
Enhancing Predictive Models for On-Street Parking Occupancy: Integrating Adaptive GCN and GRU with Household Categories and POI Factors


Abstract
1. Introduction
- This study introduces the novel AGCRU model, which combines the strengths of Adaptive Graph Convolutional Networks (GCNs) and Gated Recurrent Units (GRUs). This model is further enhanced by integrating Points of Interest (POIs) and household data, significantly improving the prediction accuracy of on-street parking occupancy.
- A unique feature of the AGCRU model is the implementation of an adaptive adjacency matrix. In contrast to traditional static graph models, the adjacency relationships are dynamically adjusted by the adaptive GCN component based on real-time data changes. This significantly enhances the model’s ability to be accurately taught and to capture the spatial dependencies inherent in urban environments.
- The AGCRU model was validated using a large-scale real-world dataset from Melbourne, demonstrating its performance over existing models through comprehensive testing across multiple time intervals.
2. Related Work
2.1. On-Street Parking Occupancy Feature
2.2. Methodologies of Parking Occupancy Prediction
2.3. Influencing Factors of Parking Prediction
3. Prediction Methodology
3.1. Overview of the Prediction Methodology
3.2. Adaptive Spatial Correlation Relationship Model
3.2.1. Adaptive Adjacency Matrix

| Algorithm 1: Calculate Learnable Adjacency Matrix in Adaptive GCN | ||
| Input: | A learnable adjacency matrix parameter | |
| Output: | , and the Laplacian matrix L | |
| 1. | Normalize Adjacency Matrix | |
| Calculate the degree matrix D by summing each row of the adjacency matrix A. | ||
| Calculate the inverse square root of D. Replace any infinite values with zeros. | ||
| . | ||
| 2. | Compute Laplacian Matrix | |
| Create the identity matrix I of shape (V, V) with the same data type and device as A. | ||
| . | ||
| 3. | Return | |
| . Output the Laplacian matrix L. | ||
3.2.2. Enhanced Feature Representation
| Algorithm 2: Adaptive Graph Convolutional Network (Adaptive GCN) Operations | |
| Input: | Node features matrix X, updated adjacency matrix A, degree matrix D, and layer weights W. |
| Output: | Transformed features suitable for parking occupancy prediction. |
| 1. | Initialize Graph Convolution Layers: Adjacency and Degree Matrices: Set for Ak and Dk for each type of connection considering edge types or directions. |
| 2. | Chebyshev Polynomial Filter Application: Input: Node features matrix X along with the Laplacian matrix L. Process: Apply the Chebyshev polynomial filter to transform features |
| 3. | Graph Convolution Operations: For each layer l perform:
|
| 4. | Feature Pooling and Normalization: Max Pooling: Insert max pooling layers between convolution layers to reduce feature dimensionality and computational load. Batch Normalization: Apply batch normalization to standardize the features of each layer. |
| 5. | Output Processing Integration: Combine all processed features for the final output suitable for parking occupancy prediction tasks. |
| 6. | Return the processed sequence data ready for application in prediction tasks. |
3.2.3. Adaptive GCN Generation
3.3. Temporal Correlation Relationship Model Structure
3.3.1. Temporal Dynamics in Parking Demand
3.3.2. GRU Model Generation
| Algorithm 3: Time Series Feature Extraction using GRU | ||
| Input: | A tensor of time series data with shape [batch_size, sequence_length, input_dim]. | |
| Output: | A tensor of processed sequence data with shape [batch_size, output_dim]. | |
| 1. | Initialize the GRU model with input dimension D, hidden size, number of GRU layers, output dimension, and dropout rate GRU. | |
| 2. | Define the first GRU layer: | |
| 1. | Input dimension: D | |
| 2. | Hidden size: Hidden_size | |
| 3. | Define the second GRU layer: | |
| 1. | Input dimension: Hidden_size | |
| 2. | Hidden size: Hidden_size | |
| 4. | Define the fully connected layer: | |
| Input dimension: hidden_size. Output dimension: num_output. | ||
| 5. | For each batch of input data: | |
| 1. | Initialize the hidden state h01 for the first GRU layer with zeros. | |
| 2. | Perform the forward pass through the first GRU layer: Input: Tensor of shape [batch_size, sequence_length, D]. Output: Tensor out1 and hidden state | |
| 3. | Initialize the hidden state h02 for the second GRU layer with zeros. | |
| 4. | Perform the forward pass through the second GRU layer: Input: Tensor out1 from the first GRU layer. Output: Tensor out2 and hidden state. | |
| 5. | Apply the fully connected layer to the output of the second GRU layer: Input: Tensor out2 of shape [batch_size, sequence_length, hidden_size]. Output: Tensor of shape [batch_size, num_output]. | |
| 6. | Return the processed sequence data. | |
3.4. Model Validation
- Root mean square error:
- Mean absolute error:
- The mean absolute percentage error:
4. Case Study
4.1. Research Area
4.2. Data Description
4.2.1. On-Street Parking Data
4.2.2. Land Use (POI)
- 1.
