this domain. First, we will examine the studies that have utilized Fuzzy C-Means (FCM) as a clustering tool, providing a broad overview of its applications across various fields. Next, we will focus on the studies that incorporate Explainable Artificial Intelligence (XAI) techniques, emphasizing the remarkable increase in the use of XAI in recent years. Following this, we will explore the integration of XAI with FCM and discuss the related works that have combined these two methodologies. Subsequently, we will analyze the use of machine learning and deep learning techniques in the context of galaxy classification, identifying trends and gaps in this field. Finally, it will be observed that the methodology combining FCM with XAI has not been previously employed in the specific context of galaxy identification, highlighting the novelty of our proposed approach.
2.1. Fuzzy C-Means and XAI
Fuzzy C-Means (FCM), introduced by Bezdek in 1981 [3], is a versatile and widely used technique that assigns data points to clusters with varying degrees of membership. Unlike traditional hard clustering methods, which rigidly allocate each data point to a single cluster, FCM allows for more flexibility by enabling each point to belong to multiple clusters, with specific membership values assigned. This approach offers a more realistic representation of data, particularly in situations where overlapping clusters and uncertainty need to be managed.
FCM has found significant application in various fields due to its capability to handle complex, uncertain data. In medical imaging, for instance, FCM is extensively used for segmenting medical images, helping to identify and delineate regions of interest such as tumors, tissues, and organs [6]. An example is its role in brain MRI segmentation, where it distinguishes between different brain tissues, such as gray matter, white matter, and cerebrospinal fluid, aiding in the diagnosis of neurological conditions [7]. In remote sensing and environmental monitoring, FCM is applied to classify land cover types using satellite imagery to segment features such as forests, water bodies, and urban areas [8]. Similarly, in image processing and pattern recognition, FCM helps improve tasks like image compression, enhancement, and feature extraction [9]. It plays a key role in face recognition systems by grouping facial features [10]. FCM is also used in market segmentation, where companies use it to identify different groups of customers based on their behavior, preferences, and demographic characteristics. This segmentation allows companies to create targeted marketing strategies, increasing customer satisfaction and engagement [11,12].
Lastly, in bioinformatics, FCM is applied to gene expression data analysis, clustering genes with similar expression patterns. This clustering contributes to understanding gene functions and interactions, further advancing genetic research and personalized medicine [13].
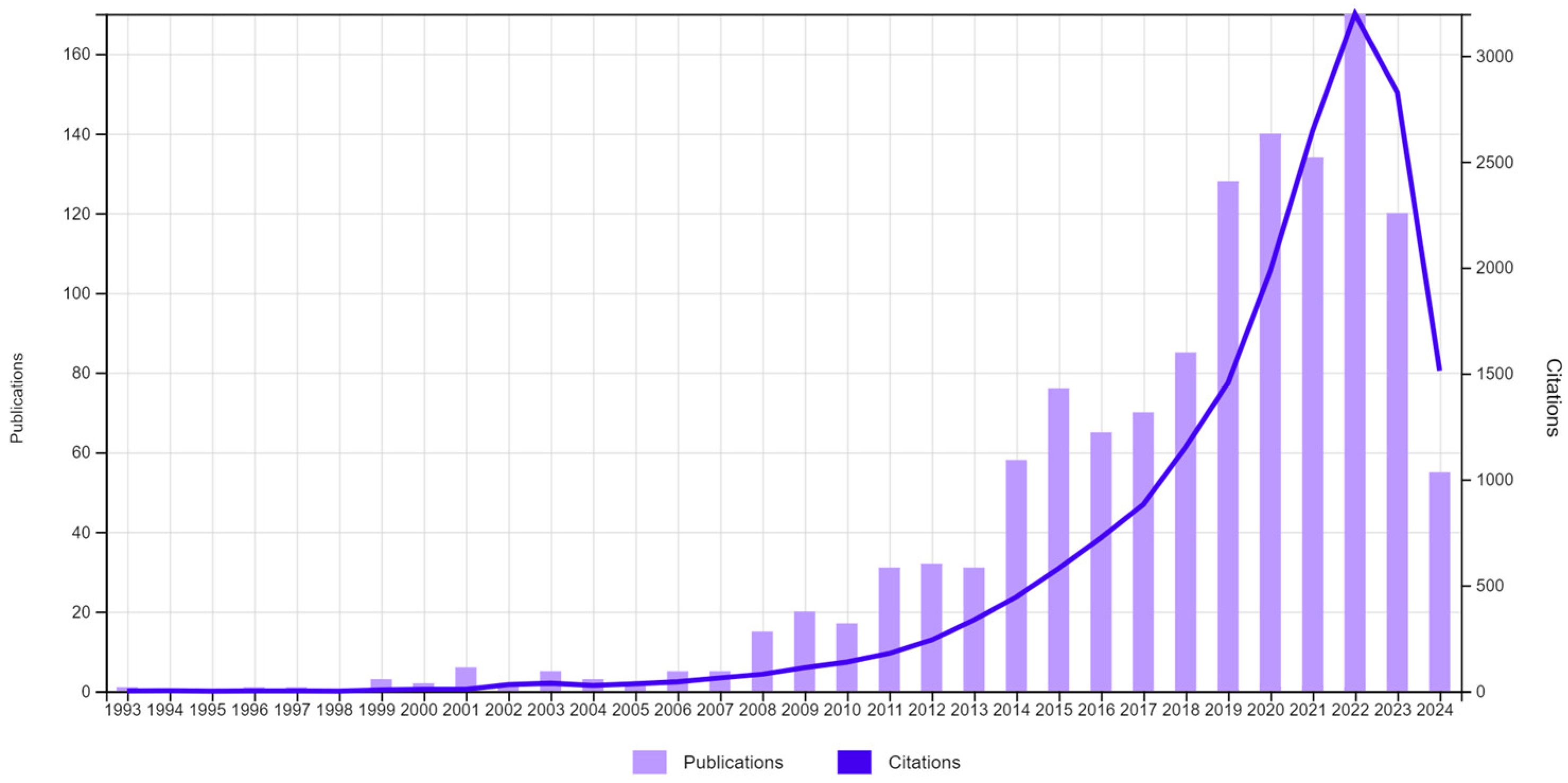
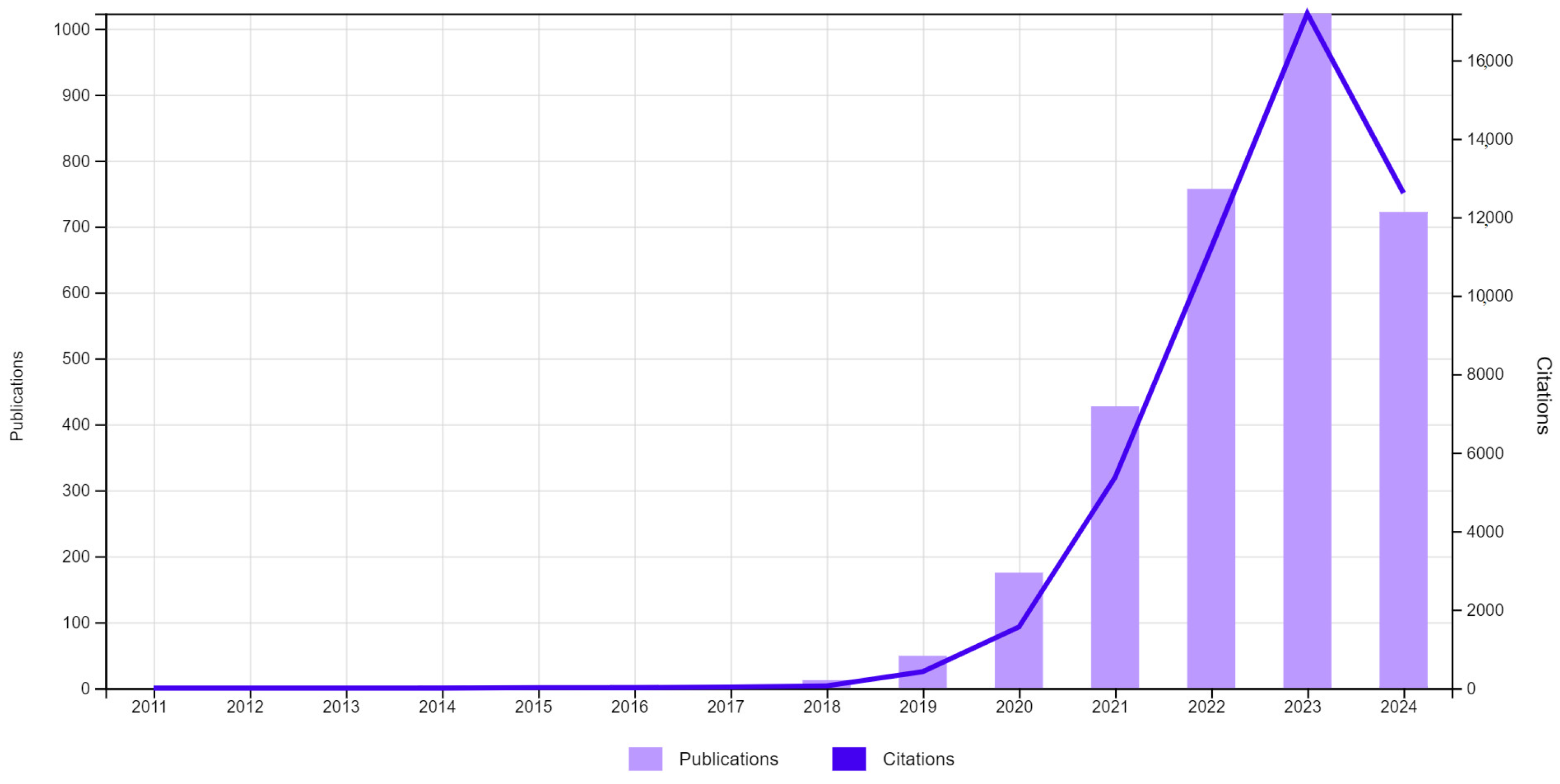
Figure 1 shows a preliminary review of research related to Fuzzy C-Means (FCM) in the Web of Science Core Collection, identifying a total of 1282 publications.
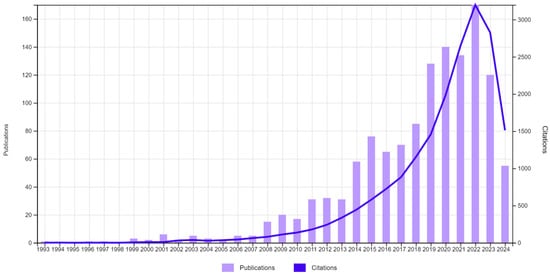
Figure 1.
Publications (1282) and citations. TS = (FUZZY C-MEANS CLUSTERING).
As data storage, management, and information processing speed continue to multiply, the successes achieved by AI in predictive models, along with occasional issues arising from the misuse of AI, such as biased data or noise, have made it imperative to approach AI projects with a focus on the interpretability and explainability of machine learning algorithms, with special emphasis on the ethical processes involved in decision-making. It is evident that research on interpretability has evolved significantly in recent years, with a notable increase in the most recent periods, as illustrated in Figure 2 and Table 1.
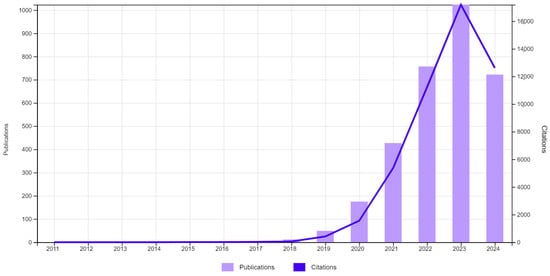
Figure 2.
Publications (3178) and citations. TS = (“XAI” OR “EXPLAINABLE ARTIFICIAL INTELLIGENCE”).

Table 1.
Publications, XAI or Explainable Artificial Intelligence.