- Landmarks and places of interest
- 2.
- Distribution of cafés, restaurants, and bistros
- 3.
- Location and industry classification of business establishments
4.2.3. Residential Dwelling Data
4.3. Hyperparameters
4.4. Data Processing
5. Results Analysis and Discussion
5.1. The Accuracy of the Parking Occupancy Prediction Results
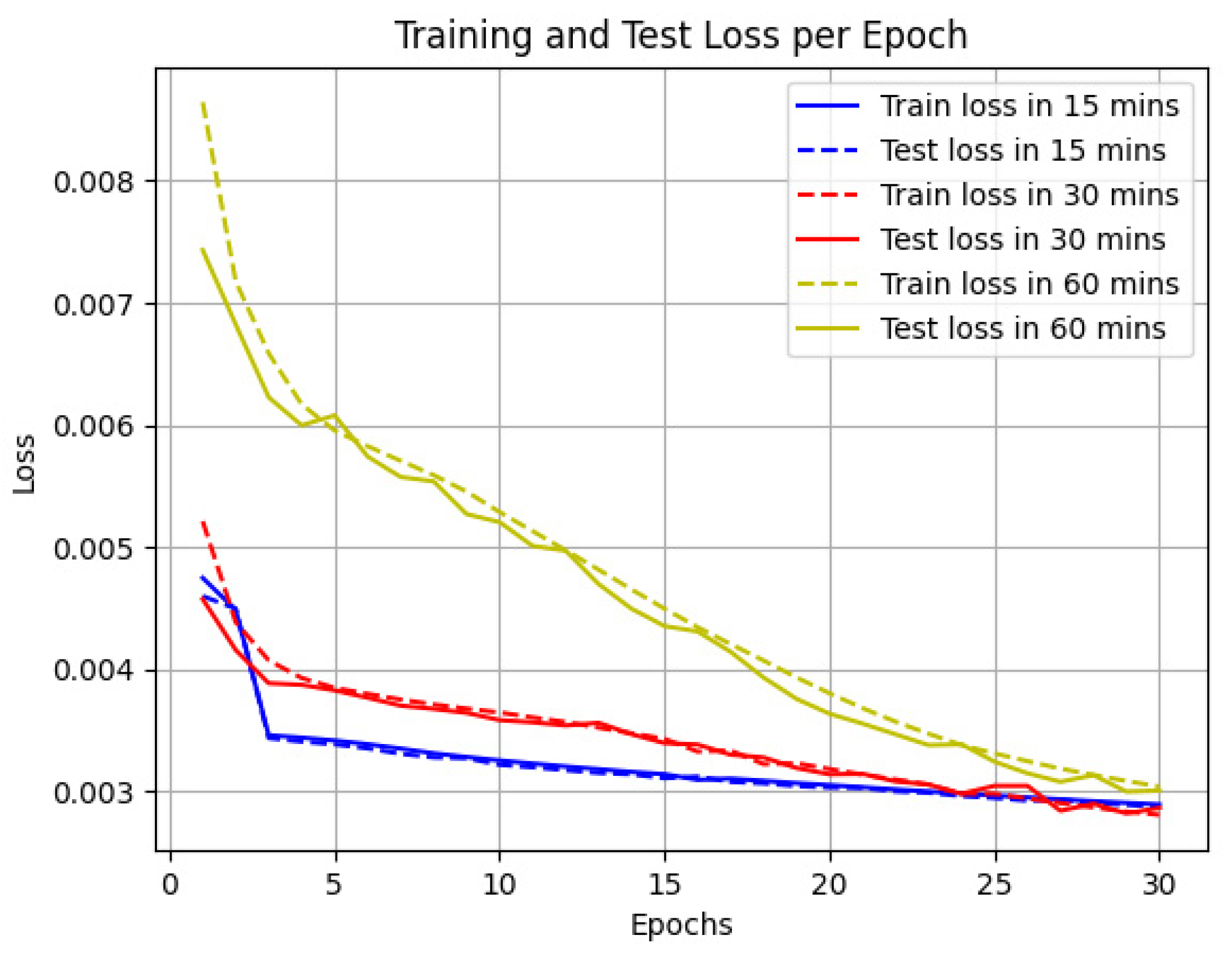
5.2. The Performance of the Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fulman, N.; Benenson, I.; Ben-Elia, E. Modeling parking search behavior in the city center: A game-based approach. Transp. Res. Part C Emerg. Technol. 2020, 120, 102800. [Google Scholar] [CrossRef]
- Xiao, R.I.; Jaller, M. Prediction framework for parking search cruising time and emissions in dense urban areas. Transportation 2023, 1–29. [Google Scholar] [CrossRef]
- Hampshire, R.C.; Jordon, D.; Akinbola, O.; Richardson, K.; Weinberger, R.; Millard-Ball, A.; Karlin-Resnik, J. Analysis of parking search behavior with video from naturalistic driving. Transp. Res. Rec. 2016, 2543, 152–158. [Google Scholar] [CrossRef]
- Zong, F.; Zeng, M.; Yu, P. A parking pricing scheme considering parking dynamics. Transportation 2023, 51, 1349–1371. [Google Scholar] [CrossRef]
- Kaur, R.; Roul, R.K.; Batra, S. A hybrid deep learning CNN-ELM approach for parking space detection in Smart Cities. Neural Comput. Appl. 2023, 35, 13665–13683. [Google Scholar] [CrossRef]
- Gong, S.; Qin, J.; Xu, H.; Cao, R.; Liu, Y.; Jing, C.; Hao, Y.; Yang, Y. Spatio-temporal parking occupancy forecasting integrating parking sensing records and street-level images. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103290. [Google Scholar] [CrossRef]
- Feng, N.; Zhang, F.; Lin, J.; Zhai, J.; Du, X. Statistical analysis and prediction of parking behavior. In Proceedings of the Network and Parallel Computing: 16th IFIP WG 10.3 International Conference, NPC 2019, Hohhot, China, 23–24 August 2019; Proceedings 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 93–104. [Google Scholar]
- Liu, Y.; Liu, C.; Luo, X. Spatiotemporal deep-learning networks for shared-parking demand prediction. J. Transp. Eng. Part A Syst. 2021, 147, 04021026. [Google Scholar] [CrossRef]
- Ye, W.; Kuang, H.; Lai, X.; Li, J. A multi-view approach for regional parking occupancy prediction with attention mechanisms. Mathematics 2023, 11, 4510. [Google Scholar] [CrossRef]