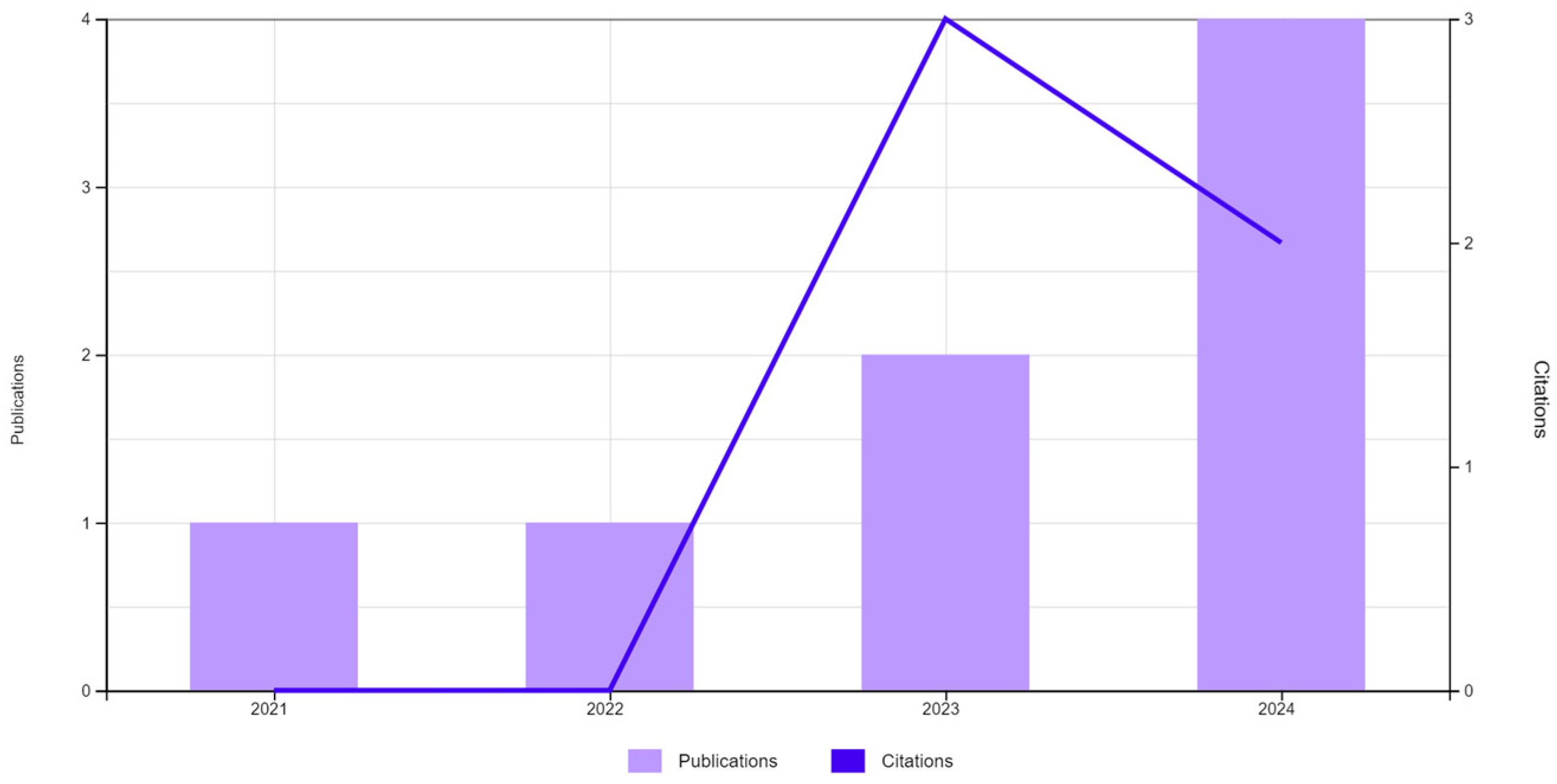
To further refine the search, we included the use of Explainable AI (XAI) techniques in conjunction with FCM. Figure 3 provides a graphical representation, followed by a detailed breakdown of the referenced publications.
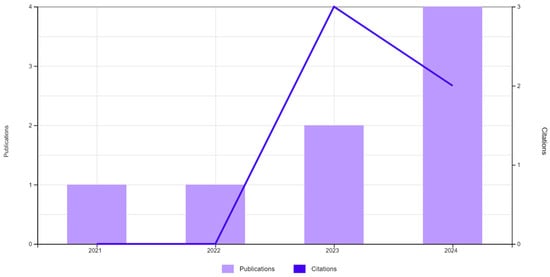
Figure 3.
Publications (8) and citations. TS = (“FUZZY C-MEANS”) AND TS = (“XAI” OR “EXPLAINABLE ARTIFICIAL INTELLIGENCE”).
In the study by V. V. Saradhi et al. [14], the techniques used are based on non-agnostic robust regression models for fuzzy models, providing a global approach to interpretability. I. Ghosh et al. [15] applied agnostic techniques based on feature importance, offering a general view of the most influential variables in the prediction. Additionally, the interpretability methods used are global rather than focused on local explanations. On the other hand, Kmita et al. [16] employ non-agnostic techniques using Semi-Supervised Fuzzy C-Means. While this approach combines labeled and unlabeled data, it lacks an explainable component that connects the model’s decisions with human-provided data. Sevas et al. [17] implement agnostic techniques using feature importance, providing a global view and explanation of the predictions. The study by Sirapangi et al. [18] uses global interpretation techniques such as Deep SHAP, offering detailed global explanations of the model. Arabikhan et al. [19] employ non-agnostic techniques based on fuzzy networks, allowing for a mathematical global interpretation of the model. In the work of Priya et al. [20], non-agnostic techniques like Long Short-Term Memory combined with polynomial kernels are used, focusing on temporal prediction. Finally, Akpan et al. [21] use artificial neural networks (ANNs) and non-agnostic techniques for classification and prediction but lack global and local explainable dimensions.
These studies predominantly employ global interpretability techniques such as feature importance, deep SHAP, and fuzzy networks, with no direct human interaction for data collection. In contrast, our study uniquely integrates human opinions through Galaxy Zoo to guide the fuzzification process, combining both global and local interpretability methods (SHAP and LIME) for a more comprehensive understanding of galaxy classifications using FCM. This human–AI hybrid approach offers a novel perspective not explored in the studies mentioned.
2.2. Galaxy Classification
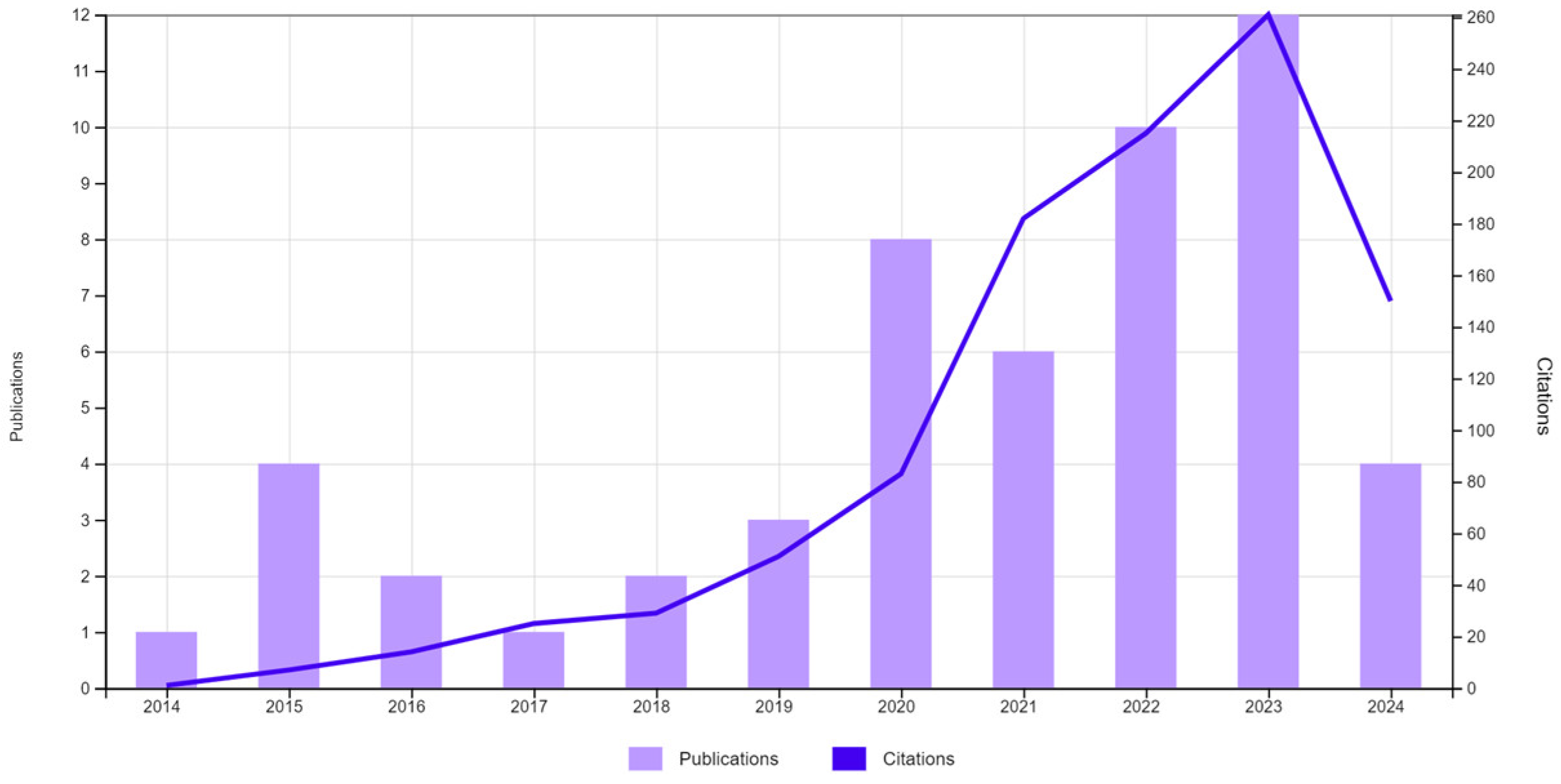
The number of studies related to galaxy classification using machine learning algorithms is depicted in Figure 4. A total of 53 studies have been conducted over the past 10 years. However, as evidenced, none of these studies incorporate algorithm interpretability.
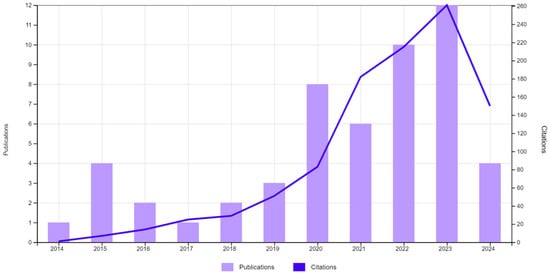
Figure 4.
Publications (53) and citations. TS = (“GALAXY CLASSIFICATION”) AND TS = (“MACHINE LEARNING” OR “DEEP LEARNING”).
Among the studies presented in Figure 4, those from the past two years have been selected, each focusing on different methods for galaxy classification. However, there are key distinctions when compared to our work.
Y. Wu et al. [22] utilize convolutional neural networks (CNNs) for galaxy spectral classification, focusing on deep learning without incorporating interpretability methods, unlike our approach, which uses Fuzzy C-Means (FCM) clustering combined with explainability techniques like SHAP and LIME. Similarly, S. Ndung’u et al. [23] address the morphological classification of radio galaxies but do not integrate explainability or human-driven data. Ma et al. [24] employ hierarchical data learning for galaxy image classification, while our study emphasizes the combination of FCM and XAI to handle uncertainty in user classifications, providing greater transparency. Stoppa et al. [25] use CNNs for galaxy classification without focusing on explainability, whereas our model adds interpretability layers to the classification process. Schneider et al. [26] apply pretraining for galaxy classification, but their approach is purely algorithmic, lacking the human–machine collaboration seen in our study. Lastly, Senel [27] explores hyperparameter optimization for galaxy classification, whereas we prioritize the integration of XAI with FCM to make the classification process understandable, highlighting the unique contributions of human observations in our methodology.
Overall, while the studies focus on improving classification accuracy, they do not address the interpretability and human-driven aspects that our work integrates.
2.3. Conclusion
The review of related work highlights the novelty and distinctiveness of the approach taken in this study. Previous research utilizing Fuzzy C-Means (FCM) clustering and Explainable AI (XAI) techniques has been applied in various fields, such as medical imaging, environmental monitoring, and financial forecasting. However, these studies typically focus on algorithmic precision and theoretical models, with little emphasis on integrating human-driven data into the clustering process. Moreover, while some research applies XAI, it is often limited to global interpretability methods, such as feature importance, without addressing the local interpretability needed for individual predictions.
In the domain of galaxy classification, most studies rely heavily on deep learning techniques, focusing on machine-based image analysis. These approaches, while accurate, lack the interpretability that XAI methods provide. They also fail to incorporate the uncertainty introduced by human classification, which is key for a dataset like Galaxy Zoo, where non-expert volunteers provide classifications based on visual assessments.
Through the integration of FCM and XAI, this work bridges the gap between human decision-making and AI, providing a transparent and ethically informed framework for galaxy classification that can be extended to other domains.
3. Methodology
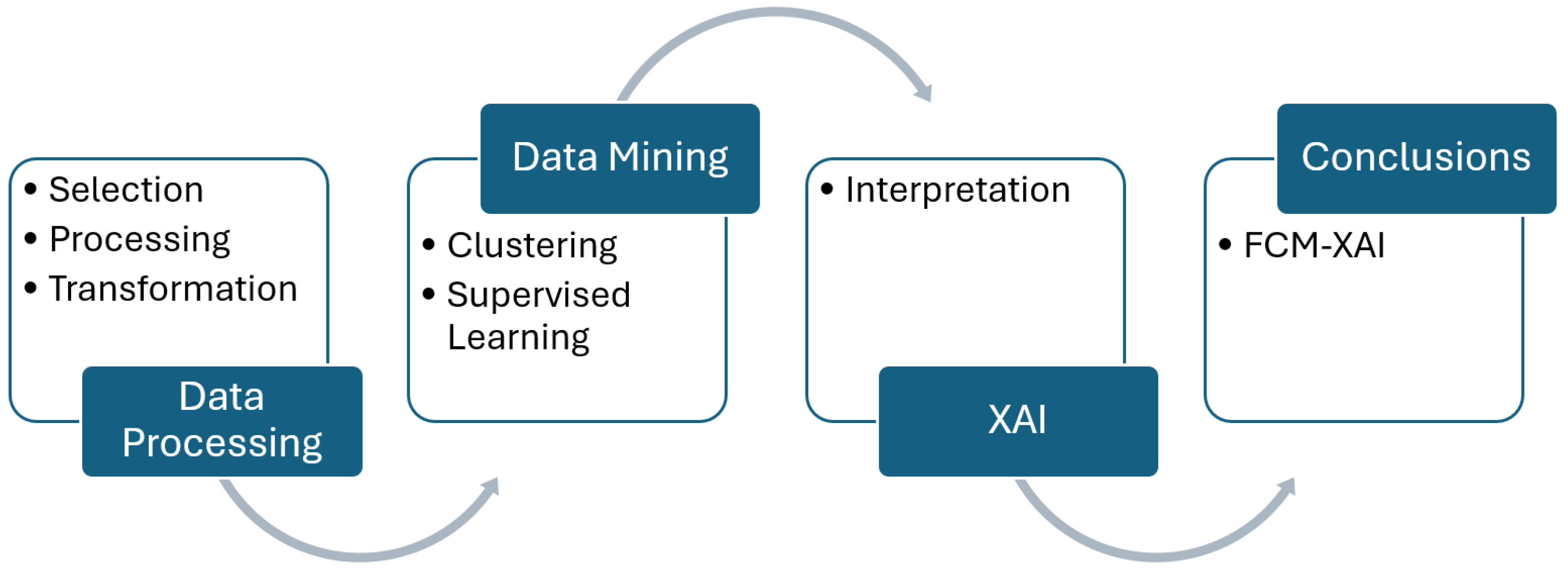
The methodology used in this study is based on the Knowledge Discovery in Databases (KDD) process [28], which is foundational for structuring data analysis and mining tasks. The KDD process involves several key stages, as depicted in Figure 5:
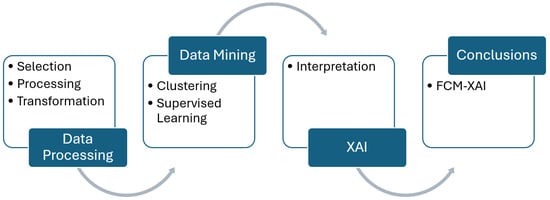
Figure 5.
Methodology.
The data collected in this study originates from the Galaxy Zoo project [1]. After selecting this data source, we proceed to develop each of the stages that constitute the model:
3.1. Data Processing
In the field of galaxy classification, the objectives should be clearly defined, including the identification of the key features that influence the classification of galaxies based on their morphological features. Once the objectives have been defined, the next step involves selecting relevant data by focusing on important features from the dataset, such as galaxy shape, the presence of spiral structures, and bulge prominence, which are likely to impact galaxy classification and align with the study’s goals. An Exploratory Data Analysis (EDA) is then conducted, which includes analyzing the distribution of galaxy shapes and structures, as well as studying the correlations between features to identify relationships and redundancies. Lastly, a standard scaler is applied to normalize the data, ensuring that each feature has a mean of 0 and a standard deviation of 1 for proper processing.
3.2. Data Mining
3.2.1. Fuzzy C-Means (FCM)
Fuzzy C-Means (FCM) is adept at handling scenarios where data points exhibit characteristics of multiple clusters [3]. This is particularly pertinent in the context of galaxy classification, where morphological features may not be distinctly categorized (Table 3). FCM allows galaxies to possess varying degrees of membership across multiple clusters, thereby offering a more nuanced classification approach.
In practical applications, including astronomical datasets, entities frequently display a blend of characteristics from distinct categories. FCM’s capability to manage overlapping memberships makes it an appropriate choice for such intricate datasets.
The objective of FCM clustering is to group galaxies into clusters based on their morphological characteristics. This method allows for overlapping clusters, meaning each galaxy can belong to multiple clusters with varying degrees of membership.
- 1.
- Initialization:
To begin the clustering process, the number of clusters () must first be set, representing the desired number of groups into which the data will be partitioned. The next step involves initializing the cluster centers (), where initial cluster centers are randomly selected as starting points for the algorithm to iterate upon.
- 2.
- Membership Calculation:
Degree of Membership of each galaxy to each cluster is calculated using the distance between and . The membership degree is calculated as follows:
In the given context, where is the membership degree of galaxy in cluster , and is the distance between galaxy and cluster center , typically, the Euclidean distance is as follows:
is the fuzziness parameter (typically ), which determines the level of cluster fuzziness.
- 3.
- Cluster Center Update:
Update the cluster centers based on the weighted average of the galaxies’ features, with weights given by their membership degrees:
In the given context, where is the updated cluster center, and is the membership degree raised to the power of .
- 4.
- Iteration:
Continue iterating between membership calculation and cluster center update until convergence is achieved. Convergence is typically defined as the point where the changes in membership degrees and cluster centers are below a predefined threshold. Mathematically, this can be represented as follows:
where is a small positive constant representing the convergence threshold, and are the cluster centers at iterations and , respectively, and , are the membership degrees at iterations and , respectively.
FCM clustering allows galaxies to be grouped based on their morphological characteristics. It allows for overlapping clusters, providing a more flexible and nuanced clustering approach compared to traditional hard clustering methods. By iterating through membership calculations and cluster center updates, FCM can accurately reflect the inherent uncertainty and variability in galaxy data.
3.2.2. Random Forest (RF) for Predictive Modeling
Random Forest (RF) is an ensemble learning method known for its high accuracy and robustness in classification tasks [29]. It operates by building multiple decision trees during training and providing the most frequent class as the output for classification. This method reduces overfitting and improves the generalizability of the model.
RF can effectively manage datasets with many features, which are common in astronomical data. Its ability to manage a diverse set of input features without requiring extensive preprocessing makes it an ideal choice for our problem.
One of the key advantages of RF is its ability to measure the importance of each feature in making predictions. This factor is key for understanding which morphological characteristics of galaxies are most influential in determining their cluster memberships.
RF determines the intrinsic cluster membership of a galaxy based on its features. While FCM assigns degrees of membership across multiple clusters, RF provides a definitive prediction of the most likely cluster for a new galaxy, using its morphological characteristics.
Let be the feature matrix and be the response vector. The steps are as follows:
- Bootstrapping and Bagging: Bootstrapping is a statistical technique in which multiple datasets are generated by sampling with replacement from the original dataset. This method forms the basis for Bagging (Bootstrap Aggregating), where each decision tree is trained on a different bootstrapped dataset. Specifically, bootstrapped datasets, denoted as , are created from the original dataset . This approach enhances the stability and accuracy of machine learning models by reducing variance and improving generalization.
- Tree Construction: At each node, a random subset of features is chosen, and the best possible split is determined from within this subset. The tree continues to grow until a specified stopping condition is reached, such as a maximum depth or a minimum number of samples per leaf. For each bootstrapped dataset , a decision tree is constructed by selecting the best split from a random subset of features at every node.
- Voting and Prediction: For classification tasks, each tree in the forest casts a vote for the predicted class. The final prediction is the class with the majority vote across all trees. For regression tasks, the overall prediction is derived by averaging the predictions from each tree. Given a new input , the Random Forest prediction is calculated as follows:
The use of RF to predict galaxy cluster membership is justified by its robustness, accuracy, and ability to manage high-dimensional data. Its non-linear nature and feature importance measures further enhance its suitability for this task. The inherent non-interpretability of RF paves the way for the application of XAI techniques, ensuring that we can obtain deterministic information about the model’s decision-making process and build confidence in its predictions.
3.3. Interpretable Machine Learning
Explainability techniques are necessary because Random Forest, although robust and accurate, is considered a “black-box” model. This means that, although it can make accurate predictions, the internal decision-making process is not inherently transparent or interpretable. Therefore, Explainable AI (XAI) techniques are used to understand and trust the model’s predictions [30].
- Inherently Interpretable Models [31] are designed to be simple and transparent, making their decision-making process easy to understand. Examples include linear regression, decision trees, and logistic regression. These models are often used when interpretability is crucial, such as in regulatory environments or when stakeholder trust is paramount.
- Black-box Models [32] are complex, and their internal workings are not easily interpretable. Examples include Random Forest, neural networks, and support vector machines. These models are often favored for their high predictive power, especially when handling large and complex datasets.
- Model-agnostic Explainability [33] techniques can be applied to any machine learning model, regardless of its internal complexity. Examples include SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), which work by approximating or analyzing the model’s output rather than its internal structure.
- Model-dependent Explainability [34] techniques are specific to certain types of models and leverage their internal structure to provide explanations. Examples include decision tree feature importances and neural network saliency maps. These methods are often more efficient but less generalizable than model-agnostic approaches.
3.3.1. SHAP (Shapley Additive exPlanations)
Derived from cooperative game theory, SHAP values offer a standardized measure of feature importance [35]. They explain the contribution of each feature to the prediction for each individual data point.
Calculating the Shapley value for a feature involves taking the average of its marginal contributions over all possible feature combinations.
Mathematically, it is given by the following:
where is the set of all features, is a subset of features excluding , and is the prediction from the model using the feature subset .
SHAP values help in understanding the overall importance of each morphological feature in determining galaxy cluster memberships. This provides insights into the key factors that drive the clustering process.
3.3.2. LIME (Local Interpretable Model-Agnostic Explanations)
LIME provides local explanations by approximating the model’s behavior in the vicinity of a particular instance with a simple interpretable model [36].
For a given instance , LIME perturbs to generate a set of new instances and obtains predictions from the original model.
Weights are assigned to these instances based on their proximity to :
A simple linear model is then fit to the weighted instances to approximate the complex model’s behavior locally:
where is the binary vector representing the presence or absence of features in .
LIME can be used to explain why a particular instance belongs to a certain cluster by showing the contribution of each feature to the prediction. This is achieved by analyzing the weights and coefficients of the locally fitted linear model.
LIME allows for explaining individual predictions, showing why a particular galaxy is assigned to a specific cluster. This helps validate the model’s decisions on a case-by-case basis.
3.4. FCM–XAI
The integration of Fuzzy C-Means for clustering and Random Forest for predictive modeling, complemented by SHAP and LIME for interpretability, establishes a comprehensive and robust framework for galaxy classification. This approach harnesses the strengths of both FCM and RF, ensuring that model predictions are transparent and interpretable, thus enhancing confidence and reliability in the classification results.
Moreover, the employed methodology is adaptable to various environments where information from multiple sources is processed. By making classification decisions understandable and explainable, this approach increases the robustness and trustworthiness of the outcomes.
4. FCM-XAI Methodology for Galaxy Classification
4.1. Data Collection, Processing, and Transformation
The methodology presented in this study aids in the development of classification models based on specific characteristics. For our research, the Galaxy Zoo data model was employed. The characteristics detailed in this model are summarized in Table 2.
Table 2.
Features of the Galaxy Zoo dataset.
The selection of the following features from the Galaxy Zoo model was guided by their relevance to galaxy classification based on morphological properties [37]. These features capture essential aspects of a galaxy’s shape, structure, and specific characteristics that are determinant for accurate and interpretable classification (Table 3).
Table 3.
Selected features of Galaxy Zoo dataset.