- Yang, S.; Ma, W.; Pi, X.; Qian, S. A deep learning approach to real-time parking occupancy prediction in transportation networks incorporating multiple spatio-temporal data sources. Transp. Res. Part C Emerg. Technol. 2019, 107, 248–265. [Google Scholar] [CrossRef]
- Kuo, P.-F.; Hsu, W.-T.; Putra, I.G.B.; Sulistyah, U.D. The proposed model for analyzing off-street parking Dynamics: A case study of Taipei City. Transp. Res. Part A Policy Pract. 2024, 180, 103965. [Google Scholar] [CrossRef]
- Zhao, D.; Ju, C.; Zhu, G.; Ning, J.; Luo, D.; Zhang, D.; Ma, H. MePark: Using meters as sensors for citywide on-street parking availability prediction. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7244–7257. [Google Scholar] [CrossRef]
- Rajabioun, T.; Ioannou, P.A. On-street and off-street parking availability prediction using multivariate spatiotemporal models. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2913–2924. [Google Scholar] [CrossRef]
- Shao, W.; Zhang, Y.; Xiao, P.; Qin, K.K.; Rahaman, M.S.; Chan, J.; Guo, B.; Song, A.; Salim, F.D. Transferrable contextual feature clusters for parking occupancy prediction. Pervasive Mob. Comput. 2024, 97, 101831. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, Y.; Feng, N.; Yang, C.; Zhai, J.; Zhang, S.; He, B.; Lin, J.; Zhang, X.; Du, X. Periodic weather-aware LSTM with event mechanism for parking behavior prediction. IEEE Trans. Knowl. Data Eng. 2021, 34, 5896–5909. [Google Scholar] [CrossRef]
- Nourinejad, M.; Roorda, M.J. Impact of hourly parking pricing on travel demand. Transp. Res. Part A Policy Pract. 2017, 98, 28–45. [Google Scholar] [CrossRef]
- Torres-López, R.; Casillas-Pérez, D.; Pérez-Aracil, J.; Cornejo-Bueno, L.; Alexandre, E.; Salcedo-Sanz, S. Analysis of machine learning approaches’ performance in prediction problems with human activity patterns. Mathematics 2022, 10, 2187. [Google Scholar] [CrossRef]
- Ho, P.W.; Ghadiri, S.M.; Rajagopal, P. Future Parking Demand at Rail Stations in Klang Valley. Proc. MATEC Web Conf. 2017, 103, 09001. [Google Scholar] [CrossRef]
- Chen, H.; Yang, M.; Zhang, Y.; Wen, H. Parking Spaces Demand Forecasting Based on ARIMA Model. In Proceedings of the Proceedings of the 2023 15th International Conference on Computer Modeling and Simulation, Dalian, China, 16–18 June 2023; pp. 133–137. [Google Scholar]
- Tavafoghi, H.; Poolla, K.; Varaiya, P. A queuing approach to parking: Modeling, verification, and prediction. arXiv 2019, arXiv:1908.11479. [Google Scholar]