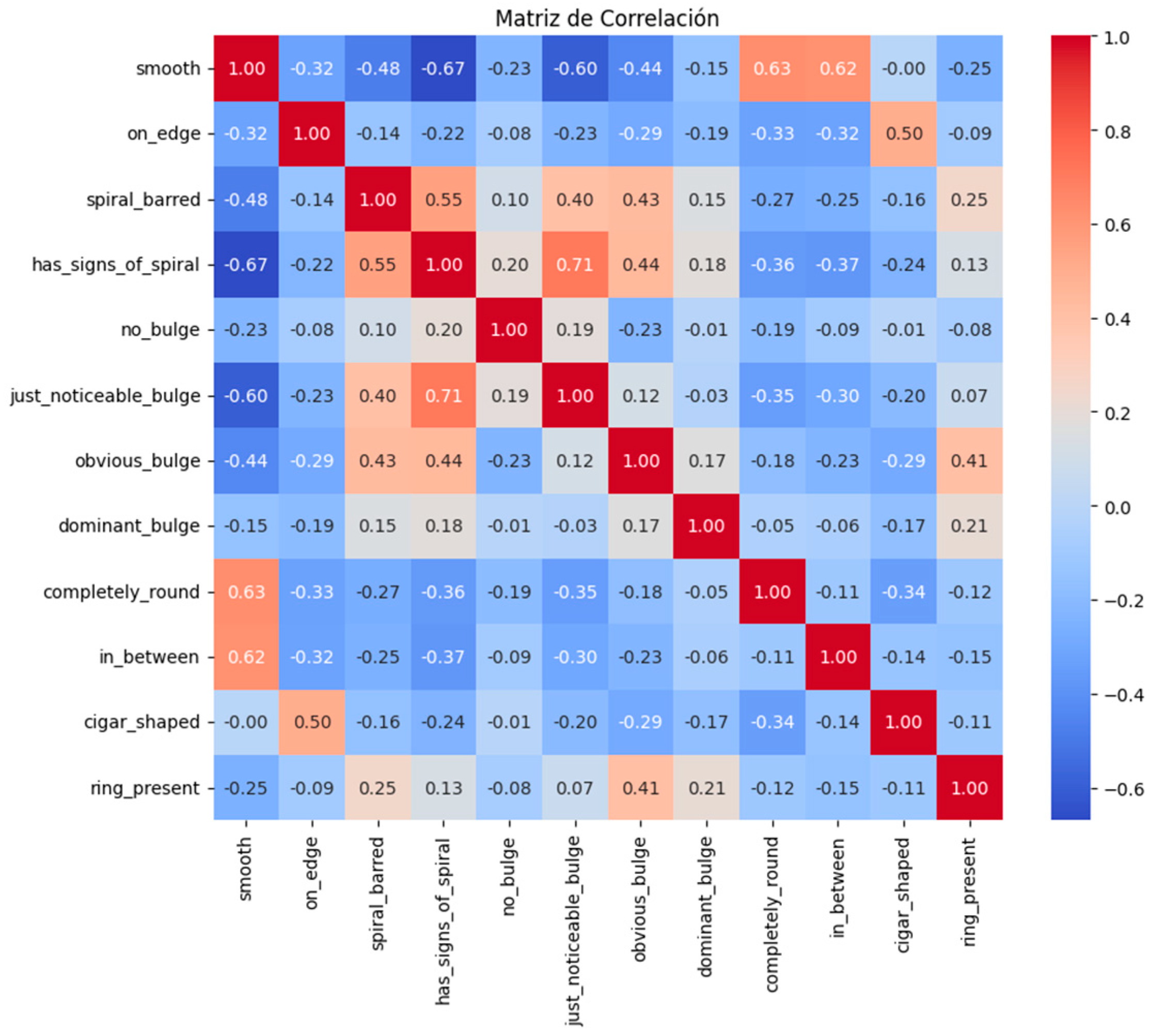
The first step in the process involves conducting an Exploratory Data Analysis (EDA). After selecting the features that will determine the cluster types, a correlation matrix is constructed, as shown in Figure 6.
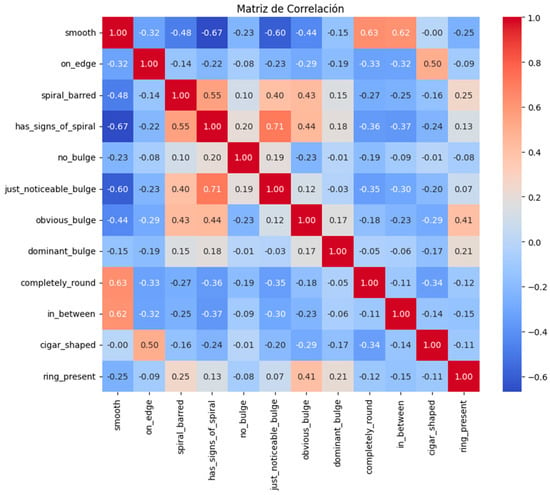
Figure 6.
Correlation matrix.
The conclusions that can be drawn from this correlation matrix are as follows:
- Smooth Galaxies: There is a strong negative correlation between “smooth” and “has_signs_of_spiral” (−0.67) as well as “spiral_barred” (−0.48). This indicates that galaxies classified as smooth are less likely to exhibit spiral characteristics. Additionally, a positive correlation is observed between “smooth” and “completely_round” (0.63), suggesting that smooth galaxies tend to have a round shape.
- Edge-On Galaxies: “On_edge” has a moderate positive correlation with “cigar_shaped” (0.50), indicating that edge-on galaxies are often cigar-shaped. Furthermore, there is a negative correlation between “on_edge” and “completely_round” (−0.33), suggesting that edge-on galaxies are less likely to be completely round.
- Spiral Barred Galaxies: “Spiral_barred” is strongly positively correlated with “has_signs_of_spiral” (0.55), indicating that barred spiral galaxies often show signs of spiral arms. Additionally, the negative correlation with “smooth” (−0.48) suggests that barred spirals are less likely to be smooth.
- Bulge Prominence: A progression of positive correlations is observed from “no_bulge” to “dominant_bulge,” through “just_noticeable_bulge” and “obvious_bulge.” This indicates a spectrum of bulge prominence, ranging from none to dominant.
- Roundness: “Completely_round” has a strong positive correlation with “smooth” (0.63), supporting the observation that round galaxies are often smooth. Negative correlations with “on_edge” (−0.33) and “cigar_shaped” (−0.34) indicate that round galaxies are less likely to be viewed edge-on or to have a cigar shape.
- Presence of a Ring: “Ring_present” shows a moderate positive correlation with “obvious_bulge” (0.41), suggesting that galaxies with rings often have an obvious bulge. Negative correlations with “smooth” (−0.25) and “on_edge” (−0.09) suggest that ringed galaxies are less likely to be smooth or edge-on.
Once the conclusions are drawn from the Exploratory Data Analysis (EDA), the next step involves scaling the features. This is accomplished using the ‘StandardScaler‘ function from Python. This process involves standardizing the features by removing the mean and scaling to unit variance, which ensures that all features contribute equally to the analysis and are on the same scale.
4.2. Galaxy Classification
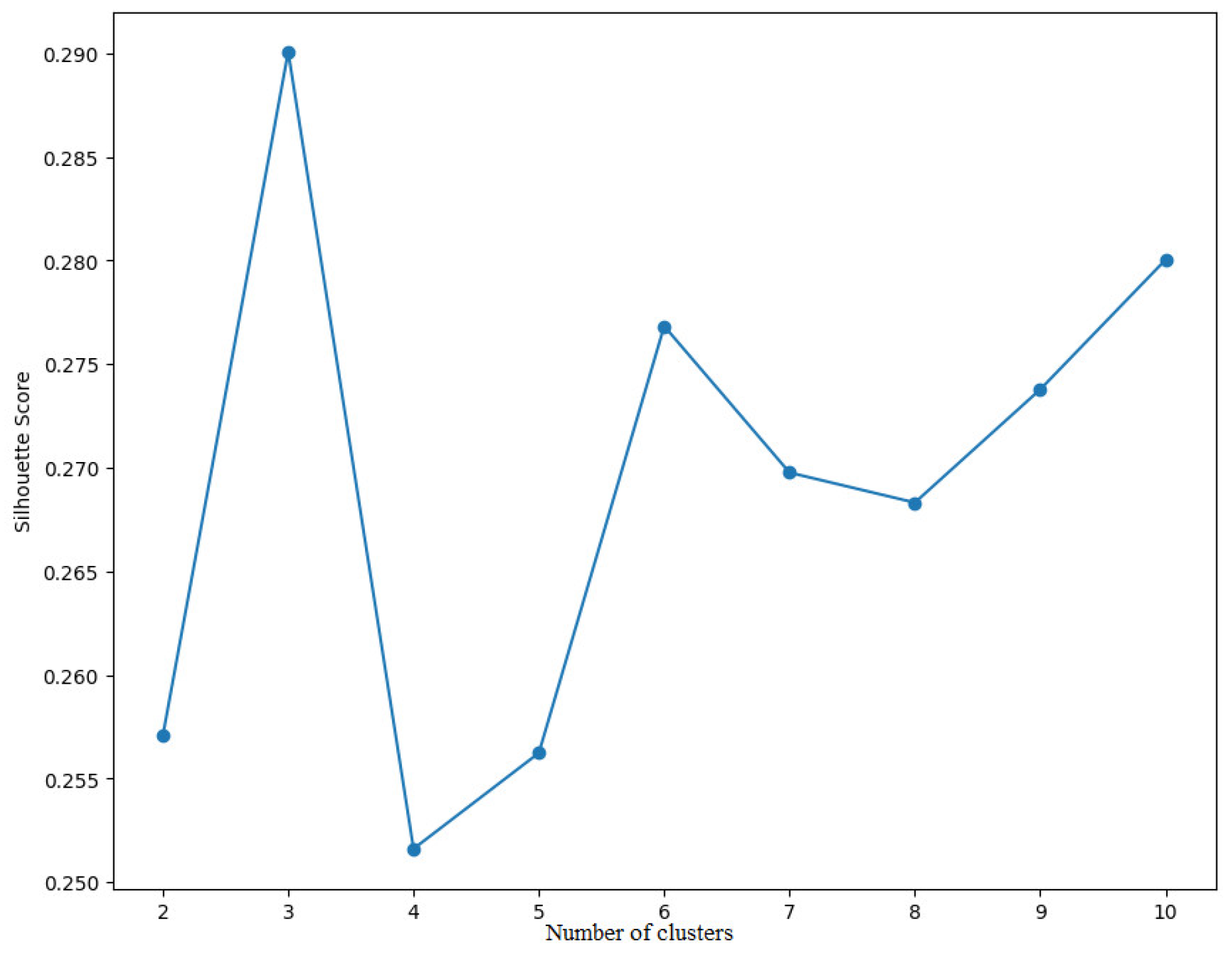
Before proceeding with the classification of galaxies, the optimal number of clusters must be determined. This step ensures that the clustering algorithm accurately captures the underlying structure of the data. An effective method to achieve this is to use the Silhouette Index.
The Silhouette Index is a widely used metric for assessing the quality of clustering results. It measures how similar an object is to its own cluster (cohesion) compared to other clusters (separation). The silhouette value ranges between −1 and 1, where values close to +1 suggest that the object is well matched to its own cluster, a value of 0 indicates that the object is near the boundary between clusters, and values near −1 suggest that the object may be misclassified and better suited to a different cluster.
A range of possible cluster numbers is defined, usually starting from 2 up to a maximum value, which can be 10 or higher depending on the size and complexity of the dataset.
The optimal number of clusters identified is 3, as shown in Figure 7. This number maximizes the average silhouette score across all points in the dataset.
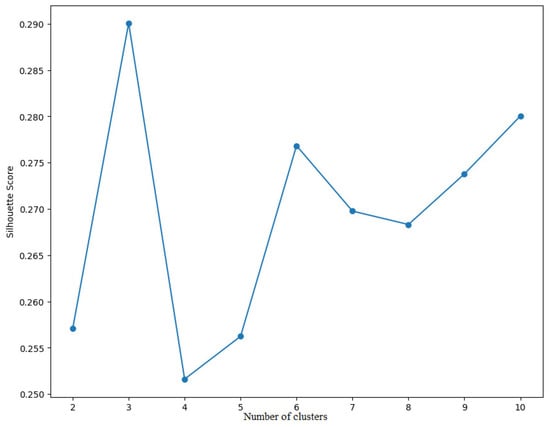
Figure 7.
Optimal number of clusters.
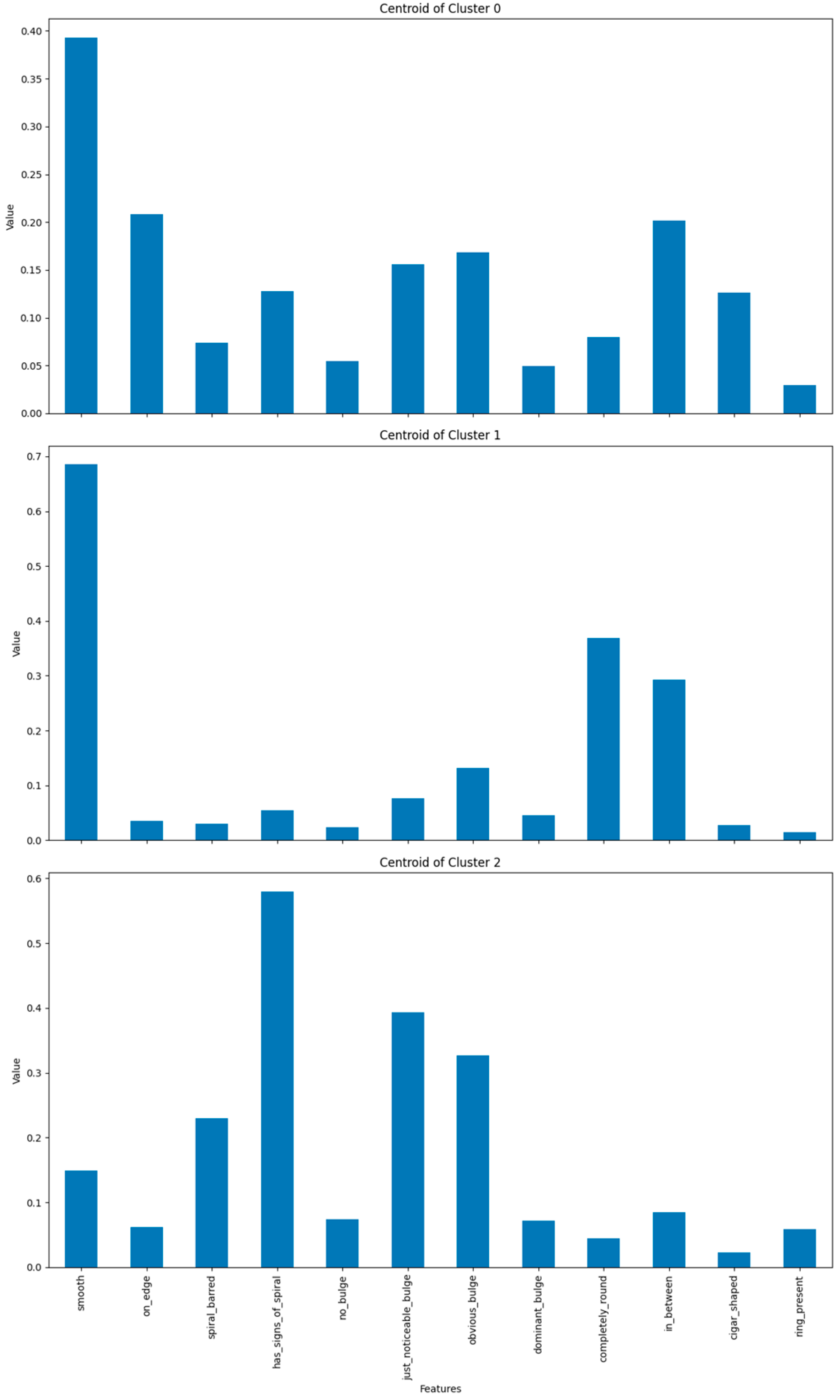
The next step involves visualizing the centroids of these clusters to understand the distinguishing features of each cluster (Figure 8).