- Hess, D.B. Access to public transit and its influence on ridership for older adults in two US cities. J. Transp. Land Use 2009, 2, 3–27. [Google Scholar] [CrossRef]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Qu, H.; Liu, S.; Li, J.; Zhou, Y.; Liu, R. Adaptation and learning to learn (all): An integrated approach for small-sample parking occupancy prediction. Mathematics 2022, 10, 2039. [Google Scholar] [CrossRef]
- Yang, H.; Ke, R.; Cui, Z.; Wang, Y.; Murthy, K. Toward a real-time smart parking data management and prediction (SPDMP) system by attributes representation learning. Int. J. Intell. Syst. 2022, 37, 4437–4470. [Google Scholar] [CrossRef]
- Haomin, G. Analysis of Space-Time Demand Characteristics and State Evaluation of Large Scale Complex Parking Lots Based on Parking Space. Master’s Thesis, Southeast University, Nanjing, China, 2021. [Google Scholar]
- Van Ommeren, J.N.; Wentink, D.; Rietveld, P. Empirical evidence on cruising for parking. Transp. Res. Part A Policy Pract. 2012, 46, 123–130. [Google Scholar] [CrossRef]
- Shoup, D. High Cost of Free Parking; Routledge: London, UK, 2021. [Google Scholar]
- Pierce, G.; Shoup, D. Getting the prices right: An evaluation of pricing parking by demand in San Francisco. J. Am. Plan. Assoc. 2013, 79, 67–81. [Google Scholar] [CrossRef]
- Mei, Z.; Zhang, W.; Zhang, L.; Wang, D. Optimization of reservation parking space configurations in city centers through an agent-based simulation. Simul. Model. Pract. Theory 2020, 99, 102020. [Google Scholar] [CrossRef]
- Inci, E. A review of the economics of parking. Econ. Transp. 2015, 4, 50–63. [Google Scholar] [CrossRef]
- Chao, Z.; Zihao, C.; Hao, Q. Time-Domain Characteristics of Residential Parking and SEM-BL Integration Model of Parking Method Choice Behaviour. Math. Probl. Eng. 2022, 2022, 5164257. [Google Scholar] [CrossRef]
- Bai, L.; Sze, N.; Liu, P.; Haggart, A.G. Effect of environmental awareness on electric bicycle users’ mode choices. Transp. Res. Part D Transp. Environ. 2020, 82, 102320. [Google Scholar] [CrossRef]
- Christiansen, P.; Engebretsen, Ø.; Fearnley, N.; Hanssen, J.U. Parking facilities and the built environment: Impacts on travel behaviour. Transp. Res. Part A Policy Pract. 2017, 95, 198–206. [Google Scholar] [CrossRef]
- Zhou, C.; Jia, H.; Juan, Z.; Fu, X.; Xiao, G. A data-driven method for trip ends identification using large-scale smartphone-based GPS tracking data. IEEE Trans. Intell. Transp. Syst. 2016, 18, 2096–2110. [Google Scholar] [CrossRef]