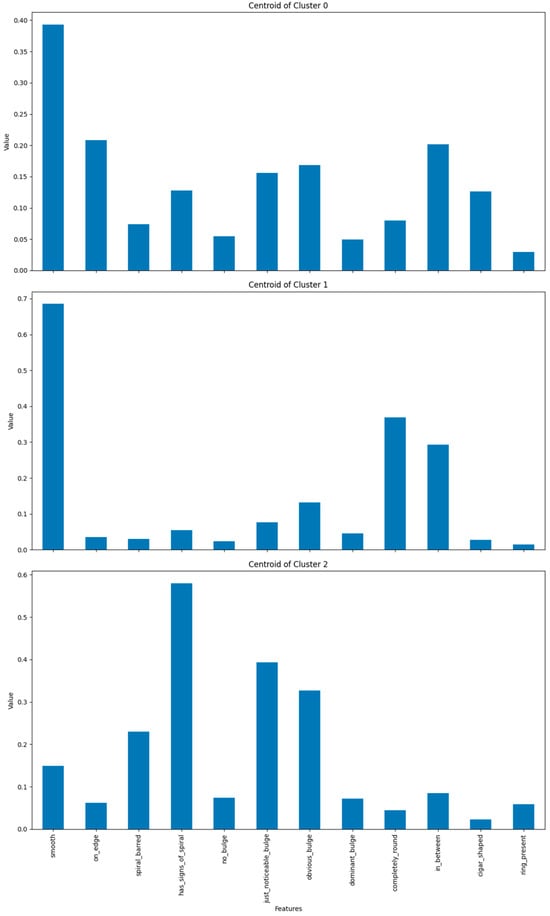
Figure 8.
Centroids by cluster.
Based on the resulting centroids, the main characteristics of each cluster can be interpreted. The centroids show the average values of the features for each cluster, allowing for a better understanding of the distinctive characteristics of each group of galaxies.
Cluster 0 is characterized by galaxies that are mostly smooth, with a smooth value of 0.393019. A considerable proportion of galaxies appear edge-on, indicated by an on_edge value of 0.208261. Some galaxies in this cluster have a spiral bar (spiral_barred: 0.074008), and others show signs of spirals (has_signs_of_spiral: 0.128044). Additionally, some galaxies have a just noticeable bulge (just_noticeable_bulge: 0.155726) or an obvious bulge (obvious_bulge: 0.168610). The cluster also contains galaxies with a shape that is intermediate between completely round and cigar-shaped (in_between: 0.201720). Overall, Cluster 0 groups galaxies that are primarily smooth, with a mix of spiral and bulge characteristics.
Cluster 1 is composed mainly of galaxies that are predominantly smooth, with a smooth value of 0.685219. Many galaxies in this cluster are completely round (completely_round: 0.368346), while a significant fraction has an intermediate shape (in_between: 0.292676). Some galaxies have obvious bulges (obvious_bulge: 0.131435), and others have just noticeable bulges (just_noticeable_bulge: 0.076257). Overall, Cluster 1 groups galaxies that are mostly smooth, either completely round or with intermediate shapes, with relatively few complex internal structures, although some have bulges that are either obvious or just noticeable.
Cluster 2 consists of galaxies that frequently exhibit signs of spirals, with a has_signs_of_spiral value of 0.579736. Many galaxies in this cluster have a just noticeable bulge (just_noticeable_bulge: 0.393652), while others have obvious bulges (obvious_bulge: 0.326246). A significant fraction of the galaxies have a spiral bar (spiral_barred: 0.230096), and some galaxies are smooth (smooth: 0.149425). Overall, Cluster 2 groups galaxies that typically display spiral features and bulges, with some galaxies also being smooth.
Figure 9, Figure 10 and Figure 11 display a sample of galaxy images from the Galaxy Zoo dataset, displaying the cluster memberships as determined by the Fuzzy C-Means clustering algorithm. Each image is annotated with the GalaxyID and the degrees of membership to three different clusters (Cluster 0, Cluster 1, and Cluster 2).

Figure 9.
Cluster 0 galaxies.

Figure 10.
Cluster 1 galaxies.

Figure 11.
Cluster 2 galaxies.
4.3. Prediction Model Random Forest (RF)
After classifying galaxies based on the previously discussed criteria, the next step involves creating a predictive model to assess the accuracy of our classification and predict the cluster membership for new galaxies. For this purpose, the RF algorithm has been chosen due to its robustness and efficiency in handling complex, non-linear relationships between features.
RF is an ensemble learning method that constructs multiple decision trees during training and outputs the mode of the classes for classification tasks. This approach helps improve the model’s accuracy and controls overfitting.
In the data preparation stage, the dataset with labeled clusters from the Fuzzy C-Means clustering is split into training and testing sets. During model training, the Random Forest model is trained on the training set, learning the patterns and relationships between the features (such as smoothness, edge-on probability, presence of spiral structures, etc.) and the cluster labels. Finally, in the model testing phase, the trained model is tested on the testing set to evaluate its predictive performance.
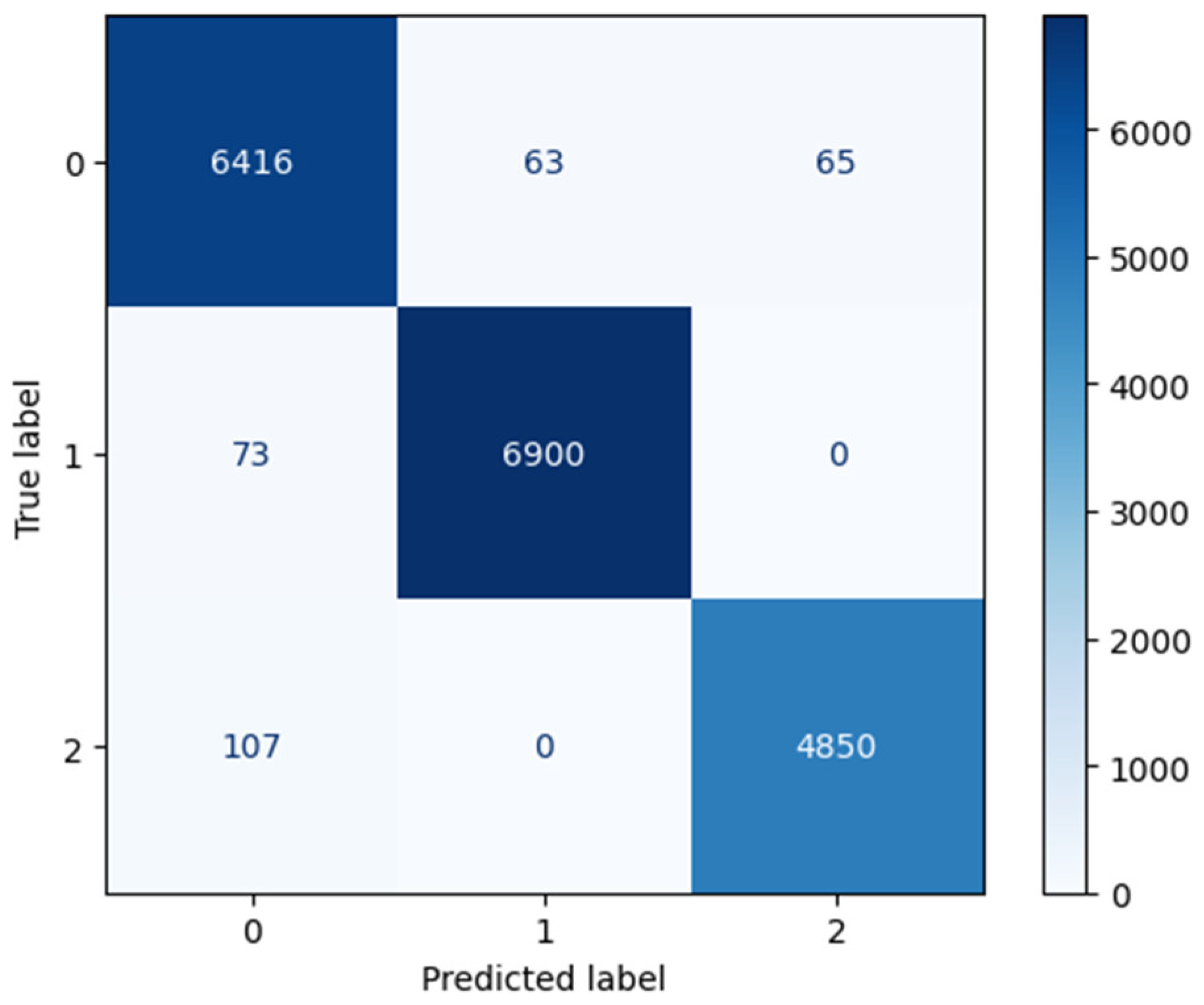
To evaluate the model’s performance, a confusion matrix is generated (Figure 12). This matrix provides a detailed breakdown of the model’s predictions compared to the actual cluster labels, showing the number of true positives, true negatives, false positives, and false negatives for each cluster.
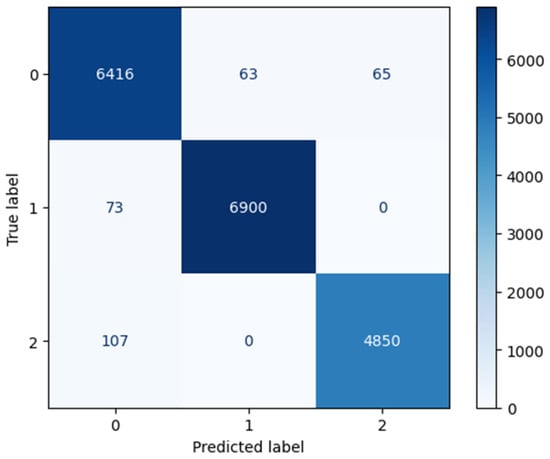
Figure 12.
Confusion matrix.
The Random Forest model can be used to predict the cluster membership of new galaxies based on their morphological characteristics. When a new galaxy is detected, its features are input into the model, which then predicts the probability of the galaxy belonging to each cluster. The cluster with the highest probability is assigned to the new galaxy.
To calculate the precision of the Random Forest model, the following equation is used:
From the confusion matrix, the precision for each cluster can be calculated as follows:
Cluster 0: (true positive: 6416; false positive: 73 + 107)
Cluster 1: (true positive: 6900; false positive: 63 + 0)
Cluster 2: (true positive: 4850; false positive: 65 + 0)
The model demonstrates high precision across all clusters, with Cluster 1 showing the highest precision at 99.1%, followed by Cluster 2 at 98.7%, and Cluster 0 at 97.3%. This indicates that the model is highly effective at correctly classifying galaxies into their respective clusters with minimal false positives.
Each cluster represents a group of galaxies with similar characteristics. Based on the cluster membership, specific actions can be taken:
- Cluster 0 (Predominantly Smooth Galaxies): For galaxies predicted to belong to this cluster, further investigation into their formation and evolution can be conducted. These galaxies may be less likely to exhibit complex structures, making them ideal candidates for studying early galaxy formation.
- Cluster 1 (Round and Intermediate Shapes): Galaxies in this cluster often have round or intermediate shapes. Research can focus on understanding the factors contributing to their shape and how they evolve over time. This cluster may also include galaxies in various evolutionary stages.