- Shoup, D. Pricing curb parking. Transp. Res. Part A Policy Pract. 2021, 154, 399–412. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on graphs via spectral graph theory. Appl. Comput. Harmon. Anal. 2011, 30, 129–150. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Li, R.; Wang, S.; Zhu, F.; Huang, J. Adaptive graph convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparison of ARIMA and LSTM in forecasting time series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 922–929. [Google Scholar]
- Xiao, X.; Jin, Z.; Hui, Y.; Xu, Y.; Shao, W. Hybrid spatial–temporal graph convolutional networks for on-street parking availability prediction. Remote Sens. 2021, 13, 3338. [Google Scholar] [CrossRef]
- Ho, Y.; Wookey, S. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Melbourne’s Public Transport System. Available online: https://transport.vic.gov.au (accessed on 29 November 2023).
- Parking in Melbourne: Strategy and Policies. Available online: https://www.melbourne.vic.gov.au (accessed on 10 July 2023).
- Yan, X.; Levine, J.; Marans, R. The effectiveness of parking policies to reduce parking demand pressure and car use. Transp. Policy 2019, 73, 41–50. [Google Scholar] [CrossRef]
- Arnott, R. Spatial competition between parking garages and downtown parking policy. Transp. Policy 2006, 13, 458–469. [Google Scholar] [CrossRef]
- City of Melbourne Open Data Team. On-Street Parking Bay Sensors; City of Melbourne Open Data Team: Melbourn, Australia, 2024.
- City of Melbourne. On-Street Car Parking Sensor Data—2019. Available online: https://data.melbourne.vic.gov.au/explore/dataset/on-street-car-parking-sensor-data-2019/information/ (accessed on 7 October 2023).
- Landmarks and Places of Interest, Including Schools, Theatres, Health Services, Sports Facilities, Places of Worship, Galleries, and Museums. Available online: https://data.melbourne.vic.gov.au/explore/dataset/landmarks-and-places-of-interest-including-schools-theatres-health-services-spor/table/?location=15,-37.82075,144.96226&basemap=mbs-7a7333 (accessed on 29 November 2023).
- Café, Restaurant, Bistro Seats. Available online: https://data.melbourne.vic.gov.au/explore/dataset/cafes-and-restaurants-with-seating-capacity/information/ (accessed on 15 December 2023).
- Pink, D.T.B. Australian and New Zealand Standard Industrial Classification. Available online: https://www.abs.gov.au/statistics/classifications/australian-and-new-zealand-standard-industrial-classification-anzsic/latest-release (accessed on 8 July 2023).