- Cluster 2 (Spiral and Bulge Structures): This cluster includes galaxies with prominent spiral features and noticeable bulges. These galaxies can be studied to understand spiral arm formation, star formation rates, and the dynamics of bulge development.
4.4. Interpretable Machine Learning
To ensure the transparency and interpretability of our predictive model, we incorporated explainability techniques into the RF algorithm used for predicting the cluster membership of new galaxies. While RFs are algorithms that excel in accuracy and the ability to manage complex, non-linear relationships between features, they are often considered “black-box” models due to their lack of inherent interpretability.
By employing Explainable AI (XAI) methods such as SHAP, we can gain insights into the decision-making process of the Random Forest model. SHAP values provide a global understanding of feature importance by assigning each feature an importance score based on its contribution to the model’s predictions. This allows us to interpret the influence of individual features on the classification of galaxies into specific clusters.
LIME, on the other hand, offers a local perspective by creating interpretable models around individual predictions. This enables us to understand the reasons behind a particular galaxy’s assignment to a specific cluster, providing a clearer and more actionable explanation for each decision made by the model.
The integration of these XAI techniques with the RF model ensures that the decisions made by the model are accurate and understandable, thereby increasing the confidence in the results obtained from the classification of new galaxies based on their morphological characteristics.
4.4.1. SHAP
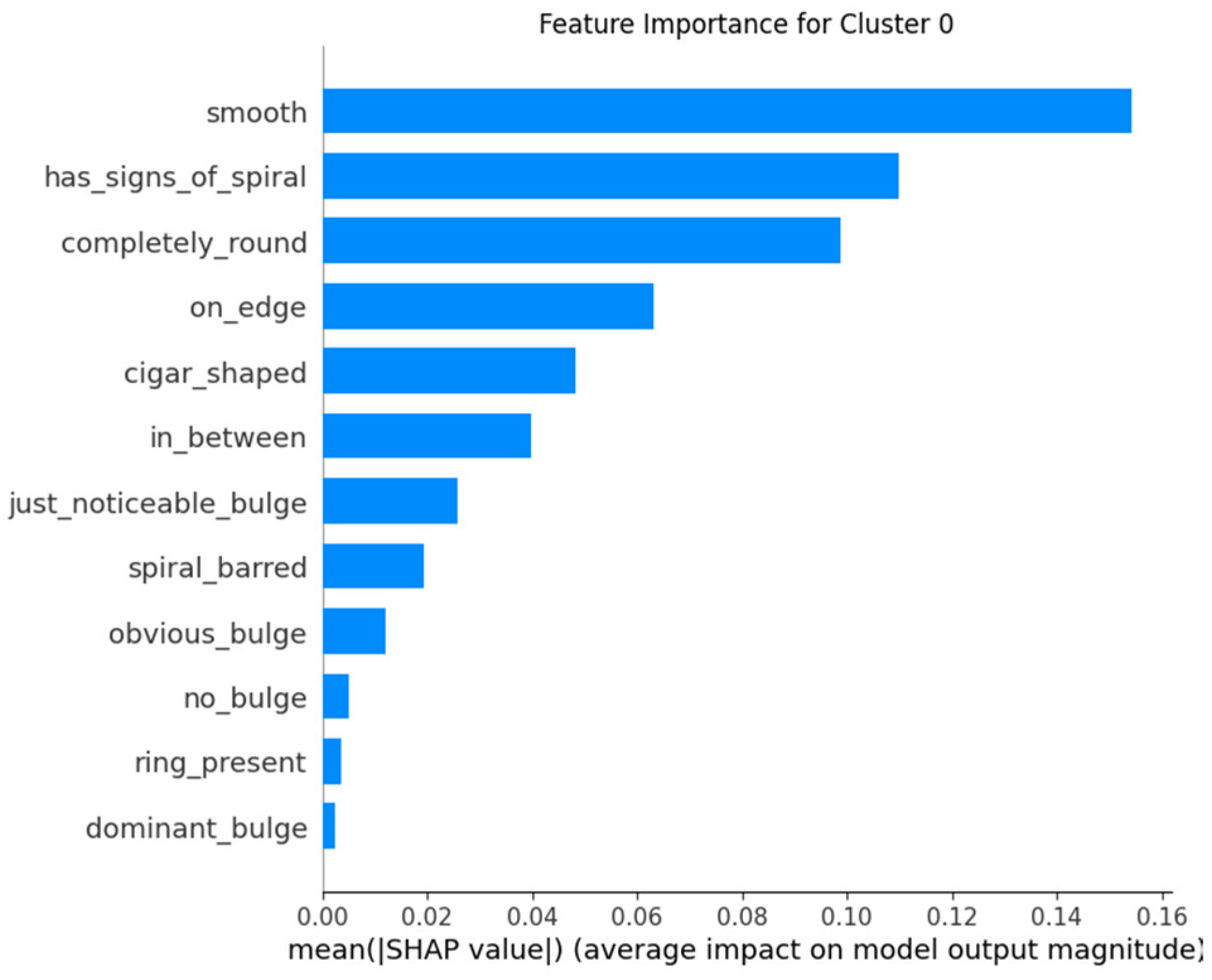
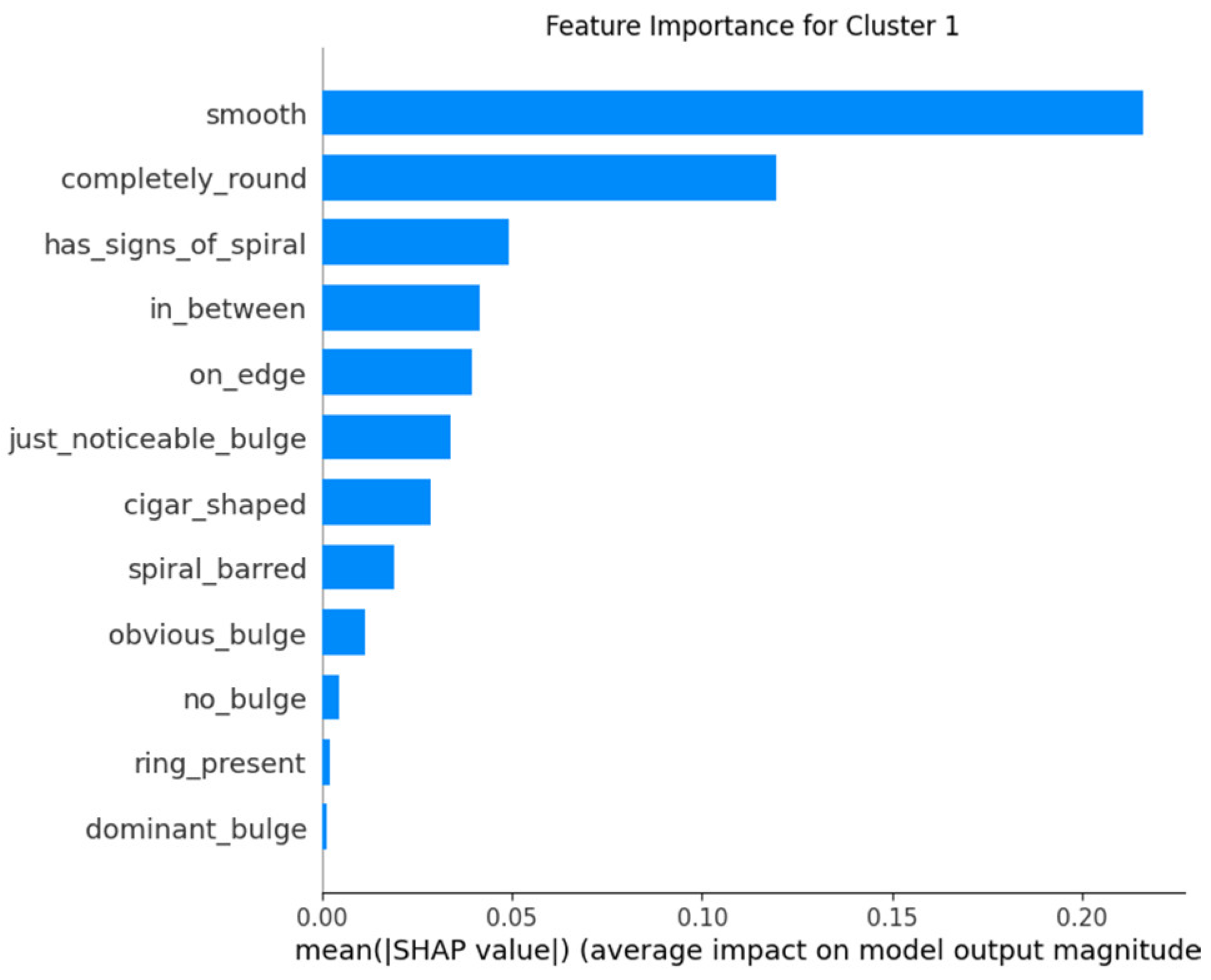
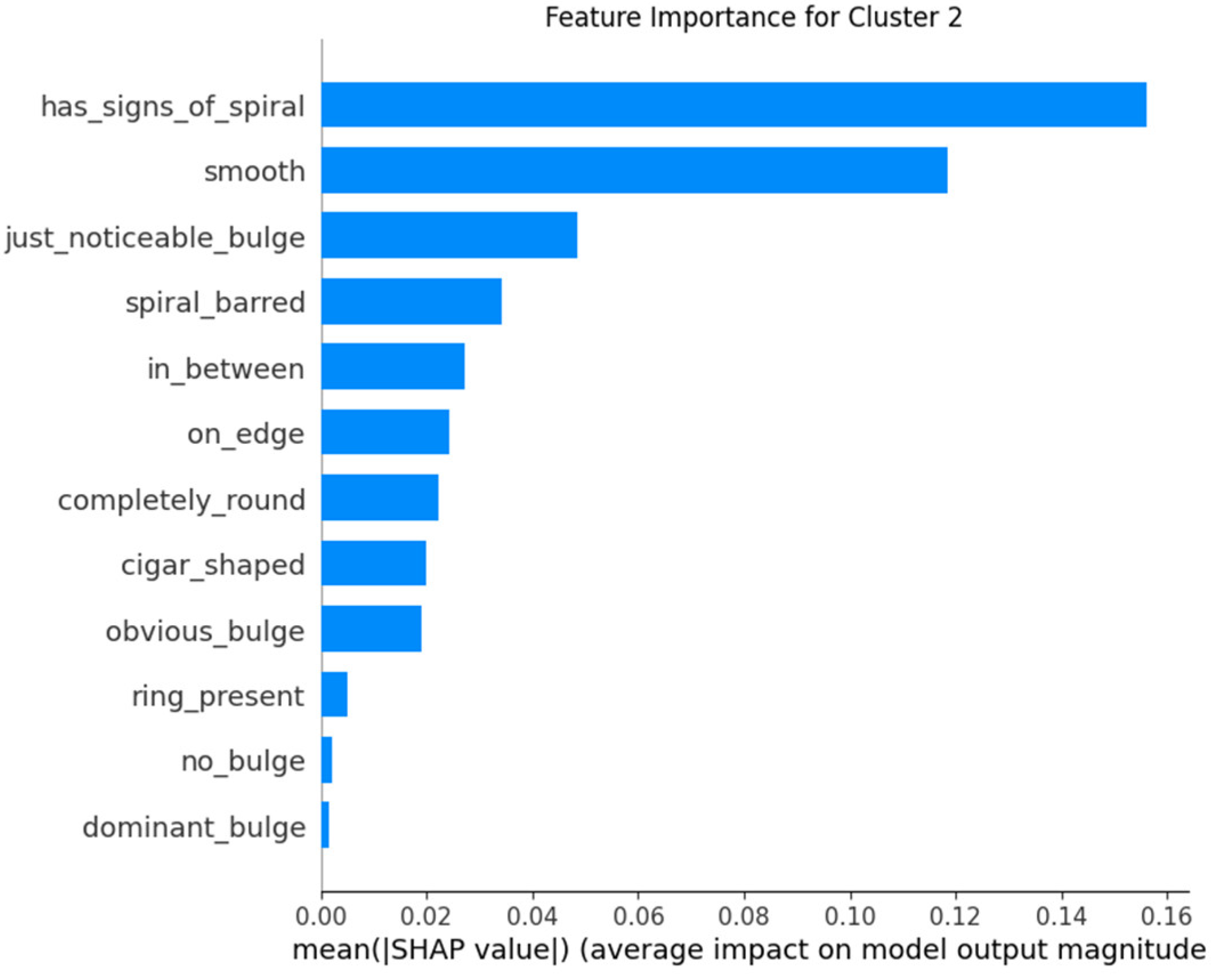
The application of SHAP allows for an understanding of which features are most influential in the model’s predictions for each cluster. By analyzing feature importance with SHAP, one can validate that the model behaves consistently with prior knowledge about galaxy classification and detect if the model uses irrelevant or biased features for predictions. Providing explanations about how the model arrives at its predictions increases trust in the system, especially for end-users who may not have deep technical expertise. Furthermore, the SHAP technique helps identify which features might be missing or misinterpreted by the model, allowing for adjustments and improvements in the model’s design (Figure 13, Figure 14 and Figure 15).
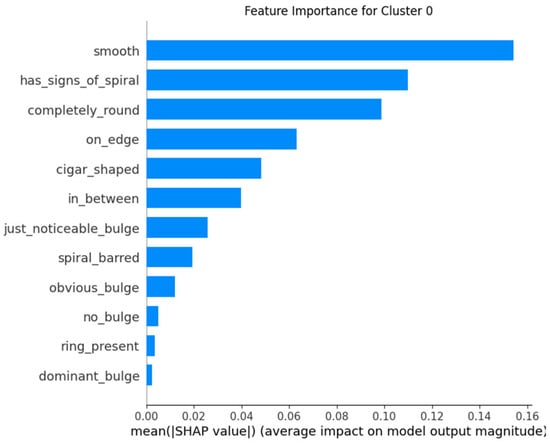
Figure 13.
Feature importance for Cluster 0.
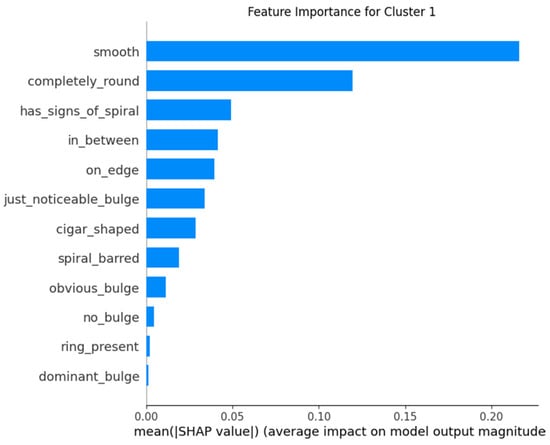
Figure 14.
Feature importance for Cluster 1.
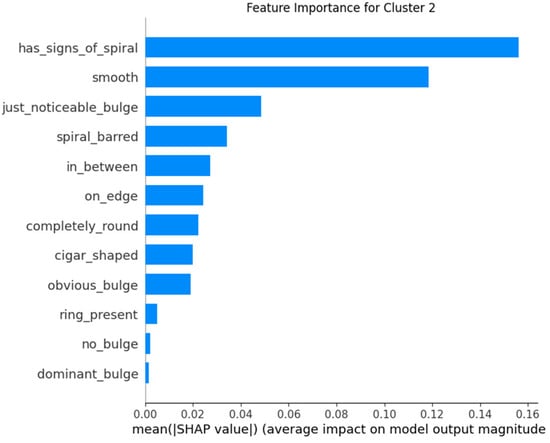
Figure 15.
Feature importance for Cluster 2.
It is important to compare the feature importance derived from SHAP with the central features of each cluster obtained previously. This allows us to validate that the Random Forest model aligns with the definitions of the clusters established by Fuzzy C-Means.
- In Cluster 0, it is observed that the smooth feature is the most influential, aligning with the prior interpretation that galaxies in this cluster are predominantly smooth.
- In Cluster 1, the “completely_round” feature stands out, consistent with the interpretation that many galaxies in this group are completely round.
- In Cluster 2, the “has_signs_of_spiral” feature emerges as the most significant, corresponding with the interpretation that galaxies in this cluster frequently display spiral signs.
This correspondence between feature importance and cluster definitions reinforces the validity of the model and provides a deeper understanding of the factors driving the model’s decisions.
4.4.2. LIME
LIME operates by creating locally accurate explanations. It takes a specific data point and constructs a dataset of similar but slightly altered instances, then produces a simpler, interpretable surrogate model (such as linear regression) to elucidate the complex model’s predictions near the selected data point. This method is particularly useful for comprehending the factors affecting specific predictions, especially when the original model is a “black box” like Random Forest [5].
The LIME result shown in Figure 16 provides an explanation for the classification of a galaxy (Galaxy ID = 553402) into Cluster 2 with a 100% probability.
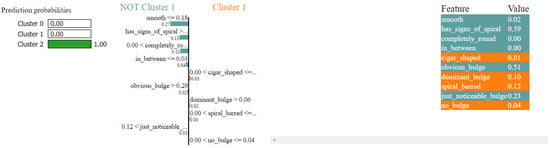
Figure 16.
Local cluster prediction (cluster = 2).
The galaxy is classified into Cluster 2 with high certainty due to its morphological characteristics. The noteworthy features influencing this decision include a low “smooth” value, a high “has_signs_of_spiral” value, and the absence of a “completely_round” shape. Specific characteristics, such as low values of “cigar_shaped” and moderate “obvious_bulge”, “dominant_bulge”, and “just_noticeable_bulge”, also contribute to this classification.
The image corresponding to Galaxy ID = 553402 is shown in Figure 17.

Figure 17.
Galaxy ID 553402, Cluster 2.
The LIME result shown in Figure 18 provides an explanation for the classification of a galaxy (Galaxy ID = 236126) with a 68% probability for Cluster 0, 0% for Cluster 1, and 32% for Cluster 2.
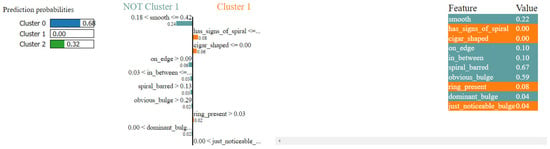
Figure 18.
Local cluster prediction (cluster = 0).
The galaxy is primarily classified into Cluster 0 with a 68% probability based on its morphological characteristics. Key features influencing this decision include moderate values for smoothness and the absence of “has_signs_of_spiral” and “cigar_shaped” traits. Additionally, low values for “dominant_bulge” and “just_noticeable_bulge”, along with moderate values for “on_edge”, “spiral_barred”, and “obvious_bulge”, further support this classification.
The image corresponding to Galaxy ID = 236126 is shown in Figure 19.

Figure 19.
Galaxy ID 236126, Cluster 0.
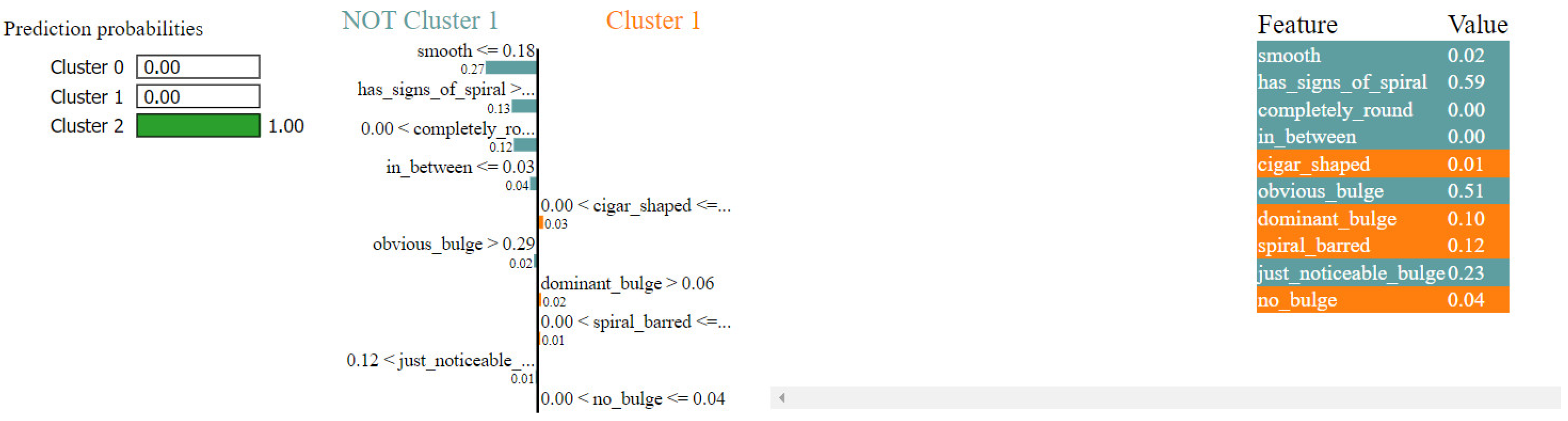
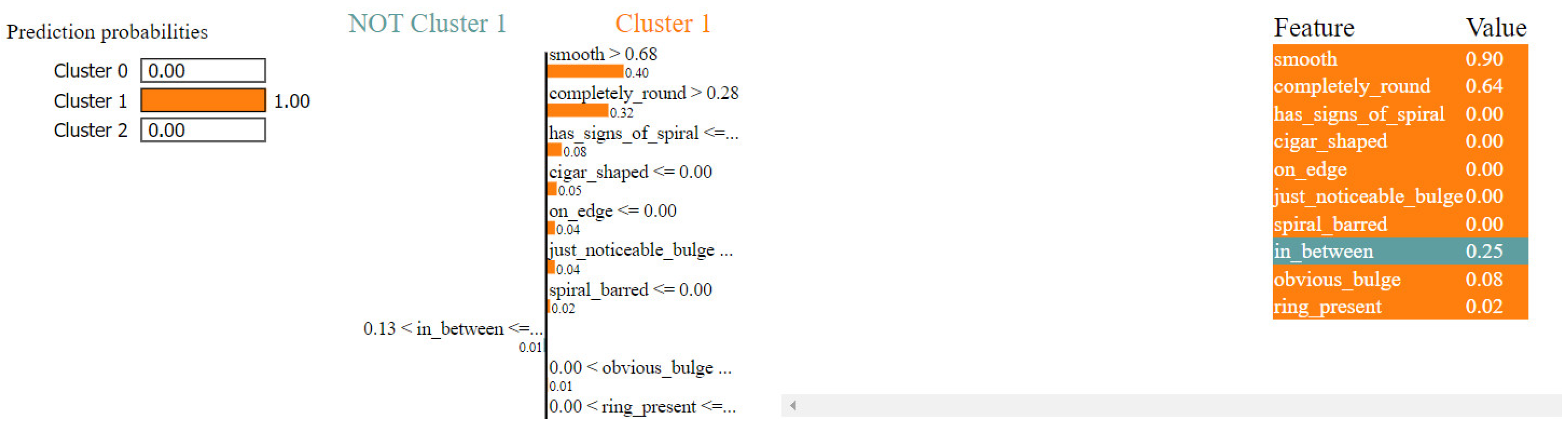
The LIME result shown in Figure 20 provides an explanation for the classification of a galaxy (Galaxy ID = 113992) with a 100% probability for Cluster 1.
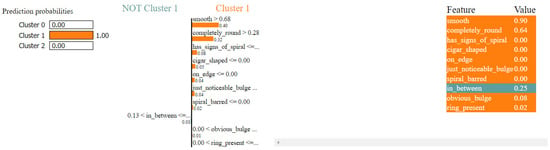
Figure 20.
Local cluster prediction (cluster = 1).
The galaxy is classified into Cluster 1 with a 100% probability, primarily due to its high values for smooth (0.90) and “completely_round” (0.64), which are the most significant contributors to this classification. The absence of spiral characteristics (“has_signs_of_spiral”: 0.00), cigar shape (“cigar_shaped”: 0.00), and edge-on view (“on_edge”: 0.00) also support this result. Additionally, low values for “just_noticeable_bulge” (0.00), “spiral_barred” (0.00), “obvious_bulge” (0.08), and “ring_present” (0.02) further reinforce the classification into Cluster 1. The feature “in_between” has a moderate value (0.25), slightly contradicting the overall classification, but is outweighed by the stronger contributions from other features.
The image corresponding to Galaxy ID = 113992 is shown in Figure 21.

Figure 21.
Galaxy ID 113992, Cluster 1.
5. Discussion
The present study has developed a comprehensive model for galaxy classification by integrating Fuzzy C-Means (FCM) clustering and predictive modeling, validated through Explainable AI techniques such as SHAP and LIME.
As observed in the related work (Section 2.2), most studies in galaxy classification primarily rely on convolutional neural networks and other deep learning techniques. These methods often achieve high classification accuracy but lack transparency and interpretability. Our study, in contrast, integrates Explainable Artificial Intelligence (XAI) methods, specifically SHAP and LIME, to provide both global and local interpretability, ensuring that the decision-making process behind the classification is understandable, unlike the studies analyzed in Section 2.1 that predominantly use global explanations. Furthermore, while many studies focus exclusively on algorithmic data classification, our work incorporates human-generated data from the Galaxy Zoo project, where non-expert volunteers contribute to the labeling of galaxies. This human interaction introduces an element of uncertainty, which we address through Fuzzy C-Means (FCM) clustering.
The model development and integration process began with employing Fuzzy C-Means (FCM) clustering to identify natural groupings within the galaxy dataset based on their morphological characteristics. This method allowed for the classification of galaxies into overlapping clusters, effectively accommodating the inherent uncertainty and variability in the data. Following this clustering step, a Random Forest model was trained to predict the cluster membership of new galaxies. By leveraging the identified clusters, the Random Forest model provided a robust predictive framework capable of accurately classifying new galaxy data.