- Central Geelong Census of Land Use and Employment (CLUE). Available online: https://www.geelongdataexchange.com.au/pages/cluev2/#:~:text=The%20Central%20Geelong%20Census%20of%20Land%20Use%20and,land%20use%2C%20and%20identifies%20key%20trends%20in%20employment (accessed on 15 December 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Theme | Study Reference | Methodology | Main Findings | Research Gaps |
| On-Street Parking Occupancy Feature | [10,11,12,13] | Spatiotemporal distribution patterns in similar cities | Consistent periodicity and trends in cities with similar population structures and commercial activities | Limited discussion on varying urban layouts and cultural backgrounds |
| [14] | Periodicity and trends in parking occupancy | Consistent periodicity and trends in parking occupancy | Model complexity and computational demands not addressed | |
| [15] | Periodic weather-aware LSTM model (PewLSTM) | Precisely predicts parking behavior during various periods including holidays and pandemics | Challenges in handling sudden non-periodic events | |
| [16] | Spatiotemporal heterogeneity in different urban areas | Significant variation in parking needs by location and time in residential and office areas | Further research needed on micro-level influences like individual preferences | |
| Theme | Reference | Technique/Focus | Main Findings | Research Gaps |
| Methodologies of parking occupancy prediction | [18] | Linear Regression | Developed a parking demand forecasting model | Limitations in capturing complex interactions and nonlinear phenomena |
| [19] | ARIMA Model | Applied for parking space occupancy prediction | Limitations in capturing complex interactions and nonlinear phenomena | |
| [20] | Queueing Model | Real-time estimation of parking lot occupancy | Challenges persist regarding regional applicability and flexibility | |
| [21] | PARKFIT Algorithm | Analyzed urban parking distribution with high-resolution data | Challenges persist regarding regional applicability and flexibility | |
| [23] | ALL Approach (Deep Learning, Federated Learning) | Improved small-sample parking occupancy prediction accuracy | Challenges persist regarding regional applicability and flexibility | |
| [24] | Deep Learning Architectures (Graph Convolutional Neural Networks, Recurrent Neural Networks) | Enhanced the accuracy of real-time predictions for urban street-level parking occupancy | Challenges persist regarding regional applicability and flexibility | |
| Theme | Reference | Focus Area | Main Findings | Research Gap |
| Influencing factors of parking prediction | [26] | Building Scale and Parking Demand | Larger commercial centers have higher parking demand than residential areas | Does not account for changes over time or special events |
| [27] | Mixed-Use Areas | Suggests mixed-use areas can reduce parking demand by optimizing travel | Limited empirical evidence to support claim | |
| [28] | Public Transportation and Parking Pressure | Efficient public transportation can alleviate parking pressure in business districts | Focuses only on core business districts, not wider urban areas | |
| [29] | Dynamic Changes in Parking Demand | Analyzed parking demand variability across times and regions | Focus primarily on proxy modeling without extensive real-world validation | |
| [30] | Economic Influence on Parking Choices | Higher fees may drive low-income groups to alternate travel modes | Does not address middle or high-income impacts | |
| [31] | Socioeconomic Background and Parking Behavior | Varied parking behavior among socioeconomic groups | Limited scope to specific demographic data | |
| [32] | Environmental Awareness | Environmental awareness influences parking choices | Lack of broader demographic applicability | |
| [33] | Parking Facilities and Built Environment | Accessibility and regulations significantly affect car usage patterns | Limited to parking facilities’ impact without considering broader transportation network impacts | |