Cluster characterization involves examining the centroids of the clusters to identify the key morphological features that define each group. These centroids represent the average values of the features for galaxies within each cluster, providing a clear understanding of the distinguishing characteristics of each cluster. SHAP values were then utilized to quantify the importance of each feature in the model’s predictions for each cluster, confirming that the model’s behavior aligns with prior knowledge about galaxy classification and ensuring relevant features were appropriately weighted. Additionally, LIME was used to provide local explanations for specific predictions, offering insights into how individual features influenced the model’s decisions for particular galaxies.
Model validation and interpretation revealed a strong correspondence between the defined clusters and the morphological types of galaxies through the combination of FCM clustering and SHAP/LIME analysis. This correspondence validates the effectiveness of both the clustering method and the predictive model. The predictive model also demonstrated a high degree of accuracy in assigning new galaxies to the appropriate clusters, extending its application to real-time galaxy classification tasks, thereby enhancing the efficiency and accuracy of astronomical research.
The utility and future improvements of this study highlight the potential for combining human visual analysis with AI-driven image analysis. By leveraging the strengths of both approaches, the model achieves a higher level of precision and reliability in galaxy classification. The enhanced interpretability provided by SHAP and LIME ensures that the model’s predictions are transparent and easily understandable, which is important for building trust in AI systems, particularly in scientific research where understanding the rationale behind decisions is critical. Additionally, the methodology developed in this study has broader applications and could be applied to other domains requiring the classification of complex data.
6. Conclusions and Future Work
The developed framework provides a robust and transparent approach to galaxy classification, which provides insight into the complex morphological characteristics of galaxies.
The integration of Fuzzy C-Means clustering with the Random Forest predictive model has proven to be highly effective in classifying galaxies based on their morphological characteristics, particularly when working with the Galaxy Zoo dataset, which is built upon non-expert opinions. The successful clustering of these images, despite the inherent variability introduced by the non-expert input, demonstrates a notable achievement in extracting meaningful clusters from the data.
Moreover, the application of Explainable AI (XAI) techniques such as SHAP and LIME further enhances our ability to assign new galaxy images to the appropriate clusters with high confidence. By utilizing user-generated data from Galaxy Zoo, the model successfully predicts the cluster to which a galaxy belongs, leveraging both the non-expert input and sophisticated clustering and prediction techniques.
The precision achieved in the Random Forest classification for each cluster further reinforces the accuracy of the methodology. The precision values obtained are as follows: Cluster 0 = 0.973; Cluster 1 = 0.991; and Cluster 2 = 0.987.
It can be noted that after applying SHAP to analyze feature importance for each cluster, the results aligned perfectly with the observations made through the Fuzzy C-Means classification. Additionally, using LIME, we conducted an in-depth analysis of three specific galaxy examples from each cluster, which allowed us to understand clearly why each galaxy was assigned to its respective cluster.
These results highlight the high level of precision achieved in classifying galaxies based on user-labeled data from Galaxy Zoo. The combination of Fuzzy C-Means and Random Forest, supported by XAI, allows for transparent and accurate classification, making it possible to incorporate human-driven insights into automated clustering models with great success.
In future work, it is proposed to advance in the following lines of research:
- Integration with Other Datasets: Future work will focus on integrating this methodology with other astronomical datasets to validate its robustness across several types of galaxy data.
- Refinement of Features: Further refinement of the features used in the model could enhance classification accuracy. Exploring additional morphological and contextual features will be a key area of research.
- Real-Time Classification: Developing a real-time classification system that can process and classify galaxies as new data becomes available will be a significant advancement.
- Expanding Interpretability Techniques: While SHAP and LIME have proven effective, exploring other interpretability techniques could provide deeper insights and improve model transparency further.
- Application to Other Domains: The methodology could be adapted for use in other domains where image classification and interpretability are important, such as medical imaging and remote sensing.
The results of this study demonstrate the potential of combining advanced clustering and predictive techniques with interpretability methods to achieve both high accuracy and transparency in complex classification tasks. This approach sets the stage for future advancements in galaxy classification and other scientific and technical fields requiring robust and Explainable AI models.
Author Contributions
Conceptualization, G.M.D.; methodology, G.M.D.; software, G.M.D.; validation, G.M.D., R.G.M. and J.A.A.J.; formal analysis, G.M.D.; investigation, G.M.D., R.G.M. and J.A.A.J.; resources, G.M.D.; data curation, G.M.D.; writing—original draft preparation, G.M.D.; writing—review and editing, G.M.D., R.G.M. and J.A.A.J.; visualization, G.M.D.; supervision, G.M.D., R.G.M. and J.A.A.J.; project administration, G.M.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Publicly accessible datasets were utilized for the analysis in this study. The data source can be accessed via the following link: https://www.zooniverse.org/projects/zookeeper/galaxy-zoo (accessed on 28 July 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zooniverse. Galaxy Zoo. 2004. Available online: https://www.zooniverse.org/projects/zookeeper/galaxy-zoo (accessed on 28 July 2024).
- Lintott, C.J.; Schawinski, K.; Slosar, A.; Land, K.; Bamford, S.; Thomas, D.; Raddick, M.J.; Nichol, R.C.; Szalay, A.; Andreescu, D.; et al. Galaxy Zoo: Morphologies derived from visual inspection of galaxies from the Sloan Digital Sky Survey. Mon. Not. R. Astron. Soc. 2008, 389, 1179–1189. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4766–4775. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, San Francisco, CA, USA, 13–17 August 2016; pp. 97–101. [Google Scholar] [CrossRef]
- Zhang, X.F.; Zhang, C.M.; Tang, W.J.; Wei, Z.W. Medical image segmentation using improved FCM. Sci. China Inf. Sci. 2012, 55, 1052–1061. [Google Scholar] [CrossRef]
- Pham, D.L.; Xu, C.; Prince, J.L. Current Methods in Medical Image Segmentation. Annu. Rev. Biomed. Eng. 2000, 2, 315–337. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Mishra, N.S.; Ghosh, S. Fuzzy clustering algorithms for unsupervised change detection in remote sensing images. Inf. Sci. 2011, 181, 699–715. [Google Scholar] [CrossRef]
- Pal, N.R.; Pal, S.K. A review on image segmentation techniques. Pattern Recognit. 1993, 26, 1277–1294. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef]
- Ho, T.H.; Park, Y.H.; Zhou, Y.P. Incorporating satisfaction into customer value analysis: Optimal investment in lifetime value. Mark. Sci. 2006, 25, 260–277. [Google Scholar] [CrossRef]
- Díaz, G.M.; Carrasco, R.A.; Gómez, D. RFID: A Fuzzy Linguistic Model to Manage Customers from the Perspective of Their Interactions with the Contact Center. Mathematics 2021, 9, 2362. [Google Scholar] [CrossRef]
- Datta, S.; Datta, S. Methods for evaluating clustering algorithms for gene expression data using a reference set of functional classes. BMC Bioinform. 2006, 7, 397. [Google Scholar] [CrossRef]
- Kocak, C.; Egrioglu, E.; Bas, E. A new explainable robust high-order intuitionistic fuzzy time-series method. Soft Comput. 2023, 27, 1783–1796. [Google Scholar] [CrossRef]
- Ghosh, I.; Chaudhuri, T.D.; Sarkar, S.; Mukhopadhyay, S.; Roy, A. Macroeconomic shocks, market uncertainty and speculative bubbles: A decomposition-based predictive model of Indian stock markets. China Financ. Rev. Int. 2024. [Google Scholar] [CrossRef]
- Kmita, K.; Kaczmarek-Majer, K.; Hryniewicz, O. Explainable Impact of Partial Supervision in Semi-Supervised Fuzzy Clustering. IEEE Trans. Fuzzy Syst. 2024, 32, 3189–3198. [Google Scholar] [CrossRef]
- Sevas, M.S.; Sharmin, N.; Santona, C.F.T.; Sagor, S.R. Advanced Ensemble Machine-Learning and Explainable AI with Hybridized Clustering for Solar Irradiation Prediction in Bangladesh. Theor. Appl. Climatol. 2024, 155, 5695–5725. [Google Scholar] [CrossRef]
- Sirapangi, M.D.; Gopikrishnan, S. MAIPFE: An Efficient Multimodal Approach Integrating Pre-Emptive Analysis, Personalized Feature Selection, and Explainable AI. Comput. Mater. Contin. 2024, 79, 2229–2251. [Google Scholar] [CrossRef]
- Arabikhan, F.; Gegov, A.; Kaymak, U.; Akbari, N. Fuzzy Networks for Explainable Artificial Intelligence. In Proceedings of the 2023 IEEE Conference on Artificial Intelligence (CAI), Santa Clara, CA, USA, 5–6 June 2023; pp. 199–200. [Google Scholar] [CrossRef]
- Priya, C.; Durai Raj Vincent, P.M. An Efficient CSPK-FCM Explainable Artificial Intelligence Model on COVID-19 Data to Predict the Emotion Using Topic Modeling. J. Adv. Inf. Technol. 2023, 14, 1390–1402. [Google Scholar] [CrossRef]
- Akpan, A.G.; Nkubli, F.B.; Ezeano, V.N.; Okwor, A.C.; Ugwuja, M.C.; Offiong, U. XAI for medical image segmentation in medical decision support systems. In Explainable Artificial Intelligence in Medical Decision Support Systems; Imoize, A.L., Hemanth, J., Do, D.T., Sur, S.N., Eds.; The Institution of Engineering and Technology: Stevenage, UK, 2022; Volume 50, pp. 137–165. [Google Scholar]
- Lin, S.Y.; Wei, J.T.; Weng, C.C.; Wu, H.H. A Case Study of Using Classification and Regression Tree and LRFM Model in A Pediatric Dental Clinic. Innov. Manag. Serv. Icms 2011, 14, 131–135. [Google Scholar]
- Ndung’u, S.; Grobler, T.; Wijnholds, S.J.; Karastoyanova, D.; Azzopardi, G. Advances on the morphological classification of radio galaxies: A review. New Astron. Rev. 2023, 97, 101685. [Google Scholar] [CrossRef]
- Ma, X.; Li, X.; Luo, A.; Zhang, J.; Li, H. Galaxy image classification using hierarchical data learning with weighted sampling and label smoothing. Mon. Not. R. Astron. Soc. 2023, 519, 4765–4779. [Google Scholar] [CrossRef]
- Stoppa, F.; Bhattacharyya, S.; Ruiz de Austri, R.; Vreeswijk, P.; Caron, S.; Zaharijas, G.; Bloemen, S.; Principe, G.; Malyshev, D.; Vodeb, V.; et al. Astrophysics Star-galaxy classification using a convolutional neural network. Astron. Astrophys. 2023, 680, A109. [Google Scholar] [CrossRef]
- Schneider, J.; Stenning, D.C.; Elliott, L.T. Efficient galaxy classification through pretraining. Front. Astron. Space Sci. 2023, 10, 1197358. [Google Scholar] [CrossRef]
- Şenel, F.A. A Hyperparameter Optimization for Galaxy Classification. Comput. Mater. Contin. 2023, 74, 4587–4600. [Google Scholar] [CrossRef]
- Shafique, U.; Qaiser, H. A Comparative Study of Data Mining Process Models (KDD, CRISP-DM and SEMMA). Int. J. Innov. Sci. Res. 2014, 12, 217–222. Available online: http://www.ijisr.issr-journals.org/ (accessed on 20 July 2024).
- Parsaei, M.R.; Rostami, S.M.; Javidan, R. A Hybrid Data Mining Approach for Intrusion Detection on Imbalanced NSL-KDD Dataset. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 20–25. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable; 2019; p. 247, Self-published; Available online: https://christophm.github.io/interpretable-ml-book (accessed on 20 July 2024).
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electron. 2019, 8, 832. [Google Scholar] [CrossRef]
- Monje, L.; Carrasco, R.A.; Rosado, C.; Sánchez-Montañés, M. Deep Learning XAI for Bus Passenger Forecasting: A Use Case in Spain. Mathematics 2022, 10, 1428. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-Agnostic Interpretability of Machine Learning. 2016. Available online: http://arxiv.org/abs/1606.05386 (accessed on 20 July 2024).
- Lou, Y.; Caruana, R.; Gehrke, J.; Hooker, G. Accurate intelligible models with pairwise interactions. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; Part F1288. pp. 623–631. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.G.; Lee, S.-I. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv 2018. [Google Scholar] [CrossRef]
- Zafar, M.R.; Khan, N.M. DLIME: A Deterministic Local Interpretable Model-Agnostic Explanations Approach for Computer-Aided Diagnosis Systems. arXiv 2019. [Google Scholar] [CrossRef]
- Willett, K.W.; Lintott, C.J.; Bamford, S.P.; Masters, K.L.; Simmons, B.D.; Casteels, K.R.V.; Edmondson, E.M.; Fortson, L.F.; Kaviraj, S.; Keel, W.C.; et al. Galaxy zoo 2: Detailed morphological classifications for 304 122 galaxies from the sloan digital sky survey. Mon. Not. R. Astron. Soc. 2013, 435, 2835–2860. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).