| [34] | Optimization of Parking Resources | Should respond flexibly to dynamic demand changes |
| Feature | Description |
|---|---|
| Parking lots ID | The unique location code of parking space sensor |
| Arrival time | The moment at which the sensors registered the arrival of vehicles |
| Departure time | The moment at which the sensors registered the arrival of vehicles |
| Location | Geographical information of Longitude/Latitude |
| Status description | Unoccupied/Occupied |
| Feature | Description |
|---|---|
| Theme | Community Use, Education Center, Health Services, Leisure/Recreation, Mixed Use, Office, Place of Assembly, Place of Worship, Purpose Built, Retail, Transport, Vacant Land |
| Subtheme | Art Gallery/Museum, Church, Function/Conference/Exhibition Center, Informal Outdoor Facility (Park/Garden/Reserve), Major Sports and Recreation Facility, Office, Public Buildings, Public Hospital, Railway Station, Retail/Office/Carpark, Tertiary (University), Theater Live |
| Feature name | Name of landmarks and place of interest |
| Location | Geographical information of Longitude/Latitude |
| Feature | Description |
|---|---|
| Year | The recording year of food service venues |
| Building address | The detail address of food service venues |
| Trading name | The name of food service venues |
| Industry description | Pubs, Taverns, Bar, Takeaway food service, Bakery product Manufacturing, Accommodation |
| Seating type | Outdoor/Indoor |
| Number of seats | The capacity of food service venues |
| Location | Geographical information of Longitude/Latitude |
| Feature | Description |
|---|---|
| Year | The recording year of business establishments venues |
| Trading name | Name of building |
| Business address | The detail address of business building |
| Industry description | Category of industry |
| Location | Geographical information of Longitude/Latitude |
| Feature | Description |
|---|---|
| Date | The update time of building location |
| Building address | Detail address of building |
| Dwelling type | Residential Apartment, House/Townhouse, Student Apartment |
| Location | Geographical information of Longitude/Latitude |
| MAE | AGCRU | ARIMA | LSTM | ST-GCN | ASTGCN | HST-GCN |
| 15 min | 0.0156 | 0.0544 | 0.0644 | 0.0355 | 0.0351 | 0.0345 |
| 30 min | 0.0330 | 0.0696 | 0.0769 | 0.0467 | 0.0466 | 0.0456 |
| 60 min | 0.0558 | 0.0982 | 0.1004 | 0.0630 | 0.0627 | 0.0593 |
| RMSE | AGCRU | ARIMA | LSTM | STGCN | ASTGCN | HST-GCN |
| 15 min | 0.0244 | 0.0711 | 0.0886 | 0.0494 | 0.0518 | 0.0487 |
| 30 min | 0.0665 | 0.0906 | 0.1037 | 0.0639 | 0.0665 | 0.0632 |
| 60 min | 0.1003 | 0.1236 | 0.1329 | 0.0851 | 0.0858 | 0.0801 |
| MAPE% | AGCRU | ARIMA | LSTM | STGCN | ASTGCN | HST-GCN |
| 15 min | 1.5561 | 10.4794 | 10.5566 | 7.2983 | 9.9607 | 7.1222 |
| 30 min | 3.3071 | 13.5052 | 12.9892 | 9.7159 | 13.3459 | 9.3656 |
| 60 min | 5.5810 | 19.1953 | 17.5452 | 12.9341 | 19.2274 | 12.2568 |
| ST-GCN | AST-GCN | HST-GCN | AGCRU |
|---|---|---|---|
| 151.83 | 623.77 | 152.05 | 147.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Zhang, M. Enhancing Predictive Models for On-Street Parking Occupancy: Integrating Adaptive GCN and GRU with Household Categories and POI Factors. Mathematics 2024, 12, 2823. https://doi.org/10.3390/math12182823
Zhao X, Zhang M. Enhancing Predictive Models for On-Street Parking Occupancy: Integrating Adaptive GCN and GRU with Household Categories and POI Factors. Mathematics. 2024; 12(18):2823. https://doi.org/10.3390/math12182823
Chicago/Turabian StyleZhao, Xiaohang, and Mingyuan Zhang. 2024. "Enhancing Predictive Models for On-Street Parking Occupancy: Integrating Adaptive GCN and GRU with Household Categories and POI Factors" Mathematics 12, no. 18: 2823. https://doi.org/10.3390/math12182823
APA StyleZhao, X., & Zhang, M. (2024). Enhancing Predictive Models for On-Street Parking Occupancy: Integrating Adaptive GCN and GRU with Household Categories and POI Factors. Mathematics, 12(18), 2823. https://doi.org/10.3390/math12182823